以 Flink 和 Spark 为代表的分布式流批计算框架的下层资源管理平台逐渐从 Hadoop 生态的 YARN 转向 Kubernetes 生态的 k8s 原生 scheduler 以及周边资源调度器,比如 Volcano 和 Yunikorn 等。这篇文章简单比较一下两种计算框架在 Native Kubernetes 的支持和实现上的异同,以及对于应用到生产环境我们还需要做些什么。
1. 什么是 Native
这里的 native 其实就是计算框架直接向 Kubernetes 申请资源。比如很多跑在 YARN 上面的计算框架,需要自己实现一个 AppMaster 来想 YARN 的 ResourceManager 来申请资源。Native K8s 相当于计算框架自己实现一个类似 AppMaster 的角色向 k8s 去申请资源,当然和 AppMaster 还是有差异的 (AppMaster 需要按 YARN 的标准进行实现)。
2. Spark on k8s 使用
提交作业
向 k8s 集群提交作业和往 YARN 上面提交很类似,命令如下,主要区别包括:
- --master 参数指定 k8s 集群的 ApiServer
- 需要通过参数 spark.kubernetes.container.image 指定在 k8s 运行作业的 image,
- 指定 main jar,需要 driver 进程可访问:如果 driver 运行在 pod 中,jar 包需要包含在镜像中;如果 driver 运行在本地,那么 jar 需要在本地。
- 通过 --name 或者 spark.app.name 指定 app 的名字,作业运行起来之后的 driver 命名会以 app 名字为前缀。当然也可以通过参数 spark.kubernetes.driver.pod.name 直接指定 dirver 的名字
$ ./bin/spark-submit \
--master k8s://https://: \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image= \
local:///path/to/examples.jar提交完该命令之后,spark-submit 会创建一个 driver pod 和一个对应的 servcie,然后由 driver 创建 executor pod 并运行作业。
deploy-mode
和在 YARN 上面使用 Spark 一样,在 k8s 上面也支持 cluster 和 client 两种模式:
- cluster mode: driver 在 k8s 集群上面以 pod 形式运行。
- client mode: driver 运行在提交作业的地方,然后 driver 在 k8s 集群上面创建 executor。为了保证 executor 能够注册到 driver 上面,还需要提交作业的机器可以和 k8s 集群内部的 executor 网络连通(executor 可以访问到 driver,需要注册)。
资源清理
这里的资源指的主要是作业的 driver 和 executor pod。spark 通过 k8s 的 onwer reference 机制将作业的各种资源连接起来,这样当 driver pod 被删除的时候,关联的 executor pod 也会被连带删除。但是如果没有 driver pod,也就是以 client 模式运行作业的话,如下两种情况涉及到资源清理:
- 作业运行完成,driver 进程退出,executor pod 运行完自动退出
- driver 进程被杀掉,executor pod 连不上 driver 也会自行退出
可以参考:
https://kubernetes.io/docs/concepts/architecture/garbage-collection/
依赖管理
前面说到 main jar 包需要在 driver 进程可以访问到的地方,如果是 cluster 模式就需要将 main jar 打包到 spark 镜像中。但是在日常开发和调试中,每次重新 build 一个镜像的 effort 实在是太大了。spark 支持提交的时候使用本地的文件,然后使用 s3 等作为中转:先上传上去,然后作业运行的时候再从 s3 上面下载下来。下面是一个实例。
...
--packages org.apache.hadoop:hadoop-aws:3.2.0
--conf spark.kubernetes.file.upload.path=s3a:///path
--conf spark.hadoop.fs.s3a.access.key=...
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
--conf spark.hadoop.fs.s3a.fast.upload=true
--conf spark.hadoop.fs.s3a.secret.key=....
--conf spark.driver.extraJavaOptions=-Divy.cache.dir=/tmp -Divy.home=/tmp
file:///full/path/to/app.jarPod Template
k8s 的 controller (比如 Deployment,Job)创建 Pod 的时候根据 spec 中的 pod template 来创建。下面是一个 Job 的示例。
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# 下面的是一个 pod template
spec:
containers:
- name: hello
image: busybox
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# The pod template ends here由于我们通过 spark-submit 提交 spark 作业的时候,最终的 k8s 资源(driver/executor pod)是由 spark 内部逻辑构建出来的。但是有的时候我们想要在 driver/executor pod 上做一些额外的工作,比如增加 sidecar 容器做一些日志收集的工作。这种场景下 PodTemplate 就是一个比较好的选择,同时 PodTemplate 也将 spark 和底层基础设施(k8s)解耦开。比如 k8s 发布新版本支持一些新的特性,那么我们只要修改我们的 PodTemplate 即可,而不涉及到 spark 的内部改动。
RBAC
RBAC 全称是 Role-based access control,是 k8s 中的一套权限控制机制。通俗来说:
- RBAC 中包含了一系列的权限设置,比如 create/delete/watch/list pod 等,这些权限集合的实体叫 Role 或者 ClusterRole
- 同时 RBAC 还包含了角色绑定关系(Role Binding),用于将 Role/ClusterRole 赋予一个或者一组用户,比如 Service Account 或者 UserAccount
为了将 Spark 作业在 k8s 集群中运行起来,我们还需要一套 RBAC 资源:
- 指定 namespace 下的 serviceaccount
- 定义了权限规则的 Role 或者 ClusterRole,我们可以使用常见的 ClusterRole "edit"(对几乎所有资源具有操作权限,比如 create/delete/watch 等)
- 绑定关系
下面命令在 spark namespace 下为 serviceaccount spark 赋予了操作同 namespace 下其他资源的权限,那么只要 spark 的 driver pod 挂载了该 serviceaccount,它就可以创建 executor pod 了。
$ kubectl create serviceaccount spark
$ kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=spark:spark --namespace=spark下面做一个简单的演示:
通过如下命令提交作业 SparkPiSleep 到 k8s 集群中。
$ spark-submit --master k8s://https://: --deploy-mode cluster --class org.apache.spark.examples.SparkPiSleep --conf spark.executor.memory=2g --conf spark.driver.memory=2g --conf spark.driver.core=1 --conf spark.app.name=test12 --conf spark.kubernetes.submission.waitAppCompletion=false --conf spark.executor.core=1 --conf spark.kubernetes.container.image= --conf spark.eventLog.enabled=false --conf spark.shuffle.service.enabled=false --conf spark.executor.instances=1 --conf spark.dynamicAllocation.enabled=false --conf spark.kubernetes.namespace=spark --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.executor.core=1 local:///path/to/main/jar查看 k8s 集群中的资源
$ kubectl get po -n spark
NAME READY STATUS RESTARTS AGE
spark-pi-5b88a27b576050dd-exec-1 0/1 ContainerCreating 0 2s
test12-9fd3c27b576039ae-driver 1/1 Running 0 8s其中第一个就是 executor pod,第二个是 driver 的 pod。除此之外还创建了一个 service,可以通过该 service 访问到 driver pod,比如 Spark UI 都可以这样访问到。
$ kubectl get svc -n spark
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test12-9fd3c27b576039ae-driver-svc ClusterIP None 7078/TCP,7079/TCP,4040/TCP 110s下面再看一下 service owner reference,executor pod 也是类似的。
$ kubectl get svc test12-9fd3c27b576039ae-driver-svc -n spark -oyaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2021-08-18T03:48:50Z"
name: test12-9fd3c27b576039ae-driver-svc
namespace: spark
# service 的 ownerReference 指向了 driver pod,只要 driver pod 被删除,该 service 也会被删除
ownerReferences:
- apiVersion: v1
controller: true
kind: Pod
name: test12-9fd3c27b576039ae-driver
uid: 56a50a66-68b5-42a0-b2f6-9a9443665d95
resourceVersion: "9975441"
uid: 06c1349f-be52-4133-80d9-07af34419b1f3. Flink on k8s 使用
Flink on k8s native 的实现支持两种模式:
- application mode:在远程 k8s 集群中启动一个 flink 集群(jm 和 tm),driver 运行在 jm 中,也就是只支持 detached 模式,不支持 attached 模式。
- session mode:在远程 k8s 集群启动一个常驻的 flink 集群(只有 jm),然后向上面提交作业,根据实际情况决定启动多少个 tm。
在生产上面使用一般不太建议使用 session mode,所以下面主要讨论的是 application mode。
Flink 的 native k8s 模式是不需要指定 tm 个数的,jm 会根据用户的代码计算需要多少 tm。
提交作业
下面是一个简单的提交命令,需要包含:
- 参数 run-application 指定是 application 模式
- 参数 --target 指定运行在 k8s 上
- 参数 kubernetes.container.image 指定作业运行使用的 flink 镜像
- 最后需要指定 main jar,路径是镜像中的路径
$ ./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=my-first-application-cluster \
-Dkubernetes.container.image=custom-image-name \
local:///opt/flink/usrlib/my-flink-job.jar资源清理
Flink 的 native 模式会先创建一个 JobManager 的 deployment,并将其托管给 k8s。同一个作业所有的相关资源的 owner reference 都指向该 Deployment,也就是说删除了该 deployment,所有相关的资源都会被清理掉。下面根据作业的运行情况讨论一下资源如何清理。
- 作业运行到终态(SUCCESS,FAILED,CANCELED 等)之后,Flink 会清理掉所有作业
- JobManager 进程启动失败(pod 中的 jm 容器启动失败),由于控制器是 Deployment,所以会一直重复拉起
- 运行过程中,如果 JobManager 的 pod 被删除,Deployment 会重新拉起
- 运行过程中,如果 JobManager 的 Deployment 被删除,那么关联的所有 k8s 资源都会被删除
Pod Template
Flink native 模式也支持 Pod Template,类似 Spark。
RBAC
类似 Spark。
依赖文件管理
Flink 暂时只支持 main jar 以及依赖文件在镜像中。也就是说用户要提交作业需要自己定制化镜像,体验不是很好。一种 workaroud 的方式是结合 PodTemplate:
- 如果依赖是本地文件,需要 upload 到一个 remote 存储做中转,比如各大云厂商的对象存储。
- 如果依赖是远端文件,不需要 upload。
- 运行时在 template 中使用 initContainer 将用户的 jar 以及依赖文件下载到 Flink 容器中,并加到 classpath 下运行。
Flink 的作业 demo 就不在演示了。
4. Spark on Kubernetes 实现
Spark on Kubernetes 的实现比较简单:
- Spark Client 创建一个 k8s pod 运行 driver
- driver 创建 executor pod,然后开始运行作业
- 作业运行结束之后 driver pod 进入到 Completed 状态,executor pod 会被清理掉。作业结束之后通过 driver pod 我们还是可以查看 driver pod 的。
代码实现
Spark 的 native k8s 实现代码在
resource-managers/kubernetes module 中。我们可以从 SparkSubmit 的代码开始分析。我们主要看一下 deploy-mode 为 cluster 模式的代码逻辑。
// Set the cluster manager
val clusterManager: Int = args.master match {
case "yarn" => YARN
case m if m.startsWith("spark") => STANDALONE
case m if m.startsWith("mesos") => MESOS
case m if m.startsWith("k8s") => KUBERNETES
case m if m.startsWith("local") => LOCAL
case _ =>
error("Master must either be yarn or start with spark, mesos, k8s, or local")
-1
}首先根据 spark.master 配置中 scheme 来判断是不是 on k8s。我们上面也看到这个配置的形式为 --master k8s://https://: 。如果是 on k8s 的 cluster 模式,则去加载 Class
org.apache.spark.deploy.k8s.submit.KubernetesClientApplication,并运行其中的 start 方法。childArgs 方法的核心逻辑简单来说就是根据 spark-submit 提交的参数构造出 driver pod 提交到 k8s 运行。
private[spark] class KubernetesClientApplication extends SparkApplication {
override def start(args: Array[String], conf: SparkConf): Unit = {
val parsedArguments = ClientArguments.fromCommandLineArgs(args)
run(parsedArguments, conf)
}
private def run(clientArguments: ClientArguments, sparkConf: SparkConf): Unit = {
// For constructing the app ID, we can't use the Spark application name, as the app ID is going
// to be added as a label to group resources belonging to the same application. Label values are
// considerably restrictive, e.g. must be no longer than 63 characters in length. So we generate
// a unique app ID (captured by spark.app.id) in the format below.
val kubernetesAppId = KubernetesConf.getKubernetesAppId()
val kubernetesConf = KubernetesConf.createDriverConf(
sparkConf,
kubernetesAppId,
clientArguments.mainAppResource,
clientArguments.mainClass,
clientArguments.driverArgs,
clientArguments.proxyUser)
// The master URL has been checked for validity already in SparkSubmit.
// We just need to get rid of the "k8s://" prefix here.
val master = KubernetesUtils.parseMasterUrl(sparkConf.get("spark.master"))
val watcher = new LoggingPodStatusWatcherImpl(kubernetesConf)
Utils.tryWithResource(SparkKubernetesClientFactory.createKubernetesClient(
master,
Some(kubernetesConf.namespace),
KUBERNETES_AUTH_SUBMISSION_CONF_PREFIX,
SparkKubernetesClientFactory.ClientType.Submission,
sparkConf,
None,
None)) { kubernetesClient =>
val client = new Client(
kubernetesConf,
new KubernetesDriverBuilder(),
kubernetesClient,
watcher)
client.run()
}
}
}上面的代码的核心就是最后创建 Client 并运行。这个 Client 是 Spark 封装出来的 Client,内置了 k8s client。
private[spark] class Client(
conf: KubernetesDriverConf,
builder: KubernetesDriverBuilder,
kubernetesClient: KubernetesClient,
watcher: LoggingPodStatusWatcher) extends Logging {
def run(): Unit = {
// 构造 Driver 的 Pod
val resolvedDriverSpec = builder.buildFromFeatures(conf, kubernetesClient)
val configMapName = KubernetesClientUtils.configMapNameDriver
val confFilesMap = KubernetesClientUtils.buildSparkConfDirFilesMap(configMapName,
conf.sparkConf, resolvedDriverSpec.systemProperties)
val configMap = KubernetesClientUtils.buildConfigMap(configMapName, confFilesMap)
// 修改 Pod 的 container spec:增加 SPARK_CONF_DIR
val resolvedDriverContainer = new ContainerBuilder(resolvedDriverSpec.pod.container)
.addNewEnv()
.withName(ENV_SPARK_CONF_DIR)
.withValue(SPARK_CONF_DIR_INTERNAL)
.endEnv()
.addNewVolumeMount()
.withName(SPARK_CONF_VOLUME_DRIVER)
.withMountPath(SPARK_CONF_DIR_INTERNAL)
.endVolumeMount()
.build()
val resolvedDriverPod = new PodBuilder(resolvedDriverSpec.pod.pod)
.editSpec()
.addToContainers(resolvedDriverContainer)
.addNewVolume()
.withName(SPARK_CONF_VOLUME_DRIVER)
.withNewConfigMap()
.withItems(KubernetesClientUtils.buildKeyToPathObjects(confFilesMap).asJava)
.withName(configMapName)
.endConfigMap()
.endVolume()
.endSpec()
.build()
val driverPodName = resolvedDriverPod.getMetadata.getName
var watch: Watch = null
var createdDriverPod: Pod = null
try {
// 通过 k8s client 创建 Driver Pod
createdDriverPod = kubernetesClient.pods().create(resolvedDriverPod)
} catch {
case NonFatal(e) =>
logError("Please check \"kubectl auth can-i create pod\" first. It should be yes.")
throw e
}
try {
// 创建其他资源,修改 owner reference 等
val otherKubernetesResources = resolvedDriverSpec.driverKubernetesResources ++ Seq(configMap)
addOwnerReference(createdDriverPod, otherKubernetesResources)
kubernetesClient.resourceList(otherKubernetesResources: _*).createOrReplace()
} catch {
case NonFatal(e) =>
kubernetesClient.pods().delete(createdDriverPod)
throw e
}
val sId = Seq(conf.namespace, driverPodName).mkString(":")
// watch pod
breakable {
while (true) {
val podWithName = kubernetesClient
.pods()
.withName(driverPodName)
// Reset resource to old before we start the watch, this is important for race conditions
watcher.reset()
watch = podWithName.watch(watcher)
// Send the latest pod state we know to the watcher to make sure we didn't miss anything
watcher.eventReceived(Action.MODIFIED, podWithName.get())
// Break the while loop if the pod is completed or we don't want to wait
// 根据参数 "spark.kubernetes.submission.waitAppCompletion" 判断是否需要退出
if(watcher.watchOrStop(sId)) {
watch.close()
break
}
}
}
}
}下面再简单介绍一下 Driver 如何管理 Executor 的流程。当 Spark Driver 运行 main 函数时,会创建一个 SparkSession,SparkSession 中包含了 SparkContext,SparkContext 需要创建一个 SchedulerBackend 会管理 Executor 的生命周期。对应到 k8s 上的 SchedulerBackend 其实就是
KubernetesClusterSchedulerBackend,下面主要看一下这个 backend 是如何创建出来的。大胆猜想一下,大概率也是根据 spark.master 的 url 的 scheme "k8s" 创建的。
下面是 SparkContext 创建 SchedulerBackend 的核心代码逻辑。
private def createTaskScheduler(...) = {
case masterUrl =>
// 创建出 KubernetesClusterManager
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
// 上面创建出来的 KubernetesClusterManager 这里会创建出 KubernetesClusterSchedulerBackend
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
throw new SparkException("External scheduler cannot be instantiated", e)
}
}
// 方法 getClsuterManager 会通过 ServiceLoader 加载所有实现 ExternalClusterManager 的 ClusterManager (KubernetesClusterManager 和 YarnClusterManager),然后通过 master url 进行 filter,选出 KubernetesClusterManager
private def getClusterManager(url: String): Option[ExternalClusterManager] = {
val loader = Utils.getContextOrSparkClassLoader
val serviceLoaders =
ServiceLoader.load(classOf[ExternalClusterManager], loader).asScala.filter(_.canCreate(url))
if (serviceLoaders.size > 1) {
throw new SparkException(
s"Multiple external cluster managers registered for the url $url: $serviceLoaders")
}
serviceLoaders.headOption
}后面就是
KubernetesClusterSchedulerBackend 管理 Executor 的逻辑了。
可以简单看一下创建 Executor 的代码逻辑。
private def requestNewExecutors(
expected: Int,
running: Int,
applicationId: String,
resourceProfileId: Int,
pvcsInUse: Seq[String]): Unit = {
val numExecutorsToAllocate = math.min(expected - running, podAllocationSize)
logInfo(s"Going to request $numExecutorsToAllocate executors from Kubernetes for " +
s"ResourceProfile Id: $resourceProfileId, target: $expected running: $running.")
// Check reusable PVCs for this executor allocation batch
val reusablePVCs = getReusablePVCs(applicationId, pvcsInUse)
for ( _ <- 0 until numExecutorsToAllocate) {
val newExecutorId = EXECUTOR_ID_COUNTER.incrementAndGet()
val executorConf = KubernetesConf.createExecutorConf(
conf,
newExecutorId.toString,
applicationId,
driverPod,
resourceProfileId)
// 构造 Executor 的 Pod Spec
val resolvedExecutorSpec = executorBuilder.buildFromFeatures(executorConf, secMgr,
kubernetesClient, rpIdToResourceProfile(resourceProfileId))
val executorPod = resolvedExecutorSpec.pod
val podWithAttachedContainer = new PodBuilder(executorPod.pod)
.editOrNewSpec()
.addToContainers(executorPod.container)
.endSpec()
.build()
val resources = replacePVCsIfNeeded(
podWithAttachedContainer, resolvedExecutorSpec.executorKubernetesResources, reusablePVCs)
// 创建 Executor Pod
val createdExecutorPod = kubernetesClient.pods().create(podWithAttachedContainer)
try {
// 增加 owner reference
addOwnerReference(createdExecutorPod, resources)
resources
.filter(_.getKind == "PersistentVolumeClaim")
.foreach { resource =>
if (conf.get(KUBERNETES_DRIVER_OWN_PVC) && driverPod.nonEmpty) {
addOwnerReference(driverPod.get, Seq(resource))
}
val pvc = resource.asInstanceOf[PersistentVolumeClaim]
logInfo(s"Trying to create PersistentVolumeClaim ${pvc.getMetadata.getName} with " +
s"StorageClass ${pvc.getSpec.getStorageClassName}")
kubernetesClient.persistentVolumeClaims().create(pvc)
}
newlyCreatedExecutors(newExecutorId) = (resourceProfileId, clock.getTimeMillis())
logDebug(s"Requested executor with id $newExecutorId from Kubernetes.")
} catch {
case NonFatal(e) =>
kubernetesClient.pods().delete(createdExecutorPod)
throw e
}
}
}5. Flink on Kubernetes 实现
Flink 的 Native K8s 实现:
- Flink Client 创建 JobManager 的 Deployment,然后将 Deployment 托管给 k8s
- k8s 的 Deployment Controller 创建 JobManager 的 Pod
- JobManager 内的 ResourceManager 负责先 Kubernetes Scheduler 请求资源并创建 TaskManager 等相关资源并创建相关的 TaskManager Pod 并开始运行作业
- 当作业运行到终态之后所有相关的 k8s 资源都被清理掉
代码(基于分支 release-1.13)实现主要如下:
- CliFrontend 作为 Flink Client 的入口根据命令行参数 run-application 判断通过方法 runApplication 去创建 ApplicationCluster
- KubernetesClusterDescriptor 通过方法 deployApplicationCluster 创建 JobManager 相关的 Deployment 和一些必要的资源
- JobManager 的实现类 JobMaster 通过 ResourceManager 调用类 KubernetesResourceManagerDriver 中的方法 requestResource 创建 TaskManager 等资源
其中
KubernetesClusterDescriptor 实现自 interface ClusterDescriptor ,用来描述对 Flink 集群的操作。根据底层的资源使用不同, ClusterDescriptor 有不同的实现,包括 KubernetesClusterDescriptor、YarnClusterDescriptor、StandaloneClusterDescriptor。
public interface ClusterDescriptor<T> extends AutoCloseable {
/* Returns a String containing details about the cluster (NodeManagers, available memory, ...). */
String getClusterDescription();
/* 查询已存在的 Flink 集群. */
ClusterClientProvider<T> retrieve(T clusterId) throws ClusterRetrieveException;
/** 创建 Flink Session 集群 */
ClusterClientProvider<T> deploySessionCluster(ClusterSpecification clusterSpecification)
throws ClusterDeploymentException;
/** 创建 Flink Application 集群 **/
ClusterClientProvider<T> deployApplicationCluster(
final ClusterSpecification clusterSpecification,
final ApplicationConfiguration applicationConfiguration)
throws ClusterDeploymentException;
/** 创建 Per-job 集群 **/
ClusterClientProvider<T> deployJobCluster(
final ClusterSpecification clusterSpecification,
final JobGraph jobGraph,
final boolean detached)
throws ClusterDeploymentException;
/** 删除集群 **/
void killCluster(T clusterId) throws FlinkException;
@Override
void close();
}下面简单看一下
KubernetesClusterDescriptor 的核心逻辑:创建 Application 集群。
public class KubernetesClusterDescriptor implements ClusterDescriptor<String> {
private final Configuration flinkConfig;
// 内置 k8s client
private final FlinkKubeClient client;
private final String clusterId;
@Override
public ClusterClientProvider<String> deployApplicationCluster(
final ClusterSpecification clusterSpecification,
final ApplicationConfiguration applicationConfiguration)
throws ClusterDeploymentException {
// 查询 flink 集群在 k8s 中是否存在
if (client.getRestService(clusterId).isPresent()) {
throw new ClusterDeploymentException(
"The Flink cluster " + clusterId + " already exists.");
}
final KubernetesDeploymentTarget deploymentTarget =
KubernetesDeploymentTarget.fromConfig(flinkConfig);
if (KubernetesDeploymentTarget.APPLICATION != deploymentTarget) {
throw new ClusterDeploymentException(
"Couldn't deploy Kubernetes Application Cluster."
+ " Expected deployment.target="
+ KubernetesDeploymentTarget.APPLICATION.getName()
+ " but actual one was \""
+ deploymentTarget
+ "\"");
}
// 设置 application 参数:$internal.application.program-args 和 $internal.application.main
applicationConfiguration.applyToConfiguration(flinkConfig);
// 创建集群
final ClusterClientProvider<String> clusterClientProvider =
deployClusterInternal(
KubernetesApplicationClusterEntrypoint.class.getName(),
clusterSpecification,
false);
try (ClusterClient<String> clusterClient = clusterClientProvider.getClusterClient()) {
LOG.info(
"Create flink application cluster {} successfully, JobManager Web Interface: {}",
clusterId,
clusterClient.getWebInterfaceURL());
}
return clusterClientProvider;
}
// 创建集群逻辑
private ClusterClientProvider<String> deployClusterInternal(
String entryPoint, ClusterSpecification clusterSpecification, boolean detached)
throws ClusterDeploymentException {
final ClusterEntrypoint.ExecutionMode executionMode =
detached
? ClusterEntrypoint.ExecutionMode.DETACHED
: ClusterEntrypoint.ExecutionMode.NORMAL;
flinkConfig.setString(
ClusterEntrypoint.INTERNAL_CLUSTER_EXECUTION_MODE, executionMode.toString());
flinkConfig.setString(KubernetesConfigOptionsInternal.ENTRY_POINT_CLASS, entryPoint);
// Rpc, blob, rest, taskManagerRpc ports need to be exposed, so update them to fixed values.
// 将端口指定为固定值,方便 k8s 的资源构建。因为 pod 的隔离性,所以没有端口冲突
KubernetesUtils.checkAndUpdatePortConfigOption(
flinkConfig, BlobServerOptions.PORT, Constants.BLOB_SERVER_PORT);
KubernetesUtils.checkAndUpdatePortConfigOption(
flinkConfig, TaskManagerOptions.RPC_PORT, Constants.TASK_MANAGER_RPC_PORT);
KubernetesUtils.checkAndUpdatePortConfigOption(
flinkConfig, RestOptions.BIND_PORT, Constants.REST_PORT);
// HA 配置
if (HighAvailabilityMode.isHighAvailabilityModeActivated(flinkConfig)) {
flinkConfig.setString(HighAvailabilityOptions.HA_CLUSTER_ID, clusterId);
KubernetesUtils.checkAndUpdatePortConfigOption(
flinkConfig,
HighAvailabilityOptions.HA_JOB_MANAGER_PORT_RANGE,
flinkConfig.get(JobManagerOptions.PORT));
}
try {
final KubernetesJobManagerParameters kubernetesJobManagerParameters =
new KubernetesJobManagerParameters(flinkConfig, clusterSpecification);
// 补充 PodTemplate 逻辑
final FlinkPod podTemplate =
kubernetesJobManagerParameters
.getPodTemplateFilePath()
.map(
file ->
KubernetesUtils.loadPodFromTemplateFile(
client, file, Constants.MAIN_CONTAINER_NAME))
.orElse(new FlinkPod.Builder().build());
final KubernetesJobManagerSpecification kubernetesJobManagerSpec =
KubernetesJobManagerFactory.buildKubernetesJobManagerSpecification(
podTemplate, kubernetesJobManagerParameters);
// 核心逻辑:在 k8s 中创建包括 JobManager Deployment 在内 k8s 资源,比如 Service 和 ConfigMap
client.createJobManagerComponent(kubernetesJobManagerSpec);
return createClusterClientProvider(clusterId);
} catch (Exception e) {
//...
}
}
}上面代码中需要说的在构建 JobManager 的时候补充 PodTemplate。简单来说 PodTemplate 就是一个 Pod 文件。
第三步的 TaskManager 创建就不再赘述了。
7. 生态
这里生态这个词可能也不太合适,这里主要指的的如果要在生产上面使用该功能还有哪些可以做的。下面主要讨论在生产环境上面用来做 trouble-shooting 的两个功能:日志和监控。
日志
日志收集对于线上系统是非常重要的一环,毫不夸张地说,80% 的故障都可以通过日志查到原因。但是前面也说过,Flink 作业在作业运行到终态之后会清理掉所有资源,Spark 作业运行完只会保留 Driver Pod 的日志,那么我们如何收集到完整的作业日志呢?
有几种方案可供选择:
- DaemonSet。每个 k8s 的 node 上面以 DaemonSet 形式部署日志收集 agent,对 node 上面运行的所有容器日志进行统一收集,并存储到类似 ElasticSearch 的统一日志搜索平台。
- SideCar。使用 Flink/Spark 提供的 PodTemplate 功能在主容器侧配置一个 SideCar 容器用来进行日志收集,最后存储到统一的日志服务里面。
这两种方式都有一个前提是有其他的日志服务提供存储、甚至搜索的功能,比如 ELK,或者各大云厂商的日志服务。
除此之外还有一种简易的方式可以考虑:利用 log4j 的扩展机制,自定义 log appender,在 appender 中定制化 append 逻辑,将日志直接收集并存储到 remote storage,比如 hdfs,对象存储等。这种方案需要将自定义的 log appender 的 jar 包放到运行作业的 ClassPath 下,而且这种方式有可能会影响作业主流程的运行效率,对性能比较敏感的作业并不太建议使用这种方式。
监控
目前 Prometheus 已经成为 k8s 生态的监控事实标准,下面我们的讨论也是讨论如何将 Flink/Spark 的作业的指标对接到 Prometheus。下面先看一下 Prometheus 的架构。
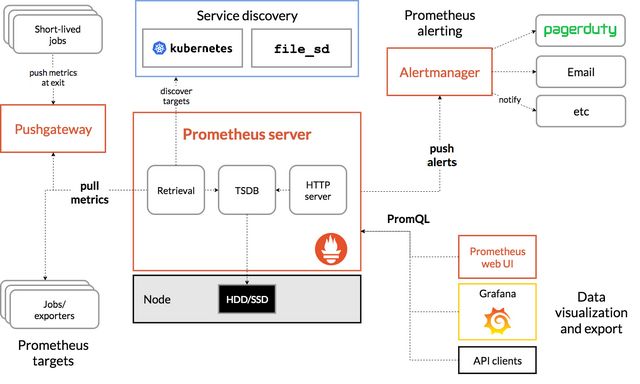
其中的核心在于 Prometheus Servier 收集指标的方式是 pull 还是 push:
- 对于常驻的进程,比如在线服务,一般由 Prometheus Server 主动去进程暴露出来的 api pull 指标。
- 对于会结束的进程指标收集,比如 batch 作业,一般使用进程主动 push 的方式。详细流程是进程将指标 push 到常驻的 PushGateway,然后 Prometheus Server 去 PushGateway pull 指标。
上面两种使用方式也是 Prometheus 官方建议的使用方式,但是看完描述不难发现其实第一种场景也可以使用第二种处理方式。只不过第二种方式由于 PushGateway 是常驻的,对其稳定性要求会比较高。
Flink
Flink 同时提供了 PrometheusReporter (将指标通过 api 暴露,由 Prometheus Server 来主动 pull 数据) 和
PrometheusPushGatewayReporter (将指标主动 push 给 PushGateway,Prometheus Server 不需要感知 Flink 作业)。
这两种方式中
PrometheusPushGatewayReporter 会更简单一点,但是 PushGateway 可能会成为瓶颈。如果使用 PrometheusReporter 的方式,需要引入服务发现机制帮助 Prometheus Server 自动发现运行的 Flink 作业的 Endpoint。Prometheus 目前支持的主流的服务发现机制主要有:
- 基于 Consul。Consul 是基于 etcd 的一套完整的服务注册与发现解决方案,要使用这种方式,我们需要 Flink 对接 Consul。比如我们在提交作业的时候,将作业对应的 Service 进行捕获并写入 Consul。
- 基于文件。文件也就是 Prometheus 的配置文件,里面配置需要拉取 target 的 endpoint。文件这种方式本来是比较鸡肋的,因为它需要 Prometheus Server 和 Flink 作业同时都可以访问,但是需要文件是 local 的。但是在 k8s 环境中,基于文件反而变的比较简单,我们可以将 ConfigMap 挂载到 Prometheus Server 的 Pod 上面,Flink 作业修改 ConfigMap 就可以了。
- 基于 Kubernetes 的服务发现机制。Kubernetes 的服务发现机制简单来说就是 label select。可以参考?https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
关于 Prometheus 支持的更多服务发现机制,可以参考:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/?,简单罗列包括:
- azure
- consul
- digitalocean
- docker
- dockerswarm
- dns
- ec2
- eureka
- file
- gce
- hetzner
- http
- kubernetes
- ...
Spark
以批计算为代表的 Spark 使用 PushGateway 的方式来对接 Prometheus 是比较好的方式,但是 Spark 官方并没有提供对 PushGateway 的支持,只支持了 Prometheus 的 Exporter,需要 Prometheus Server 主动去 pull 数据。
这里推荐使用基于 Kubernetes 的服务发现机制。
需要注意的是 Prometheus Server 拉取指标是按固定时间间隔进行拉取的,对于持续时间比较短的批作业,有可能存在还没有拉取指标,作业就结束的情况。
8. 缺陷
虽然 Spark 和 Flink 都实现了 native k8s 的模式,具体实现略有差异。但是在实际使用上发现两者的实现在某些场景下还是略有缺陷的。
Spark
pod 不具有容错性?spark-submit 会先构建一个 k8s 的 driver pod,然后由 driver pod 启动 executor 的 pod。但是在 k8s 环境中并不太建议直接构建 pod 资源,因为 pod 不具有容错性,pod 所在节点挂了之后 pod 就挂了。熟悉 k8s scheduler 的同学应该知道 pod 有一个字段叫 podName,scheduler 的核心是为 pod 填充这个字段,也就是为 pod 选择一个合适的 node。一旦调度完成之后 pod 的该字段就固定下来了。这也是 pod 不具有 node 容错的原因。
Flink
Deployment 语义。?Deployment 可以认为是 ReplicaSet 的增强版,而 ReplicaSet 的官方定义如下。
A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods.
简单来说,ReplicaSet 的目的是保证几个相同的 Pod 副本可以不间断的运行,说是为了线上服务量身定制的也不为过(线上服务最好是无状态且支持原地重启,比如 WebService)。但是尽管 Flink 以流式作业为主,但是我们并不能简单地将流式作业等同于无状态的 WebService。比如 Flink 作业的 Main Jar 如果写的有问题,会导致 JobManager 的 Pod 一直启动失败,但是由于是 Deployment 语义的问题会不断被重启。这个可能是 ByDesign 的,但是感觉并不太好。
Batch 作业处理。?由于 Flink 作业运行完所有资源包括 Deployment 都会被清理掉,拿不到最终的作业状态,不知道成功有否(流作业的话停止就可以认为是失败了)。对于这个问题可以利用 Flink 本身的归档功能,将结果归档到外部的文件系统(兼容 s3 协议,比如阿里云对象存储 oss)中。涉及到的配置如下:
- s3.access-key
- s3.secret-key
- s3.region
- s3.endpoint
- jobmanager.archive.fs.dir
如果不想引入外部系统的话,需要改造 Flink 代码在作业运行完成之后将数据写到 k8s 的 api object 中,比如 ConfigMap 或者 Secret。
作业日志。?Spark 作业运行结束之后 Executor Pod 被清理掉,Driver Pod 被保留,我们可以通过它查看到 Driver 的日志。Flink 作业结束之后就什么日志都查看不到了。
9. 总结
本文从使用方式、源码实现以及在生产系统上面如何补足周边系统地介绍了 Spark 和 Flink 在 k8s 生态上的实现、实践以及对比。但是限于篇幅,很多内容来不及讨论了,比如 shuffle 如何处理。如果你们公司也在做这方面的工作,相信还是有很多参考价值的,也欢迎留言交流。
另外,YARN 的时代已经过去了,以后 on k8s scheduler 将成为大数据计算以及 AI 框架的标配。但是 k8s scheduler 这种天生为在线服务设计的调度器在吞吐上面有很大的不足,并不是很契合大数据作业。k8s 社区的批调度器 kube-batch,以及基于 kube-batch 衍生出来的 Volcano 调度器,基于 YARN 的调度算法实现的 k8s 生态调度器 Yunikorn 也逐渐在大数据 on k8s 场景下崭露头角,不过这些都是后话了,后面有时间再专门写文章进行分析对比。
本文为阿里云原创内容,未经允许不得转载。