本文环境:
Hadoop 3.2.2
JDK 1.8.0_291
MySQL 5.7.35
Hive 3.1.2
一、安装Hadoop集群
Hadoop集群部署参考这篇文章:《Hadoop完全分布式集群搭建详细图文教程》
二、安装MySQL
MySQL5.7安装参考这篇文章:《通过yum方式安装MySQL5.7》
MySQL8.0安装参考这篇文章:《通过yum方式安装MySQL8.0》
三、安装Hive
1、上传Hive安装包
将Hive安装包上传到/opt/software目录中

2、解压Hive安装包
2.1、将文件解压至/opt/module目录下
[sumu@node101 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
2.2、重命名文件夹
[sumu@node101 software]$ cd /opt/module/
[sumu@node101 module]$ mv apache-hive-3.1.2-bin hive-3.1.2

3、将Hive添加至系统环境变量中
[sumu@node101 ~]$ sudo vim /etc/profile.d/dev_env.sh
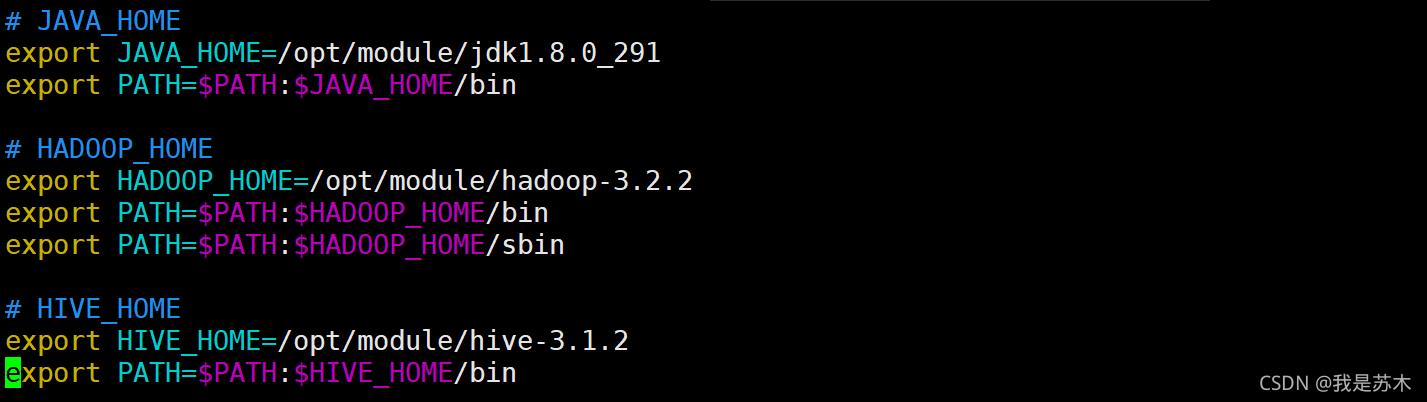
添加如下内容,注意hive安装路径
# HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
[sumu@node101 ~]$ source /etc/profile
4、将MySQL的JDBC驱动包添加至Hive的lib目录中
4.1、上传JDBC驱动包至/opt/software目录中
4.2、复制JDBC驱动包至/opt/module/hive-3.1.2/lib目录中

[sumu@node101 ~]$ cp /opt/software/mysql-connector-java-5.1.47.jar /opt/module/hive-3.1.2/lib/
5、解决Hadoop与Hive之间guava版本差异问题
5.1、删除Hive的lib目录下的guava-19.0.jar
[sumu@node101 ~]$ rm -rf /opt/module/hive-3.1.2/lib/guava-19.0.jar
5.2、将Hadoop中的guava-27.0-jre.jar复制到Hive的lib目录下
[sumu@node101 ~]$ cp /opt/module/hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive-3.1.2/lib/
6、修改Hive的环境变量配置文件hive-env.sh
# 进到Hive的conf目录
[sumu@node101 ~]$ cd /opt/module/hive-3.1.2/conf/
# 重命名hive-env.sh.template文件
[sumu@node101 conf]$ mv hive-env.sh.template hive-env.sh
# 修改hive-env.sh文件
[sumu@node101 conf]$ vim hive-env.sh
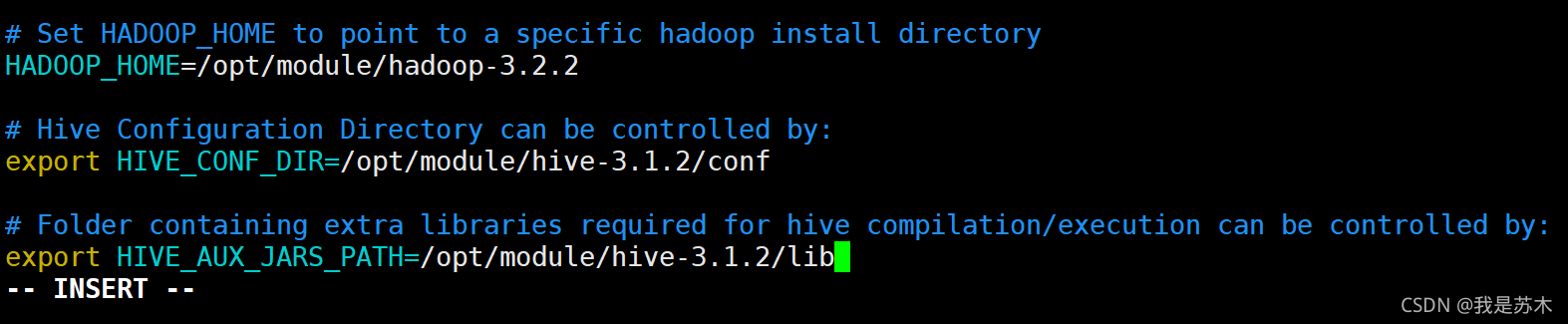
取消以下变量的注释,并修改为对应的值
HADOOP_HOME=/opt/module/hadoop-3.2.2
export HIVE_CONF_DIR=/opt/module/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/opt/module/hive-3.1.2/lib
7、配置MySQL相关信息
7.1、在Hive的conf目录下添加hive-site.xml配置文件
[sumu@node101 conf]$ vim hive-site.xml
7.2、添加如下配置信息
注意修改连接驱动名、主机名和密码等配置信息
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value> jdbc:mysql://node101:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>!QAZ2wsx</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node101</value>
</property>
<!-- 远程模式部署 metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node101:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- 关闭元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
8、初始化metadata
[sumu@node101 ~]$ cd /opt/module/hive-3.1.2/bin
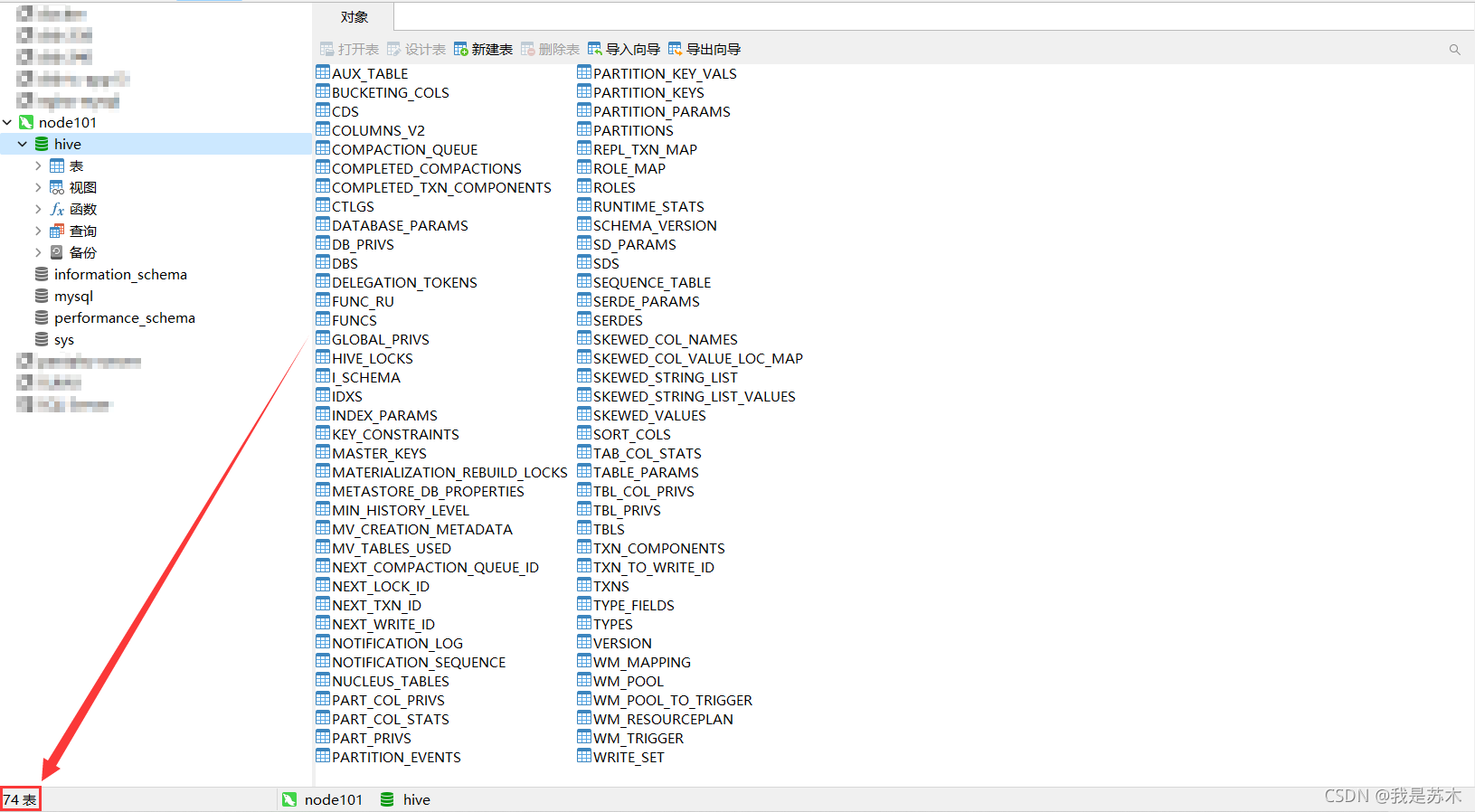
[sumu@node101 bin]$ ./schematool -initSchema -dbType mysql -verbos
初始化成功之后,会在MySQL的hive数据库中创建74张表

四、启动Hive
注意:启动Hive之前请确保Hadoop集群以及存放hive元数据的MySQL已经启动
1、启动MetaStore服务(远程模式下启动Hive客户端前必须先启动MetaStore服务)
由于已经将Hive添加至系统环境变量中,所以可以直接使用hive命令,若未添加系统环境变量,请到hive启动脚本路径下启动或指定到hive脚本所在路径(如:/opt/module/hive-3.1.2/bin/hive --service metastore)
1.1、方式一:后台挂起启动(建议使用这种方式)
[sumu@node101 ~]$ nohup hive --service metastore &

查看启动日志
[sumu@node101 ~]$ cat nohup.out
关闭MetaStore:使用jps命令查看RunJar的进程号,然后使用 kill -9 进程号 将进程杀掉

1.2、方式二:前台启动,关闭按 Ctrl+C
[sumu@node101 ~]$ hive --service metastore
前台启动并开启debug日志,请使用如下命令
[sumu@node101 ~]$ hive --service metastore --hiveconf hive.root.logger=DEBUG,console
2、Hive服务与客户端
Hive客户端与服务的关系图如下:
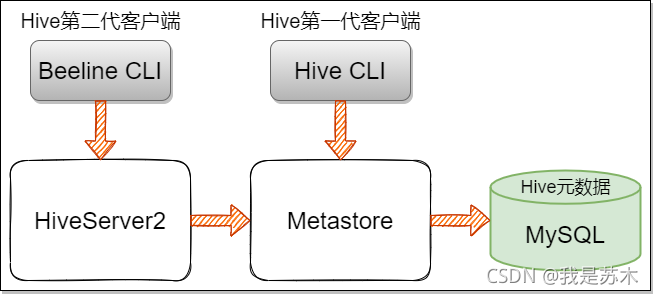
关系梳理:
-
HiveServer2是通过Metastore服务读写元数据的,所以在远程模式下,启动HiveServer2之前必须先启动Metastore服务。
-
注意:远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive,而bin/hive是通过Metastore服务访问的。
3、bin/hive客户端的使用
本教程为远程模式,所以启动Hive前必须先启动Metastore
3.1、在启动Metastore服务的节点启动Hive CLI
[sumu@node101 ~]$ hive
3.2、在其他节点使用Hive CLI
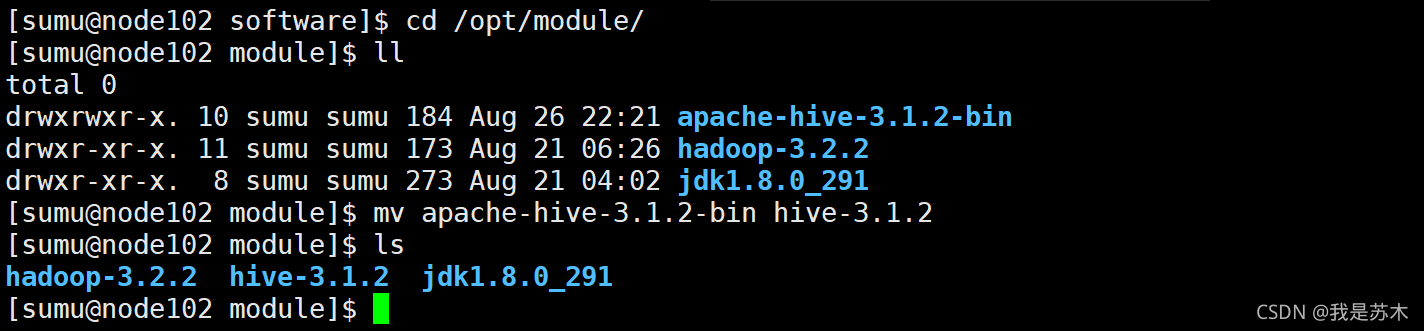
3.2.1、将Hive安装包上传至/opt/software目录

3.2.2、将Hive安装包解压至/opt/module目录,并重命名
# 解压
[sumu@node102 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
# 重命名
[sumu@node102 module]$ mv apache-hive-3.1.2-bin hive-3.1.2
3.2.3、将Hive添加至系统环境变量中
[sumu@node102 module]$ sudo vim /etc/profile.d/dev_env.sh
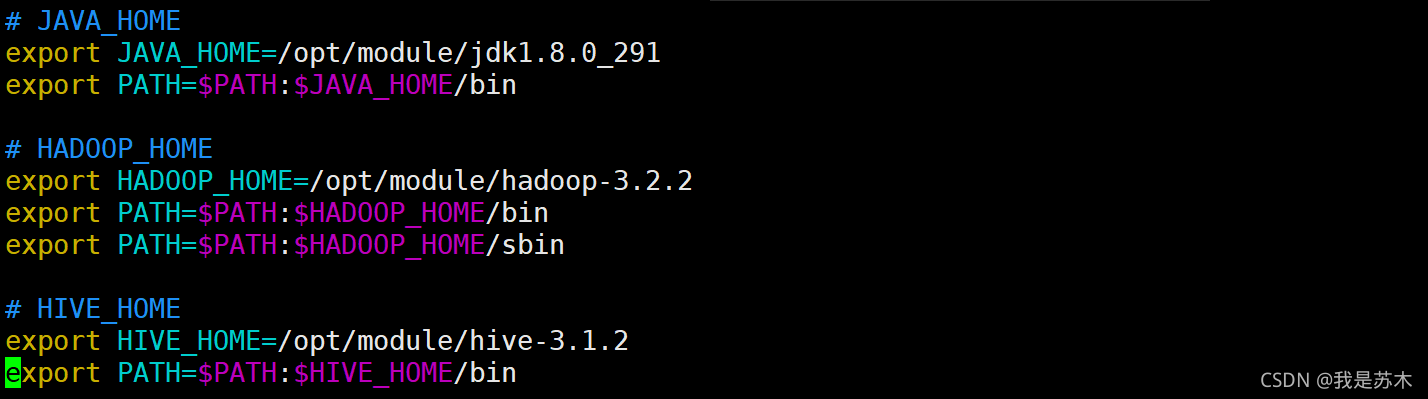
[sumu@node102 module]$ source /etc/profile
3.2.4、解决Hadoop与Hive之间guava版本差异问题(参考步骤三中的第5步)
3.2.5、修改Hive的环境变量配置文件hive-env.sh(参考步骤三中的第6步)
3.2.6、在Hive的conf目录下添加hive-site.xml配置文件
[sumu@node102 conf]$ vim hive-site.xml
添加如下配置:
<configuration>
<!-- 远程模式部署metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node101:9083</value>
</property>
</configuration>
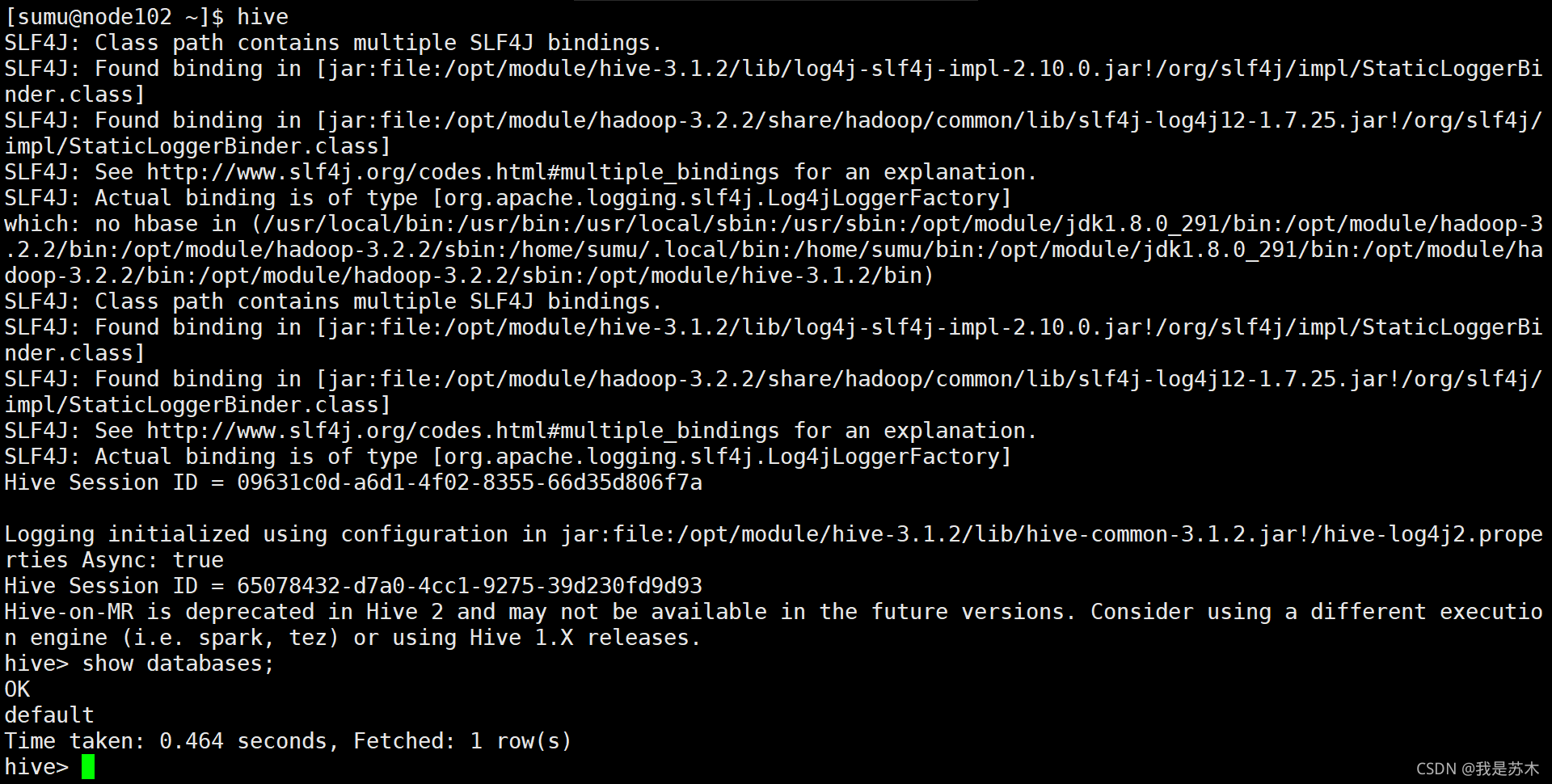
3.2.7、启动Hive CLI
[sumu@node102 ~]$ hive
4、bin/beeline客户端的使用
beeline客户端是通过HiveServer2去访问Metastore的,所以在启动beeline客户端之前,必须在安装Hive的服务器先启动Metastore,然后启动HiveServer2,最后在启动Beeline CLI
4.1、回到安装Hive的服务器启动Metastore和HiveServer2
# 1、后台挂起启动Metastore
[sumu@node101 ~]$ nohup hive --service metastore &
# 2、后台挂起启动Hiveserver2
[sumu@node101 ~]$ nohup hive --service hiveserver2 &
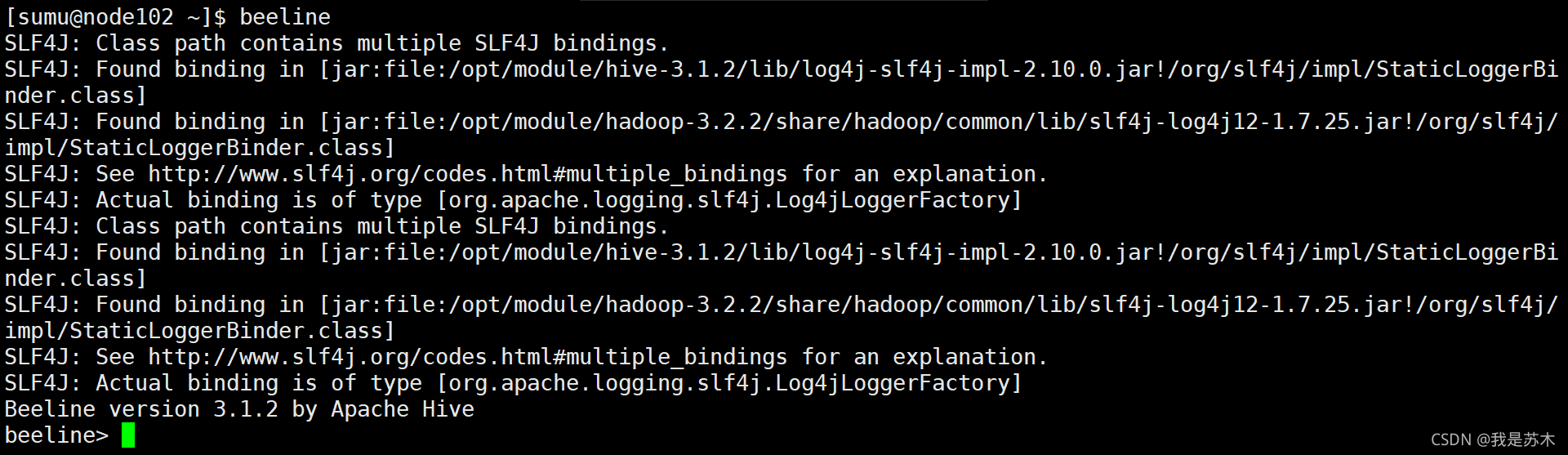
4.2、在任意服务器启动Beeline CLI
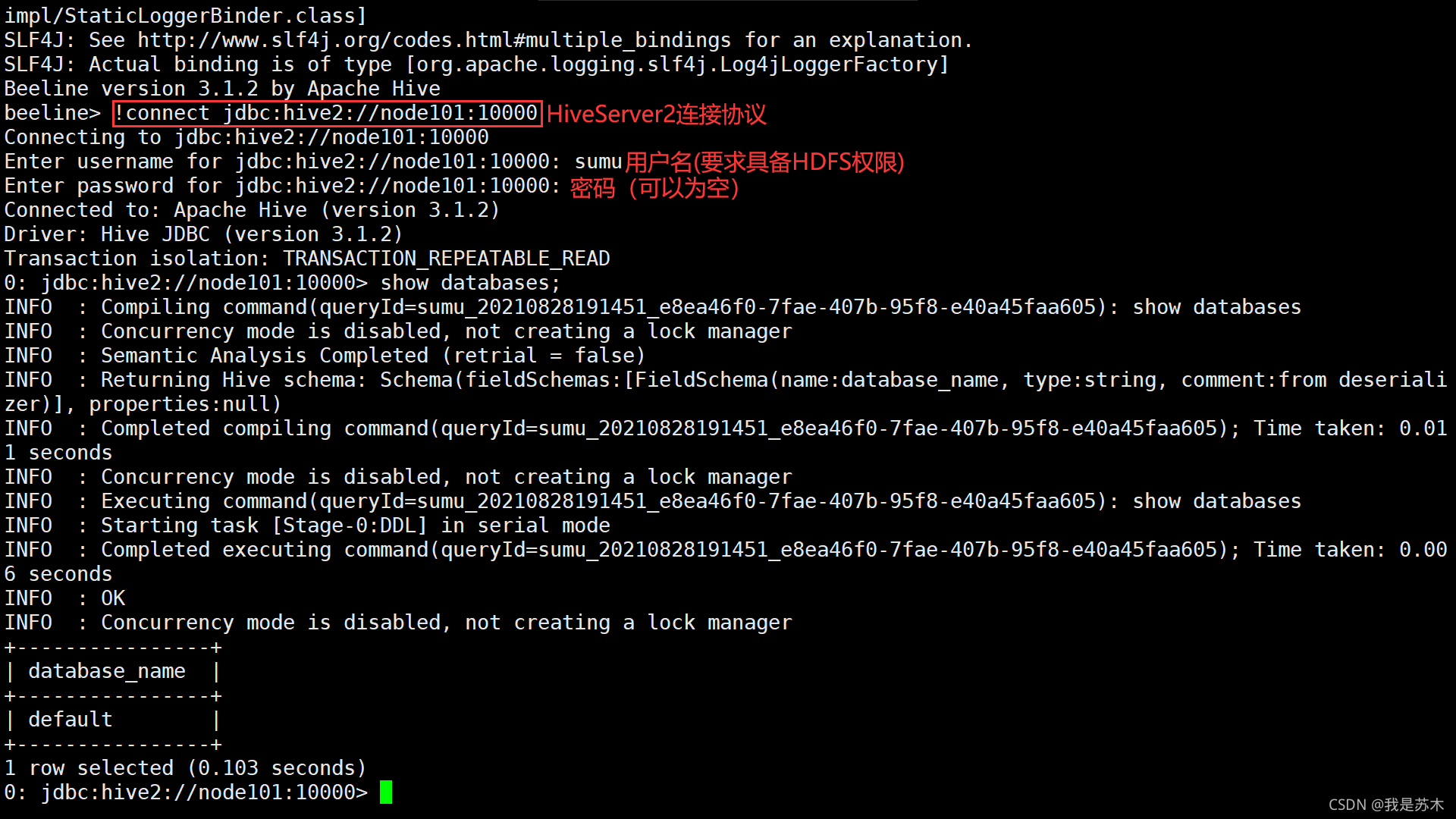
[sumu@node102 ~]$ beeline
4.3、使用Beeline连接Hive
beeline> !connect jdbc:hive2://node101:10000
若系统当前登录的用户没有HDFS的读写权限,则会报如下 不允许xxx模拟根目录 的错误

解决方法参考这篇文章:《Beeline连接报错:Could not open client transport with JDBC Uri: …》
配置好超级代理之后记得将core-site.xml配置文件分发至集群各个节点,并重启Hadoop,然后就可以使用beeline连接Hive了。