Spark 并行计算框架简介
Spark 是什么?

Spark is the most popular open-source distributed computing engine for big data analysis.
Used by data engineers and data scientists alike in thousands of organizations worldwide, Spark is the industry standard analytics engine for big data processing and machine learning. Spark enables you to process data at lightning speed for both batch and streaming workloads.
Spark can run on Kubernetes, YARN, or standalone - and it works with a wide range of data inputs and outputs.
大规模数据处理
类Hadoop MapReduce的通用并行框架
分布式计算引擎
何谓计算引擎,一言以蔽之,就是专门处理数据的程序,在大数据之前,人们用数据库来处理数据,人们常说的SQL,它是一种DSL,它的背后正是数据库的计算引擎,但是数据库的计算和存储通常被集成在一起,统称为数据库引擎。
互联网时代到来之后,由于需要计算的数据量太大,计算引擎和存储引擎分开各自演进,这一分开,让两者获得解放,从而有了无数可能,也就开启了狂飙突进的大数据时代。
从谷歌论文的大数据三驾马车到现在,计算引擎经历了多重演进。
2004年前后,谷歌发布了三篇重要的论文,也就是大数据的三驾马车:分布式文件系统GFS、计算引擎MapReduce、分布式数据库BigTable。
2006年,Lucene项目的创始人 Doug Cutting依据论文原理,开发出类似GFS和MapReduce的功能框架,后来被命名为Hadoop。Hadoop套件中的MapReduce实现了传统数据库计算能力之外的种种操作,让搭建一个大数据平台成为可能,它的种种设计理念,一直影响着后来者。
分布式计算是相对于集中式计算来说的,是利用各自独立的计算设备来共同完成一个计算任务。现代编程语言是以单机应用程序为目标设计的,要开发分布式计算程序,需要考虑很多额外的东西,比如一致性、数据完整、通信、容灾、任务调度等。
另一方面,机器学习的训练和调参过程需要计算海量数据并且进行反复学习,他们对算力的需求远远超过了摩尔定律的增长,更何况,如今摩尔定律已经快失效了。
随着这些年大数据的飞速发展,也出现了不少计算的框架(Hadoop、Storm、Spark、Flink)。在网上有人将大数据计算引擎的发展分为四个阶段。
第一代:Hadoop 承载的 MapReduce
第二代:支持 DAG(有向无环图)框架的计算引擎 Tez 和 Oozie,主要还是批处理任务
第三代:支持 Job 内部的 DAG(有向无环图),以 Spark 为代表
第四代:大数据统一计算引擎,包括流处理、批处理、AI、Machine Learning、图计算等,以 Flink 为代表.
四代大数据计算引擎
第一代,Hadoop MapReduce。
MapReduce 将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
第二代 , Tez DAG + MapReduce.
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
第三代 , Spark.
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。
第四代 , Flink 流计算 .
Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
工作负载方面表现得更加优越
Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
开源
UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室) 开源
Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是――Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
The Spark Ecosystem
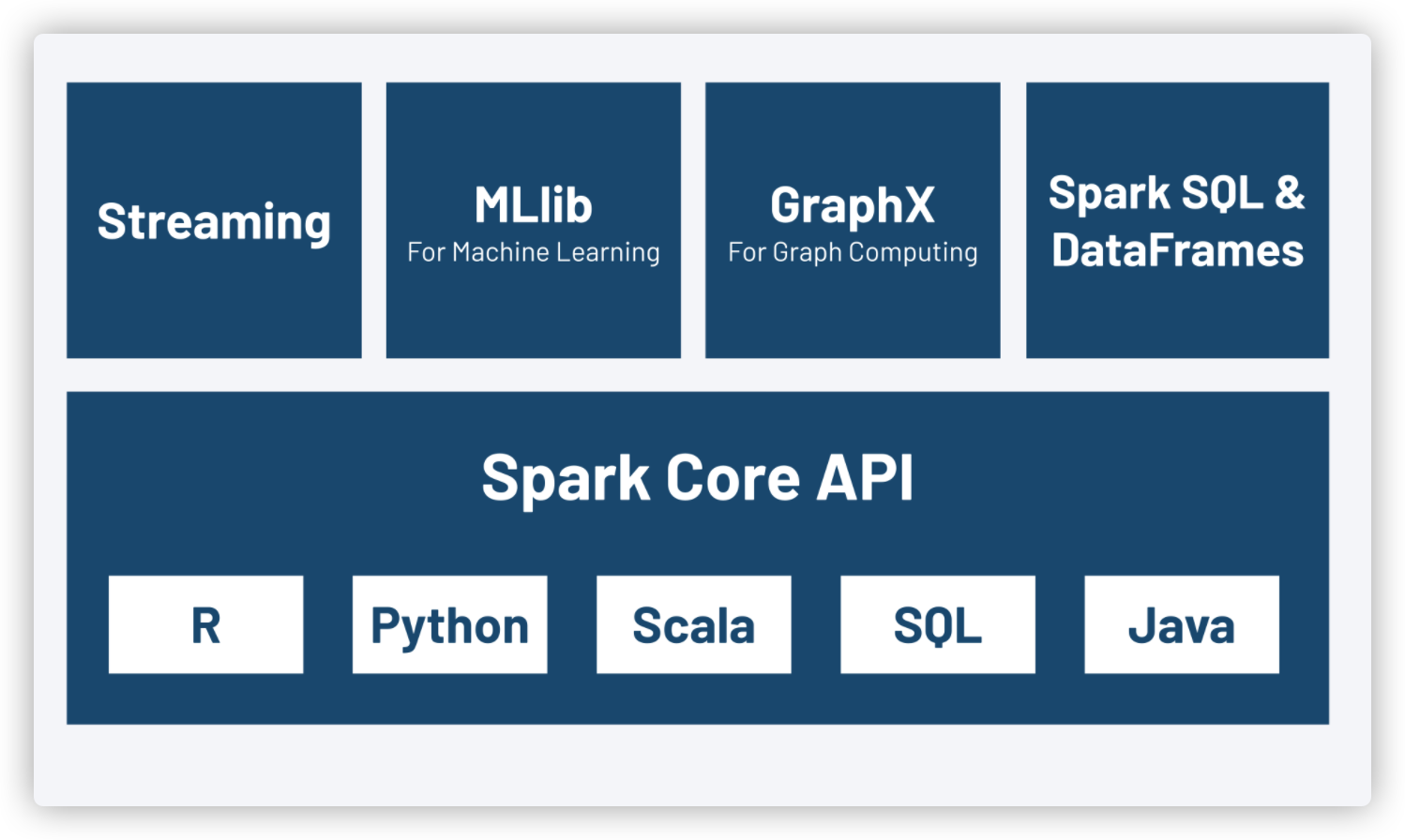
Spark makes it easy to start working with distributed computing systems.
Through its core API support for multiple languages, native libraries that enable easy streaming, machine learning, graph computing, and SQL - the Spark ecosystem offers some of the most extensive capabilities and features of any technology out there.
参考资料
https://zhuanlan.zhihu.com/p/361185327https://cloud.tencent.com/developer/article/1497323https://www.jianshu.com/p/d6dcbe473475