spark ��������Ŀʵս
����Ŀ¼����
1����������Ŀ����
1.1. ���ݲɼ�
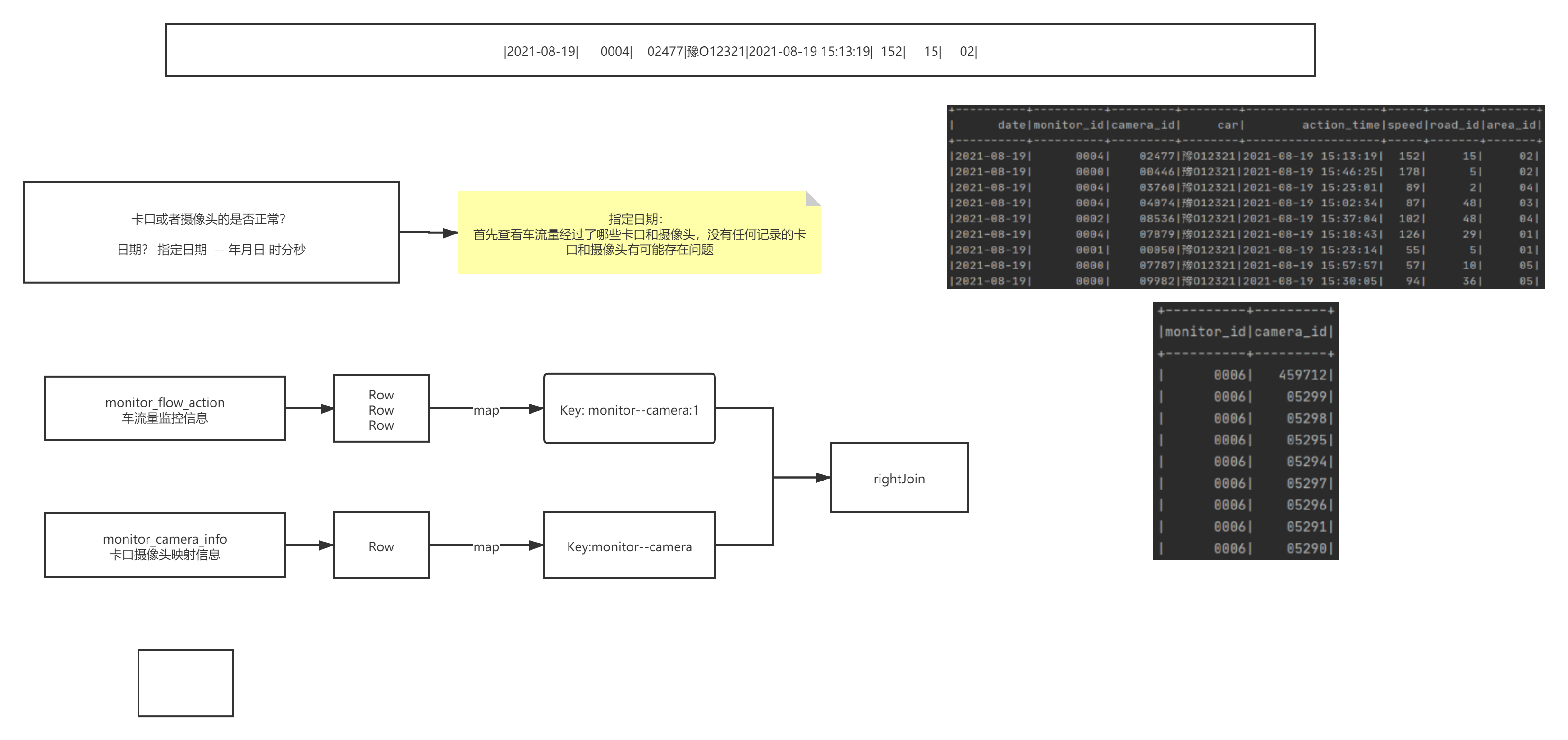
���ݴ��Ķ���?
- ����֪����������Դ,������վ,APP���߹�ҵ�豸(���翨�������豸),ʵ��ʵʱ���ݲɼ�,�������зdz���Ҫ��һ�������ν�����,Ҳ����˵,���,����վ���ĸ�ҳ����Щ��������ʱ,ǰ�˵Ĵ������javascript����app android/ios,��ͨ����������Ajax; socket���˵ķ�����������־���ݡ�
- ����ǿ�����Ϣ,��ôÿ���������Ϣ���ᴫ�䵽�������ˡ�
- ���Ⱦ���˵��վ����ҳ���������,��ô������Ҫ��ǰ�˵Ŀ�����ԱԼ����,����Щҳ����Щ����������ʱ��,��վ�Ļ���ͨ��ajax����,APP�Ļ���ͨ��Socket��������,���˵ķ���������ָ����ʽ����־�������������ݵĻ�,�Ǻͳ��̶������ݸ�ʽ��,������ָ���ĸ�ʽ�����������ʵʱ�����ݡ�
- ����ͨ��Flume���ָ�����ļ���,ת�Ƶ�HDFS����ȥ,ʵ�ʴ�����Ƿ���Hive����ΪHive���м��������,��������һ������,ʵʱ����,ͨ�����Ǵӷֲ�ʽ��Ϣ���м�Ⱥ�ж�ȡ��,����Kafka,ʵʱ��log,ʵʱ��д����Ϣ������,Ȼ���������Ǻ��ʵʱ���ݴ�������(storm��spark streaming),ʵʱ��kafka�ж�ȡ����,log��־
- ���ݳ��˴�Flume����,Ҳ�п���ֱ��ʹ��kafka ��producer��ɫ��kafka��ֱ������������
- ���������Ǵ�����ʵʱ����ϵͳ,����˵��storm��spark streaming������,����ʵʱ�Ĵ�kafka����ȡ����,Ȼ���ʵʱ�����ݽ��д����ͼ���,��������зdz����ӵ�ҵ����,�������ø��ӵĻ���ѧϰ,�����ھ�,�����Ƽ����㷨!Ȼ��ʵ��ʵʱ�ij�������,ʵʱ�Ƽ��ȵȡ�
1.2. ģ�����
- ������������ Spark Core
- ���۳�����ת���� Spark Core
- �������������top5�ĵ�·ͳ�� SparkSQL
- ���鲼��,��·ʵʱӵ��ͳ�� SparkStreaming
1.2.1. ������������ģ�����
����ʹ����(ƽ̨ʹ����)ָ����ijЩ����,ɸѡ��ָ����һ��������Ϣ(�����������ʱ��ɸѡ)
����״̬,����ɸѡ���������еĿ���(������һ������ͷ)��Ϣͳ��
- ����������
- �쳣��
- camera��������
- camera���쳣��
- camera����ϸ��Ϣ(monitor_id:camera_id)
- ����������TonN���ۺ�,�����ȡÿһ�����۵���ϸ��Ϣ(Top5 )
- �����ȡN��������Ϣ,����Щ���ݿ��Խ��ж�ά�ȷ���(��Ϊ�����ȡ������N��������Ϣ���Ժ�Ȩ���Ĵ�����������ij���)
- �������������ͨ����TopN���� (�鿴��Щ���۾���������ͨ��,����,����,����,���� ���������ٶȶν����Ĵ�����,����ͨ���ij�������ͬ�ͱȽ�����ͨ���ij�����,�Դ�����)
1.3. ��Ŀ�ܹ�����
ʹ�üܹ�
J2EEƽ̨,ǰ��ҳ��,��ҳ���п���ָ����������,�ύ����IJ���(����ʱ�䷶Χ,�����趨)ƽ̨����ܵ��û����ύ����,����õײ��װ��Spark-submit��shell�ű�,��ô����?���е���ҵ���Ի�ȡ���û�ָ����ɸѡ����,Ȼ�����ɸѡ�������м��㡣Spark����ļ�������д�뵽���ݿ���,����MySQL,Redis��
���J2EEƽ̨����ͨ��ǰ��ҳ��,չʾ���(�������ͼ���ķ�ʽչʾ���ݿ��еĽ��)��
1.4. ���ݽ���
1.4.1. ��������
���ۺ�:��һ����·��ͬλ�û�����������,���������۵ı���Dz�ͬ��,�ֱ����㲻ͬ����ij���
����ͷ���:ÿһ�������������һ������ij���,ÿһ�������ж����ͬ�ij���,ÿһ��������Ӧһ������ͷ,���Կ��ۺ�������ͷ�Ķ�Ӧ��ϵ��һ�Զ�Ĺ�ϵ��
1.4.2. ��
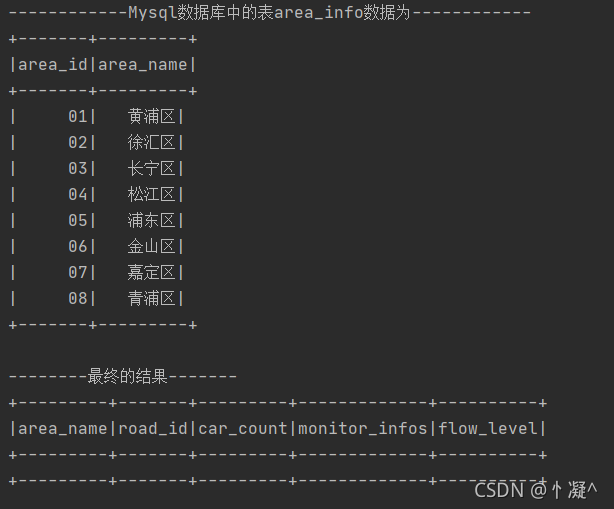
| monitor_flow_action�� | ��ص��ij�����Ϣ�� |
|---|---|
| date | ���� ��λ:�� |
| monitor_id | ���ں� |
| camera_id | ����ͷ��� |
| car | ���� |
| action_time | ij������ͷ����ʱ�� ��λ:�� |
| speed | ͨ�����۵��ٶ� |
| road_id | ��·id |
| area_id | ����ID |
| monitor_camera_info�� | ÿ�����۶�Ӧ������ͷ���(����) |
|---|---|
| monitor_id | ���۱�� |
| camera_id | ����ͷ��� |
�������ݼ����������
1.5. �������
- ������ɸѡ������Ϣ
- ����ָ�� ��ͬ������,ʱ�䷶Χ������Χ�����ۺŵ� �������ķ�����ͬ����Ŀ�����Ϣ
- ����״̬
- �Է��������Ŀ�����Ϣ,���Զ�̬�ļ��ÿһ�����۵�״̬,�鿴�����Ƿ���������,Ҳ���Բ鿴����ͷ
- ����������TonN����
- �鿴��Щ���۵ij��������,Ϊʲô�������ô�ߵij�����������ԭ��,���������ǵij����dz���,ɶԭ��,������ǵij����dz���,ɶԭ��? ���ỹ�Ǿۼ�? ������ܵ�����Ҳ���õ�����ij�������Ϣ,����һ�±��س�����ɵĻ�����س���?
- �ڷ��������Ŀ�����Ϣ�������ȡN��������Ϣ
- �����ȡN��������Ϣ,����Ȩ���Ĵ�����������ij���,��ʱ����Է�����Щ���Ĺ켣,��һ���ڲ�ͬ��ʱ��㳵�������������Ա��ڵ�·�Ĺ滮��
- �������������ͨ����TopN����
- ͳ�Ƴ��Ƿ����쭳�����,���߾������г�����ʻ,�����ڴ˴���װΥ�������豸
2����������
���ݴ�������:
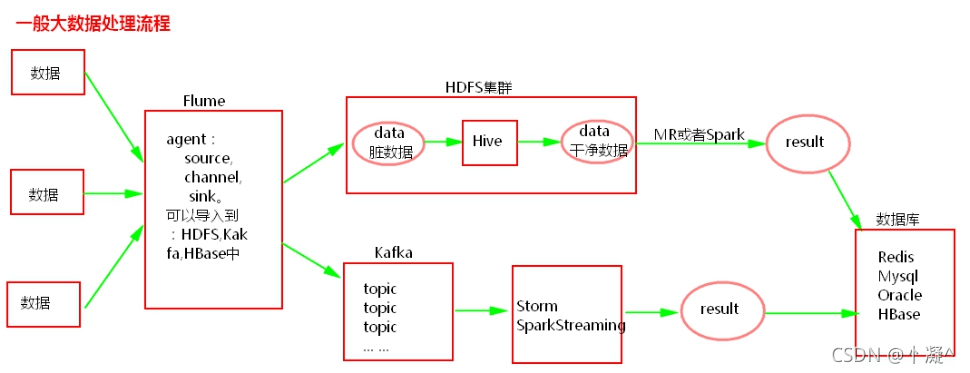
��˾�м�Ⱥû������
�ֲ�ʽ��ȡ����,��ڵ���ȡ����,һ�㽫������ȡ��flume��,���߽�����ֱ����ȡ����HDFS�С�
��˾�м�Ⱥ������
ÿ��ÿʱÿ���ڲ�������,����ֱ����ϴ����HBase����HDFS�С�������־����ֱ��ʹ��flum����ֲ�ʽ�ļ��С�
һ����������֮���ַ�Ϊ������ķ���������:
- �������ݷ�����HDFS��Ⱥ��֮��,һ����һ����Ҫ��ϴ����,���Խ�����ͨ��Hive��ϴ,��Ȼ����Hiveһ��ʹ�����,��������Ŀ���ǿ��Խ���ͬ������ֻ��HDFS�д���һ��,���������ظ����ݡ���ϴ��ɵ�����һ���ֻ����Hive���л����Խṹ�������ݷ���HDFS�ϡ��õ���ϴ������ݺ�һ���ʹ��MR����ʹ��Spark�������ݽ��з�������,Ҳ���Զ���ϴ�������ʹ��SparkSQL�����д���������֮��,��������ɵ����ݷ������ݿ���,��Redis,Mysql,Oracle��,��ǰ�˲�ѯչʾ��
- ������ݷ�����flume��,һ�㽫����sink��kafka��,��ͬ���ݵ�������벻ͬ��topic�С�Ȼ��Դ���kafka�е����ݽ�����ʽ����,һ�����ʹ��storm����SparkStreaming�����ݽ�����ϴ,��������,Ȼ����ŵ����ݿ���,��Redis,Mysql,Oracle��,�Թ�ǰ��ҳ������ѯչʾ��
3��spark����
��ν�Spark�����ύ����Ⱥ����?
���Ҳ�ǽű���ִ��Spark����
ƽ̨���ύSpark��������ͼ����:
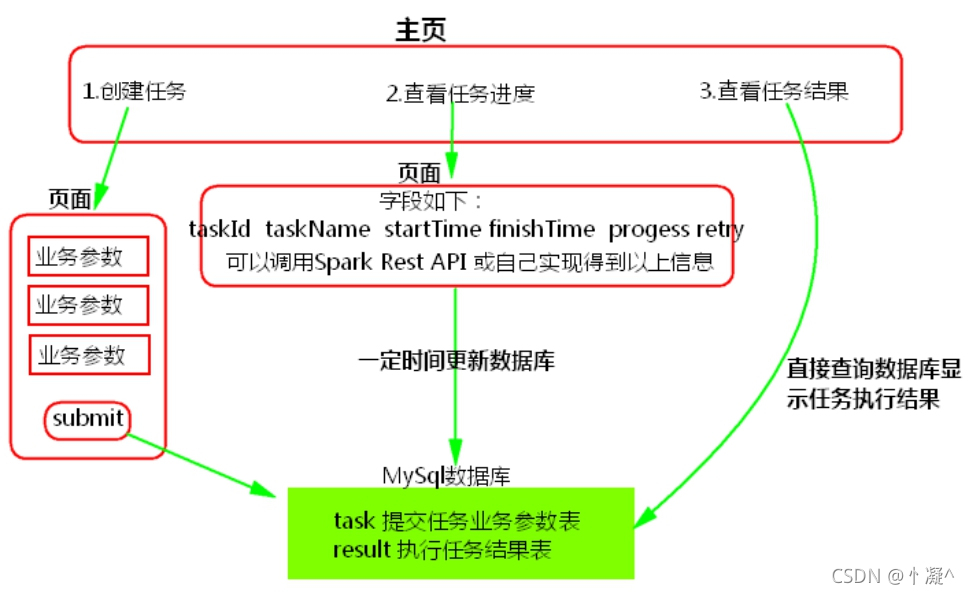
submit���Ƚ����ݴ���Mysql��,task����Ψһ����,��������Ϊ�˼�����ִ��ʧ��ʱ,����ֱ�������ݿ��в�ѯ֮ǰ���ύ��ҵ�����,������ʧ�ܺ�,�´�retryʱ����ִ�С�
submit�����ʹ��java����liunxϵͳ�ű�,ͨ��taskId�õ�ϵͳ�е�ҵ��������ݡ�
ע��: ����ʹ��tomcatʵ��ƽ̨��,��ôtomcatӦ�ò����ڿͻ��ˡ�
l java���������ִ��liunx�ű�?
Process proc = Runtime.**getRuntime**().exec(��sh �ű���);
proc.waitFor();

4��ģ�鹦��
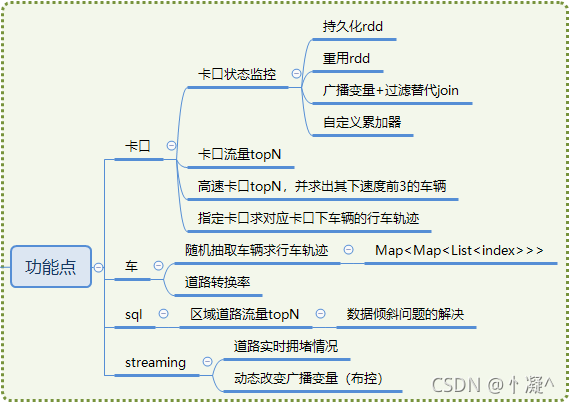
4.1��������������
- ȫ��ʹ��SparkCoreʵ�֡�
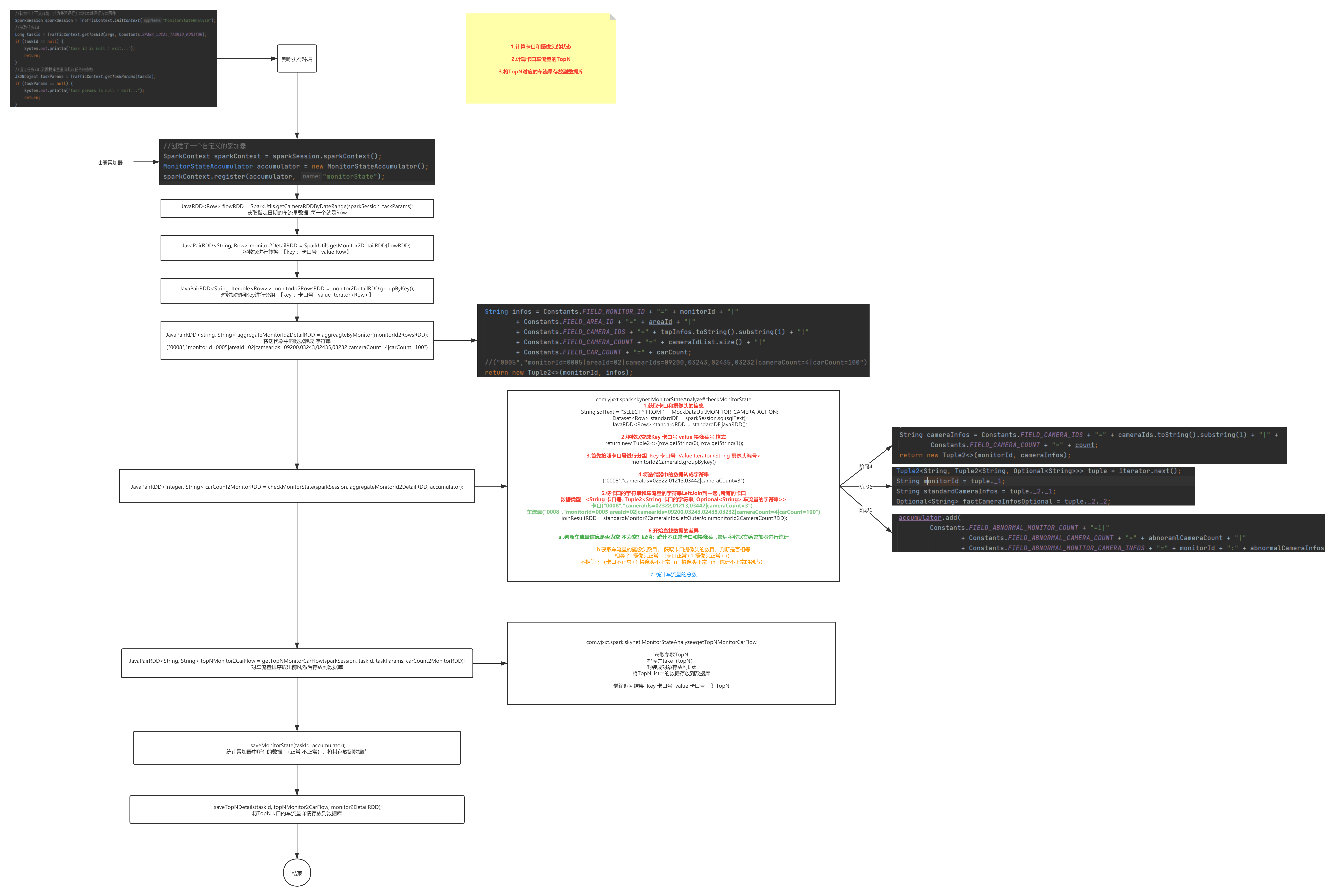
4.1.1. ����״̬���
4.1.1.1. ͳ�ƿ��ڻ�����ͷ
def main(args: Array[String]): Unit = {
//��ȡ����Դ
val sparkSession = ContextUtils.getSparkSession("Hello01MonitorState")
//��ȡ����
MockDataUtil.mock2view(sparkSession)
//------------------------------ͳ�ƿ�������ͷͨ���ij����ĺϼ�----------------------------
import sparkSession.implicits._
//��ʼ��ȡ����
val dataFrame: DataFrame = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-19' ")
//��ʼ����
val mcRdd: RDD[(String, Int)] = dataFrame.map(ele => Tuple2(ele.getString(1) + ":" + ele.getString(2), 1)).rdd
//��ʼ���кϲ�
val flowRdd: RDD[(String, Int)] = mcRdd.reduceByKey(_ + _)
//------------------------------ͳ�ƿ������е�����ͷ----------------------------
val cameraDataFrame = sparkSession.sql("select * from " + MockDataUtil.MONITOR_CAMERA_ACTION)
val cameraRdd: RDD[(String, Int)] = cameraDataFrame.map(ele => ((ele.getString(0) + ":" + ele.getString(1)), 1)).rdd
//------------------------------�ϲ�������������ͷRDD----------------------------
val allRDD: RDD[(String, (Option[Int], Int))] = flowRdd.rightOuterJoin(cameraRdd).filter(ele => ele._2._1.isEmpty)
allRDD.foreach(println)
}

4.1.1.2. ͳ��ÿ����������
def main(args: Array[String]): Unit = {
//��ȡ����Դ
val sparkSession = ContextUtils.getSparkSession("Hello02MonitorFlowCount")
//��ȡ����
MockDataUtil.mock2view(sparkSession)
//------------------------------ͳ�ƿ���ͨ���ij����ĺϼ�----------------------------
import sparkSession.implicits._
//��ʼ��ȡ����
val dataFrame: DataFrame = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ")
//��ʼ����
val mcRdd: RDD[(String, Int)] = dataFrame.map(ele => Tuple2(ele.getString(1), 1)).rdd
//��ʼ���кϲ�
val flowRdd: RDD[(String, Int)] = mcRdd.reduceByKey(_ + _)
flowRdd.foreach(println)
}

4.1.1.3. ͳ��ÿ�����������ͷ
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("Hello03MonitorStateAnalyze")
MockDataUtil.mock2view(sparkSession)
//---------------------��ʼ������������Ϣ,����������Ϊ1 ���ڲ���Ϊ����
val flowInfo: RDD[(String, String)] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd.map(row => (row.getString(1), row)).groupByKey().map(ele => {
val monitorId: String = ele._1
val cameraIdSet = new mutable.HashSet[String]()
ele._2.foreach(row => cameraIdSet.add(row.getString(2)))
//ƴ���ַ���
val info: String = Constants.FIELD_MONITOR_ID + "=" + monitorId + "|" + Constants.FIELD_AREA_ID + "=�ֶ�����|" + Constants.FIELD_CAMERA_IDS + "=" + cameraIdSet.mkString("-") + "|" + Constants.FIELD_CAMERA_COUNT + "=" + cameraIdSet.size + "|" + Constants.FIELD_CAR_COUNT + "=" + ele._2.size
//���ؽ��
(monitorId, info)
})
//-----------------------��ʼ��������ͷ����
val monitorInfo: RDD[(String, String)] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_CAMERA_ACTION).rdd.map(row => (row.getString(0), row.getString(1))).groupByKey().map(ele => {
val monitorId: String = ele._1
//ƴ���ַ���
val info: String = Constants.FIELD_CAMERA_IDS + "=" + ele._2.toList.mkString("-") + "|" + Constants.FIELD_CAMERA_COUNT + "=" + ele._2.size
//���ؽ��
(monitorId, info)
})
//-----------------------������Join��һ��
monitorInfo.leftOuterJoin(flowInfo).foreach(println)
}

4.1.1.5 ������������ �������
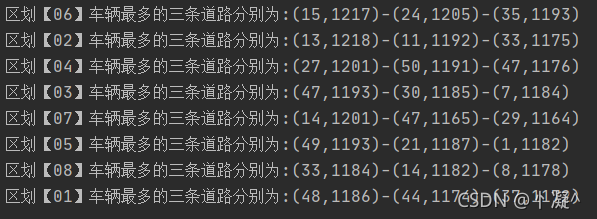
4.1.2. ��������Top3�����ٶ�
- ��������top3
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("AreaTop3Road")
MockDataUtil.mock2view(sparkSession)
//��ʼ����
val fRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd
fRdd.map(row => (row.getString(7) + "_" + row.getString(6) + "&" + (Math.random() * 30 + 10).toInt, 1)).reduceByKey(_ + _).map(ele => {
val area_road_random = ele._1
val count = ele._2
(area_road_random.split("_")(0), area_road_random.split("_")(1).split("&")(0) + "_" + count)
})
.groupByKey()
.map(ele => {
val map = new mutable.HashMap[String, Int]()
ele._2.foreach(e => {
val key = e.split("_")(0)
val value = e.split("_")(1).toInt
map.put(key, map.get(key).getOrElse(0) + value)
})
"������" + ele._1 + "����������������·�ֱ�Ϊ:" + map.toList.sortBy(_._2).takeRight(3).reverse.mkString("-")
})
.foreach(println)
}
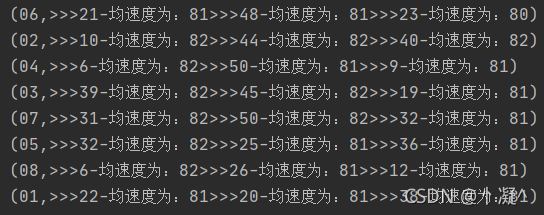
- �����·�ٶ�
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("AreaTop3Speed")
MockDataUtil.mock2view(sparkSession)
val sRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd
sRdd.map(e=>{
((e.getString(7),e.getString(6)),e.getString(5).toInt)
})
.groupByKey()
.map(e=>{
val list: List[Int] = e._2.toList
val i: Int = list.sum/list.size
(e._1._1,(e._1._2,i))
})
.groupByKey()
.map(e=>{
val tuples = e._2.toList.sortBy(_._2).reverse.take(3)
var strBui: StringBuilder = new StringBuilder
for (i <- tuples ){
val str: String = i._1 + "-���ٶ�Ϊ:" + i._2
strBui.append(">>>"+str)
}
(e._1,strBui)
})
.foreach(println)
}
4.1.3. �����иߵ�������
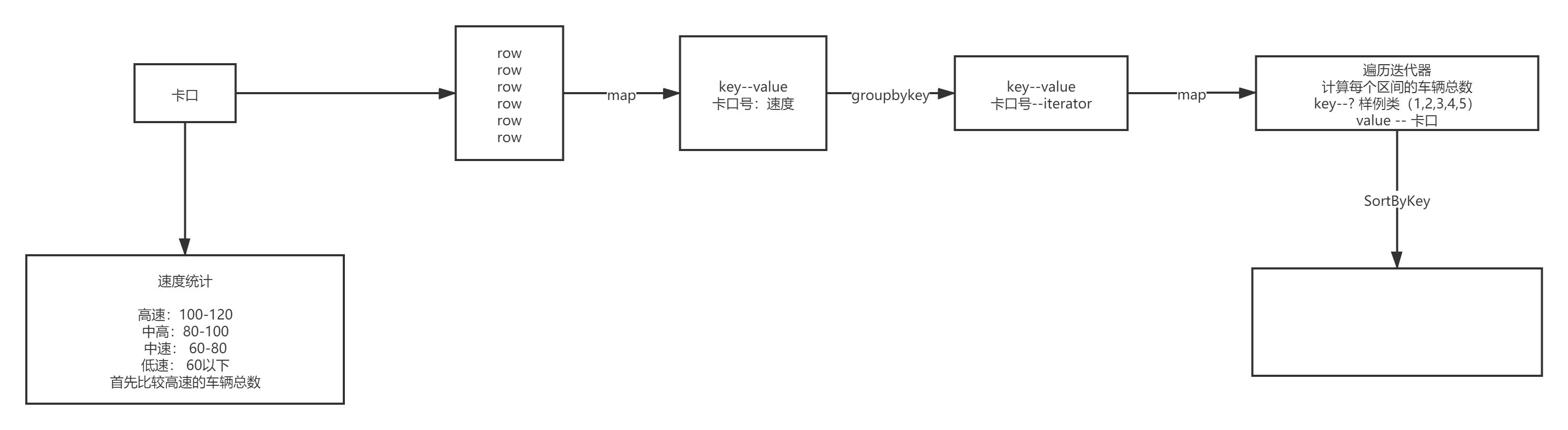
object Hello04MonitorTopNSpeed {
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("Hello04MonitorTopNSpeed")
MockDataUtil.mock2view(sparkSession)
//---------------------��ʼ������������Ϣ,����������Ϊ1 ���ڲ���Ϊ����
val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-20' ").rdd
val monitor2speedRDD: RDD[(String, Iterable[String])] = flowRdd.map(row => (row.getString(1), row.getString(5))).groupByKey()
val speedCount2monitorRDD: RDD[(SpeedCount, String)] = monitor2speedRDD.map(ele => {
//��ȡ���ں�
val monitorId: String = ele._1
//����һ��Map[0,60,100,120]
var high = 0;
var normal = 0;
var low = 0;
//��ȡ���е��ٶȵij�������
ele._2.foreach(speed => {
//�ж��ٶ�
if (speed.toInt > 100) {
high += 1
} else if (speed.toInt > 60) {
normal += 1
} else {
low += 1
}
})
//�����ٶȶ���
(SpeedCount(high, normal, low), monitorId)
})
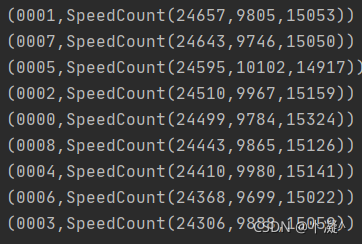
speedCount2monitorRDD.sortByKey(false).map(x => (x._2, x._1)).foreach(println)
}
}
case class SpeedCount(high: Int, normal: Int, low: Int) extends Ordered[SpeedCount] with KryoRegistrator {
override def compare(that: SpeedCount): Int = {
var result = this.high - that.high
if (result == 0) {
result = this.normal - that.normal
if (result == 0) {
result = this.low - that.low
}
}
return result
}
override def registerClasses(kryo: Kryo): Unit = {
kryo.register(SpeedCount.getClass)
}
}
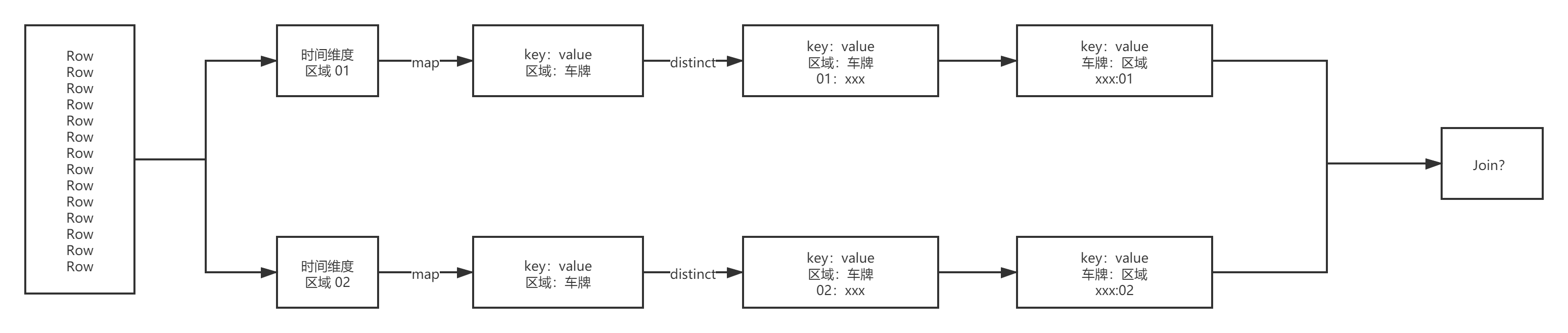
4.1.3. ָ�����ڶ�Ӧ���ڳ����켣
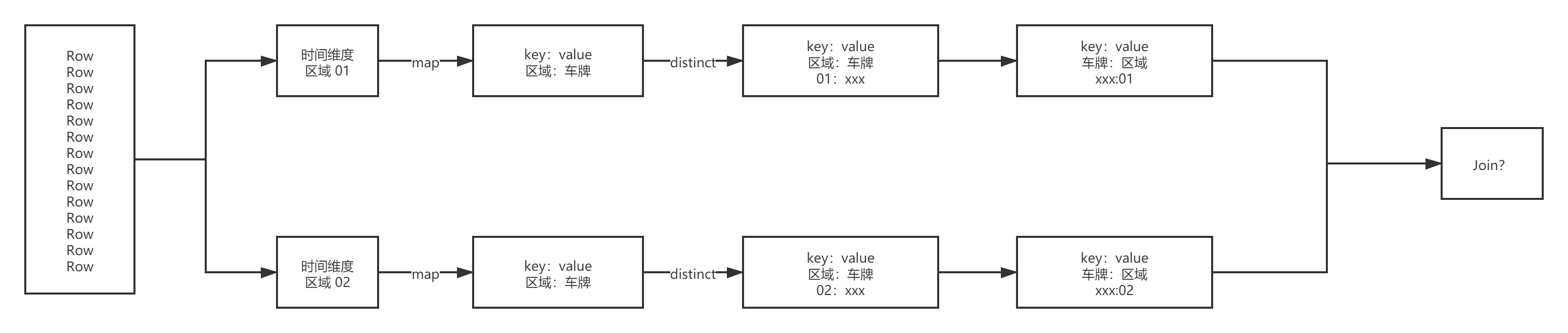
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("Hello04MonitorTopNSpeed")
MockDataUtil.mock2view(sparkSession)
//��ȡ����
val area01Rdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' and area_id = '01' ").rdd
val area02Rdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' and area_id = '02' ").rdd
val area01CarRdd = area01Rdd.map(row => (row.getString(3), row.getString(7))).groupByKey()
val area02CarRdd = area02Rdd.map(row => (row.getString(3), row.getString(7))).groupByKey()
area01CarRdd.join(area02CarRdd).foreach(println)
}

4.2���г��켣
4.2.1. �����г��켣
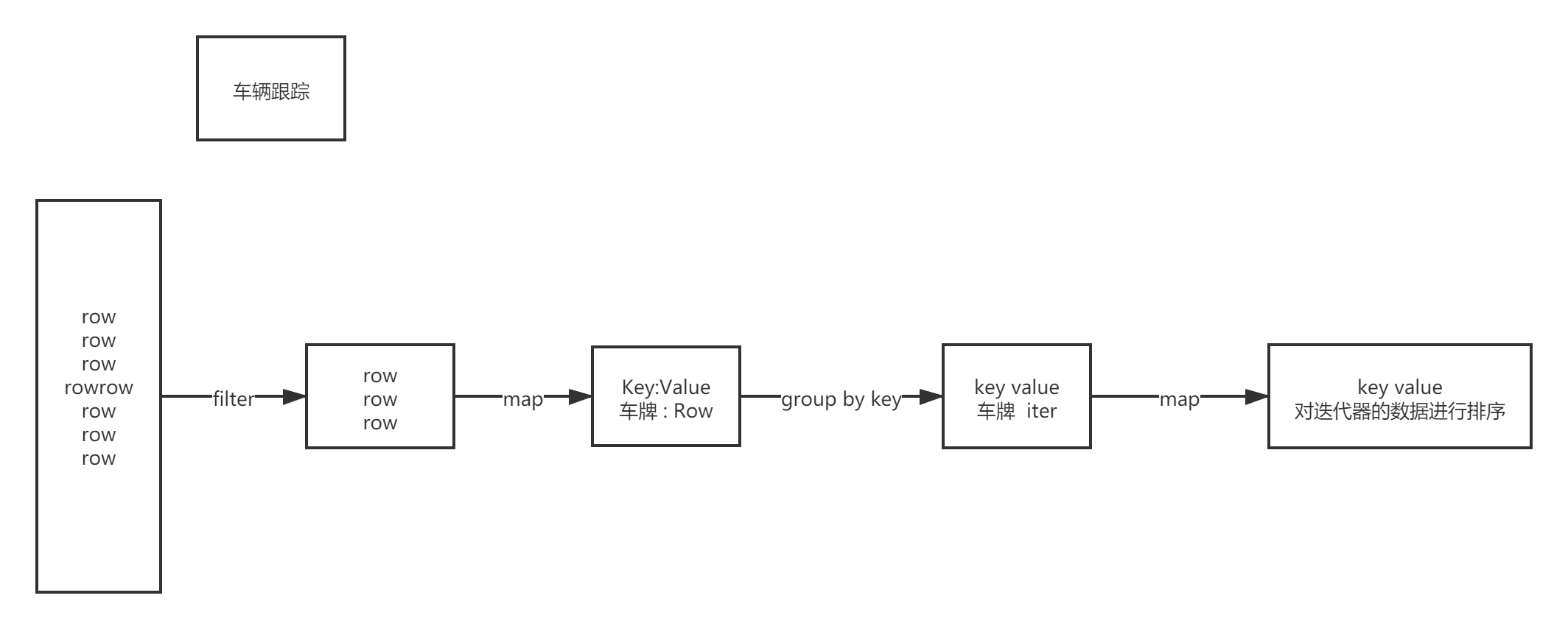
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("AreaCar")
MockDataUtil.mock2view(sparkSession)
//��ѯ ������ʻ�켣 ��������
val c1Rdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd
val carRdd: RDD[(String, StringBuilder)] = c1Rdd.map(e => { (e.getString(3), (e.getString(4), e.getString(6), e.getString(2))) })
.groupByKey()
.map(e => {
val tuples: List[(String, String, String)] = e._2.toList.sortBy(_._1)
val list = new StringBuilder
for (i <- tuples) {
//println(i)
val str: String = i._2 + ":" + i._3
list.append(str + "-")
}
(e._1, list)
})
//carRdd.foreach(println)
}

4.2.2. ��������
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("AreaCar")
MockDataUtil.mock2view(sparkSession)
//�����κεĿ��ھ��붼�� 10���ӳ��� ,���ͬһ���ӳ����ڲ�ͬ�Ŀ��ھͻ���������
val deckRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd
deckRdd.map(e => {
val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
(e.getString(3), (dateFormat.parse(e.getString(4)),e.getString(1)))
}).groupByKey(1)
.map(e => {
val list: List[(util.Date, String)] = e._2.toList.sortBy(x=>x._1)
var bool = false
var d: util.Date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2021-08-23 00:00:00")
var mid="?"
for (i <- list) {
if (d.getTime - i._1.getTime < 600000 && i._2!=mid )
bool = true
d = i._1
mid=i._2
}
(e._1, bool)
})
.filter(f => f._2)
.foreach(println)
}

4.2.3. ���������C��ˮ�س����㷨
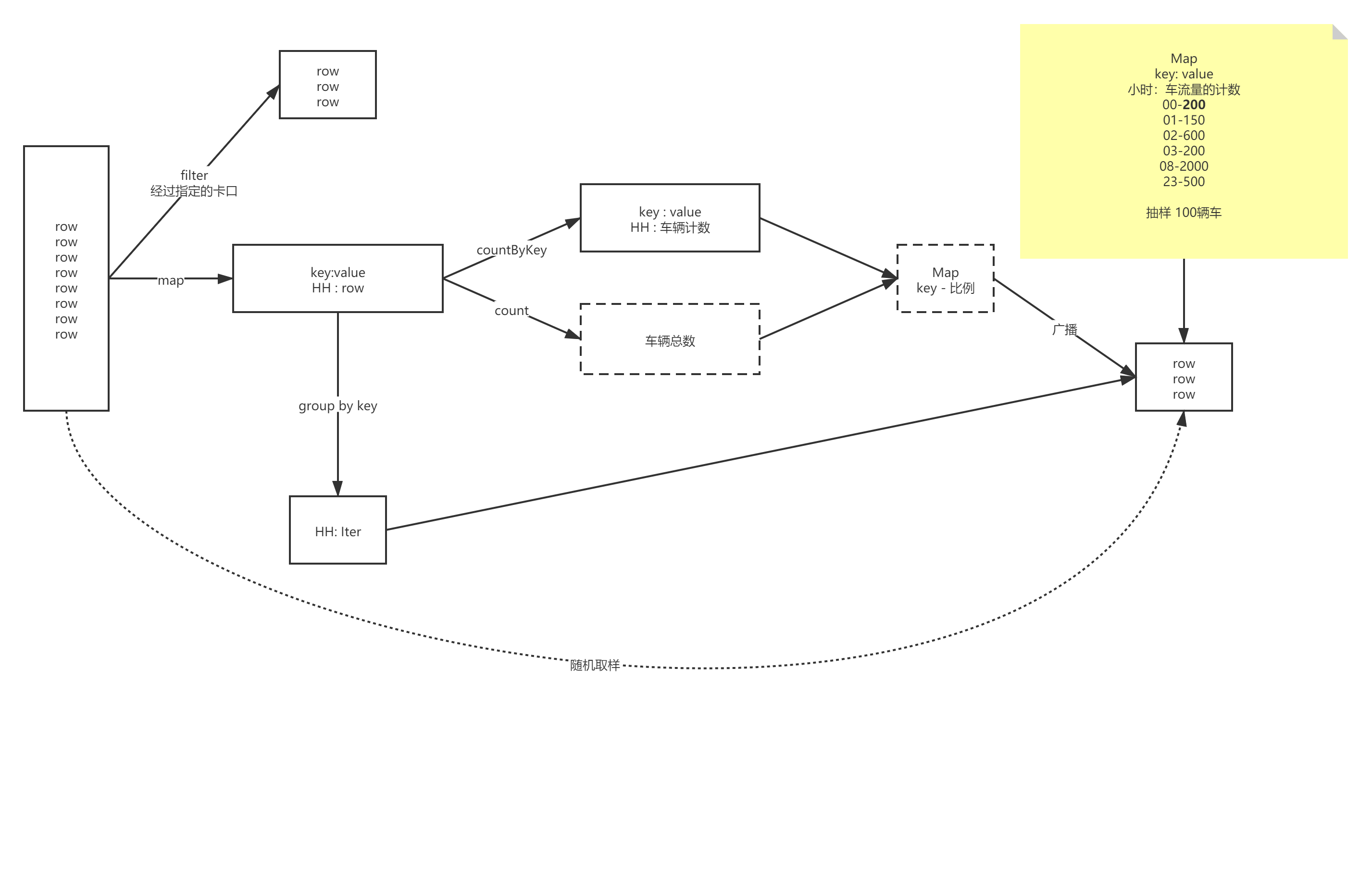
def main(args: Array[String]): Unit = {
val sparkSession = ContextUtils.getSparkSession("Hello04MonitorTopNSpeed")
MockDataUtil.mock2view(sparkSession)
//��ȡ����
val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-21' ").rdd
//yyyy-MM-dd_HH , row
val hourRDD: RDD[(String, Row)] = flowRdd.map(row => (DateUtils.getDateHour(row.getString(4)), row))
//������������,�����й㲥
val flowAllCount: Long = hourRDD.count()
val broadcastFlowAllCount: Broadcast[Long] = sparkSession.sparkContext.broadcast(flowAllCount)
//����ÿ��Сʱ�ı��� �����й㲥
val hourRatio: collection.Map[String, Double] = hourRDD.countByKey().map(e => {
(e._1, e._2 * 1.0 / broadcastFlowAllCount.value)
})
val broadcastHourRatio: Broadcast[collection.Map[String, Double]] = sparkSession.sparkContext.broadcast(hourRatio)
//��ʼ���г���
val sampleRDD: RDD[Row] = hourRDD.groupByKey().flatMap(ele => {
val hour: String = ele._1
val list: List[Row] = ele._2.iterator.toList
//���㱾ʱ��Ҫ������������
val sampleRatio: Double = broadcastHourRatio.value.get(hour).getOrElse(0)
val sampleNum: Long = Math.round(sampleRatio * 100)
//��ʼ����ȡ��(��ˮ�س���)
val sampleList: ListBuffer[Row] = new ListBuffer[Row]()
sampleList.appendAll(list.take(sampleNum.toInt))
for (i <- sampleNum until list.size) {
//�������һ������
val num = (Math.random() * list.size).toInt
if (num < sampleNum) {
sampleList.update(num, list(i.toInt))
}
}
sampleList
})
sampleRDD.foreach(println)
}
4.2.4. ��·ת����
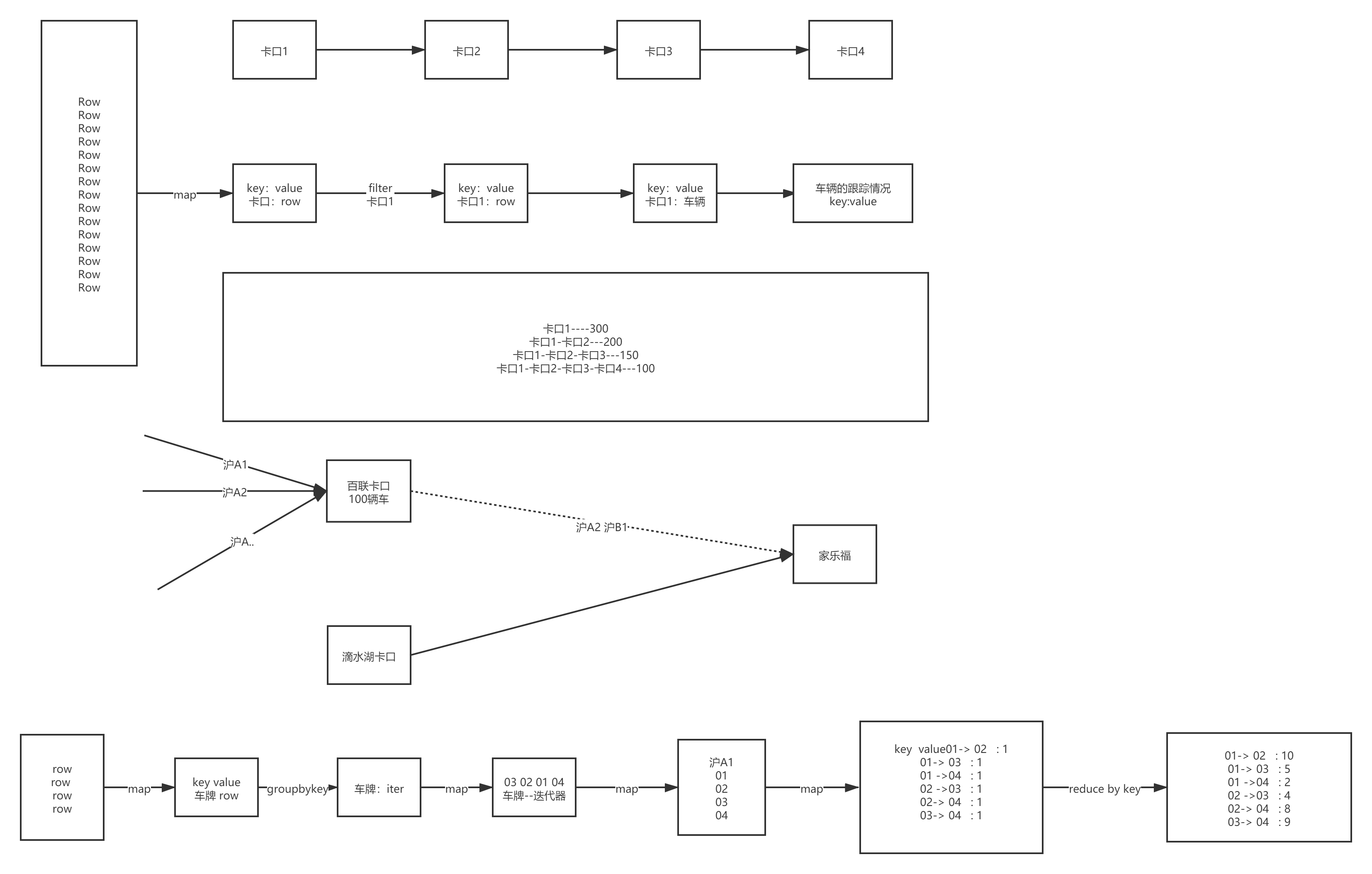
def main(args: Array[String]): Unit = {
//�����Ự
val sparkSession = ContextUtils.getSparkSession("Hello07MonitorConvertRatio")
MockDataUtil.mock2view(sparkSession)
//��ʼ����
val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd
//����ÿ�����ڵ���ͨ����
val monitorCountMap: collection.Map[String, Long] = flowRdd.map(row => (row.getString(1), row)).countByKey()
//���㿨�ڵ����ڵ�ͨ����
val sortRDD: RDD[(String, List[Row])] = flowRdd.map(row => (row.getString(3), row)).groupByKey().map(ele => (ele._1, ele._2.iterator.toList.sortBy(_.getString(4))))
val m2mMap: collection.Map[String, Long] = sortRDD.flatMap(ele => {
//���ӳ���ϵ
val map: mutable.HashMap[String, Int] = mutable.HashMap[String, Int]()
val list: List[Row] = ele._2.toList
for (i <- 0 until list.size; j <- i + 1 until list.size) {
//ƴ��Key
val key = list(i).getString(1) + "->" + list(j).getString(1)
map.put(key, map.get(key).getOrElse(0) + 1);
}
//���ؽ��
map.toList
}).countByKey()
//��ʼ���м���
m2mMap.foreach(ele => {
println("����[" + ele._1 + "]��ת����Ϊ:" + ele._2.toDouble / monitorCountMap.get(ele._1.split("->")(0)).get)
})
}

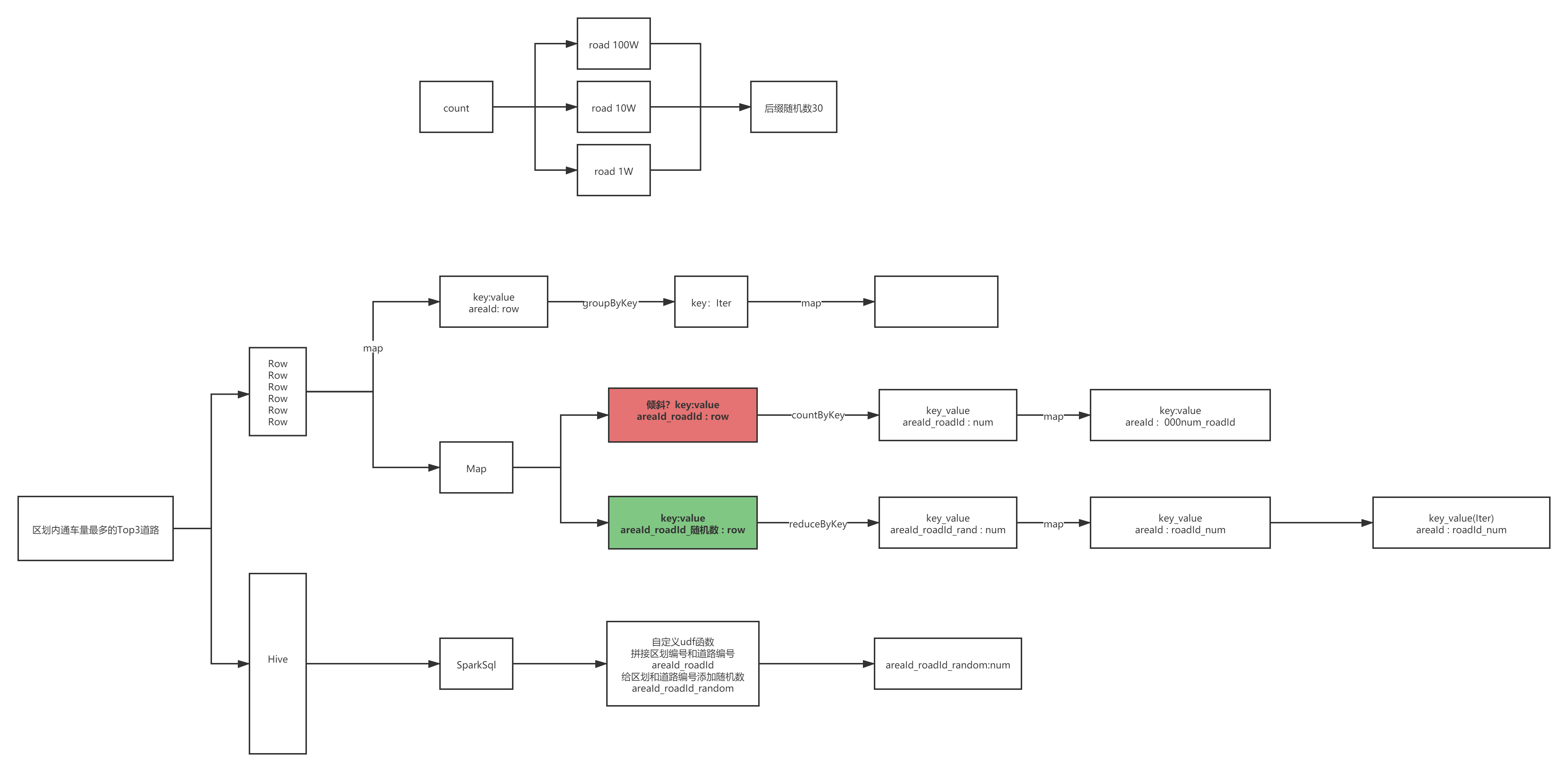
4.3�������·����Top3
- ���������
- key���Ӻ�����,��С������б
4.3.1 RDD���
def main(args: Array[String]): Unit = {
//�����Ự
val sparkSession = ContextUtils.getSparkSession("Hello07MonitorConvertRatio")
MockDataUtil.mock2view(sparkSession)
//��ʼ����
val flowRdd: RDD[Row] = sparkSession.sql("select * from " + MockDataUtil.MONITOR_FLOW_ACTION + " where date = '2021-08-23' ").rdd
//��ʼ����
flowRdd.map(row => (row.getString(7) + "_" + row.getString(6) + "&" + (Math.random() * 30 + 10).toInt, 1)).reduceByKey(_ + _).map(ele => {
val area_road_random = ele._1
val count = ele._2
(area_road_random.split("_")(0), area_road_random.split("_")(1).split("&")(0) + "_" + count)
}).groupByKey().map(ele => {
val map = new mutable.HashMap[String, Int]()
ele._2.foreach(e => {
val key = e.split("_")(0)
val value = e.split("_")(1).toInt
map.put(key, map.get(key).getOrElse(0) + value)
})
"������" + ele._1 + "����������������·�ֱ�Ϊ:" + map.toList.sortBy(_._2).takeRight(3).reverse.mkString("-")
}).foreach(println)
}
4.3.2. Java����Hive��SQL���
-
��hive�ֶ�����database Ϊtraffic ��
-
����ģ������,��ģ�������ύ��linux�ϡ�
-
��data2hive���� ���,�ύ���ͻ������С�
-
��ѯhive�����ݿ�Ϊtraffic��monitor_flow_action��monitor_camera_info�������ݿ���Ƿ������ݡ�
������mysql���ݿ����������
�ڰ�װmysql��linux�ڵ�·��/etc/my.cnf�м���:
- ��[client]������
default-character-set=utf8 - ��[mysqld]������
default-character-set=utf8
��ͼ:

������Ŀ��AreaTop3RoadFlowAnalyze����
4.4��Streaming ʵʱ
4.4.1. ��·ʵʱӵ����� --kafka
- ������
public class MockRealTimeData extends Thread {
private static final Random random = new Random();
private static final String[] locations = new String[]{"³", "��", "��", "��", "��", "��", "��", "��", "��", "��"};
private static final String topic = "RoadRealTimeLog";
private KafkaProducer<String, String> producer;
public MockRealTimeData() {
//���������ļ��б�
Properties properties = new Properties();
// kafka��ַ,�����ַ�ö��ŷָ�
properties.put("bootstrap.servers", "192.168.100.101:9092,192.168.100.102:9092,192.168.100.103:9092");
//����д�����ݵĸ�ʽ
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//д����Ӧ��ʽ
properties.put("acks", "all");
//��������
properties.put("retries", 1);
//�����
properties.put("batch.size", 16384);
//���������߶���
producer = new KafkaProducer<String, String>(properties);
}
public void run() {
while (true) {
String date = DateUtils.getTodayDate();
String baseActionTime = date + " " + StringUtils.fullFill(random.nextInt(24) + "");
baseActionTime = date + " " + StringUtils.fullFill((Integer.parseInt(baseActionTime.split(" ")[1]) + 1) + "");
String actionTime = baseActionTime + ":" + StringUtils.fullFill(random.nextInt(60) + "") + ":" + StringUtils.fullFill(random.nextInt(60) + "");
String monitorId = StringUtils.fullFill(4, random.nextInt(9) + "");
String car = locations[random.nextInt(10)] + (char) (65 + random.nextInt(26)) + StringUtils.fullFill(5, random.nextInt(99999) + "");
String speed = random.nextInt(260) + "";
String roadId = random.nextInt(50) + 1 + "";
String cameraId = StringUtils.fullFill(5, random.nextInt(9999) + "");
String areaId = StringUtils.fullFill(2, random.nextInt(8) + "");
//��װ��Ϣ����
ProducerRecord<String, String> banRecordBlue = new ProducerRecord<>(topic, "traffic_" + monitorId, date + "\t" + monitorId + "\t" + cameraId + "\t" + car + "\t" + actionTime + "\t" + speed + "\t" + roadId + "\t" + areaId);
//������Ϣ
producer.send(banRecordBlue);
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* ����Kafka Producer
*
* @param args
*/
public static void main(String[] args) {
MockRealTimeData mockRealTimeData = new MockRealTimeData();
mockRealTimeData.start();
}
}
- ������
object Hello10RealRoadState {
def main(args: Array[String]): Unit = {
//����Conf
val sparkConf = new SparkConf().setAppName("Hello10RealRoadState").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
//����Kafka��ȡ����
//������Ϣ
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "traffic",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("RoadRealTimeLog")
//��ʼ����Kafka
val linesDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils createDirectStream(streamingContext, PreferConsistent, Subscribe[String, String](topics, kafkaParams))
//���ں���
linesDStream.map(_.value())
.window(Seconds(10), Seconds(10))
.map(ele => (ele.split("\t")(1), ele.split("\t")(5).toInt))
.groupByKey()
.map(ele => {
(ele._1, ele._2.toList.sum.toDouble / ele._2.size)
})
.foreachRDD(rdd => {
rdd.foreach(ele => {
println(ele._1 + "--" + ele._2)
})
})
//��������
streamingContext.start()
streamingContext.awaitTermination()
}
}