一、准备工作
1、准备三台虚拟机:
master、node1、node2

2、时间同步
1)、查看本地时间
date
2)、删除本地时间
rm -f /etc/localtime
3)、复制时区文件到localtime
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
4)、安装插件ntpdate
yum install -y ntpdate
5)、将本地时间与网络时间同步
ntpdate -u?ntp.api.bz
6)、再次查看时间
date
7)、保存配置
hwclock -w
8)、重启
reboot
9)、再次查看时间
date
3、检查jdk的安装jdk1.8
java -version

4、修改主机名
三台分别执行 vim /etc/hostname 并将内容指定为对应的主机名
5、关闭防火墙
关闭防火墙:
systemctl stop firewalld
查看防火墙状态:
systemctl status firewalld
取消防火墙自启:
systemctl disable firewalld

6、静态IP配置
1)直接使用图形化界面配置(不推荐)
2)手动编辑配置文件进行配置
编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
HWADDR=00:0C:29:E2:B8:F2
NAME=ens33 DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.10.110
GATEWAY=192.168.10.2
NETMASK=255.255.255.0
DNS1=192.168.10.2
?DNS2=8.8.8.8
?需要修改:HWADDR(mac地址)
IPADDR(根据自己的网段,自定义IP地址)
GATEWAY(根据自己的网段填写对应的网关地址)

-
- 2、关闭NetworkManager,并取消开机自启
- systemctl stop NetworkManager
- systemctl disable NetworkManager?
- 3、重启网络服务systemctl restart network
7、免密登录
1)、生成密钥
ssh-keygen -t rsa#
2)、配置免密登录
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
3)、测试免密登录
ssh node1
8、配置好映射文件:
vim /etc/hosts
192.168.190.100 master
192.168.190.101 node1
192.168.190.102 node2
二、搭建Hadoop集群
1、上传安装包并解压
# 使用xftp上传压缩包至master的/usr/local/soft/packages/
cd /urs/local/soft/packages/
# 解压
tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
2、配置环境变量
vim /etc/profile ? JAVA_HOME=/usr/local/soft/jdk1.8.0_171 HADOOP_HOME=/usr/local/soft/hadoop-2.7.6 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH ?
# 重新加载环境变量
source /etc/profile

3、修改Hadoop配置文件
1)、修改core-site.xml
vim core-site.xml
修改内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property> <property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>

2)、修改hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171

3)、修改hdfs-site.xml
vim hdfs-site.xml
修改内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.permissions</name>
<value>false</value>
</property>

4)编辑修改mapred-site.xml
注意:该配置文件初始为mapred-site.xml.template,需要修改为mapred-site.xml
vim mapred-site.xml
修改内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>

5)、编辑修改slaves
vim slaves
修改内容:
node1 node2

6)、编辑修改yarn-site.xml
vim yarn-site.xml
修改内容:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>

4、分发Hadoop到node1、node2
cd /usr/local/soft/
scp -r hadoop-2.7.6/ node1:`pwd`
scp -r hadoop-2.7.6/ node2:`pwd`
5、格式化namenode(第一次启动的时候需要执行)
hdfs namenode -format

6、启动Hadoop集群
start-all.sh

7、检查master、node1、node2上的进程
1)master
[root@master hadoop]# jps
17698 ResourceManager
17955 Jps
17356 NameNode 1
7548 SecondaryNameNode

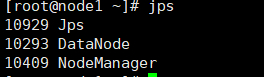
2)node1
[root@node1 ~]# jps
10530 Jps
10293 DataNode
10409 NodeManager
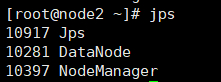
3)node2
[root@node2 ~]# jps
10518 Jps 10281
DataNode
10397 NodeManager
8、访问HDFS的WEB界面
http://master:50070

9、访问YARN的WEB界面
http://master:8088

10、关闭Hadoop集群
stop-all.sh
