在线拍卖数据分析
首先需配置部署在线拍卖数据分析系统所需要的环境,然后把数据集上传到 HDFS 分布式文件系统,利用 Hive 或 Spark 对在线拍卖数据进行分析处理,并利用 Python对分析结果进行可视化展示。
利用常用的机器学习方法,例如逻辑回归,决策树,支持向量机或者神经网络等建立分类模型,利用训练数据集对该模型进行训练,
并用测试数据集测试该分类模型的准确率
二、实验实习目的及要求
- 掌握 linux 系统基础配置与 Linux Shell 语法
- 掌握配置 hadoop 的配置与操作命令
- 掌握利用 JAVA 进行 MapReduce 编写程序
- 掌握 Hive 配置及 HiveSQL 语法
- 掌握 Spark 安装与部署及 Scala 数据分析程序(JAVA 或 Python)编写
- 掌握实际大数据项目案例的方案设计与处理流程
- 掌握 Python 数据可视化展示方法
三、实验实习设备(环境)及要求(软硬件条件)
- 系统版本:ubuntu18.04
- Hadoop 版本: Apache Hadoop 2.7.3
- Hive 版本:Apache Hive 2.1.1
- Spark 版本:spark-2.1.1-bin-hadoop2.7
- MySQL 版本:MySQL 5.7.18
- Anaconda 版本:建议 Anaconda3 4.3.0 以后版本(Python3.6)
实验环境是很早就跟着复旦大学大数据学习路线搭好的
四、实验实习过程步骤,实验实习结果及分析
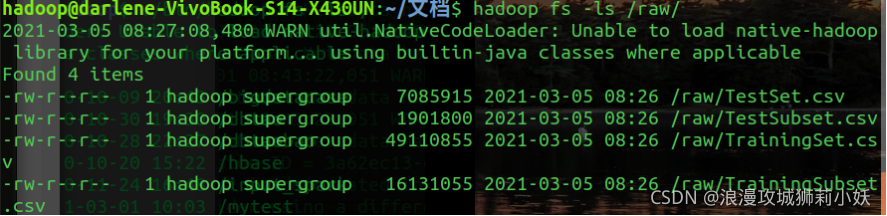
1.数据集准备
2.数据预处理
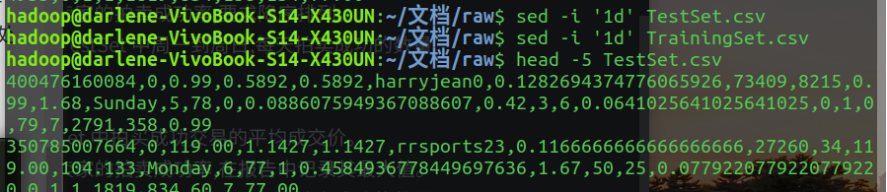
(1)删除首行
(2) 删除无意义的特征:ReturnsAccepted 是否接受退货(数据集中全为零,该特征无意义) int
3.数据分析
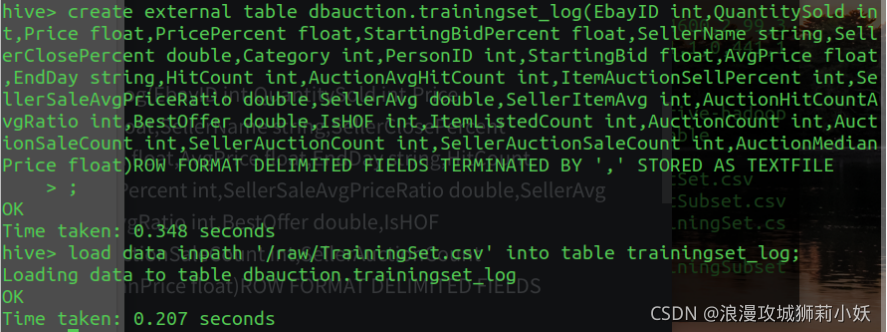
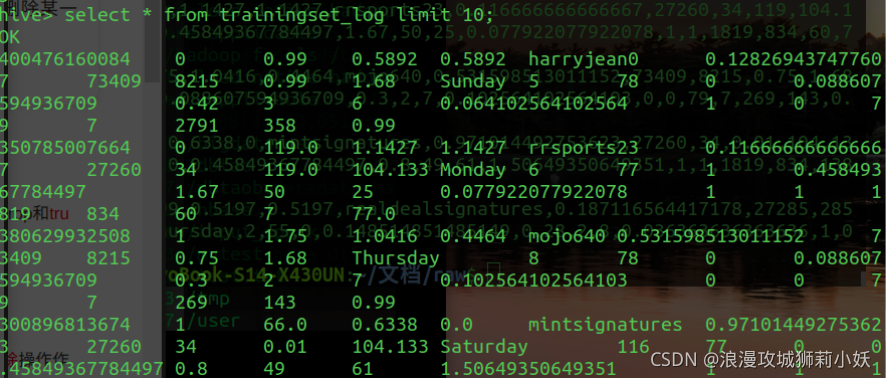
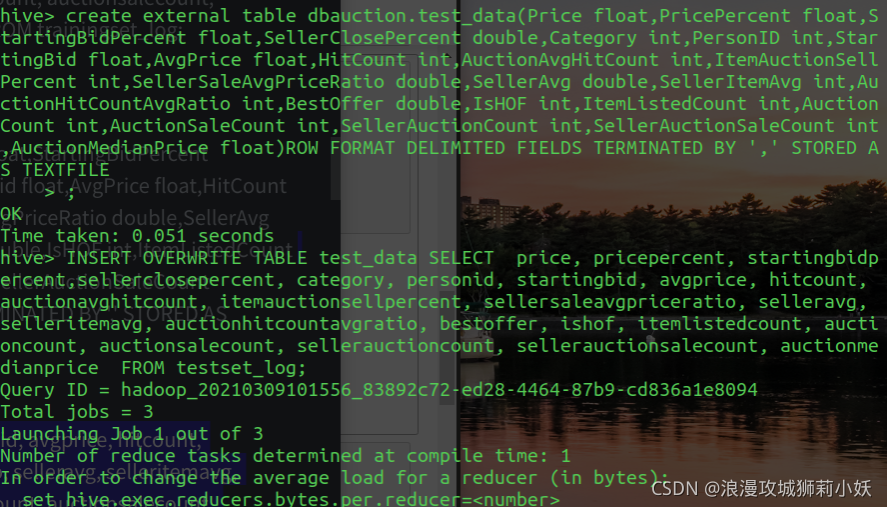
(1)在hive中建表并导入数据
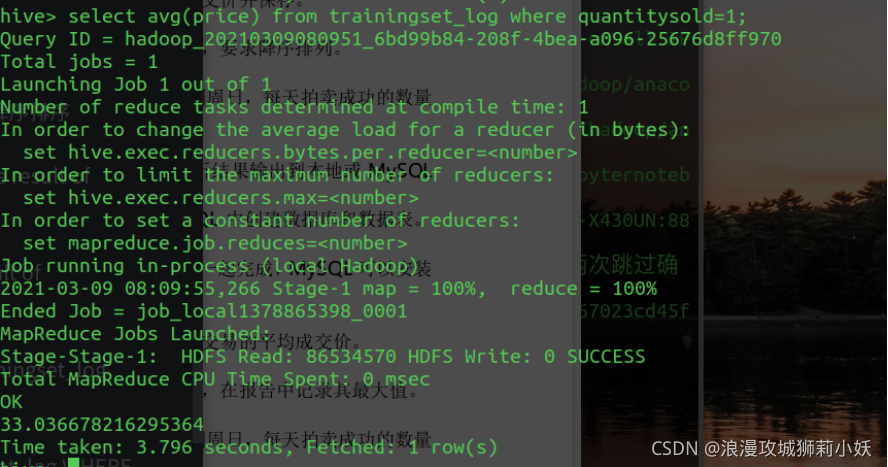
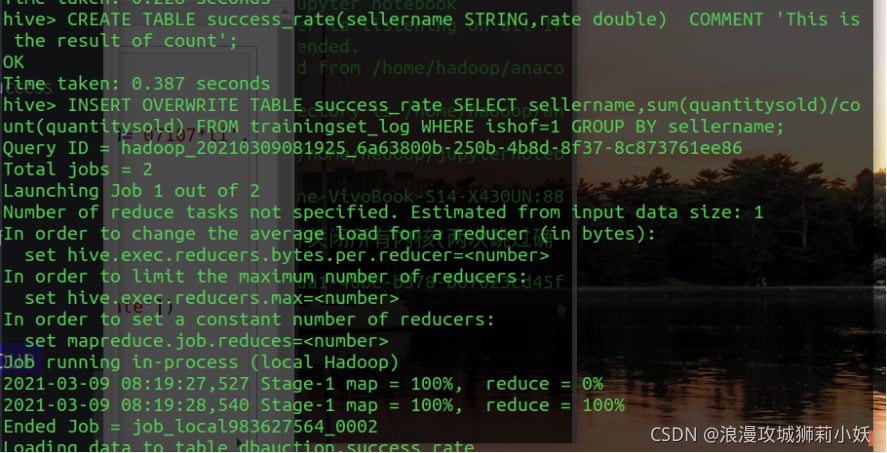
(2)统计 TrainingSet 中拍买成功交易的平均成交价并保存。
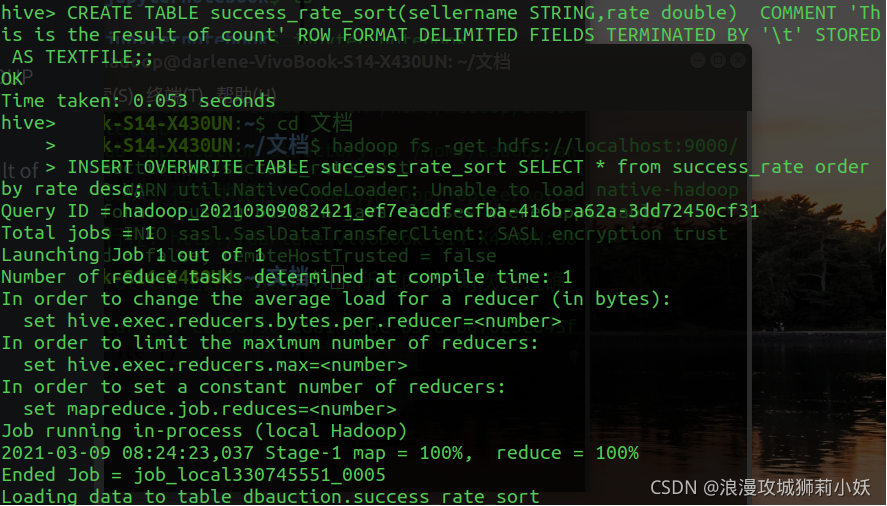
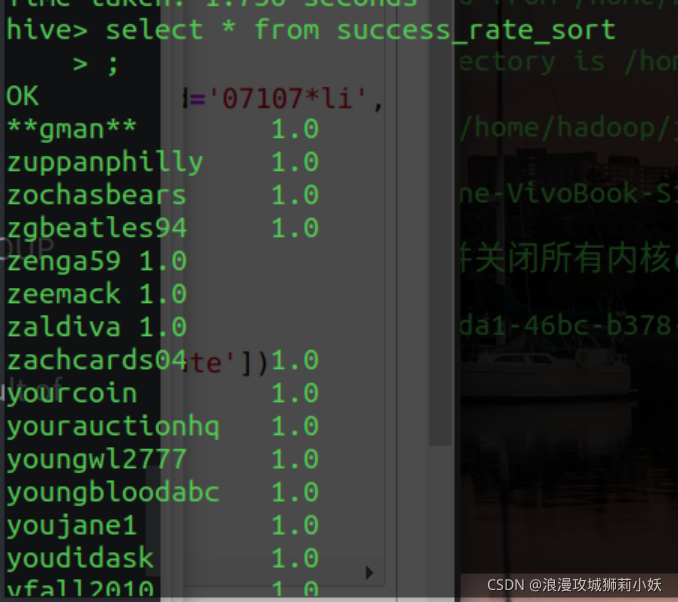
(3)统计 TrainingSet 中金牌卖家的拍卖成功率,要求降序排列。

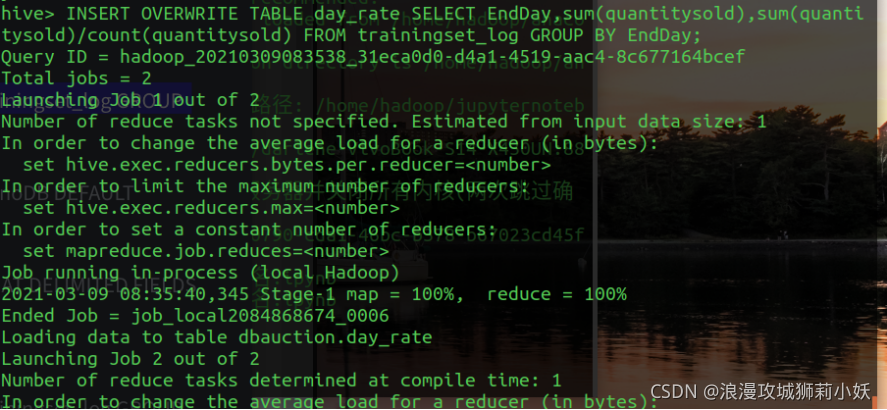
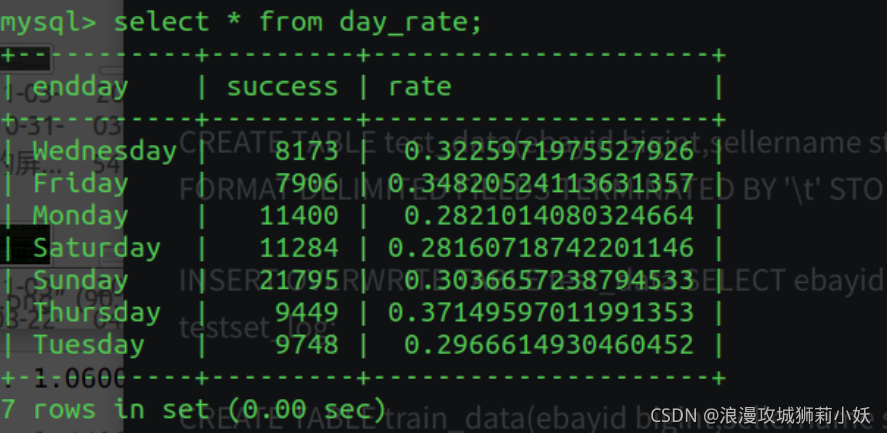
(4)分别统计 TrainingSet 和 TestSet 中周一到周日,每天拍卖成功的数量及拍卖成功率并保存。

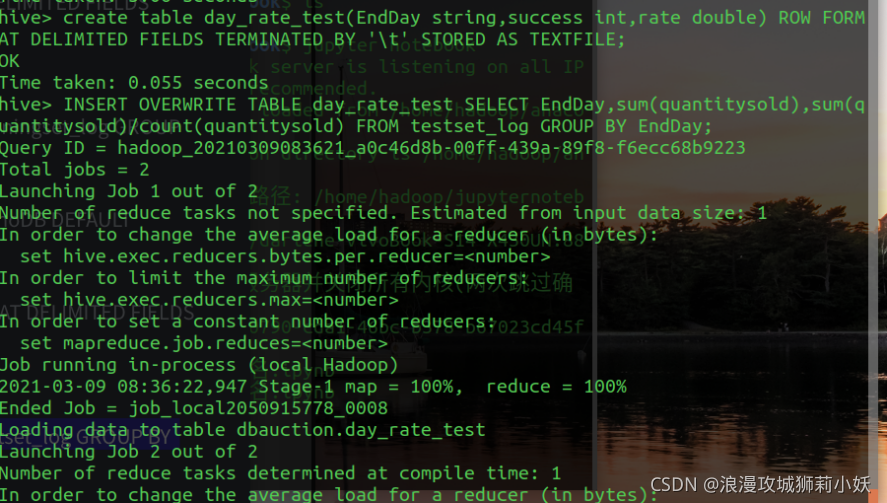
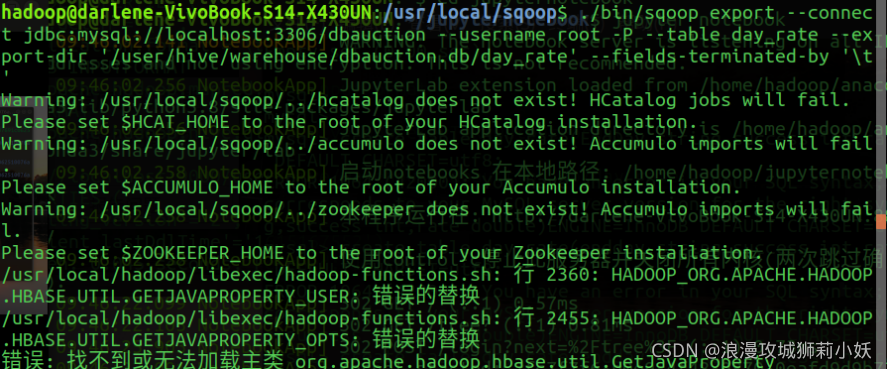
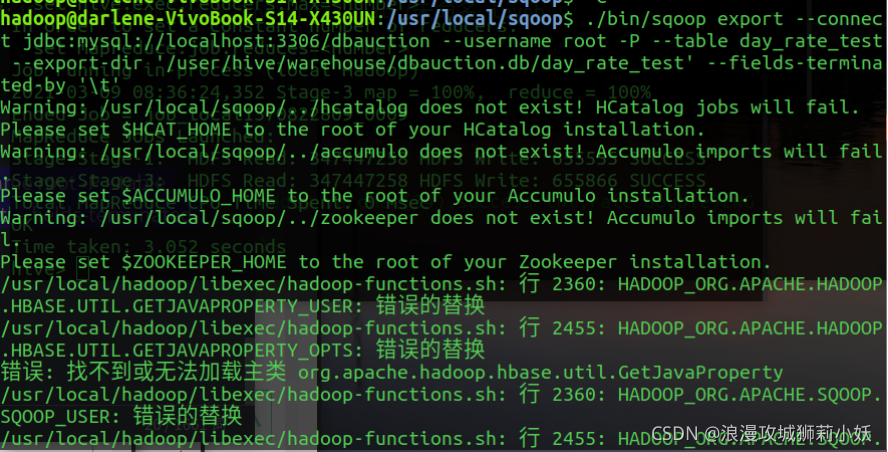
4.数据处理和导出。将 Hive 的分析结果输出到本地或 MySQL数据库中。导出到 MySQL,先在 MySQL 中创建数据库和数据表。

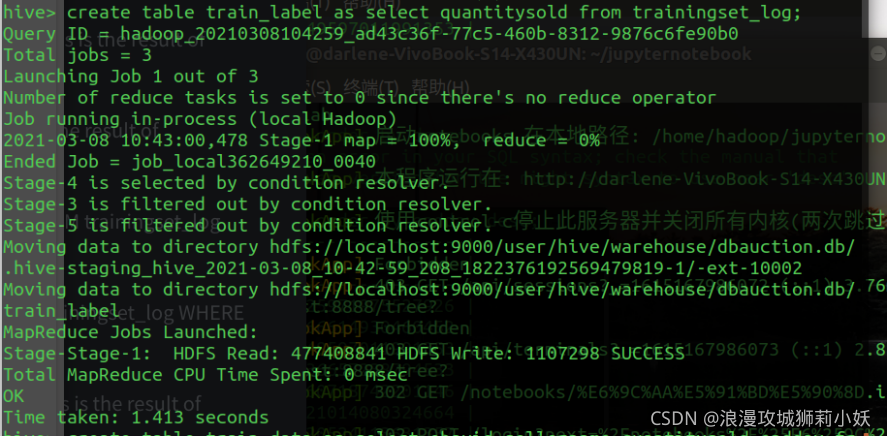
5.筛选出 TrainingSet 和 TestSet 数据中的 Quantitiysold 字段,保存为 train_label 文件和 test_label 文件。
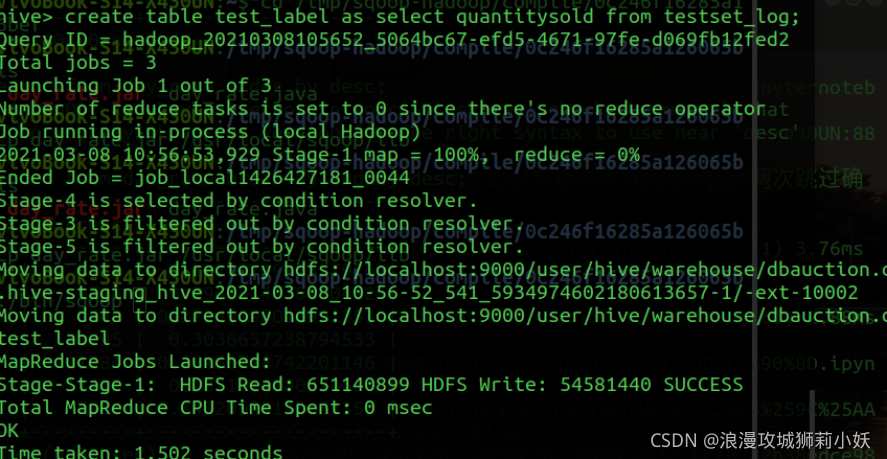
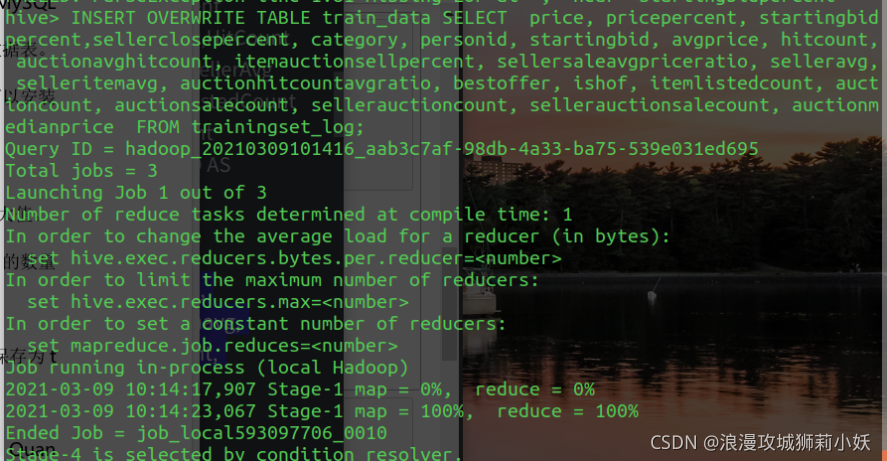
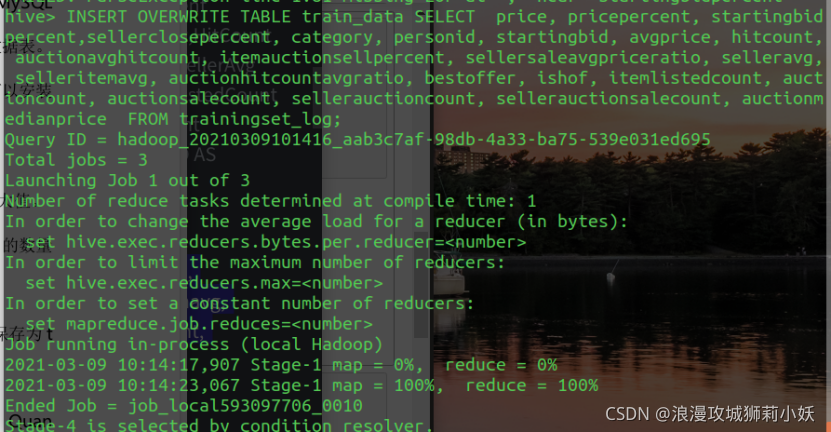
6.从 TrainingSet 和 TestSet 数据中删除的 EbayID,SellerName、QuantiySold,EndDay 字段,并将数据导出保存为 train_data 文件和 test_data 文件。
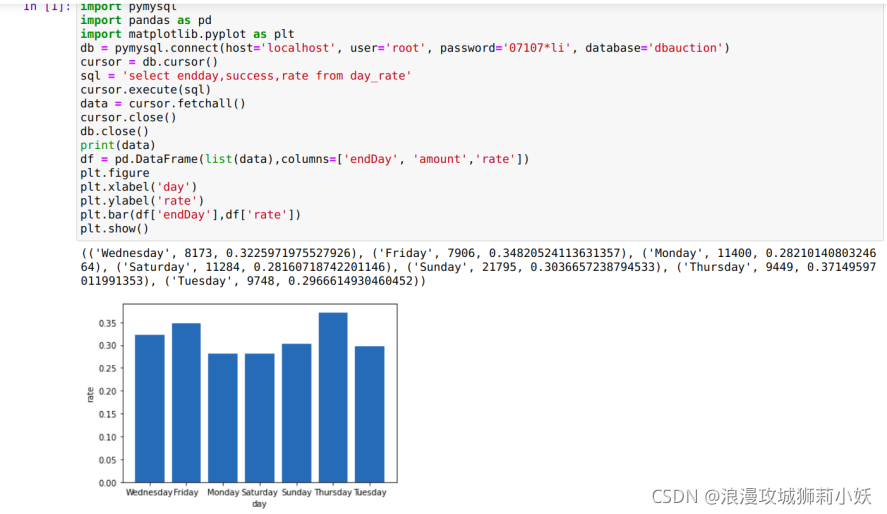
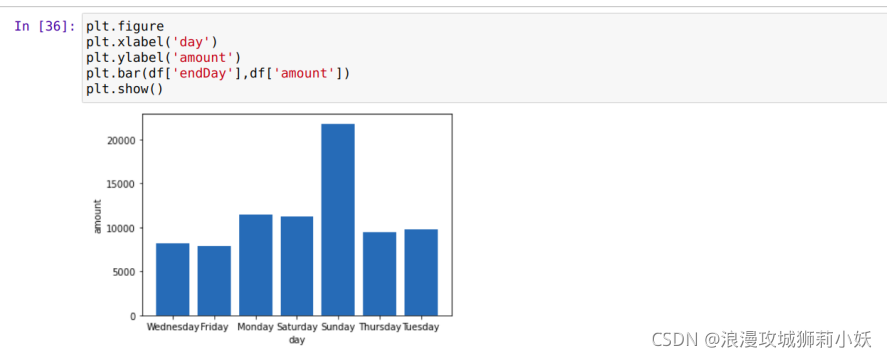
7.可视化展示:利用python 中 pandas 库的 dataframe 加载数据,再利用 matplotlib 绘制图形。绘制 Trainingset 数据中每天拍卖成功数量和拍卖成功率柱形图。TestSet数据如上。
8.利用决策树方法建立分类模型,预测每次拍卖成功与否。利用 TrainingSet 数据对该模型进行训练,并用 TestSet 数据测试该分类模型的准确率。


六、实验遇到的问题及解决办法,实验心得体会及对此实验的意见或建议。
使用sqoop将hive中的数据导入到mysql时,要将jar包导入到sqoop/lib目录下。