作业1
绘制入门案例wordcount的图解
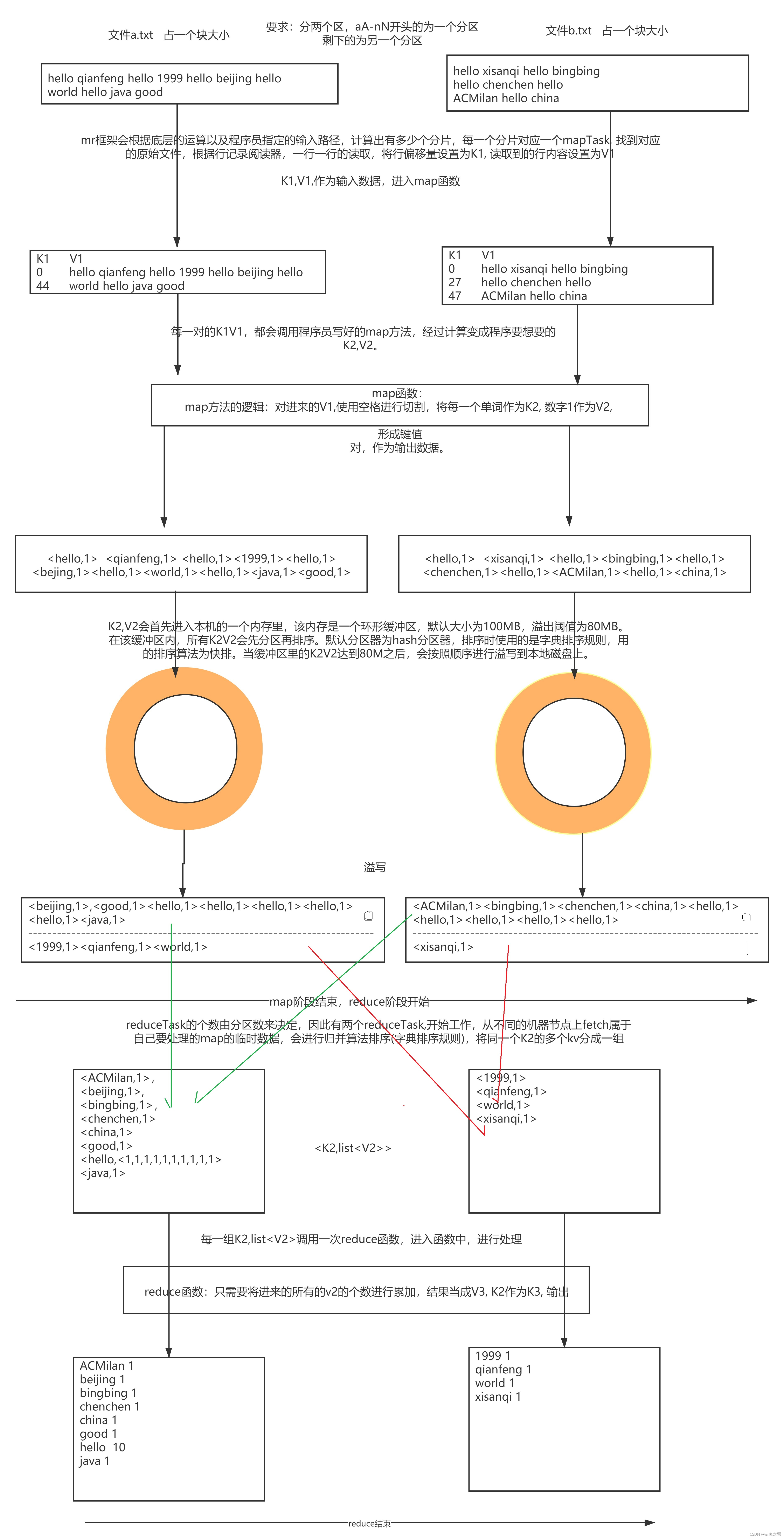
作业2:
wordcount的代码编写及其自定义分区器
- MyMapper
package com.qf.mr.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//map方法的key就是k1, 行偏移量不需要,因此不需要处理。只需要处理value,因为value就是v1,行记录
//一对k1,v1就会调用一次map函数,因此map方法执行的次数和行记录数有关系
//1: 将value的类型转为java的String类型
String line = value.toString();
//2: 使用空格对行记录进行切分成字符串数组
String[] words = line.split(" ");
//3: 遍历数组
for (String word : words) {
//要将word类型转为Text类型 ,当成k2 IntWritable类型的1作为value
Text k2 = new Text(word);
IntWritable v2 = new IntWritable(1);
//4 将k2,v2,作为输出数据写出去,写到shuffle流程中的缓存区
context.write(k2,v2);
}
}
}
- MyReducer
package com.qf.mr.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
//累加
sum+=value.get();
}
//累加的结果sum就是v3, 转成IntWritable
IntWritable v3 = new IntWritable(sum);
//k2,就是k3,写出去
context.write(key,v3);
}
}
- MyDrive
package com.qf.mr.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyDrive {
public static void main(String[] args) {
try {
Configuration conf =new Configuration();
Job job = Job.getInstance(conf);
//设置驱动类
job.setJarByClass(MyDrive.class);
//设置mapper和reducer类型
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
//设置k2,v2,k3,v3的泛型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置reduceTask的个数,默认值是1
job.setNumReduceTasks(2);
//设置自定义分区器
job.setPartitionerClass(MyPartitioner.class);
//设置mapreduce程序的输入路径和输出路径
Path inputPath = new Path("D:/test");
FileInputFormat.addInputPath(job,inputPath);
Path outPath = new Path("D:/output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
//提交等待完成
System.exit(job.waitForCompletion(true)?0:1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 自定义分区器
package com.qf.mr.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text,IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int i) {
//1: 将text类型的k2,转为String类型
String k2 = text.toString();
//截取单词的第一个字符
String firstC = k2.substring(0,1);
if(firstC.matches("[a-iA-I]")){
return 0;
}else if(firstC.matches("[j-qJ-Q]")){
return 1;
}else{
return 2;
}
}
}
作业3:数据如下:
7369,SMITH,CLERK,7902,1980-12-17,800,null,20
7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30
7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30
7566,JONES,MANAGER,7839,1981-04-02,2975,null,20
7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981-05-01,2850,null,30
7782,CLARK,MANAGER,7839,1981-06-09,2450,null,10
7788,SCOTT,ANALYST,7566,1987-04-19,3000,null,20
7839,KING,PRESIDENT,null,1981-11-17,5000,null,10
7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30
7876,ADAMS,CLERK,7788,1987-05-23,1100,null,20
7900,JAMES,CLERK,7698,1981-12-03,950,null,30
7902,FORD,ANALYST,7566,1981-12-02,3000,null,20
7934,MILLER,CLERK,7782,1982-01-23,1300,null,10
1):使用mr程序统计每年入职的人数。
最终结果要求如下:
1. 格式如下:
年份:1980 人数:xxx
年份:1981 人数:xxx
.......
2. 两个分区:
0分区存储 入职年份<1982年的
1分区存储 入职年份>=1982年的
EmpMapper代码:
package com.qf.mr.empno;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class EmpMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strings = line.split(",");
//获取年份
int year = Integer.parseInt(strings[4].substring(0, 4));
IntWritable k2 = new IntWritable(year);
IntWritable v2 = new IntWritable(1);
//写出去
context.write(k2, v2);
}
}
EmpReducer代码:
package com.qf.mr.empno;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class EmpReduce extends Reducer<IntWritable, IntWritable, Text, Text> {
Text k3 = new Text();
Text v3 = new Text();
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
k3.set("年份:"+key.get());
v3.set("人数:"+sum);
context.write(k3,v3);
}
}
EmpPartitioner代码:
package com.qf.mr.empno;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class EmpPartitioner extends Partitioner<IntWritable, IntWritable> {
@Override
public int getPartition(IntWritable intWritable, IntWritable intWritable2, int i) {
if (intWritable.get() < 1982) {
return 0;
} else {
return 1;
}
}
}
EmpDriver代码:
package com.qf.mr.empno;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EmpDriver {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//驱动
job.setJarByClass(EmpDriver.class);
//设置mapper和reducer类型
job.setMapperClass(EmpMapper.class);
job.setReducerClass(EmpReduce.class);
//设置k2,v2,k3,v3的泛型
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置reduceTask的个数,默认值是1
job.setNumReduceTasks(2);
//设置自定义分区器
job.setPartitionerClass(EmpPartitioner.class);
//设置mapreduce程序的输入路径和输出路径
FileInputFormat.addInputPath(job,new Path("D:/test"));
Path outPath = new Path("D:/output");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
System.exit(job.waitForCompletion(true)?0:1);
} catch (Exception e) {
e.printStackTrace();
}
}
}