今天给大家介绍一下Flume的多source channel sink和多Flume操作案例。
如果我们想要实现将多个数据源的数据采集到同一个地方,两种实现思路:
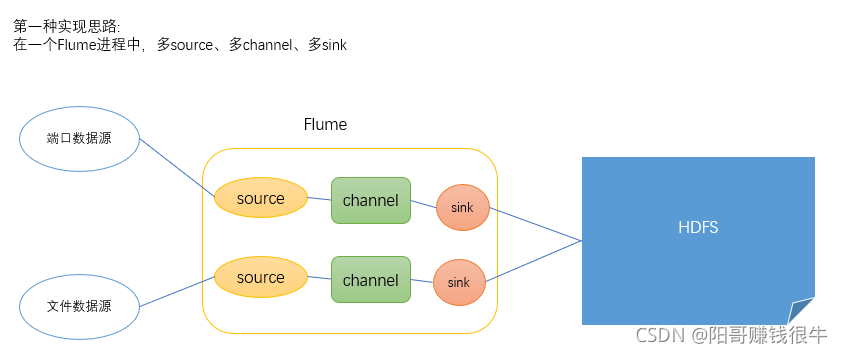
1、用一个Flume进程,但是在一个Flume进程当中有两个source、两个channel、两个sink
2、用三个Flume进程,其中前两个Flume进程分别采集端口和文件的数据,将数据发送给第三个flume,由第三个flume同一将数据采集到HDFS
一、多source、channel、sink案例
????????我们知道flume中的一个source一次只能同时连接一个数据源;一个sink一次也只能同时连接一个目的地;一个channel只能同时连接一个source、一个sink。
多数据源情况下,Flume实现数据采集的第一种方式:多个数据源一般在同一台主机上
?
# 数据源有两个 想实现一个flume采集多个数据源的数据
# 在一个flume进程中它的sources分别起的名字是什么
a1.sources = r1 r2
a1.sinks = k1 k2
a1.channels = c1 c2
# 指定source数据源连接的数据分别是什么
#先指定r1的source连接的数据源--监听文件变化
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/app/hive-2.3.8/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# 指定第二个source连接的数据源---监听端口数据的
a1.sources.r2.type = netcat
a1.sources.r2.bind = localhost
a1.sources.r2.port = 44444
#指定 文件的数据和端口的数据采集到什么地方去
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://single:9000/flume/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0
#最小冗余数
a1.sinks.k1.hdfs.minBlockReplicas = 1
#指定flume中的第二个sink
#指定 文件的数据和端口的数据采集到什么地方去
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = hdfs://single:9000/flume1/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a1.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a1.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a1.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a1.sinks.k2.hdfs.minBlockReplicas = 1
# 两个channel的数据
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# 关联一下channel sink source
# 在一个flume进程中 一个source的数据发送给多个channel 一个channel的数据必须对应一个sink去接受
a1.sources.r1.channels = c1
a1.sources.r2.channels = c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
注意:在一个flume进程中, 一个source的数据发送给多个channel ,一个channel的数据必须对应一个sink去接受。
二、多Flume操作案例
多数据源情况下,Flume实现数据采集的第二种方式:采集的数据源在不同的主机上
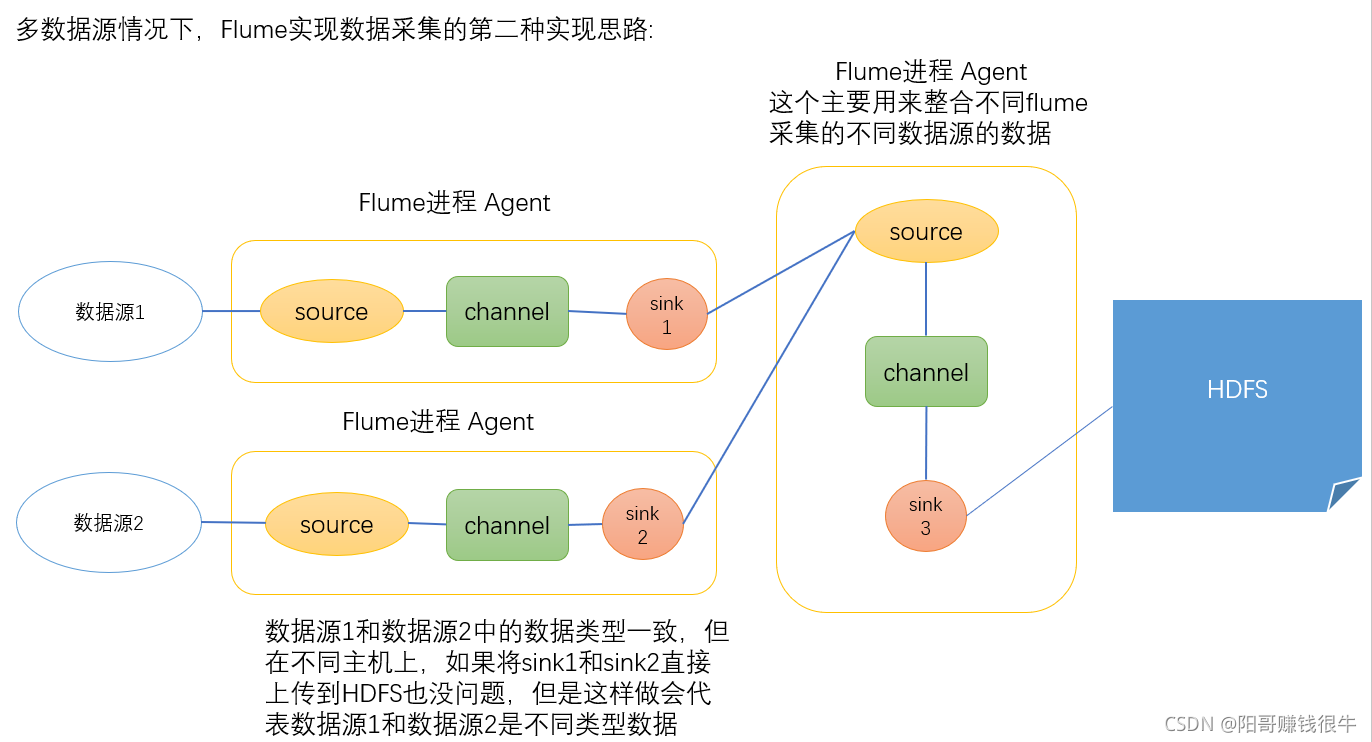
此时我们需要三份shell文件:
分别是端口数据源文件、文件数据源文件以及整合的数据源文件:
(1)端口数据源文件:(flume-port.conf)
#监听端口数据的flume进程 但是sink不是发送给HDFS的 而是给下一个Flume程序的
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 将数据发送到一个端口 由整合的flume的进程去采集这个端口的数据即可实现多个flume连接
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = single
a1.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(2)文件数据源文件:(flume-file.conf)
# 监听一个文件的数据 把监听的数据发送到一个avro的端口 由整合的flume统一采集处理
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/app/hive-2.3.8/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = avro
a2.sinks.k2.hostname = single
a2.sinks.k2.port = 4141
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
(3)整合前两个数据源的文件:(flume-inte.conf)
# 整合flume-port和flume-file传递过来的端口数据
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = single
a3.sources.r1.port = 4141
# Describe the sink
a3.sinks.k1.type = hdfs
a3.sinks.k1.hdfs.path = hdfs://single:9000/flume3/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k1.hdfs.filePrefix = flume3-
#是否按照时间滚动文件夹
a3.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a3.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k1.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k1.hdfs.minBlockReplicas = 1
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
注意:
必须先启动整合的Flume进程,再启动收集数据源1和数据源2的Flume进程(先总后分)。