一、安装 ik 分词器
官方文档
demo测试
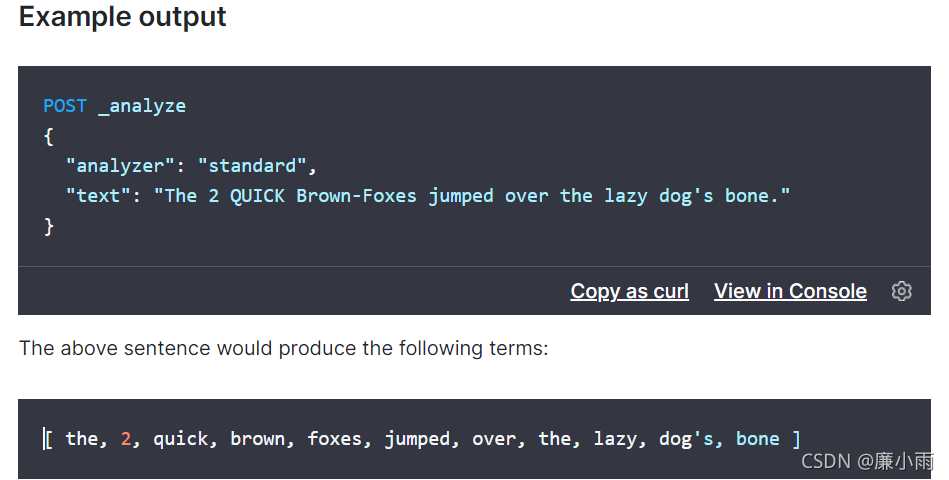
POST _analyze
{
#默认采用标准分词器 standard
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
返回结果
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "2",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<NUM>",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 12,
"end_offset" : 17,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 18,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "jumped",
"start_offset" : 24,
"end_offset" : 30,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 31,
"end_offset" : 35,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "the",
"start_offset" : 36,
"end_offset" : 39,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "lazy",
"start_offset" : 40,
"end_offset" : 44,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "dog's",
"start_offset" : 45,
"end_offset" : 50,
"type" : "<ALPHANUM>",
"position" : 9
},
{
"token" : "bone",
"start_offset" : 51,
"end_offset" : 55,
"type" : "<ALPHANUM>",
"position" : 10
}
]
}
默认支持英文的分词,中文需要下载 ik分词器,否则就会出现每一个中文字单独分开,例如
POST _analyze
{
"analyzer": "standard",
"text": "皮蛋不是蛋"
}
返回结果
{
"tokens" : [
{
"token" : "皮",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "蛋",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "不",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "是",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "蛋",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
安装步骤
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.4.2
1、进入 es 容器内部 plugins 目录
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-anal ysis-ik-7.4.2.zip

或者直接将解压后的ik分词器都放在ik包里,用 xftp将ik分词器压缩包传输进来
2、更改文件夹权限
//可读、可写、可执行
[root@localhost plugins]# chmod -R 777 ik/
查看ik包
[root@localhost ik]# ll
total 1432
-rwxrwxrwx. 1 root root 263965 Jun 17 07:02 commons-codec-1.9.jar
-rwxrwxrwx. 1 root root 61829 Jun 17 07:02 commons-logging-1.2.jar
drwxrwxrwx. 2 root root 4096 Jun 17 08:58 config
-rwxrwxrwx. 1 root root 54643 Jun 17 07:02 elasticsearch-analysis-ik-7.4.2.jar
-rwxrwxrwx. 1 root root 736658 Jun 17 07:02 httpclient-4.5.2.jar
-rwxrwxrwx. 1 root root 326724 Jun 17 07:02 httpcore-4.4.4.jar
-rwxrwxrwx. 1 root root 1805 Jun 17 07:02 plugin-descriptor.properties
-rwxrwxrwx. 1 root root 125 Jun 17 07:02 plugin-security.policy
[root@localhost ik]#
进入控制台,到容器内部,也会查看到有ik分词器包
[root@localhost plugins]# docker exec -it fe709eb23b01 /bin/bash
[root@fe709eb23b01 elasticsearch]# ls
LICENSE.txt NOTICE.txt README.textile bin config data jdk lib logs modules plugins
[root@fe709eb23b01 elasticsearch]# cd plugins/
[root@fe709eb23b01 plugins]# ls
ik
[root@fe709eb23b01 plugins]#
查看是否安装成功ik分词器
[root@fe709eb23b01 elasticsearch]# cd bin
[root@fe709eb23b01 bin]# ls
elasticsearch elasticsearch-env elasticsearch-plugin elasticsearch-sql-cli-7.4.2.jar x-pack-watcher-env
elasticsearch-certgen elasticsearch-enve elasticsearch-saml-metadata elasticsearch-syskeygen
elasticsearch-certutil elasticsearch-keystore elasticsearch-setup-passwords elasticsearch-users
elasticsearch-cli elasticsearch-migrate elasticsearch-shard x-pack-env
elasticsearch-croneval elasticsearch-node elasticsearch-sql-cli x-pack-security-env
[root@fe709eb23b01 bin]# elasticsearch-plugin list
ik
[root@fe709eb23b01 bin]# pwd
/usr/share/elasticsearch/bin
[root@fe709eb23b01 bin]#
二、测试ik分词器
没安装ik分词器之前,默认是用 standard分词器,中文会被拆分成每一个单独的汉字,安装ik后,可以用ik_smart 和 ik_max_word,会自动分词
ik_smart
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
返回结果
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
ik_max_word
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
返回结果
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
三、自定义分词
有的词语被ik分词器收集到词库了,有的没有就会被拆分成单独的词,如何自定义分词呢
详细分词流程参考
https://blog.csdn.net/weixin_40964170/article/details/117996289