Fork/Join
jdk�����ṩThreadPoolExecutor�������̳߳�,���ṩ��ForkJoinPool,����˼��,��fork,��join,�ȷֽ�����,��������������,�ٺϲ�,���á����Ρ���˼��
����,�ֶ���֮����һ�����ӵ�����ֽ�ɶ�����Ƶ�������,Ȼ���ٰ�������ֽ�ɸ�С��������,ֱ�������������ֱ�����
��鲢����,��������,���ֲ��Ҷ����ڷ�֧�㷨,�Լ����������������MapReduceͬ�������˷���˼��
��������ģ��
-
����ķֽ�
��������ֽ����ֱ�Ӽ�����������
-
����ĺϲ�
�����ϲ��������ִ�н��
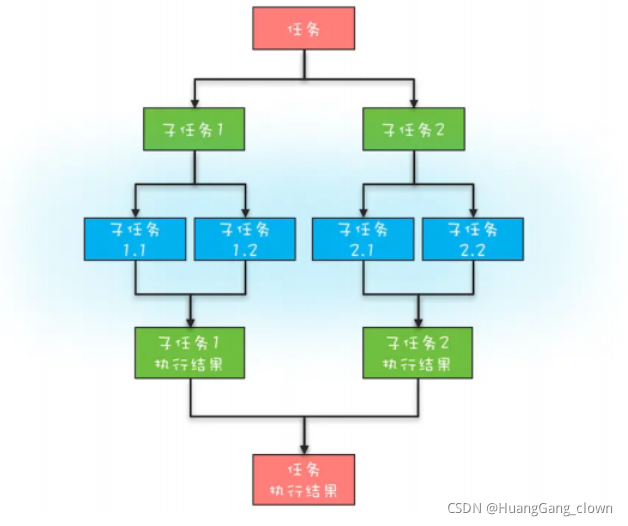
Fork/Join��ʹ��
Fork/Join ��֧�ַ�������ģ�͵IJ��м����ܡ�
Fork��Ӧ��������ģ���������ֽ�,Join��Ӧ���ǽ���ϲ���
Fork/Join��ܰ���ForkJoinPool��ForkJoinTask,
ForkJoinTask��abstract��,���ķ�����fork()��join(),fork()�첽��ִ��һ��������,join()��������ǰ�̵߳ȴ��������ִ�н����
RecursiveAction��RecursiveTask��ForkJoinTask��abstract����,����ʹ��Fork/Joinʱ,ͨ���Ǽ̳�ǰ��,����compute()ʵ�ֲ��м���������� RecursiveAction#compute()����ֵ,RecursiveTask#compute()�з���ֵ
public class FibonacciTask extends RecursiveTask<Integer> {
private Integer n;
public FibonacciTask(Integer n) {
this.n = n;
}
@Override protected Integer compute() {
if (n <= 1) {
return n;
}
FibonacciTask task1 = new FibonacciTask(n-1);
task1.fork();
FibonacciTask task2 = new FibonacciTask(n-2);
// compute() �� join() ��˳���ܽ���,task1.join() �����ǰ�̵߳ȴ��ϲ�����ִ�����,
// ����task2.compute()����ִ��,���²��ж��½�
return task2.compute() + task1.join();
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
RecursiveTask<Integer> task = new FibonacciTask(10);
forkJoinPool.submit(task);
System.out.println(task.get());
}
}
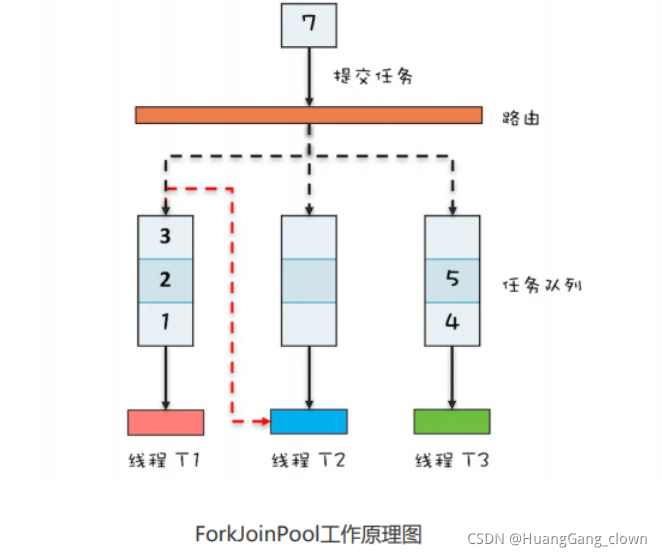
������֪,ThreadPoolExecutor�ڲ�ʹ��һ������������������,��ForkJoinPool�ڲ�ʹ���˶��������С���ʹ��ForkJoinPool#invoke()��ForkJoinPool#submit() �ύ����ʱ,ͨ��һ����·�ɹ����ύ��ij��������С������߱����϶��ǡ�������-������ģʽ����ʵ��
���������ִ�й����лᴴ��������,������Ҳ���ύ�������̶߳�Ӧ�����������
Fork/Join֧�֡�������ȡ���Ļ���,�����̶߳�Ӧ�Ĺ�������Ϊ��ʱ,���ԡ���ȡ���������������е�����,���ϲ�������ĸ�Ч�ʡ��������������˫�˶���,�����߳�����ִ������͡���ȡ������ֱ��������еIJ�ͬ�˻�ȡ
ģ��MapReduceͳ�Ƶ�������
/**
* @version 1.0.0
* @description ͳ�������е��ʳ��ֵĴ���
* @date 2021/9/1 12:35
*/
public class MapReduceTask extends RecursiveTask<Map<String, Integer>> {
private String[] data;
private int start;
private int end;
public MapReduceTask(String[] data, int start, int end) {
this.data = data;
this.start = start;
this.end = end;
}
@Override protected Map<String, Integer> compute() {
if (end - start <= 1) {
return countWords(data[start]);
}
int mid = (start + end)/2;
MapReduceTask task1 = new MapReduceTask(data, start, mid);
task1.fork();
MapReduceTask task2 = new MapReduceTask(data, mid, end);
return merge(task2.compute(), task1.join());
}
private Map<String, Integer> countWords(String line) {
String[] wordsPerRow = line.split(" ");
Map<String, Integer> result = new HashMap<>(wordsPerRow.length);
Arrays.stream(wordsPerRow).forEach(str -> {
Integer sum = result.get(str);
if (sum == null) {
result.put(str, 1);
} else {
result.put(str, sum + 1);
}
});
return result;
}
private Map<String, Integer> merge(Map<String, Integer> source, Map<String, Integer> target) {
Map<String, Integer> result = new HashMap<>();
result.putAll(source);
target.forEach( (k, v)-> {
Integer count = result.get(k);
if (count != null) {
result.put(k, count + v);
} else {
result.put(k, v);
}
});
return result;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
String[] data = {
"source target merge result", "source target merge result", "one two three", "one two second",
"import java util concurrent RecursiveTask", "import java util concurrent RecursiveTask",
"import java util concurrent RecursiveTask", "import java util concurrent RecursiveTask hg"
};
MapReduceTask task = new MapReduceTask(data, 0, data.length);
Map<String, Integer> result = forkJoinPool.invoke(task);
result.forEach((k, v) -> System.out.println(String.format("[%s = %s]", k, v)));
}
}
jdk8 ��stream�������ļ��㹲����ϵͳ�ṩ��һ��ForkJoinPool,�߳���Ĭ����CPU�ĺ���,������������㶼��CPU�ܼ���,����û������,�������I/O�ܼ��͵IJ���������,�ܿ��ܻ���Ϊһ��������I/O�������������ϵͳ�����ܡ�
����ʹ�ò�ͬ��ForkJoinPoolִ�в�ͬ���͵ļ���������