shardingsphere源码分析(五)-- 执行引擎
shardingsphere源码分析(五)-- 执行引擎
官方介绍
链接如下:
https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/execute/
ShardingSphere 采用一套自动化的执行引擎,负责将路由和改写完成之后的真实 SQL 安全且高效发送到底层数据源执行。 它不是简单地将 SQL 通过 JDBC 直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率。
- 连接模式
- 内存限制模式
使用此模式的前提是,ShardingSphere 对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的 SQL 需要对某数据库实例中的 200 张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。 并且在 SQL 满足条件情况下,优先选择流式归并,以防止出现内存溢出或避免频繁垃圾回收情况。 - 连接限制模式
使用此模式的前提是,ShardingSphere 严格控制对一次操作所耗费的数据库连接数量。 如果实际执行的 SQL 需要对某数据库实例中的 200 张表做操作,那么只会创建唯一的数据库连接,并对其 200 张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。 这样即可以防止对一次请求对数据库连接占用过多所带来的问题。该模式始终选择内存归并。
- 内存限制模式
内存限制模式适用于 OLAP 操作,可以通过放宽对数据库连接的限制提升系统吞吐量; 连接限制模式适用于 OLTP 操作,OLTP 通常带有分片键,会路由到单一的分片,因此严格控制数据库连接,以保证在线系统数据库资源能够被更多的应用所使用,是明智的选择。
- 自动化执行引擎
ShardingSphere 最初将使用何种模式的决定权交由用户配置,让开发者依据自己业务的实际场景需求选择使用内存限制模式或连接限制模式。
这种解决方案将两难的选择的决定权交由用户,使得用户必须要了解这两种模式的利弊,并依据业务场景需求进行选择。 这无疑增加了用户对 ShardingSphere 的学习和使用的成本,并非最优方案。
为了降低用户的使用成本以及连接模式动态化这两个问题,ShardingSphere 提炼出自动化执行引擎的思路,在其内部消化了连接模式概念。 用户无需了解所谓的内存限制模式和连接限制模式是什么,而是交由执行引擎根据当前场景自动选择最优的执行方案。
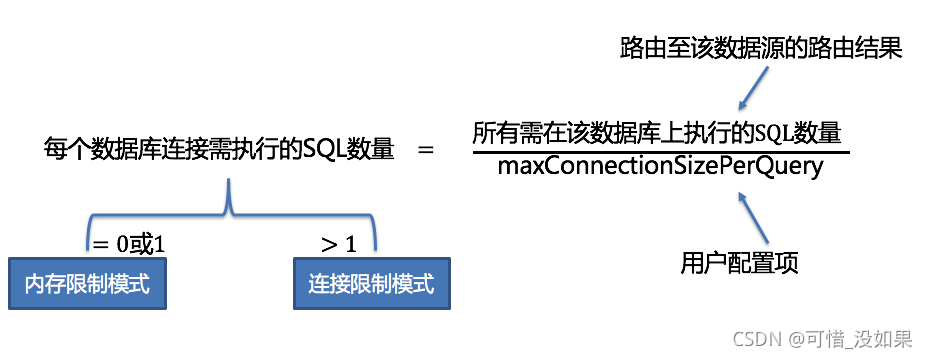
自动化执行引擎将连接模式的选择粒度细化至每一次 SQL 的操作。 针对每次 SQL 请求,自动化执行引擎都将根据其路由结果,进行实时的演算和权衡,并自主地采用恰当的连接模式执行,以达到资源控制和效率的最优平衡。 针对自动化的执行引擎,用户只需配置 max-connections-size-per-query 即可,该参数表示一次查询时每个数据库所允许使用的最大连接数。
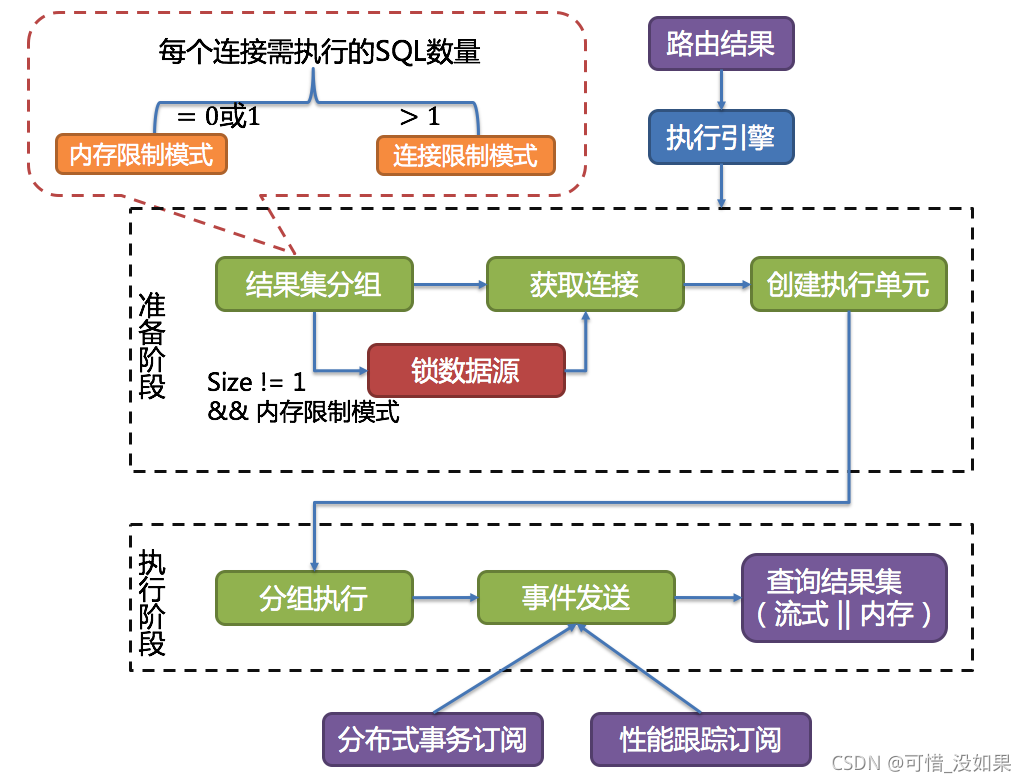
执行引擎分为准备和执行两个阶段。- 准备阶段
顾名思义,此阶段用于准备执行的数据。它分为结果集分组和执行单元创建两个步骤。 - 执行阶段
该阶段用于真正的执行 SQL,它分为分组执行和归并结果集生成两个步骤。
- 准备阶段
执行引擎的整体结构划分如下图所示。
debug
修改examples/shardingsphere-jdbc-example/sharding-example/sharding-raw-jdbc-example/src/main/resources/sharding-databases.yaml 配置
props:
sql-show: true #打印sql
max-connections-size-per-query: 2 #一次查询时每个数据库所允许使用的最大连接数。
运行examples/shardingsphere-jdbc-example/sharding-example/sharding-raw-jdbc-example/src/main/java/org/apache/shardingsphere/example/sharding/raw/jdbc/YamlRangeConfigurationExampleMain.java
启动后,会根据我们配置的 max-connections-size-per-query 来设置每个数据库的最大连接数
然后是熟悉的类,执行完路由和改写之后,就会执行sql
// KernelProcessor.jva
public ExecutionContext generateExecutionContext(LogicSQL logicSQL, ShardingSphereMetaData metaData, ConfigurationProperties props) {
// 路由
RouteContext routeContext = this.route(logicSQL, metaData, props);
// 改写
SQLRewriteResult rewriteResult = this.rewrite(logicSQL, metaData, props, routeContext);
// 执行
ExecutionContext result = this.createExecutionContext(logicSQL, metaData, routeContext, rewriteResult);
// 打印sql
this.logSQL(logicSQL, props, result);
return result;
}
private void logSQL(LogicSQL logicSQL, ConfigurationProperties props, ExecutionContext executionContext) {
// 判断配置文件里的sql打印开关是否打开
if ((Boolean)props.getValue(ConfigurationPropertyKey.SQL_SHOW)) {
// 打印sql
SQLLogger.logSQL(logicSQL, (Boolean)props.getValue(ConfigurationPropertyKey.SQL_SIMPLE), executionContext);
}
}
打印的sql 如下

生成 ExecutionContext 后,会调用执行引擎的 execute 函数
// ExecutorEngine.java
public <I, O> List<O> execute(ExecutionGroupContext<I> executionGroupContext, ExecutorCallback<I, O> firstCallback, ExecutorCallback<I, O> callback, boolean serial) throws SQLException {
if (executionGroupContext.getInputGroups().isEmpty()) {
return Collections.emptyList();
} else {
// 判断是串行执行还是并行执行
// JDBCExecutor里serial的默认值是false,所以执行引擎默认是并行执行
return serial ? this.serialExecute(executionGroupContext.getInputGroups().iterator(), firstCallback, callback) : this.parallelExecute(executionGroupContext.getInputGroups().iterator(), firstCallback, callback);
}
}
private <I, O> List<O> parallelExecute(Iterator<ExecutionGroup<I>> executionGroups, ExecutorCallback<I, O> firstCallback, ExecutorCallback<I, O> callback) throws SQLException {
ExecutionGroup<I> firstInputs = (ExecutionGroup)executionGroups.next();
// 异步执行
Collection<ListenableFuture<Collection<O>>> restResultFutures = this.asyncExecute(executionGroups, callback);
return this.getGroupResults(this.syncExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}
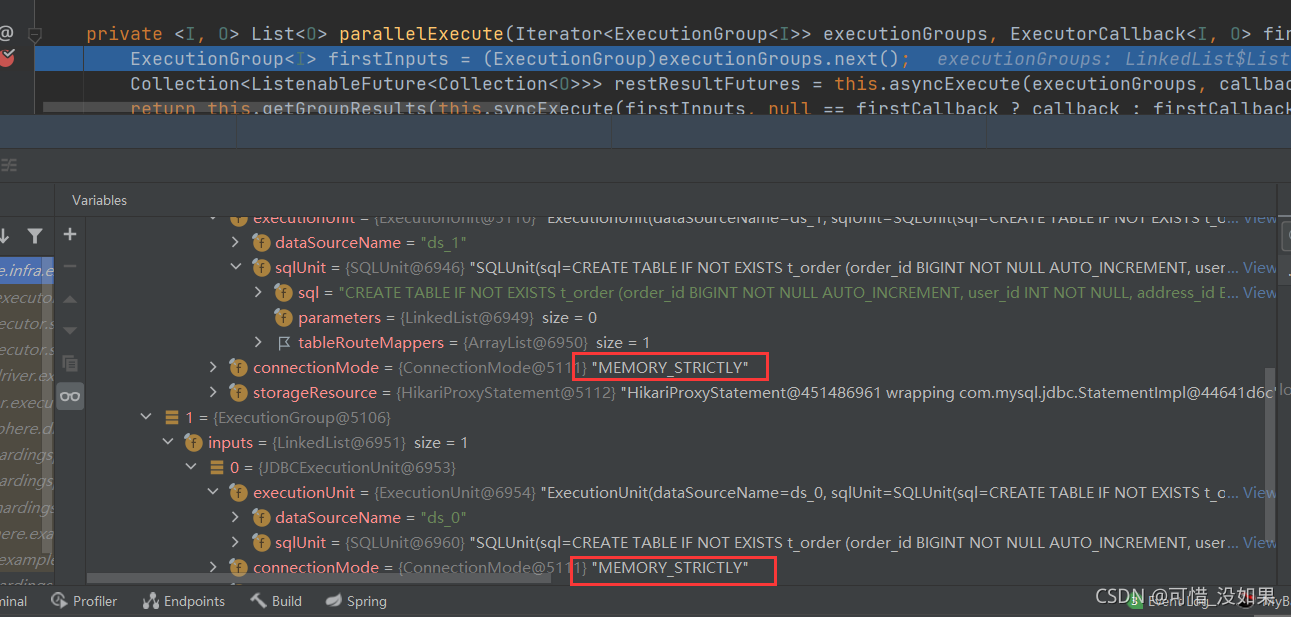
通过debug信息可以看到,这条sql的连接模式是内存限制模式
我们找下设置连接模式的地方
// AbstractExecutionPrepareEngine.java
public final ExecutionGroupContext<T> prepare(RouteContext routeContext, Collection<ExecutionUnit> executionUnits) throws SQLException {
...
ConnectionMode connectionMode = this.maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
...
}
文档里是这么写的:
可以获得每个数据库实例在 maxConnectionSizePerQuery 的允许范围内,每个连接需要执行的 SQL 路由结果组,并计算出本次请求的最优连接模式。
这里就是执行完成的地方,建表语句,返回的结果是两个0(因为建表影响行数为0)
// JDBCLockEngine.java
private <T> List<T> doExecute(ExecutionGroupContext<JDBCExecutionUnit> executionGroupContext, Collection<RouteUnit> routeUnits, JDBCExecutorCallback<T> callback, SQLStatement sqlStatement) throws SQLException {
List<T> results = this.jdbcExecutor.execute(executionGroupContext, callback);
this.refreshMetadata(sqlStatement, routeUnits);
return results;
}

我们可以看到数据库里表也已经创建完成了
总结
max-connections-size-per-query是默认值是1,一般这个值不要设置太大,和数据库连接数一样,10-30就差不多了,最多不要超过100,毕竟太多连接消耗资源,执行效率反而不高。