文章目录
避免索引失效
先创建复合索引
create index idx_seller_name_sta_addr on tb_seller(name,status,address);
-
全值匹配 ,对索引中所有列都指定具体值。该情况下,索引生效,执行效率高。
-
最左前缀法则,如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列。
-
违法最左前缀法则 , 索引失效
-
如果符合最左法则,但是出现跳跃某一列,只有最左列索引生效
-
范围查询右边的列,不能使用索引 。范围查询条件之后的字段,索引失效
-
不要在索引列上进行运算操作, 索引将失效。
-
字符串不加单引号,造成索引失效。
由于,在查询时,没有对字符串加单引号,MySQL的查询优化器,会自动的进行类型转换,造成索引失
效。
- 尽量使用覆盖索引,避免select *
尽量使用覆盖索引(只访问索引的查询(索引列完全包含查询列)),减少select * 。 - 如果查询列,超出索引列,也会降低性能。(需要回表查询)
对extra列的说明:
using index :使用覆盖索引的时候就会出现
using where:在查找使用索引的情况下,需要回表去查询所需的数据
using index condition:查找使用了索引,但是需要回表查询数据
using index ; using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查
询数据
- 用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用
到。 - 以%开头的Like模糊查询,索引失效。
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。 - 如果MySQL评估使用索引比全表更慢,则不使用索引。
- is NULL , is NOT NULL 有时 索引失效。
- in 走索引, not in 索引失效。
- 单列索引和复合索引。
- 尽量使用复合索引,而少使用单列索引。
SQL优化
大批量插入数据
当使用load命令导入数据时,适当的设置可以提高导入的效率。对于 InnoDB 类型的表,有以下几种方式可以提高导入的效率:
①按主键顺序插入:
因为InnoDB类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有
效的提高导入数据的效率。如果InnoDB表没有主键,那么系统会自动默认创建一个内部列作为主
键,所以如果可以给表创建一个主键,将可以利用这点,来提高导入数据的效率。
②关闭唯一性校验:
在导入数据前执行 SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入结束后执行SET
UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。
③手动提交事务:
如果应用使用自动提交的方式,建议在导入前执行 SET AUTOCOMMIT=0,关闭自动提交,导入结束
后再执行 SET AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
优化insert语句
- 如果需要同时对一张表插入很多行数据时,应该尽量使用多个值表的insert语句,这种方式将大大的缩减
客户端与数据库之间的连接、关闭等消耗。使得效率比分开执行的单个insert语句快。
原始方式为:
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
优化后为:
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
- 在事务中进行数据插入。
start transaction;
insert into tb_test values(1,'Tom');
insert into tb_test values(2,'Cat');
insert into tb_test values(3,'Jerry');
commit;
- 数据有序插入
优化order by语句
排序方式有两种:第一种是通过对返回数据进行排序,也就是通常说的 filesort 排序,所有不是通过索引直接返回排序
结果的排序都叫 FileSort 排序。效率低。第二种通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
了解了MySQL的排序方式,优化目标就清晰了:尽量减少额外的排序,通过索引直接返回有序数据
(using index)。where 条件和Order by 使用相同的索引,并且Order By 的顺序和索引顺序相同, 并
且Order by 的字段都是升序,或者都是降序。否则肯定需要额外的操作,这样就会出现FileSort。
Filesort 的优化:通过创建合适的索引,能够减少 Filesort 的出现,但是在某些情况下,条件限制不能让Filesort消失,那
就需要加快 Filesort的排序操作。 对于Filesort , MySQL 有两种排序算法:
- 两次扫描算法 :MySQL4.1 之前,使用该方式排序。首先根据条件取出排序字段和行指针信息,然后
在排序区 sort buffer 中排序,如果sort buffer不够,则在临时表 temporary table 中存储排序结果。完成排
序之后,再根据行指针回表读取记录,该操作可能会导致大量随机I/O操作。 - 一次扫描算法:一次性取出满足条件的所有字段,然后在排序区 sort buffer 中排序后直接输出结果
集。排序时内存开销较大,但是排序效率比两次扫描算法要高。
MySQL 通过比较系统变量 max_length_for_sort_data 的大小和Query语句取出的字段总大小, 来判定
是否那种排序算法,如果max_length_for_sort_data 更大,那么使用第二种优化之后的算法;否则使用第
一种。
可以适当提高 sort_buffer_size 和 max_length_for_sort_data 系统变量,来增大排序区的大小,
提高排序的效率。
优化group by 语句
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之
后的分组操作。当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计
算。所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引。
- 如果查询包含 group by 但是用户想要避免排序结果的消耗, 则可以执行order by null 禁止排序 。
优化嵌套查询
Mysql4.1版本之后,开始支持SQL的子查询。这个技术可以使用SELECT语句来创建一个单列的查询
结果,然后把这个结果作为过滤条件用在另一个查询中。使用子查询可以一次性的完成很多逻辑上
需要多个步骤才能完成的SQL操作,同时也可以避免事务或者表锁死,并且写起来也很容易。但
是,有些情况下,子查询是可以被更高效的连接(JOIN)替代。
select * from t_user where id in (select user_id from user_role );可以优化为:select * from t_user u , user_role ur where u.id = ur.user_id;
连接(Join)查询之所以更有效率一些 ,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上
需要两个步骤的查询工作。
优化OR条件
对于包含OR的查询子句,如果要利用索引,则OR之间的每个条件列都必须用到索引 , 而且不能使用到复合索
引; 如果没有索引,则应该考虑增加索引。
type 显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >
unique_subquery > index_subquery > range > index > ALL
UNION 语句的 type 值为 ref,OR 语句的 type 值为 range,可以看到这是一个很明显的差距
UNION 语句的 ref 值为 const,OR 语句的 type 值为 null,const 表示是常量值引用,非常快
优化分页查询
优化思路一:在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
优化思路二:该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询 。 (局限性:主键不能断层)
使用SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达
到优化操作的目的。
- USE INDEX
- IGNORE INDEX
- FORCE INDEX
SQL执行顺序
编写顺序:
SELECT DISTINCT
<select list>
FROM
<left_table> <join_type>
JOIN
<right_table> ON <join_condition>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
ORDER BY
<order_by_condition>
LIMIT
<limit_params>
执行顺序:
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT DISTINCT <select list>
ORDER BY <order_by_condition>
LIMIT <limit_params>
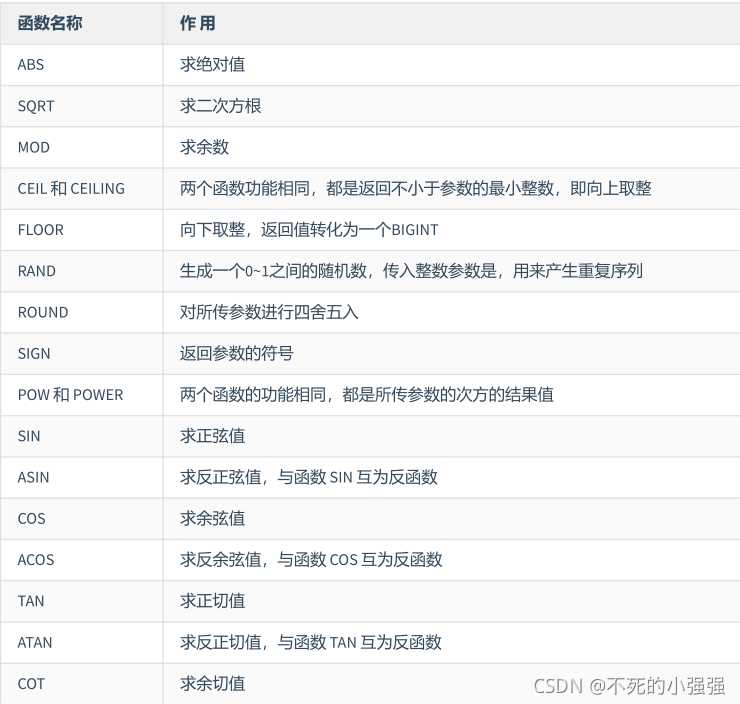
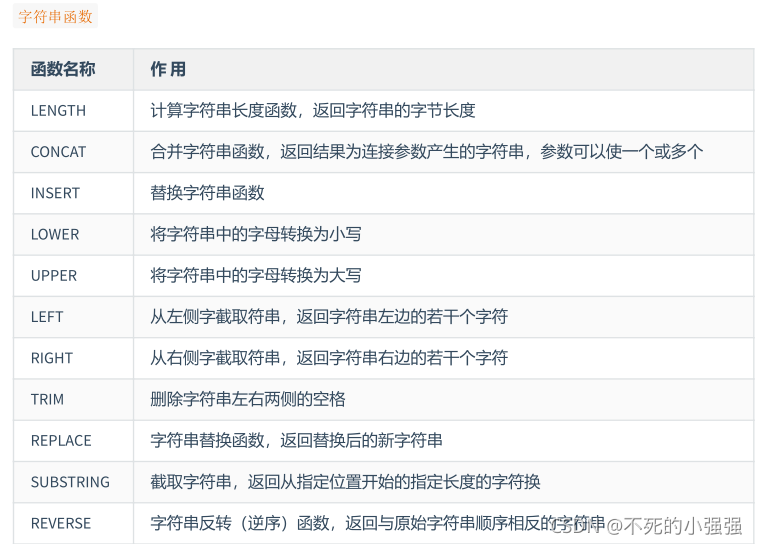
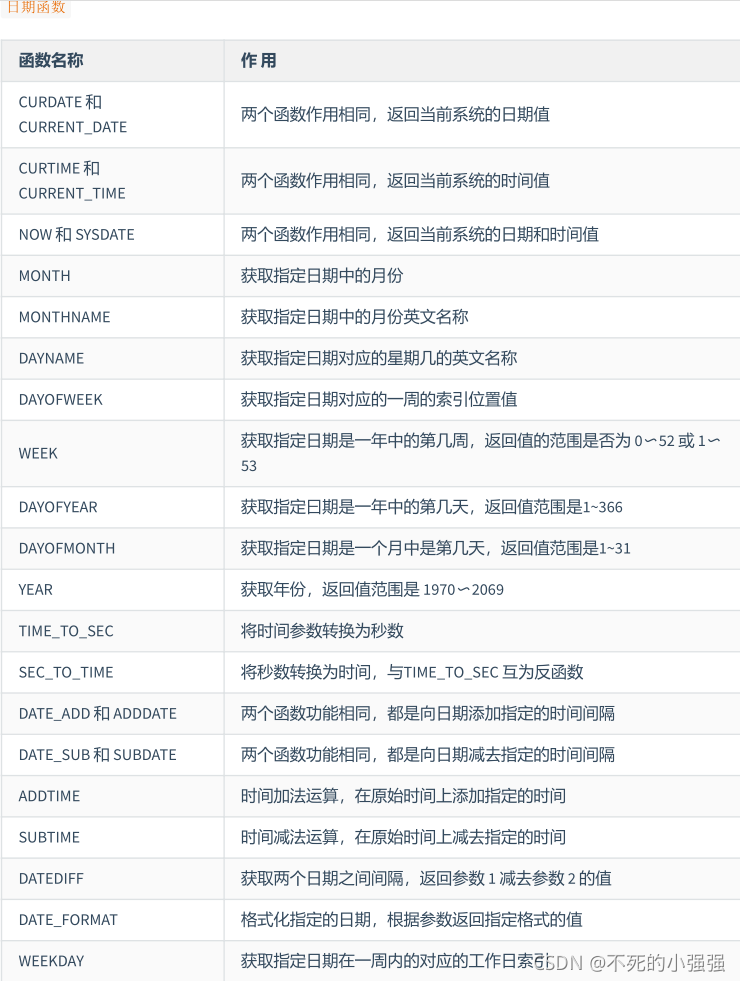
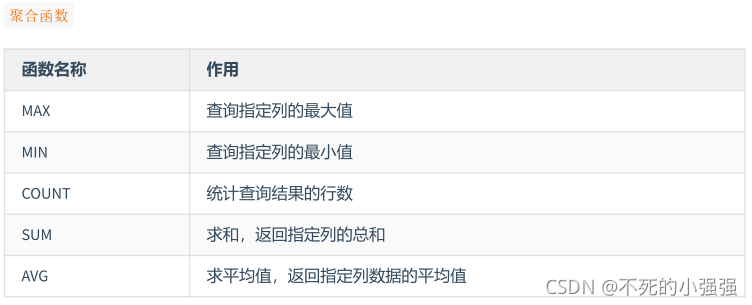
MySQL常用函数