ИааЛФњЕФаЁАЎаФ(ЙизЂ ?+ ?Еудо + дйПД),ЖдВЉжїЕФПЯЖЈ,ЛсЖНДйВЉжїГжајЕФЪфГіИќЖрЕФгХжЪЪЕеНФкШн!!!

1.ађЦЊ-БОЮФНсЙЙ
ЧАУцЕФеТНкЦЬЕцСЫФЧУДЖр,жегкдкБОНкзпШывЛЬѕ query СЫЁЃ
еыЖд datastream api ДѓМвЖМБШНЯЪьЯЄСЫ,ЛЙЪЧФЧОфЛА,дк datastream жа,ФуаДЕФДњТыТпМЪЧЪВУДбљЕФ,ЫќзюжеЕФжДааЗНЪНОЭЪЧЪВУДбљЕФЁЃ
ЕЋЪЧЖдгк flink sql ЕФжДааЙ§ГЬ,ДѓМвЛЙЪЧВЛЪьЯЄЕФЁЃ
вђДЫБОЮФЭЈЙ§вдЯТеТНкЪЙгУ ETL,group agg(sum,countЕШ)МђЕЅОлКЯРр query ДјДѓМвзпНјвЛЬѕ flink sql query ТпМЕФЪРНчЁЃАяДѓМвжСЩйФмЙЛЪьЯЄдк flink sql ГЬађдЫааЪБжЊЕР flink ГЬађдкИЩЪВУДЁЃ
-
БГОАЦЊ-ДѓМвВЛСЫНт flink sql ЪВУД?
-
ФПБъЦЊ-БОЮФФмАяжњДѓМвСЫНт flink sql ЪВУД?
-
ЪЕеНЦЊ-МђЕЅЕФ query АИР§КЭдЫаадРэ
-
змНсгыеЙЭћЦЊ
ЯШЫЕЫЕНсТл:
-
ГЁОАЮЪЬт:flink sql КмЪЪКЯМђЕЅ ETL,вдМАЛљБОШЋВПГЁОАЯТЕФОлКЯРржИБъЁЃ
-
гяЗЈЮЪЬт:flink sql гяЗЈЦфЪЕЪЧКЭЦфЫћ sql гяЗЈЛљБОвЛжТЕФЁЃЛљБОВЛЛсВњЩњгяЗЈЮЪЬтзшАЪЙгУ flink sqlЁЃ
-
дЫааЮЪЬт:ВщПД flink sql ШЮЮёЪБЕФвЛаЉММЧЩ:
-
ШЅ flink webui ПДПДетИіШЮЮёФПЧАдкзіЪВУДЁЃАќРЈЫузгУћГЦЖМЛсИјжБНгеЙЪОИјЮвУЧФПЧАФФИіЫузгдкИЩЩЖЪТЧщ,дкДІРэЩЖТпМЁЃ
-
ШчЙћФуЯыжЊЕРФуЕФ flink ШЮЮёжДааСЫЪВУДДњТы,ОЭШЅПДПД sql зюКѓзЊЛЛГЩЕФ transformation РяУцОпЬхвЊжДааФФаЉВйзїЁЃflink sql ЩњГЩЕФДњТывВдкРяУцЁЃ
-
ШчЙћФуВЛШЗЖЈЯпЩЯШЮЮёжДаадРэ,ПЩвджБНгдкБОЕиГЂЪддЫааЁЃ
2.БГОАЦЊ-ДѓМвВЛСЫНт flink sql ЪВУД?
ЪзЯШДгДѓМвгУ flink sql ЕФвЛИіГѕждКЭзДЬЌГіЗЂ,ЯывЛЯТДѓМвдкПЊЪМЩЯЪж flink sql ЪБ,ЪЧЪВУДбљЕФвЛИіЯыЗЈ?
ВЉжїДѓИХећРэСЫЯТ,дкГѕВНЩЯЪж flink sql,вЛАуДгШыЪжЕНВШПгећИіЙ§ГЬжа,вЛАуЖМЛсгавдЯТМИжжЮЪЬтЛђепЯыЗЈ:
-
ГЁОАЮЪЬт:ЪзЯШ flink sql ЪЧгУРДЬсаЇЕФ,ФЧЯрБШ datastream,ФФаЉГЁОАКмЪЪКЯ flink sql ШЅзі?
-
гяЗЈЮЪЬт:ЮваД sql ЪБ flink sql гяЗЈЛсВЛЛсКЭЦфЫћ sql гяЗЈгаВЛЭЌ?
-
дЫааЮЪЬт:ЮваДСЫвЛЬѕ sql,дЫааЦ№РДСЫ,ЕЋЪЧЖдЮвРДЫЕЪЧКкКаЕФ,ЮвдѕУДжЊЕРетИіШЮЮёе§дкжДааЪВУДВйзї?гаУЛгаЪВУДКУАьЗЈАяЮвШЅРэНт flink sql ЕФдЫааЛњжЦ?
-
РэНтЮѓЧј:дкРэНт flink sql ЕФдЫЫуЛњжЦЩЯгаФФаЉЮѓЧј?
-
Пг:flink sql вЛАуЖМгаЩЖПг?ЬсЧАСЫНтАяЮвУЧБмУтВШПгЁЃ
ОЭЪЧЩЯУцетаЉЯыЗЈ,ЛсШУКмЖрЯыдкЙЋЫОФкВПв§Шы flink sql ЕФЭЌбЇЭћЖјШДВНЁЃ
3.ФПБъЦЊ-БОЮФФмАяжњДѓМвСЫНт flink sql ЪВУД?
РДПДПДБОЮФЕФФПБъ:
-
ГЁОАЮЪЬт:АяДѓМвРэНтФФаЉГЁОАЪЧЗЧГЃЪЪКЯ flink sql ЕФ
-
гяЗЈЮЪЬт:АяДѓМвМђЕЅЪьЯЄ flink sql ЕФгяЗЈ
-
дЫааЮЪЬт:ЪЙгУвЛЬѕМђЕЅЕФ query sql ПДПДЦфдЫааЦ№РДЕФЙ§ГЬ,ЦфдЫааЕФЛњжЦ
-
РэНтЮѓЧј:дЫЫуЛњжЦЩЯЕФГЃМћЮѓЧј
-
Пг:ПДПД sql вЛАуЛсгаЩЖПг
гЩгквЛЦЊЮФеТВЛФмИВИЧЫљгаИХФю,БОЮФжївЊНщЩмвЛаЉзюМђЕЅЕФ ETL,ОлКЯГЁОА,жївЊМЏжагкЧАШ§ЕуЁЃ
КѓСНЕудкКѓајЯЕСаЮФеТжаЛсАДееГЁОАЯъЯИеЙПЊЁЃ
4.ЪЕеНЦЊ-МђЕЅЕФ query АИР§КЭдЫаадРэ
4.1.ГЁОАЮЪЬт:гаФФаЉГЁОАЪЪКЯ flink sql?
ВЛзАСЫ,ЮвЬЙАзСЫ,flink sql ЦфЪЕКмЪЪКЯИЩЕФЛюОЭЪЧ dwd ЧхЯД,dws ОлКЯЁЃ
ДЫДІжївЊеыЖдЪЕЪБЪ§ВжЕФГЁОАРДЫЕЁЃflink sql ФмИЩ dwd ЧхЯД,dws ОлКЯ,ЛљБОЩЯЪЕЪБЪ§ВжЕФДѓЖрЪ§ГЁОАЖМФмИјИВИЧСЫЁЃ
flink sql ХЃБЦ!!!
ЕЋЪЧ!!!
ОЙ§ВЉжїЪЙгУ flink sql ОбщРДПД,ВЂВЛЪЧЫљгаЕФ dwd,dws ОлКЯГЁОАЖМЪЪКЯ flink sql(НижЙЗЂЮФНзЖЮРДЫЕ)!!!
ЦфЪЕетаЉФПЧАВЛЪЪКЯ flink sql ЕФГЁОАзмНсЯТРДОЭЪЧдкДІРэЩЯБШ datastream ЛЙЪЧЛсгавЛЖЈЕФЫ№ЪЇЁЃ
ЯШзмНсЯТЪЙгУГЁОА:
1. dwd:МђЕЅЕФЧхЯДЁЂИДдгЕФЧхЯДЁЂЮЌЖШЕФРЉГфЁЂИїжж udf ЕФЪЙгУ
2. dws:ИїРрОлКЯ
ШЛКѓЗжЪЪКЯЕФГЁОАКЭВЛЪЪКЯЕФГЁОАРДЫЕ,вђЮЊжЛетвЛЦЊВЛФмИВИЧЫљгаЕФФкШн,ЫљвдБОЮФДЫДІЯШДѓжТИјИіНсТл,жЎКѓЛсНсКЯОпЬхЕФГЁОАЯъЯИУшЪіЁЃ
- ЪЪКЯЕФГЁОА:
-
МђЕЅЕФ dwd ЧхЯДГЁОА
-
ШЋГЁОАЕФ dws ОлКЯГЁОА
- ФПЧАВЛЬЋЪЪКЯЕФГЁОА:
-
ИДдгЕФ dwd ЧхЯДГЁОА:ОйР§БШШчЪЙгУСЫКмЖр udf ЧхЯД,гШЦфЪЧЪЙгУКмЖрЕФ json РрНтЮіЧхЯД
-
ЙиСЊЮЌЖШГЁОА:ОйР§БШШч datastream жаОГЃЛсгадмвЛХњЪ§ОнХњСПЗУЮЪЭтВПНгПкЕФГЁОА,flink sql ФПЧАЖдгкетжжГЁОАЫфШЛга localcacheЁЂвьВНЗУЮЪФмСІ,ЕЋЪЧвРШЛЛЙЪЧвЛЬѕвЛЬѕЗУЮЪЭтВПЛКДц,етбљЯрБШХњСПЗУЮЪЛЙЪЧЛсгаадФмВюОрЁЃ
4.2.гяЗЈ\дЫааЮЪЬт
ЦфЪЕзмНсРДЫЕ,ЖдгкНгДЅЙ§ sql ЕФЭЌбЇРДЫЕ,Г§СЫ flink sql жаДАПкОлКЯРрЕФаДЗЈРДЫЕ,ЦфЫћЕФ sql гяЗЈЖМЪЧЯрЭЌЕФ,КмШнвзРэНтЁЃ
БОНкЛсеыЖдОпЬхЕФАИР§НјааЯъЯИНщЩмЁЃ
4.2.1.ETL
зюМђЕЅЕФ ETL РраЭШЮЮёЁЃ
SELECT?select_list?FROM?table_expression?[?WHERE?boolean_expression?]
1.ГЁОА:МђЕЅЕФ dwd ЧхЯДЙ§ТЫГЁОА
дДТыЙЋжкКХКѓЬЈЛиИДВЛЛсСЌзюЪЪКЯ flink sql ЕФ ETL КЭ group agg ГЁОАЖМУЛМћЙ§АЩЛёШЁЁЃ
Ъ§ОндДБэ:
CREATE?TABLE?source_table?(
????order_number?BIGINT,
????price????????DECIMAL(32,2)
)?WITH?(
??'connector'?=?'datagen',
??'rows-per-second'?=?'10',
??'fields.order_number.min'?=?'10',
??'fields.order_number.max'?=?'11'
)
Ъ§ОнЛуБэ:
CREATE?TABLE?sink_table?(
????order_number?BIGINT,
????price????????DECIMAL(32,2)
)?WITH?(
??'connector'?=?'print'
)
ETL ТпМ:
insert?into?sink_table
select?*?from?source_table
where?order_number?=?10
2.дЫаа:ПЩвдПДЕН,ЦфЪЕдк flink sql ШЮЮёжа,ЦфЛсАбЖдгІЕФДІРэТпМИјаДЕНЫузгУћГЦЩЯУцЁЃ
Notes - ЙлВь flink sql ММЧЩ 1:
етИіЦфЪЕОЭЪЧЮвУЧЙлВь flink sql ШЮЮёЕФЕквЛИіММЧЩЁЃШчЙћФуЯыжЊЕРФуЕФ flink ШЮЮёдкИЩЩЖ,ЕквЛЗДгІЪЧШЅ flink webui ПДПДетИіШЮЮёФПЧАдкзіЪВУДЁЃАќРЈЫузгУћГЦЖМЛсИјжБНгеЙЪОИјЮвУЧФПЧАФФИіЫузгдкИЩЩЖЪТЧщ,дкДІРэЩЖТпМ
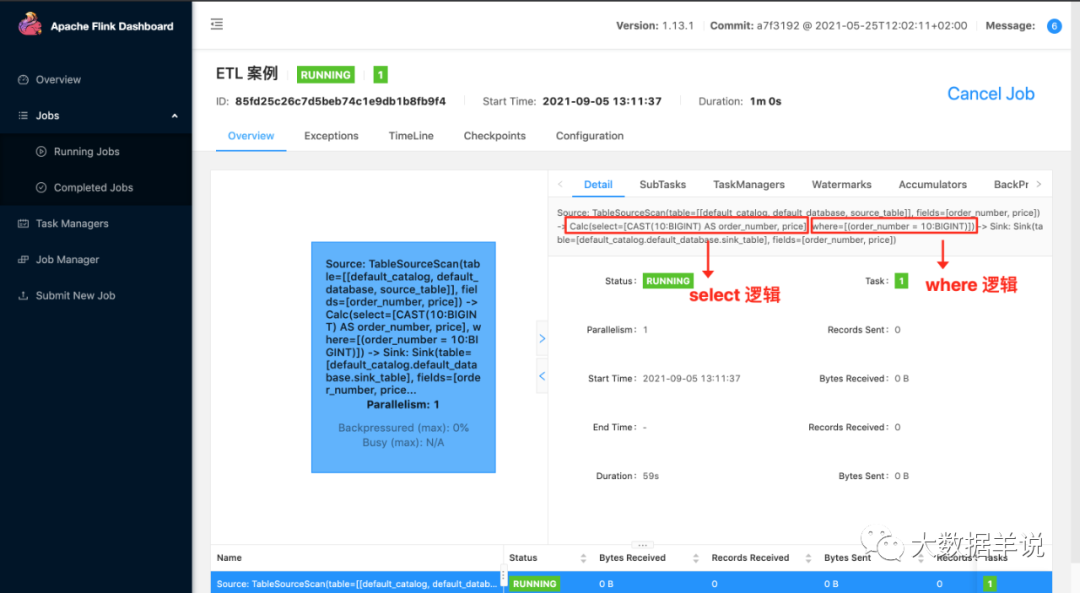
5
3.НсЙћ
+I[10,?337546916355686018150362513408.00]
+I[10,?734895198061906189720381030400.00]
+I[10,?496632591763800912960818249728.00]
+I[10,?495090465926828588045441171456.00]
+I[10,?167305033642317182838130081792.00]
+I[10,?409466913112794578407573684224.00]
+I[10,?894352160414515330502514180096.00]
+I[10,?680063350384451712068576346112.00]
+I[10,?50807402446574997641386524672.00]
+I[10,?646597093362022945955245981696.00]
+I[10,?233317961584082024331537809408.00]
...
4.дРэ:
ЯШПДвЛЯТвЛИі flink sql ШЮЮёЕФШыПкжДааТпМЁЃ
ЪзЯШПДПДНЈБэгяОфЕФжДааКЭ query гяОфжДааЕФТпМгаЪВУДВЛЭЌЁЃ
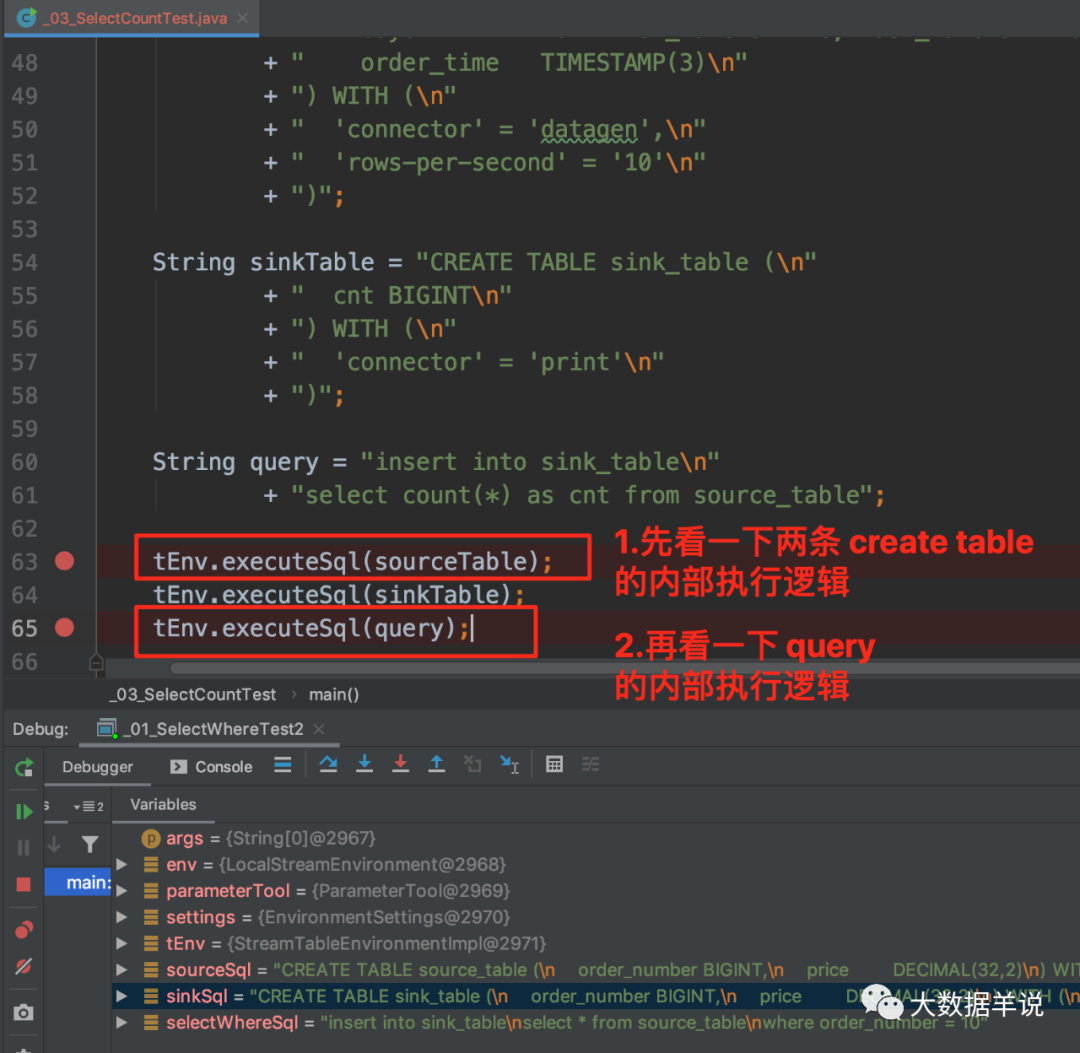
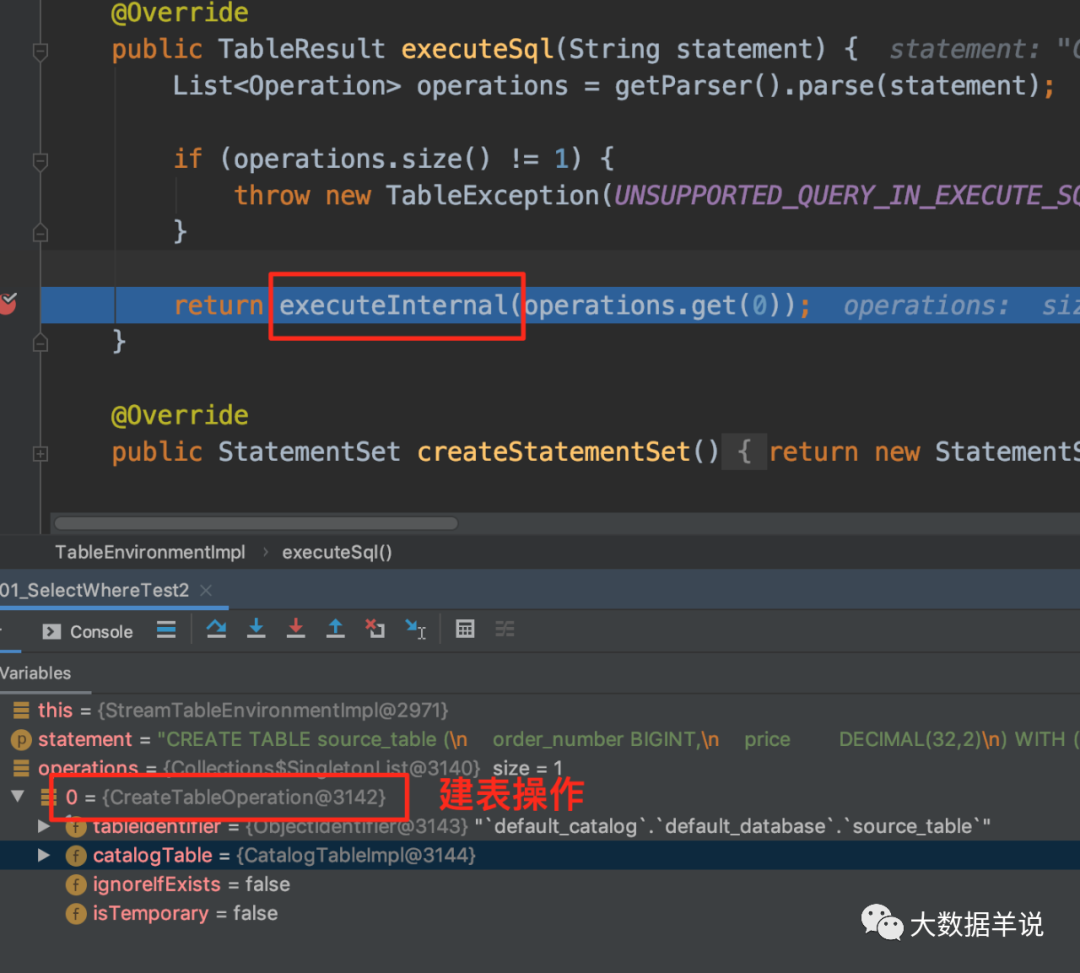
ПЩвдЗЂЯжжДааЕН executeInternal ЪБЛсеыЖдОпЬхЕФ operation РДжДааВЛЭЌЕФВйзїЁЃ
жДааНЈБэВйзїОЭЪЧОпЬхЕФ CreateTableOperation ЪБ,ЛсНЋБэЕФаХЯЂБЃДцЕН catalogManagerЁЃ
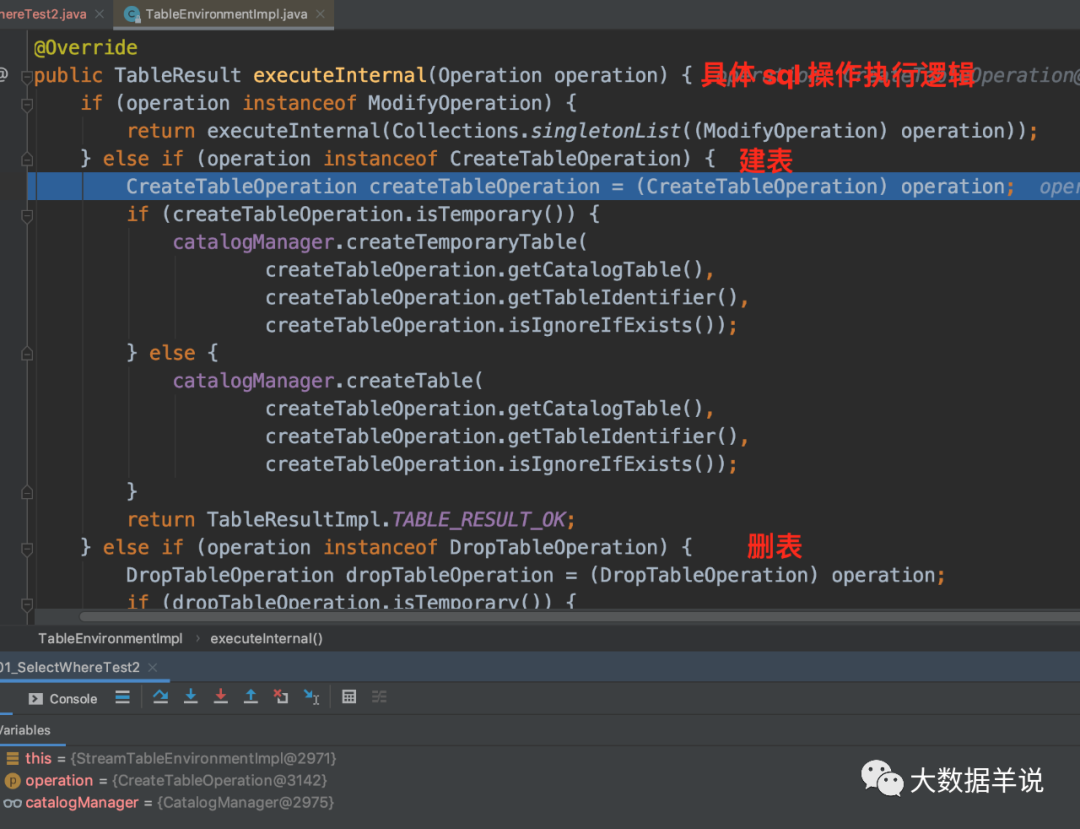
8
жДаа query ВйзїОЭЪЧОпЬхЕФ ModifyOperation ЪБ,ЛсНЋЖдгІЕФТпМзЊЛЛГЩЖдгІЕФ TransformationЁЃ
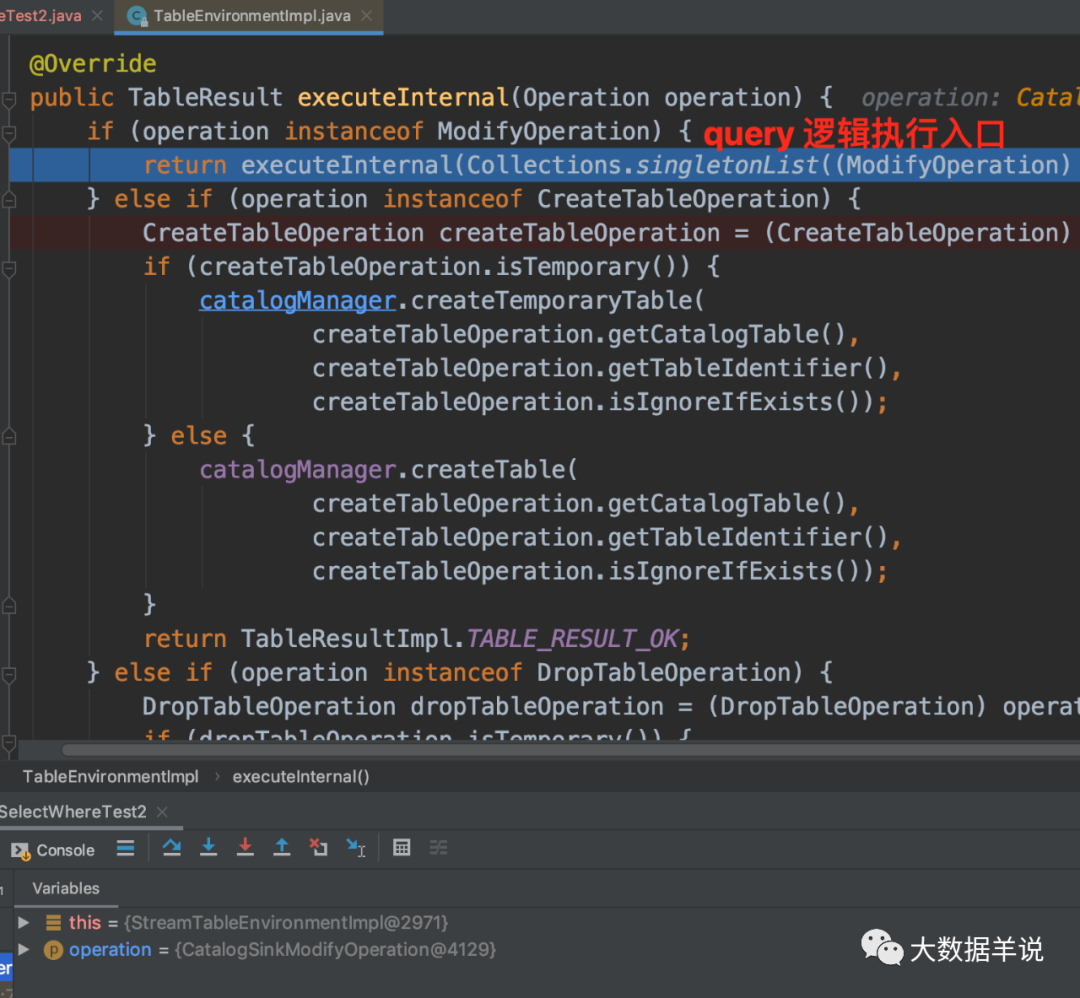
9
Transformation жаОЭАќКЌСЫжДааЕФећЬхТпМвдМАЖдгІвЊжДааЕФ sql ДњТыФкШнЁЃ
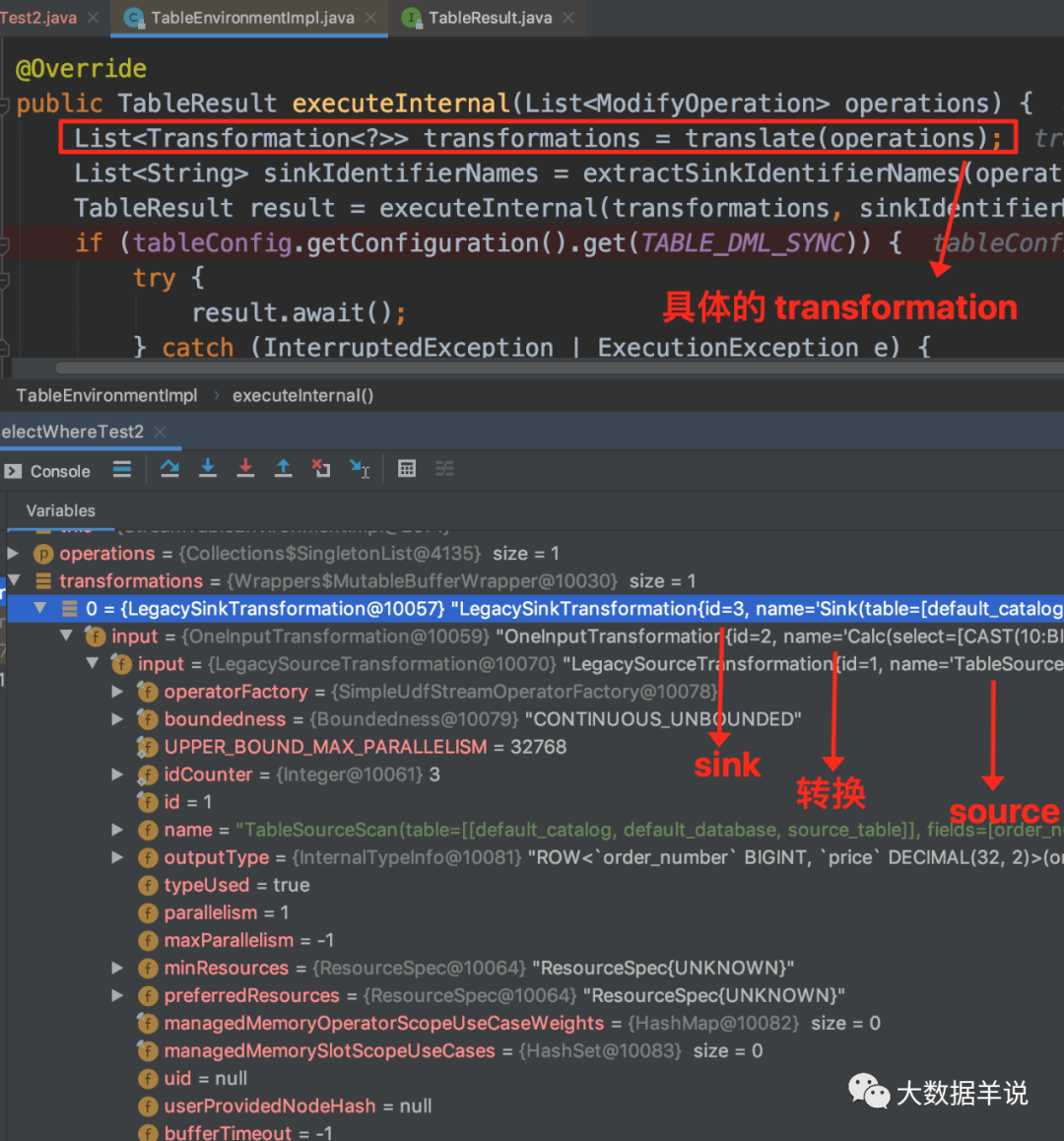
10
НгЯТРДЮвУЧЯъЯИПДЯТЖдгІЕФ transform жаАќКЌСЫЪВУДФкШнЁЃ
ЪзЯШЪЧзюЭтВу LegacySinkTransformation,МД sink Ыузг,ШчЭМОЭЪЧ print sink functionЁЃБШНЯКУРэНтЁЃ
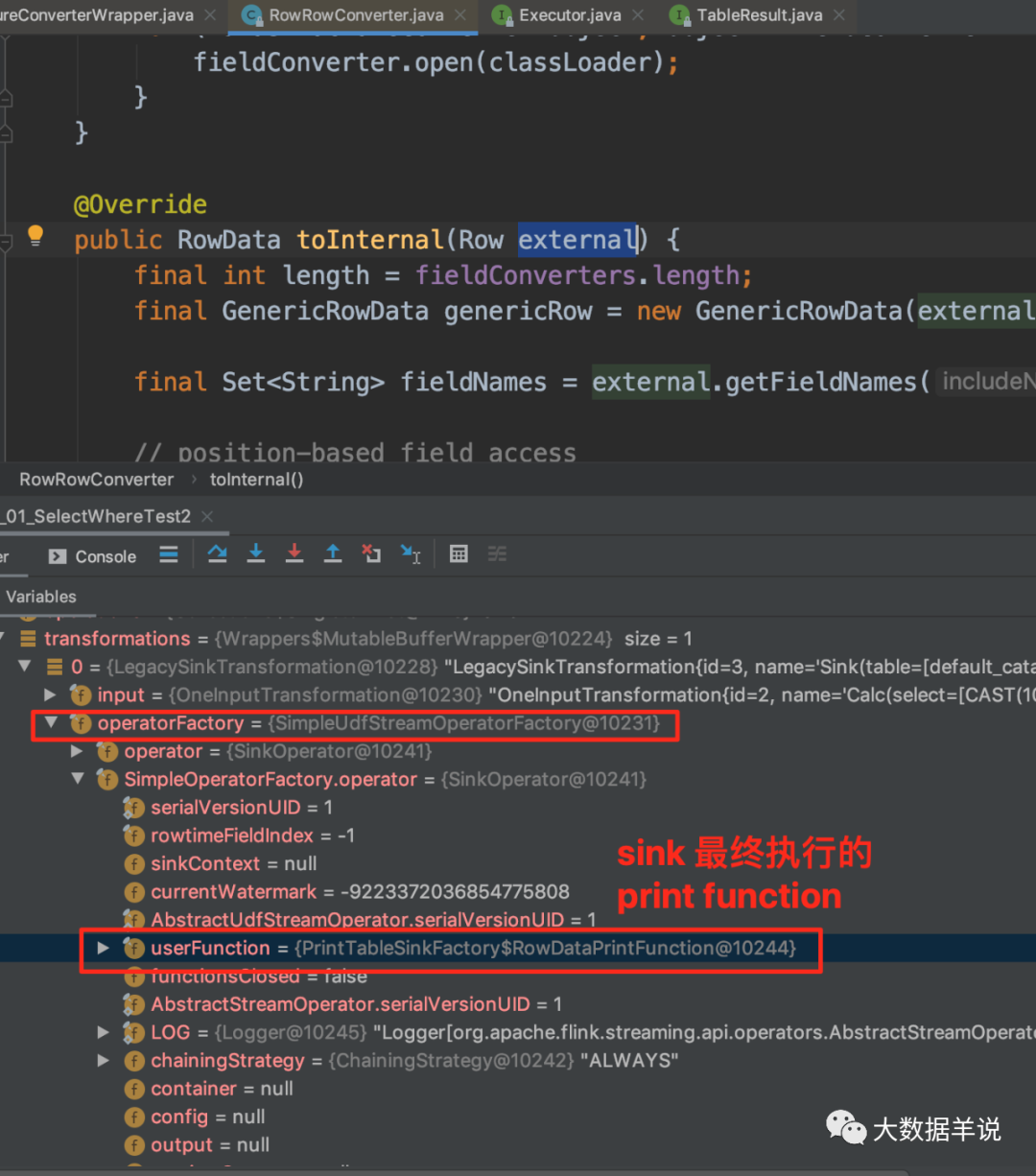
11
ШЛКѓЪЧжаМфВу OneInputTransformation,МД sql жаЙ§ТЫКЭзЊЛЛВйзї(select * from source_table where order_number = 10),ШчЭМЪЧДњТыЩњГЩЕФОпЬхЙ§ТЫКЭзЊЛЛТпМЁЃ
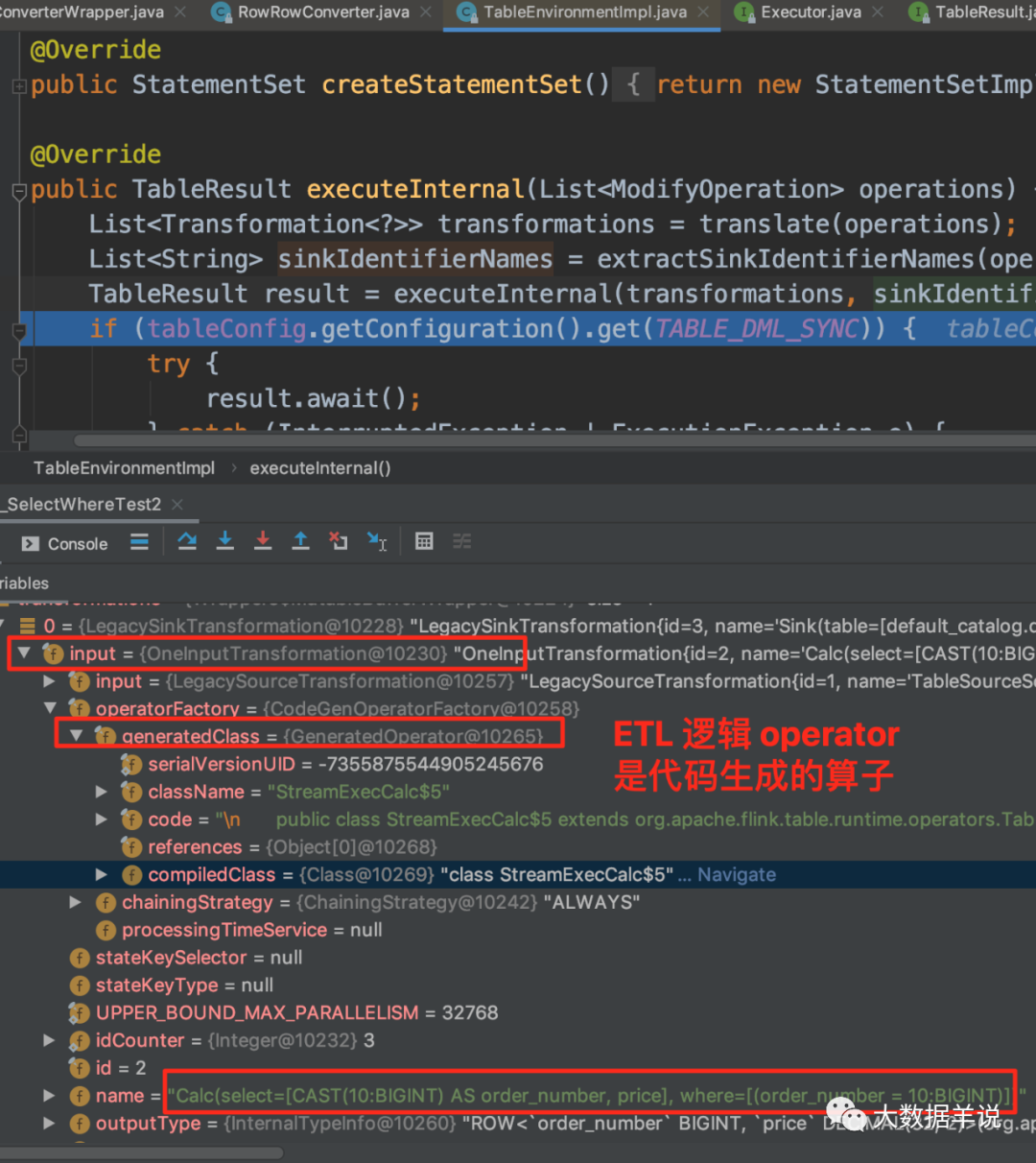
12
ЩњГЩЕФДњТыОЭдк GeneratedOperator жаЕФ code зжЖЮЁЃЮвУЧНЋЖдгІЕФ code ИДжЦЕНвЛИіаТЕФЮФМўМажаЁЃ
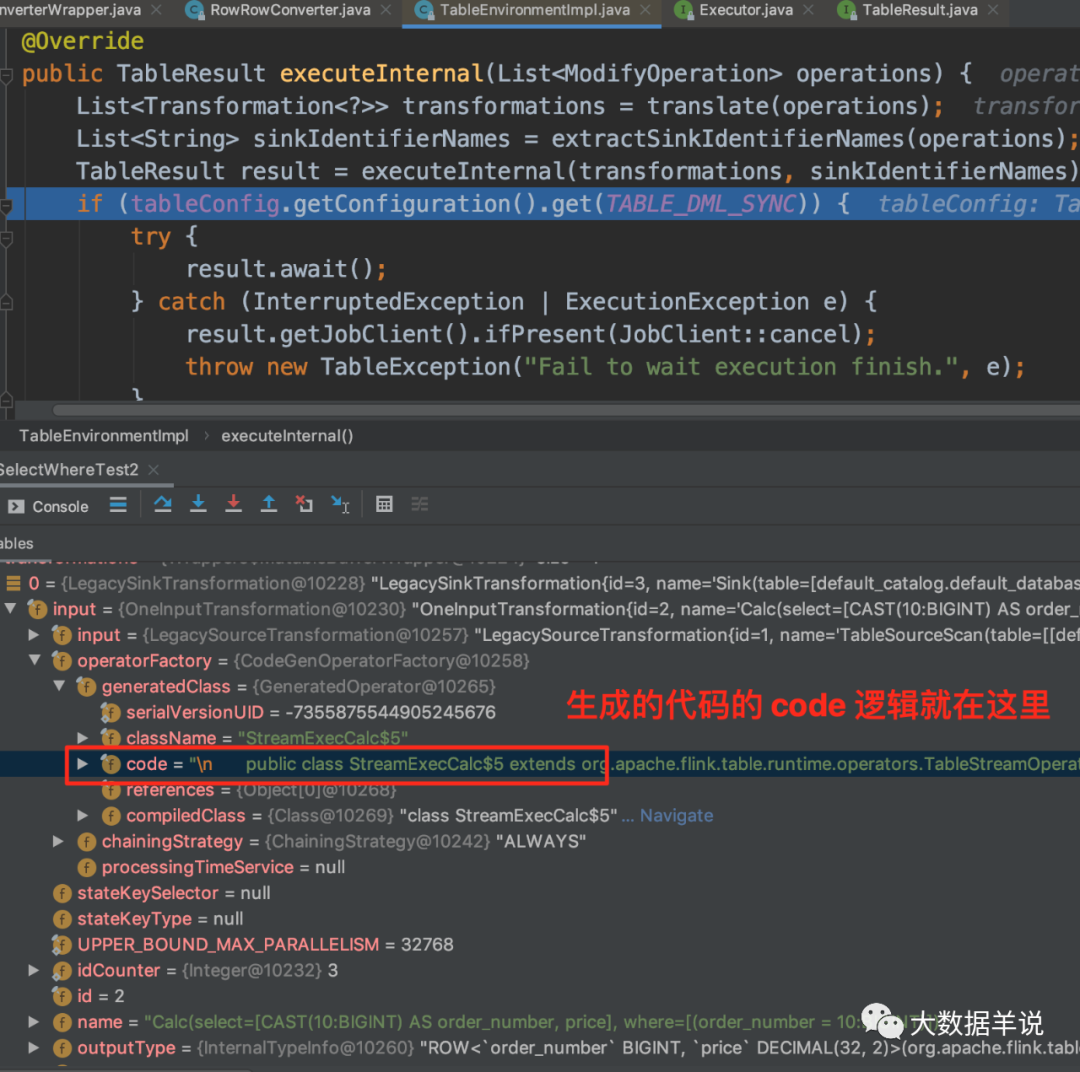
13
етИіЫузгЪЧжБНгМЬГаСЫ OneInputStreamOperator НјаажБНгжДааТпМ,ЬјЙ§СЫ datastream ФЧвЛВуЁЃ
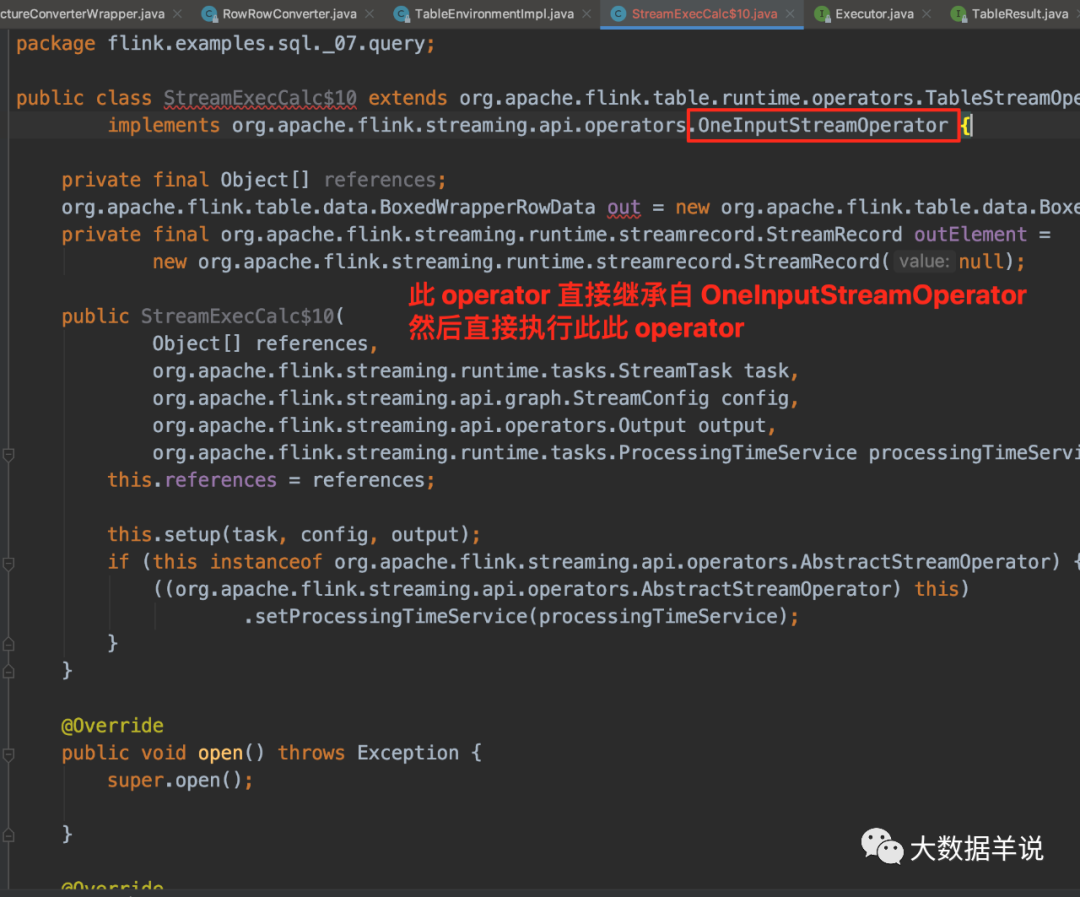
14
ЮвУЧРДПДПДзюживЊЕФ processElement ТпМ,ОпЬхзжЖЮНтЪЭКЭжДааТпМШчЭМЫљЪОЁЃ
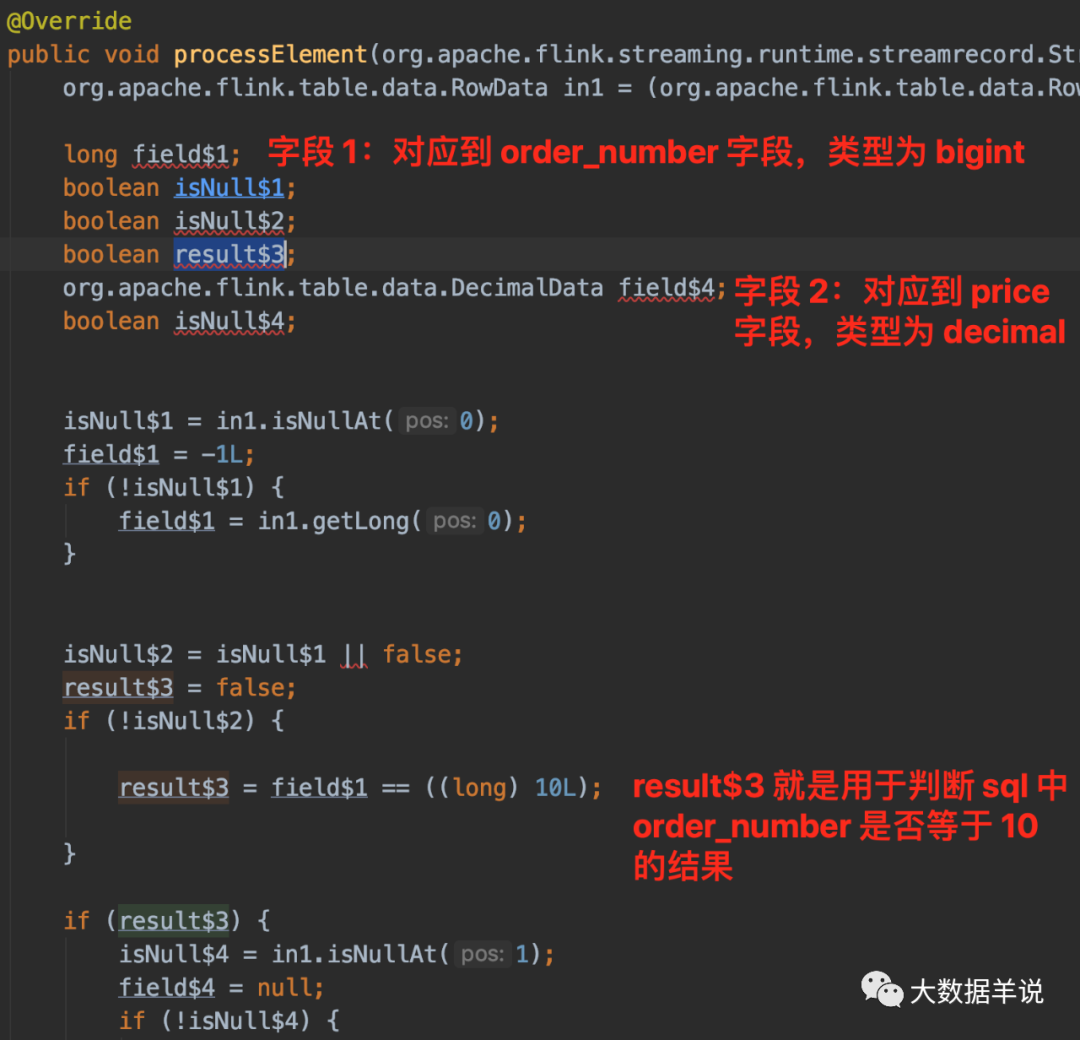
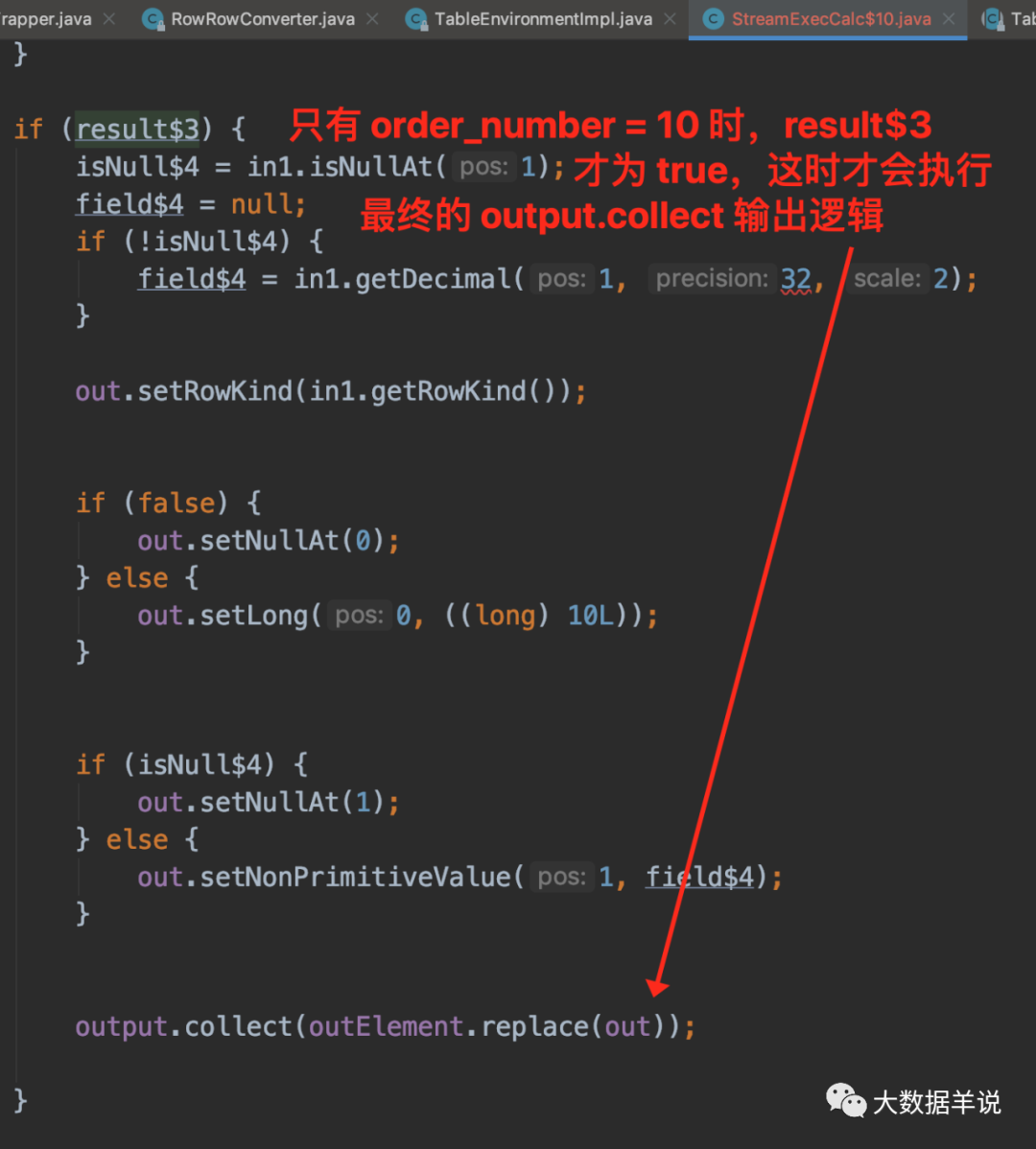
Notes - ЙлВь flink sql ММЧЩ 2:
етИіЦфЪЕОЭЪЧЮвУЧЙлВь flink sql ШЮЮёЕФЕкЖўИіММЧЩЁЃШчЙћФуЯыжЊЕРФуЕФ flink ШЮЮёжДааСЫЪВУДДњТы,ОЭШЅПДПД sql зюКѓзЊЛЛГЩЕФ transformation РяУцОпЬхвЊжДааФФаЉВйзїЁЃ
4.2.2.ШЅжиГЁОА
1.ГЁОА:зюМђЕЅЕФШЅжиГЁОА
дДТыЙЋжкКХКѓЬЈЛиИДВЛЛсСЌзюЪЪКЯ flink sql ЕФ ETL КЭ group agg ГЁОАЖМУЛМћЙ§АЩЛёШЁЁЃ
Ъ§ОндД:
CREATE?TABLE?source_table?(
????string_field?STRING
)?WITH?(
??'connector'?=?'datagen',
??'rows-per-second'?=?'10',
??'fields.string_field.length'?=?'3'
)
Ъ§ОнЛу:
CREATE?TABLE?sink_table?(
????string_field?STRING
)?WITH?(
??'connector'?=?'print'
)
Ъ§ОнДІРэ:
insert?into?sink_table
select?distinct?string_field
from?source_table
2.дЫаа:ПЩвдПДЕН,ЦфЪЕдк flink sql ШЮЮёжа,ЦфЛсАбЖдгІЕФДІРэТпМИјаДЕНЫузгУћГЦЩЯУцЁЃ
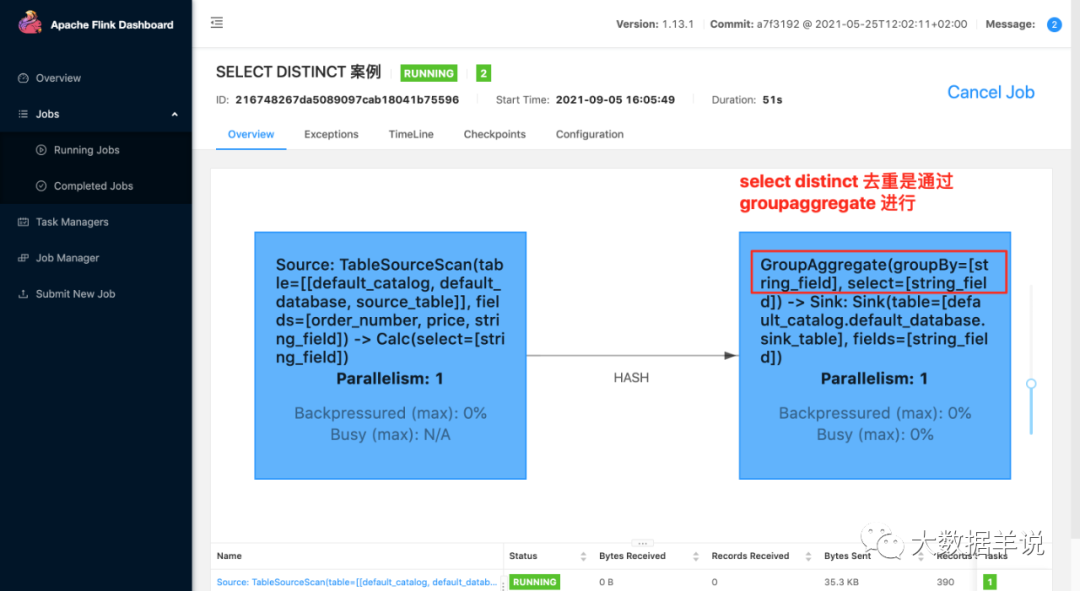
17
3.ЩЯУцетИіАИР§ЕФНсЙћ:
+I[cd3]
+I[8fc]
+I[b0c]
+I[1d8]
+I[e28]
+I[c5f]
+I[e7d]
+I[dfa]
+I[1fe]
...
4.дРэ:
ДЫДІЮвУЧжЛЙизЂКЭЩЯУцВЛЭЌЕФТпМЁЃ
ЕквЛИіОЭЪЧ PartitionTransform жаЕФ KeyGroupStreamPartitioner,ОЭЪЧЖдгІЕФЗжЧјТпМЁЃРДПДПДЩњГЩДњТыЕФТпМЁЃ
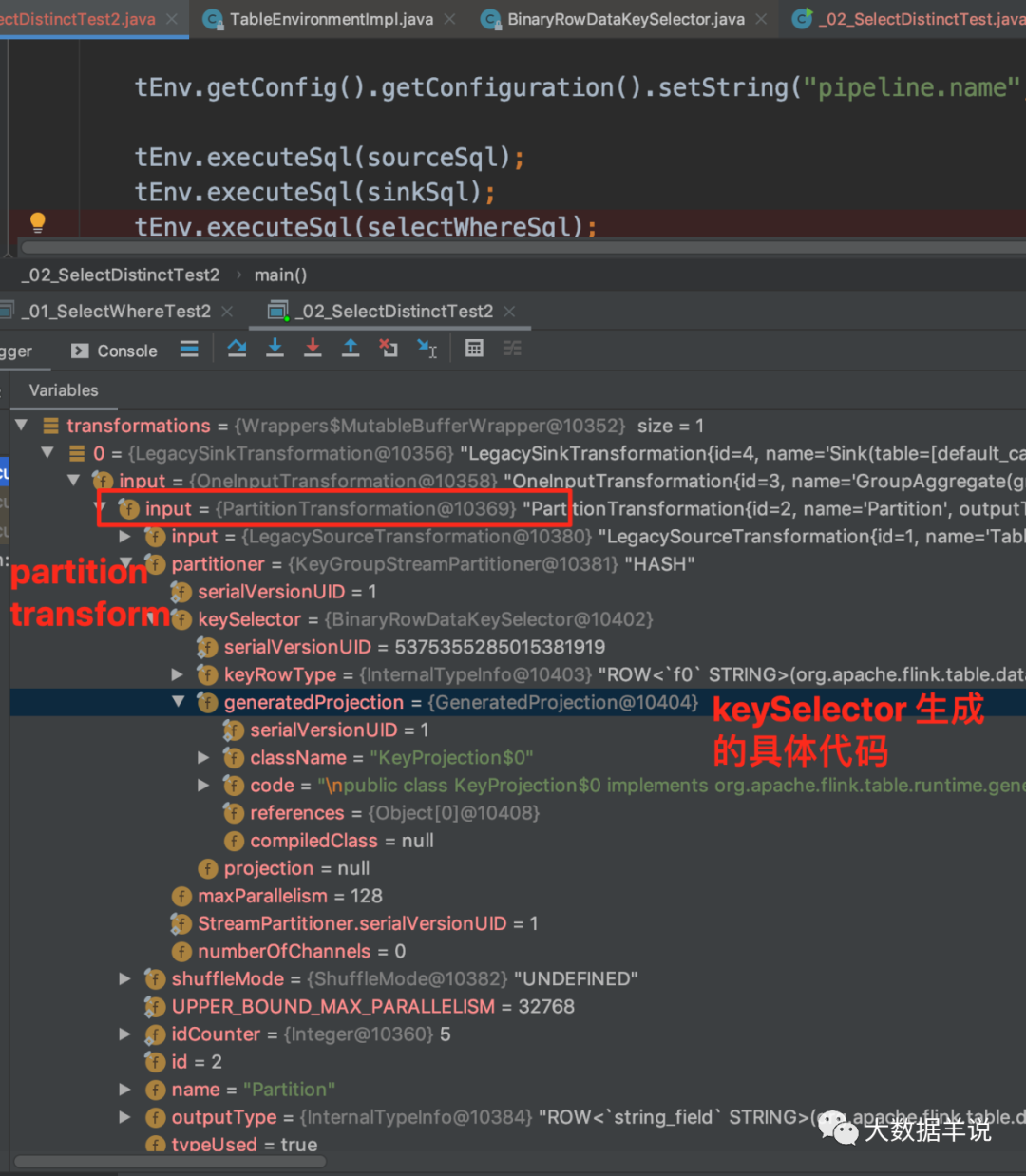
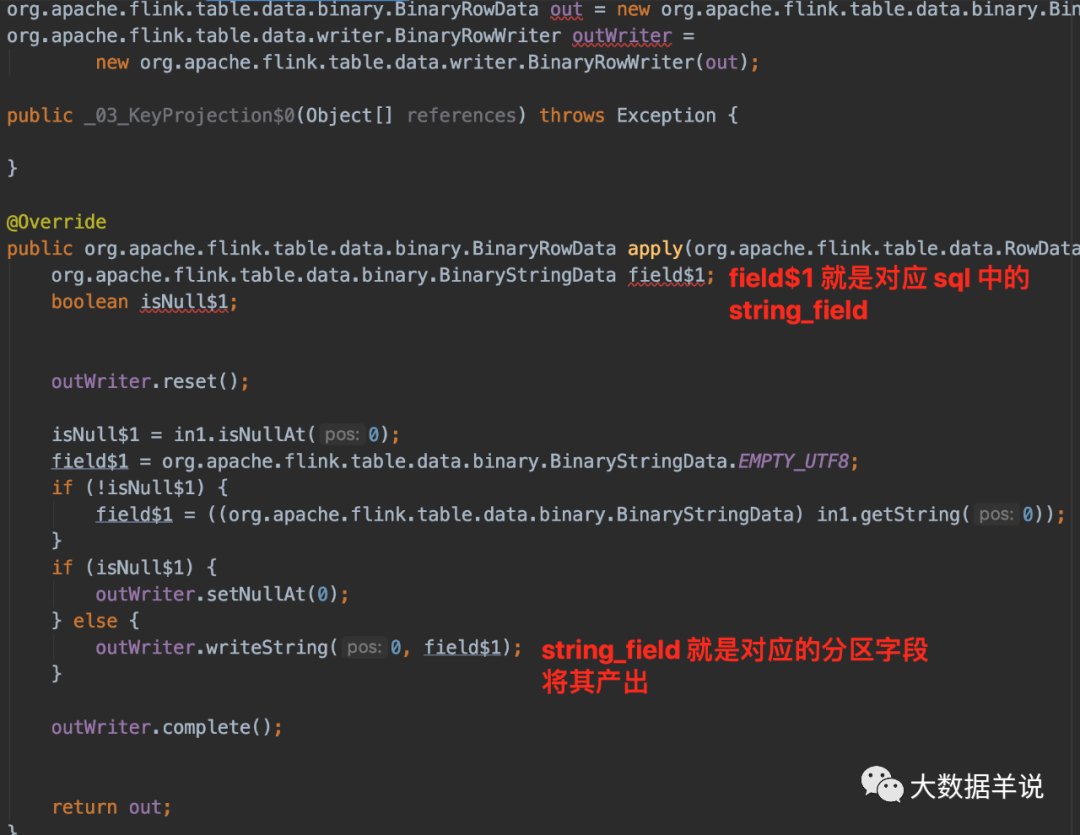
Цфжазі shuffle ТпМЪБ,ЪЧАДее string_field зїЮЊ key Нјаа shuffleЁЃ
ЕкЖўИіОЭЪЧ OneInputTransformation жаЕФ KeyedProcessOperator,ОЭЪЧЖдгІЕФШЅжиТпМЁЃ
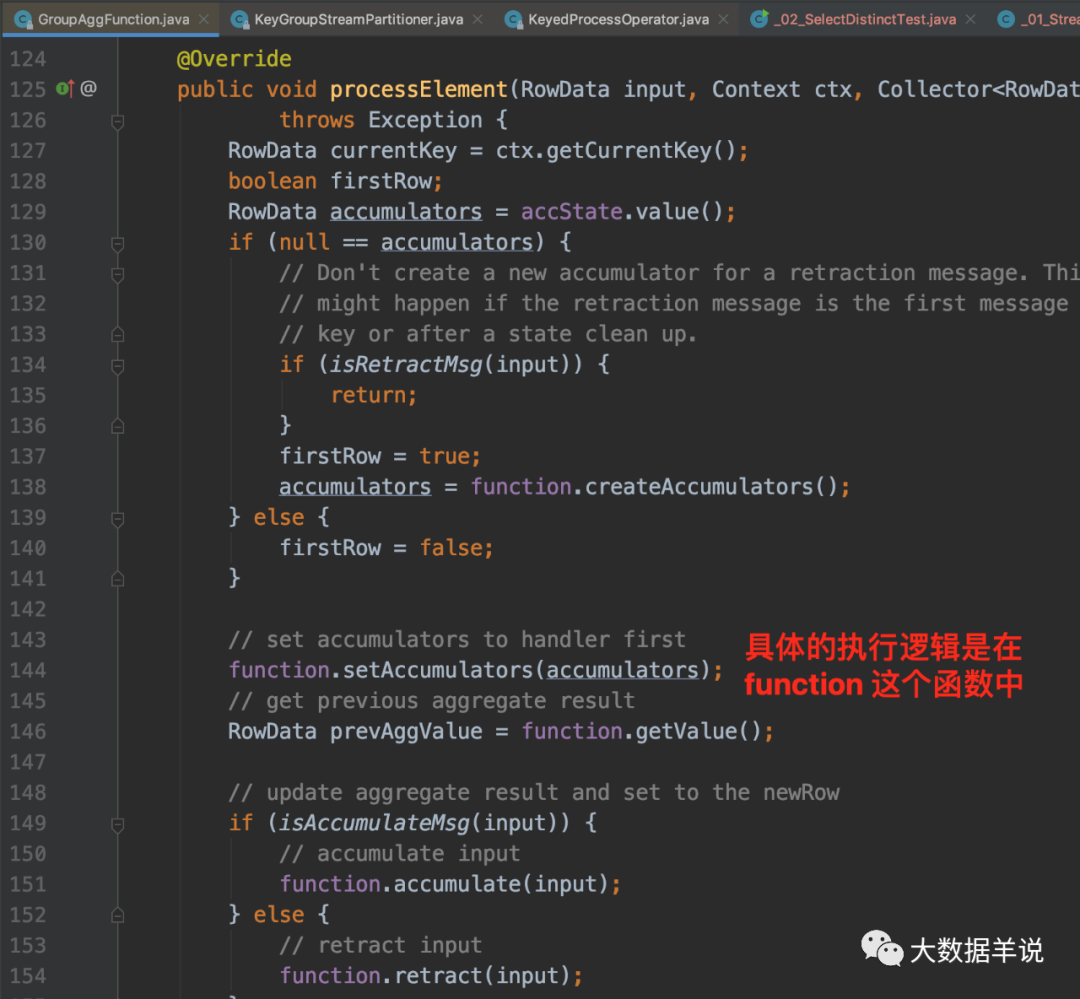


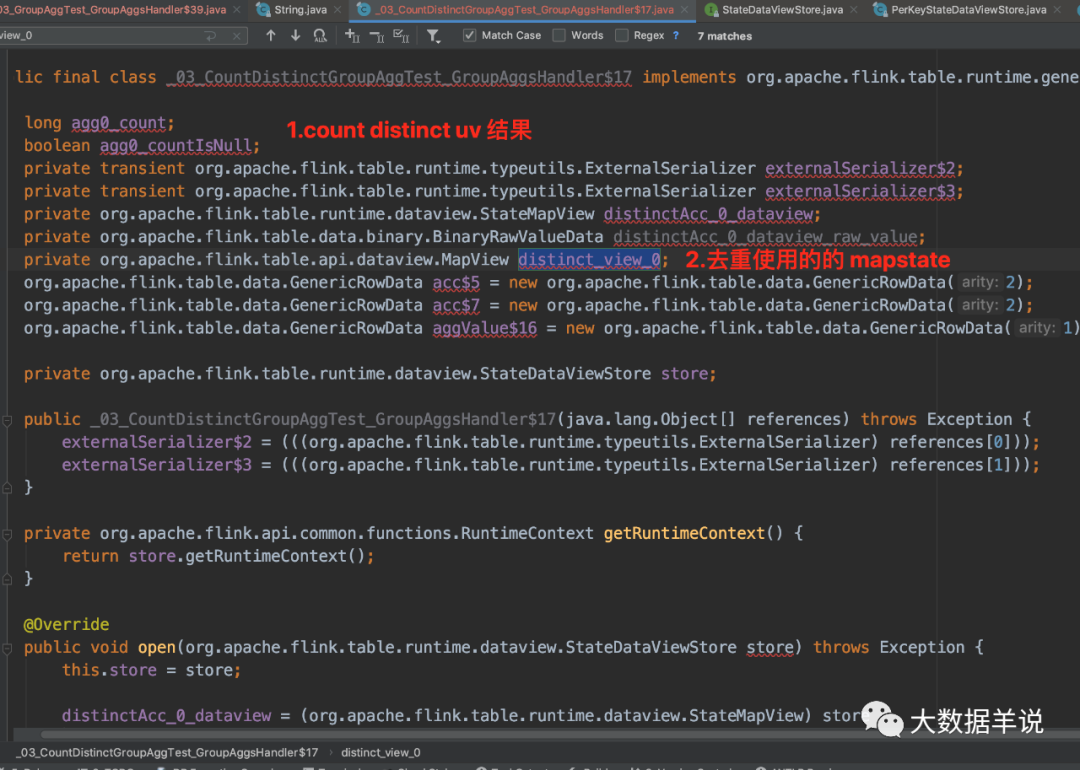
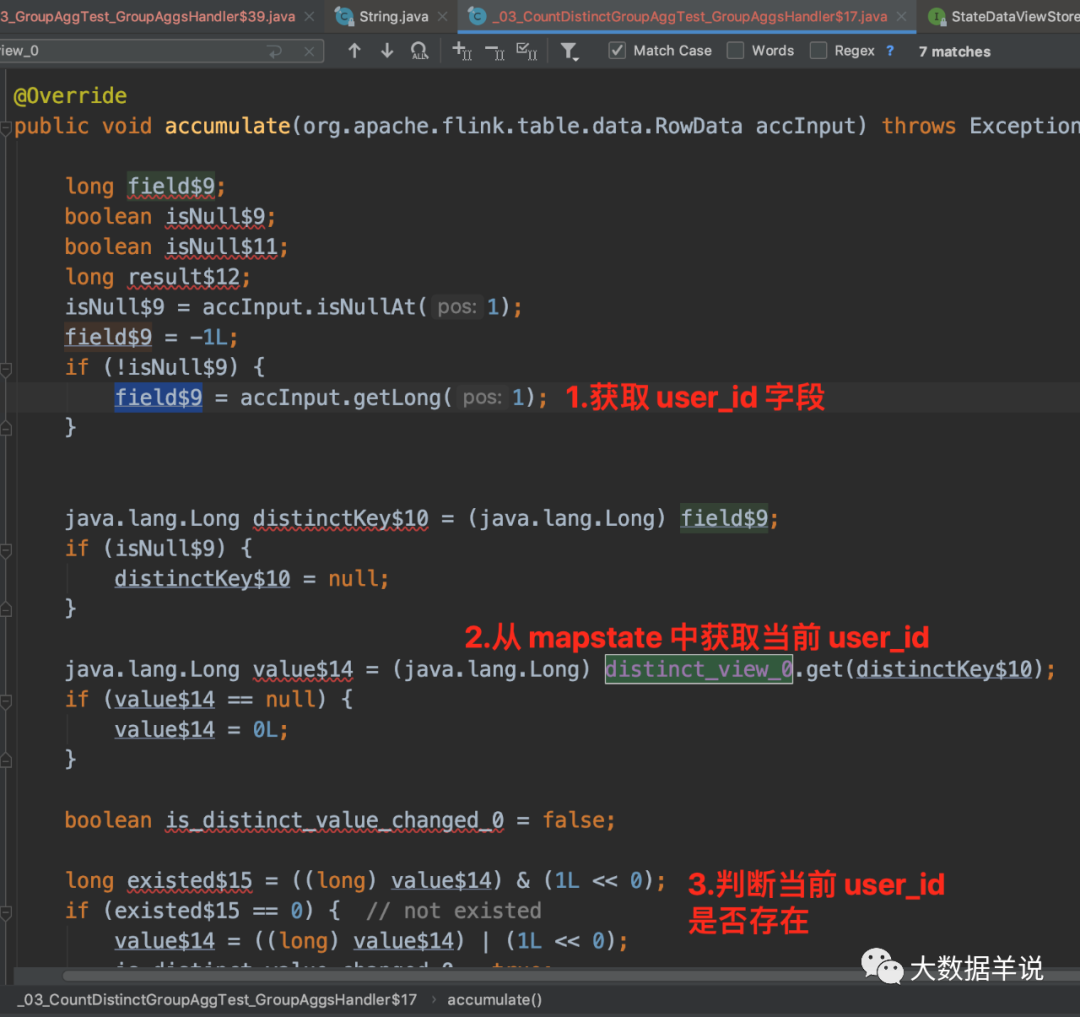
ПЩвдПДЕНЩњГЩЕФ function жажЛгаетШ§ЖЮДњТыЪЧвЕЮёТпМДњТы,ЕЋЪЧЦфжаЕФ RowData ГѕЪМЛЏДѓаЁЖМЪЧ 0ЁЃФЧУДЕНЕзЪЧФФРязіЕФШЅжиТпМФи?
24
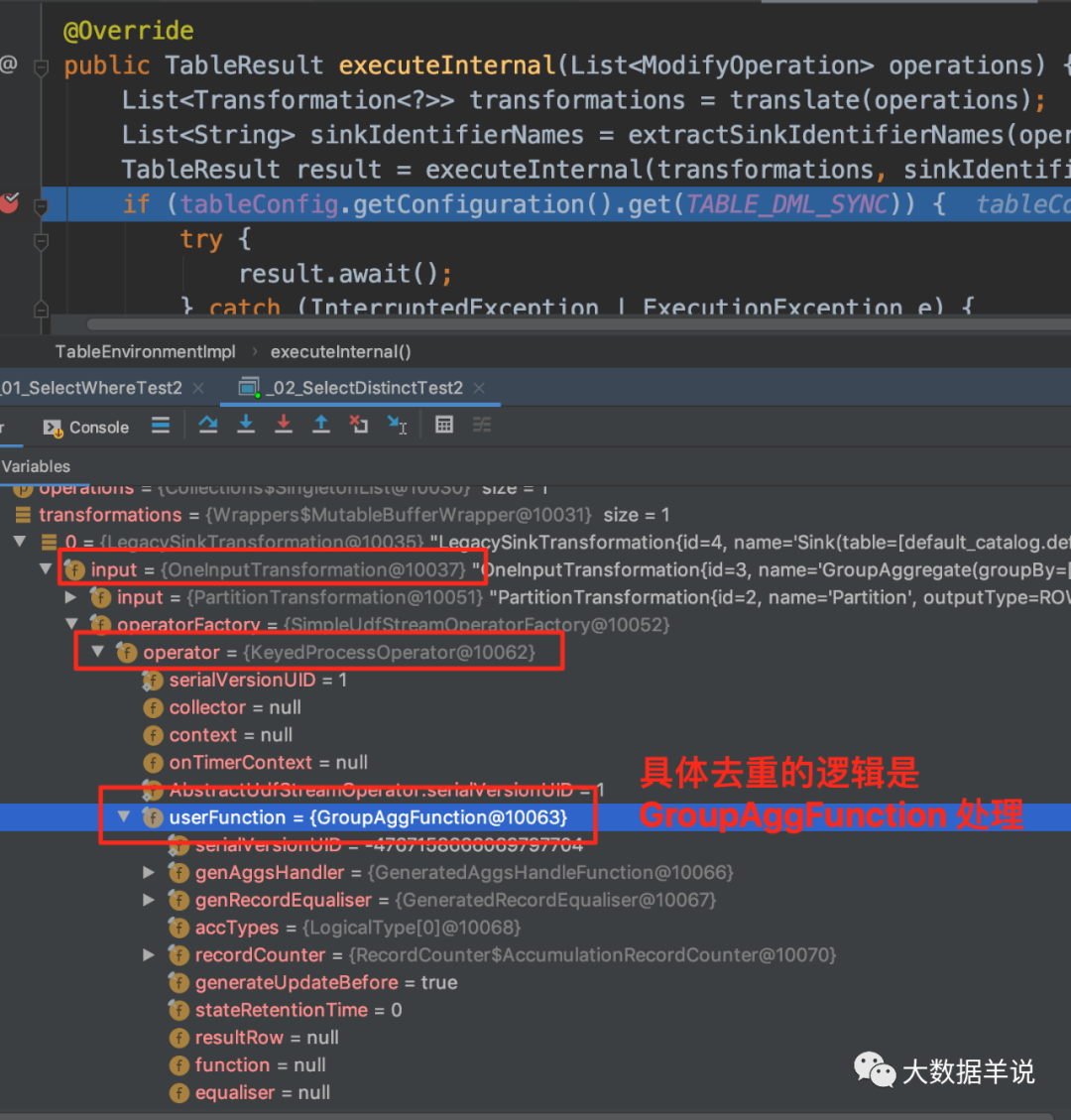
ЮвУЧИњвЛЯТДІРэТпМЛсЗЂЯжЁЃШЅжиТпМжївЊМЏжадк GroupAggFunction#processElementЁЃ

25
4.2.3.group ОлКЯГЁОА
4.2.3.1.МђЕЅОлКЯГЁОА
1.ГЁОА:зюМђЕЅЕФОлКЯГЁОА
дДТыЙЋжкКХКѓЬЈЛиИДВЛЛсСЌзюЪЪКЯ flink sql ЕФ ETL КЭ group agg ГЁОАЖМУЛМћЙ§АЩЛёШЁЁЃ
count,sum,avg,max,min ЕШ:
Ъ§ОндД:
CREATE?TABLE?source_table?(
????order_id?STRING,
????price?BIGINT
)?WITH?(
??'connector'?=?'datagen',
??'rows-per-second'?=?'10',
??'fields.order_id.length'?=?'1',
??'fields.price.min'?=?'1',
??'fields.price.max'?=?'1000000'
)
Ъ§ОнЛу:
CREATE?TABLE?sink_table?(
????order_id?STRING,
????count_result?BIGINT,
????sum_result?BIGINT,
????avg_result?DOUBLE,
????min_result?BIGINT,
????max_result?BIGINT
)?WITH?(
??'connector'?=?'print'
)
Ъ§ОнДІРэТпМ:
insert?into?sink_table
select?order_id,
???????count(*)?as?count_result,
???????sum(price)?as?sum_result,
???????avg(price)?as?avg_result,
???????min(price)?as?min_result,
???????max(price)?as?max_result
from?source_table
group?by?order_id
2.дЫаа:
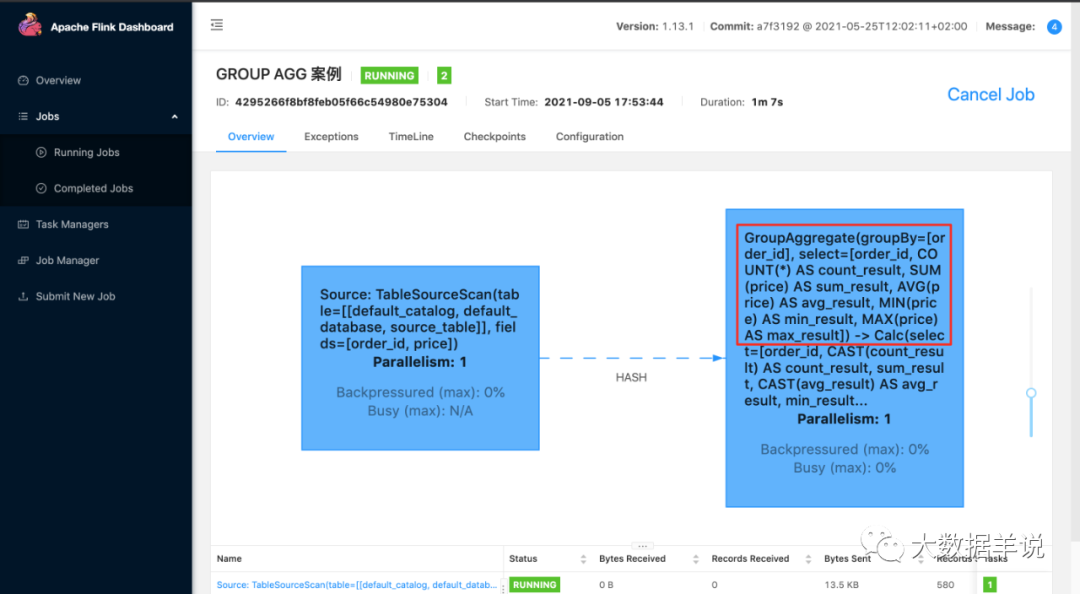
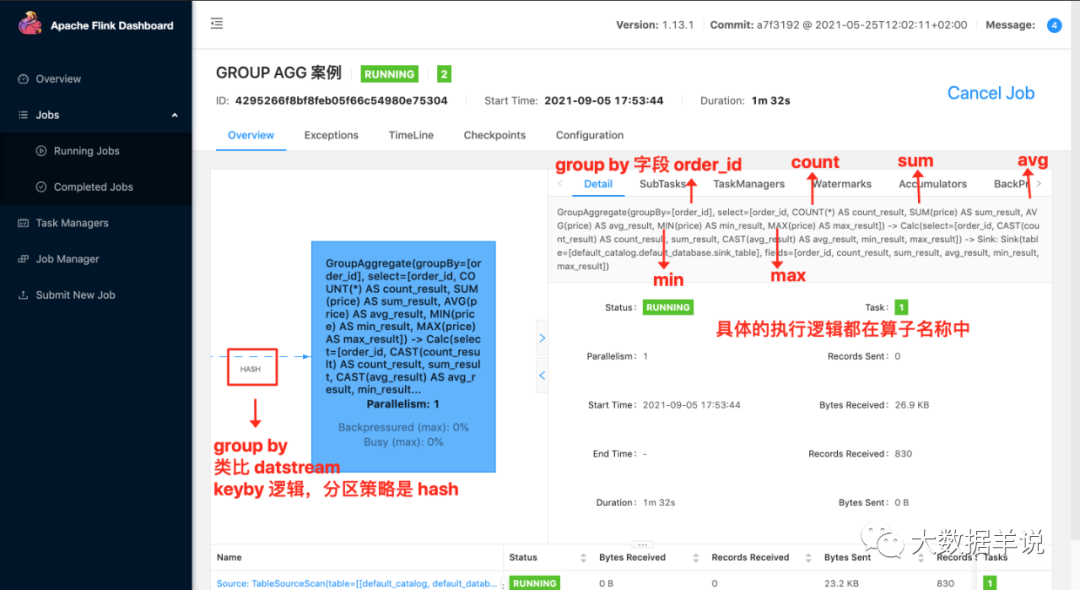
3.ЩЯУцетИіАИР§ЕФНсЙћ:
+I[1,?1,?415300,?415300.0,?415300,?415300]
+I[d,?1,?416878,?416878.0,?416878,?416878]
+I[0,?1,?120837,?120837.0,?120837,?120837]
+I[c,?1,?337749,?337749.0,?337749,?337749]
+I[7,?1,?387053,?387053.0,?387053,?387053]
+I[8,?1,?387042,?387042.0,?387042,?387042]
+I[2,?1,?546317,?546317.0,?546317,?546317]
+I[e,?1,?22131,?22131.0,?22131,?22131]
+I[9,?1,?651731,?651731.0,?651731,?651731]
-U[0,?1,?120837,?120837.0,?120837,?120837]
+U[0,?2,?566664,?283332.0,?120837,?445827]
+I[b,?1,?748659,?748659.0,?748659,?748659]
-U[7,?1,?387053,?387053.0,?387053,?387053]
+U[7,?2,?1058056,?529028.0,?387053,?671003]
4.дРэ:
РДГђвЛбл transformationЁЃ

28
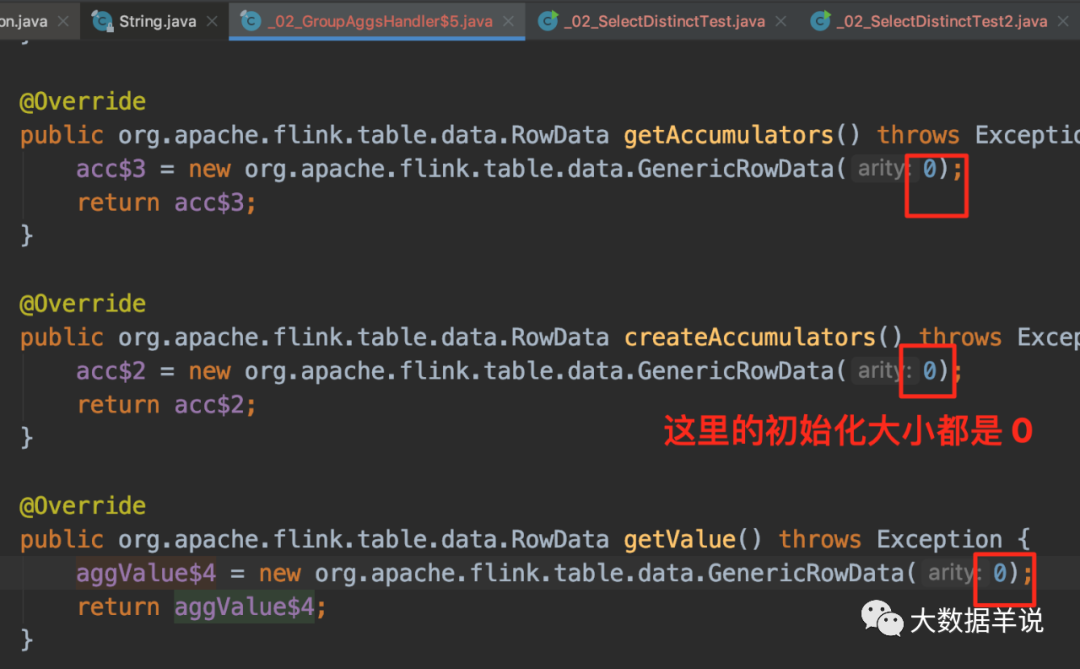
ЛЙЪЧКЭжЎЧАЕФТпМвЛбљ,ИњвЛЯТ GroupAggFunction ЕФТпМЁЃШчЯТЭМ,гаЮхИіжДааВНжшжДааМЦЫуЁЃ

33
дйПДзюжеЩњГЩЕФ function ДњТыТпМЁЃ
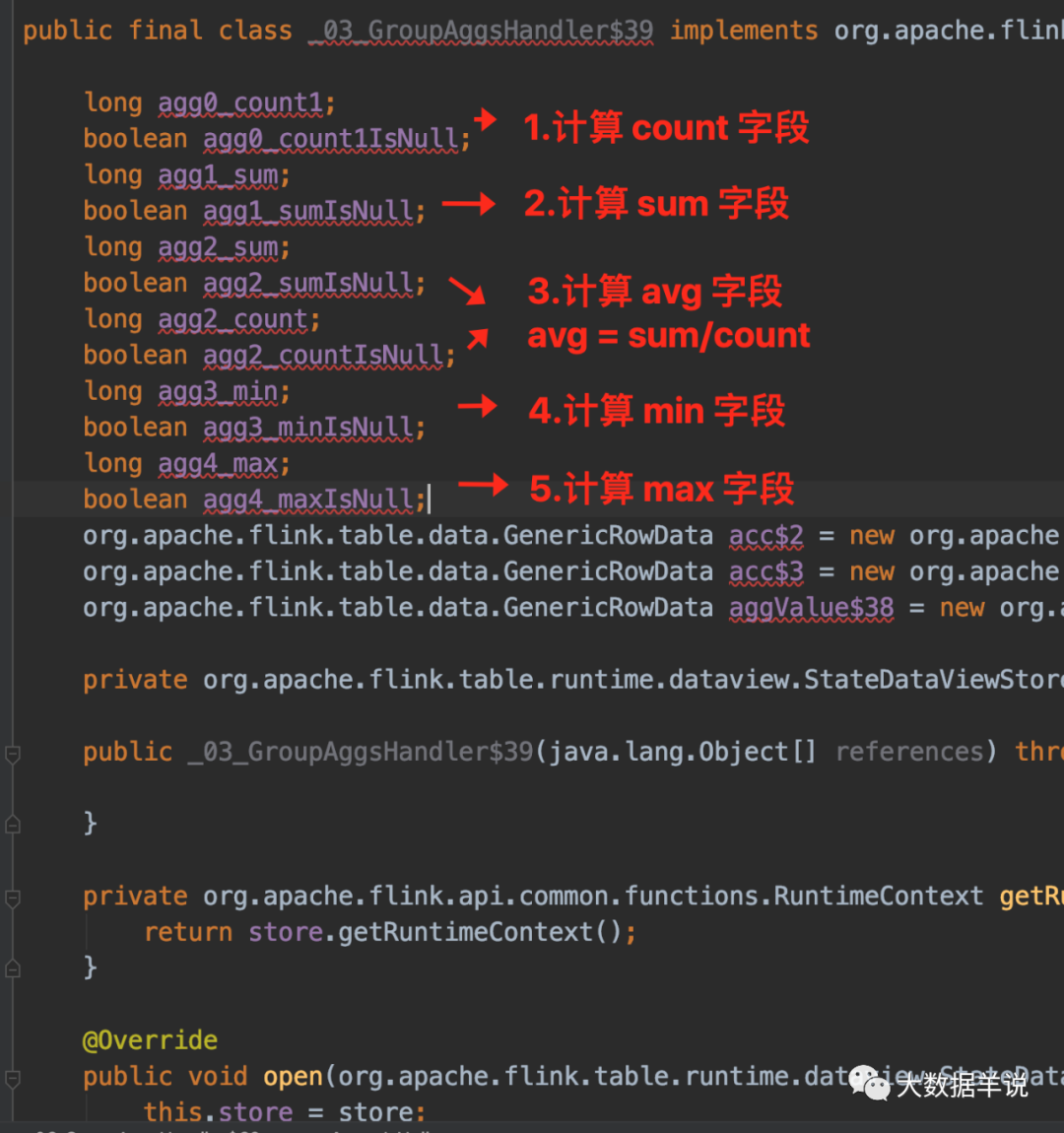
31
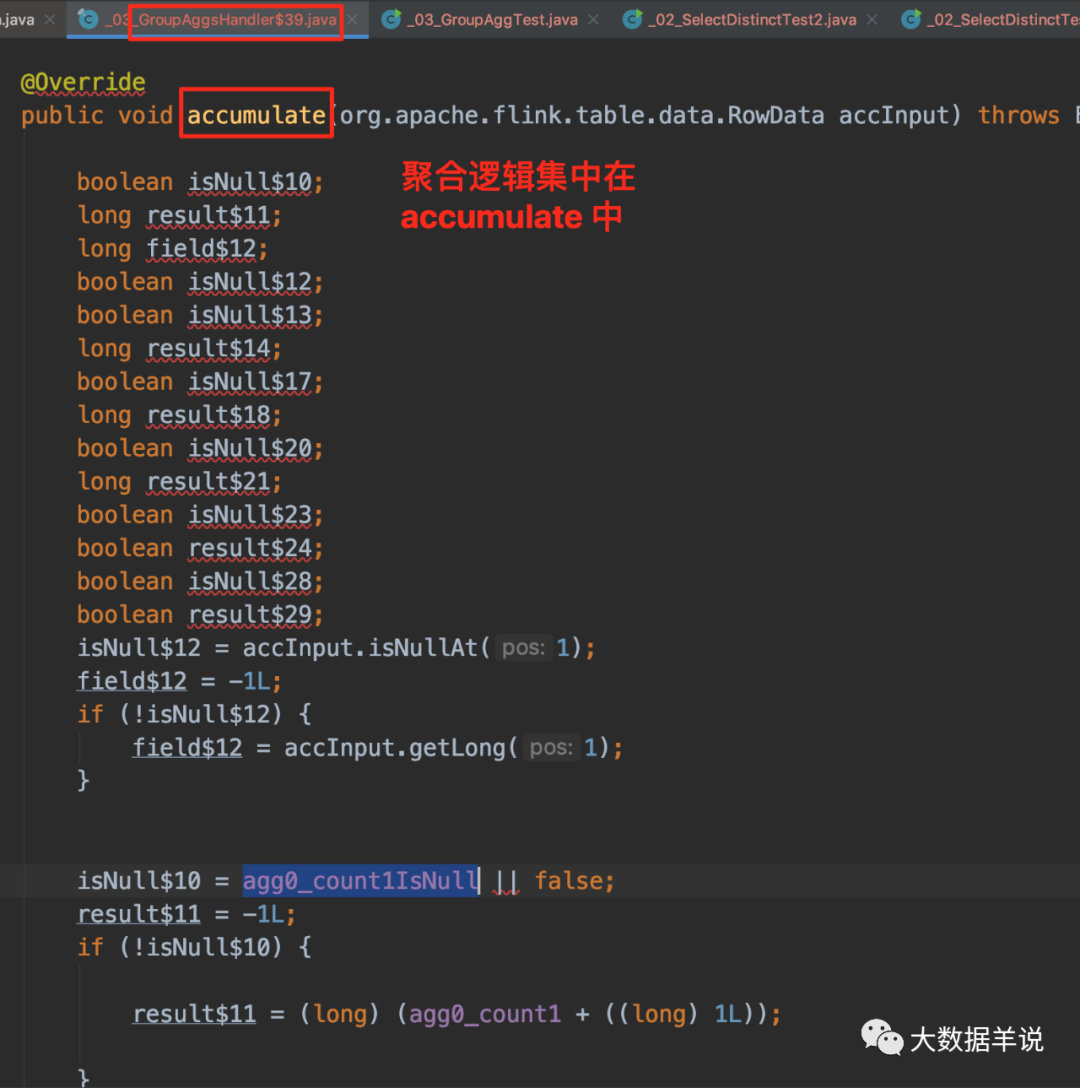
29
ЪзЯШПДПД count дѕУДЫуЕФЁЃ
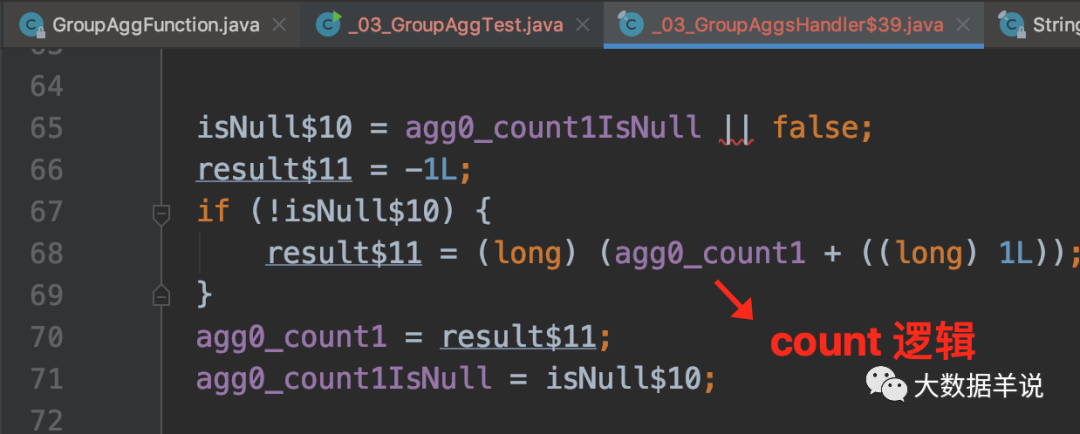
30
sum дѕУДЫуЕФЁЃ

32
4.2.3.2.ШЅжиОлКЯГЁОА
1.ГЁОА:ШЅжиОлКЯГЁОА
Ъ§ОндД:
CREATE?TABLE?source_table?(
????dim?STRING,
????user_id?BIGINT
)?WITH?(
??'connector'?=?'datagen',
??'rows-per-second'?=?'10',
??'fields.dim.length'?=?'1',
??'fields.user_id.min'?=?'1',
??'fields.user_id.max'?=?'1000000'
)
Ъ§ОнЛу:
CREATE?TABLE?sink_table?(
????dim?STRING,
????uv?BIGINT
)?WITH?(
??'connector'?=?'print'
)
Ъ§ОнДІРэ:
insert?into?sink_table
select?dim,
???????count(distinct?user_id)?as?uv
from?source_table
group?by?dim
2.дЫаа:
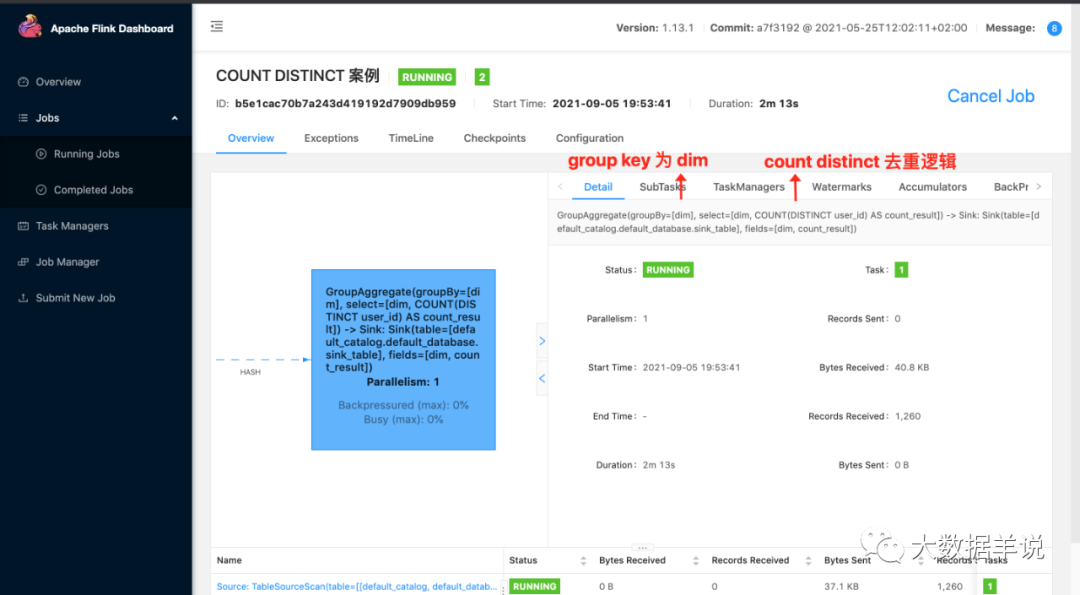
35
3.ЩЯУцетИіАИР§ЕФНсЙћ:
+U[9,?3097]
-U[a,?3054]
+U[a,?3055]
-U[8,?3030]
+U[8,?3031]
-U[4,?3137]
+U[4,?3138]
-U[6,?3139]
+U[6,?3140]
-U[0,?3082]
+U[0,?3083]
4.дРэ:
ДЫДІжЛПДКЭжЎЧАЕФАИР§ВЛвЛбљЕФЕиЗНЁЃ
4.2.3.3.гяЗЈЬЧ
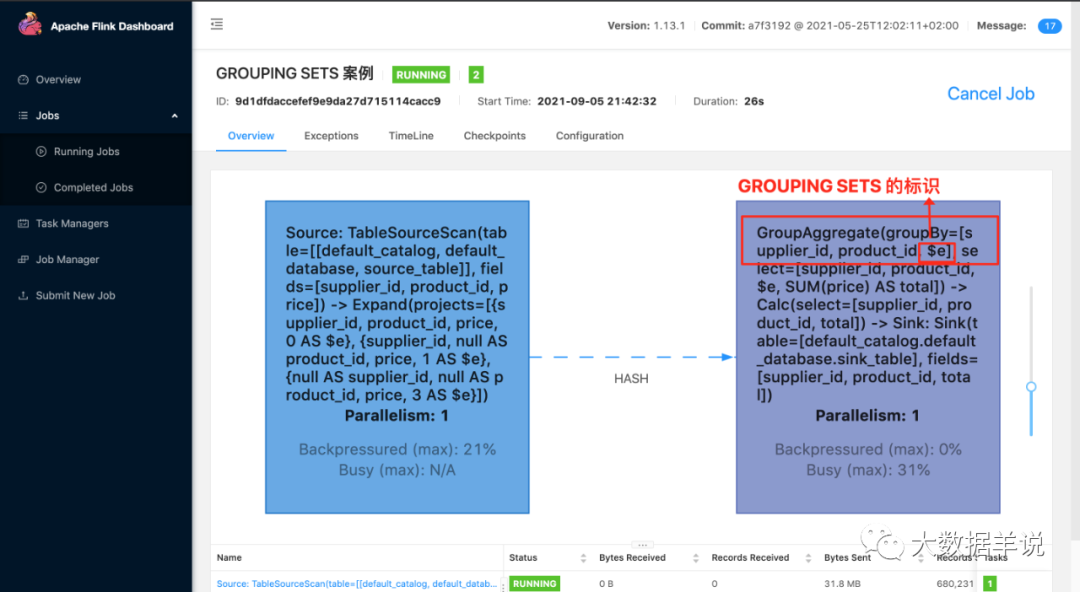
1.grouping sets
ЖрЮЌМЦЫуЁЃЯрЕБгкгяЗЈЬЧ,гУЛЇПЩвдИљОнздМКЕФГЁОАШЅжИЖЈздМКЯывЊЕФЮЌЖШзщКЯЁЃ
Ъ§ОнЛу:
CREATE?TABLE?sink_table?(
????supplier_id?STRING,
????product_id?STRING,
????total?BIGINT
)?WITH?(
??'connector'?=?'print'
)
Ъ§ОнДІРэТпМ:
insert?into?sink_table
SELECT
?????supplier_id,
?????product_id,
?????COUNT(*)?AS?total
FROM?(VALUES
?????('supplier1',?'product1',?4),
?????('supplier1',?'product2',?3),
?????('supplier2',?'product3',?3),
?????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
GROUP?BY?GROUPING?SETS?((supplier_id,?product_id),?(supplier_id),?())
ЦфНсЙћЕШЭЌгк:
insert?into?sink_table
SELECT
?????supplier_id,
?????product_id,
?????COUNT(*)?AS?total
FROM?(VALUES
?????('supplier1',?'product1',?4),
?????('supplier1',?'product2',?3),
?????('supplier2',?'product3',?3),
?????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
GROUP?BY?supplier_id,?product_id
UNION?ALL
SELECT
?????supplier_id,
?????cast(null?as?string)?as?product_id,
?????COUNT(*)?AS?total
FROM?(VALUES
?????('supplier1',?'product1',?4),
?????('supplier1',?'product2',?3),
?????('supplier2',?'product3',?3),
?????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
GROUP?BY?supplier_id
UNION?ALL
SELECT
?????cast(null?as?string)?AS?supplier_id,
?????cast(null?as?string)?AS?product_id,
?????COUNT(*)?AS?total
FROM?(VALUES
?????('supplier1',?'product1',?4),
?????('supplier1',?'product2',?3),
?????('supplier2',?'product3',?3),
?????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
НсЙћШчЯТ:
+I[supplier1,?product1,?1]
+I[supplier1,?null,?1]
+I[null,?null,?1]
+I[supplier1,?product2,?1]
-U[supplier1,?null,?1]
+U[supplier1,?null,?2]
-U[null,?null,?1]
+U[null,?null,?2]
+I[supplier2,?product3,?1]
+I[supplier2,?null,?1]
-U[null,?null,?2]
+U[null,?null,?3]
+I[supplier2,?product4,?1]
-U[supplier2,?null,?1]
+U[supplier2,?null,?2]
-U[null,?null,?3]
+U[null,?null,?4]
grouping sets ФмАяжњЮвУЧдкЖрЮЌГЁОАЯТ,МѕЩйКмЖрШпгрДњТыЁЃЙигк grouping sets дРэКѓУцЕФЯЕСаЮФеТЛсНщЩмЁЃ
38
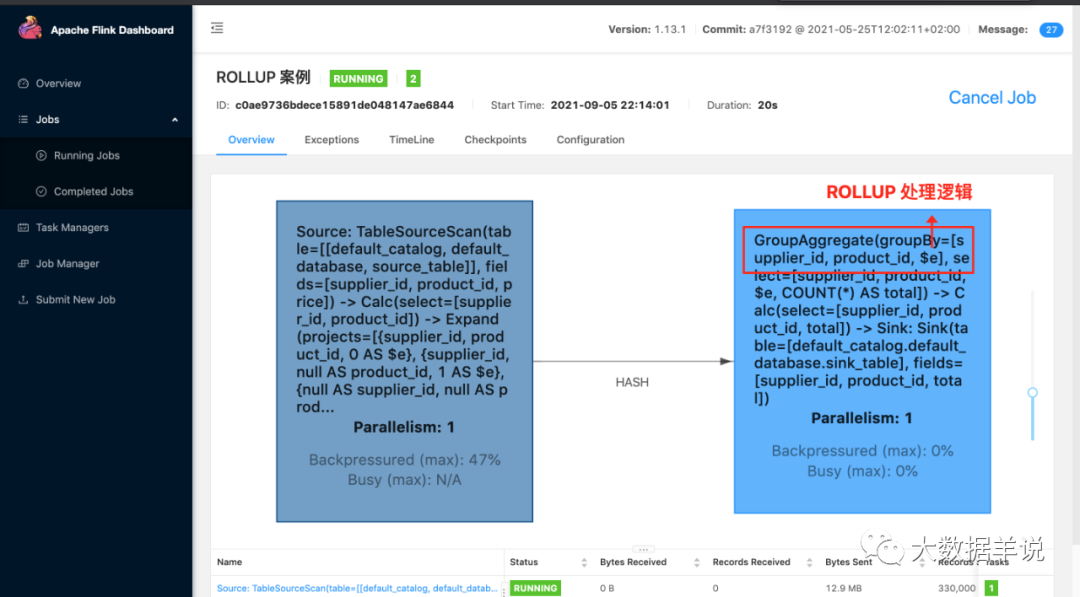
2.rollup
rollup ЪЧЩЯОэМЦЫуЕФвЛжжМђЛЏаДЗЈЁЃБШШчПЩвдАб GROUPING SETS ((supplier_id, product_id), (supplier_id), ()) МђЛЏЮЊ ROLLUP (supplier_id, product_id)ЁЃ
Ъ§ОнЛу:
CREATE?TABLE?sink_table?(
????supplier_id?STRING,
????product_id?STRING,
????total?BIGINT
)?WITH?(
??'connector'?=?'print'
)
Ъ§ОнДІРэТпМ:
SELECT?supplier_id,?rating,?COUNT(*)
FROM?(VALUES
????('supplier1',?'product1',?4),
????('supplier1',?'product2',?3),
????('supplier2',?'product3',?3),
????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
GROUP?BY?ROLLUP?(supplier_id,?product_id)
ЦфНсЙћЕШЭЌгк:
SELECT?supplier_id,?rating,?product_id,?COUNT(*)
FROM?(VALUES
????('supplier1',?'product1',?4),
????('supplier1',?'product2',?3),
????('supplier2',?'product3',?3),
????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
GROUP?BY?GROUPING?SET?(
????(?supplier_id,?product_id?),
????(?supplier_id?????????????),
????(?????????????????????????)
)
НсЙћШчЯТ:
+I[supplier1,?product1,?1]
+I[supplier1,?null,?1]
+I[null,?null,?1]
+I[supplier1,?product2,?1]
-U[supplier1,?null,?1]
+U[supplier1,?null,?2]
-U[null,?null,?1]
+U[null,?null,?2]
+I[supplier2,?product3,?1]
+I[supplier2,?null,?1]
-U[null,?null,?2]
+U[null,?null,?3]
+I[supplier2,?product4,?1]
-U[supplier2,?null,?1]
+U[supplier2,?null,?2]
-U[null,?null,?3]
+U[null,?null,?4]
39
5.CUBE МЦЫу
дДТыЙЋжкКХКѓЬЈЛиИДВЛЛсСЌзюЪЪКЯ flink sql ЕФ ETL КЭ group agg ГЁОАЖМУЛМћЙ§АЩЛёШЁЁЃ
cube ЯрЕБгкЪЧвЛжжИВИЧСЫЫљгаЮЌЖШзщКЯОлКЯМЦЫуЁЃБШШч group by a, b, cЁЃЦфЛсНЋ a, b, c Ш§ИіЮЌЖШЕФЫљгаЮЌЖШзщКЯНјаа group byЁЃ
Ъ§ОнЛу:
CREATE?TABLE?sink_table?(
????supplier_id?STRING,
????product_id?STRING,
????total?BIGINT
)?WITH?(
??'connector'?=?'print'
)
Ъ§ОнДІРэТпМ:
SELECT?supplier_id,?rating,?product_id,?COUNT(*)
FROM?(VALUES
????('supplier1',?'product1',?4),
????('supplier1',?'product2',?3),
????('supplier2',?'product3',?3),
????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
GROUP?BY?CUBE?(supplier_id,?product_id)
ЫќЕШЭЌгк
SELECT?supplier_id,?rating,?product_id,?COUNT(*)
FROM?(VALUES
????('supplier1',?'product1',?4),
????('supplier1',?'product2',?3),
????('supplier2',?'product3',?3),
????('supplier2',?'product4',?4))
AS?Products(supplier_id,?product_id,?rating)
GROUP?BY?GROUPING?SET?(
????(?supplier_id,?product_id?),
????(?supplier_id?????????????),
????(??????????????product_id?),
????(?????????????????????????)
)
НсЙћШчЯТ:
+I[supplier1,?product1,?1]
+I[supplier1,?null,?1]
+I[null,?product1,?1]
+I[null,?null,?1]
+I[supplier1,?product2,?1]
-U[supplier1,?null,?1]
+U[supplier1,?null,?2]
+I[null,?product2,?1]
-U[null,?null,?1]
+U[null,?null,?2]
+I[supplier2,?product3,?1]
+I[supplier2,?null,?1]
+I[null,?product3,?1]
-U[null,?null,?2]
+U[null,?null,?3]
+I[supplier2,?product4,?1]
-U[supplier2,?null,?1]
+U[supplier2,?null,?2]
+I[null,?product4,?1]
-U[null,?null,?3]
+U[null,?null,?4]

40
5.змНсгыеЙЭћЦЊ
БОЮФжївЊНщЩмСЫ ETL,group agg ОлКЯРржИБъЕФвЛаЉГЃМћГЁОААИР§вдМАЦфЕзВудЫаадРэЁЃЮвУЧПЩвдЗЂЯж flink sql ЕФгяЗЈЦфЪЕКЭ hive sql,mysql ЩЖЕФгяЗЈЖМЪЧЛљБОвЛжТЕФЁЃЫљвдЩЯЪж flink sql ЪБ,гяЗЈЛљБОВЛЛсГЩЮЊЮвУЧЕФеЯАЁЃ
ЖјЧввВНщЩмСЫдкВщПД flink sql ШЮЮёЪБЕФвЛаЉММЧЩ:
-
ШЅ flink webui ПДПДетИіШЮЮёФПЧАдкзіЪВУДЁЃАќРЈЫузгУћГЦЖМЛсИјжБНгеЙЪОИјЮвУЧФПЧАФФИіЫузгдкИЩЩЖЪТЧщ,дкДІРэЩЖТпМЁЃ
-
ШчЙћФуЯыжЊЕРФуЕФ flink ШЮЮёжДааСЫЪВУДДњТы,ОЭШЅПДПД sql зюКѓзЊЛЛГЩЕФ transformation РяУцОпЬхвЊжДааФФаЉВйзїЁЃ
КѓајЮФеТЛсМЬајНщЩм flink sql ДАПкОлКЯ,вЛаЉРэНтЮѓЧј,КЭПгжЎРрЕФАИР§ЁЃ
ЯЃЭћДѓМвФмГжајЙизЂЁЃжЇГжВЉжїЁЃЯВЛЖЕФЧыЙизЂ + Еудо + дйПДЁЃ
ЭљЦкЭЦМі
[
flink sql жЊЦфЫљвдШЛ(Сљ)| flink sql дМЛс calcite(ПДетЦЊОЭЙЛСЫ)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247489112&idx=1&sn=21e86dab0e20da211c28cd0963b75ee2&chksm=c1549aa0f62313b6674833cd376b2a694752a154a63532ec9446c9c3013ef97f2d57b4e2eb64&scene=21#wechat_redirect)
[
flink sql жЊЦфЫљвдШЛ(Юх)| здЖЈвх protobuf format
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488994&idx=1&sn=20236350b1c8cfc4ec5055687b35603d&chksm=c154991af623100c46c0ed224a8264be08235ab30c9f191df7400e69a8ee873a3b74859fb0b7&scene=21#wechat_redirect)
[
flink sql жЊЦфЫљвдШЛ(ЫФ)| sql api РраЭЯЕЭГ
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488788&idx=1&sn=0127fd4037788762a0401313b43b0ea5&chksm=c15499ecf62310fa747c530f722e631570a1b0469af2a693e9f48d3a660aa2c15e610653fe8c&scene=21#wechat_redirect)
[
flink sql жЊЦфЫљвдШЛ(Ш§)| здЖЈвх redis Ъ§ОнЛуБэ(ИНдДТы)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488720&idx=1&sn=5695e3691b55a7e40814d0e455dbe92a&chksm=c1549828f623113e9959a382f98dc9033997dd4bdcb127f9fb2fbea046545b527233d4c3510e&scene=21#wechat_redirect)
[
flink sql жЊЦфЫљвдШЛ(Жў)| здЖЈвх redis Ъ§ОнЮЌБэ(ИНдДТы)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488635&idx=1&sn=41817a078ef456fb036e94072b2383ff&chksm=c1549883f623119559c47047c6d2a9540531e0e6f0b58b155ef9da17e37e32a9c486fe50f8e3&scene=21#wechat_redirect)
[
flink sql жЊЦфЫљвдШЛ(вЛ)| source\sink дРэ
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488486&idx=1&sn=b9bdb56e44631145c8cc6354a093e7c0&chksm=c1549f1ef623160834e3c5661c155ec421699fc18c57f2c63ba14d33bab1d37c5930fdce016b&scene=21#wechat_redirect)
ИќЖр Flink ЪЕЪБДѓЪ§ОнЗжЮіЯрЙиММЪѕВЉЮФ,ЪгЦЕЁЃКѓЬЈЛиИД?ЁАflinkЁБ Лђ ЁАflink sqlЁБ?ЛёШЁЁЃ
ЕуИідо+дкПД,ИааЛФњЕФПЯЖЈ?👇