一、简述
hash就是经过一系列处理后将无限数据映射到有限位置中的一个过程。而redis中的hash相比于一般的hash的有点主要在于在缩/扩容方面,当hash需要扩容时,一般的hash操作将一次性将原先的所有数据移动到新的hash中,这样在数据量很大的情况下很耗时,对于redis单线程执行命令的服务器来说这样非常影响吞吐量。
所以redis的hash在扩容时,并不是一次性将原有数据迁移到扩容后的hash中,而是渐进式的,部分部分的迁移,这样将一次耗时平摊到多次查询上,或者无查询时通过定时任务继续进行迁移。缺点则是在扩容期间,查询需要两次,先在原先的hash中查询,没有查询到则到新hash中查询。
二、redis的hash结构
以redis6.06源码为例
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;

- 将具体的hash函数等操作函数独立出来, dictType类型,同一套底层代码,方便灵活
- hash节点entry中值是一个联合体,可以存各种数据值
- hash冲突时使用链式解决
- hash冲突时,头插法,刚插入的数据更容易被再次访问
- 在有子进程时,会禁止hash扩容,这样减少cow时的内存拷贝(但也不完全禁止,当hash使用率达到阈值一样要库容)
- 有两个hashtable,扩容时渐进式的数据迁移
三、实际例子
3.1 创建空的hash
/* Create a new hash table */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
/* Reset a hash table already initialized with ht_init().
* NOTE: This function should only be called by ht_destroy(). */
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
比如创建一个集合
dictType setDictType = {
dictSdsHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* key compare */
dictSdsDestructor, /* key destructor */
NULL /* val destructor */
};
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT;
return o;
}
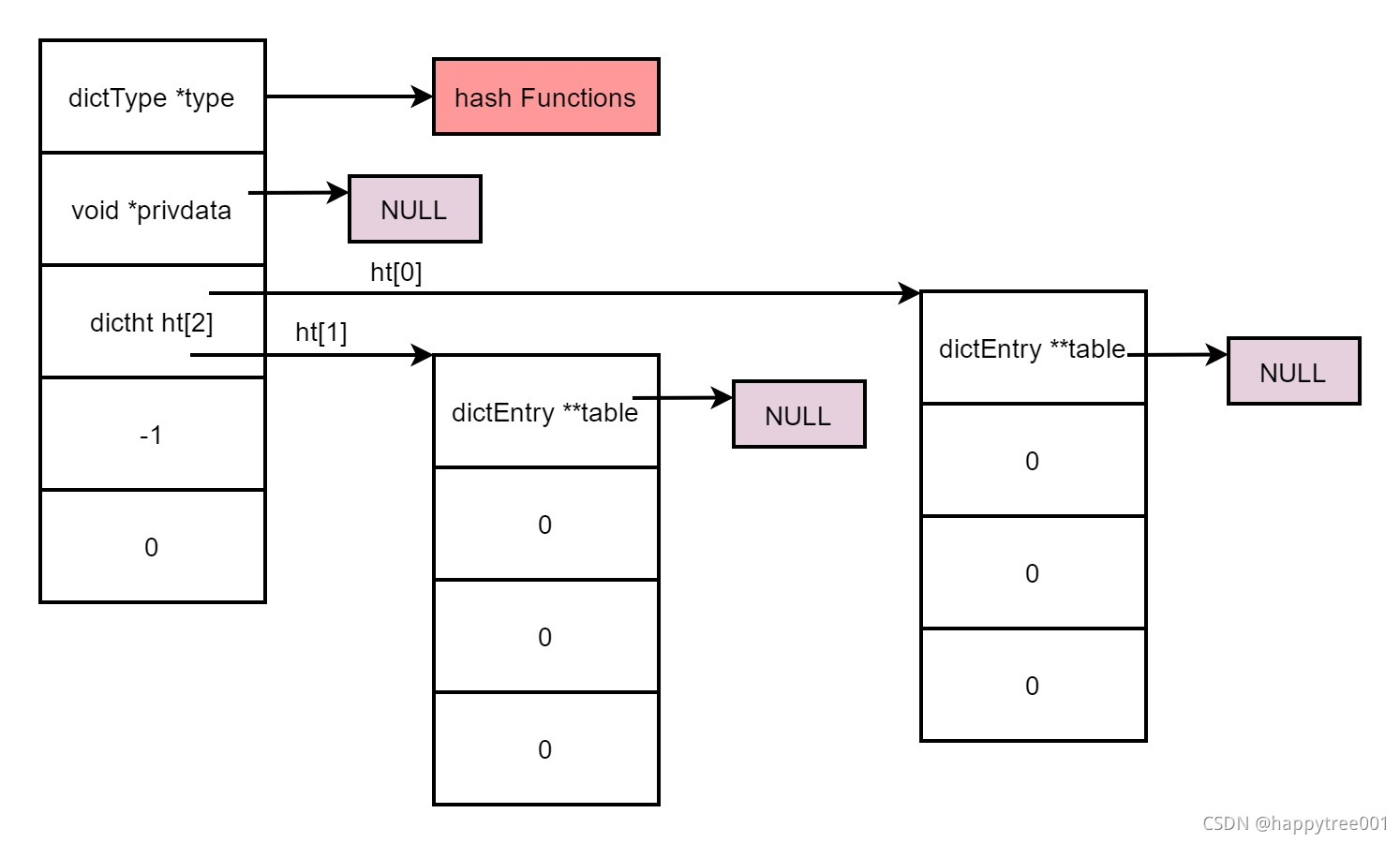
- 创建一个hash时,桶的个数为0
3.2 插入kv, “name”:“zhangsan”
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
- 先插入key
- 再赋值value
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
//如果正在扩容迁移,则处理一个桶的数据
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
//查找位置,如果key存在,则返回-1
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
//如果正在扩容迁移,则插入到ht[1]中,否则插入ht[0]
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
//头插法
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
查询插入桶的位置
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}
首先判断是否需要扩容
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
//增在扩容迁移,则返回
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
//如果ht[0].size ==0, 则表示是一个新的空的hash,直接扩容,4个大小的桶
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
//1. 当使用的个数达到hash桶的个数,并且未禁止hash扩容
//2. 当使用的个数达到hash桶的个数,禁止hash扩容,但是使用率已经超过dict_force_resize_ratio(5)
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
扩容策略 使用个数的2倍
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
//如果正在扩容,或者扩容大小小于已经使用的大小,则出错
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size); //将size进行2的指数对齐
/* Rehashing to the same table size is not useful. */
//如果扩容大小和已经使用大小一致,则库容无用,出错
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
//重新分配空间
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
//如果是一个空的hash,则直接赋值,退出
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
//将新的hash表赋值到ht[1]
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
大小对2的指数对齐
/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX + 1LU;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}

3.3替换
- key不存在则插入
- key存在则替换value
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, *existing, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will succeed. */
entry = dictAddRaw(d,key,&existing);
if (entry) {
dictSetVal(d, entry, val);
return 1;
}
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
auxentry = *existing;
dictSetVal(d, existing, val);
dictFreeVal(d, &auxentry);
return 0;
}
3.4 删除key
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}
3.5 根据key查询节点
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
3.6 根据key获取值
void *dictFetchValue(dict *d, const void *key) {
dictEntry *he;
he = dictFind(d,key);
return he ? dictGetVal(he) : NULL;
}
3.7 获取随机key
/* Return a random entry from the hash table. Useful to
* implement randomized algorithms */
dictEntry *dictGetRandomKey(dict *d)
{
dictEntry *he, *orighe;
unsigned long h;
int listlen, listele;
if (dictSize(d) == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
if (dictIsRehashing(d)) {
do {
/* We are sure there are no elements in indexes from 0
* to rehashidx-1 */
h = d->rehashidx + (random() % (d->ht[0].size +
d->ht[1].size -
d->rehashidx));
he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :
d->ht[0].table[h];
} while(he == NULL);
} else {
do {
h = random() & d->ht[0].sizemask;
he = d->ht[0].table[h];
} while(he == NULL);
}
/* Now we found a non empty bucket, but it is a linked
* list and we need to get a random element from the list.
* The only sane way to do so is counting the elements and
* select a random index. */
listlen = 0;
orighe = he;
while(he) {
he = he->next;
listlen++;
}
listele = random() % listlen;
he = orighe;
while(listele--) he = he->next;
return he;
}
3.8 生成hash指纹
/* A fingerprint is a 64 bit number that represents the state of the dictionary
* at a given time, it's just a few dict properties xored together.
* When an unsafe iterator is initialized, we get the dict fingerprint, and check
* the fingerprint again when the iterator is released.
* If the two fingerprints are different it means that the user of the iterator
* performed forbidden operations against the dictionary while iterating. */
long long dictFingerprint(dict *d) {
long long integers[6], hash = 0;
int j;
integers[0] = (long) d->ht[0].table;
integers[1] = d->ht[0].size;
integers[2] = d->ht[0].used;
integers[3] = (long) d->ht[1].table;
integers[4] = d->ht[1].size;
integers[5] = d->ht[1].used;
/* We hash N integers by summing every successive integer with the integer
* hashing of the previous sum. Basically:
*
* Result = hash(hash(hash(int1)+int2)+int3) ...
*
* This way the same set of integers in a different order will (likely) hash
* to a different number. */
for (j = 0; j < 6; j++) {
hash += integers[j];
/* For the hashing step we use Tomas Wang's 64 bit integer hash. */
hash = (~hash) + (hash << 21); // hash = (hash << 21) - hash - 1;
hash = hash ^ (hash >> 24);
hash = (hash + (hash << 3)) + (hash << 8); // hash * 265
hash = hash ^ (hash >> 14);
hash = (hash + (hash << 2)) + (hash << 4); // hash * 21
hash = hash ^ (hash >> 28);
hash = hash + (hash << 31);
}
return hash;
}
3.9 hash迭代
- 安全迭代过程中, hash不进行扩容迁移
- 否则不安全迭代过程中,hash可以继续迁移
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
i->safe = 1;
return i;
}
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
iter->d->iterators++;
else
iter->fingerprint = dictFingerprint(iter->d);
}
iter->index++;
if (iter->index >= (long) ht->size) {
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {
break;
}
}
iter->entry = ht->table[iter->index];
} else {
iter->entry = iter->nextEntry;
}
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
if (iter->safe)
iter->d->iterators--;
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
3.10 释放节点
void dictFreeUnlinkedEntry(dict *d, dictEntry *he) {
if (he == NULL) return;
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
3.11 hash销毁
/* Destroy an entire dictionary */
int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {
unsigned long i;
/* Free all the elements */
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (callback && (i & 65535) == 0) callback(d->privdata);
if ((he = ht->table[i]) == NULL) continue;
while(he) {
nextHe = he->next;
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
ht->used--;
he = nextHe;
}
}
/* Free the table and the allocated cache structure */
zfree(ht->table);
/* Re-initialize the table */
_dictReset(ht);
return DICT_OK; /* never fails */
}
/* Clear & Release the hash table */
void dictRelease(dict *d)
{
_dictClear(d,&d->ht[0],NULL);
_dictClear(d,&d->ht[1],NULL);
zfree(d);
}
3.12 缩容
- 桶个数大于4
- 使用率小于 10%
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}