����Ŀ¼
ǰ��
��λС����Һ�,�����Ϊ��˾���Թ�̬Ӳ�̻����ʹ�Ժ��Ǩ���Ȱ�ҵ�����,����һֱ�ȽϿ���;����ĩ����Һ�,������ôд��ר��������¸���λС�����һ����֪ʶ�ĺ�����������,�ú���֪ʶ�������Լ�������,����ȷ��������һƪ�dz�ȫ���HBase����,��ҿ���һ������������,����ص�������뷨����һ������ѧϰ��������˵,ֱ�ӿ�ʼ���ǽ��������,��������HBase�����о������ΰ�:
һ HBase���
HBase��һ���߿ɿ��ԡ������ܡ������С��������ķֲ�ʽ�洢ϵͳ,����HBase������������PC Server�ϴ����ģ�ṹ���洢��Ⱥ��
HBase��Ŀ���Ǵ洢���������͵�����,��������˵�ǽ���ʹ����ͨ��Ӳ������,���ܹ������ɳ�ǧ������к�������ɵĴ������ݡ�
HBase��Google Bigtable�Ŀ�Դʵ��,����Ҳ�к֮ܶͬ��������:Google Bigtable����GFS��Ϊ���ļ��洢ϵͳ,HBase����Hadoop HDFS��Ϊ���ļ��洢ϵͳ;Google����MAPREDUCE������Bigtable�еĺ�������,HBaseͬ������Hadoop MapReduce������HBASE�еĺ�������;Google Bigtable����Chubby��ΪЭͬ����,HBase����Zookeeper��Ϊ��Ӧ��������nosql��RDBMS֮��,����ͨ������(row key)��������range����������,��֧�ֵ�������(��ͨ��hive֧����ʵ�ֶ��join�ȸ��Ӳ���)����Ҫ�����洢�ǽṹ���Ͱ�ṹ������ɢ���ݡ�
HBase��mysql��oralce��db2��sqlserver�ȹ�ϵ�����ݿⲻͬ,����һ��NoSQL���ݿ�(�ǹ�ϵ�����ݿ�)
HBase�ı�ģ�����ϵ�����ݿ�ı�ģ�Ͳ�ͬ:
HBase��mysql��oralce��db2��sqlserver�ȹ�ϵ�����ݿⲻͬ,����һ��NoSQL���ݿ�(�ǹ�ϵ�����ݿ�)
HBase�ı�ģ�����ϵ�����ݿ�ı�ģ�Ͳ�ͬ:
HBase�ı�û�й̶����ֶζ���;
HBase�ı���ÿ�д洢�Ķ���һЩkey-value��;
Hbase�ı���������Ļ���,�û�����ָ������Щkv�����ĸ�����;
Hbase�ı��������洢��,�ǰ����������ָ��,��ͬ���������һ���洢�ڲ�ͬ���ļ���;
Hbase�ı��е�ÿһ�ж��̶���һ���м�,����ÿһ�е��м��ڱ��в����ظ�;
Hbase�е�����,�����м�,����key,����value,����byte[ ]����,hbase������Ϊ�û�ά����������;
HBASE�������֧�ֺܲ�;
HBASE���������nosql���ݿ�(mongodb��redis��cassendra��hazelcast)���ص�:
Hbase�ı����ݴ洢��HDFS�ļ�ϵͳ��,����,hbase�߱���������:
�����洢
��ʽ�洢
���ݴ洢�İ�ȫ�Կɿ��Լ���
֧�ָ߲���
�洢��������������չ
�� HBase��������ģ��

1 rowkey�м�
table������,table�еļ�¼����rowkey ���ֵ����������
Row key�м������������ַ���(����� 64KB,ʵ��Ӧ���г���һ��Ϊ 10-100bytes)
2 Column Family����
������д�
HBase���е�ÿ����,��������ij������
�����DZ���schema��һ����(���в���),������ʱ����ָ��һ������
���紴��һ�ű�,��Ϊuser,����������,�ֱ���info��data,�������create ��user��, ��info��, ��data��
3 Column��
�п϶��DZ���ijһ�����µ�һ����,��������:������ʾ,��info�����µ�name��,��ʾΪinfo:name
����ijһ��ColumnFamily,����������mysql���д����ľ������
4 cell��Ԫ��
ָ��row key�м������塢��,����ȷ����һ��cell��Ԫ��
cell�е�������û�����͵�,ȫ�������ֽ�������д洢

5 Timestampʱ���
���ԶԱ��е�Cell��θ�ֵ,ÿ�θ�ֵ����ʱ��ʱ���timestamp,�ɿ���Cellֵ�İ汾��version number;��һ��Cell�����ж���汾��ֵ
�� HBase����ܹ�
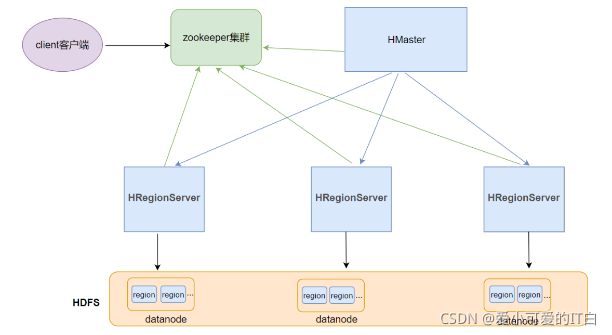
1 Client�ͻ���
Client�Dz���HBase��Ⱥ�����;
���ڹ�����IJ���,���������ɾ���IJ���,Clientͨ��RPC��HMasterͨ�����;
���ڱ����ݵĶ�д����,Clientͨ��RPC��RegionServer����,��д����
Client����:
HBase shell
Java��̽ӿ�
Thrift��Avro��Rest�ȵ�
2 ZooKeeper��Ⱥ
����:
ʵ����HMaster�ĸ߿���,��HMaster���������ѡ��;
������HBase��Ԫ������Ϣmeta��,�ṩ��HBase����region��Ѱַ��ڵ���������;
��HMaster��HRegionServerʵ���˼��;
3 HMaster
HBase��ȺҲ�����Ӽܹ�,HMaster�����Ľ�ɫ,���ϴ�
��Ҫ����Table����Region����ع�������:
����Table
����Client��Table����ɾ�ĵIJ���
����Region
��Region���Ѻ�,������Region���䵽ָ����HRegionServer��
����HRegionServer��ĸ��ؾ���,Ǩ��region�ֲ�
��HRegionServer崻���,�������ϵ�region��Ǩ��
4 HRegionServer
HBase��Ⱥ�дӵĽ�ɫ,��С��
����:
��Ӧ�ͻ��˵Ķ�д��������
�������һϵ�е�Region
�����������region
5 Region
HBase��Ⱥ�зֲ�ʽ�洢����С��Ԫ
һ��Region��Ӧһ��Table���IJ�������
HBaseʹ��,��Ҫ��������ʽ:������;��Java���
�� HBase��װ
HBASE��һ���ֲ�ʽϵͳ
������һ��������ɫ:HMaster(һ��2̨,һ̨active,һ̨backup)
���������ݽڵ��ɫ:HRegionServer(�ܶ�̨,��������)
1 ��װ��
��Ҫ����һ��java����
����,Ҫ��һ��HDFS��Ⱥ,����������;regionserverӦ�ø�hdfs�е�datanode��һ��
���,����Ҫһ��zookeeper��Ⱥ,����������,Ȼ��,��װHBase
��ɫ��������:
Hdp01: namenode datanode regionserver hmaster zookeeper
Hdp02: datanode regionserver zookeeper
Hdp03: datanode regionserver zookeeper
2 ��װ����
��ѹHBase��װ��
��hbase-env.sh
export JAVA_HOME=/root/apps/jdk1.7.0_67
export HBASE_MANAGES_ZK=false
��hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdp01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hdp01:2181,hdp02:2181,hdp03:2181</value>
</property>
</configuration>
�� regionservers
hdp01
hdp02
hdp03
3 ����HBase��Ⱥ
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/start-hbase.sh
�������,�������ڼ�Ⱥ��������һ̨��������һ�����õ�master
bin/hbase-daemon.sh start master
���������master�ᴦ��backup״̬
4 ֹͣHBase��Ⱥ
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/stop-hbase.sh
�� HBase shell �����������
1 ����HBase�ͻ��������������
node01ִ����������,����HBase��shell�ͻ���
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/hbase shell

���������ͼ��ʾ���,˵��HBaseδ��������
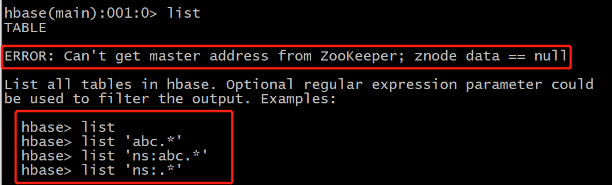
����Ϊ��������ҳ��,��������ؽ���
�� list�鿴��ǰ���ݿ�������Щ��

�� �鿴HBase��Ⱥ״̬

�� �鿴HBase��Ⱥ�汾

ps:NameSpace����
HBaseϵͳĬ�϶���������ȱʡ��namespace
hbase:ϵͳ�ڽ���,����namespace��meta��
default:�û�����ʱδָ��namespace�ı��������ڴ�
����:create_namespace 'lzc'
ɾ��:drop_namespace 'lzc'
�鿴:describe_namespace 'lzc'
�����:list_namespace
��namespace�´�����:create 'lzc:user_info','id','name','age'
�鿴namespace�µı� :list_namespace_tables 'lzc'
2 HBase��ģ���ص�

1.һ����,�б���
2.һ�������Է�Ϊ�������(��ͬ��������ݻ�洢�ڲ�ͬ�ļ���)
3.���е�ÿһ����һ�����м�rowkey��,�����м��ڱ��в����ظ�
4.���е�ÿһ��kv���ݳ���һ��cell
5.hbase���Զ����ݴ洢�����ʷ�汾(��ʷ�汾����������)
6.���ű���������������,�ᱻ�����зֳ����ɸ�region(��rowkey��Χ��ʶ),��ͬregion������Ҳ�洢�ڲ�ͬ�ļ���

7.hbase��Բ�������ݰ�˳��洢:
Ҫ��һ:���Ȼᰴ�м�����
Ҫ���:ͬһ�������kv�ᰴ��������,�ٰ�k����
3 HBase��������
hbase��ֻ֧��byte[]
�˴���byte[] ������:rowkey,key,value,������,����
4 HBase�������
| ���� | �������ʽ |
|---|---|
| ������ | create ��������, ��������1��,��������2��,��������N�� |
| �鿴���б� | list |
| ������ | describe �������� |
| �жϱ����� | exists �������� |
| �ж��Ƿ�������ñ� | is_enabled �������� is_disabled �������� |
| ���Ӽ�¼ | put ��������, ��rowKey��, ������ : �С� , ��ֵ�� |
| �鿴��¼rowkey�µ��������� | get �������� , ��rowKey�� |
| �鿴���еļ�¼���� | count �������� |
| ��ȡij������ | get ��������,��rowkey��,�����塯 |
| ��ȡij�������ij���� | get ��������,��rowkey��,'����:�С� |
| ɾ����¼ | delete �������� ,�������� , ������:�С� |
| ɾ������ | deleteall ��������,��rowkey�� |
| ɾ��һ�ű� | ��Ҫ���θñ�,���ܶԸñ�����ɾ�� ��һ�� disable �������� ,�ڶ��� drop �������� |
| ��ձ� | truncate �������� |
| �鿴���м�¼ | scan �������� |
| �鿴ij����ij�������������� | scan �������� , {COLUMNS=>��������:������} |
| ���¼�¼ | ������дһ��,���и���,hbaseû����,������ |
�� help ��������
hbase(main):005:0> help
�鿴��������İ�����Ϣ
hbase(main):006:0> help ��create��
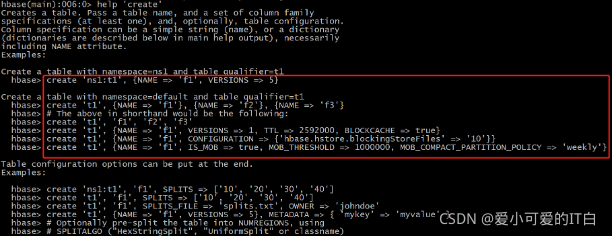
�� create ������
����user��,����info��data��������
ʹ��create����
hbase(main):008:0> create ��user��, ��info��, ��data��
0 row(s) in 1.3080 seconds
����
=> Hbase::Table - user
hbase(main):009:0> create ��user��,{NAME => ��info��, VERSIONS => ��3��},{NAME => ��data��}
ERROR: Table already exists: user!

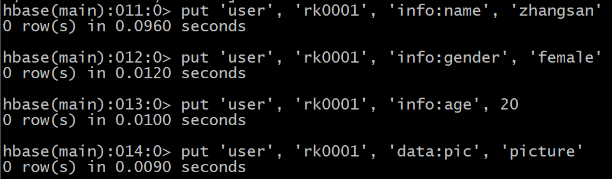
�� put �������ݲ���
����������
ʹ��put����
��user���в�����Ϣ,row keyΪrk0001,����info��������Ϊname����,ֵΪzhangsan
HBase(main):011:0> put ��user��, ��rk0001��, ��info:name��, ��zhangsan��
��user���в�����Ϣ,row keyΪrk0001,����info��������Ϊgender����,ֵΪfemale
HBase(main):012:0> put ��user��, ��rk0001��, ��info:gender��, ��female��
��user���в�����Ϣ,row keyΪrk0001,����info��������Ϊage����,ֵΪ20
HBase(main):013:0> put ��user��, ��rk0001��, ��info:age��, 20
��user���в�����Ϣ,row keyΪrk0001,����data��������Ϊpic����,ֵΪpicture
HBase(main):014:0> put ��user��, ��rk0001��, ��data:pic��, ��picture��
�� ��ѯ���ݲ���һ
��ѯ��ʽһ ʹ��get����ͨ��rowkey���в�ѯ
��ȡuser����row keyΪrk0001��������Ϣ(������cell������)
ʹ��get����
HBase(main):015:0> get ��user��, ��rk0001��

ʹ��get����鿴rowkey��ij���������Ϣ
��ȡuser����row keyΪrk0001,info�����������Ϣ
HBase(main):016:0> get ��user��, ��rk0001��, ��info��

ʹ��get����鿴rowkeyָ������ָ���ֶε�ֵ
��ȡuser����row keyΪrk0001,info�����name��age�е���Ϣ
HBase(main):017:0> get ��user��, ��rk0001��, ��info:name��, ��info:age��


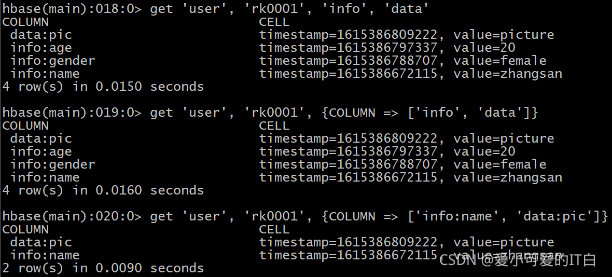
ʹ��get����鿴rowkeyָ������������Ϣ
��ȡuser����row keyΪrk0001,info��data�������Ϣ
HBase(main):018:0> get ��user��, ��rk0001��, ��info��, ��data��
������Ҳ��������д
HBase(main):019:0> get ��user��, ��rk0001��, {COLUMN => [��info��, ��data��]}
������Ҳ��������д,Ҳ��
HBase(main):020:0> get ��user��, ��rk0001��, {COLUMN => [��info:name��, ��data:pic��]}
ʹ��get����ָ��rowkey����ֵ��������ѯ
��ȡuser����row keyΪrk0001,cell��ֵΪzhangsan����Ϣ
HBase(main):021:0> get ��user��, ��rk0001��, {FILTER => ��ValueFilter(=, ��binary:zhangsan��)��}

ʹ��get����ָ��rowkey������ģ����ѯ
��ȡuser����row keyΪrk0001,�б�ʾ���к���a����Ϣ
HBase(main):022:0> get ��user��, ��rk0001��, {FILTER => ��QualifierFilter(=,��substring:a��)��}

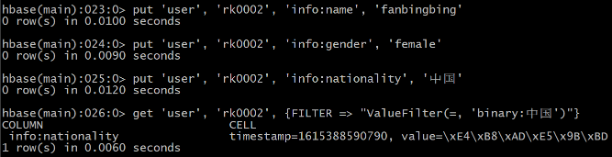
��������һ������
HBase(main):023:0> put ��user��, ��rk0002��, ��info:name��, ��fanbingbing��
HBase(main):024:0> put ��user��, ��rk0002��, ��info:gender��, ��female��
HBase(main):025:0> put ��user��, ��rk0002��, ��info:nationality��, �����
HBase(main):026:0> get ��user��, ��rk0002��, {FILTER => ��ValueFilter(=, ��binary:���)��}
�� ��ѯ�����е����ݶ�
��ѯuser���е�������Ϣ
ʹ��scan����
HBase(main):027:0> scan ��user��

ʹ��scan������������ѯ
��ѯuser��������Ϊinfo����Ϣ
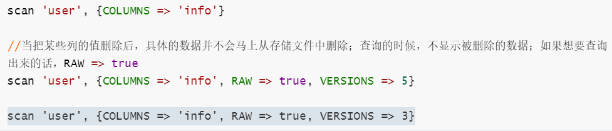
scan ��user��, {COLUMNS => ��info��}

//����ijЩ�е�ֵɾ����,��������ݲ��������ϴӴ洢�ļ���ɾ��;��ѯ��ʱ��,����ʾ��ɾ��������;�����Ҫ��ѯ�����Ļ�,RAW => true
scan ��user��, {COLUMNS => ��info��, RAW => true, VERSIONS => 5}

scan ��user��, {COLUMNS => ��info��, RAW => true, VERSIONS => 3}

ʹ��scan������ж������ѯ
��ѯuser��������Ϊinfo��data����Ϣ
scan ��user��, {COLUMNS => [��info��, ��data��]}

ʹ��scan����ָ��������ij��������ѯ
��ѯuser��������Ϊinfo���б�ʾ��Ϊname����Ϣ
scan ��user��, {COLUMNS => ��info:name��}

��ѯinfo:name�С�data:pic�е�����
scan ��user��, {COLUMNS => [��info:name��, ��data:pic��]}

��ѯuser��������Ϊinfo���б�ʾ��Ϊname����Ϣ,���Ұ汾���µ�5��
scan ��user��, {COLUMNS => ��info:name��, VERSIONS => 5}

ʹ��scan����ָ���������������ģ����ѯ
��ѯuser��������Ϊinfo��data���б�ʾ���к���a�ַ�����Ϣ
scan ��user��, {COLUMNS => [��info��, ��data��], FILTER => ��QualifierFilter(=,��substring:a��)��}

ʹ��scan����ָ��rowkey�ķ�Χ��ѯ
��ѯuser��������Ϊinfo,rk��Χ��[rk0001, rk0003)������
scan ��user��, {COLUMNS => ��info��, STARTROW => ��rk0001��, ENDROW => ��rk0003��}

ʹ��scan����ָ��rowkeyģ����ѯ
��ѯuser����row key��rk�ַ���ͷ������

ʹ��scan����ָ�����ݰ汾�ķ�Χ��ѯ
��ѯuser����ָ����Χ������(ǰ�պ�)
scan ��user��, {TIMERANGE => [1392368783980, 1392380169184]}

hbase(main):039:0> scan ��user��, {TIMERANGE => [1615386788707,1615386809222]}

�� �������ݲ���
1 ��������ֵ
���²���ͬ�������һģһ��,ֻ���������ݾ���,û���ݾ�����
ʹ��put����
2 ���°汾��
��user����f1����汾����Ϊ5
HBase(main):040:0> alter ��user��, NAME => ��info��, VERSIONS => 5

�� ɾ�������Լ�ɾ��������
1 ָ��rowkey�Լ���������ɾ��
ɾ��user��row keyΪrk0001,�б�ʾ��Ϊinfo:name������(ɾ��һ��kv����)
HBase(main):041:0> delete ��user��, ��rk0001��, ��info:name��

ɾ����������
hbase(main):024:0> deleteall 't_user_info','001'
0 row(s) in 0.0090 seconds
hbase(main):025:0> get 't_user_info','001'
COLUMN CELL
0 row(s) in 0.0110 seconds
2 ָ��rowkey,�����Լ��汾�Ž���ɾ��
ɾ��user��row keyΪrk0001,�б�ʾ��Ϊinfo:name,timestampΪ1392383705316������
hbase(main):042:0> delete ��user��, ��rk0001��, ��info:name��, 1392383705316

3 ɾ��һ������
ɾ��һ������:
alter ��user��, NAME => ��info��, METHOD => ��delete��
�� alter ��user��, ��delete�� => ��info��

4 ��ձ�����
HBase(main):045:0> truncate ��user��

5 ɾ����
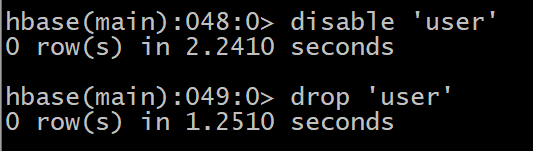
������Ҫ���øñ�Ϊdisable״̬,ʹ������:
HBase(main):049:0> disable ��user��
Ȼ��ʹ��drop����ɾ�������
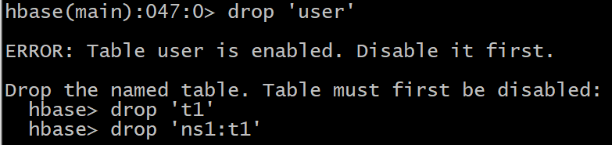
HBase(main):050:0> drop ��user��
(ע��:���ֱ��drop��,�ᱨ��:Drop the named table. Table must first be disabled)
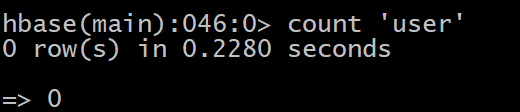
�� ͳ��һ�ű��ж���������
HBase(main):046:0> count ��user��
�� HBase�ĸ�shell��������
1 status
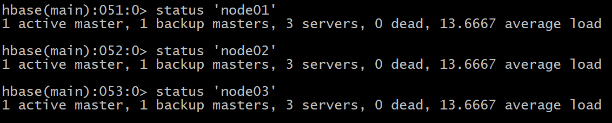
����:��ʾ������״̬
HBase(main):051:0> status ��node01��
2 whoami
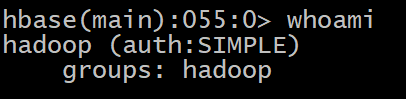
��ʾHBase��ǰ�û�,����:
HBase> whoami
3 list
��ʾ��ǰ���еı�
HBase > list

4 count
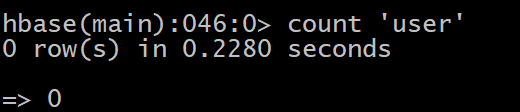
ͳ��ָ�����ļ�¼��,����:
HBase> count ��user��
Ϊ��չʾ���湦��,Ȼ�����´���user��,����������
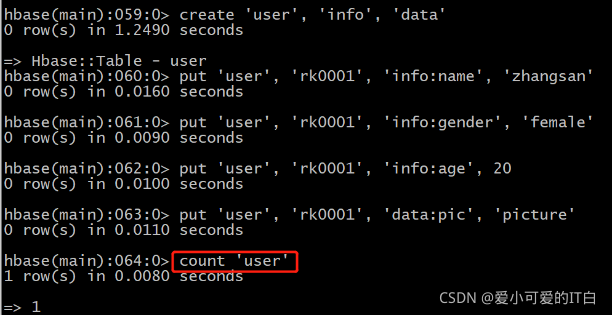
����user��,����info��data��������
ʹ��create����
hbase(main):008:0> create 'user', 'info', 'data'
0 row(s) in 1.3080 seconds
����������
ʹ��put����
��user���в�����Ϣ,row keyΪrk0001,����info��������Ϊname����,ֵΪzhangsan
HBase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
��user���в�����Ϣ,row keyΪrk0001,����info��������Ϊgender����,ֵΪfemale
HBase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female'
��user���в�����Ϣ,row keyΪrk0001,����info��������Ϊage����,ֵΪ20
HBase(main):013:0> put 'user', 'rk0001', 'info:age', 20
��user���в�����Ϣ,row keyΪrk0001,����data��������Ϊpic����,ֵΪpicture
HBase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'
5 describe
չʾ���ṹ��Ϣ
HBase> describe ��user��

6 exists
�����Ƿ����,�����ڱ����ر������
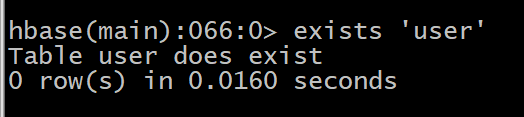
7 is_enabled��is_disabled
�����Ƿ����û����
HBase> is_enabled ��user��
HBase> is_disabled ��user��
8 alter
��������Ըı���������ģʽ,����:
Ϊ��ǰ����������:
HBase> alter ��user��, NAME => ��CF2��, VERSIONS => 2

Ϊ��ǰ��ɾ������:
HBase(main):002:0> alter ��user��, ��delete�� => ��CF2��

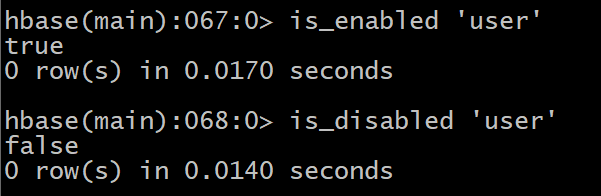
9 disable/enable
����һ�ű�/����һ�ű�
HBase> disable ��user��
HBase> enable ��user��
10 drop
ɾ��һ�ű�,�ǵ���ɾ����֮ǰ�����Ƚ���
11 truncate
���ñ�-ɾ����-������
�� Hive��HBase�ļ���
Hive�ṩ����HBase�ļ���,ʹ���ܹ���HBase����ʹ?HQL����?��
ѯ ��?�����Լ���?Join��Union�ȸ��Ӳ�ѯ��ͬʱҲ���Խ�hive���е�
����ӳ�䵽Hbase�С�
�汾˵��:
? hbase�汾:hbase-1.2.0-cdh5.14.2
? hive�汾:hive-1.1.0-cdh5.14.2
����ģ��:
row,addres,age,username
001,guangzhou,20,alex
002,shenzhen,34,jack
003,beijing,23,lili
����HBase������:
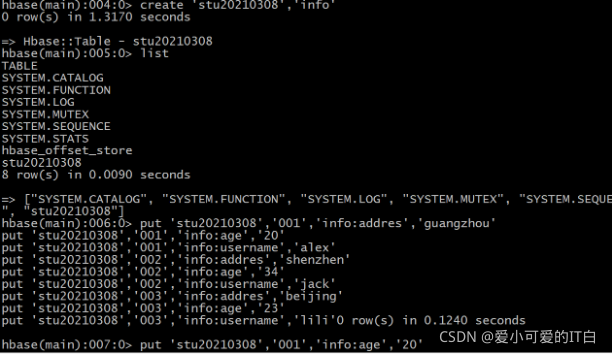
create 'stu20210308','info'
put 'stu20210308','001','info:addres','guangzhou'
put 'stu20210308','001','info:age','20'
put 'stu20210308','001','info:username','alex'
put 'stu20210308','002','info:addres','shenzhen'
put 'stu20210308','002','info:age','34'
put 'stu20210308','002','info:username','jack'
put 'stu20210308','003','info:addres','beijing'
put 'stu20210308','003','info:age','23'
put 'stu20210308','003','info:username','lili'
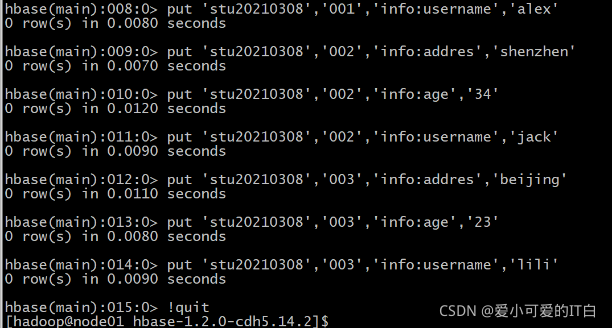
ps:�˳�HBASEָ����!quit
������HBase���ɵ�Hive���ⲿ��:
CREATE EXTERNAL TABLE stu20210308(
id string,
addres string,
age string,
username string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" =
":key,info:addres,info:age,info:username")
TBLPROPERTIES ("hbase.table.name" = "stu20210308");
hive (test)> CREATE EXTERNAL TABLE stu20210308(
> id string,
> addres string,
> age string,
> username string)
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES (
> "hbase.columns.mapping" =
> ":key,info:addres,info:age,info:username")
> TBLPROPERTIES ("hbase.table.name" = "stu20210308");
OK
Time taken: 1.933 seconds
hive (test)> select * from stu20210308;
OK
stu20210308.id stu20210308.addres stu20210308.age stu20210308.username
001 guangzhou 20 alex
002 shenzhen 34 jack
003 beijing 23 lili
Time taken: 0.09 seconds, Fetched: 3 row(s)
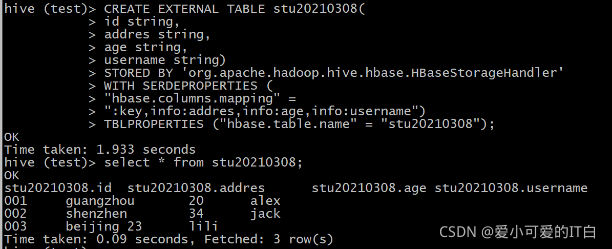
ps:��������ɲ鿴Hive��HBase�ļ���
Hive��ӳ��HBaseʵ����
��HBase��
hbase(main):018:0> create ��user_info��,��info��
���ݲ���HBase
info:order_amt
info:order_id
info:user_id
info:user_name
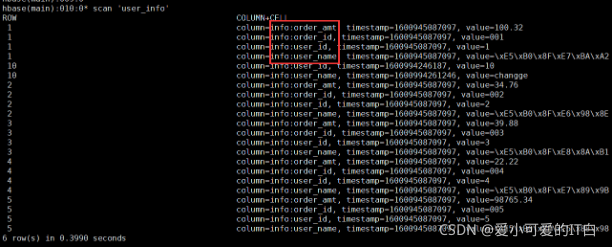
��hiveӳ���
create external table wedw_tmp.t_user_info
(
id string
,order_id string
,order_amt string
,user_id string
,user_name string
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping"=":key,info:order_id,info:order_amt,info:user_id,info:user_name")
tblproperties("hbase.table.name"="user_info");
��ѯӳ��õ�hive��
select * from wedw_tmp.t_user_info;
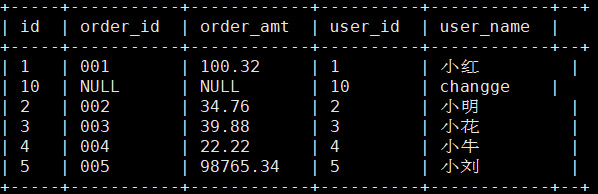
�� HBase�ͻ���API����
������
��������
ɾ������
ȫ��ɨ��
������
ƥ��
�� phoenix����HBase
Phoenix,��saleforce.com ��Դ��һ����Ŀ,���־����Apache�����൱��һ��Java �м��,����������,��
ʹ��jdbc ���ʹ�ϵ�����ݿ�һ��,����NoSql ���ݿ�HBase��
Apache Phoenix ������Hadoop ��Ʒ��ȫ����,��Spark,Hive,Pig,Flume ��MapReduce��
1 ��װpheonix
1.1 ����pheonix
http://phoenix.apache.org/download.html
ע��:����Phoenix ��ʱ��,��ע���Ӧ�İ汾,����4.14 �汾����������HBase0.98��1.1��1.2��1.3��1.4 �ϡ�
����ʱҲ����ֱ��ʹ��:
wget http://mirrors.shu.edu.cn/apache/phoenix/apache-phoenix-4.14.0-HBase-1.2/bin/apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz
1.2 ��ѹpheonix
tar -zxvf apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz
1.3 ����phoenix��hbase
�鿴Phoenix �µ����е��ļ�,��phoenix-4.14.0-HBase-1.2-server.jar ����������HBase �ڵ�(����Hmaster�Լ�HregionServer)��lib Ŀ¼��:
����HBase:
bin/stop-hbase.sh
bin/start-hbase.sh
1.4 ʹ��phoenix SQL������
����Phoenix �İ�װ��,ִ��:
bin/sqlline.py bigdata1:2181
1.4.1 ������
��Phoenix �ն��´���us_population ��:
>> CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
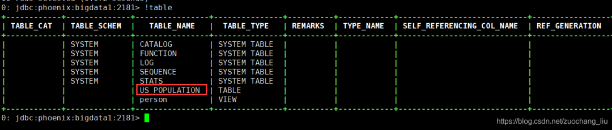
ʹ��!tables �鿴�����ı�:
>> !tables
1.4.2 �༭����������
��Phoenix Ŀ¼�´���һ��data Ŀ¼,��data Ŀ¼�´���:
vi us_population.csv
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
ִ��bin/psql.py data/us_population.csv �������ݡ�
���˵���������,������ʹ��Phoenix �����������:upsert into us_population values(��NY��,��NewYork��,8143197);
1.4.3 ��ѯ����
��ʽһ:��data Ŀ¼�´���us_population_queries.sql �ļ�:
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
ִ��bin/psql.py data/us_population_queries.sql �������ݡ�
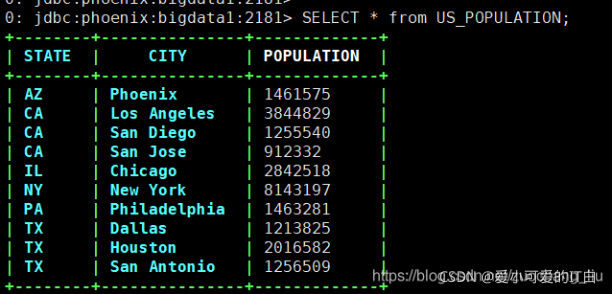
��ʽ��:ʹ���������ն�
bin/sqlline.py bigdata1:2181
>> select * from us_populcation;
2 Squirrel-sql ����Phoenix
2.1 ����Squirrel-sql
http://www.squirrelsql.org/#installation
2.2 ����Squirrel-sql ����Phoenix
����Phoenix Client jar��phoenix-4.14.0-HBase-1.2-client.jar����Squirrel-sql ��lib Ŀ¼;
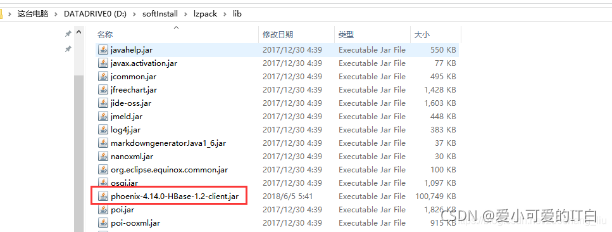
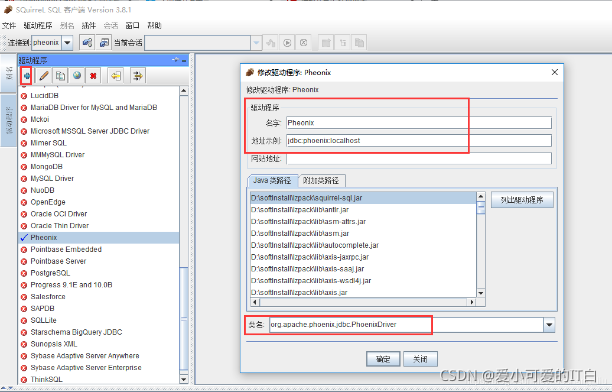
����Phoenix ���ӵ�Driver ��Ϣ,����localhost Ϊzookeeper ���ڵ�������ַ,��дһ�����ɡ�
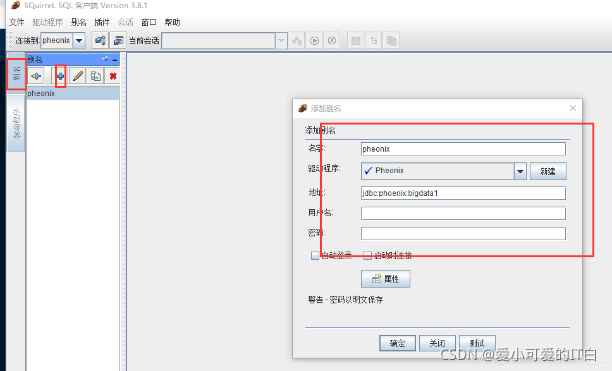
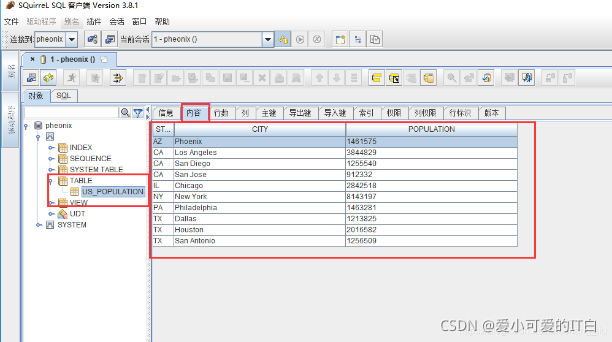
3 Phoenix ӳ��Hbase ��
����Hbase �������ն�bin/hbase shell
����Hbase ����phoenix��:
�C ����Hbase ��Phoenix,����info
create ��phoenix��,��info��
�C ��������
put ��phoenix��, ��row001��,��info:name��,��phoenix��
put ��phoenix��, ��row002��,��info:name��,��hbase��
ӳ��HBase ���ķ�ʽ������,һֱ����ͼӳ��,һ���DZ�ӳ�䡣
���ߵ�������Ƕ�HBase ����������û��Ӱ��;
ɾ��Phoenix ��ͼӳ�䲻���Hbase �ı����Ӱ��;
ɾ��Phoenix ��ӳ��ὫHbase �ı�Ҳɾ��;
�DZ�Ҫ�����һ�㴴����ͼӳ�䡣
3.1 ��ͼӳ��
��Phoenix �´�����ͼӳ��HBase ��:
-- ������ͼ����ӳ��Hbase ��
create view "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
);
��ѯ�����õ�Phoenix ��ͼ:
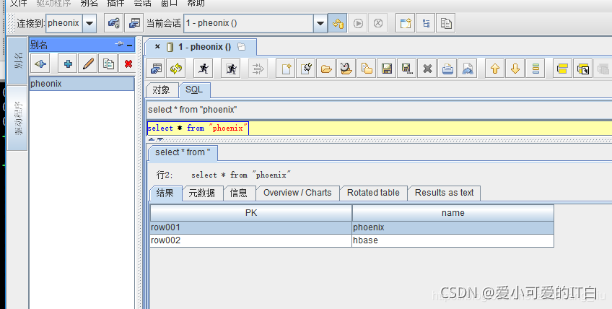
�C ɾ����ͼ��,��hbase shell �ն��²鿴phoenix ��Ȼ����
drop view "phoenix";
3.2 ��ӳ��
��Phoenix �´�����ӳ��HBase ��:
�C ����������ӳ��Hbase ��,4.10 �Ժ�Phoenix �Ż�����ӳ��,COLUMN_ENCODED_BYTES=0 ������ӳ�䡣
create table "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
) COLUMN_ENCODED_BYTES = 0;
��ѯ����:
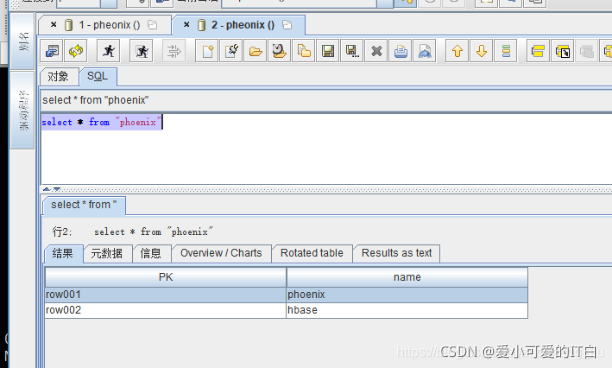
����:
��ƪ���½��ܵ��˽���,���ֲ���,�����ƪ���¶�����������,�鷳�������Ƶ�С��,��������,��ע,�ղ�֧���¡�����Ҫ��ͨ������,����ʱ��ͨ����,��л���֧��!!!


