???写作不易请多多点赞评论支持博主??
1、目的
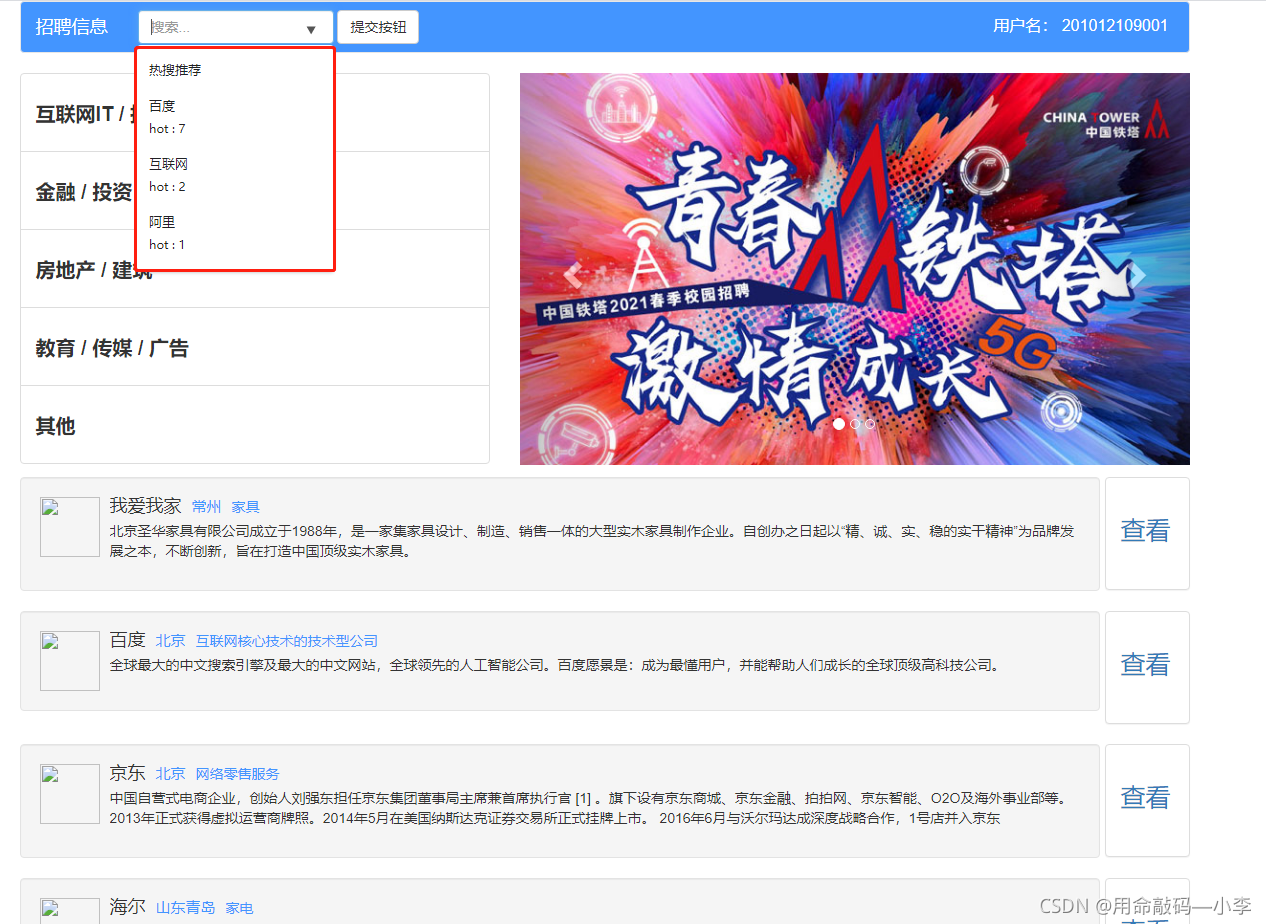
"定时处理用户搜索日志,统计用户搜索词"
2、期望结果
"当鼠标下拉点入搜索栏后显示搜索热词统计结果"
?使用spring+springmvc+mysql+bootstarp实现的学生就业案例~(教学需要大佬勿喷)?
?3、环境要求
- anaconda python3.6
- jdk1.8
- spark-2.4.7-bin-hadoop2.7
- scala-2.13.3
- hadoop-2.8.5
安装教程可参考:http://t.zoukankan.com/yfb918-p-10978856.html
百度网盘安装包:https://pan.baidu.com/s/1AI1kVeXb_lJ1Z-CWagT5Yg(spark+hadoop+scala)
提取码:a8uf
4、代码实现
日志格式:日志+用户+搜索词
log.log
2021-05-04_12:11:48 [INFO] 201012109001:百度
2021-05-04_12:12:46 [INFO] 201012109001:阿里
2021-05-04_12:12:47 [INFO] 201012109001:百度
2021-05-04_12:12:48 [INFO] 201012109001:北京
2021-05-04_12:13:49 [INFO] 201012109001:互联网
2021-05-04_12:13:49 [INFO] 201012109002:互联网
2021-05-04_12:13:49 [INFO] 201012109002:百度
?注意:需要把该内容放在log.log文件中并与处理程序存放在相同位置下
import findspark
findspark.init()
from pyspark import SparkContext ,SparkConf
import json
"""
定时器
"""
from threading import Timer
import datetime
def sparkTimert():
print('TimeNow:%s' % (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')))
res = getData()
saveJson(res)
t = Timer(120, sparkTimert)
t.start()
"""
spark数据处理
"""
def getData():
conf=SparkConf().setAppName("Project1").setMaster("local[4]")
sc = SparkContext(conf=conf)
lines = sc.textFile("log.log")
"""
热搜实现
"""
# 过滤log为info的数据,按照空格将字符串切割存储在数组中,取数组中第三个数据按照分号分割取第二个数据并使用countByValue进行统计个数
data = lines.filter(lambda s: "INFO" in s).map(lambda s: s.split(" ")[2].split(":")[1]).countByValue()
sc.stop()
return {i[0]:i[1] for i in sorted(data.items(), key=lambda d: d[1],reverse=True)[:3]}
"""
保存热搜json
"""
def saveJson(data):
filename='data.json'
with open(filename,'w') as file_obj:
json.dump(data,file_obj)
# getData()
if __name__ == '__main__':
sparkTimert()?注意:确保各个环境已安装成功
统计结果
data.json
{"百度": 6, "互联网": 2, "阿里": 1}
???写作不易请多多点赞评论支持博主??