���ں����Ƽ�:
🔶🔷Hadoop����dz�� �����������HDFS��MapReduce��Yarn��ܽṹ���������ʽ����ϸѧϰ�������ղ�!!!��
🔶🔷Redis����ͭ������,�ӻ����������ʹ��,����һƪ����,��ȫ������ϸ����,�Ͻ��ղذ�!!!
🔶🔷Ӳ������������,ѧ�����ݿ�ֻҪһƪ����,����!MySQL���������Լ����õ����ú�����������
🔶🔷Redis���Ӹ��� �Լ� ��Ⱥ� ��ϸ�������,�Ͽ��ղ����ְ�!
🔶🔷Hadoop��ȺHDFS��YARN�߿���HA��ϸ���ò���˵��,��Zookeeper���ϸ���衾�����ղ�!!!��
🔶🔷SQL����-��������MySQL,JDBC����MySQLʵ����ɾ�IJ�,�Ͽ��ղذ�!
🔶🔷��С��ѧJava��D25 ������Java�еĸ��ּ��ϴ����,ѧϰ����
💜🧡💛��������,��λ�����Ǹ������!
🧡💛💚����👍 ? �ղ�? ? ��ע?
💛💚💙��ӭ��λ����ָ��,һ����������!
��������ƪ������Ҫ�����ҷ���,Hive��һЩ��������,����,��Ͱ,���ں����ȵ�,�Լ�Hive��HQL��ʹ����ϰ,���д���,�������ָ�̡�ϣ������ܹ�ϲ��!
Ŀ¼
????????🧡һ���˽�Hive
????????????????💜1��Hive�ĸ���ܹ�
????????????????💜2��Hive�봫ͳ���ݿ�Ƚ�
????????????????💜3��Hive�����ݴ洢��ʽ
????????????????💜4��Hive�����ͻ���
????????🧡����Hive�Ļ����
????????????????💜1��Hive�����
????????????????💜2��Hive��������
????????????????💜3��Hive �ڲ���(Managed tables)vs �ⲿ��(External tables)
????????????????💜4��Hive ����
????????????????💜5��Hive��̬����
????????????????💜6��Hive��Ͱ
????????????????💜7��Hive����JDBC
????????🧡����Hive����������
????????????????💜1��������������
????????????????💜2����������
????????????????💜3��������������
????????🧡�ġ�Hive HQLʹ���
????????????????💜1��HQL�-DDL
????????????????💜2��HQL�-DML
????????🧡�塢Hive HQLʹ��ע��
????????🧡����Hive �ĺ���ʹ��
????????????????💜1��Hive-���ú���
????????????????????????💚(1)��ϵ����
????????????????????????💚(2)��ֵ����
????????????????????????💚(3) ��������
????????????????????????💚(4)���ں���
????????????????????????💚(5) �ַ�������
????????????????💜2��Hive-������
????????????????????????💚(1)���ں���(��������):�û������п���
????????????????????????💚(2)Hive ��ת��
????????????????????????💚(3)Hive ��ת��
????????????????????????💚(4)Hive�Զ��庯��UserDefineFunction
????????????????????????????????? UDF:һ��һ��
?????????????????????????????????UDTF:һ�����
?????????????????????????????????UDAF:���һ��
????????????????💜3��Hive �е�wordCount
????????🧡�ߡ�Hive ��Shellʹ��
һ���˽�Hive
1��Hive�ĸ���ܹ�
??????????????????????????���ҷ���Ŀ¼
????????Hive �ǽ����� Hadoop �ϵ����ݲֿ��������ܡ����ṩ��һϵ�еĹ���,������������������ȡת������(ETL ),����һ�ֿ��Դ洢����ѯ�ͷ����洢�� Hadoop �еĴ��ģ���ݵĻ��ơ�Hive �����˼��� SQL ��ѯ����,��Ϊ HQL ,��������Ϥ SQL ���û���ѯ���ݡ�ͬʱ,�������Ҳ������Ϥ MapReduce �Ŀ����߿����Զ���� mapper �� reducer �������ڽ��� mapper �� reducer ����ɵĸ��ӵķ���������Hive��SQL��������,����SQL���ת���Map/Reduce JobȻ����Hadoopִ�С�Hive�ı���ʵ����HDFS��Ŀ¼,���������ļ��зֿ�������Ƿ�����,�����ֵ�����ļ���,����ֱ����Map/Reduce Job��ʹ����Щ���ݡ�Hive�൱��hadoop�Ŀͻ��˹���,����ʱ��һ�����ڼ�Ⱥ�����ڵ���,Ҳ���Է���ij���ڵ��ϡ�
���ݲֿ�,Ӣ������ΪData Warehouse,�ɼ�дΪDW��DWH�����ݲֿ�,��Ϊ��ҵ���м���ľ����ƶ�����,�ṩ������������֧�ֵ�ս�Լ��ϡ������ڷ����Ա���;���֧��Ŀ�Ķ�������Ϊ��Ҫҵ�����ܵ���ҵ,�ṩָ��ҵ�����̸Ľ�������ʱ�䡢�ɱ��������Լ����ơ�
Hive�İ汾����:
0.13��.14�汾,�ȶ��汾,���Dz�֧�ָ���ɾ��������
1.2.1��1.2.2 �汾,�ȶ��汾,ΪHive2�汾(�������汾)
1.2.1�ij���ֻ������hive1.2.1 ��hiveserver2
2��Hive�봫ͳ���ݿ�Ƚ�
??????????????????????????���ҷ���Ŀ¼
| ��ѯ���� | HiveQL | SQL |
|---|---|---|
| ���ݴ洢λ�� | HDFS | Raw Device or ����FS |
| ���ݸ�ʽ | �û����� | ϵͳ���� |
| ���ݸ��� | ��֧��(1.x�Ժ�汾֧��) | ֧�� |
| ���� | �°汾��,���� | �� |
| ִ�� | MapReduce | Executor |
| ִ���ӳ� | �� | �� |
| ����չ�� | �� | �� |
| ���ݹ�ģ | �� | С |
- ��ѯ�������� SQL �IJ�ѯ���� HQL����Ϥ SQL �����Ŀ����߿��Ժܷ����ʹ�� Hive ���п�����
- ���ݴ洢λ�������� Hive �����ݶ��Ǵ洢�� HDFS �еġ������ݿ�����Խ����ݱ����ڿ��豸���߱����ļ�ϵͳ�С�
- ���ݸ�ʽ��Hive ��û�ж���ר�ŵ����ݸ�ʽ���������ݿ���,�������ݶ��ᰴ��һ������֯�洢,���,���ݿ�������ݵĹ��̻�ȽϺ�ʱ��
- ���ݸ�����Hive �����ݵĸ�д�����ӱȽ�����,0.14�汾֮��֧��,��Ҫ��������������ݿ��е�����ͨ������Ҫ���������ĵġ�
- ������Hive �ڼ������ݵĹ����в�������ݽ����κδ�������˷����ӳٽϸߡ����ݿ�����кܸߵ�Ч��,�ϵ͵��ӳ١��������ݵķ����ӳٽϸ�,������ Hive ���ʺ��������ݲ�ѯ��
- ִ�м�����Hive ��ִ����ͨ�� MapReduce ��ʵ�ֵĶ����ݿ�ͨ�����Լ���ִ�����档
- ���ݹ�ģ������ Hive �����ڼ�Ⱥ�ϲ��������� MapReduce ���в��м���,��˿���֧�ֺܴ��ģ������;��Ӧ��,���ݿ����֧�ֵ����ݹ�ģ��С��
3��Hive�����ݴ洢��ʽ
??????????????????????????���ҷ���Ŀ¼
-
Hive�����ݴ洢����Hadoop HDFS��
-
Hiveû��ר�ŵ������ļ���ʽ,�����������¼���:TEXTFILE��SEQUENCEFILE��AVRO��RCFILE��ORCFILE��PARQUET��
����������ϸ�Ŀ�һ��Hive�ij������ݸ�ʽ:
-
TextFile:
???????? TEXTFILE ���������ı���ʽ,��HiveĬ���ļ��洢��ʽ,��Ϊ����������Դ�����ļ�������text�ļ���ʽ����(���ڲ鿴�����ͷ�ֹ����)�����ָ�ʽ�ı��ļ���HDFS��������,����hadoop fs -cat����鿴,��HDFS��get������Ҳ����ֱ�Ӷ�ȡ��
???????? TEXTFILE �洢�ļ�Ĭ��ÿһ�о���һ����¼,����ָ������ķָ��������ֶμ�ķָ�������ʽ��ѹ��,��Ҫ�Ĵ洢�ռ�ܴ� ��Ȼ���Խ��Gzip��Bzip2��Snappy��ʹ��,ʹ�����ַ�ʽ,Hive��������ݽ����з�,�Ӷ��������ݽ��в��в�����һ��ֻ��������ϵͳ�����ݽ����Ľӿڱ�����TEXTFILE ��ʽ,������ʵ����ά�ȱ���������ʹ�á� -
RCFile:
????????Record Columnar����д����Hadoop�е�һ�����ļ���ʽ�� �ܹ��ܺõ�ѹ���Ϳ��ٵIJ�ѯ���ܡ�ͨ��д�����Ƚ���,�ȷ�����ʽ���ļ���ʽ��Ҫ������ڴ�ռ�ͼ������� RCFile��һ�����д洢���ϵĴ洢��ʽ�� ����,�佫���ݰ��зֿ�,��֤ͬһ��record��һ������,�����һ����¼��Ҫ��ȡ���block�����,��������ʽ�洢,����������ѹ���Ϳ��ٵ��д�ȡ�� -
ORCFile:
????????Hive��0.11�汾��ʼ�ṩ��ORC���ļ���ʽ,ORC�ļ���������һ����ʽ�ļ��洢��ʽ,����Ҫ�������źܸߵ�ѹ����,��������MapReduce��˵�ǿ��з�(Split)�������,��Hive��ʹ��ORC��Ϊ�����ļ��洢��ʽ,�������Ժܴ�̶ȵĽ�ʡHDFS�洢��Դ,���Ҷ����ݵIJ�ѯ�ʹ����������ŷdz��������,��ΪORC�������ļ���ʽѹ���ȸ�,��ѯ�������������������,ʹ�õ�TaskҲ�ͼ����ˡ�ORC�ܴܺ�̶ȵĽ�ʡ�洢�ͼ�����Դ,�����ڶ�дʱ����Ҫ���Ķ����CPU��Դ��ѹ���ͽ�ѹ��,��Ȼ�ⲿ�ֵ�CPU�����Ƿdz��ٵġ� -
Parquet:
???????? ͨ������ʹ�ù�ϵ���ݿ�洢�ṹ������,����ϵ���ݿ���ʹ������ģ�Ͷ��DZ�ƽʽ��,��������List��Map���Զ���Struct��ʱ�����Ҫ�û���Ӧ�ò�����������ڴ����ݻ�����,ͨ�����ݵ���Դ�Ƿ���˵��������,�ܿ�����Ҫ�ѳ����е�ijЩ����������Ϊ�����һ����,��ÿһ����������Ƕ��,��������ܹ�ԭ����֧����������,�����ڲ�ѯ��ʱ��Ͳ���Ҫ����Ľ������ܻ����Ҫ�Ľ����Parquet�����������2010��Google������Dremel����,���н�����һ��֧��Ƕ�ṹ�Ĵ洢��ʽ,����ʹ������ʽ�洢�ķ�ʽ������ѯ���ܡ�Parquet������һ�ִ洢��ʽ,�������ԡ�ƽ̨�ص�,���Ҳ���Ҫ���κ�һ�����ݴ�����ܰ���Ҳ��parquet�����orc�Ľ�������:֧��Ƕ�ṹ��Parquet û��̫��������Ȧ�ɵ�ĵط�,��������֧��update����(����д�ɺ���),��֧��ACID��. -
SEQUENCEFILE:
???????? SequenceFile��Hadoop API �ṩ��һ�ֶ������ļ�,����������<key,value>����ʽ���л����ļ��С� ���ֶ������ļ��ڲ�ʹ��Hadoop �ı���Writable �ӿ�ʵ�����л��ͷ����л�������Hadoop API�е�MapFile �ǻ�����ݵġ�Hive �е�SequenceFile �̳���Hadoop API ��SequenceFile,��������keyΪ��,ʹ��value ���ʵ�ʵ�ֵ, ������Ϊ�˱���MR ������map �ε�������̡� SequenceFile֧������ѹ��ѡ��:NONE, RECORD, BLOCK�� Recordѹ���ʵ�,һ�㽨��ʹ��BLOCKѹ���� SequenceFile����Ҫ���ŵ����Hadoopԭ��֧�ֽϺ�,��API,������֮��ƽƽ����,ʵ�������в���ʹ�á� -
AVRO:
???????? Avro��һ������֧�������ܼ��͵Ķ������ļ���ʽ�������ļ���ʽ��Ϊ����,��Ҫ��ȡ��������ʱ,Avro�ܹ��ṩ���õ����л��ͷ����л����ܡ�����Avro�����ļ������Ǵ�Schema�����,����������Ҫ��������API ����ʵ���Լ���Writable����Avro�ṩ�Ļ���ʹ��̬���Կ��Է���ش���Avro������������Hadoop ����Ŀ��֧��Avro ���ݸ�ʽ,��Pig ��Hive��Flume��Sqoop��Hcatalog��
���е�TextFile��RCFile��ORC��ParquetΪHive��õ��Ĵ�洢��ʽ
���ǵ��洢Ч�ʼ�ִ���ٶȱȽ�����:
????ORCFile�洢�ļ�������Ч�����,��ʱ�Ƚ�(ORC<Parquet<RCFile<TextFile)
????ORCFile�洢�ļ�ռ�ÿռ���,ѹ��Ч�ʸ�(ORC<Parquet<RCFile<TextFile)
4��Hive�����ͻ���
??????????????????????????���ҷ���Ŀ¼
���õĿͻ���������:CLI,JDBC/ODBC
-
CLI,��Shell������
-
JDBC/ODBC �� Hive ��Java,��ʹ�ô�ͳ���ݿ�JDBC�ķ�ʽ���ơ�
-
Hive ��Ԫ���ݴ洢�����ݿ���(metastore),Ŀǰֻ֧�� mysql��derby�� Hive �е�Ԫ���ݰ�����������,�����кͷ�����������,��������(�Ƿ�Ϊ�ⲿ����),������������Ŀ¼��;�ɽ����������������Ż������ HQL ��ѯ���Ӵʷ�����������������롢�Ż��Լ���ѯ�ƻ�(plan)�����ɡ����ɵIJ�ѯ�ƻ��洢�� HDFS ��,��������� MapReduce ����ִ�С�
-
Hive �����ݴ洢�� HDFS ��,�ֵIJ�ѯ�� MapReduce ���(���� * �IJ�ѯ,���� select * from table �������� MapRedcue ����)
Hive��metastore
metastore��hiveԪ���ݵļ��д�ŵء�
metastoreĬ��ʹ����Ƕ��derby���ݿ���Ϊ�洢����
Derby�����ȱ��:һ��ֻ�ܴ�һ���Ự
ʹ��MySQL��Ϊ���ô洢����,���Զ��û�ͬʱ����`Ԫ���ݿ�����:�鿴mysql SDS����TBLS��
���ӵ�ַ:https://blog.csdn.net/haozhugogo/article/details/73274832
����Hive�Ļ����
1��Hive�����
??????????????????????????���ҷ���Ŀ¼
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
// �����ֶ���,�ֶ�����
[(col_name data_type [COMMENT col_comment], ...)]
// ��������ע��
[COMMENT table_comment]
// ����
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
// ��Ͱ
[CLUSTERED BY (col_name, col_name, ...)
// ���������ֶ� ������
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[
// ָ�������С��зָ���
[ROW FORMAT row_format]
// ָ��Hive�����ʽ:textFile��rcFile��SequenceFile Ĭ��Ϊ:textFile
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [ WITH SERDEPROPERTIES (...) ] (Note: only available starting with 0.6.0)
]
// ָ������λ��
[LOCATION hdfs_path]
// ���ⲿ�����ʹ��,����:ӳ��HBase��,Ȼ�����ʹ��HQL��hbase���ݽ��в�ѯ,��Ȼ�ٶȱȽ���
[TBLPROPERTIES (property_name=property_value, ...)] (Note: only available starting with 0.6.0)
[AS select_statement] (Note: this feature is only available starting with 0.5.0.)
������ʽ1:ȫ��ʹ��Ĭ�Ͻ�����ʽ
??????????????????????????���ҷ���Ŀ¼
create table students
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
// ��ѡ,ָ���зָ���
������ʽ2:ָ��location (���ַ�ʽҲ�Ƚϳ���)
??????????????????????????���ҷ���Ŀ¼
create table students2
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input1';
// ָ��Hive�������ݵĴ洢λ��,һ���������Ѿ��ϴ���HDFS,��Ҫֱ��ʹ��,��ָ��Location,
//ͨ��Locaion����ⲿ��һ��ʹ��,�ڲ���һ��ʹ��Ĭ�ϵ�location
������ʽ3:ָ���洢��ʽ
??????????????????????????���ҷ���Ŀ¼
create table students3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS rcfile;
// ָ�������ʽΪrcfile,inputFormat:RCFileInputFormat,outputFormat:RCFileOutputFormat,
//�����ָ��,Ĭ��Ϊtextfile,
//ע��:��textfile����,�����Ĵ洢��ʽ�����ݶ�����ֱ�Ӽ���,��Ҫʹ�ôӱ����صķ�ʽ��
������ʽ4:create table xxxx as select_statement(SQL���) (���ַ�ʽ�Ƚϳ���)
??????????????????????????���ҷ���Ŀ¼
ע��:
- �½�����������
�ⲿ���� - select�������Ҫ���Ѿ����ڵı�,����ͬʱ��������ݡ�
- ������mapreduce����ȥ��ȡԴ������д���±�
create table students4 as select * from students2;
������ʽ5:create table xxxx like table_name ֻ�뽨��,����Ҫ��������
create table students5 like students;
2��Hive��������
??????????????????????????���ҷ���Ŀ¼
1)��ʹ��hdfs dfs -put '��������' 'hive����Ӧ��HDFSĿ¼��'
2)��ʹ�� load data inpath
????????��hdfs��������,·��������Ŀ¼,�ὫĿ¼�������ļ�����,�����ļ���ʽ����һ��
// ��HDFS�ϵ�/input1Ŀ¼��������� �ƶ��� students����Ӧ��HDFSĿ¼��
// ע���� �ƶ�!�ƶ�!�ƶ�!
load data inpath '/input1/students.txt' into table students;
// ��ձ�
truncate table students;
�ӱ����ļ�ϵͳ����
// ���� local �ؼ��� ���Խ�Linux����Ŀ¼�µ��ļ� �ϴ��� hive����ӦHDFS Ŀ¼�� ԭ�ļ����ᱻɾ��
load data local inpath '/usr/local/soft/data/students.txt' into table students;
// overwrite ���Ǽ���
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
3)��create table xxx as SQL���,���Ա�����
4)��insert into table xxxx SQL��� (û��as),���Ա�����:
// �� students�������ݲ��뵽students2
//���Ǹ��� �����ƶ� students���еı��е����ݲ��ᶪʧ
insert into table students2 select * from students;
// ���Dz��� ��into ���� overwrite
insert overwrite table students2 select * from students;
ע��:
1,����������û��ָ���洢·��,�������ⲿ�������ڲ���,�洢·�����ǻ�Ĭ����hive/warehouse/xx.db/������Ŀ¼�¡�
���ص����������HDFS�ϻ��ƶ����ñ��Ĵ洢Ŀ¼�¡�ע�����ƶ�,���Ǹ���
2,ɾ���ⲿ��,�ļ�����ɾ��,��ӦĿ¼Ҳ����ɾ��
3��Hive �ڲ���(Managed tables)vs �ⲿ��(External tables)
??????????????????????????���ҷ���Ŀ¼
�ⲿ������ͨ��������
- �ⲿ����·�������Զ���,�ڲ�����·����Ҫ�� hive/warehouse/Ŀ¼��
- ɾ������,��ͨ�������ļ��ͱ���Ϣ��ɾ�����ⲿ����ɾ������Ϣ
1)���������:
// �ڲ���
create table students_internal
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input2';
// �ⲿ��
create external table students_external
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input3';
2)����������:
hive> dfs -put /usr/local/soft/data/students.txt /input2/;
hive> dfs -put /usr/local/soft/data/students.txt /input3/;
3)��ɾ����:
hive> drop table students_internal;
Moved: 'hdfs://master:9000/input2' to trash at: hdfs://master:9000/user/root/.Trash/Current
OK
Time taken: 0.474 seconds
hive> drop table students_external;
OK
Time taken: 0.09 seconds
1�����Կ���,ɾ���ڲ�����ʱ��,���е�����(HDFS�ϵ��ļ�)�ᱻͬ����Ԫ����һ��ɾ��;ɾ���ⲿ����ʱ��,ֻ��ɾ������Ԫ����,������ɾ�����е�����(HDFS�ϵ��ļ�)
2��һ���ڹ�˾��,ʹ���ⲿ����һ��,��Ϊ���ݿ�����Ҫ���������ʹ��,������ɾ,ͨ���ⲿ������locationһ��ʹ��
3���ⲿ�������Խ���������Դ�е����� ӳ�䵽 hive��,����˵:hbase,ElasticSearch��
4������ⲿ���ij��Ծ��� �� ����Ԫ���� �� ���� ����
4��Hive ����
??????????????????????????���ҷ���Ŀ¼
????????������ʵ�������ڱ���Ŀ¼�����Է�������,����Ŀ¼;����:���з����ü�,����ȫ��ɨ��,����MapReduce������������,���Ч��
????????һ���ڹ�˾��hive��,���еı������϶��Ƿ�����,ͨ�������ڷ������������;��������ʹ�õ�ʱ��ǵü��Ϸ����ֶ�;����Ҳ����Խ��Խ��,һ�㲻����3��,����ʵ��ҵ�����
�����ĸ���ͷ�����:
������ָ�����ڴ�����ʱָ�������ռ�,ʵ���Ͼ�����hdfs�ϱ���Ŀ¼���ٴ�����Ŀ¼��
��ʹ������ʱ���ָ������Ҫ���ʵķ�������,��ֻ���ȡ��Ӧ�ķ���,����ȫ��ɨ��,��߲�ѯЧ�ʡ�
1)������������:
create external table students_pt1
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(pt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
2)������һ������:
alter table students_pt1 add partition(pt='20210904');
3)��ɾ��һ������:
alter table students_pt drop partition(pt='20210904');
4)���鿴ij���������з���
// �Ƽ����ַ�ʽ(ֱ�Ӵ�Ԫ�����л�ȡ������Ϣ)
show partitions students_pt;
// ���Ƽ�
select distinct pt from students_pt;
5)���������������:
insert into table students_pt partition(pt='20210902') select * from students;
load data local inpath '/usr/local/soft/data/students.txt' into table students_pt partition(pt='20210902');
6)����ѯij������������:
// ȫ��ɨ��,���Ƽ�,Ч�ʵ�
select count(*) from students_pt;
// ʹ��where�������з����ü�,������ȫ��ɨ��,Ч�ʸ�
select count(*) from students_pt where pt='20210101';
// Ҳ������where������ʹ�÷ǵ�ֵ�ж�
select count(*) from students_pt where pt<='20210112' and pt>='20210110';
5��Hive��̬����
??????????????????????????���ҷ���Ŀ¼
�е�ʱ������ԭʼ���е�������������� ���������ֶ� dt����,������Ҫ����dt�в�ͬ������,��Ϊ��ͬ�ķ���,��ԭʼ������ɷ�������
hiveĬ�ϲ�������̬����
��̬����:����������ij���еIJ�ͬ��ȡֵ ���� ��ͬ�ķ���
# ��ʾ������̬����
hive> set hive.exec.dynamic.partition=true;
# ��ʾ��̬����ģʽ:strict(��Ҫ��Ͼ�̬����һ��ʹ��)��nostrict
# strict: insert into table students_pt partition(dt='anhui',pt) select ......,pt from students;
hive> set hive.exec.dynamic.partition.mode=nostrict;
# ��ʾ֧�ֵ����ķ�������Ϊ1000,���Ը���ҵ���Լ�����
hive> set hive.exec.max.dynamic.partitions.pernode=1000;
1)������ԭʼ������������
create table students_dt
(
id bigint,
name string,
age int,
gender string,
clazz string,
dt string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
2)����������������������
create table students_dt_p
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
3)��ʹ�ö�̬������������
// �����ֶ���Ҫ���� select �����,����ж�������ֶ� ͬ��,
//���ǰ�λ��ƥ��,���ǰ�����ƥ��
insert into table students_dt_p partition(dt) select id,name,age,gender,clazz,dt from students_dt;
// ����������������ʹ��age��Ϊ�����ֶ�,������ʹ��student_dt�е�dt��Ϊ�����ֶ�
insert into table students_dt_p partition(dt) select id,name,age,gender,dt,age from students_dt;
4)���༶����
create table students_year_month
(
id bigint,
name string,
age int,
gender string,
clazz string,
year string,
month string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
create table students_year_month_pt
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(year string,month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into table students_year_month_pt partition(year,month) select id,name,age,gender,clazz,year,month from students_year_month;
�йط������ķ���:�ϵ�������:https://developer.aliyun.com/article/81775
6��Hive��Ͱ
??????????????????????????���ҷ���Ŀ¼
????????��Ͱʵ�����Ƕ��ļ�(����)�Ľ�һ���з�;HiveĬ�Ϲرշ�Ͱ;��Ͱ������:������Ͱ���в������ݵ�ʱ��,����� clustered by ָ�����ֶ� ����hash���� ��ָ����buckets���� ����ȡ��,�������Խ����ݷָ��buckets�������ļ�,�Դﵽ���ݾ��ȷֲ�,���Խ��Map�˵ġ�������б������,��������ȡ��������,���Map joinЧ��;��Ͱ�ֶ� ��Ҫ����ҵ������趨
1)��������Ͱ����
hive> set hive.enforce.bucketing=true;
2)��������Ͱ��
create table students_buks
(
id bigint,
name string,
age int,
gender string,
clazz string
)
CLUSTERED BY (clazz) into 12 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
3)������Ͱ���в�������
// ֱ��ʹ��load data �����ܽ����ݴ�ɢ
load data local inpath '/usr/local/soft/data/students.txt' into table students_buks;
// ��Ҫʹ���������ַ�ʽ��������,����ʹ��Ͱ��������������
insert into students_buks select * from students;
Hive���ڷ�Ͱ���ķ���, Hive��Ͱ����ʹ�ó����Լ���ȱ�����:https://zhuanlan.zhihu.com/p/93728864
7��Hive����JDBC
??????????????????????????���ҷ���Ŀ¼
1)������hiveserver2�ķ���
hive --service hiveserver2 &
2)�� �½�maven��Ŀ��������������
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
3)�� ��дJDBC����
import java.sql.*;
public class HiveJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn = DriverManager.getConnection("jdbc:hive2://master:10000/test3");
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery("select * from students limit 10");
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
int age = rs.getInt(3);
String gender = rs.getString(4);
String clazz = rs.getString(5);
System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
}
rs.close();
stat.close();
conn.close();
}
}
����Hive����������
1��������������
??????????????????????????���ҷ���Ŀ¼
��ֵ��:
TINYINT �� ����,ֻռ��1���ֽ�,ֻ�ܴ洢0-255��������
SMALLINT�C С����,ռ��2���ֽ�,�洢��Χ�C32768 �� 32767��
INT�C ����,ռ��4���ֽ�,�洢��Χ-2147483648��2147483647��
BIGINT�C ������,ռ��8���ֽ�,�洢��Χ-2^63��2^63-1��
������
BOOLEAN �� TRUE/FALSE
������
FLOAT�C �����ȸ�������
DOUBLE�C ˫���ȸ�������
�ַ�����
STRING�C ���趨���ȡ�
2����������
??????????????????????????���ҷ���Ŀ¼
- ʱ��� timestamp
- ���� date
create table testDate(
ts timestamp
,dt date
) row format delimited fields terminated by ',';
// 2021-01-14 14:24:57.200,2021-01-11
- ʱ�����ʱ���ַ���ת��
// from_unixtime ����һ��ʱ����Լ�pattern(yyyy-MM-dd)
//���Խ� ʱ���ת���ɶ�Ӧ��ʽ���ַ���
select from_unixtime(1630915221,'yyyy��MM��dd�� HHʱmm��ss��')
// unix_timestamp ����һ��ʱ���ַ����Լ�pattern,
//���Խ��ַ�������patternת����ʱ���
select unix_timestamp('2021��09��07�� 11ʱ00��21��','yyyy��MM��dd�� HHʱmm��ss��');
select unix_timestamp('2021-01-14 14:24:57.200')
3��������������
??????????????????????????���ҷ���Ŀ¼
��Ҫ�����ָ�����������:Structs,Maps,Arrays ,���Բο�:https://blog.csdn.net/woshixuye/article/details/53317009
�ġ�Hive HQLʹ���
??????????????????????????���ҷ���Ŀ¼
����֪��
SQL���Կ��Է�Ϊ5����:
(1)DDL(Data Definition Language) ���ݶ�������
�����������ݿ����:���ݿ�,��,�еȡ�
�ؼ���:create,drap,alter��
( 2)DML(Data Manipulation Language) ���ݲ�������
���������ݿ��б������ݽ�����ɾ�ġ�
�ؼ���:insert,delete,update��
( 3)DQL(Data Query Language)���ݲ�ѯ����
������ѯ���ݿ���ļ�¼(����)��
�ؼ���:select,where ��
( 4)DCL(Data Control Language) ���ݿ�������
�����������ݿ�ķ���Ȩ�Ͱ�ȫ����,�������û���
�ؼ���:GRANT,REVOKE��
(5)TCL(Transaction Control Language) �����������
T CL���������ڿ���ԭ�Ϳ������ű���̡�GUI�Ͳ��Եȷ���,
�ؼ���: commit��rollback�ȡ�
1��HQL�-DDL
??????????????????????????���ҷ���Ŀ¼
�������ݿ� create database xxxxx;
�鿴���ݿ� show databases;
ɾ�����ݿ� drop database tmp;
ǿ��ɾ�����ݿ�:drop database tmp cascade;
�鿴��:SHOW TABLES;
�鿴����Ԫ��Ϣ:
desc test_table;
describe extended test_table;
describe formatted test_table;
�鿴�������:show create table table_XXX
��������:
alter table test_table rename to new_table;
������������:alter table lv_test change column colxx string;
���ӡ�ɾ������:
alter table test_table add partition (pt=xxxx)
alter table test_table drop if exists partition(...);
2��HQL�-DML
??????????????????????????���ҷ���Ŀ¼
where ���ڹ���,�����ü�,ָ������
join ������������,left outer join ,join,mapjoin(1.2�汾��Ĭ�Ͽ���)
group by ���ڷ���ۺ�,ͨ����ϾۺϺ���һ��ʹ��
order by ����ȫ������,Ҫ������������,�����ȫ�������,�������е�reduce����������
sort by :���ж��reduceʱ,ֻ�ܱ�֤����reduce�������,���ܱ�֤ȫ������
cluster by = distribute by + sort by
distinct ȥ��
order by��distribute by��sort by��cluster by���
��������:?Hive��order��sort��distribute��cluster by��������ϵ https://zhuanlan.zhihu.com/p/93747613
�塢Hive HQLʹ��ע��
??????????????????????????���ҷ���Ŀ¼
-
HQL ִ�����ȼ�:
from��where�� group by ��having��order by��join��select ��limit -
where �����ﲻ֧�ֲ���ʽ�Ӳ�ѯ,ʵ������֧�� in��not in��exists��not exists
-
hive�д�Сд������
-
��hive��,�����������null�ַ���,���ص����е�ʱ����� null (�����ַ���)
�����Ҫ�ж� null,ʹ�� ij���ֶ��� is null �����ķ�ʽ���ж�;����ʹ�� nvl() ����,���� ֱ�� ij���ֶ��� == null -
ʹ��explain�鿴SQLִ�мƻ�
����Hive �ĺ���ʹ��
??????????????????????????���ҷ���Ŀ¼
1��Hive-���ú���
??????????????????????????���ҷ���Ŀ¼
(1)��ϵ����
??????????????????????????���ҷ���Ŀ¼
// ��ֵ�Ƚ� = == <=>
// ����ֵ�Ƚ� != <>
// ����Ƚ�: select * from default.students where id between 1500100001 and 1500100010;
// ��ֵ/�ǿ�ֵ�ж�:is null��is not null��nvl()��isnull()
// like��rlike��regexp�÷�
(2)��ֵ����
??????????????????????????���ҷ���Ŀ¼
ȡ������(��������):round
����ȡ��:ceil
����ȡ��:floor
(3) ��������
??????????????????????????���ҷ���Ŀ¼
- if: if(����ʽ,�������ʽ�����ķ���ֵ,�������ʽ�������ķ���ֵ)
select if(1>0,1,0);
select if(1>0,if(-1>0,-1,1),0);
- COALESCE
select COALESCE(null,'1','2'); // 1 �������� һ��ƥ�� ֱ���ǿ�Ϊֹ
select COALESCE('1',null,'2'); // 1
- case when �� then �� else �� end
select score
,case when score>120 then '����'
when score>100 then '����'
when score>90 then '����'
else '������'
end as pingfen
from default.score limit 20;
# ע��������˳��
(4)���ں���
??????????????????????????���ҷ���Ŀ¼
select from_unixtime(1610611142,'YYYY/MM/dd HH:mm:ss');
select from_unixtime(unix_timestamp(),'YYYY/MM/dd HH:mm:ss');
// '2021��01��14��' -> '2021-01-14'
select from_unixtime(unix_timestamp('2021��01��14��','yyyy��MM��dd��'),'yyyy-MM-dd');
// "04ţ2021����16��" -> "2021/04/16"
select from_unixtime(unix_timestamp("04ţ2021����16��","MMţyyyy����dd��"),"yyyy/MM/dd");
(5) �ַ�������
??????????????????????????���ҷ���Ŀ¼
concat('123','456'); // 123456
concat('123','456',null); // NULL
select concat_ws('#','a','b','c'); // a#b#c
select concat_ws('#','a','b','c',NULL); // a#b#c ����ָ���ָ���,���һ��Զ�����NULL
select concat_ws("|",cast(id as string),name,cast(age as string),gender,clazz) from students limit 10;
select substring("abcdefg",1); // abcdefg HQL���漰��λ�õ�ʱ�� �Ǵ�1��ʼ����
// '2021/01/14' -> '2021-01-14'
select concat_ws("-",substring('2021/01/14',1,4),substring('2021/01/14',6,2),substring('2021/01/14',9,2));
select split("abcde,fgh",","); // ["abcde","fgh"]
select split("a,b,c,d,e,f",",")[2]; // c
select explode(split("abcde,fgh",",")); // abcde
// fgh
// ����json��ʽ������
select get_json_object('{"name":"zhangsan","age":18,"score":[{"course_name":"math","score":100},{"course_name":"english","score":60}]}',"$.score[0].score"); // 100
2��Hive-������
??????????????????????????���ҷ���Ŀ¼
(1)���ں���(��������):�û������п���
??????????????????????????���ҷ���Ŀ¼
????????��sql����һ�ຯ�������ۺϺ���,����sum()��avg()��max()�ȵ�,���ຯ�����Խ��������ݰ��չ���ۼ�Ϊһ��,һ�������ۼ����������Ҫ���ھۼ�ǰ��������.������ʱ������Ҫ����ʾ�ۼ�ǰ������,��Ҫ��ʾ�ۼ��������,��ʱ���DZ������˴��ں�����(��������,����һ�����ڷ������� TopN����)
���ķ���,Hive���ں���
������ʾ:
����:
111,69,class1,department1
112,80,class1,department1
113,74,class1,department1
114,94,class1,department1
115,93,class1,department1
121,74,class2,department1
122,86,class2,department1
123,78,class2,department1
124,70,class2,department1
211,93,class1,department2
212,83,class1,department2
213,94,class1,department2
214,94,class1,department2
215,82,class1,department2
216,74,class1,department2
221,99,class2,department2
222,78,class2,department2
223,74,class2,department2
224,80,class2,department2
225,85,class2,department2
����:
create table new_score(
id int
,score int
,clazz string
,department string
) row format delimited fields terminated by ",";
row_number():��������
ʹ�ø�ʽ:
select xxxx, row_number() over(partition by �����ֶ� order by �����ֶ� desc) as rn from tb group by xxxx
dense_rank():�в�������,�������ε���
rank():�в�������,�����ε���
percent_rank():(rank�Ľ��-1)/(���������ݵĸ���-1)
cume_dist():����ij�����ڻ������ij��ֵ���ۻ��ֲ���
�ٶ���������,��ʹ�����¹�ʽȷ���ۻ��ֲ�: С�ڵ��ڵ�ǰֵx������ / ���ڻ�partition�����ڵ�������������,x ���� order by �Ӿ���ָ�����еĵ�ǰ���е�ֵ��
NTILE(n):�Է����������ٷֳ�n��,Ȼ��������
max()��min()��avg()��count()��sum()�Ⱥ���:�ǻ���ÿ��partition�����ڵ���������Ӧ�ļ���
����֡:���ڴӷ�����ѡ��ָ���Ķ�����¼,�����ں�������
??????????????????????????���ҷ���Ŀ¼
Hive �ṩ�����ֶ��崰��֡����ʽ:
ROWS��RANGE���������Ͷ���Ҫ�����Ͻ���½硣
����,ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW��ʾѡ�������ʼ��¼����ǰ��¼��������;
SUM(close) RANGE BETWEEN 100 PRECEDING AND 200 FOLLOWING��ͨ�� �ֶβ�ֵ ������ѡ��
�統ǰ�е�close�ֶ�ֵ��200,��ô�������֡�Ķ���ͻ�ѡ�������close�ֶ�ֵ����100��400����ļ�¼��
���������п��ܵĴ���֡������ϡ����û�ж��崰��֡,��Ĭ��ΪRANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW��
ע��:����ֻ֡��������max��min��avg��count��sum��FIRST_VALUE��LAST_VALUE�⼸�����ں�����
����1:
SELECT id
,score
,clazz
,SUM(score) OVER w as sum_w
,round(avg(score) OVER w,3) as avg_w
,count(score) OVER w as cnt_w
FROM new_score
WINDOW w AS (PARTITION BY clazz ORDER BY score rows between 2 PRECEDING and 2 FOLLOWING);
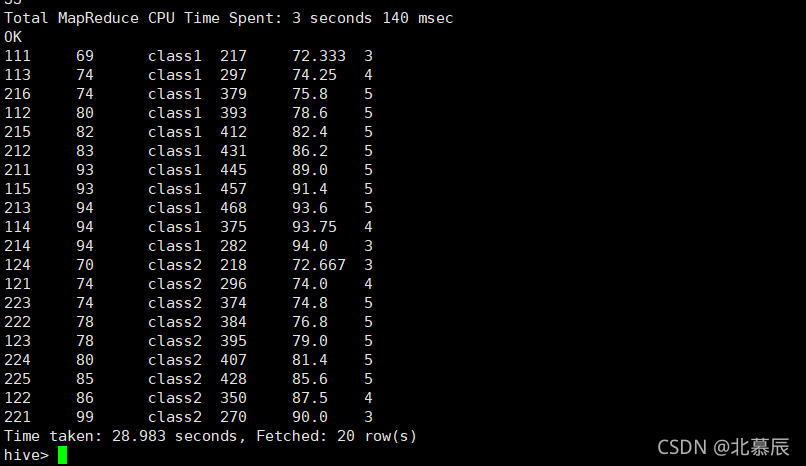
����2:
select id
,score
,clazz
,department
,row_number() over (partition by clazz order by score desc) as rn_rk
,dense_rank() over (partition by clazz order by score desc) as dense_rk
,rank() over (partition by clazz order by score desc) as rk
,percent_rank() over (partition by clazz order by score desc) as percent_rk
,round(cume_dist() over (partition by clazz order by score desc),3) as cume_rk
,NTILE(3) over (partition by clazz order by score desc) as ntile_num
,max(score) over (partition by clazz order by score desc range between 3 PRECEDING and 11 FOLLOWING) as max_p
from new_score;
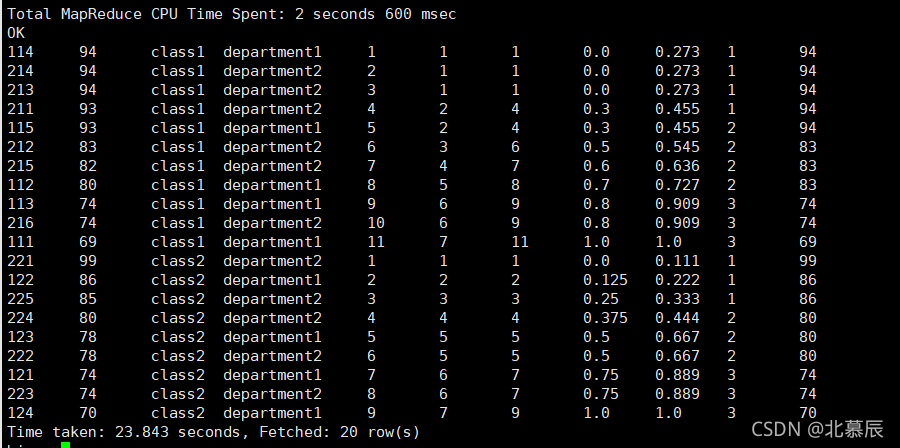
LAG(col,n):��ǰ��n������
LEAD(col,n):�����n������
FIRST_VALUE:ȡ�����������,��ֹ����ǰ��,��һ��ֵ
LAST_VALUE:ȡ�����������,��ֹ����ǰ��,���һ��ֵ,���ڲ��е�����,ȡ���һ��
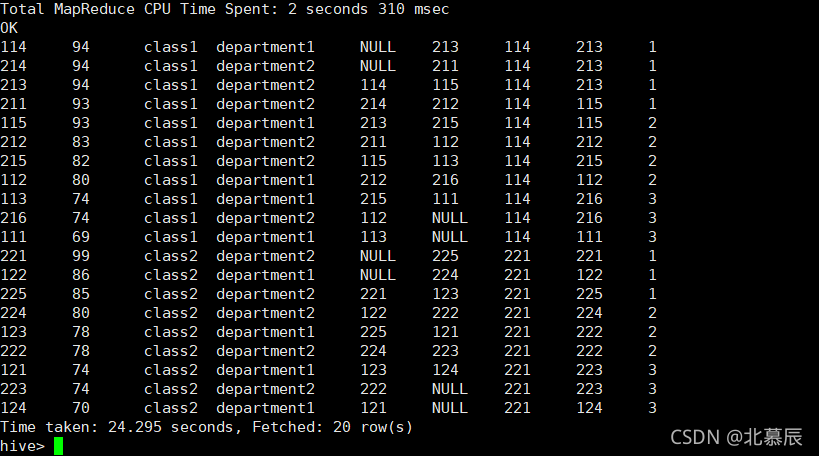
����3:
select id
,score
,clazz
,department
,lag(id,2) over (partition by clazz order by score desc) as lag_num
,LEAD(id,2) over (partition by clazz order by score desc) as lead_num
,FIRST_VALUE(id) over (partition by clazz order by score desc) as first_v_num
,LAST_VALUE(id) over (partition by clazz order by score desc) as last_v_num
,NTILE(3) over (partition by clazz order by score desc) as ntile_num
from new_score;
(2)Hive ��ת��
??????????????????????????���ҷ���Ŀ¼
ʹ�ùؼ���: lateral view explode
������ʾ:
����:
create table testArray2(
name string,
weight array<string>
)row format delimited
fields terminated by '\t'
COLLECTION ITEMS terminated by ',';
��������:
����� "150","170","180"
������ "150","180","190"

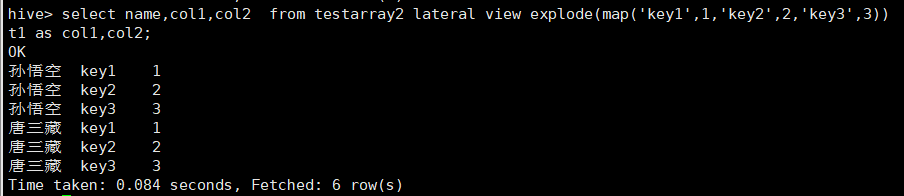
select name,col1 from testarray2 lateral view explode(weight) t1 as col1;

select key from (select explode(map('key1',1,'key2',2,'key3',3)) as (key,value)) t;

select name,col1,col2 from testarray2 lateral view explode(map('key1',1,'key2',2,'key3',3)) t1 as col1,col2;
select name,pos,col1 from testarray2 lateral view posexplode(weight) t1 as pos,col1;
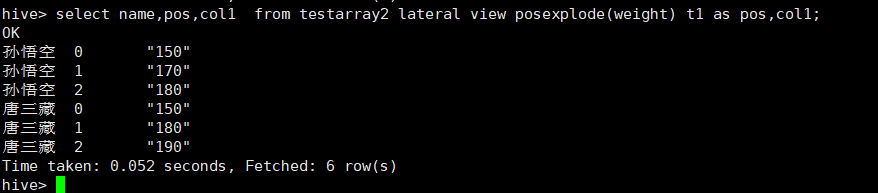
(3)Hive ��ת��
??????????????????????????���ҷ���Ŀ¼
����:
����� 150
����� 170
����� 180
������ 150
������ 180
������ 190
����:
create table testLieToLine(
name string,
col1 int
)row format delimited
fields terminated by '\t';
����1:
select name,collect_list(col1) from testLieToLine group by name;

����2:
select t1.name
,collect_list(t1.col1)
from (
select name
,col1
from testarray2
lateral view explode(weight) t1 as col1
) t1 group by t1.name;

(4)Hive�Զ��庯��UserDefineFunction
??????????????????????????���ҷ���Ŀ¼
? UDF:һ��һ��
??????????????????????????���ҷ���Ŀ¼
- ����maven��Ŀ,����������
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
- ��д����,�̳�org.apache.hadoop.hive.ql.exec.UDF,ʵ��evaluate����,��evaluate������ʵ���Լ�����
import org.apache.hadoop.hive.ql.exec.UDF;
public class HiveUDF extends UDF {
// hadoop => #hadoop$
public String evaluate(String col1) {
// �������������� ����� # �� �ұ��� $
String result = "#" + col1 + "$";
return result;
}
}
- ���jar�����ϴ���Linux�����(С��·��:/usr/local/soft/jars/)
- ��hive shell��,ʹ��
add jar ·����jar����Ϊ��Դ���ӵ�hive������
add jar /usr/local/soft/jars/HiveUDF2-1.0.jar;
- ʹ��jar����Դע��һ����ʱ����,fxxx1����ĺ�����,'MyUDF����������
create temporary function fxxx1 as 'MyUDF';
- ʹ�ú�������������
select fxx1(name) as fxx_name from students limit 10;
#ʩЦ��$
#������$
#������$
#�����$
#������$
#�߰���$
#�й·�$
#����˫$
#��²�$
#�����$
?UDTF:һ�����
??????????????????????????���ҷ���Ŀ¼
��������:
"key1:value1,key2:value2,key3:value3"
key1 value1
key2 value2
key3 value3
����һ:ʹ�� explode+split
select split(t.col1,":")[0],split(t.col1,":")[1]
from (select
explode(split("key1:value1,key2:value2,key3:value3",",")) as
col1) t;
������:�Զ�UDTF
//�Զ������
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class HiveUDTF extends GenericUDTF {
// ָ����������� �� ����
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
ArrayList<String> filedNames = new ArrayList<String>();
ArrayList<ObjectInspector> filedObj = new ArrayList<ObjectInspector>();
filedNames.add("col1");
filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
filedNames.add("col2");
filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(filedNames, filedObj);
}
// ������ my_udtf(col1,col2,col3)
// "key1:value1,key2:value2,key3:value3"
// my_udtf("key1:value1,key2:value2,key3:value3")
public void process(Object[] objects) throws HiveException {
// objects ��ʾ�����N��
String col = objects[0].toString();
// key1:value1 key2:value2 key3:value3
String[] splits = col.split(",");
for (String str : splits) {
String[] cols = str.split(":");
// ���������
forward(cols);
}
}
// ��UDTF����ʱ����
public void close() throws HiveException {
}
}
SQL:
select my_udtf("key1:value1,key2:value2,key3:value3");
����˵��:
�ֶ�:id,col1,col2,col3,col4,col5,col6,col7,col8,col9,col10,col11,col12
��13������:
a,1,2,3,4,5,6,7,8,9,10,11,12
b,11,12,13,14,15,16,17,18,19,20,21,22
c,21,22,23,24,25,26,27,28,29,30,31,32
ת��3��:id,hours,value
����:
a,1,2,3,4,5,6,7,8,9,10,11,12
a,0ʱ,1
a,2ʱ,2
a,4ʱ,3
a,6ʱ,4
��
����:
create table udtfData(
id string
,col1 string
,col2 string
,col3 string
,col4 string
,col5 string
,col6 string
,col7 string
,col8 string
,col9 string
,col10 string
,col11 string
,col12 string
)row format delimited fields terminated by ',';
java����:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class HiveUDTF2 extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
ArrayList<String> filedNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldObj = new ArrayList<ObjectInspector>();
filedNames.add("col1");
fieldObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
filedNames.add("col2");
fieldObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(filedNames, fieldObj);
}
public void process(Object[] objects) throws HiveException {
int hours = 0;
for (Object obj : objects) {
hours = hours + 1;
String col = obj.toString();
ArrayList<String> cols = new ArrayList<String>();
cols.add(hours + "ʱ");
cols.add(col);
forward(cols);
}
}
public void close() throws HiveException {
}
}
����jar��Դ:
add jar /usr/local/soft/HiveUDF2-1.0.jar;
ע��udtf����:
create temporary function my_udtf as 'MyUDTF';
SQL:
select id
,hours
,value from udtfData lateral view
my_udtf(col1,col2,col3,col4,col5,col6,col7,col8,col9,col10,col11,col12)
t as hours,value ;
?UDAF:���һ��
??????????????????????????���ҷ���Ŀ¼
���ķ���: hive�Զ��庯��ѧϰ
3��Hive �е�wordCount
??????????????????????????���ҷ���Ŀ¼
����:
create table words(
words string
)row format delimited fields terminated by '|';
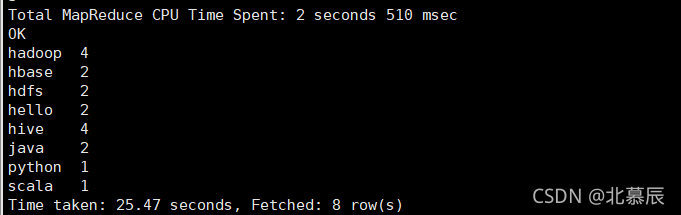
����:
hello,java,hello,java,scala,python
hbase,hadoop,hadoop,hdfs,hive,hive
hbase,hadoop,hadoop,hdfs,hive,hive

select word,count(*) from (select explode(split(words,',')) word from words) a group by a.word;
�ߡ�Hive ��Shellʹ��
??????????????????????????���ҷ���Ŀ¼
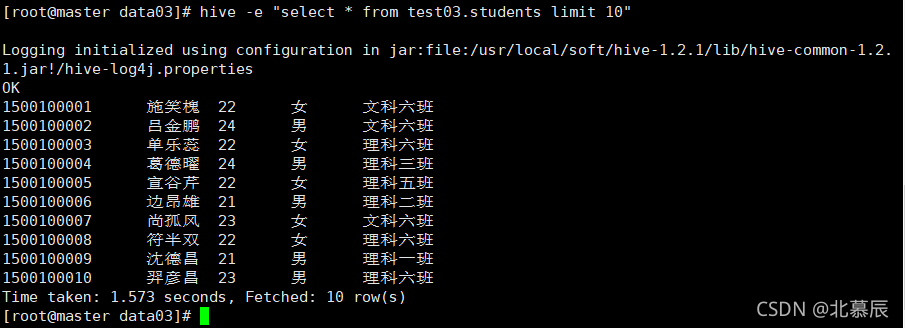
��һ��shell
hive -e "select * from test03.students limit 10"
�ڶ���shell
hive -f hql�ļ�·��
# ��HQLд��һ���ļ���,��ʹ�� -f ����ָ�����ļ�