����Ŀ¼
Ϊ��Ҫ�RabbitMQ��Ⱥ?
���ֻ��Ϊ��ѧϰRabbitMQ������֤ҵ�̵���ȷ����ô�ڱ��ػ������߲��Ի�����ʹ���䵥ʵ������Ϳ�����,���dz���MQ�м�������Ŀɿ��ԡ������ԡ�����������Ϣ�ѻ�����������Ŀ���,������������һ�㶼�ῼ��ʹ��RabbitMQ�ļ�Ⱥ������
��Ⱥ����ԭ��
RabbitMQ�����Ϣ�����м����Ʒ�����ǻ���Erlang��д,Erlang���������߱��ֲ�ʽ����(ͨ��ͬ��Erlang��Ⱥ���ڵ��magic cookie��ʵ��)�����,RabbitMQ��Ȼ֧��Clustering����ʹ��RabbitMQ��������Ҫ��ActiveMQ��Kafka����ͨ��ZooKeeper�ֱ���ʵ��HA�����ͱ��漯Ⱥ��Ԫ���ݡ���Ⱥ�DZ�֤�ɿ��Ե�һ�ַ�ʽ,ͬʱ����ͨ��ˮƽ��չ�Դﵽ������Ϣ������������Ŀ�ġ�
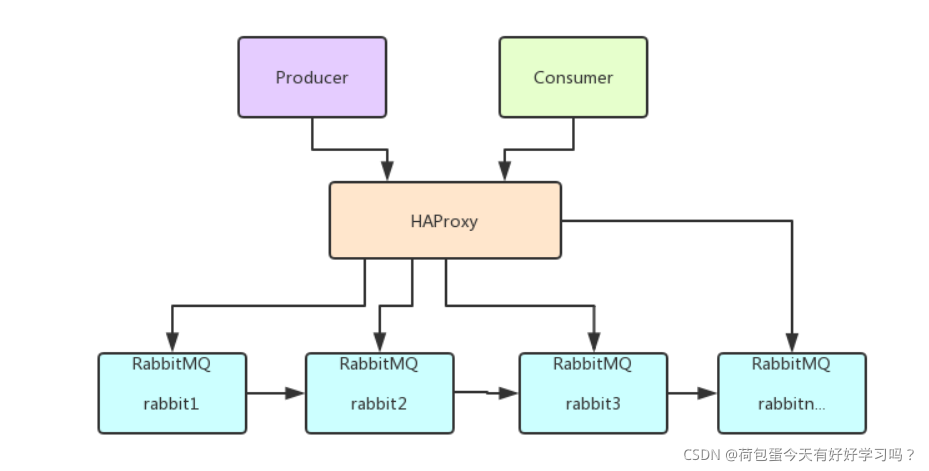
���ö��RabbitMQ�Ľڵ�,�ڵ�֮��ʹ�þ��������ͬ������,������ʹ��HAProxy�������,��ôHAProxy����Ϊ ������ʵĹ�����ʽ,�������������������߶�����HAProxy,��ͨ��HAProxy����RabbitMQ�Ľڵ�,�����е�ijЩ�ڵ����Ҳû��ϵ,ֻҪ��һ�����ͺ�,�ҵ��Ľڵ����ú������ֻᱻͬ���á�
������ʵ����ʽ���Ⱥ
��һ̨�����������2��RabbitMQ�Ľڵ�,��ڵ�֮���ö˿�����(ʵ�ʴ��Ⱥʽ��ip����)�����Ʒ�������,�ǵ�ȥ������Ӧ�˿ڡ�
�ο��ٷ��ĵ�:https://www.rabbitmq.com/clustering.html
����:
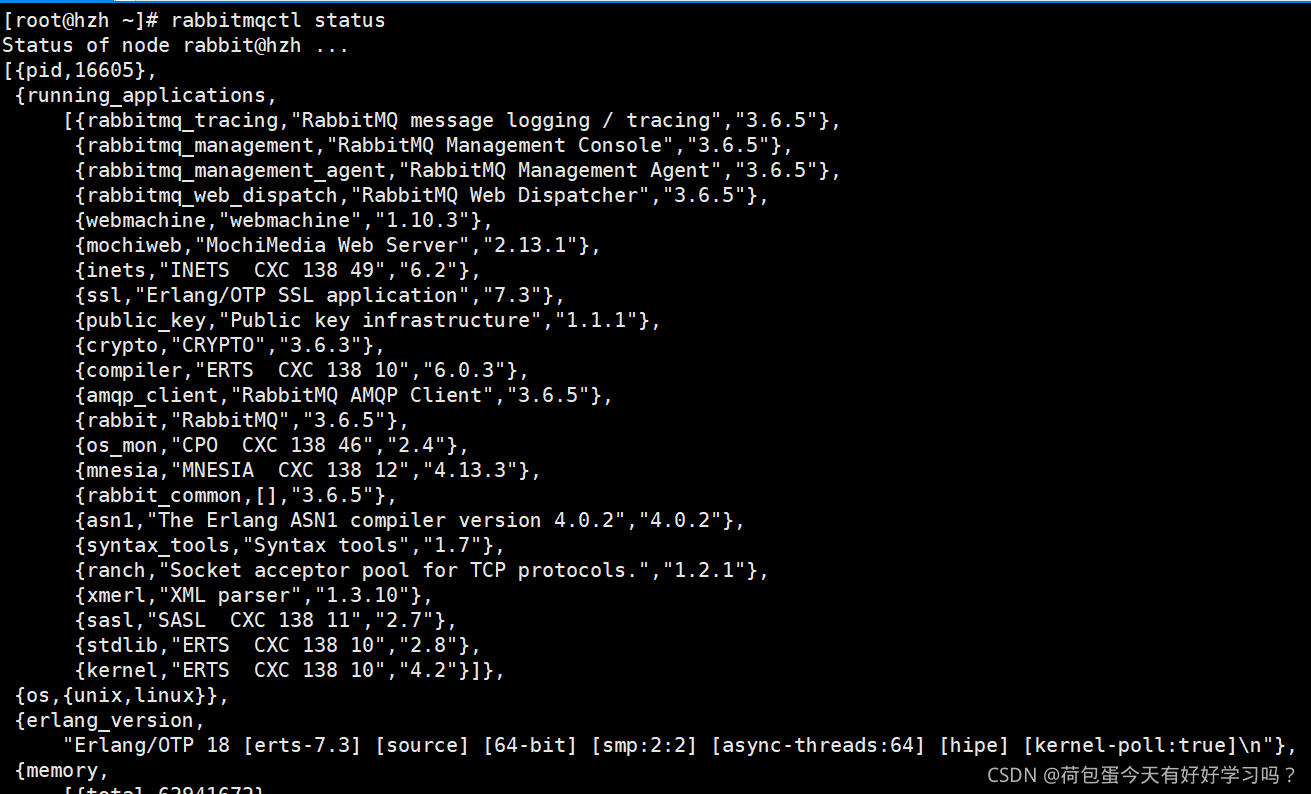
1.��ȷ��RabbitMQ����û������
����:rabbitmqctl status
2.ֹͣrabbitmq����
����:service rabbitmq-server stop

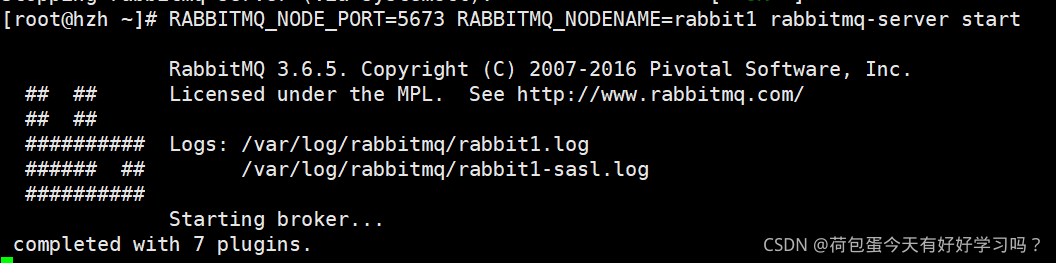
3.������һ���ڵ�:
����:
RABBITMQ_NODE_PORT=5673 RABBITMQ_NODENAME=rabbit1 rabbitmq-server start
4.�������һ���ڵ��,��¡�Ự���������ڶ����ڵ�
web��������˿�ռ��,���Ի�Ҫָ����web���ռ�õĶ˿ںš�
����: RABBITMQ_NODE_PORT=5674 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15674}]" RABBITMQ_NODENAME=rabbit2 rabbitmq-server start

�ٸ���һ���Ự���нڵ�����
5.rabbit1������Ϊ���ڵ�:
����ִ����������:
rabbitmqctl -n rabbit1 stop_app
rabbitmqctl -n rabbit1 reset
rabbitmqctl -n rabbit1 start_app
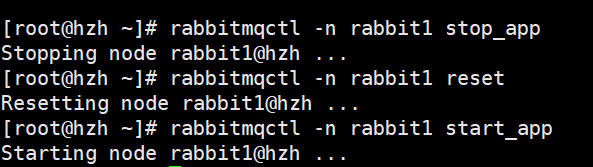
6.rabbit2����Ϊ�ӽڵ�:
����ִ����������:
rabbitmqctl -n rabbit2 stop_app
rabbitmqctl -n rabbit2 reset
rabbitmqctl -n rabbit2 join_cluster rabbit1@��super�� ###��'���������������Լ���
rabbitmqctl -n rabbit2 start_app
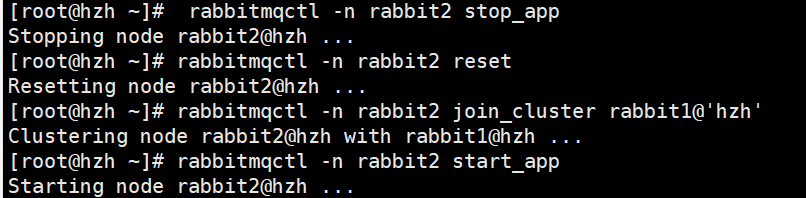
7.�鿴��Ⱥ״̬
rabbitmqctl cluster_status -n rabbit1
����,rabbit1��rabbit2�����һ����Ⱥ,���ǻ�������,����������(�����ݲ�ͬ��)
���ڵ�:
���Կ������˵���������

�ӽڵ�:
���Կ������˵���������
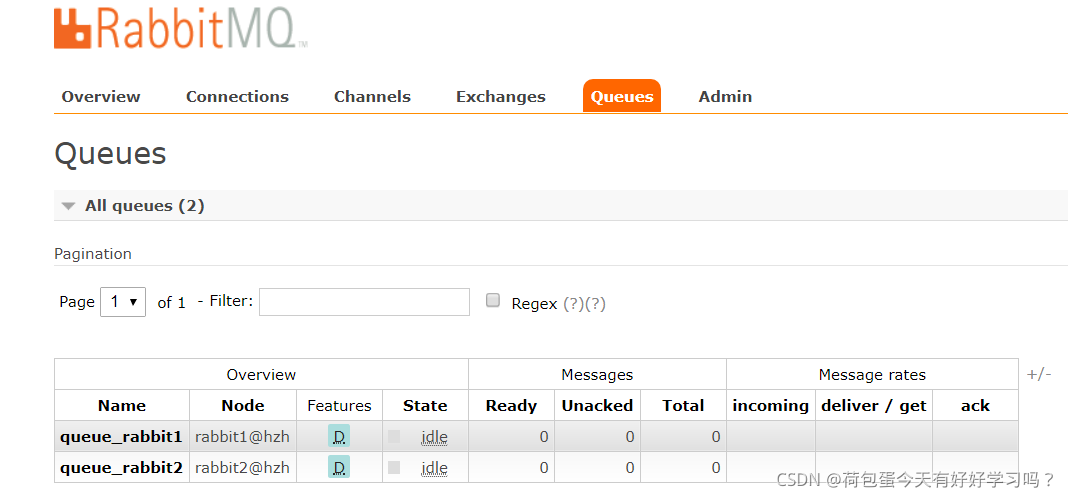
���ӽڵ��ϵ�rabbit2���з�һ����Ϣ
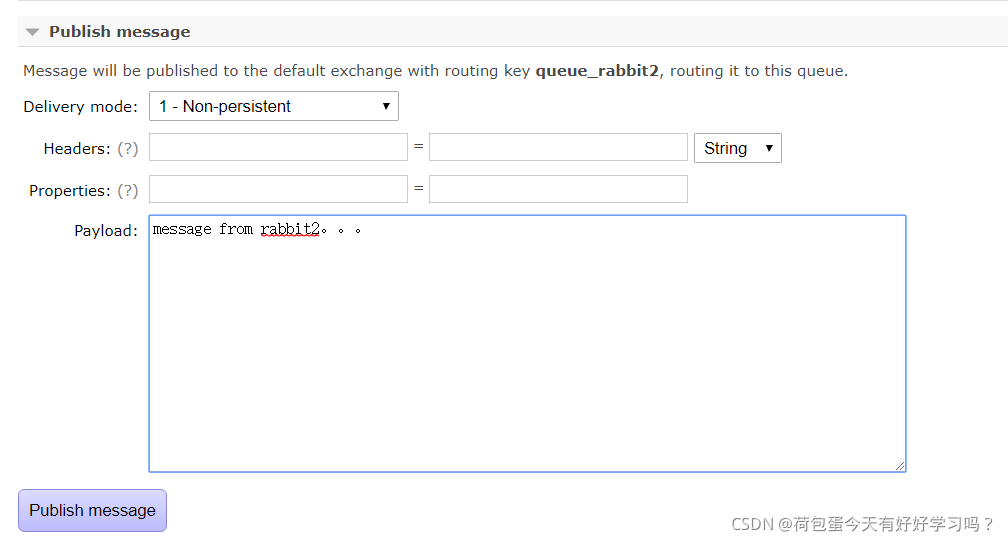

�ٿ����ڵ�:
Ҳ���Կ���rabbit2������һ����Ϣ

���������е�ʱ�����Ī��ʲô����,��ʱ�ֶ���rabbit2�ӽڵ�ҵ�

�ٴ����ڵ㿴:
ֱ���ò���������

�շ�����Ϣ�Ǹ��ӽڵ�,�ӽڵ�û��֮ǰ���ڵ�����õ�����,�ӽڵ���˺�ֱ�Ӿ�?,��˵����Ϣʵ�ʴ������Լ��Ľڵ���,Ҳ��������ûͬ���������˸չҵ��Ĵӽڵ�,��ϢҲû�ˡ�����

��Ⱥ����
rabbitmqctl join_cluster {cluster_node} [�Cram]
���ڵ����ָ����Ⱥ�С����������ִ��ǰ��ҪֹͣRabbitMQӦ�ò����ýڵ㡣
rabbitmqctl cluster_status
��ʾ��Ⱥ��״̬��
rabbitmqctl change_cluster_node_type {disc|ram}
�ļ�Ⱥ�ڵ�����͡����������ִ��ǰ��ҪֹͣRabbitMQӦ�á�
rabbitmqctl forget_cluster_node [�Coffline]
���ڵ�Ӽ�Ⱥ��ɾ��,��������ִ�С�
rabbitmqctl update_cluster_nodes {clusternode}
�ڼ�Ⱥ�еĽڵ�Ӧ������ǰ��ѯclusternode�ڵ��������Ϣ,��������Ӧ�ļ�Ⱥ��Ϣ�������join_cluster��ͬ,�������뼯Ⱥ����������һ�����,�ڵ�A�ͽڵ�B���ڼ�Ⱥ��,���ڵ�A������,�ڵ�C�ֺͽڵ�B�����һ����Ⱥ,Ȼ��ڵ�B���뿪�˼�Ⱥ,��A������ʱ��,���᳢����ϵ�ڵ�B,����������ʧ��,��Ϊ�ڵ�B�Ѿ����ڼ�Ⱥ���ˡ�
rabbitmqctl cancel_sync_queue [-p vhost] {queue}
ȡ������queueͬ������IJ�����
����Ⱥ����
�����Ѿ����RabbitMQĬ�ϼ�Ⱥģʽ,��������֤���еĸ߿�����,���ܽ�����������Щ���Ը��Ƶ���Ⱥ����κ�һ���ڵ�,���Ƕ������ݲ��Ḵ�ơ���Ȼ��ģʽ���һ��Ŀ��ڵ�ѹ��,�����нڵ�崻�ֱ�ӵ��¸ö�����Ӧ��,ֻ�ܵȴ�����,����Ҫ���ڶ��нڵ�崻������Ҳ������Ӧ��,��Ҫ���ƶ������ݵ���Ⱥ���ÿ���ڵ�,����Ҫ����������С�
��������ǻ�����ͨ�ļ�Ⱥģʽ��,Ȼ��������һЩ����,�����㻹�ǵ���������ͨ��Ⱥ,Ȼ��������þ������,���Ǿ�������ļ�Ⱥ��������
���õľ�����п���ͨ����������ҳ�Ĺ�����Admin->Policies,Ҳ����ͨ�����
����ķ�ʽ: rabbitmqctl set_policy my_ha ��^�� ��{��ha-mode��:��all��}��
ͨ����������ҳ�Ĺ�����:
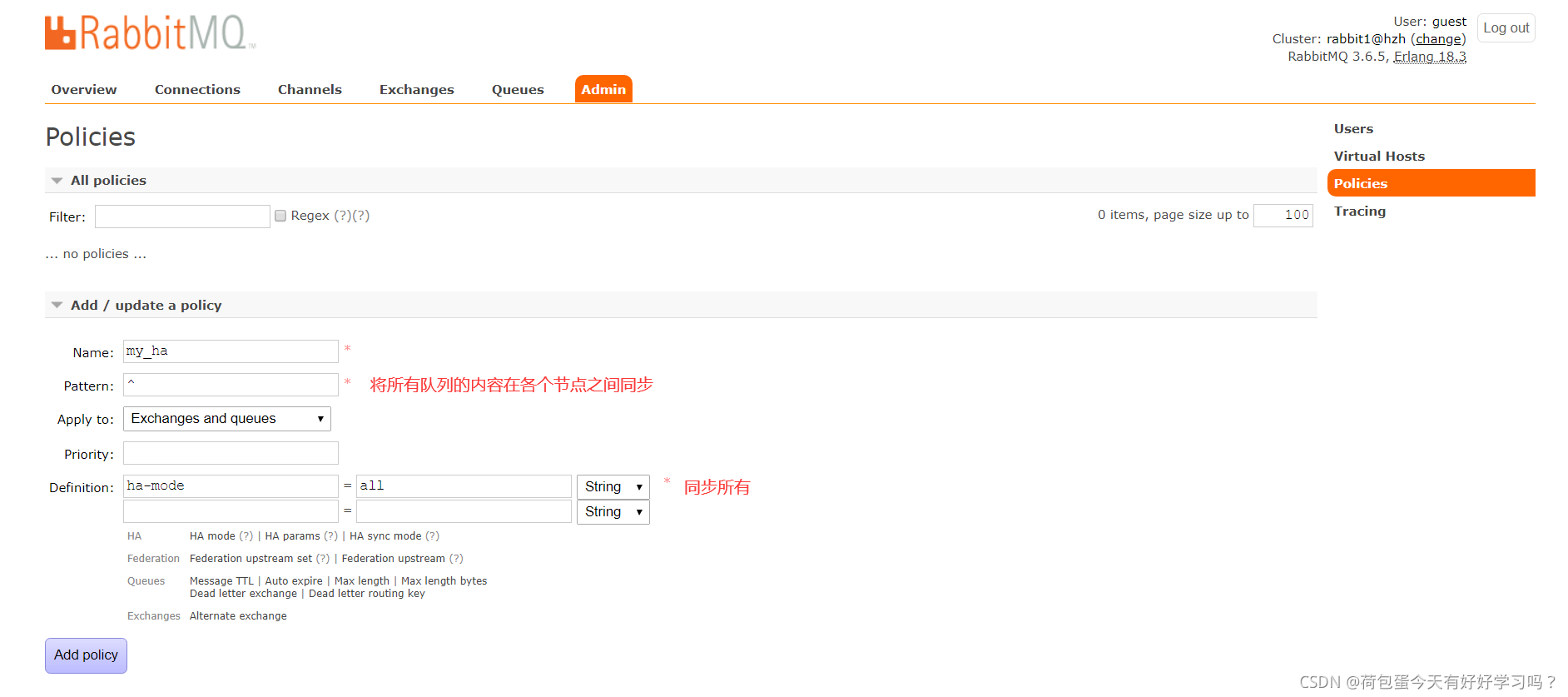
- Name:��������
- Pattern:ƥ��Ĺ���,�����ƥ�����еĶ���,��^.
- Definition:ʹ��ha-modeģʽ�е�all,Ҳ����ͬ������ƥ��Ķ��С��ʺ����Ӱ����ĵ���
�ڽ��о���Ⱥ�����ú�:
�����ڵ㿴:

��������rabbit1��,���Կ�����ʾ��ͬ����rabbit2�ڵ㡣
�Ǹ�+���ͱ�ʾҪͬ���������ڵ���ȥ
�ڴӽڵ㿴:

���Կ���rabbit2ͬ����rabbit1��
���������ڵ�ҵ�һ��,��һ��Ҳ���ᶪʧ����,�ҵ����Ǹ�����������Ҳ������ͬ����
�������µ����������,������ͨ���������RabbitMQʱ,�Ƿ��ʵ�һ���ڵ���?���ǵڶ���?���ʵ���һ������զ��?������������дһ��ͳһ��ip�Ͷ˿ں�,�����������˻������Ѷ�,��ͨ�����ip�Ͷ˿�������RabbitMQ�ϵ�����ڵ㡣
���ؾ���-HAProxy
��װHAProxy
//����������
yum install gcc vim wget
//�ϴ�haproxyԴ���
//��ѹ
tar -zxvf haproxy-1.6.5.tar.gz -C /usr/local
//����Ŀ¼�����б��롢��װ
cd /usr/local/haproxy-1.6.5
make TARGET=linux31 PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
//��Ȩ
groupadd -r -g 149 haproxy
useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy
//����haproxy�����ļ�
mkdir /etc/haproxy
vim /etc/haproxy/haproxy.cfg
����HAProxy
�����ļ�·��:/etc/haproxy/haproxy.cfg
#logging options
global
log 127.0.0.1 local0 info
maxconn 5120
chroot /usr/local/haproxy
uid 99
gid 99
daemon
quiet
nbproc 20
pidfile /var/run/haproxy.pid
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
contimeout 5s
clitimeout 60s
srvtimeout 15s
#front-end IP for consumers and producters
listen rabbitmq_cluster
bind 0.0.0.0:5672 #�����ṩ����Ķ˿�
mode tcp
#balance url_param userid
#balance url_param session_id check_post 64
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
balance roundrobin
#�ڵ��ip
server node1 127.0.0.1:5673 check inter 5000 rise 2 fall 2
server node2 127.0.0.1:5674 check inter 5000 rise 2 fall 2
listen stats
bind 172.16.98.133:8100 #HAProxy��������̨�ĵ�ַ,����ip�ǵû�
mode http
option httplog
stats enable
stats uri /rabbitmq-stats
stats refresh 5s
����HAproxy����
��������:/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
//�鿴haproxy����״̬
ps -ef | grep haproxy
�������µ�ַ��mq�ڵ���м��(����ip�����Լ�������ĵ�)
http://172.16.98.133:8100/rabbitmq-stats
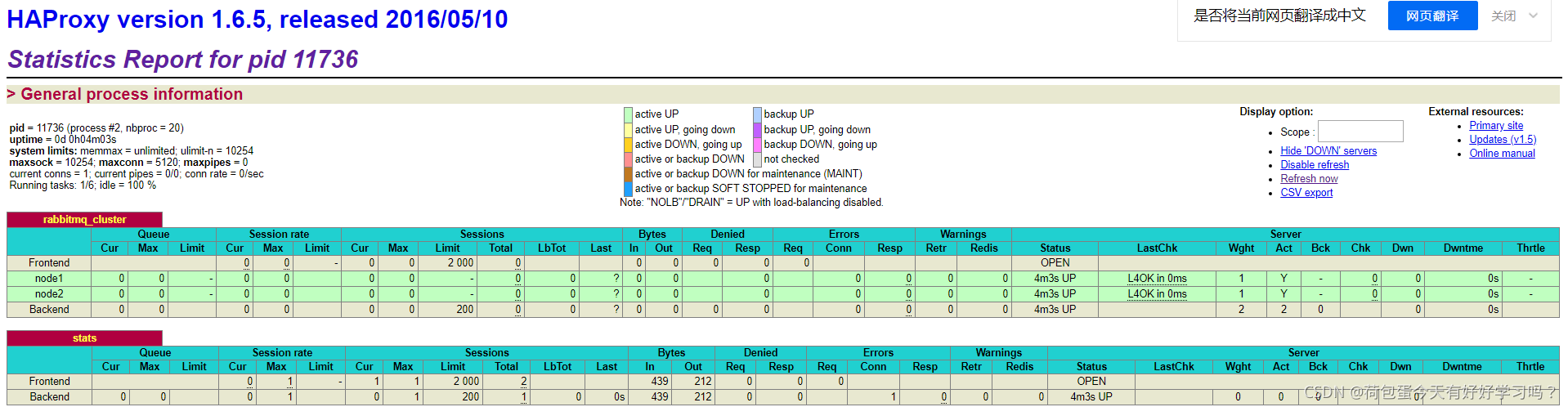
�����з���mq��Ⱥ��ַ,���Ϊ����haproxy��ַ:5672
������Լ�Ⱥ
helloworld������:
public class ProducerHelloWorldHAProxyTest {
public static void main(String[] args) throws IOException, TimeoutException {
//1.�������ӹ���
ConnectionFactory factory = new ConnectionFactory();
//2.����
factory.setHost("106.15.50.230"); //ip,����HAProxy��������ip
factory.setPort(5672); //�˿� ����HAProxy�������Ķ˿�
factory.setVirtualHost("/"); //����� Ĭ��/
factory.setUsername("guest"); //�û��� Ĭ��guest
factory.setPassword("guest"); //���� Ĭ��guest
//3.�������� Connection
Connection connection = factory.newConnection();
//4.���� Channel
Channel channel = connection.createChannel();
//5.��������
/**
* queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete, Map<String, Object> arguments)
* ����:
* 1.queue:��������
* 2.durable:�Ƿ�־û�,��Ŀǰ������,����
* 3.exclusive:
* �Ƿ��ռ,��ֻ��һ�����������˿�
* ��Connection�ر�ʱ,�Ƿ�ɾ������
* 4.autoDelete:�Ƿ��Զ�ɾ��,��û��Consumerʱ�Զ�ɾ������
* 5.arguments:����
*/
//��û��ͬ���Ķ���,��ᴴ��,���ᴴ��
channel.queueDeclare("queue_haproxy",true,false,false,null);
//6.������Ϣ
String body = "hello haproxy~";
/**
* basicPublish(String exchange, String routingKey, BasicProperties props, byte[] body)
* ����:
* 1.exchange:���������ơ���ģʽ��ʵ��ʹ��""��ʾʹ��Ĭ�ϵĽ�����AMQP
* 2.routingKey:·�ɵ�����
* 3.props:������Ϣ
* 4.body:���͵���Ϣ����
*/
//ʹ��Ĭ�ϵĽ�����ʱ,routingKey��Ҫ�Ͷ��е�����һ������·�ɵ���Ӧ�Ķ���
channel.basicPublish("","queue_haproxy",null,body.getBytes());
//7.�ͷ���Դ
channel.close();
connection.close();
}
}
���к�,�鿴RabbitMQManagement:
���Կ����ɹ������˶���,��������һ����Ϣ

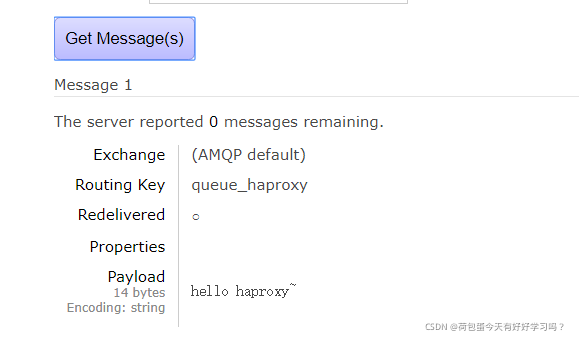
��ʱ���ǹҵ�һ���ڵ�,:

������һ������Ĵ����:
���Կ����������Ľڵ��ϵĶ����յ�����Ϣ

���������ҵ��Ľڵ�:
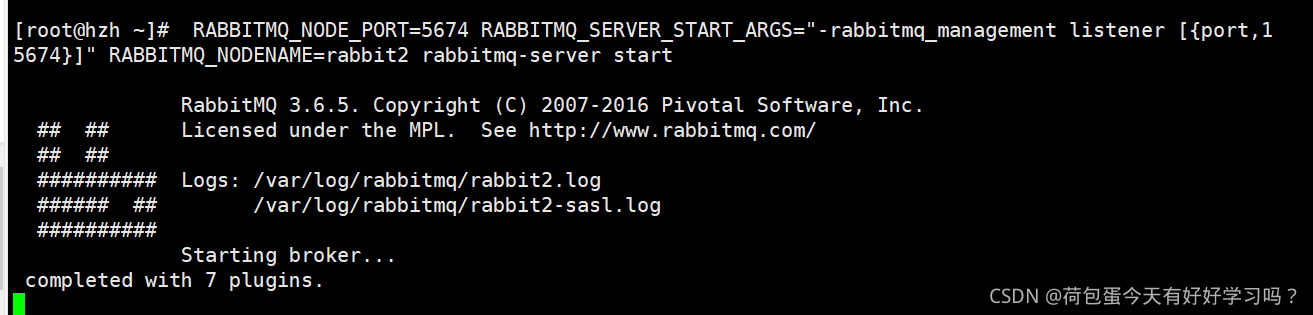
ȥ����̨�鿴:
ͬ��������
