目录
MapReduce框架原理
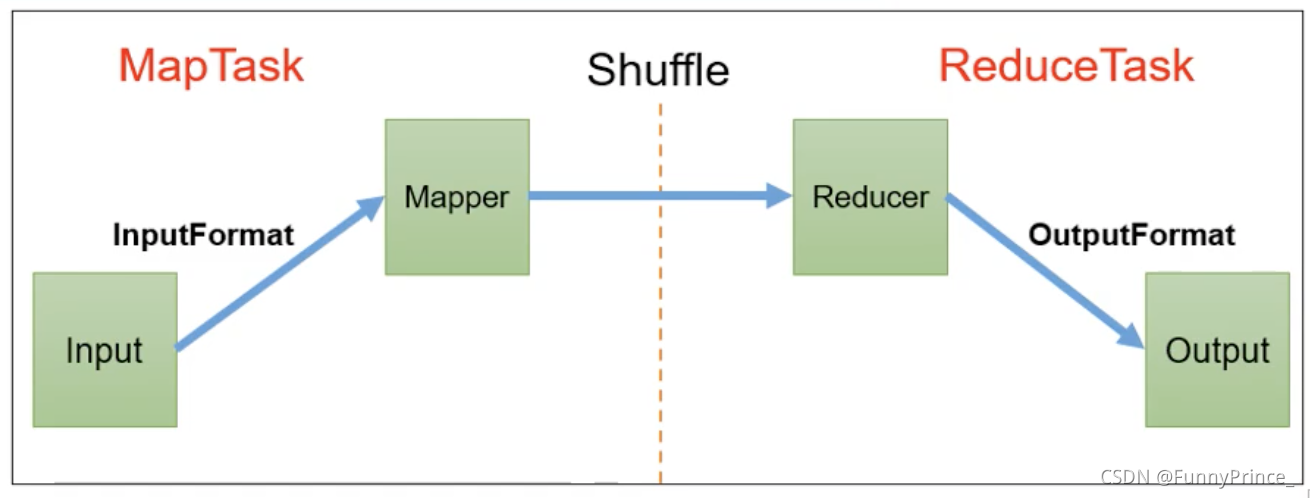
一、InputFormat数据输入
1. 切片与MapTask并行度决定机制
1.问题:
MapTask的并行度决定Map阶段的任务处理并发度,进而影响整个job的处理速度。
但是相对于1G数据启动8个MapTask,可以提高集群的并发处理能力。1k的数据数据启动8个MapTask不一定会提高集群性能;MapTask并行任务是否越多越好?哪些因素影响了MapTask并行度?
2.MapTask并行度决定机制
数据块:block是HDFS物理上把数据进行分块(0-128MB)。数据块是HDFS存储数据单位;
数据切片:数据切片只是逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
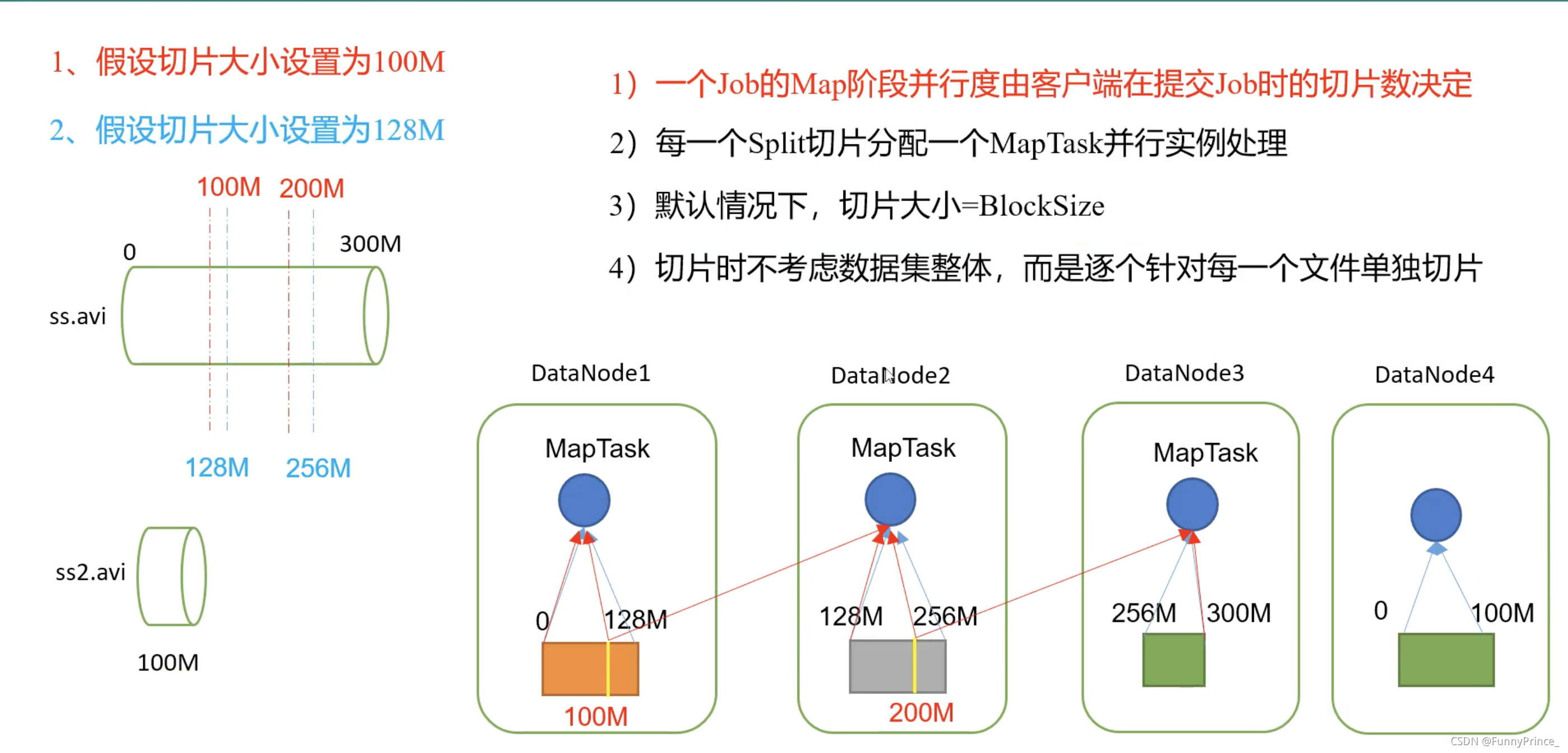
tips: 切片大小最好与block大小一致,即设置默认128MB,处理更加有效率。
FielInputFormat切片源码解析:

2. FielInputFormat切片机制

3. FileInputFormat切片大小的参数设置

4. TextInputFormat
1).FileInputFormat实现类
在运行MapReduce程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce时如何读取这些数据的呢?
FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
2).TextInputFormat
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键时存储该行在整个文件中的起始字节偏移量,LongWritable类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text类型。
5. CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的Maptask,处理效率极其低下。
1). 应用场景
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2). 虚拟存储切片最大值设置
CombineTextInputFormat.setmaxInputSplitSize(job,4194304); // 4M
tips: 虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3). 切片机制
生成切片过程包括:虚拟存储过程和切片过程两部分。

二、MapReduce工作流程
切片数量影响Maptask,分区数量影响ReduceTask。
MapReduce详细工作流程一:
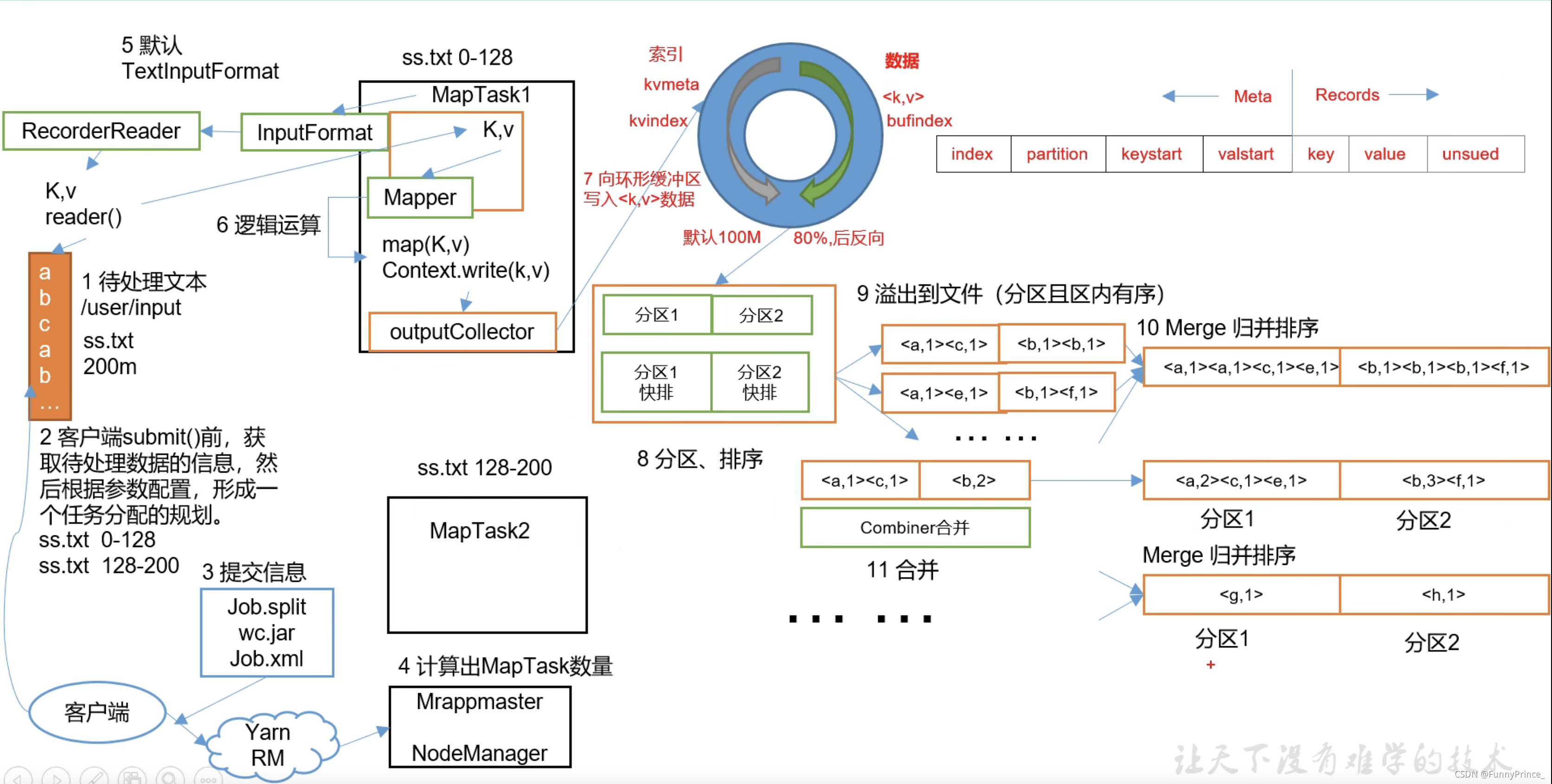
tips: 步骤7. 数据往内存中写到80%的时候,新开了一个线程把内存中的旧数据往磁盘的文件进行溢写,另一个线程继续把从MapTask来的数据写到内存里,因为此时还未到100%,所以新的数据可以正常写,不需要等所有的数据都溢写完后再开始。
若是往内存写数据的线程写到交界点,它会等溢写完成后再继续写,此处的等待时间会比写到100%之后溢写等待的时间短,且此时的等待是为了保证数据干净必须等待的。
步骤8. 在溢写之前对数据进行排序,通过对key的索引按照字典顺序进行快速排序。
步骤10. 对溢写之后的数据进行归并排序。
combiner在聚合操作的场景下,使得传到Reduce的数据量变小( <a,1><a,1> ==> <a,2> ),从而提高效率。
MapReduce详细工作流程二:
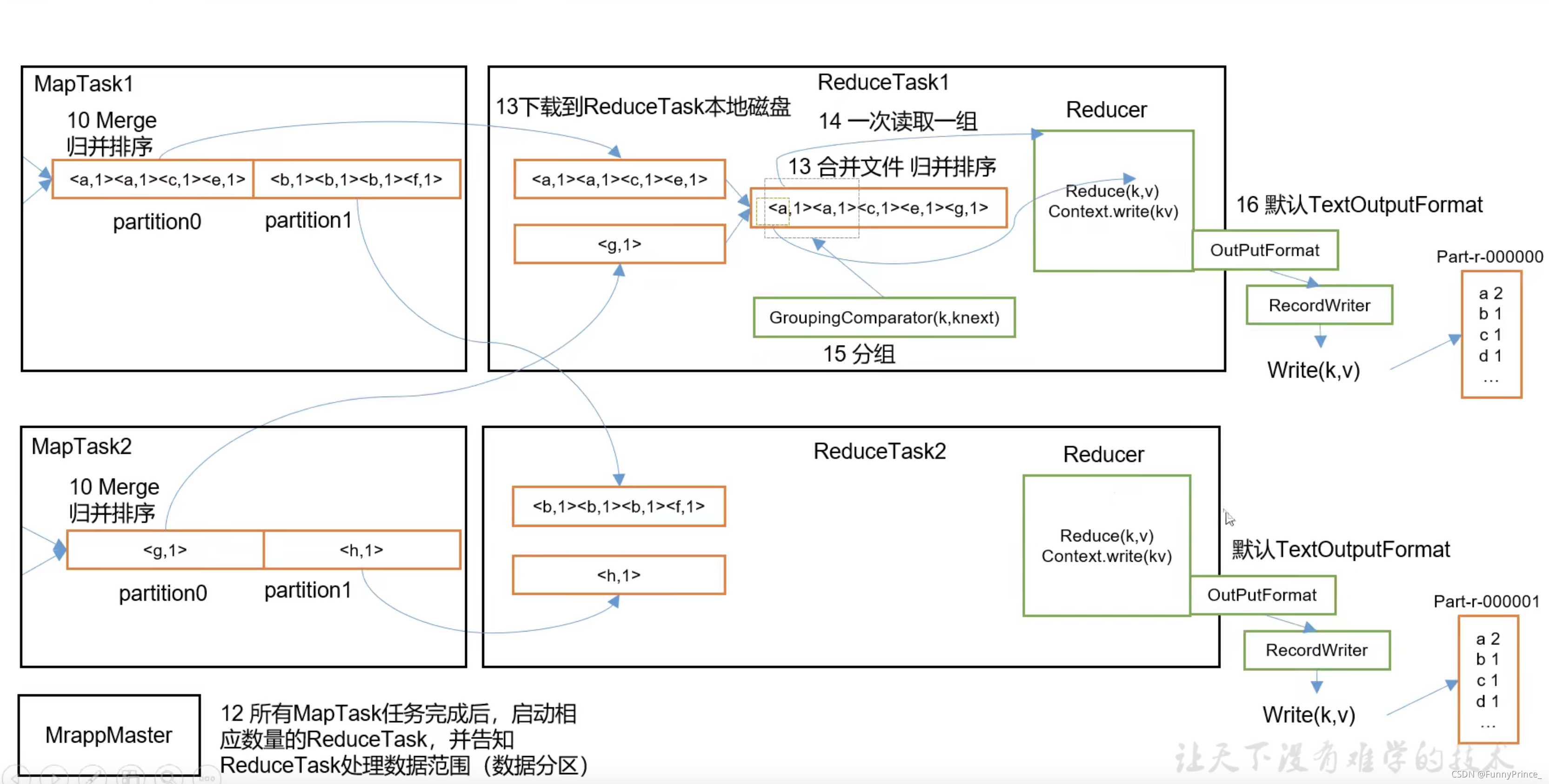
tips: 步骤13. ReduceTask主动从MapTask分区拉取数据,而不是等待MapTask传递数据给它。