一、Redis如何处理海量数据存储?
Redis从官方3.0开始,提供了RedisCluster的方案,与MySQL分库分表类似,Redis Cluster也是通过分片的方式,把数据分布到不同的节点上。
对于分片,Redis Cluster引入了“槽(slot)”的概念,每个集群的槽都是固定的16384个,在Redis Cluster构建的时候,节点会自动分配这16384个槽,而且每个key落在哪个槽也是固定的。对于一个key,会先计算Key的CRC值,在取模获取到所在槽的下标,计算方法:
HASH_SLOT = CRC16(key) mod 16384
客户端可以连接任意一个节点来访问集群的数据,Redis Cluster本身是采用去中心化的设计思路。客户端请求一个 Key 的时候,被请求的那个 Redis 实例会先计算key在哪个槽,然后再查询槽和节点的映射关系找到真正节点,如果刚好是自己,那么就会执行命令,如果数据不在当前节点上,就给客户端返回一个重定向的命令,告诉客户端,应该去连哪个节点上请求这个 Key 的数据。
Redis Cluster 支持水平扩容来增加集群的存储容量。但是因为集群里16384个槽是固定的,因此每次增加节点时都需要从集群的老节点中,搬运一些槽到新节点,也手动指定哪些槽迁移到新节点上,或者利用官方提供的redis-trib.rb脚本自动重新分配,自动迁移。
二、Redis Cluster怎么保证高可用?
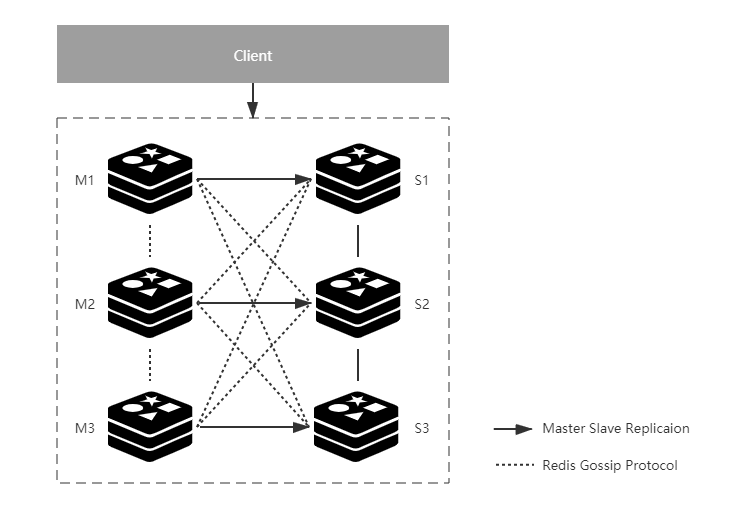
分片可以解决Redis海量数据存储的问题,对于HA高可用,通常的处理方式采用多副本的方式。Redis Cluster 支持给每个分片增加一个或多个从节点,每个从节点在连接到主节点上之后,会先给主节点发送一个 SYNC 命令,进行全量复制。全量复制完成之后,进入同步阶段,主节点会把全量复制期间收到的命令,以及后续收到的命令增量的方式同步到从节点。
如果某个分片的主节点宕机了,集群中的其他节点会重新选出一个新的节点作为主节点继续提供服务。新的主节点选举出来后,集群中的所有节点都会感知到,如果客户端的请求 key 刚好落在故障分片上,就会被重定向到新的主节点上。
三、Redis Cluster怎么处理高并发问题?
一般来说,Redis Cluster 进行了分片之后,每个分片都会承接一部分并发的请求,加上 Redis 本身单节点的性能就非常高,所以大部分情况下不需要再像 MySQL 那样做读写分离来解决高并发的问题。默认情况下,集群的读写请求都是由主节点负责的,从节点只是起一个热备的作用。当然了,Redis Cluster 也支持读写分离,在从节点上读取数据。原理图如下:
四、为什么Redis Cluster不适合超大规模集群?
Redis Cluster 的优点是易于使用。分片、主从复制、弹性扩容这些功能都可以做到自动化,通过简单的部署就可以获得一个大容量、高可靠、高可用的 Redis 集群,并且对于应用来说,近乎于是透明的。
所以,Redis Cluster 是非常适合构建中小规模 Redis 集群,集群大概几个到几十个节点这样的规模。
Redis Cluster 不太适合构建超大规模集群,主要原因是:采用了去中心化的设计。Redis 每个节点上,都保存了所有槽和节点的映射关系表,客户端可以访问任意一个节点,再通过重定向命令,找到数据所在的那个节点。那么则需要去维护这份映射数据,比如说,集群加入了新节点,或者某个主节点宕机了,新的主节点被选举出来,而Redis采用了Gossip协议来传播集群配置的变化。
Gossip好处是去中心化,不需要组织,便于部署和维护,也避免了中心节点的单点故障问题。但他的缺点是传播速度比较慢,并且是集群规模越大,传播的越慢。在集群规模太大的情况下,数据不同步的问题会被明显放大,存有一定的不确定性,如果出现问题很难排查。
五、如何用Redis构建超大规模集群?
一种是基于代理的方式,在客户端和Redis节点之间,增加一层代理服务。主要有三个作用:
1:负责在客户端和Redis之间转发请求和响应,客户端只和代理服务打交道,代理收到客户端的请求之后,再转发到对应的 Redis 节点上,节点返回的响应再经由代理转发返回给客户端。
2:负责监控集群中所有 Redis 节点状态,如果发现有问题节点,及时进行主从切换。
3:就是维护集群的元数据,这个元数据主要就是集群所有节点的主从信息,以及槽和节点关系映射表。
开源Redis集群解决方案twemproxy和Codis就是这种架构。
这个架构最大的优点是对客户端透明,在客户端视角来看,整个集群就是一个大容量的Redis单节点。并且,由于分片算法是代理服务控制的,扩容也比较方便,新节点加入集群后,直接修改代理服务中的元数据就可以完成扩容。不过,因为增加了一层代理转发,每次数据访问的链路更长了,必然会带来一定的性能损失,而且,还需要考虑代理服务本身的高可用。
另一种就是不用代理服务,把代理服务的寻址功能前移到客户端中去,整体类似注册中心的思想。客户端在发起请求之前,先去查询元数据,获得要访问的分片和节点,再直连对应的 Redis 节点访问数据。
当然,客户端不用每次都去查询元数据,因为一般元数据变化的概率比较小,客户端可以进行本地缓存元数据,当某个分片的主节点宕机了,新的主节点被选举出来之后,再通知更新元数据信息。对集群的扩容操作也比较简单,除了迁移数据的工作必须要做以外,更新一下元数据就可以了。
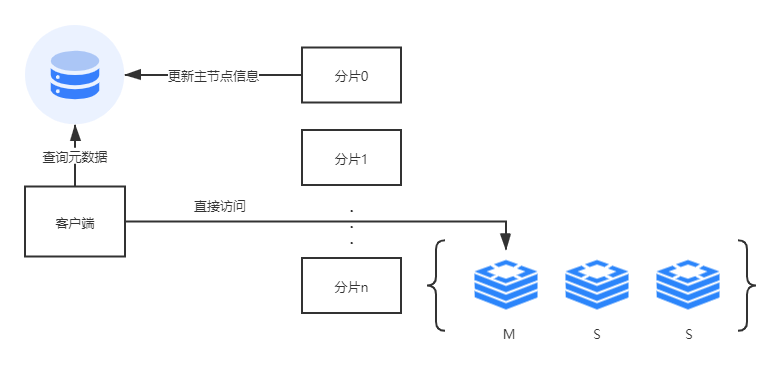
虽然说,元数据服务仍然是单点,但是它的数据量不大,访问量也不大,相对比较容易实现。可以用ZooKeeper、etcd 甚至 MySQL 都能满足要求。这个方案应该是最适合超大规模 Redis 集群的方案了,在性能、弹性、高可用几方面表现都非常好,缺点是整个架构比较复杂,客户端不能通用,需要开发定制化的 Redis 客户端,开发成本比较高。