�������reviewʱ,��һ��SQL�������������ͬѧ�������ۡ�����Ա���ŵ��Ǵ�Ҷ�����ʵ,��explain�鿴���,���ɽ�����顣
ԭ��
֮������дexplain,�����¼���ԭ��:
-
�������MySQL45���������кܶೡ������explain����
-
ǰЩ������һ��SQL��������,ʹ��explain������֤
-
���Ϻܶ�����,ֻ��explain�����ֶεĺ���,ȴû�ж�Ӧʵ��,��Ҹ��ܲ���
-
��explain����һЩ�˽�,��û���ر�����
������Щԭ��,����һ��explain���ֶκ��塣
���ṹ������
���ṹ
���ݿ��д������ű�trace_sp_info��trace_spinfo2,�������ṹ���һ��:
mysql> show create table trace_sp_info;
CREATE TABLE `trace_sp_info` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '����ID',
`sp_id` bigint unsigned NOT NULL DEFAULT '0' COMMENT '������id',
`sp_name` varchar(50) NOT NULL DEFAULT '' COMMENT '����������',
`type` tinyint DEFAULT '0' COMMENT '����������:0��Ӧ�������� 1��˷����� 2��Դ�빩Ӧ��',
`type_name` varchar(50) NOT NULL DEFAULT '' COMMENT '��������������',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '״̬ 0δ���� 1���� 2ʧЧ',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '����ʱ��',
`create_by` varchar(50) NOT NULL DEFAULT '' COMMENT '������',
`update_by` varchar(50) NOT NULL DEFAULT '' COMMENT '������',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '����ʱ��',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_spid` (`sp_id`),
KEY `idx_update_time` (`update_time`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='����������';
����
mysql> select * from trace_sp_info;

mysql> select * from trace_sp_info2;

MySQL�汾
mysql> select version();

�ֶ����
mysql> explain select * from trace_sp_info;

ͨ��explain���,���Կ�����id��select_type��table��partitions��type��possible_keys��key��key_len��ref��rows��filtered��Extra�ֶΡ�
id
����
����SQL����ִ��˳��
-
id�����ͬ,������Ϊ��ͬһ��,��������˳��ִ��
-
idֵԽ��,���ȼ�Խ��,Խ��ִ��;�����Ӳ�ѯ,id����Ż����
ʵ��
ͬid
mysql> explain select * from trace_sp_info2 where id in (select id from trace_sp_info where id = 2);

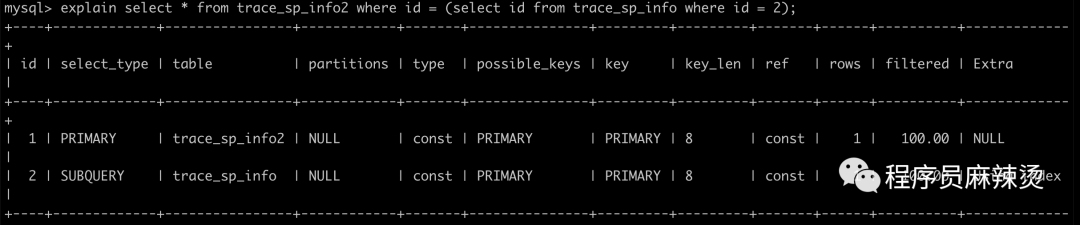
��ͬid
mysql> explain select * from trace_sp_info2 where id = (select id from trace_sp_info where id = 2);
select_type
����
select��ѯ������,��Ҫ����������ͨ��ѯ�����ϲ�ѯ���Ӳ�ѯ֮��ĸ��Ӳ�ѯ������������:
-
SIMPLE:��SELECT,��ʹ��UNION���Ӳ�ѯ��
-
PRIMARY:�Ӳ�ѯ��������ѯ,��ѯ���������κθ��ӵ��Ӳ���,������select�����ΪPRIMARY
-
UNION:UNION�еĵڶ���������SELECT���
-
DEPENDENT UNION:UNION�еĵڶ���������SELECT���,ȡ��������IJ�ѯ
-
UNION RESULT:UNION�Ľ��,union����еڶ���select��ʼ��������select
-
SUBQUERY:�Ӳ�ѯ�еĵ�һ��SELECT,������������ⲿ��ѯ
-
DEPENDENT SUBQUERY:�Ӳ�ѯ�еĵ�һ��SELECT,�������ⲿ��ѯ
-
DERIVED:��������SELECT, FROM�Ӿ���Ӳ�ѯ
-
UNCACHEABLE SUBQUERY:һ���Ӳ�ѯ�Ľ�����ܱ�����,�����������������ӵĵ�һ��
���������SIMPLE��PRIMARY��SUBQUERY��
ʵ��
SIMPLE
mysql> explain select * from trace_sp_info;

PRIMARY+SUBQUERY
mysql> explain select * from trace_sp_info2 where id = (select id from trace_sp_info where id = 2);
table
����
��ʾ��һ��SQL�����ʵı�����,����һ�е�������Դ�����ű�����ʱ������ʵ�ı�����,�����DZ���,Ҳ�����ǵڼ���ִ�еĽ���ļ��
ʵ��
����
mysql> explain select * from trace_sp_info s1, trace_sp_info2 s2 where s1.id=s2.id;

partitions
����
�����ѯ�ǻ��ڷ������Ļ�,����ʾ��ѯ�����ʵķ���
type
����
�Ա��ķ��ʷ�ʽ,��ʾMySQL�ڱ����ҵ������еķ�ʽ,�ֳơ��������͡���ͨ��type���Կ��ٲ鿴SQL���ܡ�
���õ�������: ALL��index��range�� ref��eq_ref��const��system��NULL(������,���ܴӲ��)
-
ALL:Full Table Scan, MySQL������ȫ�����ҵ�ƥ�����
-
index:Full Index Scan,index��ALL����Ϊindex����ֻ����������
-
range:ֻ����������Χ����,ʹ��һ��������ѡ����
-
ref:��ʾ��������ƥ������,����Щ�л��������ڲ����������ϵ�ֵ,��ָ��ֵ,�����Ƿ�Χ
-
eq_ref:����ref,�������ʹ�õ�������Ψһ����,����ÿ��������ֵ,����ֻ��һ����¼ƥ��,����˵,���Ƕ��������ʹ��primary key���� unique key��Ϊ��������
-
const��system:��MySQL�Բ�ѯij���ֽ����Ż�,��ת��Ϊһ������ʱ,ʹ����Щ���ͷ��ʡ��罫��������where�б���,MySQL���ܽ��ò�ѯת��Ϊһ������,system��const���͵�����,����ѯ�ı�ֻ��һ�е������,ʹ��system
-
NULL:MySQL���Ż������зֽ����,ִ��ʱ�������÷��ʱ�������,�����һ����������ѡȡ��Сֵ����ͨ����������������ɡ�
ʵ��
ALL
mysql> explain select * from trace_sp_info;
��������ֻ�ܱ���ȫ��

index
mysql> explain select id from trace_sp_info;
ֻ������Ǿ۴�����idx_update_time,ֱ�ӻ�ȡ��id,���ûر�,ʵ���˸��������Ĺ��ܡ�
������Ҳ���ƶϳ�,���MySQLѡ��ͬ������,�����id˳����ܲ�һ�¡�

range
mysql> explain select * from trace_sp_info where id >1;
�Ż���������������,ʵ��������,�ܹ����ٶ�λ��id>1��λ��,Ȼ��Ӵ���1��λ�ÿ�ʼ����

ref
mysql> explain select * from trace_sp_info where update_time =��2021-08-31 18:03:5��;

eq_ref
mysql> explain select * from trace_sp_info s1,trace_sp_info2 s2 where s1.sp_id=s2.sp_id and s1.sp_id >=1;
һ����primary key���� unique key��Ϊ��������

const
mysql> explain select * from trace_sp_info where id=1;

NULL
mysql> explain select max(id) from trace_sp_info;

possible_keys
����
��ʾ����Ӧ�õ�����,һ��һ�����߶����
SQL����漰�����ֶ�������������,����������г�,���Dz�һ����ʵ��ʹ�á�
���������NULL,��û����ص�������
ʵ��
mysql> explain select id from trace_sp_info where id >1;

key
����
key����ʾMySQLʵ�ʾ���ʹ�õļ�(����),����ʰ�����possible_keys�С�
key��ֵ��һ����possible-keys���Ӽ���SQL����е��ֶ�,��û���漰������,MySQLѡ������,���������������key�б��С�
���û��ѡ������,����NULL��
Ҫ��ǿ��MySQLʹ�û����possible_keys���е�����,�ڲ�ѯ��ʹ��FORCE INDEX��USE INDEX����IGNORE INDEX��
ʵ��
��������
mysql> explain select id from trace_sp_info;

force index
ʹ��force index���Խ��MySQLѡ��������������⡣
mysql> explain select id from trace_sp_info where id >1;
mysql> explain select id from trace_sp_info force index (idx_update_time) where id >1;

key_len
����
��ʾ������ʹ�õ��ֽ���,��ͨ�����м����ѯ��ʹ�õ������ij���,�ڲ���ʧ��ȷ�Ե������,����Խ��Խ�á�
key-len��ʾ��ֵΪ�����ֶε������ܳ���,����ʵ��ʹ�ó���,��key_len�Ǹ��ݱ�����������,����ͨ�����ڼ������ġ�
ʵ��
mysql> explain select * from trace_sp_info force index (id) where update_time>0;

mysql> explain select * from trace_sp_info where id=1;

ref
����
��ʾ��������һ�б�ʹ���ˡ�
��ʱ�����һ������,��ʾ��Щ�л��������ڲ����������ϵ�ֵ��
ʵ��
const
mysql> explain select * from trace_sp_info where update_time =��2021-08-31 18:03:5��;
ָ����
mysql> explain select * from trace_sp_info s1,trace_sp_info2 s2 where s1.sp_id=s2.sp_id and s1.sp_id >=1;
����trace_sp_info��sp_id�е�ֵ�����ڲ���trace_sp_info2��sp_id��Ӧ��ֵ��

rows
����
������������,��ʾMySQL���ݱ�ͳ����Ϣ������ѡ�����,�����ҵ������¼��Ҫ��ȡ��������
��ͳ����Ϣ��,��һ������Ϊ����,��ʾһ�������ϲ�ͬ��ֵ�ĸ���������ͳ�Ƶ�ʱ��,InnoDB Ĭ�ϻ�ѡ�� N ������ҳ,ͳ����Щҳ���ϵIJ�ֵͬ,�õ�һ��ƽ��ֵ,Ȼ��������������ҳ����,�͵õ�����������Ļ�����
ʵ��
mysql> explain select * from trace_sp_info;
filtered
����
filtered��ʾ���ؽ��������ռ���ȡ�����İٷֱ�,filtered�е�ֵԽ��Խ��,Ҳ�ǹ���ֵ
ʵ��
100%
mysql> explain select * from trace_sp_info;

50%
mysql> explain select * from trace_sp_info where status=0;

Extra
����
���а���MySQL�����ѯ����ϸ��Ϣ,���Ƿ�ʹ���ļ���,��Ҫ�����¼������:
-
Using where:ʹ��where��������
-
Using temporary(ʮ����������ʾ,����Ӱ��mysql����,��Ҫ�����Ż�):��ʾMySQL��Ҫʹ����ʱ�����洢�����,����������ͷ����ѯ,���� group by ; order by��group byһ��Ҫ��ѭ����������˳��
-
Using filesort(����һ������ʾ,��Ҫ�����Ż�):��Query�а��� order by ����,�����������������
�����������Ϊ���ļ����������ʱ�������ѭ����������˳�����Ϳ��ܻ����Using filesort��
-
Using Index(Ч�ʲ���):
��ʾ��Ӧ��select������ʹ���˸�������(Covering Index),��������˱���������,Ч�ʲ���
���ͬʱ����Using Where,��������������ִ��������ֵ�IJ���
���û��ͬʱ����Using Where,��������������ȡ���ݶ���ִ�в��ҹ���
-
Using join buffer:��ֵǿ�����ڻ�ȡ��������ʱû��ʹ������,������Ҫ���ӻ��������洢�м�����������������ֵ,��Ӧ��ע��,���ݲ�ѯ�ľ������������Ҫ�����������Ľ��ܡ�
-
Impossible where:���ֵǿ����where���ᵼ��û�з�����������(ͨ���ռ�ͳ����Ϣ�����ܴ��ڽ��)��
-
Select tables optimized away:���ֵ��ζ�Ž�ͨ��ʹ������,�Ż������ܽ��ӾۺϺ�������з���һ��
-
No tables used:Query�����ʹ��from dual ���κ�from�Ӿ�
����Using filesort,Using temporary,Using index��Ϊ����,����ǰ���ֱ�ʾ����Ҫ�Ż��ĵط�,���ֵ����ֱ�ʾ����Ч�ʲ�����
ʵ��
Using where
mysql> explain select * from trace_sp_info where type=0;

Using filesort
mysql> explain select * from trace_sp_info order by type ;

Using temporary
mysql> explain select count(*),type from trace_sp_info group by type;

mysql> explain select count(*) from trace_sp_info group by update_time;

Using index
mysql> explain select id from trace_sp_info where update_time =��2021-08-31 18:03:5��;

Using where+Using index
mysql> explain select id from trace_sp_info where update_time > 0;

�ܽ�
��Ȼexplain�кܶ��ֶ�,����ҿ����ص��עtype��rows��Extra��ͨ���ı��������߸ı�SQL,�����ܸ��á�
���дSQL��ʱ��,��������explain���һ��,���ܲ鿴����,Ҳ�ܼ���Ƿ����Լ��뷨һ�¡�
����
-
MySQL Explain���
-
004�CExplainʵս���:id����
-
explainִ�мƻ����
-
https://blog.csdn.net/weixin_42288943/article/month/2017/08
-
MySQLexplain֮Extra����
���
������ϲ���ҵ�����,���Թ�ע�ҵĹ��ں�(����Ա������)
�ҵĸ��˲���Ϊ:https://shidawuhen.github.io/

�������»ع�: