����Ŀ¼:
һ��Flink���
����Flink ��������
����Flink ���мܹ�
�ġ�Flink ���Ӵ�ȫ
�塢�������е� Time �� Window
����Flink ״̬����
�ߡ�Flink �ݴ�
�ˡ�Flink SQL
�š�Flink CEP
ʮ��Flink CDC
ʮһ������ Flink ����ȫ����ʵʱ����
ʮ����Flink ��������
Flink �漰��֪ʶ������ͼ��ʾ,���Ľ���һ����:
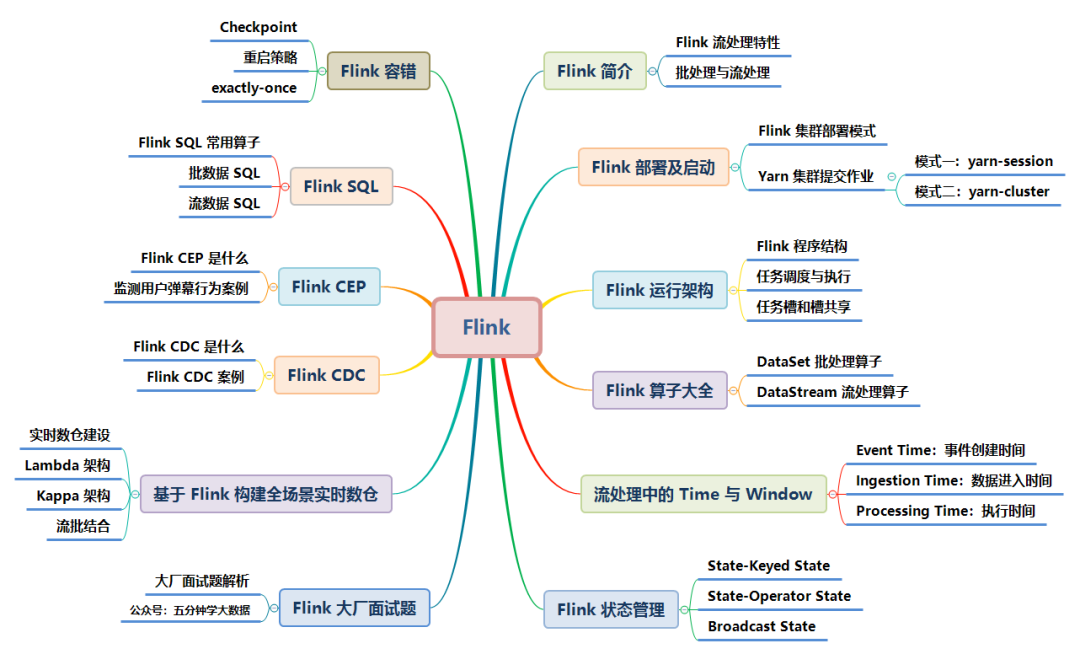
���ĵ��ο���?Flink �Ĺ����������ڶ�������������,Ϊ��������Ű漰���ʵ��Ķ�,����ģ����������ͼƬ���ڰ�ͼƬ�������»��Ƴ��˸����ͼ��
���ij���,��ȡ��������PDF�ĵ�,��Ŀ¼��ȫ�ܽ�,��ɨ���ע���ںš������ѧ��������,��̨����:flink pdf,�������ش�Ŀ¼��������flink�ĵ�:

���Ŀ�ʼ:
һ��Flink ���
1. Flink ��չ
�⼸������ݵķ��ٷ�չ,�����˺ܶ����ŵĿ�Դ����,������������ Hadoop��Storm,�Լ������� Spark,���Ƕ����Ÿ���רע��Ӧ�ó�����Spark �ƿ����ڴ������Ⱥ�,Ҳ���ڴ�Ϊ��ע,Ӯ�����ڴ����ķ��ٷ�չ��Spark �Ļ��Ȼ����ٵ��ڸ��������ֲ�ʽ�����ϵͳ��Ӱ������ Flink,Ҳ�������ʱ��ĬĬ�ķ�չ�š�
�ڹ���һЩ����,�кܶ��˽������ݵļ�������ֳ��� 4 ��,��Ȼ,Ҳ�кܶ��˲�����ͬ�������ȹ�����ô��Ϊ�����ۡ�
���ȵ�һ���ļ�������,���ɾ��� Hadoop ���ص� MapReduce��������Ӧ�ö������ MapReduce İ��,���������Ϊ������,�ֱ�Ϊ Map �� Reduce�������ϲ�Ӧ����˵,�Ͳ��ò��뷽�跨ȥ����㷨,�����ڲ��ò����ϲ�Ӧ��ʵ�ֶ�� Job �Ĵ���,�����һ���������㷨,����������㡣
���������ı�,������֧�� DAG ��ܵIJ��������,֧�� DAG �Ŀ�ܱ�����Ϊ�ڶ����������档�� Tez �Լ����ϲ�� Oozie���������Dz�ȥϸ������ DAG ʵ��֮�������,�������ڵ�ʱ�� Tez �� Oozie ��˵,����������������
������������ Spark Ϊ�����ĵ������ļ������档����������������ص���Ҫ�� Job �ڲ��� DAG ֧��(����Խ Job),�Լ�ǿ����ʵʱ���㡣������,�ܶ���Ҳ����Ϊ��������������Ҳ�ܹ��ܺõ������������� Job��
���ŵ�������������ij���,�ٽ����ϲ�Ӧ�ÿ��ٷ�չ,������ֵ�������������Լ���������� SQL �ȵ�֧�֡�Flink �ĵ����ͱ������˵��Ĵ�����Ӧ����Ҫ������ Flink ���������֧��,�Լ���һ����ʵʱ�����档��Ȼ Flink Ҳ����֧�� Batch ������,�Լ� DAG �����㡣
�ܽ�:
�� 1 ��:Hadoop MapReduc ������ Mapper��Reducer 2;
�� 2 ��:DAG ���(Oozie ��Tez),Tez + MapReduce ������ 1 �� Tez = MR(1) + MR(2) + ... + MR(n) ��� MR ����������;
�� 3 ��:Spark ����������������SQL �߲� API ֧�� �Դ� DAG �ڴ�������㡢���ܽ�֮ǰ�����;
�� 4 ��:Flink ����������������SQL �߲� API ֧�� �Դ� DAG ��ʽ�������ܸ��ߡ��ɿ��Ը��ߡ�
2. ʲô�� Flink
Flink ��Դ�� Stratosphere ��Ŀ,Stratosphere ���� 2010~2014 ���� 3 ���ش����ֵĴ�ѧ��ŷ��һЩ�����Ĵ�ѧ��ͬ���е��о���Ŀ,2014 �� 4 �� Stratosphere �Ĵ��뱻���Ʋ��������� Apache ���������,�μ����������Ŀ�ij�ʼ��Ա�� Stratosphere ϵͳ�ĺ��Ŀ�����Ա,2014 �� 12 ��,Flink һԾ��Ϊ Apache ���������Ķ�����Ŀ��
�ڵ�����,Flink һ�ʱ�ʾ���ٺ�����,��Ŀ����һֻ����IJ�ɫͼ����Ϊ logo,�ⲻ������Ϊ������п��ٺ����ɵ��ص�,����Ϊ���ֵ�������һ�����˵ĺ���ɫ,�� Flink ������ logo ӵ�пɰ���β��,β�͵���ɫ�� Apache ���������� logo ��ɫ���Ӧ,Ҳ����˵,����һֻ Apache ��������

Flink ��ҳ���䶥��չʾ�˸���Ŀ������:��Apache Flink ��Ϊ�ֲ�ʽ�������ܡ���ʱ�����Լ�ȷ��������Ӧ�ó������Ŀ�Դ�������������
Apache Flink ��һ����ܺͷֲ�ʽ��������,���ڶ�����н�������������״̬���㡣Flink ����������г����ļ�Ⱥ����������,���ڴ�ִ���ٶȺ������ģ��ִ�м��㡣
3. Flink ����������
-
֧�ָ����¡����ӳ١������ܵ�������
-
֧�ִ����¼�ʱ��Ĵ���(Window)����
-
֧����״̬����� Exactly-once ����
-
֧�ָ߶����Ĵ���(Window)����,֧�ֻ��� time��count��session,�Լ� data-driven �Ĵ��ڲ���
-
֧�־��� Backpressure ���ܵij�����ģ��
-
֧�ֻ����������ֲ�ʽ����(Snapshot)ʵ�ֵ��ݴ�
-
һ������ʱͬʱ֧�� Batch on Streaming ������ Streaming ����
-
Flink �� JVM �ڲ�ʵ�����Լ����ڴ����
-
֧�ֵ�������
-
֧�ֳ����Զ��Ż�:�����ض������ Shuffle������Ȱ������,�м����б�Ҫ���л���
4. Flink ��ʯ
Flink ֮��������ô����,�벻��������Ҫ���ĸ���ʯ:Checkpoint��State��Time��Window��
������ Checkpoint ����,���� Flink ����Ҫ��һ��������Flink ����Chandy-Lamport�㷨ʵ����һ���ֲ�ʽ��һ���ԵĿ���,�Ӷ��ṩ��һ���Ե����塣Chandy-Lamport �㷨ʵ������ 1985 ���ʱ���Ѿ��������,����û�б��ܹ㷺��Ӧ��,�� Flink �������㷨�������ˡ�
Spark �����ʵ�� Continue streaming,Continue streaming ��Ŀ����Ϊ�˽�������������ʱ,��Ҳ��Ҫ�ṩ����һ���Ե�����,���ղ��� Chandy-Lamport ����㷨,˵�� Chandy-Lamport �㷨��ҵ��õ���һ���Ŀ϶���
�ṩ��һ���Ե�����֮��,Flink Ϊ�����û��ڱ��ʱ�ܹ������ɡ�������ȥ����״̬,���ṩ��һ�dz������˵� State API,����������� ValueState��ListState��MapState,���������� BroadcastState,ʹ�� State API �ܹ��Զ����ܵ�����һ���Ե����塣
����֮��,Flink ��ʵ���� Watermark �Ļ���,�ܹ�֧�ֻ����¼���ʱ��Ĵ���,����˵����ϵͳʱ��Ĵ���,�ܹ��������ݵ���ʱ���������ݵijٵ���������������ݡ�
������������һ���ڶ������ݽ��в���֮ǰ�����Ƚ��п���,������һ��ʲô���Ĵ�������������㡣Flink �ṩ�˿��伴�õĸ��ִ���,���绬�����ڡ��������ڡ��Ự�����Լ��dz������Զ���Ĵ��ڡ�
5. ��������������
���������ص����н硢�־á�����,�������dz��ʺ���Ҫ����ȫ��¼������ɵļ��㹤��,һ����������ͳ�ơ����������ص����硢ʵʱ,��������ʽ��������������ݼ�ִ�в���,���Ƕ�ͨ��ϵͳ�����ÿ��������ִ�в���,һ������ʵʱͳ�ơ�
�� Spark ��̬��ϵ��,�����������������������˲�ͬ�ļ������,�������� SparkSQL ʵ��,�������� Spark Streaming ʵ��,��Ҳ�Ǵֿ�ܲ��õIJ���,ʹ�ö����Ĵ�����ʵ����������������,�� Flink ����ͬʱʵ������������������
Flink �����ͬʱʵ��������������������?����,Flink ��������(���������ľ�̬����)����һ���������������
Flink �ĺ��ļ���ܹ�����ͼ�е� Flink Runtime ִ������,����һ���ֲ�ʽϵͳ,�ܹ�����������������һ̨���̨���������ݴ���ʽִ�С�
Flink Runtime ִ�����������Ϊ YARN(Yet Another Resource Negotiator)��Ӧ�ó����ڼ�Ⱥ������,Ҳ������ Mesos ��Ⱥ������,�������ڵ���������(����ڵ��� Flink Ӧ�ó�����˵�dz�����)��
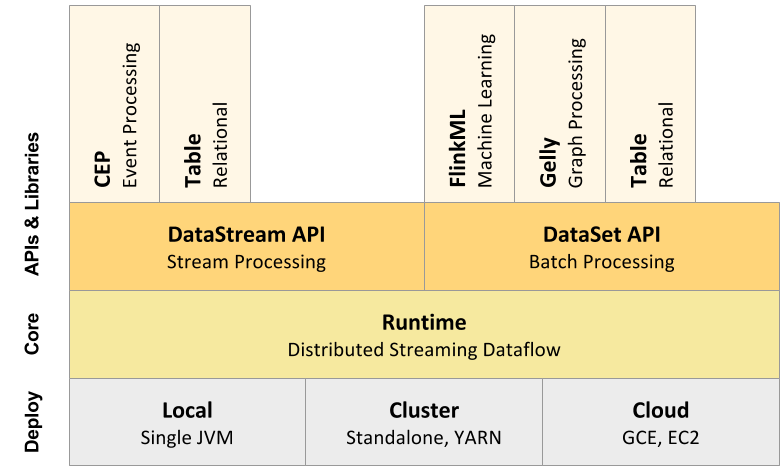
��ͼΪ Flink ����ջ�ĺ�����ɲ���,ֵ��һ�����,Flink �ֱ��ṩ��������ʽ�����Ľӿ�(DataStream API)�������������Ľӿ�(DataSet API)�����,Flink �ȿ������������,Ҳ���������������Flink ֧�ֵ���չ���漰����ѧϰ(FlinkML)�������¼�����(CEP)���Լ�ͼ����(Gelly),���зֱ�������������������� Table API��
�ܱ� Flink Runtime ִ��������ܵij����ǿ��,���������ij��������߳��Ĵ���,��д����Ҳ�ܷ���,�������ԭ��,Flink �ṩ�˷�װ�� Runtime ִ������֮�ϵ� API,�����û������������ʽ�������Flink �ṩ�������������� DataStream API �������������� DataSet API��ֵ��ע�����,���� Flink Runtime ִ�������ǻ�����������,���� DataSet API ���� DataStream API ����������,������Ϊ��ҵ��������������������� Flink ����֮��������
DataStream API ���������ط�������������,���ҿ����� Java ���� Scala ����ʵ����������Ա��Ҫ����һ���� DataStream �����ݽṹ������,������ݽṹ���ڱ�ʾ����ֹͣ�ķֲ�ʽ��������
Flink �ķֲ�ʽ�ص����������ܹ��ڳɰ���ǧ̨����������,�������͵ļ�������ֳ�����С�IJ���,ÿ������ִ��һ���֡�Flink �ܹ��Զ���ȷ�������������ϻ�����������ʱ�����ܹ���������,�������� bug ����а汾�������мƻ�����ִ��һ�Ρ���������ʹ�ÿ�����Ա����Ҫ��������ʧ�ܡ�Flink ������ʹ���ݴ���������,��ʹ�ÿ�����Ա���Է���������������Զ������������(��������)��
����Flink ��������
Flink ֧�ֶ��ְ�װģʽ:
-
local(����)��������ģʽ,һ�㲻ʹ��;
-
standalone��������ģʽ,Flink �Դ���Ⱥ,�������Ի���ʹ��;
-
yarn����������Դͳһ�� Hadoop YARN ����,��������ʹ�á�
Flink ��Ⱥ�İ�װ�����ڱ��ĵ��ķ���,�簲װ Flink,�������������Ͻ��а�װ��
�����ص��� Flink �� Yarn ����ģʽ��
��һ����ҵ��,Ϊ��������ü�Ⱥ��Դ,һ�㶼����һ����Ⱥ��ͬʱ���ж������͵� Workload,����ʹ�� YARN ���������м�����Դ��
1. Flink �� Yarn �ϵIJ���ܹ�
![]()
��ͼ�п��Կ���,Yarn �Ŀͻ�����Ҫ��ȡ hadoop ��������Ϣ,���� Yarn �� ResourceManager������Ҫ���� YARN_CONF_DIR ���� HADOOP_CONF_DIR ���� HADOOP_CONF_PATH,ֻҪ����������һ����������,�ͻᱻ��ȡ�������ȡ�����ı���ʧ����,��ô����ѡ�� hadoop_home �Ļ�������,�᳢�Լ���$HADOOP_HOME/etc/hadoop �������ļ���
-
������һ�� Flink Yarn �Ựʱ,�ͻ������Ȼ��鱾���������Դ(�洢������)�Ƿ��㹻����Դ�㹻�����ϴ����� HDFS �� Flink ��������Ϣ�� Flink �� jar ���� HDFS;
-
�ͻ����� RM ��������;
-
RM �� NM ������ָ��,���� container,���� HDFS ������ jar �Լ������ļ�;
-
���� ApplicationMaster �� jobmanager,�� jobmanager �ĵ�ַ��Ϣд�������ļ���,�ٷ��� hdfs ��;
-
ͬʱ,AM �� RM ��������ע���Լ�,������Դ(cpu���ڴ�);
-
���� TaskManager ����,�� HDFS ������ jar ���������ļ�������;
-
�� task ����ͨ�� jobmanager �㱨�Լ���״̬�ͽ���,AM �� jobmanager ��һ��������,AM �������ո����������״̬,�Ӷ�����������ʧ��ʱ,������������;
-
������ɺ�,AM �� RM ע�����ر��Լ�;
2. ������Ⱥ
-
�� hadoop ������:
vim etc/hadoop/yarn-site.xml
����:
<property>
?????????<name>yarn.nodemanager.vmem-check-enabled</name>
?????????<value>false</value>
</property>
�� Hadoop �� yarn-site.xml,���Ӹ����ñ�ʾ�ڴ泬������ֵ,�Ƿ�����ɱ����
Ĭ��Ϊ true������ Flink ����,�������ڴ泬��,���ʱ�� yarn ���Զ�ɱ�� job��
-
��ȫ�ֱ���?
/etc/profile:
����:export HADOOP_CONF_DIR=/export/servers/hadoop/etc/Hadoop
YARN_CONF_DIR ���� HADOOP_CONF_DIR ���뽫������������Ϊ��ȡ YARN �� HDFS ����
-
���� HDFS��zookeeper(��������� zookeeper)��YARN ��Ⱥ;
-
ʹ�� yarn-session ��ģʽ�ύ��ҵ��
Yarn Session ģʽ�ύ��ҵ�����ַ�ʽ:yarn-session �� yarn-cluster
3. ģʽһ: yarn-session
�ص�:
-
ʹ�� Flink �е� yarn-session(yarn �ͻ���),������������Ҫ���� JobManager �� TaskManagers;
-
�ͻ���ͨ�� yarn-session �ύ��ҵ;
-
yarn-session ��һֱ����,��ͣ�ؽ��տͻ����ύ������;
-
���ӵ���д�����С��ҵ,�ʺ�ʹ�����ַ�ʽ��
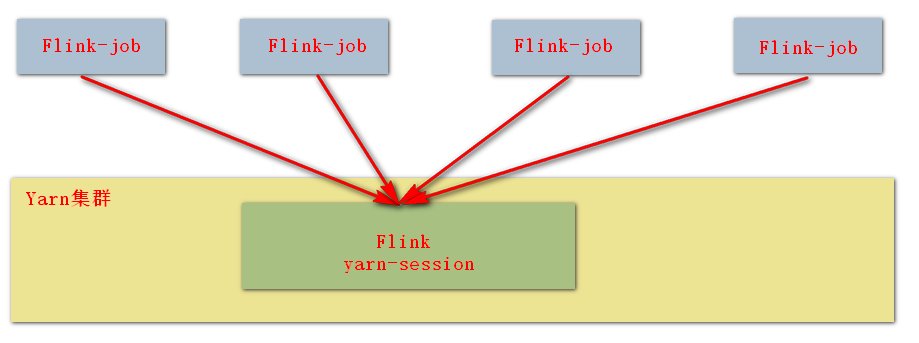
�� flink Ŀ¼���� yarn-session:
bin/yarn-session.sh -n 2 -tm 800 -jm 800 -s 1 -d
-n ��ʾ���� 2 ������
-s ��ʾÿ�������������ٸ� slot ��ģʽ,��ʾ�Ժ�̨��
-tm ��ʾÿ�� TaskManager ���� 800M �ڴ�
-d ����ʽ����
ʹ�� flink �ύ����:
bin/flink run examples/batch/WordCount.jar
���������������,����ʹ�� yarn application -kill application_id ɱ������:
yarn application -kill application_1554377097889_0002
bin/yarn-session.sh -n 2 -tm 800 -s 1 -d ��˼��:
ͬʱ�� Yarn ���� 3 �� container(����ֻ����������,��Ϊ ApplicationMaster �� Job Manager ��һ�������������һ���� Flink ���� YARN Ⱥ����,���ͻ���ʾ Job Manager ��������ϸ��Ϣ),���� 2 �� Container ���� TaskManager(-n 2),ÿ�� TaskManager ӵ������ Task Slot(-s 1),������ÿ�� TaskManager �� Container ���� 800M ���ڴ�,�Լ�һ�� ApplicationMaster(Job Manager)��
4. ģʽ��: yarn-cluster
�ص�:
-
ֱ���ύ����� YARN;
-
����ҵ,�ʺ�ʹ�����ַ�ʽ;
-
���Զ��ر� session��
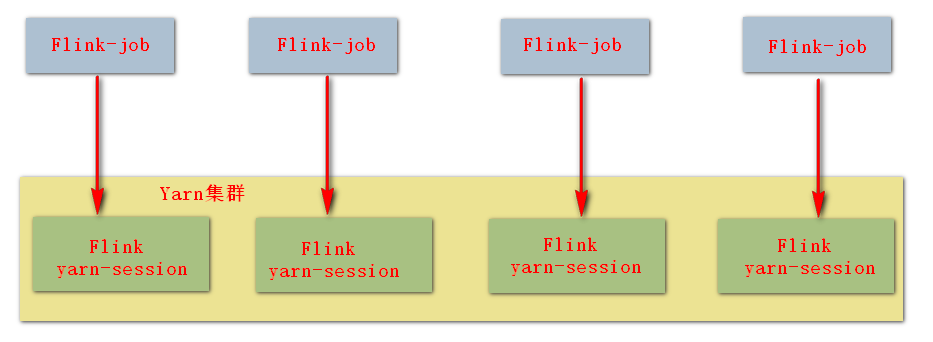
ʹ�� flink ֱ���ύ����:
bin/flink run -m yarn-cluster -yn 2 -yjm 800 -ytm 800 /export/servers/flink-1.6.0/examples/batch/WordCount.jar
-yn ��ʾ TaskManager �ĸ���
ע��:
-
�ڴ�����Ⱥ��ʱ��,��Ⱥ�����ò�����д����,����������Ϊҵ����Ҫ,Ҫ����һЩ���ò���,���ʱ����Բ�����Ϊһ��ʵ�����ύ���� conf/flink-conf.yaml;
����ͨ��:-D <arg> Dynamic properties������ԭ�е�������Ϣ:����:
-Dfs.overwrite-files=true -Dtaskmanager.network.numberOfBuffers=16368
-
���ʹ�õ��� flink on yarn ��ʽ,���л��� standalone ģʽ�Ļ�,��Ҫɾ��:
/tmp/.yarn-properties-root,��ΪĬ�ϲ��ҵ�ǰ yarn ��Ⱥ�����е� yarn-session ��Ϣ�е� jobmanager��
����Flink ���мܹ�
1. Flink ����ṹ
Flink ����Ļ���������������ת��(��ע��,Flink �� DataSet API ��ʹ�õ� DataSet Ҳ���ڲ��� )���Ӹ����Ͻ�,����(��������ֹ����)���ݼ�¼��,��ת���ǽ�һ����������Ϊһ���������IJ���������,������һ�������������
![]()
Flink Ӧ�ó���ṹ��������ͼ��ʾ:
Source: ����Դ,Flink �����������������ϵ� source ����� 4 ��:���ڱ��ؼ��ϵ� source�������ļ��� source�������������ֵ� source���Զ���� source���Զ���� source �������� Apache kafka��RabbitMQ ��,��Ȼ��Ҳ���Զ����Լ��� source��
Transformation:����ת���ĸ��ֲ���,��?Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select��,�����ܶ�,���Խ�����ת�����������Ҫ�����ݡ�
Sink:������,Flink ��ת�����������ݷ��͵ĵص� ,�������Ҫ�洢����,Flink ������ Sink ��������¼���:д���ļ�����ӡ������д�� socket ���Զ���� sink ���Զ���� sink �������� Apache kafka��RabbitMQ��MySQL��ElasticSearch��Apache Cassandra��Hadoop FileSystem ��,ͬ����Ҳ���Զ����Լ��� sink��
2. Flink ����������
Flink ������ִ�е�ʱ��,�ᱻӳ���һ�� Streaming Dataflow,һ�� Streaming Dataflow ����һ�� Stream �� Transformation Operator ��ɵġ�������ʱ��һ������ Source Operator ��ʼ,������һ������ Sink Operator��
Flink ���������Dz��еĺͷֲ�ʽ��,��ִ�й�����,һ����(stream)����һ������������,��ÿһ�� operator ����һ������ operator ���������������˴˶���,�ڲ�ͬ���߳���ִ��,�������ڲ�ͬ�Ļ�����ͬ�������ϡ�operator ���������������һ�ض� operator �IJ��жȡ���ͬ�����еIJ�ͬ operator �в�ͬ����IJ��жȡ�
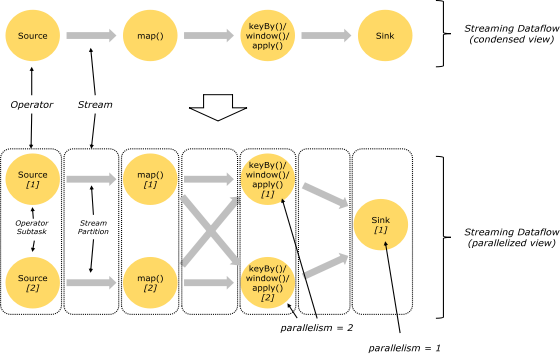
һ�� Stream ���Ա��ֳɶ�� Stream �ķ���,Ҳ���� Stream Partition��һ�� Operator Ҳ���Ա���Ϊ��� Operator Subtask������ͼ��,Source ���ֳ� Source1 �� Source2,���Ƿֱ�Ϊ Source �� Operator Subtask��ÿһ�� Operator Subtask �����ڲ�ͬ���̵߳��ж���ִ�еġ�һ�� Operator �IJ��ж�,�͵��� Operator Subtask �ĸ�������ͼ Source �IJ��ж�Ϊ 2����һ�� Stream �IJ��жȾ͵��������ɵ� Operator �IJ��жȡ�
���������� operator ֮�䴫�ݵ�ʱ��������ģʽ:
One to One ģʽ:���� operator �ô�ģʽ���ݵ�ʱ��,�ᱣ�����ݵķ����������ݵ�����;����ͼ�е� Source1 �� Map1,���ͱ����� Source �ķ�������,�Լ�����Ԫ�ش����������ԡ�
Redistributing (���·���)ģʽ:����ģʽ��ı����ݵķ�����;ÿ��һ�� operator subtask �����ѡ�� transformation �����ݷ��͵���ͬ��Ŀ�� subtasks,���� keyBy()��ͨ�� hashcode ���·���,broadcast()�� rebalance()������������·���;
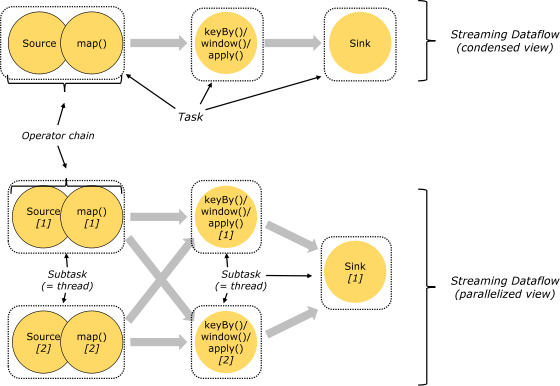
3. Task �� Operator chain
Flink�����в�������֮ΪOperator,�ͻ������ύ�����ʱ����Operator�����Ż�����,�ܽ��кϲ���Operator�ᱻ�ϲ�Ϊһ��Operator,�ϲ����Operator��ΪOperator chain,ʵ���Ͼ���һ��ִ����,ÿ��ִ��������TaskManager��һ���������߳���ִ�С�
4. ���������ִ��
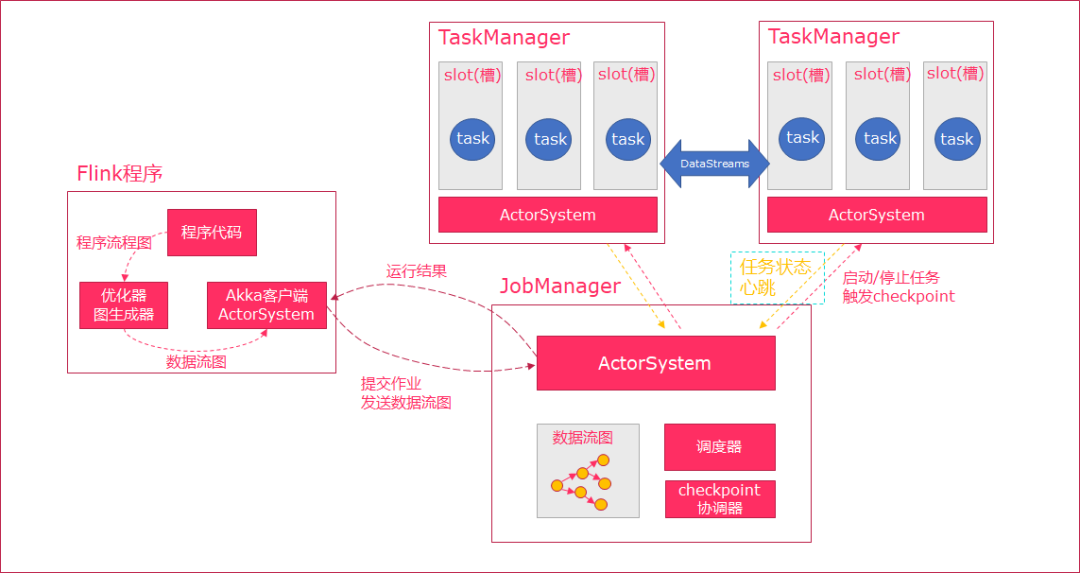
-
��Flinkִ��executor���Զ����ݳ����������DAG������ͼ;
-
ActorSystem����Actor��������ͼ����JobManager�е�Actor;
-
JobManager��Ͻ���TaskManager��������Ϣ,�Ӷ����Ի�ȡ����Ч��TaskManager;
-
JobManagerͨ����������TaskManager�е���ִ��Task(��Flink��,��С�ĵ��ȵ�Ԫ����task,��Ӧ����һ���߳�);
-
�ڳ������й�����,task��task֮���ǿ��Խ������ݴ���ġ�
Job Client:
-
��Ҫְ�����ύ����, �ύ����Խ�������, Ҳ���Եȴ��������;
-
Job Client ���� Flink ����ִ�е��ڲ�����,����������ִ�е����;
-
Job Client ��������û��ij������,Ȼ��������,���������ύ�� Job Manager �Ա��һ��ִ�С�ִ����ɺ�,Job Client ��������ظ��û���
JobManager:
-
��Ҫְ���ǵ��ȹ�����Э������������;
-
��Ⱥ������Ҫ��һ�� master,master ������� task,Э��checkpoints ���ݴ�;
-
�߿������õĻ������ж�� master,��Ҫ��֤һ���� leader, ������standby;
-
Job Manager ���� Actor System��Scheduler��CheckPoint������Ҫ�����;
-
JobManager�ӿͻ��˽��յ������Ժ�, ���������Ż�����ִ�мƻ�, �ٵ��ȵ�TaskManager��ִ�С�
TaskManager:
-
��Ҫְ���Ǵ�JobManager����������, ���������������, �������ε����ݲ�����;
-
Task Manager ���� JVM �е�һ�������߳���ִ������Ĺ����ڵ�;
-
TaskManager�ڴ���֮�������ú���Slot, ÿ��Slot����ִ��һ������
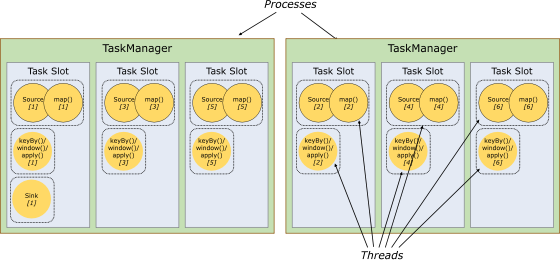
5. ����ۺͲ۹���
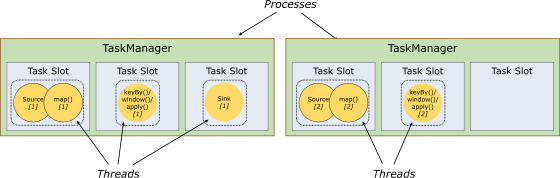
ÿ��TaskManager��һ��JVM�Ľ���, �����ڲ�ͬ���߳���ִ��һ������������Ϊ�˿���һ��worker�ܽ��ն��ٸ�task��workerͨ��task slot�����п���(һ��worker������һ��task slot)��
1) �����
ÿ��task slot��ʾTaskManagerӵ����Դ��һ���̶���С���Ӽ���
flink�����̵��ڴ�����˻��ֵ����slot�С�
ͼ����2��TaskManager,ÿ��TaskManager��3��slot��,ÿ��slotռ��1/3���ڴ档
�ڴ汻���ֵ���ͬ��slot֮����Ի�����ºô�:
-
TaskManager�����ͬʱ����ִ�е������ǿ��Կ��Ƶ�,�Ǿ���3��,��Ϊ���ܳ���slot��������
-
slot�ж�ռ���ڴ�ռ�,������һ��TaskManager�п������ж����ͬ����ҵ,��ҵ֮�䲻��Ӱ�졣
2) �۹���
Ĭ�������,Flink���������������,��ʹ�����Dz�ͬ�����������,ֻҪ��������ͬһ����ҵ�������һ���ۿ��Ա�����ҵ�������ܵ���������۹�����������Ҫ�ô�:
-
ֻ�����Job����߲��ж�(parallelism)��task slot,ֻҪ�������,������jobҲ�������㡣
-
��Դ������ӹ�ƽ,����бȽϿ��е�slot���Խ������������������ͼ����û������۹���,���ز��ߵ�Source/Map��subtask����ռ��������Դ,�����ؽϸߵĴ���subtask���ȱ����Դ��
-
��������۹���,���Խ��������ж�(base parallelism)��2������6.����˷ֲ���Դ�������ʡ�ͬʱ�������Ա���TaskManager��subtask�ķ����slot�������ӹ�ƽ��
�ġ�Flink ���Ӵ�ȫ
Flink��Spark����,Ҳ��һ��һվʽ�����Ŀ��;�ȿ��Խ���������(DataSet),Ҳ���Խ���ʵʱ����(DataStream)��
�������潫Flink�����ӷ�Ϊ������:һ����DataSet,һ����DataStream��
DataSet ����������
һ��Source����
1. fromCollection
fromCollection:�ӱ��ؼ��϶�ȡ����
��:
val?env?=?ExecutionEnvironment.getExecutionEnvironment
val?textDataSet:?DataSet[String]?=?env.fromCollection(
??List("1,����",?"2,����",?"3,����",?"4,����")
)
2. readTextFile
readTextFile:���ļ��ж�ȡ
val?textDataSet:?DataSet[String]??=?env.readTextFile("/data/a.txt")
3. readTextFile:����Ŀ¼
readTextFile���Զ�һ���ļ�Ŀ¼�ڵ������ļ�,����������Ŀ¼�е������ļ��ı������ʷ�ʽ
val?parameters?=?new?Configuration
//?recursive.file.enumeration?�����ݹ�
parameters.setBoolean("recursive.file.enumeration",?true)
val?file?=?env.readTextFile("/data").withParameters(parameters)
4. readTextFile:��ȡѹ���ļ�
��������ѹ������,����Ҫָ���κζ����inputformat����,flink�����Զ�ʶ���ҽ�ѹ������,ѹ���ļ����ܲ��Ტ�ж�ȡ,������˳���ȡ��,�������ܻ�Ӱ����ҵ�Ŀ������ԡ�
| ѹ������ | �ļ���չ�� | �Ƿ�ɲ��ж�ȡ |
|---|---|---|
| DEFLATE | .deflate | no |
| GZip | .gz .gzip | no |
| Bzip2 | .bz2 | no |
| XZ | .xz | no |
val?file?=?env.readTextFile("/data/file.gz")
����Transformת������
��ΪTransform���ӻ���Source���Ӳ���,�������ȹ���Flinkִ�л�����Source����,����Transform���Ӳ������ڴ�:
val?env?=?ExecutionEnvironment.getExecutionEnvironment
val?textDataSet:?DataSet[String]?=?env.fromCollection(
??List("����,1",?"����,2",?"����,3",?"����,4")
)
1. map
��DataSet�е�ÿһ��Ԫ��ת��Ϊ����һ��Ԫ��
//?ʹ��map��Listת��Ϊһ��Scala��������
case?class?User(name:?String,?id:?String)
val?userDataSet:?DataSet[User]?=?textDataSet.map?{
??text?=>
????val?fieldArr?=?text.split(",")
????User(fieldArr(0),?fieldArr(1))
}
userDataSet.print()
2. flatMap
��DataSet�е�ÿһ��Ԫ��ת��Ϊ0...n��Ԫ�ء�
//?ʹ��flatMap����,�������е�����:
//?���ݵ�һ��Ԫ��,���з���
//?���ݵڶ���Ԫ��,���оۺ���ֵ?
val?result?=?textDataSet.flatMap(line?=>?line)
??????.groupBy(0)?//?���ݵ�һ��Ԫ��,���з���
??????.sum(1)?//?���ݵڶ���Ԫ��,���оۺ���ֵ
??????
result.print()
3. mapPartition
��һ�������е�Ԫ��ת��Ϊ��һ��Ԫ��
//?ʹ��mapPartition����,��Listת��Ϊһ��scala��������
case?class?User(name:?String,?id:?String)
val?result:?DataSet[User]?=?textDataSet.mapPartition(line?=>?{
??????line.map(index?=>?User(index._1,?index._2))
????})
????
result.print()
4. filter
���˳���һЩ����������Ԫ��,����booleanֵΪtrue��Ԫ��
val?source:?DataSet[String]?=?env.fromElements("java",?"scala",?"java")
val?filter:DataSet[String]?=?source.filter(line?=>?line.contains("java"))//���˳���java������
filter.print()
5. reduce
���Զ�һ��dataset����һ��group�����оۺϼ���,�����ۺϳ�һ��Ԫ��
//?ʹ��?fromElements?��������Դ
val?source?=?env.fromElements(("java",?1),?("scala",?1),?("java",?1))
//?ʹ��mapת����DataSetԪ��
val?mapData:?DataSet[(String,?Int)]?=?source.map(line?=>?line)
//?������Ԫ�ط���
val?groupData?=?mapData.groupBy(_._1)
//?ʹ��reduce�ۺ�
val?reduceData?=?groupData.reduce((x,?y)?=>?(x._1,?x._2?+?y._2))
//?��ӡ����
reduceData.print()
6. reduceGroup
��һ��dataset����һ��group�ۺϳ�һ������Ԫ����
reduceGroup��reduce��һ���Ż�����;
�����ȷ���reduce,Ȼ�����������reduce;�������ĺô����ǿ��Լ�������IO
//?ʹ��?fromElements?��������Դ
val?source:?DataSet[(String,?Int)]?=?env.fromElements(("java",?1),?("scala",?1),?("java",?1))
//?������Ԫ�ط���
val?groupData?=?source.groupBy(_._1)
//?ʹ��reduceGroup�ۺ�
val?result:?DataSet[(String,?Int)]?=?groupData.reduceGroup?{
??????(in:?Iterator[(String,?Int)],?out:?Collector[(String,?Int)])?=>
????????val?tuple?=?in.reduce((x,?y)?=>?(x._1,?x._2?+?y._2))
????????out.collect(tuple)
????}
//?��ӡ����
result.print()
7. minBy��maxBy
ѡ�������Сֵ�����ֵ��Ԫ��
//?ʹ��minBy����,��List��ÿ���˵���Сֵ
//?List("����,1",?"����,2",?"����,3",?"����,4")
case?class?User(name:?String,?id:?String)
//?��Listת��Ϊһ��scala��������
val?text:?DataSet[User]?=?textDataSet.mapPartition(line?=>?{
??????line.map(index?=>?User(index._1,?index._2))
????})
????
val?result?=?text
??????????.groupBy(0)?//?������������
??????????.minBy(1)???//?ÿ���˵���Сֵ
8. Aggregate
�����ݼ��Ͻ��оۺ�����ֵ(���ֵ����Сֵ)
val?data?=?new?mutable.MutableList[(Int,?String,?Double)]
????data.+=((1,?"yuwen",?89.0))
????data.+=((2,?"shuxue",?92.2))
????data.+=((3,?"yuwen",?89.99))
//?ʹ��?fromElements?��������Դ
val?input:?DataSet[(Int,?String,?Double)]?=?env.fromCollection(data)
//?ʹ��groupִ�з������
val?value?=?input.groupBy(1)
????????????//?ʹ��aggregate�����ֵԪ��
????????????.aggregate(Aggregations.MAX,?2)?
//?��ӡ����
value.print()???????
Aggregateֻ��������Ԫ����
ע��:
Ҫʹ��aggregate,ֻ��ʹ���ֶ����������������������з���?groupBy(0)?,����ᱨһ�´���:
Exception in thread "main" java.lang.UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet.
9. distinct
ȥ���ظ�������
//?����Դʹ����һ���
//?ʹ��distinct����,���ݿ�Ŀȥ���������ظ���Ԫ������
val?value:?DataSet[(Int,?String,?Double)]?=?input.distinct(1)
value.print()
10. first
ȡǰN����
input.first(2)?//?ȡǰ������
11. join
������DataSet����һ���������ӵ�һ��,�γ��µ�DataSet
// s1 �� s2 ���ݼ���ʽ����:
//?DataSet[(Int,?String,String,?Double)]
?val?joinData?=?s1.join(s2)??//?s1���ݼ�?join?s2���ݼ�
?????????????.where(0).equalTo(0)?{?????//?join������
??????(s1,?s2)?=>?(s1._1,?s1._2,?s2._2,?s1._3)
????}
12. leftOuterJoin
��������,��ߵ�Dataset�е�ÿһ��Ԫ��,ȥ�����ұߵ�Ԫ��
�����:
rightOuterJoin:��������,��ߵ�Dataset�е�ÿһ��Ԫ��,ȥ������ߵ�Ԫ��
fullOuterJoin:ȫ������,�������ߵ�Ԫ��,ȫ������
������ leftOuterJoin ����ʾ��:
?val?data1?=?ListBuffer[Tuple2[Int,String]]()
????data1.append((1,"zhangsan"))
????data1.append((2,"lisi"))
????data1.append((3,"wangwu"))
????data1.append((4,"zhaoliu"))
val?data2?=?ListBuffer[Tuple2[Int,String]]()
????data2.append((1,"beijing"))
????data2.append((2,"shanghai"))
????data2.append((4,"guangzhou"))
val?text1?=?env.fromCollection(data1)
val?text2?=?env.fromCollection(data2)
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
??????if(second==null){
????????(first._1,first._2,"null")
??????}else{
????????(first._1,first._2,second._2)
??????}
????}).print()
13. cross
�������,ͨ���γ�������ݼ����������ݼ��ĵѿ�����,����һ���µ����ݼ�
��join����,�������ֽ������������ѿ�����,�����ݱȽϴ��ʱ��,�Ƿdz������ڴ�IJ���
val?cross?=?input1.cross(input2){
??????(input1?,?input2)?=>?(input1._1,input1._2,input1._3,input2._2)
????}
cross.print()
14. union
���ϲ���,�����������Ը����ݼ����������ݼ���Ԫ�ص������ݼ�,����ȥ��
val?unionData:?DataSet[String]?=?elements1.union(elements2).union(elements3)
//?ȥ���ظ�����
val?value?=?unionData.distinct(line?=>?line)
15. rebalance
FlinkҲ��������б��ʱ��,���統ǰ�����������10����������Ҫ����,�ڴ��������п��ܻᷢ����ͼ��ʾ��״��:
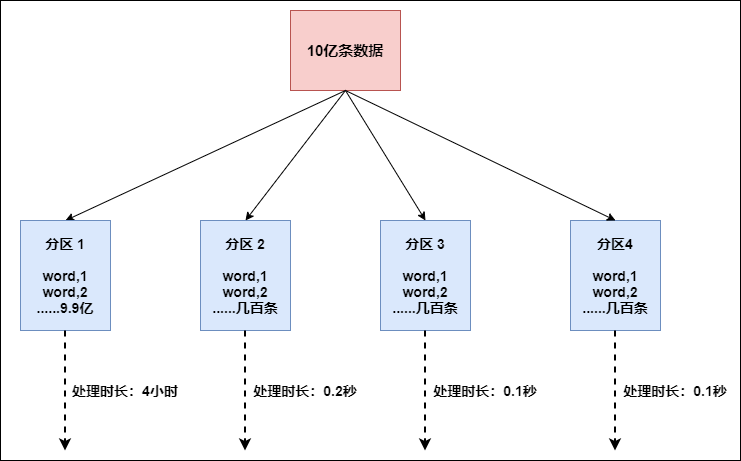
���ʱ��������������ֻ��Ҫ10���ӽ��������,������������б,����1�ϵ�������Ҫ4��Сʱ�������,��ô����3̨����ִ�����ҲҪ�ȴ�����1ִ����Ϻ�������彫�������;������ʵ�ʵĹ�����,������������ȽϺõĽ���������ǽ�����Ҫ���ܵġ�rebalance(�ڲ�ʹ��round robin���������ݾ��ȴ�ɢ�������������бʱ�Ǻܺõ�ѡ��)
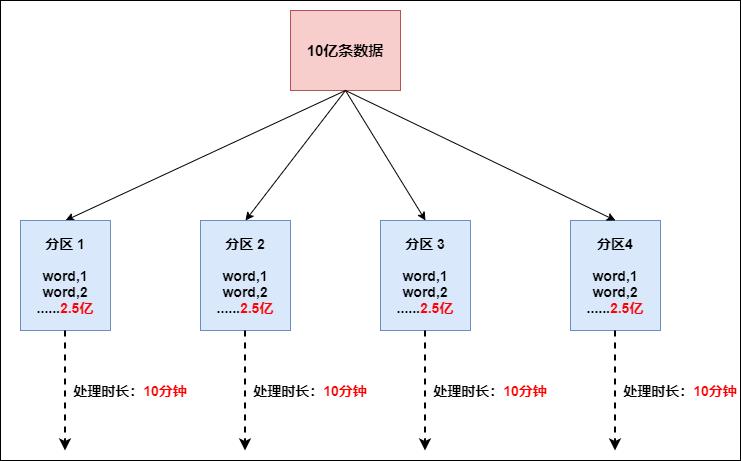
//?ʹ��rebalance����,����������б
val?rebalance?=?filterData.rebalance()
16. partitionByHash
����ָ����key����hash����
val?data?=?new?mutable.MutableList[(Int,?Long,?String)]
data.+=((1,?1L,?"Hi"))
data.+=((2,?2L,?"Hello"))
data.+=((3,?2L,?"Hello?world"))
val?collection?=?env.fromCollection(data)
val?unique?=?collection.partitionByHash(1).mapPartition{
??line?=>
????line.map(x?=>?(x._1?,?x._2?,?x._3))
}
unique.writeAsText("hashPartition",?WriteMode.NO_OVERWRITE)
env.execute()
17. partitionByRange
����ָ����key�����ݼ����з�Χ����
val?data?=?new?mutable.MutableList[(Int,?Long,?String)]
data.+=((1,?1L,?"Hi"))
data.+=((2,?2L,?"Hello"))
data.+=((3,?2L,?"Hello?world"))
data.+=((4,?3L,?"Hello?world,?how?are?you?"))
val?collection?=?env.fromCollection(data)
val?unique?=?collection.partitionByRange(x?=>?x._1).mapPartition(line?=>?line.map{
??x=>
????(x._1?,?x._2?,?x._3)
})
unique.writeAsText("rangePartition",?WriteMode.OVERWRITE)
env.execute()
18. sortPartition
����ָ�����ֶ�ֵ���з���������
val?data?=?new?mutable.MutableList[(Int,?Long,?String)]
????data.+=((1,?1L,?"Hi"))
????data.+=((2,?2L,?"Hello"))
????data.+=((3,?2L,?"Hello?world"))
????data.+=((4,?3L,?"Hello?world,?how?are?you?"))
val?ds?=?env.fromCollection(data)
????val?result?=?ds
??????.map?{?x?=>?x?}.setParallelism(2)
??????.sortPartition(1,?Order.DESCENDING)//��һ���������������ĸ��ֶν��з���
??????.mapPartition(line?=>?line)
??????.collect()
println(result)
����Sink����
1. collect
��������������ؼ���
result.collect()
2. writeAsText
������������ļ�
Flink֧�ֶ��ִ洢�豸�ϵ��ļ�,���������ļ�,hdfs�ļ���
Flink֧�ֶ����ļ��Ĵ洢��ʽ,����text�ļ�,CSV�ļ���
//?������д�뱾���ļ�
result.writeAsText("/data/a",?WriteMode.OVERWRITE)
//?�������HDFS
result.writeAsText("hdfs://node01:9000/data/a",?WriteMode.OVERWRITE)
DataStream����������
��DataSetһ��,DataStreamҲ����һϵ�е�Transformation����
һ��Source����
Flink����ʹ�� StreamExecutionEnvironment.addSource(source) ��Ϊ���ǵij�������������Դ��
Flink �Ѿ��ṩ������ʵ�ֺ��˵� source functions,��Ȼ����Ҳ����ͨ��ʵ�� SourceFunction ���Զ���Dz��е�source����ʵ�� ParallelSourceFunction �ӿڻ�����չ RichParallelSourceFunction ���Զ��岢�е� source��
Flink���������ϵ�source�����������ϵ�source����һ�¡�������4����:
-
�������ؼ�����source(Collection-based-source)
-
�����ļ���source(File-based-source)- ��ȡ�ı��ļ�,������ TextInputFormat �淶���ļ�,��������Ϊ�ַ�������
-
��������������source(Socket-based-source)- �� socket ��ȡ��Ԫ�ؿ����÷ָ����з֡�
-
�Զ�����source(Custom-source)
����ʹ��addSource��Kafka����д��FlinkΪ��:
�����Ҫ�ⲿ����Դ�Խ�,��ʹ��addSource,�罫Kafka����д��Flink, ����������:
<!--?https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.11?-->
<dependency>
????<groupId>org.apache.flink</groupId>
????<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
????<version>1.10.0</version>
</dependency>
��Kafka�����Flink:
val?properties?=?new?Properties()
properties.setProperty("bootstrap.servers",?"localhost:9092")
properties.setProperty("group.id",?"consumer-group")
properties.setProperty("key.deserializer",?"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",?"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset",?"latest")
val?source?=?env.addSource(new?FlinkKafkaConsumer011[String]("sensor",?new?SimpleStringSchema(),?properties))
�����������ֵ�:
val?source?=?env.socketTextStream("IP",?PORT)
����Transformת������
1. map
��DataSet�е�ÿһ��Ԫ��ת��Ϊ����һ��Ԫ��
dataStream.map?{?x?=>?x?*?2?}
2. FlatMap
����һ������Ԫ���������,һ����������Ԫ�������ӷָ�Ϊ���ʵ�flatmap����
dataStream.flatMap?{?str?=>?str.split("?")?}
3. Filter
����ÿ������Ԫ�IJ�������,�����溯������true������Ԫ�����˵���ֵ�Ĺ�����
dataStream.filter?{?_?!=?0?}
4.?KeyBy
���Ͻ�������Ϊ���ཻ�ķ�����������ͬKeys�����м�¼�������ͬһ���������ڲ�,keyBy()��ʹ��ɢ�з���ʵ�ֵġ�ָ�����в�ͬ�ķ�����
��ת������KeyedStream,���а���ʹ�ñ�Keys��״̬�����KeyedStream��
dataStream.keyBy(0)?
5. Reduce
��Keys���������ϵġ�������Reduce������ǰ����Ԫ�����һ��Reduce��ֵ��ϲ�������ֵ
keyedStream.reduce?{?_?+?_?}??
6.?Fold
���г�ʼֵ�ı�Keys���������ϵġ��������۵�������ǰ����Ԫ������۵���ֵ��ϲ�������ֵ
val?result:?DataStream[String]?=??keyedStream.fold("start")((str,?i)?=>?{?str?+?"-"?+?i?})?
//?����:����������Ӧ��������(1,2,3,4,5)ʱ,��������start-1��,��start-1-2��,��start-1-2-3��,...
7. Aggregations
�ڱ�Keys���������Ϲ����ۺϡ�min��minBy֮��IJ�����min������Сֵ,��minBy���ظ��ֶ��о�����Сֵ������Ԫ(max��maxBy��ͬ)��
keyedStream.sum(0);
keyedStream.min(0);
keyedStream.max(0);
keyedStream.minBy(0);
keyedStream.maxBy(0);
8.?Window
�������Ѿ�������KeyedStream�϶���Windows��Windows����ijЩ����(����,�����5���ڵ��������)��ÿ��Keys�е����ݽ��з��顣���ﲻ�ٶԴ��ڽ������,�йش��ڵ�����˵��,��鿴��ƪ����:Flink �м�����Ҫ�� Time �� Window ��ϸ����
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));?
9.?WindowAll
Windows�����ڳ���DataStream�϶��塣Windows����ijЩ����(����,�����5���ڵ��������)���������¼����з��顣
ע��:�����������,���ǷDz���ת�������м�¼���ռ���windowAll ���ӵ�һ�������С�
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
10. Window Apply
��һ�㺯��Ӧ�����������ڡ�
ע��:���������ʹ��windowAllת��,����Ҫʹ��AllWindowFunction��
������һ���ֶ���ʹ�������Ԫ�ĺ���
windowedStream.apply?{?WindowFunction?}
allWindowedStream.apply?{?AllWindowFunction?}
11. Window Reduce
��������������Ӧ���ڴ��ڲ�������С��ֵ
windowedStream.reduce?{?_?+?_?}
12. Window Fold
�������۵�����Ӧ���ڴ��ڲ������۵�ֵ
val?result:?DataStream[String]?=?windowedStream.fold("start",?(str,?i)?=>?{?str?+?"-"?+?i?})?
//?��������Ӧ��������(1,2,3,4,5)ʱ,�������۵�Ϊ�ַ�����start-1-2-3-4-5��
13.?Union
��������������������,����������������������������Ԫ��������ע��:���������������������,����ڽ�����л�ȡ��������Ԫ
dataStream.union(otherStream1,?otherStream2,?...)
14.?Window Join
�ڸ���Keys������������������������
dataStream.join(otherStream)
????.where(<key?selector>).equalTo(<key?selector>)
????.window(TumblingEventTimeWindows.of(Time.seconds(3)))
????.apply?(new?JoinFunction?()?{...})
15. Interval Join
�ڸ�����ʱ������ʹ�ù���Keys����������Key��������������������Ԫe1��e2,�Ա�e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
am.intervalJoin(otherKeyedStream)
????.between(Time.milliseconds(-2),?Time.milliseconds(2))?
????.upperBoundExclusive(true)?
????.lowerBoundExclusive(true)?
????.process(new?IntervalJoinFunction()?{...})
16. Window CoGroup
�ڸ���Keys���������϶���������������Cogroup
dataStream.coGroup(otherStream)
????.where(0).equalTo(1)
????.window(TumblingEventTimeWindows.of(Time.seconds(3)))
????.apply?(new?CoGroupFunction?()?{...})
17.?Connect
�����ӡ��������������͵�����������������������֮��Ĺ���״̬
DataStream<Integer>?someStream?=?...?DataStream<String>?otherStream?=?...?ConnectedStreams<Integer,?String>?connectedStreams?=?someStream.connect(otherStream)
//?...?����ʡ���м����
18.?CoMap,CoFlatMap
�����������������ϵ�map��flatMap
connectedStreams.map(
????(_?:?Int)?=>?true,
????(_?:?String)?=>?false)connectedStreams.flatMap(
????(_?:?Int)?=>?true,
????(_?:?String)?=>?false)
19.?Split
����ijЩ���������Ϊ������������
val?split?=?someDataStream.split(
??(num:?Int)?=>
????(num?%?2)?match?{
??????case?0?=>?List("even")
??????case?1?=>?List("odd")
????})??????
20.?Select
�Ӳ������ѡ��һ��������
SplitStream<Integer>?split;DataStream<Integer>?even?=?split.select("even");DataStream<Integer>?odd?=?split.select("odd");DataStream<Integer>?all?=?split.select("even","odd")
����Sink����
֧�ֽ����������:
-
�����ļ�(�ο�������)
-
���ؼ���(�ο�������)
-
HDFS(�������)
����֮��,��֧��:
-
sink��kafka
-
sink��mysql
-
sink��redis
������sink��kafka��:
val?sinkTopic?=?"test"
//������
case?class?Student(id:?Int,?name:?String,?addr:?String,?sex:?String)
val?mapper:?ObjectMapper?=?new?ObjectMapper()
//������ת�����ַ���
def?toJsonString(T:?Object):?String?=?{
????mapper.registerModule(DefaultScalaModule)
????mapper.writeValueAsString(T)
}
def?main(args:?Array[String]):?Unit?=?{
????//1.������ִ�л���
????val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
????//2.������
????val?dataStream:?DataStream[Student]?=?env.fromElements(
??????Student(8,?"xiaoming",?"beijing?biejing",?"female")
????)
????//��studentת�����ַ���
????val?studentStream:?DataStream[String]?=?dataStream.map(student?=>
??????toJsonString(student)?//?������Ҫ��ʾSerializerFeature�е�ijһ��,����ᱨͬʱƥ�����������Ĵ���
????)
????//studentStream.print()
????val?prop?=?new?Properties()
????prop.setProperty("bootstrap.servers",?"node01:9092")
????val?myProducer?=?new?FlinkKafkaProducer011[String](sinkTopic,?new?KeyedSerializationSchemaWrapper[String](new?SimpleStringSchema()),?prop)
????studentStream.addSink(myProducer)
????studentStream.print()
????env.execute("Flink?add?sink")
}
���ĵ����ڹ��ںš������ѧ�����ݡ�,��������ݼ����ĵ����·�ɨ���ע��ȡ:
![]()
�塢�������е�Time��Window
Flink ����ʽ�ġ�ʵʱ�� �������档
����һ�仰������������,һ������ʽ,һ����ʵʱ��
��ʽ:��������ԴԴ���ϵ�������,Ҳ��������û�б߽�,�������Ǽ����ʱ�������һ���б߽�ķ�Χ�ڽ���,�������������һ������,�߽���ôȷ��?�Ǿ����ַ�ʽ,����ʱ��λ�������������ȷ��,����ʱ��ξ���ÿ���ʱ��ͻ���һ���߽�,��������������ÿ�����������ݻ���һ���߽�,Flink �о�����ô���ֱ߽��,���Ļ���ϸ���⡣
ʵʱ:�������ݷ�����֮�������ͽ�����صļ���,Ȼ������������ļ���������:
-
һ����ֻ�б߽��ڵ����ݽ��м���,���ֺ�����,����ͳ��ÿ���û������������������������,�Ϳ���ȡ���������ڵ���������,Ȼ�����ÿ���û�����,ͳ�����ŵ�������
-
��һ���DZ߽����������ⲿ���ݽ��й�������,����:ͳ������������������ŵ��û�����������Щ����,���־���Ҫ���������������ŵ��û���Ϣ�� hive �еĵ���ά�����й���,Ȼ���ڽ�����ؼ��㡣
���������� Flink ���ݾ���Χ�����ϸ��������ϸ������!
1. Time
��Flink��,�����ʱ��λ��ֱ߽�Ļ�,��ôʱ�����һ��������Ҫ���ֶΡ�
Flink�е�ʱ������������,����ͼ��ʾ:
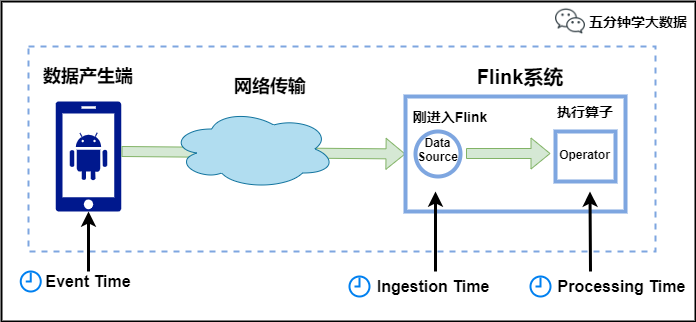
-
Event Time:���¼�������ʱ�䡣��ͨ�����¼��е�ʱ�������,����ɼ�����־������,ÿһ����־�����¼�Լ�������ʱ��,Flinkͨ��ʱ��������������¼�ʱ�����
-
Ingestion Time:�����ݽ���Flink��ʱ�䡣
-
Processing Time:��ÿһ��ִ�л���ʱ����������ӵı���ϵͳʱ��,��������,Ĭ�ϵ�ʱ�����Ծ���Processing Time��
����,һ����־����Flink��ʱ��Ϊ2021-01-22 10:00:00.123,����Window��ϵͳʱ��Ϊ2021-01-22 10:00:01.234,��־����������:
2021-01-06 18:37:15.624 INFO Fail over to rm2
����ҵ����˵,Ҫͳ��1min�ڵĹ�����־����,�ĸ�ʱ�������������?���� eventTime,��Ϊ����Ҫ������־������ʱ�����ͳ�ơ�
2. Window
Window,������,����ǰ��һֱ�ᵽ�ı߽���������Window(����)��
�ٷ�����:��ʽ������һ�ֱ�������ڴ����������ݼ������ݴ�������,���������ݼ���ָһ�ֲ��������ı������������ݼ�,��window��һ���и���������Ϊ������д������ֶ���
����Window�����������������ĺ���,Window��һ������stream��ֳ�����С�ġ�buckets��Ͱ,���ǿ�������ЩͰ�������������
Window����
���ĸտ�ʼ�ᵽ,���ִ��ھ����ַ�ʽ:
-
����ʱ����н�ȡ(time-driven-window),����ÿ1����ͳ��һ�λ�ÿ10����ͳ��һ�Ρ�
-
�������ݽ��н�ȡ(data-driven-window),����ÿ5������ͳ��һ�λ�ÿ50������ͳ��һ�Ρ�
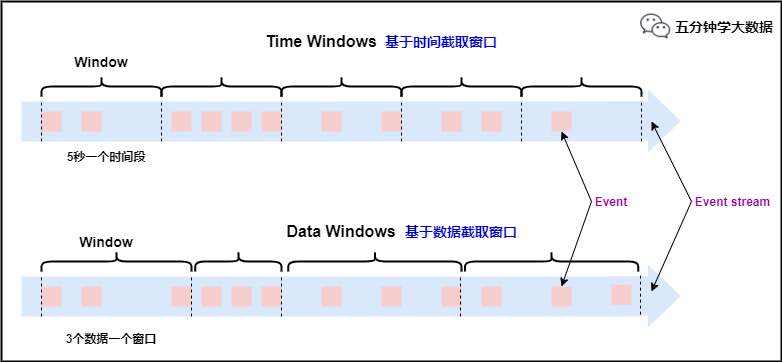
��������
����TimeWindow(����ʱ�仮�ִ���), ���Ը��ݴ���ʵ��ԭ���IJ�ͬ�ֳ�����:��������(Tumbling Window)����������(Sliding Window)�ͻỰ����(Session Window)��
-
��������(Tumbling Windows)
���������ݹ̶��Ĵ��ڳ��ȶ����ݽ�����Ƭ��
�ص�:ʱ�����,���ڳ��ȹ̶�,û���ص���
�������ڷ�������ÿ��Ԫ�ط��䵽һ��ָ�����ڴ�С�Ĵ�����,����������һ���̶��Ĵ�С,���Ҳ�������ص���
����:�����ָ����һ��5���Ӵ�С�Ĺ�������,���ڵĴ�������ͼ��ʾ:
![]()
��������
���ó���:�ʺ���BIͳ�Ƶ�(��ÿ��ʱ��εľۺϼ���)��
-
��������(Sliding Windows)
���������ǹ̶����ڵĸ������һ����ʽ,���������ɹ̶��Ĵ��ڳ��Ⱥͻ��������ɡ�
�ص�:ʱ�����,���ڳ��ȹ̶�,���ص���
�������ڷ�������Ԫ�ط��䵽�̶����ȵĴ�����,�������������,���ڵĴ�С�ɴ��ڴ�С����������,��һ�����ڻ����������ƻ������ڿ�ʼ��Ƶ�ʡ����,�������������������С�ڴ��ڴ�С�Ļ�,�����ǿ����ص���,�����������Ԫ�ػᱻ���䵽��������С�
����,����10���ӵĴ��ں�5���ӵĻ���,��ôÿ��������5���ӵĴ�����������ϸ�10���Ӳ���������,����ͼ��ʾ:
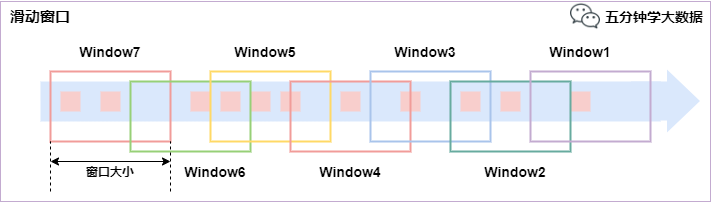
��������
���ó���:�����һ��ʱ����ڵ�ͳ��(��ij�ӿ����5min��ʧ�����������Ƿ�Ҫ����)��
-
�Ự����(Session Windows)
��һϵ���¼����һ��ָ��ʱ�䳤�ȵ�timeout��϶���,������webӦ�õ�session,Ҳ����һ��ʱ��û�н��յ������ݾͻ������µĴ��ڡ�
�ص�:ʱ��������
session���ڷ�����ͨ��session�����Ԫ�ؽ��з���,session���ڸ��������ںͻ����������,�������ص��̶��Ŀ�ʼʱ��ͽ���ʱ������,�෴,������һ���̶���ʱ�������ڲ����յ�Ԫ��,���ǻ�������,�Ǹ�������ھͻ�ر���һ��session����ͨ��һ��session���������,���session��������˷ǻ�Ծ���ڵij���,������ǻ�Ծ���ڲ���,��ô��ǰ��session���رղ��Һ�����Ԫ�ؽ������䵽�µ�session������ȥ��
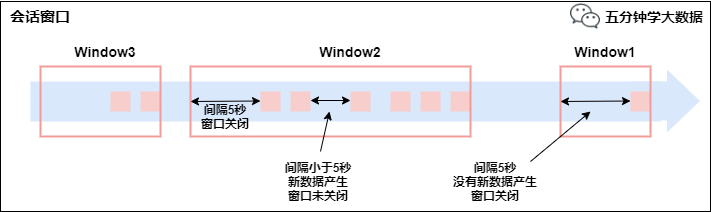
�Ự����
3. Window API
1) TimeWindow
TimeWindow�ǽ�ָ��ʱ�䷶Χ�ڵ������������һ��window,һ�ζ�һ��window������������ݽ��м���(���DZ��Ŀ�ͷ˵�Ķ�һ���߽��ڵ����ݽ��м���)��
������?���̵�·��ͨ������������?Ϊ����:
���̵�·�ڻ�������ͨ��,һ�����ж�������ͨ��,�����㡣��Ϊ����ԴԴ����,����û�б߽硣
��������ͳ��ÿ15����ͨ����·�Ƶ���������,���һ��15��Ϊ2��,�ڶ���15��Ϊ3��,������15��Ϊ1�� ...
-
tumbling-time-window (���ص�����)
����ʹ�� Linux �е� nc ����ģ�����ݵķ��ͷ�
1.�������Ͷ˿�,�˿ں�Ϊ9999
nc?-lk?9999
2.��������(key?������ͬ��·��,value?����ÿ��ͨ���ij���)
һ�η���һ��,���͵�ʱ������������������ʱ����
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
Flink ���вɼ����ݲ�����:
object?Window?{
??def?main(args:?Array[String]):?Unit?=?{
????//TODO?time-window
????//1.���������
????val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
????//2.������������Դ
????val?text?=?env.socketTextStream("localhost",?9999)
????//3.ת�����ݸ�ʽ,text->CarWc
????case?class?CarWc(sensorId:?Int,?carCnt:?Int)
????val?ds1:?DataStream[CarWc]?=?text.map?{
??????line?=>?{
????????val?tokens?=?line.split(",")
????????CarWc(tokens(0).trim.toInt,?tokens(1).trim.toInt)
??????}
????}
????//4.ִ��ͳ�Ʋ���,ÿ��sensorIdһ��tumbling����,���ڵĴ�СΪ5��
????//Ҳ����˵,ÿ5����ͳ��һ��,�����ȥ��5������,����·��ͨ�����̵�������������
????val?ds2:?DataStream[CarWc]?=?ds1
??????.keyBy("sensorId")
??????.timeWindow(Time.seconds(5))
??????.sum("carCnt")
????//5.��ʾͳ�ƽ��
????ds2.print()
????//6.����������
????env.execute(this.getClass.getName)
??}
}
���Ƿ��͵����ݲ�û��ָ��ʱ���ֶ�,����Flinkʹ�õ���Ĭ�ϵ� Processing Time,Ҳ����Flinkϵͳ��������ʱ��ʱ�䡣
-
sliding-time-window (���ص�����)
//1.���������
val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
//2.������������Դ
val?text?=?env.socketTextStream("localhost",?9999)
//3.ת�����ݸ�ʽ,text->CarWc
case?class?CarWc(sensorId:?Int,?carCnt:?Int)
val?ds1:?DataStream[CarWc]?=?text.map?{
??line?=>?{
????val?tokens?=?line.split(",")
????CarWc(tokens(0).trim.toInt,?tokens(1).trim.toInt)
??}
}
//4.ִ��ͳ�Ʋ���,ÿ��sensorIdһ��sliding����,����ʱ��10��,����ʱ��5��
//Ҳ����˵,ÿ5����ͳ��һ��,�����ȥ��10������,����·��ͨ�����̵�������������
val?ds2:?DataStream[CarWc]?=?ds1
??.keyBy("sensorId")
??.timeWindow(Time.seconds(10),?Time.seconds(5))
??.sum("carCnt")
//5.��ʾͳ�ƽ��
ds2.print()
//6.����������
env.execute(this.getClass.getName)
2) CountWindow
CountWindow���ݴ�������ͬkeyԪ�ص�����������ִ��,ִ��ʱֻ����Ԫ�������ﵽ���ڴ�С��key��Ӧ�Ľ����
ע��:CountWindow��window_sizeָ������ͬKey��Ԫ�صĸ���,�������������Ԫ�ص�������
-
tumbling-count-window (���ص�����)
//1.���������
val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
//2.������������Դ
val?text?=?env.socketTextStream("localhost",?9999)
//3.ת�����ݸ�ʽ,text->CarWc
case?class?CarWc(sensorId:?Int,?carCnt:?Int)
val?ds1:?DataStream[CarWc]?=?text.map?{
??(f)?=>?{
????val?tokens?=?f.split(",")
????CarWc(tokens(0).trim.toInt,?tokens(1).trim.toInt)
??}
}
//4.ִ��ͳ�Ʋ���,ÿ��sensorIdһ��tumbling����,���ڵĴ�СΪ5
//����key�����ռ�,��Ӧ��key���ֵĴ����ﵽ5����Ϊһ�����
val?ds2:?DataStream[CarWc]?=?ds1
??.keyBy("sensorId")
??.countWindow(5)
??.sum("carCnt")
//5.��ʾͳ�ƽ��
ds2.print()
//6.����������
env.execute(this.getClass.getName)
-
sliding-count-window (���ص�����)
ͬ��Ҳ�Ǵ��ڳ��Ⱥͻ������ڵIJ���:���ڳ�����5,����������3
//1.���������
val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
//2.������������Դ
val?text?=?env.socketTextStream("localhost",?9999)
//3.ת�����ݸ�ʽ,text->CarWc
case?class?CarWc(sensorId:?Int,?carCnt:?Int)
val?ds1:?DataStream[CarWc]?=?text.map?{
??(f)?=>?{
????val?tokens?=?f.split(",")
????CarWc(tokens(0).trim.toInt,?tokens(1).trim.toInt)
??}
}
//4.ִ��ͳ�Ʋ���,ÿ��sensorIdһ��sliding����,���ڴ�С3������,���ڻ���Ϊ3������
//Ҳ����˵,ÿ��·�ڷֱ�ͳ��,�յ���������3����Ϣʱͳ�������5����Ϣ��,����·��ͨ������������
val?ds2:?DataStream[CarWc]?=?ds1
??.keyBy("sensorId")
??.countWindow(5,?3)
??.sum("carCnt")
//5.��ʾͳ�ƽ��
ds2.print()
//6.����������
env.execute(this.getClass.getName)
-
Window �ܽ�
-
flink֧�����ֻ��ִ��ڵķ�ʽ(time��count)
-
�������ʱ�仮�ִ���,��ô������һ��time-window
-
����������ݻ��ִ���,��ô������һ��count-window
-
-
flink֧�ִ��ڵ�������Ҫ����(size��interval)
-
���size=interval,��ô�ͻ��γ�tumbling-window(���ص�����)
-
���size>interval,��ô�ͻ��γ�sliding-window(���ص�����)
-
���size<interval,��ô���ִ��ڽ��ᶪʧ���ݡ�����ÿ5����,ͳ�ƹ�ȥ3���ͨ��·������������,����©��2���ӵ����ݡ�
-
-
ͨ����Ͽ��Եó����ֻ�������
-
time-tumbling-window ���ص����ݵ�ʱ�䴰��,���÷�ʽ����:timeWindow(Time.seconds(5))
-
time-sliding-window ?���ص����ݵ�ʱ�䴰��,���÷�ʽ����:timeWindow(Time.seconds(5), Time.seconds(3))
-
count-tumbling-window���ص����ݵ���������,���÷�ʽ����:countWindow(5)
-
count-sliding-window ���ص����ݵ���������,���÷�ʽ����:countWindow(5,3)
-
3) Window Reduce
WindowedStream �� DataStream:��window��һ��reduce���ܵĺ���,������һ���ۺϵĽ����
import?org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import?org.apache.flink.api.scala._
import?org.apache.flink.streaming.api.windowing.time.Time
object?StreamWindowReduce?{
??def?main(args:?Array[String]):?Unit?=?{
????//?��ȡִ�л���
????val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
????//?����SocketSource
????val?stream?=?env.socketTextStream("node01",?9999)
????//?��stream���д�������key�ۺ�
????val?streamKeyBy?=?stream.map(item?=>?(item,?1)).keyBy(0)
????//?����ʱ�䴰��
????val?streamWindow?=?streamKeyBy.timeWindow(Time.seconds(5))
????//?ִ�оۺϲ���
????val?streamReduce?=?streamWindow.reduce(
??????(item1,?item2)?=>?(item1._1,?item1._2?+?item2._2)
????)
????//?���ۺ�����д���ļ�
????streamReduce.print()
????//?ִ�г���
????env.execute("TumblingWindow")
??}
}
4) Window Apply
apply�������Խ���һЩ�Զ��崦��,ͨ�������ڲ���ķ�����ʵ�֡�����һЩ���Ӽ���ʱʹ�á�
�÷�
-
ʵ��һ�� WindowFunction ��
-
ָ������ķ���Ϊ [������������, �����������, keyBy��ʹ�÷����ֶε�����, ��������]
ʾ��:ʹ��apply������ʵ�ֵ���ͳ��
����:
-
��ȡ���������л���
-
����socket������Դ,��ָ��IP��ַ�Ͷ˿ں�
-
�Խ��յ�������ת���ɵ���Ԫ��
-
ʹ�� keyBy ���з���(����)
-
ʹ�� timeWinodw ָ�����ڵij���(ÿ3�����һ��)
-
ʵ��һ��WindowFunction�����ڲ���
-
apply������ʵ�־ۺϼ���
-
ʹ��Collector.collect�ռ�����
-
���Ĵ�������:
????//1.?��ȡ���������л���
????val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
????//2.?����socket������Դ,��ָ��IP��ַ�Ͷ˿ں�
????val?textDataStream?=?env.socketTextStream("node01",?9999).flatMap(_.split("?"))
????//3.?�Խ��յ�������ת���ɵ���Ԫ��
????val?wordDataStream?=?textDataStream.map(_->1)
????//4.?ʹ��?keyBy?���з���(����)
????val?groupedDataStream:?KeyedStream[(String,?Int),?String]?=?wordDataStream.keyBy(_._1)
????//5.?ʹ��?timeWinodw?ָ�����ڵij���(ÿ3�����һ��)
????val?windowDataStream:?WindowedStream[(String,?Int),?String,?TimeWindow]?=?groupedDataStream.timeWindow(Time.seconds(3))
????//6.?ʵ��һ��WindowFunction�����ڲ���
????val?reduceDatStream:?DataStream[(String,?Int)]?=?windowDataStream.apply(new?RichWindowFunction[(String,?Int),?(String,?Int),?String,?TimeWindow]?{
??????//��apply������ʵ�����ݵľۺ�
??????override?def?apply(key:?String,?window:?TimeWindow,?input:?Iterable[(String,?Int)],?out:?Collector[(String,?Int)]):?Unit?=?{
????????println("hello?world")
????????val?tuple?=?input.reduce((t1,?t2)?=>?{
??????????(t1._1,?t1._2?+?t2._2)
????????})
????????//��Ҫ���ص������ռ�����,���ͻ�ȥ
????????out.collect(tuple)
??????}
????})
????reduceDatStream.print()
????env.execute()
5) Window Fold
WindowedStream �� DataStream:�����ڸ�һ��fold���ܵĺ���,������һ��fold��Ľ����
import?org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import?org.apache.flink.api.scala._
import?org.apache.flink.streaming.api.windowing.time.Time
object?StreamWindowFold?{
??def?main(args:?Array[String]):?Unit?=?{
????//?��ȡִ�л���
????val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
????//?����SocketSource
????val?stream?=?env.socketTextStream("node01",?9999,'\n',3)
????//?��stream���д�������key�ۺ�
????val?streamKeyBy?=?stream.map(item?=>?(item,?1)).keyBy(0)
????//?�����������
????val?streamWindow?=?streamKeyBy.timeWindow(Time.seconds(5))
????//?ִ��fold����
????val?streamFold?=?streamWindow.fold(100){
??????(begin,?item)?=>
????????begin?+?item._2
????}
????//?���ۺ�����д���ļ�
????streamFold.print()
????//?ִ�г���
????env.execute("TumblingWindow")
??}
}
6) Aggregation on Window
WindowedStream �� DataStream:��һ��window�ڵ�����Ԫ�����ۺϲ�����min�� minBy��������min���ص�����Сֵ,��minBy���ص��ǰ�����Сֵ�ֶε�Ԫ��(ͬ����ԭ�������� max �� maxBy)��
import?org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import?org.apache.flink.streaming.api.windowing.time.Time
import?org.apache.flink.api.scala._
object?StreamWindowAggregation?{
??def?main(args:?Array[String]):?Unit?=?{
????//?��ȡִ�л���
????val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
????//?����SocketSource
????val?stream?=?env.socketTextStream("node01",?9999)
????//?��stream���д�������key�ۺ�
????val?streamKeyBy?=?stream.map(item?=>?(item.split("?")(0),?item.split("?")(1))).keyBy(0)
????//?�����������
????val?streamWindow?=?streamKeyBy.timeWindow(Time.seconds(5))
????//?ִ�оۺϲ���
????val?streamMax?=?streamWindow.max(1)
????//?���ۺ�����д���ļ�
????streamMax.print()
????//?ִ�г���
????env.execute("TumblingWindow")
??}
}
4. EventTime��Window
1) EventTime������
-
����ʵ�����е�ʱ���Dz�һ�µ�,��flink�б�����Ϊ�¼�ʱ��,��ȡʱ��,����ʱ�����֡�
-
�����EventTimeΪ��������ʱ�䴰���ǽ��γ�EventTimeWindow,Ҫ����Ϣ������Ӧ��Я��EventTime
-
�����IngesingtTimeΪ��������ʱ�䴰���ǽ��γ�IngestingTimeWindow,��source��systemTimeΪ��
-
�����ProcessingTime��������ʱ�䴰���ǽ��γ�ProcessingTimeWindow,��operator��systemTimeΪ��
��Flink����ʽ������,���ֵ�ҵ��ʹ��eventTime,һ��ֻ��eventTime��ʹ��ʱ,�Żᱻ��ʹ��ProcessingTime����IngestionTime��
���Ҫʹ��EventTime,��ô��Ҫ����EventTime��ʱ������,���뷽ʽ������ʾ:
val?env?=?StreamExecutionEnvironment.getExecutionEnvironment
//?�ӵ���ʱ�̿�ʼ��env������ÿһ��stream��ʱ������
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
2) Watermark
����֪��,���������¼�����,������ source,�ٵ� operator,�м�����һ�����̺�ʱ���,��Ȼ�������,���� operator �����ݶ��ǰ����¼�������ʱ��˳������,����Ҳ���ų��������硢��ѹ��ԭ��,��������IJ���,��ν����,����ָ Flink ���յ����¼����Ⱥ�˳�����ϸ����¼��� Event Time ˳�����е�,���� Flink �����Ƶ�ʱ��,�Ϳ��ǵ��������ӳ�,�������������,���������һ���������:ˮӡ(WaterMark);
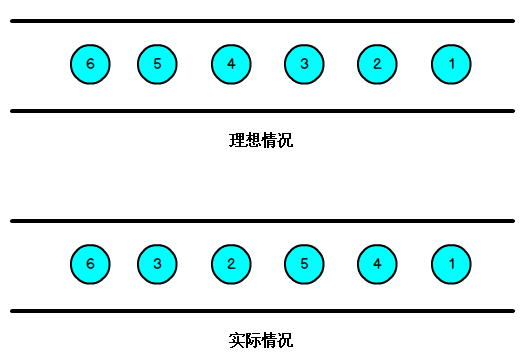
����ͼ��ʾ,�ͳ���һ������,һ����������,���ֻ���� EventTime ���� Window ������,���Dz�����ȷ�����Ƿ�ȫ����λ,���ֲ��������ڵĵ���ȥ,��ʱ����Ҫ�и���������֤һ���ض���ʱ���,���봥�� Window ȥ���м�����,����ر�Ļ���,���� Watermark��
Watermark �����ڴ��������¼���,����ȷ�Ĵ��������¼�,ͨ���� Watermark ���ƽ�� Window ��ʵ����
�������е� Watermark ���ڱ�ʾ timestamp С�� Watermark ������,���Ѿ�������,���,Window ��ִ��Ҳ���� Watermark �����ġ�
Watermark ���������һ���ӳٴ�������,���ǿ������� Watermark ����ʱʱ�� t,ÿ��ϵͳ��У���Ѿ���������������� maxEventTime,Ȼ���϶� EventTime С�� maxEventTime - t ���������ݶ��Ѿ�����,����д��ڵ�ֹͣʱ����� maxEventTime �C t,��ô������ڱ�����ִ����
��������Watermarker����ͼ��ʾ:(Watermark����Ϊ0)

�������ݵ�Watermark
��������Watermarker����ͼ��ʾ:(Watermark����Ϊ2)
![]()
�������ݵ�Watermark
�� Flink ���յ�ÿһ������ʱ,�������һ�� Watermark,���� Watermark �͵��ڵ�ǰ���е��������е� maxEventTime - �ӳ�ʱ��,Ҳ����˵,Watermark ��������Я����,һ������Я���� Watermark �ȵ�ǰδ�����Ĵ��ڵ�ֹͣʱ��Ҫ��,��ô�ͻᴥ����Ӧ���ڵ�ִ�С����� Watermark ��������Я����,���,������й���������ȡ�µ�����,��ôû�б������Ĵ��ڽ���Զ������������
��ͼ��,�������õ���������ӳٵ���ʱ��Ϊ2s,����ʱ���Ϊ7s���¼���Ӧ��Watermark��5s,ʱ���Ϊ12s���¼���Watermark��10s,������ǵĴ���1��1s~5s,����2��6s~10s,��ôʱ���Ϊ7s���¼�����ʱ��Watermarkerǡ�ô�������1,ʱ���Ϊ12s���¼�����ʱ��Watermarkǡ�ô�������2��
3) Flink���ڳٵ����ݵĴ���
waterMark��Window���ƽ������ʽ���ݵ���������,������Ϊ�ӳٶ�˳�����������,���Ը���eventTime����ҵ����,���ӳٵ�����FlinkҲ���Լ��Ľ���취,��Ҫ�İ취�Ǹ���һ�������ӳٵ�ʱ��,�ڸ�ʱ�䷶Χ���Կ��Խ��ܴ����ӳ����ݡ�
���������ӳٵ�ʱ����ͨ��?allowedLateness(lateness: Time)?����
�����ӳ���������ͨ��?sideOutputLateData(outputTag: OutputTag[T])?����
��ȡ�ӳ�������ͨ��?DataStream.getSideOutput(tag: OutputTag[X])?��ȡ
������÷�����:
allowedLateness(lateness: Time)
def?allowedLateness(lateness:?Time):?WindowedStream[T,?K,?W]?=?{
??javaStream.allowedLateness(lateness)
??this
}
�÷�������һ��Timeֵ,�����������ݳٵ���ʱ��,���ʱ��� WaterMark �е�ʱ����ͬ�������ع�һ��:
WaterMark=���ݵ��¼�ʱ��-��������ʱ��ֵ
���������ݵĵ���,waterMark��ֵ�����Ϊ���������¼�ʱ��-��������ʱ��ֵ,���������ʱ��
����һ����ʷ����,waterMarkֵ����¡��ܵ���˵,waterMark��Ϊ���ܽ��յ������ܶ���������ݡ�
�������Timeֵ,��Ҫ��Ϊ�˵ȴ��ٵ�������,��һ��ʱ�䷶Χ��,������ڸô��ڵ����ݵ���,�Ի���м���,�����Լ��㷽ʽ��ϸ˵��
ע��:�÷���ֻ����ڻ���event-time�Ĵ���,����ǻ���processing-time,����ָ���˷����timeֵ����׳��쳣��
sideOutputLateData(outputTag: OutputTag[T])
def?sideOutputLateData(outputTag:?OutputTag[T]):?WindowedStream[T,?K,?W]?=?{
??javaStream.sideOutputLateData(outputTag)
??this
}
�÷����ǽ����������ݱ�����������outputTag����,��OutputTag������������ӳ����ݵ�һ������
DataStream.getSideOutput(tag: OutputTag[X])
ͨ��window�Ȳ������ص�DataStream���ø÷���,�������ӳ����ݵĶ�������ȡ�ӳٵ����ݡ�
���ӳ����ݵ�����
�ӳ�������ָ:
�ڵ�ǰ���ڡ����贰�ڷ�ΧΪ10-15���Ѿ�����֮��,������һ�����ڸô��ڵ����ݡ������¼�ʱ��Ϊ13��,��ʱ���Իᴥ�� Window ����,�������ݾͳ�Ϊ�ӳ����ݡ�
��ô��������,�ӳ�ʱ����ô������?
���贰�ڷ�ΧΪ10-15,�ӳ�ʱ��Ϊ2s,��ֻҪ WaterMark<15+2,�������ڸô���,���ܴ��� Window ���������������һ������ʹ�� WaterMark>=15+2,10-15������ھͲ����ٴ��� Window ����,��ʹ���������ݵ� Event Time �����������ʱ���� ��
4) Flink ���� Hive ������
Flink 1.12 ֧���� Hive ���µķ�����Ϊʱ̬���Ĺ���,����ͨ�� SQL �ķ�ʽֱ�ӹ��� Hive �����������·���,���һ��Զ��������µ� Hive ����,����ص��µķ�����,���Զ�����ά�����ݵ�ȫ���滻��ͨ�����ַ�ʽ,�û������д DataStream �������?Kafka ��ʵʱ�������µ� Hive ����ʵ�����ݴ����
�����÷�:
�� Sql Client ��ע�� HiveCatalog:
vim?conf/sql-client-defaults.yaml?
catalogs:?
??-?name:?hive_catalog?
????type:?hive?
????hive-conf-dir:?/disk0/soft/hive-conf/?#��Ŀ¼��Ҫ��hive-site.xml�ļ�?
���� Kafka ��
CREATE?TABLE?hive_catalog.flink_db.kfk_fact_bill_master_12?(??
????master?Row<reportDate?String,?groupID?int,?shopID?int,?shopName?String,?action?int,?orderStatus?int,?orderKey?String,?actionTime?bigint,?areaName?String,?paidAmount?double,?foodAmount?double,?startTime?String,?person?double,?orderSubType?int,?checkoutTime?String>,??
proctime?as?PROCTIME()??--?PROCTIME������Hiveʱ̬������??
)?WITH?(??
?'connector'?=?'kafka',??
?'topic'?=?'topic_name',??
?'format'?=?'json',??
?'properties.bootstrap.servers'?=?'host:9092',??
?'properties.group.id'?=?'flinkTestGroup',??
?'scan.startup.mode'?=?'timestamp',??
?'scan.startup.timestamp-millis'?=?'1607844694000'??
);?
Flink ��ʵ���� Hive ���·������ݹ���
dim_extend_shop_info �� Hive ���Ѵ��ڵı�,���������� table hint ��̬�ؿ���ά��������
CREATE?VIEW?IF?NOT?EXISTS?hive_catalog.flink_db.view_fact_bill_master?as??
SELECT?*?FROM??
?(select?t1.*,?t2.group_id,?t2.shop_id,?t2.group_name,?t2.shop_name,?t2.brand_id,???
?????ROW_NUMBER()?OVER?(PARTITION?BY?groupID,?shopID,?orderKey?ORDER?BY?actionTime?desc)?rn??
????from?hive_catalog.flink_db.kfk_fact_bill_master_12?t1??
???????JOIN?hive_catalog.flink_db.dim_extend_shop_info???
??/*+?OPTIONS('streaming-source.enable'='true',??
?????'streaming-source.partition.include'?=?'latest',??
?????'streaming-source.monitor-interval'?=?'1?h',
?????'streaming-source.partition-order'?=?'partition-name')?*/
????FOR?SYSTEM_TIME?AS?OF?t1.proctime?AS?t2?--ʱ̬��??
????ON?t1.groupID?=?t2.group_id?and?t1.shopID?=?t2.shop_id??
????where?groupID?in?(202042))?t??where?t.rn?=?1?
��������:
-
streaming-source.enable?������ʽ��ȡ Hive ���ݡ�
-
streaming-source.partition.include?����������ֵ:
-
latest ����: ֻ��ȡ���·������ݡ�
-
all: ��ȡȫ���������� ,Ĭ��ֵΪ all,��ʾ�����з���,latest ֻ������ temporal join ��,���ڶ�ȡ���·�����Ϊά��,����ֱ�Ӷ�ȡ���·������ݡ�
-
-
streaming-source.monitor-interval?�����·������ɵ�ʱ�䡢���˹��� �������1 ��Сʱ,��ΪĿǰ��ʵ����ÿ�� task �����ѯ metastore,��Ƶ�IJ���ܻ��metastore ���������ѹ������Ҫע�����,1.12.1 �ſ����������,���Խ��鰴��ʵ��ҵ��Ҫ���̫�̵� interval��
-
streaming-source.partition-order?��������,��Ҫ������ 3 ��,������Ϊ�Ƽ�����?partition-name:
-
partition-name ʹ��Ĭ�Ϸ�������˳��������·���
-
create-time ʹ�÷����ļ�����ʱ��˳��
-
partition-time ʹ�÷���ʱ��˳��
-
������������
����������,�����ϴ�����,��ȡ������pdf,��ɨ���ע���ںš������ѧ��������,��̨����:flink pdf,�������ش�Ŀ¼��������flink�ĵ�:?

?