创建连接
使用Java操作hdfs,其实是使用hdfs的文件管理系统file system(在hdfs-site.xml中)
FileSystem fs;
@Before
public void main() throws Exception{
//获取配置文件,通过configuration这个类
Configuration configuration = new Configuration();
//设置副本数
configuration.set("dfs.replication","1");
//获取指定的连接地址
//端口9000在core-site.xml中,50070只是一个前端的界面端口号
URI uri = new URI("hdfs://master:9000");
//创建获取文件管理系统的对象,通过对象操作hdfs
fs = FileSystem.get(uri, configuration);
}
创建目录或文件
值得注意的是mkdirs方法里面需要的是Path,而不是一个直接的路径
@Test
public void mk() throws Exception{
boolean mkdirs = fs.mkdirs(new Path("/test/test/test"));
System.out.println(mkdirs);
}
删除目录或文件
public void delete() throws Exception{
//boolean表示是否可以迭代删除
//为true可以,false不可以
boolean delete = fs.delete(new Path("/test"), true);
System.out.println(delete);
}
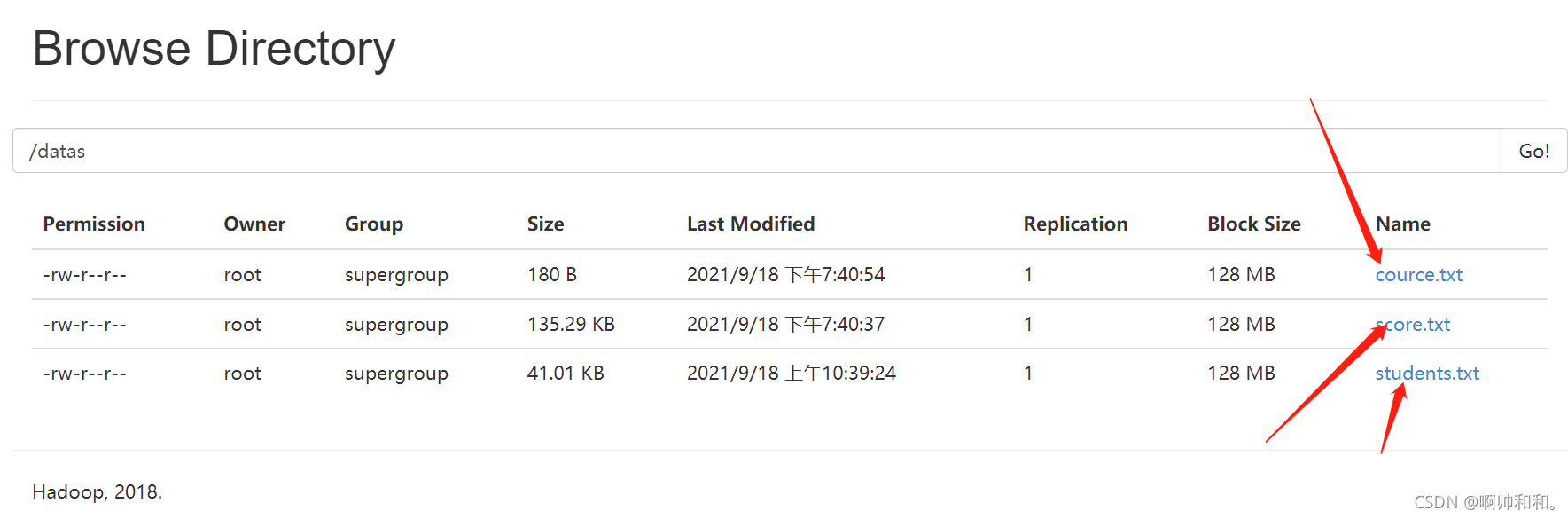
查看文件状态
@Test //查看文件状态
public void listStatus() throws Exception{
FileStatus[] fileStatuses = fs.listStatus(new Path("/datas"));
for (FileStatus f:fileStatuses) {
System.out.println(f.getBlockSize());//固定是128MB
System.out.println(f.getLen());//表示的是当前的数据量
System.out.println(f.getReplication());//表示的是副本数量,配置文件里面设置过了,刚开始的初始化也设置了
System.out.println(f.getPermission());//权限
System.out.println(f.getPath());//详细地址(路径)
System.out.println("--------");
}
简而言之,这里面的代码查的是这些东西
文件切分一个block块
现在查的是这这个块里面的内容
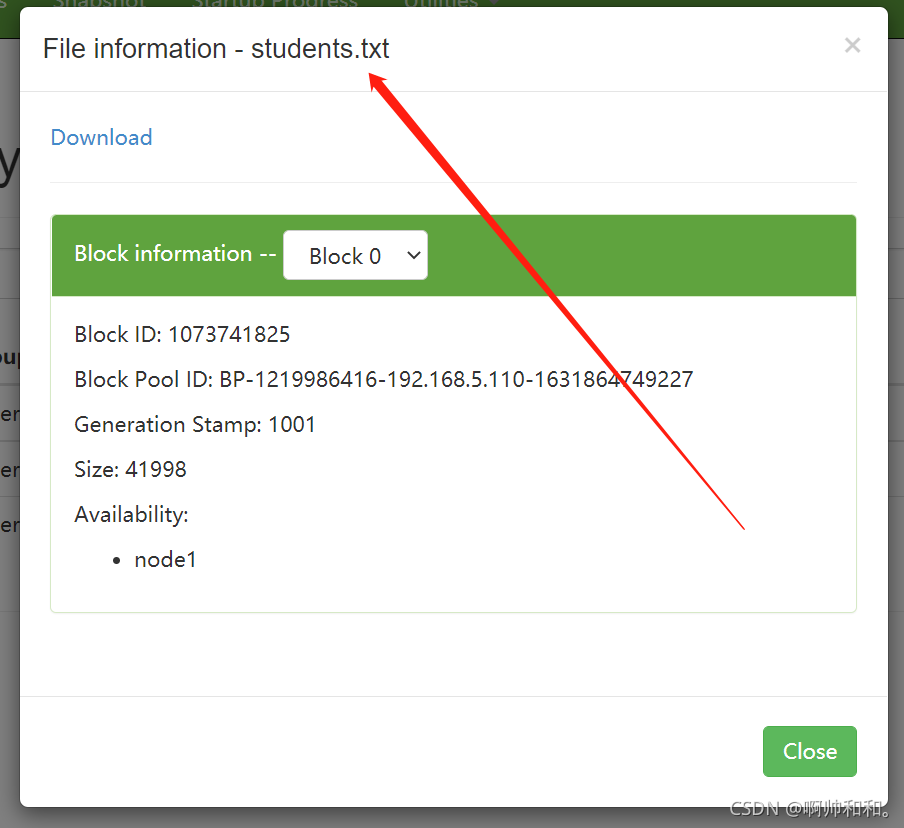
发现代码查出的内容与上面一样
@Test //查看块的状态
public void listBlockLocation() throws IOException {
//这个块是一个数组,是因为有可能不止一个块
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(
new Path("/datas/students.txt"),
0,
10
);
for(BlockLocation blockLocation:fileBlockLocations){
// System.out.println(blockLocation.getHosts());//这里获取的是一个地址,说明是一个容器,继续遍历
String[] hosts = blockLocation.getHosts();
for (String s:hosts) {
System.out.println(s);
}
System.out.println(blockLocation.getLength());
// System.out.println(blockLocation.getNames());//这里也是一个地址,继续遍历
String[] names = blockLocation.getNames();
for (String s:names) {
System.out.println(s);
}
System.out.println(blockLocation.getOffset());//偏移量0,指的是Block0里面的0
// System.out.println(blockLocation.getTopologyPaths());//这里也是一个地址,继续遍历
String[] topologyPaths = blockLocation.getTopologyPaths();
for (String s:topologyPaths) {
System.out.println(s);
}
}
}
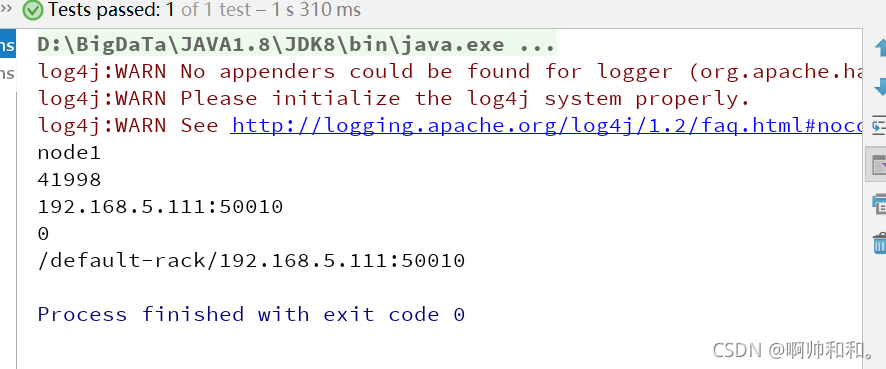
文件切分多个block块
@Test
//文件切分多个block块
public void getBlockLocation() throws Exception{
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(new Path("/datas/bigstudent.txt"), 0, 1000000000);
for (BlockLocation blockLocation:fileBlockLocations){
String[] hosts = blockLocation.getHosts();
for(int i=0;i<hosts.length;i++){
System.out.println(hosts[i]+"---"+blockLocation.getOffset());
}
}
所有完整代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
public class hdfsAPI {
//1.获取hdfs的文件管理系统file system(hdfs-site.xml)
FileSystem fs;
@Before
public void main() throws Exception{
//获取配置文件,通过configuration这个类
Configuration configuration = new Configuration();
//设置副本数
configuration.set("dfs.replication","1");
//获取指定的连接地址
//端口9000在core-site.xml中,50070只是一个前端的界面端口号
URI uri = new URI("hdfs://master:9000");
//创建获取文件管理系统的对象,通过对象操作hdfs
fs = FileSystem.get(uri, configuration);
}
@Test
public void mk() throws Exception{
boolean mkdirs = fs.mkdirs(new Path("/test/test/test"));
System.out.println(mkdirs);
}
@Test
public void delete() throws Exception{
//boolean表示是否可以迭代删除
//为true可以,false不可以
boolean delete = fs.delete(new Path("/test"), true);
System.out.println(delete);
}
@Test //查看文件状态
public void listStatus() throws Exception{
FileStatus[] fileStatuses = fs.listStatus(new Path("/datas"));
for (FileStatus f:fileStatuses) {
System.out.println(f.getBlockSize());//固定是128MB
System.out.println(f.getLen());//表示的是当前的数据量
System.out.println(f.getReplication());//表示的是副本数量,配置文件里面设置过了,刚开始的初始化也设置了
System.out.println(f.getPermission());//权限
System.out.println(f.getPath());//详细地址(路径)
System.out.println("--------");
}
}
@Test //查看块的状态
//文件切分一个block块
public void listBlockLocation() throws IOException {
//这个块是一个数组,是因为有可能不止一个块
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(
new Path("/datas/bigstudent.txt"),
0,
10
);
for(BlockLocation blockLocation:fileBlockLocations){
// System.out.println(blockLocation.getHosts());//这里获取的是一个地址,说明是一个容器,继续遍历
String[] hosts = blockLocation.getHosts();
for (String s:hosts) {
System.out.println(s);
}
System.out.println(blockLocation.getLength());
// System.out.println(blockLocation.getNames());//这里也是一个地址,继续遍历
String[] names = blockLocation.getNames();
for (String s:names) {
System.out.println(s);
}
System.out.println(blockLocation.getOffset());//偏移量0,指的是Block0里面的0
// System.out.println(blockLocation.getTopologyPaths());//这里也是一个地址,继续遍历
String[] topologyPaths = blockLocation.getTopologyPaths();
for (String s:topologyPaths) {
System.out.println(s);
}
}
}
@Test
//文件切分多个block块
public void getBlockLocation() throws Exception{
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(new Path("/datas/bigstudent.txt"), 0, 1000000000);
for (BlockLocation blockLocation:fileBlockLocations){
String[] hosts = blockLocation.getHosts();
for(int i=0;i<hosts.length;i++){
System.out.println(hosts[i]+"---"+blockLocation.getOffset());
}
}
}
}
block块如何划分
一个文件大于128MB,并且也超出了10%的缓存,就会被瓜分到不同的block块中,且分去的地方不尽相同。有些被分到了node1,有些分到了node2,而master中是不存数据的
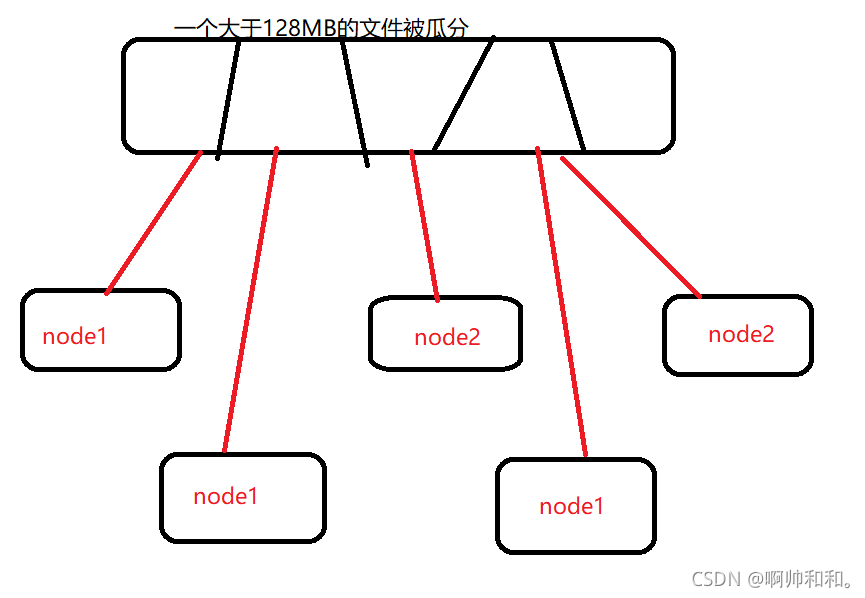
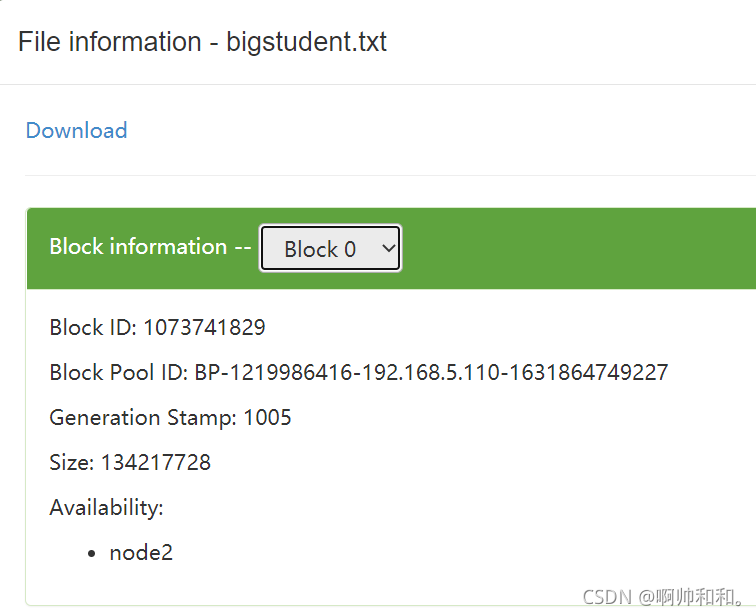
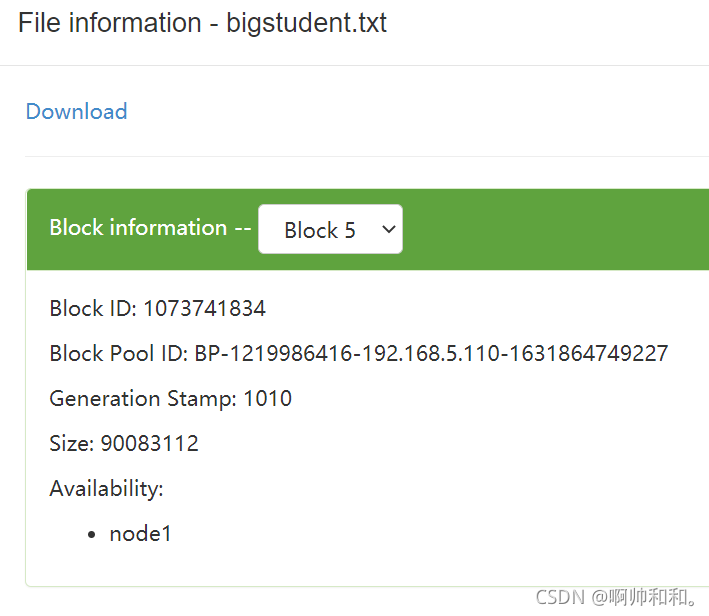
每一块的数据如何相连
不同的数据被分成了许多的block块,那么机器是怎么知道哪几个block块是对应一个数据的呢?
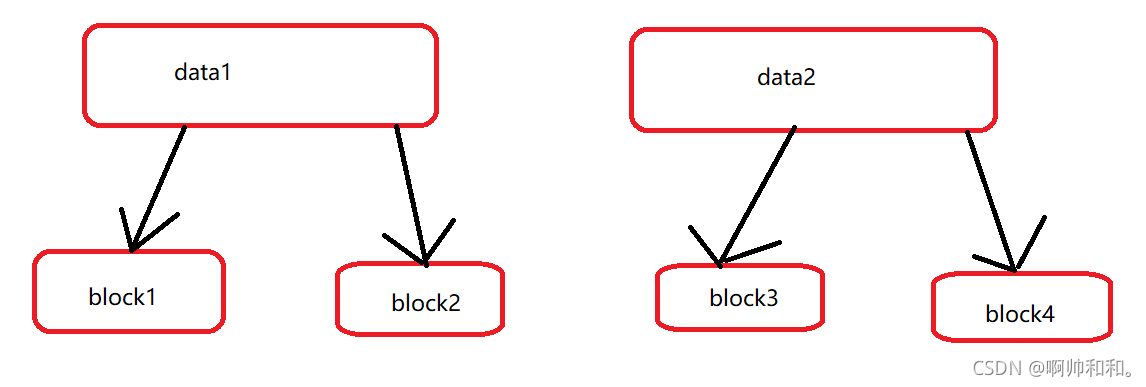
不同的block块虽然被放到了不同的节点(node)中,但是拿数据的时候是根据ID号来取数据的,同一个数据的ID号是连一起的(读一个数据文件,比如students.txt的时候,寻找的只是这个文件里面的block块的ID,不会去找别的ID)
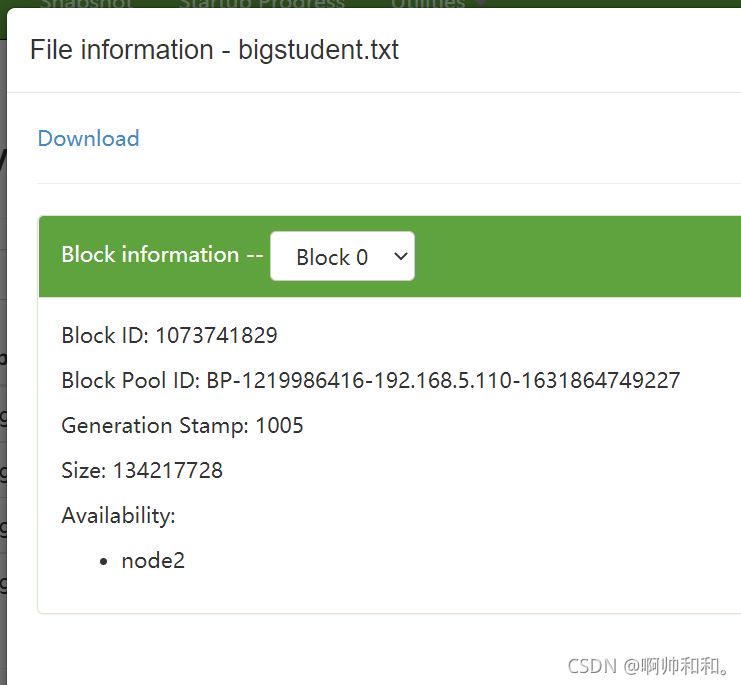
感谢阅读,我是啊帅和和,一位大数据专业大四学生,祝你快乐。