MapReduce�ľ������Ű���
WordCount��Ŀ
Javaʵ��
-
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.xxxx</groupId> <artifactId>hadoop-mr-wordcount-demo</artifactId> <version>1.0</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <!-- Hadoop�汾���� --> <hadoop.version>3.1.2</hadoop.version> <!-- commons-io�汾���� --> <commons-io.version>2.4</commons-io.version> </properties> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>${hadoop.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-jobclient--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>${hadoop.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/commons-io/commons-io --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>${commons-io.version}</version> </dependency> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency> <!--���߰�--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.4.1</version> </dependency> </dependencies> <build> <!-- <finalName>${project.name}</finalName>--> <plugins> <!--������--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>2.5.5</version> <configuration> <archive> <manifest> <mainClass>com.yjxxt.job.WordCountJob</mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <appendAssemblyId>false</appendAssemblyId> </configuration> </plugin> </plugins> </build> </project> -
����Job��
import cn.hutool.core.date.DatePattern; import cn.hutool.core.date.DateUtil; import com.yjxxt.mapper.WordCountMapper; import com.yjxxt.reducer.WordCountReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.util.Date; /** * ͳ�Ƶ��ʴ��������� */ public class WordCountJob { private static final int REDUCER_NUM = 2; private static final String DATA_PATH = "/yjxxt/harry.txt"; public static void main(String[] args) throws Exception { // 1. �������� Configuration configuration=new Configuration(true); // �������� // �����еIJ������� //configuration.set("mapreduce.framework.name", "yarn"); // 2.����Job�� Job job = Job.getInstance(configuration); // 3. ����Job��ز��� // ����job�������� job.setJarByClass(WordCountJob.class); String dateTimeStr = DateUtil.format(new Date(), DatePattern.PURE_DATETIME_FORMAT); job.setJobName(String.format("wc_%s", dateTimeStr)); // ���� --> ������ < ö�� (�����ļ�) job.setNumReduceTasks(REDUCER_NUM); // 4. �������ݶ�ȡ�����洢Ŀ¼(HDFS��) FileInputFormat.setInputPaths(job, new Path(DATA_PATH)); FileOutputFormat.setOutputPath(job, new Path(String.format("/yjxxt/result/wc_%s", dateTimeStr))); // Mapper������������� job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 5. ָ��Mapper �� Reducer���� job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 6. �ύ���� job.waitForCompletion(true); } } -
����Mapper��
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.IOException; import java.util.Arrays; /** * ͳ�Ƶ��ʵij��ָ��� */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { private static final Logger LOGGER = LoggerFactory.getLogger(WordCountMapper.class); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { // None��s good-ness them noticed a large, tawny owl flutter past the window. LOGGER.info("����ƫ����key = {}, ��ȡ����value = {}", key, value); String newValue = value.toString().replaceAll("[^a-zA-Z0-9'\\s]", ""); LOGGER.info("�滻�����ַ�Value = {}", newValue); String[] strArrays = newValue.split(" "); Arrays.stream(strArrays).forEach(v -> { try { context.write(new Text(v), new LongWritable(1)); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } }); } } -
����Reducer��
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.IOException; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> { private static final Logger LOGGER = LoggerFactory.getLogger(WordCountReducer.class); @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long num = 0; while(values.iterator().hasNext()) { num += values.iterator().next().get(); } LOGGER.info("�����key = {}, value = {}", key, num); // ��� context.write(key, new LongWritable(num)); } }
Resources�ļ����·ŵ������ļ�
- core-site.xml
- hdfs-site.xml
- log4j.properties
- mapred-site.xml
- yarn-site.xml
Linux������
ʹ�ò��maven-assembly-plugin,����ú�jar���ϴ���linux������,ִ��hadoop jar wordcount.jar com.yjxxt.job.WordCountJob
������Ϣ
ͳ�Ƹ�����ÿ�������º������
-
����WeatherJob��
import cn.hutool.core.date.DateUtil; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.util.Date; /** * ͳ�Ƹ���ÿ�����ߺ�������� */ public class WeatherCounterJob { public static void main(String[] args) throws Exception { // 1. ���������ļ� Configuration configuration = new Configuration(true); configuration.set("mapreduce.framework.name", "local"); // 2. ����job String dateStr = DateUtil.format(new Date(), "yyyyMMddHHmmss"); String jobName = String.format("WeatherCounter-%s", dateStr); Job weatherCounterJob = Job.getInstance(configuration, jobName); // ����job weatherCounterJob.setJarByClass(WeatherCounterJob.class); // 3. ����job weatherCounterJob.setMapOutputKeyClass(Text.class); weatherCounterJob.setMapOutputValueClass(IntWritable.class); // 4.���������������·�� FileInputFormat.setInputPaths(weatherCounterJob, "/yjxxt/data/area_weather.csv"); FileOutputFormat.setOutputPath(weatherCounterJob, new Path(String.format("/yjxxt/result/%s", jobName))); // 5.����MapReduce���� weatherCounterJob.setMapperClass(WeatherCounterMapper.class); weatherCounterJob.setReducerClass(WeatherCounterReducer.class); // 6. �ύjob weatherCounterJob.waitForCompletion(true); } } -
����Maper��
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WeatherCounterMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // ������һ�� if (key.get() == 0) { return; } // "187","�㶫","��ɳ��","440115","��","25","����","��3","96","1/6/2020 14:52:21","1/6/2020 15:00:03" // 187,�㶫,��ɳ��,440115,��,25,����,��3,96,1/6/2020 14:52:21,1/6/2020 15:00:03 String[] recode = value.toString().replaceAll("\"", "").split(","); // "ʡ����:����"; String outPutKey = String.format("%s%s%s:%s", recode[1], recode[2], recode[3], recode[9].split(" ")[0]); int temperature = Integer.parseInt(recode[5]); context.write(new Text(outPutKey), new IntWritable(temperature)); } } -
����Reducer��
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WeatherCounterReducer extends Reducer<Text, IntWritable, Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//��key�л�ȡ��ߺ���͵�����
int minTemperature=Integer.MAX_VALUE;
int maxTemperature=Integer.MIN_VALUE;
while (values.iterator().hasNext()){
int temp=values.iterator().next().get();
//����ֵȡ��Сֵ
minTemperature=Math.min(temp, minTemperature);
//����ֵȡ���ֵ
maxTemperature=Math.max(temp, maxTemperature);
}
Text outputValue=new Text(String.format("%s������¶���:%d, ����¶���:%d", key, maxTemperature, minTemperature));
context.write(outputValue, null);
}
}
ͳ�Ƹ�����ÿ�µ�ǰ�����¶�
- ÿ������,ÿ�������¶Ⱥ�����¶ȷֱ��Ƕ���?
- ÿ������,ÿ������ߵ������¶��Լ�����Ӧ���Ǽ���
- [����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-J05nV9Wn-1631968670332)(C:/Users/Administrator/Desktop/bigData�ĵ�/005_Hadoop-MapReduce 30��/Hadoop-MapReduce.assets/image-20201106001412832.png)]
����ʵ��
����Weather��
import cn.hutool.core.date.DateUtil;
import com.google.common.base.Objects;
import lombok.*;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Date;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class WeatherWritable03 implements WritableComparable<WeatherWritable03> {
private String province;
private String city;
private String adcode;
private Date date; // ������,ͳһ��ʽ:yyyy-MM-dd
private int temperature;
private String winddirection;
private String windpower;
private String weather;
private String humidity;
@Override
public int compareTo(WeatherWritable03 o) {
// ʡ > ��> ��> ���� > �¶�
int result = this.province.compareTo(o.province); // ������
if (result == 0) {
result = this.city.compareTo(o.city);
if (result == 0) {
result = this.adcode.compareTo(o.adcode);
if (result == 0) {
result = DateUtil.format(this.date, "yyyy-MM").
compareTo(DateUtil.format(o.date, "yyyy-MM"));
if (result == 0) {
result = o.temperature - this.temperature;
}
}
}
}
return result;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
WeatherWritable03 that = (WeatherWritable03) o;
return temperature == that.temperature && Objects.equal(province, that.province)
&& Objects.equal(city, that.city) && Objects.equal(adcode, that.adcode)
&& Objects.equal(date, that.date) && Objects.equal(winddirection, that.winddirection)
&& Objects.equal(windpower, that.windpower) && Objects.equal(weather, that.weather)
&& Objects.equal(humidity, that.humidity);
}
@Override
public int hashCode() {
return Objects.hashCode(province, city, adcode, date, temperature, winddirection,
windpower, weather, humidity);
}
@Override
public String toString() {
return "WeatherWritable{" +
"province='" + province + '\'' +
", city='" + city + '\'' +
", adcode='" + adcode + '\'' +
", date='" + date + '\'' +
", temperature=" + temperature +
", winddirection='" + winddirection + '\'' +
", windpower='" + windpower + '\'' +
", weather='" + weather + '\'' +
", humidity='" + humidity + '\'' +
'}';
}
@Override
public void write(DataOutput out) throws IOException {
// �������
out.writeUTF(this.province);// �ַ���
out.writeUTF(this.city);
out.writeUTF(this.adcode);
out.writeLong(this.date.getTime());
out.writeInt(this.temperature);
out.writeUTF(this.weather);
out.writeUTF(this.windpower);
out.writeUTF(this.winddirection);
out.writeUTF(this.humidity);
}
@Override
public void readFields(DataInput in) throws IOException {
// �����л�
this.province = in.readUTF();
this.city = in.readUTF();
this.adcode = in.readUTF();
this.date = new Date(in.readLong());
this.temperature = in.readInt();
this.weather = in.readUTF();
this.windpower = in.readUTF();
this.winddirection = in.readUTF();
this.humidity = in.readUTF();
}
}
����WeatherGroupingComparator����Ƚ���
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class WeatherGroupingComparator extends WritableComparator {
/**
* ���������
*/
public WeatherGroupingComparator() {
super(WeatherWritable03.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//������ת��
WeatherWritable03 w1 = (WeatherWritable03) a;
WeatherWritable03 w2 = (WeatherWritable03) b;
//��ʼ�Ƚ϶���w1��w2(ʡ �� ����[����])
int result = w1.getProvince().compareTo(w2.getProvince());
if (result == 0) {
//Ȼ��Ƚϵ���
result = w1.getCity().compareTo(w2.getCity());
if (result == 0) {
//Ȼ��Ƚ�����
result = DateUtil.format(w1.getDate(), "yyyy-MM")
.compareTo(DateUtil.format(w2.getDate(), "yyyy-MM"));
//new SimpleDateFormat("yyyy-MM")
//.format(w1.getDate()).compareTo(new SimpleDateFormat("yyyy-MM")
// .format(w2.getDate()));
}
}
return result;
}
}
�������
import org.apache.hadoop.mapreduce.Partitioner;
public class WeatherWritablePartitioner extends Partitioner {
@Override
public int getPartition(Object o, Object o2, int numPartitions) {
return 0;
}
}
����Job��
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Date;
/**
* ͳ�Ƹ���ÿ�µ�����
*/
public class WeatherCounterJob03 {
public static void main(String[] args) throws Exception {
// 1. ���������ļ�
Configuration configuration = new Configuration(true);
configuration.set("mapreduce.framework.name", "local");
// 2. ����job
String dateStr = DateUtil.format(new Date(), "yyyyMMddHHmmss");
String jobName = String.format("WeatherCounter03-%s", dateStr);
Job weatherCounterJob = Job.getInstance(configuration, jobName);
// ����job
weatherCounterJob.setJarByClass(WeatherCounterJob03.class);
// 3. ����job
weatherCounterJob.setMapOutputKeyClass(WeatherWritable03.class);
weatherCounterJob.setMapOutputValueClass(IntWritable.class);
// ����key�ıȽ���
weatherCounterJob.setGroupingComparatorClass(WeatherGroupingComparator.class);
// weatherCounterJob.setPartitionerClass(WeatherWritablePartitioner.class);
// 4.�����������
FileInputFormat.setInputPaths(weatherCounterJob, "/yjxxt/data/area_weather.csv");
FileOutputFormat.setOutputPath(weatherCounterJob, new Path(String.format("/yjxxt/result/%s", jobName)));
// 5.����MapReduce����
weatherCounterJob.setMapperClass(WeatherCounterMapper03.class);
weatherCounterJob.setReducerClass(WeatherCounterReducer03.class);
// 6. �ύjob
weatherCounterJob.waitForCompletion(true);
}
}
����Mapper��
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Date;
public class WeatherCounterMapper03 extends Mapper<LongWritable, Text, WeatherWritable03, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// ������һ��
if (key.get() == 0) {
return;
}
// "187","�㶫","��ɳ��","440115","��","25","����","��3","96","1/6/2020 14:52:21","1/6/2020 15:00:03"
// 187,�㶫,��ɳ��,440115,��,25,����,��3,96,1/6/2020 14:52:21,1/6/2020 15:00:03
String[] recode = value.toString().replaceAll("\"", "").split(",");
// "ʡ����:����";
String outPutKey = String.format("%s%s%s:%s", recode[1],
recode[2], recode[3], recode[9].split(" ")[0]);
int temperature = Integer.parseInt(recode[5]);
// 1/6/2020
// 11/6/2020
// 7/6/2020
// 2020-06-01
// 2020-06-07
// 2020-06-11
Date createTime = DateUtil.parse(recode[9], "dd/MM/yyyy HH:mm:ss"); // ����ʱ�����01/06/2020 12:09:09
String yearAndMonthDateStr = DateUtil.format(DateUtil.date(DateUtil.calendar(createTime)), "yyyy-MM-dd"); // 2020-06-11 00:00:00 ����ʱ���ַ���
Date yearAndMonthDate = DateUtil.parse(yearAndMonthDateStr, "yyyy-MM-dd"); // ת��2020-06-11����
// ͨ��������ģʽ��������
WeatherWritable03 weatherWritable = WeatherWritable03.builder().weather(recode[4])
.adcode(recode[3]).city(recode[2])
.date(yearAndMonthDate)
.humidity(recode[8]).province(recode[1])
.temperature(temperature).winddirection(recode[6]).windpower(recode[7])
.build();
context.write(weatherWritable, new IntWritable(temperature));
}
}
����Reducer��
import cn.hutool.core.date.DateUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class WeatherCounterReducer03 extends Reducer<WeatherWritable03, IntWritable, Text, NullWritable> {
@Override
protected void reduce(WeatherWritable03 key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//����
Set<String> set = new HashSet<>();
//��ȡ������
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
StringBuffer buffer = new StringBuffer();
buffer.append(key.getProvince()).append("|");
buffer.append(key.getCity()).append("|");
buffer.append(DateUtil.format(key.getDate(), "yyyy-MM-dd")).append("|");
buffer.append(iterator.next().get());
//��ŵ�Set
set.add(buffer.toString());
//�жϱ�
if (set.size() == 3) {
break;
}
}
//����
for (String s : set) {
context.write(new Text(s), null);
}
}
}
�����Ƽ�ϵͳ
- ������
- QQ�����Ƽ��C>
- ÿ��QQ200����
- 5��QQ��
- QQ�����Ƽ��C>
- ���˼·
- ��Ҫ�����н��м���
- ����ͬ�Ƽ����ó���ͬ��key,����reduceͳһ����
- ����
tom hello hadoop cat
world hello hadoop hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world hello
hello tom world hive mr
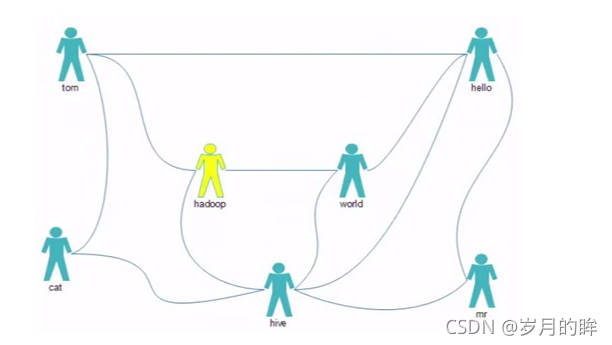
�����Ƽ��Ĵ���ʵ��
����:
�����żһԵĺ����б�:�żһ� ����Ȫ ������ ���� ���� л��Ƽ Ф� ������ ������ --------------------------------------------------------------------------------------------------- ����һ�п���String����,[�żһ�,����Ȫ,������,����,����,л��Ƽ,Ф�,������,������] names[0]��ʾ��ǰ�û�,names[i]��ʾ���ĺ���;����ֵ��ʾ�Ƽ�ֵ ֱ�Ӻ���:��ֱ�Ӻ���Ϊ 0�Ƽ�ֵ �żһ� ����Ȫ 0 �żһ� ������ 0 �żһ� ���� 0 ... ��Ӻ���:�Ǽ�Ӻ���Ϊ1�Ƽ�ֵ ����Ȫ������ 1 ����Ȫ ���� 1 ����Ȫ ���� 1 ����Ȫ л��Ƽ 1 ����Ȫ Ф� 1 ����Ȫ ������ 1 ����Ȫ ������ 1
����һ��Friend��
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Timestamp;
import java.util.Date;
import java.util.Objects;
/**
* ����һ��Friend��ʵ�ֿ�д�����ݿ��д�ӿ�
*/
public class Friend implements Writable, DBWritable{
private String id;
private String person;//ֱ�Ӻ���
private String friend;//��Ӻ���
private Integer count;
private Date createtime;
public Friend() {
}
public Friend(String id, String person, String friend, Integer count, Date createtime) {
this.id = id;
this.person = person;
this.friend = friend;
this.count = count;
this.createtime = createtime;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getPerson() {
return person;
}
public void setPerson(String person) {
this.person = person;
}
public String getFriend() {
return friend;
}
public void setFriend(String friend) {
this.friend = friend;
}
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
public Date getCreatetime() {
return createtime;
}
public void setCreatetime(Date createtime) {
this.createtime = createtime;
}
@Override
public String toString() {
return "Friend{" +
"id='" + id + '\'' +
", person='" + person + '\'' +
", friend='" + friend + '\'' +
", count=" + count +
", createtime=" + createtime +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Friend friend1 = (Friend) o;
return Objects.equals(id, friend1.id) &&
Objects.equals(person, friend1.person) &&
Objects.equals(friend, friend1.friend) &&
Objects.equals(count, friend1.count) &&
Objects.equals(createtime, friend1.createtime);
}
@Override
public int hashCode() {
return Objects.hash(id, person, friend, count, createtime);
}
@Override
public void write(DataOutput dataOutput) throws IOException {
//�����ݴ��ڴ����л���������
dataOutput.writeUTF(this.id);
dataOutput.writeUTF(this.person);
dataOutput.writeUTF(this.friend);
dataOutput.writeInt(this.count);
dataOutput.writeLong(this.createtime.getTime());
}
@Override
public void readFields(DataInput dataInput) throws IOException {
//�����л�,�Ӵ����϶�ȡ����
this.id = dataInput.readUTF();
this.person = dataInput.readUTF();
this.friend = dataInput.readUTF();
this.count = dataInput.readInt();
this.createtime = new Date(dataInput.readLong());
}
@Override
//���л������ݿ�
public void write(PreparedStatement preparedStatement) throws SQLException {
preparedStatement.setString(1, this.id);
preparedStatement.setString(2, this.person);
preparedStatement.setString(3, this.friend);
preparedStatement.setInt(4, this.count);
preparedStatement.setTimestamp(5, new Timestamp(this.createtime.getTime()));
}
@Override
//�����ݿ��ж�ȡ�ֶε��ڴ���
public void readFields(ResultSet resultSet) throws SQLException {
this.id = resultSet.getString(1);
this.person = resultSet.getString(2);
this.friend = resultSet.getString(3);
this.count = resultSet.getInt(4);
this.createtime = resultSet.getTimestamp(5);
}
}
ʹ��reservoir Sampling��ˮ���㷨������ɺ���
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.util.*;
import java.util.stream.Collectors;
/**
* ������ɺ����б�
*/
public class FriendRandomUtil {
public static void main(String[] args) throws IOException {
//��ȡѧ����Ϣ
List<String> studentList = FileUtils.readLines(new File(FriendRandomUtil.class.getResource("/students.txt").getPath()));
//���������б�ӳ���ϵ
Map<String, Set<String>> friendMap = studentList.stream().collect(Collectors.toMap(e -> e, e -> new HashSet<>()));
//��ʼ����
for (String student : friendMap.keySet()) {
//ʹ����ˮ���㷨��ȡ�������
List<String> sampleList = FriendRandomUtil.reservoirSampling(studentList, new Random().nextInt(30) + 10);
//���������ӵ�set
friendMap.get(student).addAll(sampleList);
//ͬʱ����ǰѧ�����ӵ��Է��ĺ���
for (String friend : sampleList) {
friendMap.get(friend).add(student);
}
}
//��ӡ������Ϣ
for (String student : friendMap.keySet()) {
System.out.print(student + "\t");
friendMap.get(student).stream().forEach(e -> System.out.print(e + "\t"));
System.out.println();
}
}
/**
* ��ˮ�س����㷨
*
* @param studentList
* @param num
* @return
*/
public static List<String> reservoirSampling(List<String> studentList, int num) {
//�������ݵ���ˮ��
List<String> sampleList = studentList.subList(0, num);
//��ʼ���г���
for (int i = num; i < studentList.size(); i++) {
//��0-j�������һ����
int r = new Random().nextInt(i);
if (r < num) {
//����������r<ˮ�ش�С ,������滻
sampleList.set(r, studentList.get(i));
}
}
return sampleList;
}
}
����FriendJob������
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FriendJob {
private static String driverClass = "com.mysql.cj.jdbc.Driver";
private static String url = "jdbc:mysql://192.168.191.101:3306/friend?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8";
private static String username = "root";
private static String password = "123456";
private static String tableName = "t_friends";
private static String[] fields = {"id", "person", "friend", "count", "createtime"};
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//��������
Configuration configuration = new Configuration(true);
configuration.set("mapreduce.framework.name", "local");
//�������ݿ�������ļ�
DBConfiguration.configureDB(configuration, driverClass, url
, username, password);
//����Job������
Job job = Job.getInstance(configuration);
//����Job����
//����job��������
job.setJarByClass(Hello01FriendJob.class);
//����JonName,ָ��job������
job.setJobName("Hello01Friend" + System.currentTimeMillis());
//��������reduceTask����
job.setNumReduceTasks(2);
//�������ݵ�����·��
FileInputFormat.setInputPaths(job,new Path("/yjxxt/friends.txt"));
//����Ҫ����Ľ��·��
FileOutputFormat.setOutputPath(job, new Path("/yjxxt/result/friend_"+System.currentTimeMillis()));
//����job�����ʽ��,ָ�������ݿ�
//job.setOutputFormatClass(DBOutputFormat.class);
//�������ݿ������ʽ,����ָ��job����ͱ���,�ֶ�
//DBOutputFormat.setOutput(job, tableName, fields);
//����Map�����key������Ϊ�ı�����
job.setMapOutputKeyClass(Text.class);
//����Map�����Value������Ϊ��д������
job.setMapOutputValueClass(IntWritable.class);
//ָ��Mapper��ִ��������Reducer��ִ�������
job.setMapperClass(FriendMap.class);
job.setReducerClass(FriendReducer.class);
//�ύ����
job.waitForCompletion(true);
}
}
����һ��FriendMap��
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* �żһ� ����Ȫ ������ ���� ���� л��Ƽ Ф� ������ ������
*
* ֱ�Ӻ���:��ֱ�Ӻ���Ϊ 0�Ƽ�ֵ
* �żһ� ����Ȫ 0 �żһ� ������ 0 �żһ� ���� 0 ...
* ��Ӻ���:�Ǽ�Ӻ���Ϊ1�Ƽ�ֵ
* ����Ȫ ������ 1 ����Ȫ ���� 1 ����Ȫ ���� 1 ����Ȫ л��Ƽ 1 ����Ȫ Ф� 1 ����Ȫ ������ 1 ����Ȫ ������ 1
*/
public class FriendMap extends Mapper<LongWritable, Text, Text, IntWritable> {
//������̬��Ա����
private static IntWritable one = new IntWritable(1);//��̬����1��ʾ��Ӻ���
private static IntWritable zero = new IntWritable(0);//0��ʾֱ�Ӻ���
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//�з�����,�����Ʊ��������ݽ����и�,Ȼ��浽һ��names���ַ���������
String[] names = value.toString().split("\t");
//��ʼƴ��ֱ�Ӻ����б� names[0]-->��ǰ�û�
for (int i = 1; i < names.length; i++) {
//����һ���ı�����,�������ֽ�������,����ǰ�û�names[0],ֱ�Ӻ���Ϊname[i]��
context.write(new Text(namesSort(names[0], names[i])), zero);
}
//��ʼƴ���Ƽ������б�
for (int i = 1; i < names.length; i++) {
for (int j = i + 1; j < names.length; j++) {// names[i] ��names[i+1]Ϊ��Ӻ���
context.write(new Text(namesSort(names[i], names[j])), one);
}
}
}
/**
* ���������û������ֽ�������
*
* @param name1
* @param name2
* @return
*/
private String namesSort(String name1, String name2) {
//�����û�����������,name1����name2 --> ��name1 �ŵ�name2ǰ��,����name1�ŵ�name2����
return name1.compareTo(name2) > 0 ? name2 + "-" + name1 : name1 + "-" + name2;
}
}
����һ��FriendReducer��
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Date;
import java.util.Iterator;
import java.util.UUID;
public class FriendReducer extends Reducer<Text, IntWritable, Friend, NullWritable> {
private String jobName;
//setup(Context context) **
protected void setup(Context context) throws IOException, InterruptedException {
jobName = context.getJobName();
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//�����ۼ���
int count = 0;
//��values��ȡ������
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
int value = iterator.next().get();
if (value == 0) {//value=0��ʾΪֱ�Ӻ���,�����Ƽ����Է�Ϊ����
return;
}
count += value;
}
//��ʼд������,�������� �ζ�-���� 11
String[] names = key.toString().split("-");//��keyת��ΪString����,Ȼ��-�ָ�[�ζ�, ����]
Friend f1 = new Friend(jobName + UUID.randomUUID().toString().substring(0, 9), names[0], names[1], count, new Date());
Friend f2 = new Friend(jobName + UUID.randomUUID().toString().substring(0, 9), names[1], names[0], count, new Date());
//�����
context.write(f1, NullWritable.get());
context.write(f2, NullWritable.get());
}
}
PageRank
��������
PageRank��Sergey Brin��Larry Page��1998����WWW7�������������**,����������ӷ�������ҳ����������**
- PageRank��Google������㷨,���ں����ض���ҳ������������������е�������ҳ���Ե���Ҫ�̶�
- PageRankʵ���˽����Ӽ�ֵ������Ϊ��������
- �Ժ�������Ӧ�ؼ��ʵ�ʱ��,������վ��Ȩ��˳����ʾ��ҳ
-
������ԭ��
-
ͶƱ�㷨
-
��Ϊ������������,���ǻὫȫ������վȫ����ȡ���Լ��ķ��������з���
-
Ȼ���������ǰҳ���е�������վ������(����)
-
ͬʱҲ����������վ���ӵ���ǰ��վ(����)
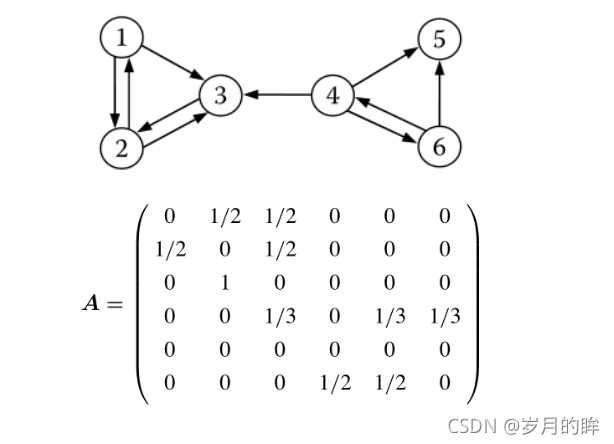
�㷨����
- ����ÿ����վĬ�ϵ�Ȩ����һ����(ʮ����,�ٷ���)
- Ȼ����վ��Ȩ��ƽ�ָ���ǰ��վ�����г���( 10 / 5 = 2 )
- ���һ����վ�ж������,�ͽ��������е������÷��ۼӵ�һ��(2+4+7+1+10=24��)
- ��ô���εĵ÷ֻ����ڼ����´γ����ļ��� (24/5 = 4.8)
- �ظ���������Ĺ���,�����ﵽһ������ֵ
- �������Ǻ������μ��㾫�ȵ���Ч����
- ����99.9%����վprֵ���ϴ�һ��
- ���е�pr��ֵ(���κ��ϴ�)�ۼ���ƽ��ֵ������ 0.0001
- ֹͣ����
����ϵ��
-
���Լ�����100������,Ȼ���ָ���Լ���Ŀ����վ
- �ջ�
- ֻ������
- ֻ������
-
����PageRank���㹫ʽ:��������ϵ��(damping factor)
- d=0.85
-
�µ�PR��ʽ
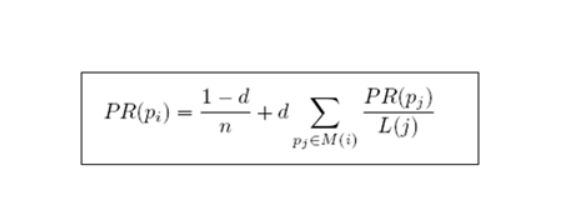
- d:����ϵ����>����ֵ0.85
- M(i):ָ��i��ҳ�漯��---->��Ӧ����ҳ�漯��
- L(j):ҳ��ij�����---->��Ӧ����ҳ�漯���C>������String[] adjacentNodeNames ����������
- PR(pj):jҳ���PRֵ�C>����ֵ
- n:����ҳ������>���е�ҳ��
�㷨ȱ��
- ��һ,û������վ�ڵ������ӡ��ܶ���վ����ҳ���кܶ��վ������ҳ�������,��Ϊվ�ڵ������ӡ���Щ�����벻ͬ��վ֮����������,�϶��Ǻ��߸�������PageRankֵ�Ĵ��ݹ�ϵ��
- �ڶ�,û�й��˹�����Ӻ������ӡ���Щ����ͨ��û��ʲôʵ�ʼ�ֵ,ǰ�����ӵ����ҳ��,���߳������ӵ�ij���罻��վ��ҳ��
- ����,������ҳ���Ѻá�һ������ҳ��һ��������Խ���,��ʹ�������ݵ������ܸ�,Ҫ��Ϊһ����PRֵ��ҳ������Ҫ�ܳ�ʱ����ƹ㡣
- ���PageRank�㷨��ȱ��,���������TrustRank�㷨�������������2004��˹̹����ѧ���Ż���һ�������о�,�������������վ��TrustRank�㷨�Ĺ���ԭ��:���˹�ȥʶ���������ҳ��(�������ӡ�ҳ��),��ô�ɡ����ӡ�ҳ��ָ���ҳ��Ҳ�����Ǹ�����ҳ��,����TRֵҲ��,�롰���ӡ�ҳ�������ԽԶ,ҳ���TRֵԽ�͡������ӡ�ҳ���ѡ�������϶����ҳ,Ҳ��ѡPRֵ�ϸߵ���վ
- TrustRank�㷨����ÿ����ҳ��TRֵ����PRֵ��TRֵ�������,���Ը�ȷ���ж���ҳ����Ҫ�ԡ�
�����о�
-
a b d b c c a b d b c a 1.0 b d b 1.0 c c 1.0 a b d 1.0 b c a 0.5 b d b 1.5 c c 1.5 a b d 0.5 b c a 0. b d b 1.25 c c 1.75 a b d 0.25 b c
ִ�����̷���:
a 1 b d
b 1 c
c 1 a b
d 1 b c
��ʼ���в��
--------> Map
a 1 b d
b 0.5
d 0.5
b 1 c
c 1
c 1 a b
a 0.5
b 0.5
d 1 b c
b 0.5
c 0.5
--------->Reduce��һ�ι�Լ���
a 0.5 b d
b 1.5 c
c 1.5 a b
d 0.5 b c
---------------->Map�ڶ���.....
����
1. �㷨���̷���
- ����ÿ����վĬ�ϵ�Ȩ����һ����(ʮ����,�ٷ���)����Ĭ�ϳ�ʼֵ1.0
- Ȼ����վ��Ȩ��ƽ�ָ���ǰ��վ�����г���( 10 / 5 = 2 )
- ���һ����վ�ж������,�ͽ��������е������÷��ۼӵ�һ��(2+4+7+1+10=24��)
- ��ô���εĵ÷ֻ����ڼ����´γ����ļ��� (24/5 = 4.8)
- �ظ���������Ĺ���,�����ﵽһ������ֵ
2. ������
����Ĭ�������,ÿ����վ��1�ֵķ�ֵ��Щ��ֵĬ��ƽ�ָ����еij���,�����е���վ������ƽ��֮��,��ʼ���㱾��վ���е�������ֵ;������ֵ֮�;����´ε���վ�ķ�����
- ���������� ��Щ��վû�г�����������ÿ�μ��㶼�ڼ���
-
�������� ��ֹ�Լ��ķ����˷�,�� ��ֵ�����Է���
�������:
-
��������ϵ������ֹ��������� d = 0.85���м�������ս��������������һ�� ������1.99%
-
���е���վ�IJ�ֵ������ 0.0001
-
3. ��������ϵ�����������Prֵ
����PageRank���㹫ʽ:
-
��������ϵ��(damping factor)d=0.85
-
�µ�PR��ʽ
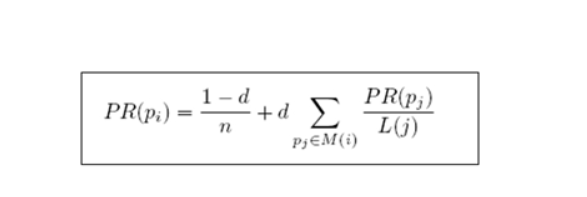
- d:����ϵ����>����ֵ0.85
- M(i):ָ��i��ҳ�漯��---->��Ӧ����ҳ�漯��
- L(j):ҳ��ij�����---->��Ӧ����ҳ�漯���C>������String[] adjacentNodeNames ����������
- PR(pj):jҳ���PRֵ�C>ÿһ�ֵ�PRֵ�������㶼��ȷ������ֵ
- n:����ҳ������>���е�ҳ��
4. ˼·����:
����һ��PageNode��,���ڷ�װҳ�� PR�Ͷ�Ӧ�ij�����ַ;����һ������,���ݴ���� prֵ + �����ַ���,����ת��Node����ȷ��Map��key��value;�ж��Ƿ�Ϊ��һ�μ���,�����ݷ�װ��һ������{pr,������};�����ϵ�prֵ�Ͷ�Ӧ��ҳ���ϵ
���� a 0.75 b d ��Ӧ�ij�����prֵ
key�C> a value�C> 0.75 b d ;��ȷ��key��value��ʼMap�β��,�жϽڵ�����Ƿ��г���,����оͼ��㡣��ʼ����ÿ���ڵ㱾��Ӧ�õ�prֵ;ÿ���ڵ��pr=��ǰҳ��ڵ�pr/������������Reducer�θ�������Ĺ�ʽ���м���,��Լ������ս������Job���ж��Ƿ�ﵽ����ֵ,�ﵽ���������˳���ѭ����
�����ʵ��
����һ��ö�����ڱ�����������ֵ
public enum MyCounter {
//���ÿ�����ݼ��������ֵ֮��
CONVERGENCESUM
}
����һ��PageNode��,���ڷ�װҳ�� PR�Ͷ�Ӧ�ij�����ַ
import org.apache.commons.lang.StringUtils;
import java.io.IOException;
import java.util.Arrays;
/**
* a 1.0 b d
* ��װҳ�� PR�Ͷ�Ӧ�ij�����ַ
* pageRank
* String[] adjacentNodeNames ����������
*/
public class PageNode {
//ҳ��Ȩ��ֵ
private double pageRank = 1.0;
//�����Ľڵ�����
private String[] adjacentNodeNames;
//�ָ���
public static final char fieldSeparator = '\t';
/**
* �жϵ�ǰ�ڵ��Ƿ����������վ
*
* @return
*/
public boolean containsAdjacentNodes() {
return adjacentNodeNames != null && adjacentNodeNames.length > 0;
}
/**
* ���ݴ���� pr + �����ַ���,����ת��Node����
*
* @param value 0.3 B D
* @return
* @throws IOException
*/
public static PageNode fromMR(String value) throws IOException {
//���շָ����з�����
String[] parts = StringUtils.splitPreserveAllTokens(value, fieldSeparator);
//����зֺ�С��һ��,˵������PRֵ��ӳ���ϵ
if (parts.length < 1) {
throw new IOException("Expected 1 or more parts but received " + parts.length);
}
//�����ڵ����
// Double.valueOf(parts[0])-->��Ӧ����valueֵ��0�±�
// ����:a 1.0 b d---��KeyValueTextInputFormat�Ὣ��ֳ�������,��һ�ж�Ӧ��key,��ߵIJ��ֶ�Ӧ����value
PageNode node = new PageNode().setPageRank(Double.valueOf(parts[0]));
//�������1˵�����ӽڵ�,���� a 1.0 parts���鳤�Ȳ�����1˵��ֻ�нڵ��Ȩ��ֵû�г���
if (parts.length > 1) {
node.setAdjacentNodeNames(Arrays.copyOfRange(parts, 1, parts.length));
}
//���ؽڵ�
return node;
}
public static PageNode fromMR(String v1, String v2) throws IOException {
//a 1 b d
return fromMR(v1 + fieldSeparator + v2);
}
public double getPageRank() {
return pageRank;
}
public PageNode setPageRank(double pageRank) {
this.pageRank = pageRank;
return this;
}
public String[] getAdjacentNodeNames() {
return adjacentNodeNames;
}
public PageNode setAdjacentNodeNames(String[] adjacentNodeNames) {
this.adjacentNodeNames = adjacentNodeNames;
return this;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(pageRank);
if (getAdjacentNodeNames() != null) {
sb.append(fieldSeparator).append(StringUtils.join(getAdjacentNodeNames(), fieldSeparator));
}
return sb.toString();
}
}
����PageRankJob��
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageRankJob {
//������ָ��
private static double convergence = 0.0001;
public static void main(String[] args) {
//��ȡ�����ļ�
Configuration configuration = new Configuration(true);
//��ƽִ̨��
configuration.set("mapreduce.app-submission.cross-platform", "true");
configuration.set("mapreduce.framework.name", "local");
//������������Ĵ���
int runCount = 0;
//��ʼִ�е�������
while (true) {
//�����ۼ�
runCount++;
try {
//�������ļ�������һ������
configuration.setInt("runCount", runCount);
//��ȡ�ֲ�ʽ�ļ�ϵͳ
FileSystem fs = FileSystem.get(configuration);
//����JOB,�����û�����Ϣ
Job job = Job.getInstance(configuration);
job.setJarByClass(PageRankJob.class);
job.setJobName("pagerank-" + runCount);
//����Mapper���������
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//����Mapper��Reducer
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
//ʹ�����µ������ʽ����
job.setInputFormatClass(KeyValueTextInputFormat.class);
//���ö�ȡ���ݵ�·��(��һ��)
Path inputPath = new Path("/yjxxt/pagerank/input/");
//�ڶ���֮���ȡ����,����ǰһ�εĽ��
if (runCount > 1) {
inputPath = new Path("/yjxxt/pagerank/output/pr" + (runCount - 1));
}
//��ȡ���ݵ�·��
FileInputFormat.addInputPath(job, inputPath);
//�������·��
Path outpath = new Path("/yjxxt/pagerank/output/pr" + runCount);
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
//�������·��
FileOutputFormat.setOutputPath(job, outpath);
//�ύ����,����ȡ���������Ƿ�ɹ�
boolean flag = job.waitForCompletion(true);
if (flag) {
System.out.println("--------------------------success." + runCount);
//����ֵ�ĺ�
long sum = job.getCounters().findCounter(MyCounter.CONVERGENCESUM).getValue();
double avgConvergence = sum / 40000.0;
//���ƽ��ֵ�ﵽ����ָ��,ֹͣѭ��
if (avgConvergence < convergence) {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
����һ��PageRankMapper��
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* ��һ�� a b d
* key a
* value b d
* �ڶ��� a 0.75 b d
* key a
* value 0.75 b d
*
* @author Administrator
*/
public class PageRankMapper extends Mapper<Text, Text, Text, Text> {
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
//����ǵ�һ�ζ�ȡ�ļ�,��ô��Ҫ��PR����Ĭ��ֵ1
int runCount = context.getConfiguration().getInt("runCount", 1);
//�Կո��зֵ�ǰ��,��һ���ո�ǰΪKEY,��������ΪValue
String page = key.toString();
//�������Node
PageNode node = null;
//�ж��Ƿ�Ϊ��һ�μ���,�����ݷ�װ��һ������{pr,������}
if (runCount == 1) {
node = PageNode.fromMR("1.0", value.toString());
} else {
node = PageNode.fromMR(value.toString());
}
//�����ϵ�prֵ�Ͷ�Ӧ��ҳ���ϵ key--> a value--> 0.75 b d
context.write(new Text(page), new Text(node.toString()));
//��ʼ����ÿ���ڵ㱾��Ӧ�õ�prֵ
if (node.containsAdjacentNodes()) {
//ÿ���ڵ��pr=��ǰҳ��ڵ�pr/����������
double outValue = node.getPageRank() / node.getAdjacentNodeNames().length;
//��ʼд���ӽڵ��prֵ
for (int i = 0; i < node.getAdjacentNodeNames().length; i++) {
String outPage = node.getAdjacentNodeNames()[i];
//ҳ��AͶ��˭,˭��Ϊkey,val��Ʊ��ֵ,Ʊ��ֵΪ:ÿ���ڵ��pr
context.write(new Text(outPage), new Text(outValue + ""));
}
}
}
}
����һ��PageRankReducer��
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Administrator
* //ҳ���Ӧ��ϵ���ϵ�prֵ
* //a 1.0 b d
* //�µ�ͶƱֵ
* //a 0.5
* //����д���Ľ��
* //a 0.5 c
* //����������ֵ 0.5-1.0= -0.5
*/
public class PageRankReducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> iterable, Context context) throws IOException, InterruptedException {
//�����������µ�PRֵ(����֮ǰ)
double sum = 0.0;
//��ȡԭ���Ľڵ�
PageNode sourceNode = null;
for (Text i : iterable) {
//�����µĽڵ�
PageNode node = PageNode.fromMR(i.toString());
//�ж����ϵ�ӳ���ϵ�����µ�PRֵ
if (node.containsAdjacentNodes()) {//�ϵİ�������
sourceNode = node;
} else {
sum = sum + node.getPageRank();//������µľ����prֵ
}
}
// ��������ϵ��Ϊ���¼���PRֵ
double newPR = (0.15 / 4.0) + (0.85 * sum);
System.out.println(key + "*********** new pageRank value is " + newPR);
//���µ�prֵ�ͼ���֮ǰ��pr�Ƚ�(��ȡ����ֵ)
double d = newPR - sourceNode.getPageRank();//�����ֵ
//������λ��Ч����,Ȼ��ȡ����ֵ,jΪ����ֵ
int j = Math.abs((int) (d * 1000.0));
context.getCounter(MyCounter.CONVERGENCESUM).increment(j);
//����ǰ��վ��PRֵд��
sourceNode.setPageRank(newPR);
context.write(key, new Text(sourceNode.toString()));
}
}