1. 背景
运维调研图数据库差不多有半年多了,试用了Neo4j和Nebula,Nebula因其免费、开源的分布式支持成为了最终的图数据库选型确定的方案。在测试环境积累了一定的运维经验后,需要应用在真实的业务场景中。搜索推荐要引入个性化推荐(在此之前主要基于Query搜索词扩展推荐),离线算法召回结果需要一个能够支撑亿级数据规模的存储引擎,之前的首页个性化推荐召回存储方案经历了HBase -> Cassandra的变迁,但目前看来,Cassandra的稳定性和数据读取性能并不是太如人意,因此调研通过Nebula存储用户离线个性化召回集
2. 数据建模
- 实体
- 用户 user
- 商品 product
- 类目 taxcate
- 搜索词 query
- 关系
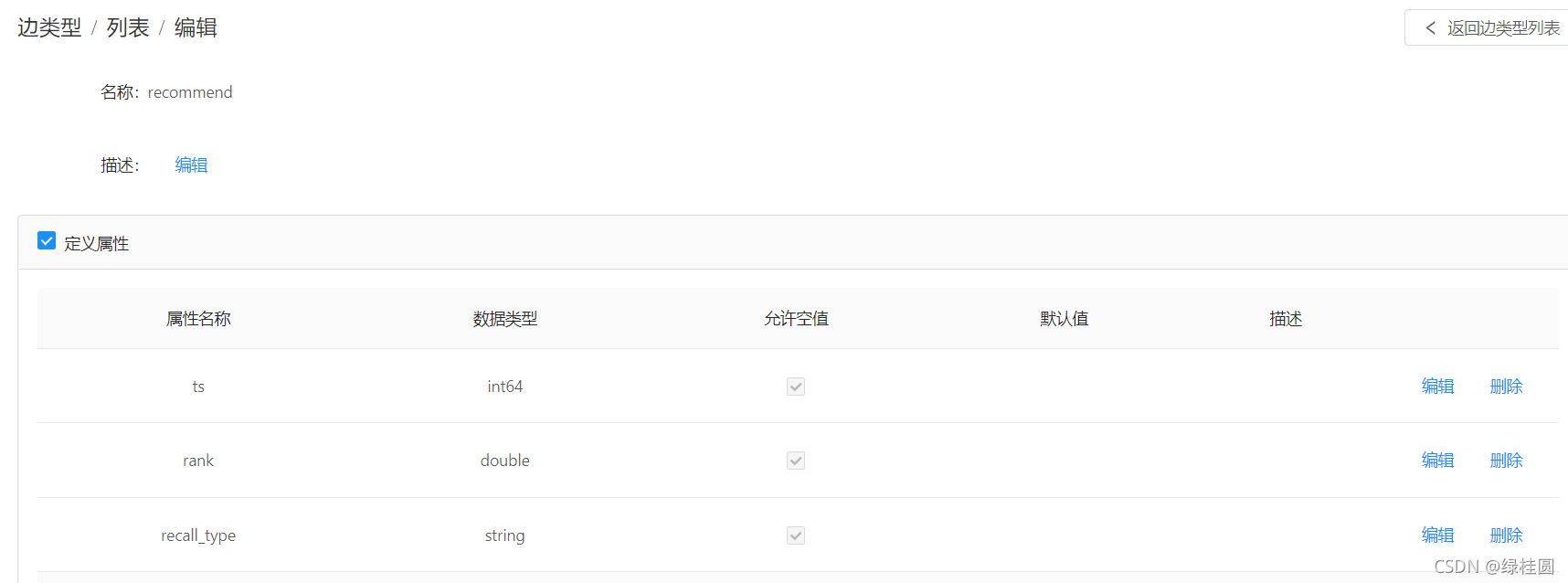
- 推荐 recommend
- 商品类目 product_taxcate
“商品类目”作为一种关系可能会让人感到不解,之所以这样设计主要考虑是类目不仅可以和商品关联,还可以跟搜索词、用户关联,因此类目应该作为一个单独的实体类别,通过关系和其他实体进行关联。另外因为需要区分商品的召回来源,因此recommend添加了recall_type的属性:
3. 数据导入
采用官方推荐的nebula-spark-connector进行导入,但目前发现有一个问题,数据量在亿的时候,很容易就把机器16G的内存吃死了,storaged进程挂掉,其中的关键问题在于:为何内存占用会不断增加?nebula的compact机制是怎样的?这些问题还有待解决,主要是运维那边在跟
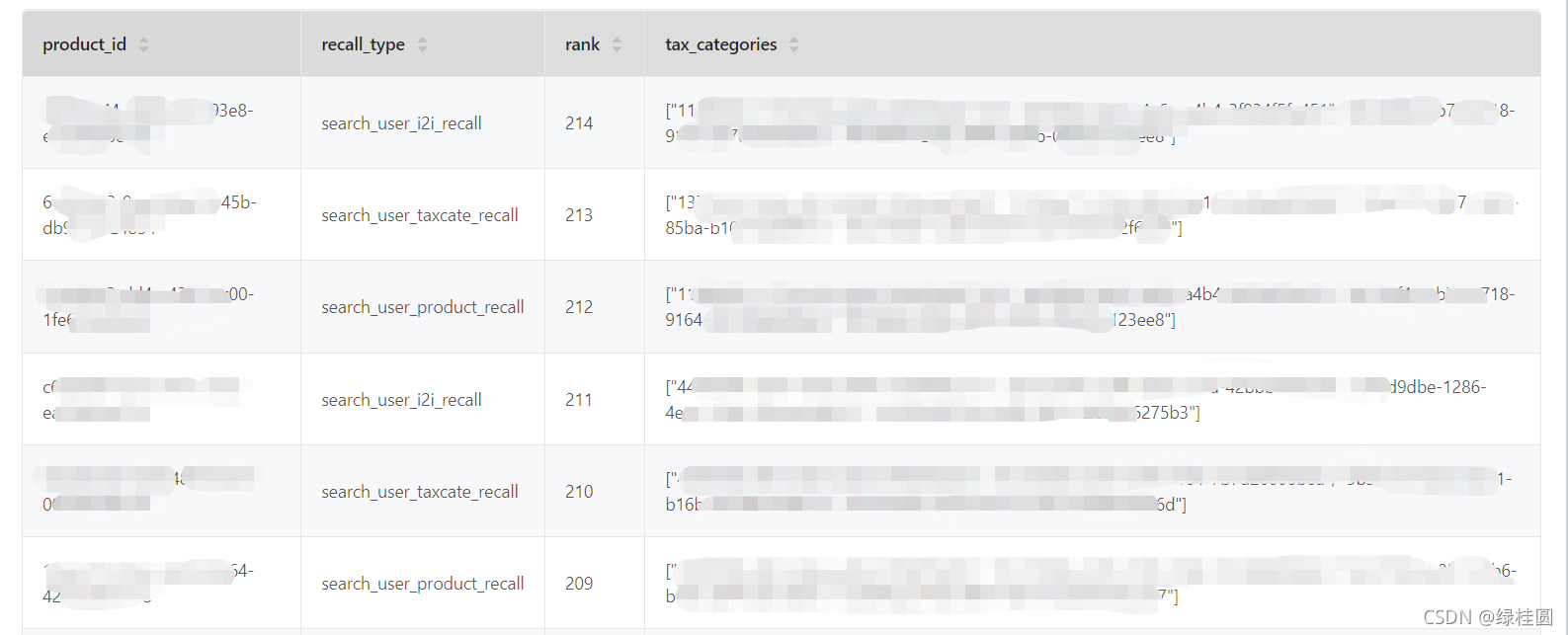
4. 结果展示

5. 在线应用
主要是根据user_id查询个性化召回商品集合,查询语句如下:
go from "某个user_id" over recommend yield recommend._dst as pid, recommend.rank as rank, recommend.recall_type as recall_type |
go from $-.pid over product_taxcate yield $-.pid as pid, $-.recall_type as recall_type, $-.rank as rank, product_taxcate._dst as taxcate |group by $-.pid, $-.recall_type, $-.rank yield $-.pid as product_id, $-.recall_type as recall_type, $-.rank as rank, collect($-.taxcate) as tax_categories |
order by $-.rank desc