?Map阶段
?下图为Map阶段详细的工作流程

-
待处理文本:如 /opt/data/input.txt
-
根据参数配置,分配一个作业(Job)
-
提交切片信息:Job.split、wc.jar、Job.xml
-
计算出MapTask数量
-
当实例化一个maptask后,创建TextInputFormat,调用里面的RecoreReader方法将切片读取封装成(k,v)传送给Mapper
-
每输入一次(k,v)Mapper会执行一次map(k,v)方法
-
当调用了context.write()方法时,此时会初始化一个outputCollector对象将map输出的key,value收集到缓冲区(MapOutBuffer)中
-
当从缓冲区溢写到文件之前,会以分区为单位对区内的数据进行快速排序
-
此时将环形缓冲区的数据溢写到文件(分区且区内有效)
-
对所有溢写的文件进行Merge归并排序,此时一个maptask结束
Reduce阶段
下图为Reduce阶段详细的工作流程
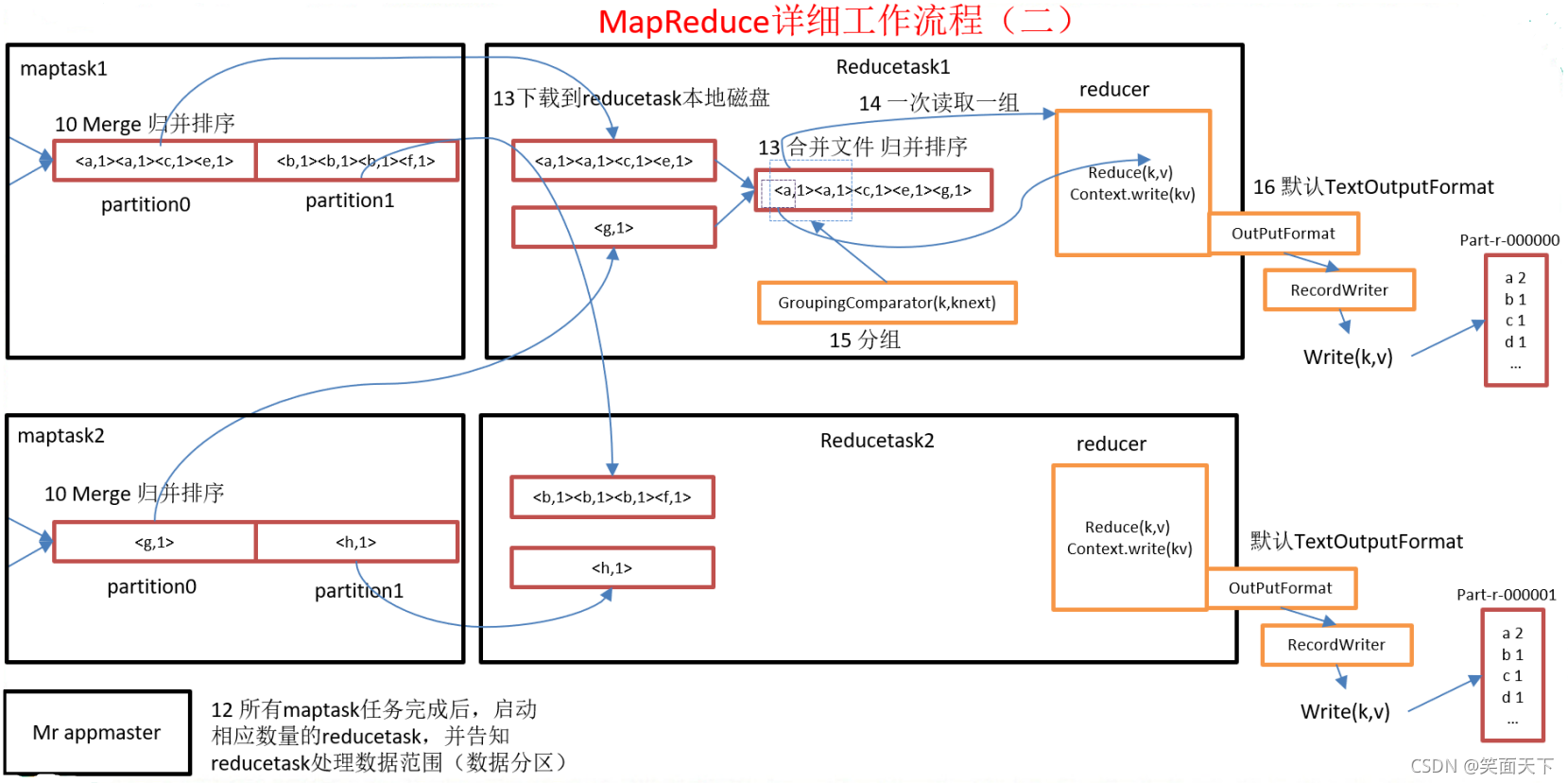
- 所有maptask任务完成后,启动相应数量的reducetask,并告知reducetask处理数据的范围(也就是管哪个分区)
- 启动shuffle线程通过网络I/O将数据拷贝到内存中合并,此时如果数据量太大或者shuffle线程不够的话它也会先进行combiner合并一部分溢写到磁盘,最后全部下载到reducetask本地磁盘
- 对每个map来的数据并归排序,让其所有数据整体有序
- 按照相同key进行分组(GroupingComparator(k,knext))
- 使用分组比较器对(key,value)进行迭代,一次读入一组进入reducer(k,v)
- 创建TextOutputFormat对象,调用里面的RecoreWriter方法对数据进行写出