大家好,我是土哥。
今天,有位Flink初学者问我有没有Flink的安装教程,看到这后,土哥二话不说直接安排上。
以下教程全部使用 Flink1.13.2版本,在普通用户下面部署:
1、Standalone部署
版本要求:
| 版本 | 节点 | 部署方式 |
|---|---|---|
| flink-1.13.2-bin-scala_2.11.tgz | 192.168.244.129 | standalone |
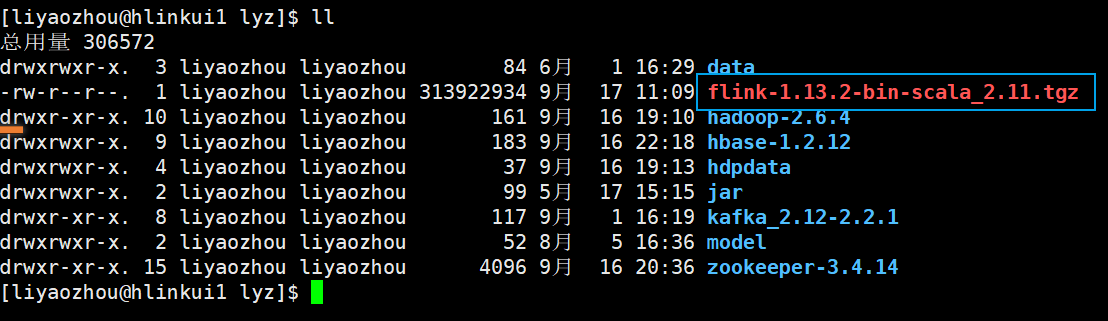
1.1 将软件安装包放入集群中
1.2、软件包解压
tar -zxvf flink-1.13.2-bin-scala_2.11.tgz

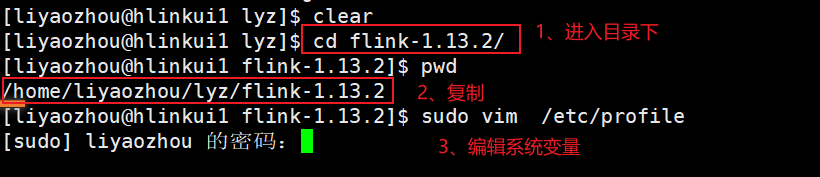
1.3、 配置系统环境变量
# 1、进入目录下
cd flink-1.13.2/
# 2、查看完整classpsth,然后复制
pwd
# 3、编辑系统变量
sudo vim /etc/profile
#4、配置变量环境
export FLINK_HOME=/home/liyaozhou/lyz/flink-1.13.2
export PATH=$PATH:$FLINK_HOME/bin
#5 刷新系统变量环境
source /etc/profile
#6 查看是否配置成功
$FLINK_HOME


1.4、配置Flink conf文件
进入到flink-1.13.2/conf目录下
1.4.1 配置flink-conf.yaml
#1. 配置jobmanager rpc 地址
jobmanager.rpc.address: 192.168.244.129
#2. 修改taskmanager内存大小,可改可不改
taskmanager.memory.process.size: 2048m
#3. 修改一个taskmanager中对于的taskslot个数,可改可不改
taskmanager.numberOfTaskSlots: 4
#修改并行度,可改可不改
parallelism.default: 4

1.4.2 配置master
#修改主节点ip地址
192.168.244.129:8081
1.4.3 配置work
#修改从节点ip,因为是standalone,所有主从一样
192.168.244.129
1.4.4 配置zoo
# 新建snapshot存放的目录,在flink-1.13.2目录下建
mkdir tmp
cd tmp
mkdir zookeeper
#修改conf下zoo.cfg配置
vim zoo.cfg
#snapshot存放的目录
dataDir=/home/liyaozhou/lyz/flink-1.13.2/tmp/zookeeper
#配置zookeeper 地址
server.1=192.168.244.129:2888:3888

1.5、启动Flink 集群
进入flink-1.13.2/bin目录下
./start-cluster.sh


2、Standalone-HA集群部署
集群部署两节点
| 版本 | 主节点 | 从节点 | 部署方式 |
|---|---|---|---|
| flink-1.13.2-bin-scala_2.11.tgz | 192.168.244.129 | 192.168.244.130 | standalone-HA |
| hadoop 2.6.4 | 192.168.244.129 | 192.168.244.130 | Distributed |
| zookeeper3.4.14 | 192.168.244.129 | 192.168.244.130 | Distributed |
前提是zookeeper 和 hadoop 集群全部配置好
2.1、 将软件安装包放入集群中

2.2、软件包解压
tar -zxvf flink-1.13.2-bin-scala_2.11.tgz

2.3、 配置系统环境变量
# 1、进入目录下
cd flink-1.13.2/
# 2、查看完整classpsth,然后复制
pwd
# 3、编辑系统变量
sudo vim /etc/profile
#4、配置变量环境
export FLINK_HOME=/home/liyaozhou/lyz/flink-1.13.2
export PATH=$PATH:$FLINK_HOME/bin
#5、添加hadoop_conf classpath
export HADOOP_CONF_DIR=/home/liyaozhou/lyz/hadoop-2.6.4/etc/hadoop
#6 刷新系统变量环境
source /etc/profile
#7 查看是否配置成功
$FLINK_HOME



2.4、配置Flink conf文件
进入到flink-1.13.2/conf目录下
2.4.1 配置flink-conf.yaml
#1. 配置jobmanager rpc 地址
jobmanager.rpc.address: 192.168.244.129
#2. 修改taskmanager内存大小,可改可不改
taskmanager.memory.process.size: 2048m
#3. 修改一个taskmanager中对于的taskslot个数,可改可不改
taskmanager.numberOfTaskSlots: 4
#4. 修改并行度,可改可不改
parallelism.default: 4
#5. 配置状态后端存储方式
state.backend:filesystem
#6. 配置启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://192.168.244.129:9000/flink-checkpoints
#7. 配置保存点,可以将快照保存到HDFS
state.savepoints.dir: hdfs://192.168.244.129:9000/flink-savepoints
#8. 使用zookeeper搭建高可用
high-availability: zookeeper
#9. 配置ZK集群地址
high-availability.zookeeper.quorum: 192.168.244.129:2181
#10. 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://192.168.244.129:9000/flink/ha/
#11. 配置zookeeper client默认是 open,如果 zookeeper security 启用了更改成 creator
high-availability.zookeeper.client.acl: open


2.4.2 配置master
#修改主节点ip地址
192.168.244.129:8081
2.4.3 配置work
#修改从节点ip,因为是standalone-ha,改另一个节点
192.168.244.130
2.4.4 配置zoo
# 新建snapshot存放的目录,在flink-1.13.2目录下建
mkdir tmp
cd tmp
mkdir zookeeper
#修改conf下zoo.cfg配置
vim zoo.cfg
#snapshot存放的目录
dataDir=/home/liyaozhou/lyz/flink-1.13.2/tmp/zookeeper
#配置zookeeper 地址
server.1=192.168.244.129:2888:3888

2.5、下载hadoop依赖包
下载地址:https://flink.apache.org/downloads.html#additional-components
将包复制到flink-1.13.2/lib目录下

2.6、 文件传输
将主节点flink包复制到从节点
scp -r flink-1.13.2 192.168.244.130:/home/liyaozhou/lyz/

修改从节点 flink-conf.yaml rpc 的ip地址

2.7、启动Flink 集群
进入flink-1.13.2/bin目录下
./start-cluster.sh


可以在登录界面看到,TaskManager的地址为192.168.244.130

3、Flink On Yarn集群部署
集群部署两节点
| 版本 | 主节点 | 从节点 | 部署方式 |
|---|---|---|---|
| flink-1.13.2-bin-scala_2.11.tgz | 192.168.244.129 | 192.168.244.130 | yarn |
| hadoop 2.6.4 | 192.168.244.129 | 192.168.244.130 | Distributed |
| zookeeper3.4.14 | 192.168.244.129 | 192.168.244.130 | Distributed |
前提是zookeeper 和 hadoop 集群全部配置好
3.1 修改Hadoop集群的yarn-site.xml文件
YARN模式下的HA需要注意一点,官方给出建议,必须要增加以下两项配置:
YARN配置,修改yarn-site.xml
<!-- master(JobManager)失败重启的最大尝试次数-->
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
<!-- 关闭yarn内存检查 -->
<!-- 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认为 true -->
<!-- 因为对于 flink 使用 yarn 模式下,很容易内存超标,这个时候 yarn 会自动杀掉 job,因此需要关掉-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
3.2 修改flink conf配置
在flink-conf.yaml中添加如下两项:
#用户提交作业失败时,重新执行次数
yarn.application-attempts: 4
#设置Task在所有节点平均分配
cluster.evenly-spread-out-slots: true

3.3 启动测试(Session模式)
3.3.1 启动 Flink 会话(在192.168.244.129上测试)
# 主节点中执行
bin/yarn-session.sh -d -jm 1024 -tm 1024 -s 1
# -tm 表示每个 TaskManager 的内存大小
# -s 表示每个 TaskManager 的 slots 数量
# -d 表示以后台程序方式运行

3.3.2 登录yarn集群页面查看
登录网址:192.168.244.129:8088/cluster

3.3.3 在yarn上提交任务 通过session模式
注意:此时提交的任务都通过该会话(Session)执行,不会再申请 yarn 资源
(1)创建一个wordcount.txt文本,随便早一些数据,然后放到flink-1.13.2下面,然后将该文件传到hdfs中
hadoop fs -copyFromLocal wordcount.txt /

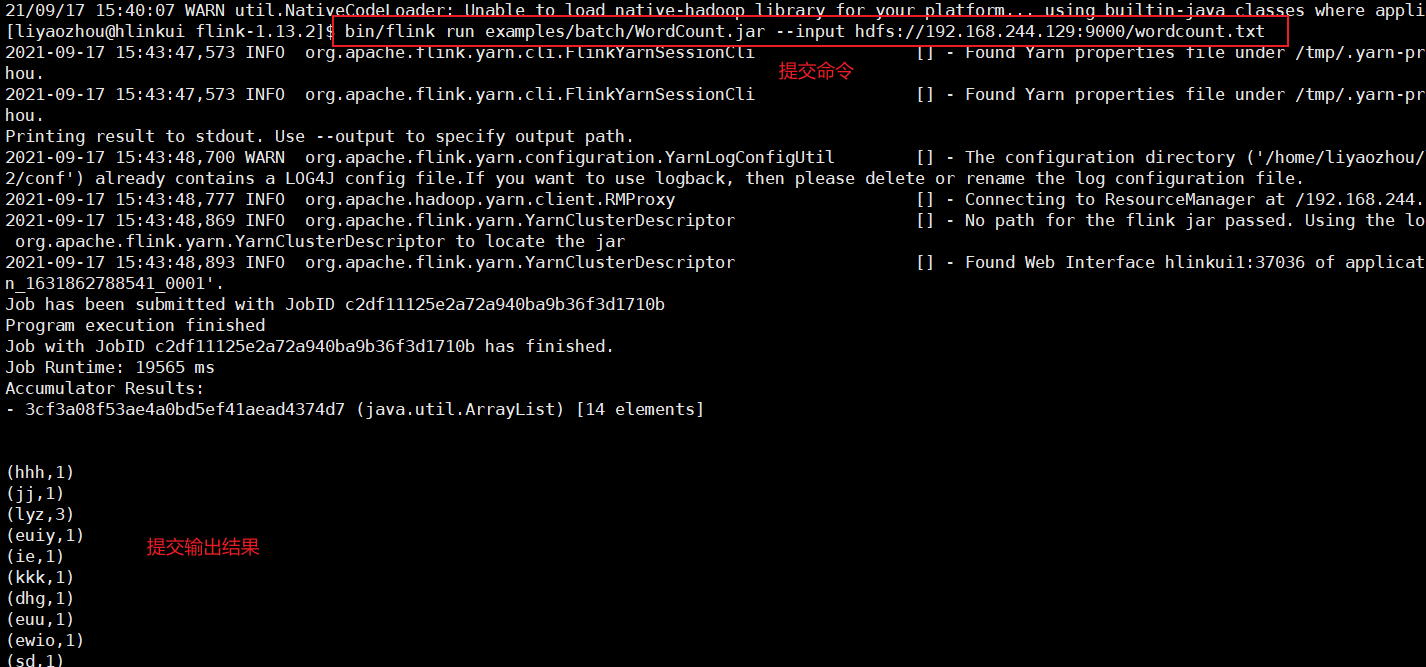
(2)提交任务
# 192.168.244.129 中执行即可
bin/flink run examples/batch/WordCount.jar --input hdfs://192.168.244.129:9000/wordcount.txt
3.3.3 查看 Hadoop 的 ApplicationManager 的 WEB-UI 页面


3.3.4 关闭Session模式
yarn application -kill application_1631862788541_0001

3.4 启动测试(Per-job模式)
3.4.1 直接提交 Job
# -m jobmanager 的地址
# -yjm 1024 指定 jobmanager 的内存信息
# -ytm 1024 指定 taskmanager 的内存信息
bin/flink run \
-t yarn-per-job -yjm 1024 -ytm 1024 \
--detached examples/batch/WordCount.jar \
--input hdfs://192.168.244.129:9000/wordcount.txt


