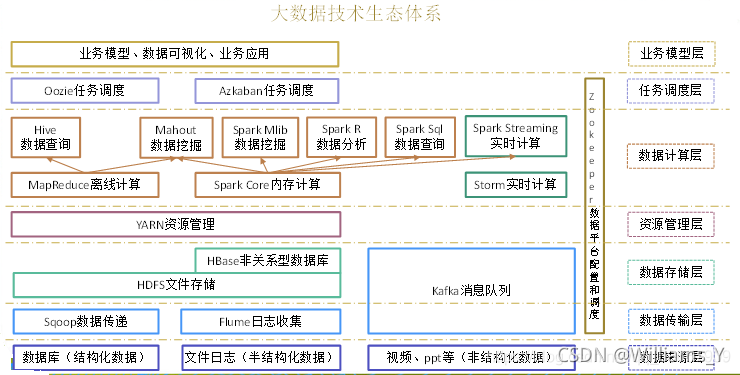
һ����Hadoop������۴�������̬
������(big data),ָ����һ��ʱ�䷶Χ���ó����������߽��в��������ʹ��������ݼ���,����Ҫ�´���ģʽ���ܾ��и�ǿ�ľ����������췢�����������Ż������ĺ������������ʺͶ���������Ϣ�ʲ���
1.1 Hadoop��ʲô
(1)Hadoop��һ����Apache������������ķֲ�ʽϵͳ�����ܹ�
(2)��Ҫ���,�������ݵĴ洢�ͺ������ݵķ����������⡣
(3)��������˵,HADOOPͨ����ָһ�����㷺�ĸ����HADOOP��̬Ȧ

1.2 Hadoop��չ��ʷ
(1)Lucene�CDoug Cutting�����Ŀ�Դ����,��java��д����,ʵ����Google���Ƶ�ȫ����������,���ṩ��ȫ�ļ�������ļܹ�,���������IJ�ѯ�������������
(2)2001����׳�Ϊapache������һ������Ŀ
(3)���ڴ������ij���,Lucene�����Googleͬ��������
(4)ѧϰ��ģ��Google�����Щ����İ취 :�Ͱ�Nutch
(5)����˵Google��hadoop��˼��֮Դ(Google�ڴ����ݷ������ƪ����)
GFS ��>HDFS
Map-Reduce ��>MR
BigTable ��>Hbase
(6)2003-2004��,Google�����˲���GFS��Mapreduce˼���ϸ��,�Դ�Ϊ����Doug Cutting��������2��ҵ��ʱ��ʵ����DFS��Mapreduce����,ʹNutch�������
(7)2005 ��Hadoop ��Ϊ Lucene������Ŀ Nutch��һ������ʽ����Apache����ᡣ2006 �� 3 �·�,Map-Reduce��Nutch Distributed File System (NDFS) �ֱ������Ϊ Hadoop ����Ŀ��
(8)������Դ��Doug Cutting���ӵ���ߴ���

(9)Hadoop�ʹ˵�����Ѹ�ٷ�չ,��־���Ƽ���ʱ������
1.3 Hadoop�����а汾
Hadoop �����а汾: Apache��Cloudera��Hortonworks
Apache�汾��ԭʼ(�����)�İ汾,��������ѧϰ��á�
Cloudera�ڴ��ͻ�������ҵ���õĽ϶ࡣ
Hortonworks�ĵ��Ϻá�
Cloudera Hadoop
(1)2008�������Cloudera�����罫Hadoop���õĹ�˾,Ϊ��������ṩHadoop�����ý������,��Ҫ�ǰ���֧�֡���ѯ������ѵ��
(2)2009��Hadoop�Ĵ�ʼ��Doug CuttingҲ����Cloudera��˾��Cloudera��Ʒ��ҪΪCDH,Cloudera Manager,Cloudera Support
(3)CDH��Cloudera��Hadoop���а�,��ȫ��Դ,��Apache Hadoop�ڼ�����,��ȫ��,�ȶ�����������ǿ��
(4)Cloudera Manager�Ǽ�Ⱥ�������ַ����������ƽ̨,�����ڼ���Сʱ�ڲ����һ��Hadoop��Ⱥ,���Լ�Ⱥ�Ľڵ㼰�������ʵʱ��ء�Cloudera Support���Ƕ�Hadoop�ļ���֧�֡�
(5)Cloudera�ı��Ϊÿ��ÿ���ڵ�4000��Ԫ��Cloudera�����������˿�ʵʱ���������ݵ�Impala��Ŀ��
Hortonworks Hadoop
(1)2011�������Hortonworks���Ż����ȷ�Ͷ��˾Benchmark Capital�����齨��
(2)��˾����֮���������˴�Լ25����30��ר���о�Hadoop���Ż�����ʦ,��������ʦ����2005�꿪ʼЭ���Ż�����Hadoop,������Hadoop80%�Ĵ��롣
(3)�Ż����̸��ܲá��Ż�Hadoop�����ŶӸ�����Eric Baldeschwieler����Hortonworks����ϯִ�й١�
(4)Hortonworks�������Ʒ��Hortonworks Data Platform(HDP),Ҳͬ����100%��Դ�IJ�Ʒ,HDP����������Ŀ�������Ambari,һ�Դ�İ�װ����ϵͳ��
(5)HCatalog,һ��Ԫ���ݹ���ϵͳ,HCatalog���Ѽ��ɵ�Facebook��Դ��Hive�С�Hortonworks��Stinger�����Եļ�����Ż���Hive��Ŀ��HortonworksΪ�����ṩ��һ���dz��õ�,����ʹ�õ�ɳ�С�
(6)Hortonworks�����˺ܶ���ǿ���Բ��ύ����������,��ʹ��Apache Hadoop�ܹ��ڰ���Window Server��Windows Azure���ڵ�microsoft Windowsƽ̨�ϱ������С������Լ�ȺΪ����,ÿ10���ڵ�ÿ��Ϊ12500��Ԫ��
1.4 Hadoop������
(1)�߿ɿ���:��ΪHadoop�������Ԫ�غʹ洢����ֹ���,��Ϊ��ά������������ݸ���,�ڳ��ֹ���ʱ���Զ�ʧ�ܵĽڵ����·ֲ�������
(2)����չ��:�ڼ�Ⱥ�������������,�ɷ������չ����ǧ�ƵĽڵ㡣
(3)��Ч��:��MapReduce��˼����,Hadoop�Dz��й�����,�Լӿ��������ٶȡ�
(4)���ݴ���:�Զ������ݸ�������,�����ܹ��Զ���ʧ�ܵ��������·��䡣
1.5 Hadoop���
(1)Hadoop HDFS:һ���߿ɿ������������ķֲ�ʽ�ļ�ϵͳ��
(2)Hadoop MapReduce:һ���ֲ�ʽ�����߲��м����ܡ�
(3)Hadoop YARN:��ҵ�����뼯Ⱥ��Դ�����Ŀ�ܡ�
(4)Hadoop Common:֧������ģ��Ĺ���ģ�顣

HDFS�ܹ�����
(1)NameNode(nn):�洢�ļ���Ԫ����,���ļ���,�ļ�Ŀ¼�ṹ,�ļ�����(����ʱ�䡢���������ļ�Ȩ��),�Լ�ÿ���ļ��Ŀ��б��Ϳ����ڵ�DataNode�ȡ�
(2)DataNode(dn):�ڱ����ļ�ϵͳ�洢�ļ�������,�Լ������ݵ�У��͡�
(3)Secondary NameNode(2nn):�������HDFS״̬�ĸ�����̨����,ÿ��һ��ʱ���ȡHDFSԪ���ݵĿ��ա�
YARN�ܹ�����
(1)ResourceManager(rm):�����ͻ�����������/���ApplicationMaster�����NodeManager����Դ���������;
(2)NodeManager(nm):�����ڵ��ϵ���Դ��������������ResourceManager�������������ApplicationMaster������;
(3)ApplicationMaster:�����з֡�ΪӦ�ó���������Դ,��������ڲ��������������ݴ���
(4)Container:���������л����ij���,��װ��CPU���ڴ�ȶ�ά��Դ�Լ������������������������������ص���Ϣ��
MapReduce�ܹ�����
MapReduce��������̷�Ϊ������:Map��Reduce
(1)Map�β��д�����������
(2)Reduce�ζ�Map������л���
1.6 ��������̬��ϵ
(1)Sqoop:Sqoop��һ�Դ�Ĺ���,��Ҫ������Hadoop��Hive�봫ͳ�����ݿ�(MySql)��������ݵĴ���,���Խ�һ����ϵ�����ݿ�(���� :MySQL,Oracle ��)�е����ݵ�����Hadoop��HDFS��,Ҳ���Խ�HDFS�����ݵ�������ϵ�����ݿ��С�
(2)Flume:Flume��Cloudera�ṩ��һ���߿��õ�,�߿ɿ���,�ֲ�ʽ�ĺ�����־�ɼ����ۺϺʹ����ϵͳ,Flume֧������־ϵͳ�ж��Ƹ������ݷ��ͷ�,�����ռ�����;ͬʱ,Flume�ṩ�����ݽ��м���,��д���������ݽ��ܷ�(�ɶ���)��������
(3)Kafka:Kafka��һ�ָ��������ķֲ�ʽ����������Ϣϵͳ,����������:
ͨ��O(1)�Ĵ������ݽṹ�ṩ��Ϣ�ij־û�,���ֽṹ���ڼ�ʹ����TB����Ϣ�洢Ҳ�ܹ����ֳ�ʱ����ȶ����ܡ�
��������:��ʹ�Ƿdz���ͨ��Ӳ��KafkaҲ����֧��ÿ�����������Ϣ��
֧��ͨ��Kafka�����������ѻ���Ⱥ��������Ϣ��
֧��Hadoop�������ݼ��ء�
(4)Storm:Storm���ڡ��������㡱,����������������ѯ,�ڼ���ʱ�ͽ������������ʽ������û���
(5)Spark:Spark�ǵ�ǰ�����еĿ�Դ�������ڴ�����ܡ����Ի���Hadoop�ϴ洢�Ĵ����ݽ��м��㡣
(6)Oozie:Oozie��һ������Hdoop��ҵ(job)�Ĺ������̵��ȹ���ϵͳ��
(7)Hbase:HBase��һ���ֲ�ʽ�ġ������еĿ�Դ���ݿ⡣HBase��ͬ��һ��Ĺ�ϵ���ݿ�,����һ���ʺ��ڷǽṹ�����ݴ洢�����ݿ⡣
(8)Hive:Hive�ǻ���Hadoop��һ�����ݲֿ��,���Խ��ṹ���������ļ�ӳ��Ϊһ�����ݿ��,���ṩ��SQL��ѯ����,���Խ�SQL���ת��ΪMapReduce����������С� ���ŵ���ѧϰ�ɱ���,����ͨ����SQL������ʵ�ּ�MapReduceͳ��,���ؿ���ר�ŵ�MapReduceӦ��,ʮ���ʺ����ݲֿ��ͳ�Ʒ�����
(9)R����:R������ͳ�Ʒ�������ͼ�����ԺͲ���������R������GNUϵͳ��һ�����ɡ���ѡ�Դ���뿪�ŵ�����,����һ������ͳ�Ƽ����ͳ����ͼ�����㹤�ߡ�
(10)Mahout:Apache Mahout�Ǹ�����չ�Ļ���ѧϰ�������ھ�⡣
(11)ZooKeeper:Zookeeper��Google��Chubbyһ����Դ��ʵ�֡�����һ����Դ��ͷֲ�ʽϵͳ�Ŀɿ�Э��ϵͳ,�ṩ�Ĺ��ܰ���:����ά�������ַ��� �ֲ�ʽͬ���������ȡ�ZooKeeper��Ŀ����Ƿ�װ�ø����׳����Ĺؼ�����,�������õĽӿں����ܸ�Ч�������ȶ���ϵͳ�ṩ���û���
����Hadoop��������
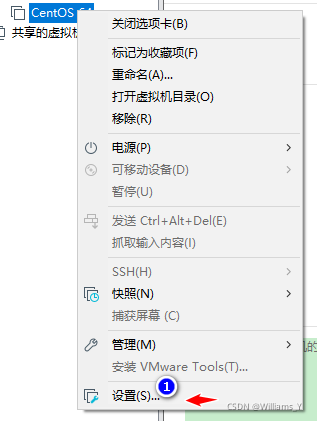
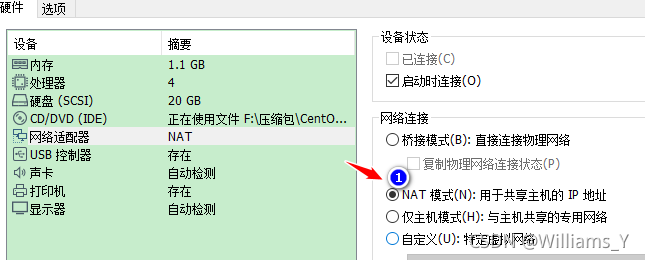
2.1 ���������ģʽ����ΪNAT(��̬ģʽ)
�������������,��ο����²���
����������
��װ�����,��ο����²���
����������
����½��õ�������Ҽ�:
2.2 �ľ�̬IP
(1)�鿴���ص�ַ
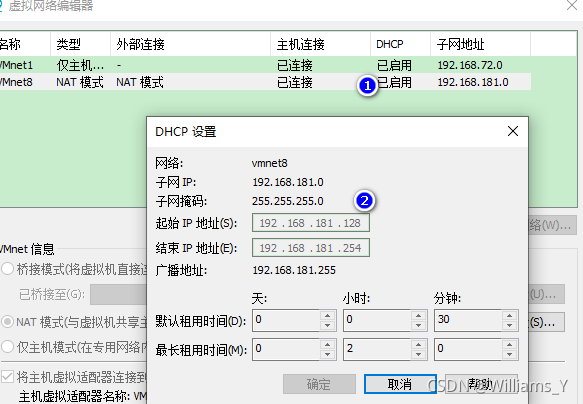
(2)��ip��ַ
��¼��Linux,ִ������(ifcfg-eno16777736�ǵ�ǰ���������������)
vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
��������5������:
IPADDR=192.168.181.150
NETMASK=255.255.255.0
GATEWAY=192.168.181.2
ONBOOT=yes
BOOTPROTO=static
DNS1=192.168.181.2
�����Լ������ؽ�������
û����ǰ:
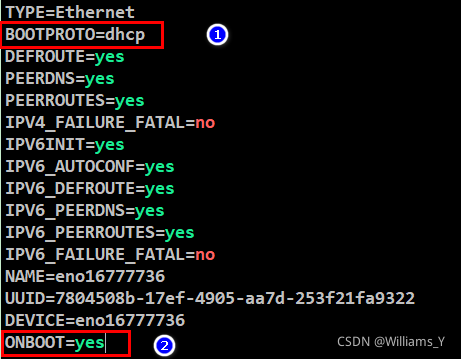
�ĺ�:

��Ees���˳��༭ģʽ,�� :wq �����˳�
(3)������������
ִ������
service network restart
2.3 ��ӳ����������host�ļ�
���ǿ��Խ����ġ�ͨ���༭/etc/hosts�ļ�
ִ������
vi /etc/hosts

2.4 �رշ���ǽ
�رշ���ǽ(CentOS7��)
ִ������رշ���ǽ
systemctl stop firewalld.service
ִ�������ֹ�������÷���ǽ
systemctl disable firewalld.service
2.5 �ϴ��ļ���Ҫ�ļ�
���뵽/Ŀ¼��,��������Ŀ¼
ִ��������ϴ���װ���ļ���Ŀ¼
mkdir /tools
ִ���������ѹ����Ŀ¼
mkdir /training
���MobaXterm���ߵ���߲˵�,�����Windowsһ��,����ϴ��İ�ť
MobaXtermԶ�̵�¼���߲ο����²���
����������
����Ҫ�Ĺ��߽����ϴ���toolsĿ¼��

2.6 ��װJDK
���ϴ���toolsĿ¼�µ�JDK���н�ѹ
ִ�������ѹ
tar -zvxf /tools/jdk-8u171-linux-x64.tar.gz -C /training/
���û�������:
ִ������
vi ~/.bash_profile
����JDK�Ļ�������,����������Ϣ
export JAVA_HOME=/training/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin

ִ�������û���������Ч
source ~/.bash_profile
ִ��������֤jdk�Ƿ�װ�ɹ�
java -version

2.7 ��װHadoop
���ϴ���toolsĿ¼�µ�Hadoop���н�ѹ
ִ�������ѹHadoop
tar -zvxf /tools/hadoop-2.7.3.tar.gz -C /training
���û�������:
ִ������
vi ~/.bash_profile
����Hadoop��������,����������Ϣ
export HADOOP_HOME=/training/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

ִ�������û���������Ч
source ~/.bash_profile
����Hadoop����ģʽ
(1)�ٷ���ַ
- �ٷ���վ
http://hadoop.apache.org/ - �����汾�鵵���ַ
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/ - hadoop2.7.2�汾�������
http://hadoop.apache.org/docs/r2.7.3/
(2)Hadoop����ģʽ - ����ģʽ(Ĭ��ģʽ)
����Ҫ���õ�������,ֱ�ӿ�������,���ԺͿ���ʱʹ�� - α�ֲ�ʽģʽ
��ͬ����ȫ�ֲ�ʽ,ֻ��һ���ڵ� - ��ȫ�ֲ�ʽģʽ
����ڵ�һ������
3.1 ����ģʽ��������
�ص�:û��HDFS,ֻ�ܽ���MapReduce����,����ֻ����Linux�ϵ��ļ�
���뵽hadoop��װ��Ŀ¼��/training/hadoop-2.7.3/etc/hadoop
ִ������
vi hadoop-env.sh
��Java��������(��������ԭ�ļ��е�λ�����и�����)
export JAVA_HOME=/training/jdk1.8.0_171

���沢�˳�
3.1.1 �ٷ�Grep����
��/���洴��һ��/demo/inputĿ¼,ִ������
mkdir /demo/input
��Hadoop��xml�����ļ����Ƶ�input,ִ������
cp /training/hadoop-2.7.3/etc/hadoop/*.xml /demo/input
���뵽:cd /training/hadoop-2.7.3/share/hadoop/mapreduce/Ŀ¼��
ִ������
hadoop jar hadoop-mapreduce-examples-2.7.3.jar grep /demo/input /demo/output 'dfs[a-z.]+'

ע��:~/demo/output ����Ҫ���ȴ���,���ڻᱨ��
���뵽/demo/output�²鿴���,ִ������
cat /demo/output

3.1.2 �ٷ�wordcount����
����ǰ��Ҫ��������Ŀ¼�Ͳ����ļ�
vi /demo/input/test.txt
������������:
I love Guiyang
I love Guizhou
Guiyang is the capital of Guizhou
���뵽:cd /training/hadoop-2.7.3/share/hadoop/mapreduce/Ŀ¼��
ִ������
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /demo/input/test.txt /demo/output

ע��:~/demo/output ����Ҫ���ȴ���,���ڻᱨ��
�鿴���:
MapReduce�����ִ�н����Ĭ�ϰ���Ӣ�ĵ��ʵ��ֵ�˳�����������

3.2 α�ֲ�ģʽ
�ص�:�߱�HDFSȫ������
HDFS:NameNode + DataNode
Yarn:ReourceManager + NodeManager
1)����
(1)��1̨�ͻ���
(2)��װjdk
(3)���û�������
(4)��װhadoop
(5)���û�������
(6)���ü�Ⱥ
(7)���������Լ�Ⱥ����ɾ����
(8)��HDFS��ִ��wordcount����
2)ִ�в���
��Ҫ����hadoop�ļ�����
(a)����:hadoop-env.sh
���뵽hadoopĿ¼��/training/hadoop-2.7.3/etc/hadoop
ִ������:vi hadoop-env.sh
����Java��������:
export JAVA_HOME=/training/jdk1.8.0_171
ע:�˴��ڱ���ģʽ�����Ѿ���������
���뵽:cd /training/hadoop-2.7.3/etc/hadoopĿ¼��
(b)����:hdfs-site.xml
ִ������
vi hdfs-site.xml
������������,ԭ����:һ���м������ݽڵ�����ü���,�������ܳ���3
<!--��ʾ���ݿ������� Ĭ��Ϊ3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>

(c)����:core-site.xml
ִ������
vi core-site.xml
������������
<!--����NameNode��ͨѶ��ַ 9000 ��RPCĬ�ϵ�ͨ�Ŷ˿�-->
<!�� bigdata�����Linuxӳ�������(��ip��ַ��ӳ����) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata:9000</value>
</property>
<!--HDFS���ݱ�����Linux���ĸ�Ŀ¼,Ĭ��ֵ��Linux��tmpĿ¼��������-->
<property>
<name>hadoop.tmp.dir</name>
<value>/training/hadoop-2.7.3/tmp</value>
</property>
ע��: /training/hadoop-2.7.3/tmp �������ȴ���,����ᱨ��
ִ�������Ŀ¼
mkdir /training/hadoop-2.7.3/tmp
(d)����:mapred-site.xml
����ļ������Dz����ڵ�,��Ҫ����һ��
ִ�������
cp mapred-site.xml.template mapred-site.xml
ִ������
vi mapper-site.xml
������������
<!--����MR������-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

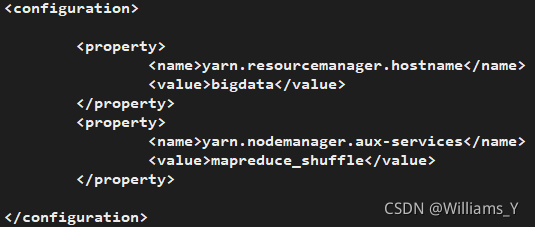
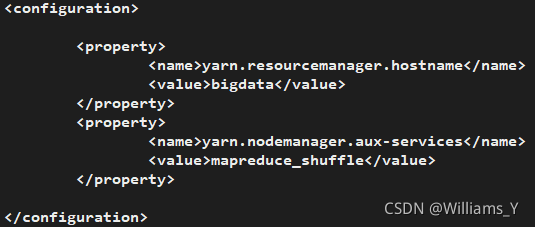
(e)����:yarn-site.xml
ִ������
vi yarn-site.xml
������������
<!--Yarn�����ڵ�RM��λ��,bigdata����ip��ַ��ӳ����-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata</value>
</property>
<!--MapReduce���з�ʽ:shuffleϴ��-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(f) �������������¼
ִ���������ɹ�Կ��˽Կ:
ִ������
ssh-keygen -t rsa
Ȼ����(�����س�),�ͻ����������ļ�id_rsa(˽Կ)��id_rsa.pub(��Կ)

����Կ������Ҫ���ܵ�¼��Ŀ�������(192.168.181.150,bigdata)
ִ������
ssh-copy-id bigdata

(g)��ʽ��:HDFS(NameNode)
ִ������
hdfs namenode -format

��ʽ��û���κδ���,˵�����óɹ���
����hadoop��Ⱥ����
start-all.sh
���Hadoop��Ⱥ����û���κδ���,����jps������������

����:�������,��������������µ�ַ�Ϳ��Է���web����(bigdata��Linux��ip��ַ)
HDFS
http://bigdata:50070
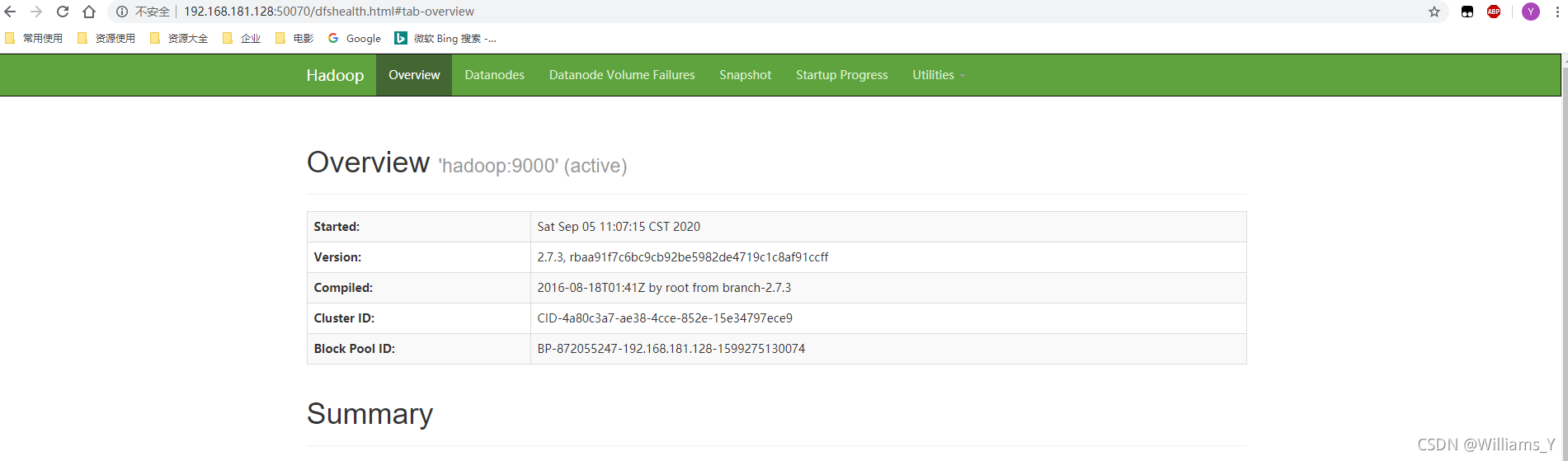
Yarn
http:// bigdata:8088

ֹͣhadoop��Ⱥ����
stop-all.sh
3.3 Hadoopα�ֲ�wordcount����
��Linux������,�༭demo.txt�ļ�,д�뵥�ʡ�
���Ȳ鿴LinuxĿ¼���Ƿ���/demo/inputĿ¼,���û��ִ�����������Ŀ¼
ִ�������Ŀ¼:mkdir -p /demo/input
ִ��������ļ�:vi /demo/input/demo.txt
������Ӣ�ĸ��Ƶ�demo.txt�ı���(����Ӣ��Ҫ���Ҳ�����ͬ,�����������һƪ)
I have a dream that one day this nation will rise up and live out the true meaning of its creed: ��We hold these truths to be self-evident, that all men are created equal.��
I have a dream that one day on the red hills of Georgia, the sons of former slaves and the sons of former slave owners will be able to sit down together at the table of brotherhood.
I have a dream that one day even the state of Mississippi, a state sweltering with the heat of injustice, sweltering with the heat of oppression, will be transformed into an oasis of freedom and justice.
I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character.
I have a dream today!
I have a dream that one day, down in Alabama, with its vicious racists, with its governor having his lips dripping with the words of ��interposition�� and ��nullification�� �C one day right there in Alabama little black boys and black girls will be able to join hands with little white boys and white girls as sisters and brothers.
I have a dream today!
I have a dream that one day every valley shall be exalted, and every hill and mountain shall be made low, the rough places will be made plain, and the crooked places will be made straight; ��and the glory of the Lord shall be revealed and all flesh shall see it together.��
������Ҫ���ļ��ϴ���HDFS��,��HDFS�ϴ���һ��Ŀ¼
ִ�������Ŀ¼:hadoop fs -mkdir /input
�����ص��ı��ϴ���HDFS�ϴ�����Ŀ¼
ִ�������ϴ��ļ�:hadoop fs -put /demo/input/demo.txt /input
���뵽:cd /training/hadoop-2.7.3/share/hadoop/mapreduce/Ŀ¼��
ִ����������ļ�:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/demo.txt /output
�鿴���
ִ������鿴�������:hadoop fs -cat /output/part-r-0000
���ߵ�HDFS�����ص�����,���Ҫ���ص�����,��Ҫ����Windows������,��������ͼ
��hosts�ļ����Ƶ�����,ʹ�ü��±���,����Linux��ip��ַ��ӳ����,����֮���Ƶ�ԭ�����Ƴ������ļ�,�滻��ԭ�����ļ���
��HDFS�Ĺ�������,�������ú�֮��HDFS:http://bigdata:50070�������,�����ͼ�Ϳ�������
3.4 Hadoopȫ�ֲ�ģʽ
����:
1)��3̨�ͻ���(�رշ���ǽ����̬ip����������)
2)��װjdk
3)���û�������
4)��װhadoop
5)���û�������
6)��װssh
7)���ü�Ⱥ
8)�������Լ�Ⱥ
1)������
1������������װjdk
2��������������Ҫ�رշ���ǽ
3��������������Ҫ���������� vi /etc/hosts
4�������������¼(��������֮����������¼)
���еĻ�������Ҫ����һ����Կ:��Կ��˽Կ
ssh-keygen -t rsa
����������Ҫִ��
ssh-copy-id -i .ssh/id_rsa.pub root@hadoop01
ssh-copy-id -i .ssh/id_rsa.pub root@hadoop02
ssh-copy-id -i .ssh/id_rsa.pub root@hadoop03
5����֤ÿ̨������ʱ����һ����
�����һ���Ļ�,������ִ��MapReduce�����ʱ����ܻ��������
�������:
1)�һ��ʱ��ͬ���ķ�����,���Ϻܶ�̳̿���ʹ��
2)ʹ��putty����,���Լ�ʵ���������:
date -s 2020-09-01 ���������һ���س�
2)�����ڵ��Ͻ��а�װ����(hadoop01)
()�ϴ�hadoop��װ��,������û�������
tar -zvxf hadoop-2.7.3.tar.gz -C /training/
ͬʱ����:hadoop01 hadoop02 hadoop03
HADOOP_HOME=/training/hadoop-2.7.3
export HADOOP_HOME
PATH=
H
A
D
O
O
P
H
O
M
E
/
b
i
n
:
HADOOP_HOME/bin:
HADOOPH?OME/bin:HADOOP_HOME/sbin:$PATH
epxort PATH
()�������ļ�
vi hadoop-env.sh ����JDK��·��
hdfs-site.xml:
dfs.replication
2
core-site.xml:
fs.defaultFS
hdfs://hadoop01:9000
hadoop.tmp.dir
/training/hadoop-2.7.3/tmp
mapper-site.xml:
mapreduce.framework.name
yarn
yarn-site.xml:
yarn.resourcemanager.hostname
niit01
yarn.nodemanager.aux-services
mapreduce_shuffle
savles:
hadoop02
hadoop03
()��ʽ��nameNode
hdfs namenode -format
��־:
common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
()��hadoop01�ϵ�hadoop�������Ƶ�hadoop02 hadoop03
scp -r hadoop-2.7.3/ root@hadoop02:/training/
scp -r hadoop-2.7.3/ root@hadoop03:/training/
(*)�����ڵ�(niit01)������hdfs
start-all.sh
3.5 Hadoop����ֹͣ��ʽ
1)�������������һ����
(1)�ֱ�����hdfs���
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
(2)����yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
2)����ģ��ֿ�����(����ssh��ǰ��)����
(1)��������/ֹͣhdfs
start-dfs.sh
stop-dfs.sh
(2)��������/ֹͣyarn
start-yarn.sh
stop-yarn.sh
3)ȫ������(������ʹ��)
start-all.sh
stop-all.sh
3.6 ���ü�Ⱥ��������
1)����ǽû�رա�����û������yarn
INFO client.RMProxy: Connecting to ResourceManager at hadoop/192.168.181.100:8032
2)������������
3)ip��ַ���ô���
4)sshû�����ú�
5)root�û�������Ⱥ��ͳһ
6)�����ļ��IJ�ϸ��
7)δ����Դ��
Unable to load native-hadoop library for your platform�� using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
8)datanode����namenodeʶ������
Namenode��format��ʼ����ʱ����γ�������ʶ,blockPoolId��clusterId���µ�datanode����ʱ,���ȡ��������ʶ��Ϊ�Լ�����Ŀ¼�еı�ʶ��
һ��namenode����format��,namenode�����ݱ�ʶ�ѱ�,��datanode�����Ȼ����ԭ����id,�Ͳ��ᱻnamenodeʶ��
����취,ɾ��datanode�ڵ��е����ݺ�,�ٴ����¸�ʽ��namenode��
9)��ʶ����������
java.net.UnknownHostException: hadoop: hadoop
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
����취:
(1)��/etc/hosts�ļ�������192.168.181.100 hadoop
(2)�������Ʋ�Ҫ��hadoop hadoop000����������
10)datanode��namenode����ͬʱֻ�ܹ���һ����
11)ִ������ ����Ч,ճ��word������ʱ,����-�ͳ��Cû���ֿ�����������ʧЧ
����취:������Ҫճ��word�д��롣
12)jps���ֽ����Ѿ�û��,��������������Ⱥ,��ʾ�����Ѿ�������ԭ������linux�ĸ�Ŀ¼��/tmpĿ¼�д��������Ľ�����ʱ�ļ�,����Ⱥ��ؽ���ɾ����,������������Ⱥ��