вЛЁЂУцЪдИХПі
НёЬьЪЧжЎЧАУцУРЭХjavaбаЗЂСЙжЎКѓЕФ,УРЭХКѓЖЫРЬЦ№УцЪд,ЮвжЎЧАвЛжБЪЧОѕЕУздЮвИаОѕСМКУЕФ,ЁОИаОѕММЪѕУцвдМАЫФУХзЈвЕПЮ=====ДгРДВЛащЁП,НсЙћНёЬьИаОѕЗЧГЃЕФжЊзу,ВЛЪЧЫЕЕФБЪЪдКЭУцЪддѕУДбюАЩ,ОЭЪЧЮвдкНёЬьетГЁУцЪджа,Л§дмЕНСЫКмЖрОбщ,евЕНСЫздЩэЕФВЛзу,гІИУЫМПМЕФЕиЗН,УцЪдЕФвЊЕу,ШУЮвКмЪЧЪмвц,ЫљвдзЅНєзівЛИіБЪМЧЁЃ
ЖўЁЂУцЪд-БЪЪд
СНИіЫуЗЈ:
вЛИіЪЧЖўВцЪїЕФЯШађБщРњЁОзіГіРДСЫЁП
КЯВЂСНИігаађЪ§зщЁОвВзіГіРДСЫЁП
Ш§ЁЂММЪѕУц
3.1 RedisЁОвЛжБдкИЩredisСЌЛЗХкЁП
3.2 ЫЕвЛЯТredisЮЊЪВУДПь?
ЮвЫЕЛљгкФкДц,ЛљгкЕЅЯпГЬ,ШЛКѓЭјТчЧыЧѓгаIOЖрТЗИДгУЫљвдКмПьЁЃ
1ЁЂЭъШЋЛљгкФкДц
2ЁЂЪ§ОнНсЙЙМђЕЅ
3ЁЂВЩгУЕЅЯпГЬ,БмУтСЫВЛБивЊЕФЩЯЯТЮФЧаЛЛКЭОКељЬѕМў,вВВЛДцдкЖрНјГЬЛђепЖрЯпГЬЕМжТЕФЧаЛЛЖјЯћКФ CPU,ВЛгУШЅПМТЧИїжжЫјЕФЮЪЬт,ВЛДцдкМгЫјЪЭЗХЫјВйзї,УЛгавђЮЊПЩФмГіЯжЫРЫјЖјЕМжТЕФадФмЯћКФ;
4ЁЂЪЙгУЖрТЗ I/O ИДгУФЃаЭ,ЗЧзшШћ IO;
3.3 redisШчКЮБЃжЄЪ§ОнЕФвЛжТад?
ЮвЫЕСЫИіМЏШК ЗжЧјЪ§ОнЭЌВНвЛжТад,вђЮЊецЕФЯыВЛЕНСЫ
3.4 redisЕФЫјЛњжЦ
1.RedisжаПЩвдЪЙгУSETNXУќСюЪЕЯжЗжВМЪНЫј
ЕБЧвНіЕБ key ВЛДцдк,НЋ key ЕФжЕЩшЮЊ valueЁЃ ШєИјЖЈЕФ key вбОДцдк,дђ SETNX ВЛзіШЮКЮЖЏзї
2.RedLock
АВШЋЬиад:ЛЅГтЗУЮЪ,МДгРдЖжЛгавЛИі client ФмФУЕНЫј
БмУтЫРЫј:зюже client ЖМПЩФмФУЕНЫј,ВЛЛсГіЯжЫРЫјЕФЧщПі,МДЪЙдБОЫјзЁФГзЪдДЕФ client crash СЫЛђепГіЯжСЫЭјТчЗжЧј
ШнДэад:жЛвЊДѓВПЗж Redis НкЕуДцЛюОЭПЩвде§ГЃЬсЙЉЗўЮё
3.redission
RedissonЪЧвЛИіИпМЖЕФЗжВМЪНаЕїRedisПЭЗўЖЫ,ФмАяжњгУЛЇдкЗжВМЪНЛЗОГжаЧсЫЩЪЕЯжвЛаЉJavaЕФЖдЯѓ (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)ЁЃ
3.5 redisЕФЪТЮёЁОredis ЪТЮёВЛБЃжЄдзгад,ВЛжЇГжЛиЙіЁП
Redis ЪТЮёЕФБОжЪЪЧЭЈЙ§MULTIЁЂEXECЁЂWATCHЕШвЛзщУќСюЕФМЏКЯЁЃЪТЮёжЇГжвЛДЮжДааЖрИіУќСю,вЛИіЪТЮёжаЫљгаУќСюЖМЛсБЛађСаЛЏЁЃдкЪТЮёжДааЙ§ГЬ,ЛсАДееЫГађ ДЎааЛЏжДааЖгСажаЕФУќСю,ЦфЫћПЭЛЇЖЫЬсНЛЕФУќСюЧыЧѓВЛЛсВхШыЕНЪТЮёжДааУќСюађСажа
1.ЕЅЖРЕФИєРыВйзї:ЪТЮёжаЕФЫљгаУќСюЛсБЛађСаЛЏЁЂАДЫГађжДаа,дкжДааЕФЙ§ГЬжаВЛЛсБЛЦфЫћПЭЛЇЖЫЗЂЫЭРДЕФУќСюДђЖЯ
2.УЛгаИєРыМЖБ№ЕФИХФю:ЖгСажаЕФУќСюдкЪТЮёУЛгаБЛЬсНЛжЎЧАВЛЛсБЛЪЕМЪжДаа
3.ВЛБЃжЄдзгад:redisжаЕФвЛИіЪТЮёжаШчЙћДцдкУќСюжДааЪЇАм,ФЧУДЦфЫћУќСювРШЛЛсБЛжДаа,УЛгаЛиЙіЛњжЦ
змНсЫЕ:redisЪТЮёОЭЪЧвЛДЮадЁЂЫГађадЁЂХХЫћадЕФжДаавЛИіЖгСажаЕФвЛЯЕСаУќСю
1.ЪТЮёПЊЪМ MULTI
2.УќСюШыЖг
3.ЪТЮёжДаа EXEC
3.6 redisЕФЮхДѓЪ§ОнРраЭ
String,List,Set,Zset,Hash
3.7 redisЕФ5ДѓЪ§ОнРраЭЕФЪЙгУГЁОА
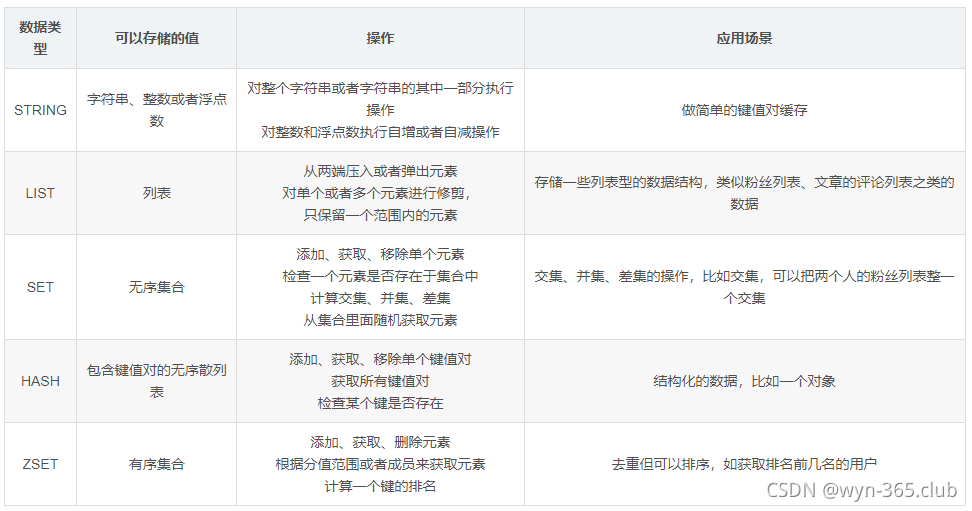
1.String НјаазддіздМѕдЫЫу,ДгЖјЪЕЯжМЦЪ§ЦїЙІФм,КмЪЪКЯДцДЂЦЕЗБЖСаДЕФМЦЪ§СП
2.list: ПЩвдЭЈЙ§lpush/rpush rpop/lpop ЖСШЁКЭаДШыЯћЯЂ,ЪЕЯжзшШћЖгСа
3.Set ПЩвдЪЕЯжНЛМЏЁЂВЂМЏЕШВйзї,ДгЖјЪЕЯжЙВЭЌКУгб,ЭЦМіЕШЕШЙІФм
4.ZSet ПЩвдЪЕЯжгаађадВйзї,ДгЖјЪЕЯжХХааАёЕШЙІФмЁЃ
3.8 redisЕФlist гы setЕФЧјБ№?
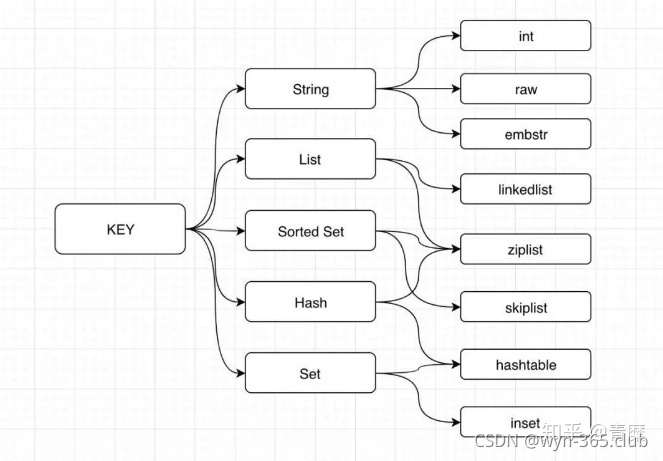
3.9 redisЕФStringЕзВудѕУДЪЕЯжЕФ?listЁЂset,hashЕФЕзВудѕУДЪЕЯж?
1.StringЕФЪ§ОнРраЭЪЧгЩSDSЁОМђЕЅЖЏЬЌзжЗћДЎЁПЪЕЯжЕФ,CгябдЕФЪЕЯжЗНЪНгазЈУХгУгкБЃДцзжЗћДЎГЄЖШЕФБфСП,ЫљвдПЩвддкO(1)ЪБМфФкЛёЕУ
2.СДБэЪЧlistЕФЪЕЯжЗНЪНжЎвЛЁЃЕБlistАќКЌСЫЪ§СПНЯЖрЕФдЊЫи,ЛђепСаБэжаАќКЌЕФдЊЫиЖМЪЧБШНЯГЄЕФзжЗћДЎЪБ,RedisЛсЪЙгУСДБэзїЮЊЪЕЯжListЕФЕзВуЪЕЯжЁЃДЫСДБэЪЧЫЋЯђСДБэЁЃ
СДБэНсЙЙЕФЬиЕуЪЧПЩвдПьЫйЕФдкБэЭЗКЭБэЮВВхШыКЭЩОГ§дЊЫи,ЕЋВщевИДдгЖШИп,ЪЧСаБэЕФЕзВуЪЕЯжжЎвЛ
3.Hash:Ъ§зщ + СДБэ(ВЩгУЭЗВхЗЈНтОіГхЭЛ,ВЛЛсЯёjavaгябдЕФmapвЛбљзЊЛЏЮЊКьКкЪї),redisЛсАбkayЁЂvalueЗтзАГЩвЛИіdictEntryЕФНсЙЙЬх(dictEntryЕФkeyЮЊstringРраЭ,valueЪЧвЛИіжИеы,жИЯђвЛИіredisObjectЖдЯѓ(ВЛЯёjavaгябдвЛбљАбhashmapЕФkeyЁЂvalueЕФОпЬхжЕЗтзАдквЛЦ№))
3.listЕзВуЪЕЯж:ЕзВуЪЧСДБэ,гаСНИіlist,вЛИіЪЧziplist,зжУцвтЪЧбЙЫѕСаБэ,СэвЛИіЪЧquicklist,зжУцвтЪЧПьЫйСаБэ,дкredisжажБНгЪЙгУЕФЪЧquicklist.
4.setЕзВуЪЕЯж: SetЪЧвЛИіЬиЪтЕФvalueЮЊПеЕФHash
5.zsetЕзВуЪЕЯж:ZsetЕзВуЪЧвЛжжЬјБэSkipListЪ§ОнНсЙЙ(ЬјБэдкдгаЕФгаађСДБэЩЯУцдіМгСЫЖрМЖЫїв§,ЭЈЙ§Ыїв§РДЪЕЯжПьЫйВщев,ЪЕжЪОЭЪЧвЛжжПЩвдНјааЖўЗжВщевЕФ
ЦфЪЕЬјБэжївЊЪЧРДЬцДњЦНКтЖўВцЪїЕФ,БШЦ№ЦНКтЪїРДЫЕ,ЬјБэЕФЪЕЯжвЊМђЕЅжБЙлЕФЖрЁЃ
ЬјдОБэ(skiplist)ЪЧвЛжжгаађЪ§ОнНсЙЙ,ЫќЭЈЙ§дкУПИіНкЕужаЮЌГжЖрИіжИЯђЦфЫћНкЕуЕФжИеы,ДгЖјДяЕНПьЫйВщевЗУЮЪНкЕуЕФФПЕФЁЃЬјдОБэЪЧвЛжжЫцЛњЛЏЕФЪ§Он,ЬјдОБэвдгаађЕФЗНЪНдкВуДЮЛЏЕФСДБэжаБЃДцдЊЫи,аЇТЪКЭЦНКтЪїцЧУР ЁЊЁЊВщевЁЂЩОГ§ЁЂЬэМгЕШВйзїЖМПЩвддкO(logn)ЦкЭћЪБМфЯТЭъГЩ

3.10 дкЪЙгУГЁОАжадѕУДЧјБ№ list гы set ?
2.list: ПЩвдЭЈЙ§lpush/rpush rpop/lpop ЖСШЁКЭаДШыЯћЯЂ,ЪЕЯжзшШћЖгСа
3.Set ПЩвдЪЕЯжНЛМЏЁЂВЂМЏЕШВйзї,ДгЖјЪЕЯжЙВЭЌКУгб,ЭЦМіЕШЕШЙІФм
4.ZSet ПЩвдЪЕЯжгаађадВйзї,ДгЖјЪЕЯжХХааАёЕШЙІФмЁЃ
3.11 RedisЕФФкДцгУЭъСЫ?
1.RedisжЇГждЫааЪБЭЈЙ§УќСюЖЏЬЌаоИФФкДцДѓаЁ
2.RedisЕФФкДцЬдЬ

3.12 redisЕФФЧаЉУќСюЪЧдзгадЕФ?

3.13 RDB && AOF
RDBЪЧдкФГИіЪБМфЕуНЋЪ§ОнаДШывЛИіСйЪБЮФМў,ГжОУЛЏНсЪјКѓ,гУетИіСйЪБЮФМўЬцЛЛЩЯДЮГжОУЛЏЕФЮФМў,ДяЕНЪ§ОнЛжИДЁЃ
гХЕу:ЪЙгУЕЅЖРзгНјГЬРДНјааГжОУЛЏ,жїНјГЬВЛЛсНјааШЮКЮIOВйзї,БЃжЄСЫredisЕФИпадФм
ШБЕу:RDBЪЧМфИєвЛЖЮЪБМфНјааГжОУЛЏ,ШчЙћГжОУЛЏжЎМфredisЗЂЩњЙЪеЯ,ЛсЗЂЩњЪ§ОнЖЊЪЇЁЃЫљвдетжжЗНЪНИќЪЪКЯЪ§ОнвЊЧѓВЛбЯНїЕФЪБКђredis.conf
AOF:НЋЁАВйзї + Ъ§ОнЁБвдИёЪНЛЏжИСюЕФЗНЪНзЗМгЕНВйзїШежОЮФМўЕФЮВВП,дкappendВйзїЗЕЛиКѓ(вбОаДШыЕНЮФМўЛђепМДНЋаДШы),ВХНјааЪЕМЪЕФЪ§ОнБфИќ,ЁАШежОЮФМўЁББЃДцСЫРњЪЗЫљгаЕФВйзїЙ§ГЬ;ЕБserverашвЊЪ§ОнЛжИДЪБ,ПЩвджБНгreplayДЫШежОЮФМў,МДПЩЛЙдЫљгаЕФВйзїЙ§ГЬЁЃAOFЯрЖдПЩПП,ЫќКЭmysqlжаbin.logЁЂapache.logЁЂzookeeperжаtxn-logМђжБвьЧњЭЌЙЄЁЃAOFЮФМўФкШнЪЧзжЗћДЎ,ЗЧГЃШнвздФЖСКЭНтЮіЁЃ
AOFФЌШЯЙиБе,ПЊЦєЗНЗЈ,аоИФХфжУЮФМўreds.conf: appendonly yes
гХЕу:ПЩвдБЃГжИќИпЕФЪ§ОнЭъећад,ШчЙћЩшжУзЗМгfileЕФЪБМфЪЧ1s,ШчЙћredisЗЂЩњЙЪеЯ,зюЖрЛсЖЊЪЇ1sЕФЪ§Он;ЧвШчЙћШежОаДШыВЛЭъећжЇГжredis-check-aofРДНјааШежОаоИД;ЁЃAOFЕФЬиадОіЖЈСЫЫќЯрЖдБШНЯАВШЋ,ШчЙћФуЦкЭћЪ§ОнИќЩйЕФЖЊЪЇ,ФЧУДПЩвдВЩгУAOFФЃЪН
ШБЕу:AOFЮФМўБШRDBЮФМўДѓ,ЧвЛжИДЫйЖШТ§ЁЃ
ЫФЁЂMysql
4.1 ЫЕвЛЯТInnodbв§Чц
МђЕЅ
4.2 ЫЕвЛЯТmysqlЕФЫјЛњжЦ
БЏЙлЫј
дкЖдШЮвтМЧТМНјаааоИФЧА,ЯШГЂЪдЮЊИУМЧТММгЩЯХХЫћЫј(exclusive locking)
ШчЙћМгЫјЪЇАм,ЫЕУїИУМЧТМе§дкБЛаоИФ,ФЧУДЕБЧАВщбЏПЩФмвЊЕШД§ЛђепХзГівьГЃЁЃ ОпЬхЯьгІЗНЪНгЩПЊЗЂепИљОнЪЕМЪашвЊОіЖЈЁЃ
ШчЙћГЩЙІМгЫј,ФЧУДОЭПЩвдЖдМЧТМзіаоИФ,ЪТЮёЭъГЩКѓОЭЛсНтЫјСЫЁЃ
ЦфМфШчЙћгаЦфЫћЖдИУМЧТМзіаоИФЛђМгХХЫћЫјЕФВйзї,ЖМЛсЕШД§ЮвУЧНтЫјЛђжБНгХзГівьГЃЁЃ
гХЕуКЭШБЕу
гХЕу:АВШЋ
ШБЕу:БЏЙлЫјЪЕМЪЩЯЪЧВЩШЁСЫЁАЯШШЁЫјдкЗУЮЪЁБЕФВпТд,ЮЊЪ§ОнЕФДІРэАВШЋЬсЙЉСЫБЃжЄ,ЕЋЪЧдкаЇТЪЗНУц,гЩгкЖюЭтЕФМгЫјЛњжЦВњЩњСЫЖюЭтЕФПЊЯњ,ВЂЧвдіМгСЫЫРЫјЕФЛњЛсЁЃВЂЧвНЕЕЭСЫВЂЗЂад;ЕБвЛИіЪТЮяЫљвдвЛааЪ§ОнЕФЪБКђ,ЦфЫћЪТЮяБиаыЕШД§ИУЪТЮёЬсНЛжЎКѓ,ВХФмВйзїетааЪ§ОнЁЃ
РжЙлЫј
ЯрЖдБЏЙлЫјЖјбд,РжЙлЫјМйЩшШЯЮЊЪ§ОнвЛАуЧщПіЯТВЛЛсдьГЩГхЭЛ,ЫљвддкЪ§ОнНјааЬсНЛИќаТЕФЪБКђ,ВХЛсе§ЪНЖдЪ§ОнЕФГхЭЛгыЗёНјааМьВт,ШчЙћЗЂЯжГхЭЛСЫ,дђШУЗЕЛигУЛЇДэЮѓЕФаХЯЂ,ШУгУЛЇОіЖЈШчКЮШЅзіЁЃ
ЯрЖдгкБЏЙлЫј,дкЖдЪ§ОнПтНјааДІРэЕФЪБКђ,РжЙлЫјВЂВЛЛсЪЙгУЪ§ОнПтЬсЙЉЕФЫјЛњжЦЁЃвЛАуЕФЪЕЯжРжЙлЫјЕФЗНЪНОЭЪЧМЧТМЪ§ОнАцБО
РжЙлЫјЕФгХЕуКЭШБЕу
РжЙлВЂЗЂПижЦЯраХЪТЮёжЎМфЕФЪ§ОнОКељ(data race)ЕФИХТЪЪЧБШНЯаЁЕФ,вђДЫОЁПЩФмжБНгзіЯТШЅ,жБЕНЬсНЛЕФЪБКђВХШЅЫјЖЈ,ЫљвдВЛЛсВњЩњШЮКЮЫјКЭЫРЫјЁЃЕЋШчЙћжБНгМђЕЅетУДзі,ЛЙЪЧгаПЩФмЛсгіЕНВЛПЩдЄЦкЕФНсЙћ,Р§ШчСНИіЪТЮёЖМЖСШЁСЫЪ§ОнПтЕФФГвЛаа,ОЙ§аоИФвдКѓаДЛиЪ§ОнПт,етЪБОЭгіЕНСЫЮЪЬтЁЃ
4.3 ЫЕвЛЯТШчКЮХХВщТ§SQL
1.mysqlФЌШЯВЛПЊЦєТ§SQLШежО,МьВщЪЧЗёПЊЦєСЫ Т§ВщбЏШежО :
show variables like '%slow_query_log%' ;
2.ПЊЦєТ§SQL
/etc/my.cnf жазЗМгХфжУ:vi /etc/my.cnf
[mysqld]
slow_query_log=1
slow_query_log_file=/var/lib/mysql/localhost-slow.log
3.ВщбЏГЌЙ§ЗЇжЕЕФSQL
show global status like '%slow_queries%' ;
4.Т§ВщбЏЕФsqlБЛМЧТМдкСЫШежОжа,вђДЫПЩвдЭЈЙ§ШежО ВщПДОпЬхЕФТ§SQLЁЃ
cat /var/lib/mysql/localhost-slow.log
5.ЭЈЙ§explainЗжЮіsqlгяОф,Р§:
explain select name from tablex where a = '1';

4.4 ЫЕвЛЯТmysqlБЏЙлЫјгыРжЙлЫјЕФЪЙгУГЁОА?
БЏЙлЫј:БШНЯЪЪКЯаДШыВйзїБШНЯЦЕЗБЕФГЁОА,ШчЙћГіЯжДѓСПЕФЖСШЁВйзї,УПДЮЖСШЁЕФЪБКђЖМЛсНјааМгЫј,етбљЛсдіМгДѓСПЕФЫјЕФПЊЯњ,НЕЕЭСЫЯЕЭГЕФЭЬЭТСПЁЃ
РжЙлЫј:БШНЯЪЪКЯЖСШЁВйзїБШНЯЦЕЗБЕФГЁОА,ШчЙћГіЯжДѓСПЕФаДШыВйзї,Ъ§ОнЗЂЩњГхЭЛЕФПЩФмадОЭЛсдіДѓ,ЮЊСЫБЃжЄЪ§ОнЕФвЛжТад,гІгУВуашвЊВЛЖЯЕФжиаТЛёШЁЪ§Он,етбљЛсдіМгДѓСПЕФВщбЏВйзї,НЕЕЭСЫЯЕЭГЕФЭЬЭТСПЁЃ
змНс:СНжжЫљИїгагХШБЕу,ЖСШЁЦЕЗБЪЙгУРжЙлЫј,аДШыЦЕЗБЪЙгУБЏЙлЫјЁЃ
ЮхЁЂJVM
5.1 ЫЕвЛЯТдкЪВУДЧщПіЯТ,ЖдЯѓЛсНјШыРЯФъДњ?
1.ДѓЖдЯѓ
2.ГЄЦкДцЛюЕФЖдЯѓ s0 s1 15ЫъвдКѓЁОжЛД№ГіРДетИіЁП
5.2 ЫЕвЛЯТЮЊЪВУД s0Чј = s1Чј
УЛД№ГіРД
5.3 ШчЙћjavaГЬађCPUЙ§Ип,ШчКЮХХВщ????
НјГЬ====ЁЗЖЈЮЛЯпГЬ
вЛАуjavaгІгУcpuЙ§ИпЛљБОЩЯЪЧвђЮЊ
1.ГЬађМЦЫуБШНЯУмМЏ
2.ГЬађЫРбЛЗ
3.ГЬађТпЧыЧѓЖТШћ
4.IOЖСаДЬЋИп
1ЁЂЯШЭЈЙ§topУќСюевЕНЯћКФcpuКмИпЕФНјГЬidМйЩшЪЧ123
2ЁЂжДааtop -p 123ЕЅЖРМрПиИУНјГЬ
3ЁЂдкЕк2ВНЕФМрПиНчУцЪфШыH,ЛёШЁЕБЧАНјГЬЯТЕФЫљгаЯпГЬаХЯЂ
4ЁЂевЕНЯћКФcpuЬиБ№ИпЕФЯпГЬБрКХ,МйЩшЪЧ123
5ЁЂжДааjstack 123456ЖдЕБЧАЕФНјГЬзі jmap -dump,ЪфГіЫљгаЕФЯпГЬаХЯЂ
6 НЋЕк4ВНЕУЕНЕФЯпГЬБрКХ11354зЊГЩ16НјжЦЪЧ0x7b
7 ИљОнЕк6ВНЕУЕНЕФ0x7bдкЕк5ВНЕФЯпГЬаХЯЂРяУцШЅевЖдгІЯпГЬФкШн
8 НтЖСЯпГЬаХЯЂ,ЖЈЮЛОпЬхДњТыЮЛжУ
ЖЈЮЛЕНcpuЙ§ИпЪЧIOЖСаДЬЋИп ,НгЯТРДОЭЪЧевПЊЗЂШЫдБШЗШЯетЖЮДњТыЪЧЗёПЩвдгХЛЏ
5.4 Java OOMЮЪЬтШчКЮХХВщ????
1.ВщПДjava НјГЬ/ЯпГЬЖдЯЕЭГЕФеМгУЧщПі,Шч top -pid
2.jstack pid > file.log ЭЈЙ§jstack АбИУНјГЬЕФЫљгаЯпГЬЖбеЛДђгЁЕНfile.logжа
3.jmap -heap НјГЬ/ЯпГЬКХ ЯдЪОЖбФкДцаХЯЂ
4.jmap -dump ЩњГЩЖбФкДцзЊДЂПьее
5.МгдиЖдБШ ЖбЮФМў,ЗЂЯж ЖдЯѓдіЖр,ГѕВНЖЈЮЛЕНЮЪЬт
СљЁЂJava
дкЮвЗЧГЃЩУГЄЕФjavaетвЛПщ,жЛЮЪСЫвЛИіvolitizeЙиМќзж
ЮвЫЕ,ЪЧвЛИіЙиМќзж,жЛФмзїгУдкБфСПЩЯ,БЃжЄПЩМћад,ЗРжЙжИСюжиХХ,ВЛБЃжЄдзгад
УцЪдЙйЗДЮЪ:Г§СЫПЩМћад,ЛЙФмБЃжЄЪВУД????
ЦпЁЂЗДЮЪ
ЮвЫЕЮвздМКНёЬьБэЯжВЛЪЧКмКУ,ЮЪЮЪУцЪдЙйЖдЮвгаЪВУДЕиЗНИФНј?
УцЪдЙй:ЫЕЖдЮвЦкЭћЬиБ№Ип,ПДЕНЮвМђРњЫЕЮвЛсЕФММЪѕеЛКмШЋ,ЫљвдЮЪЮвЕФЪБКђВЂУЛгаЕѓФбЮв,ВЛвЊЮЊСЫУцЪдЖјУцЪд,ЖјЪЧбЁдёгаЫМПМЕФШУЮвШЅПМТЧЮЪЬтЁЃ
зюКѓИааЛСЫУцЪдЙй,вђЮЊецЕФЪеЛёКмДѓ,вВжЊЕРСЫдкбЇЯАЪБКђШчКЮШчБмУтаЮГЩПЬАхЫМТЗ,ЖрЫМПМ!!!
