Ŀ¼
1 UDTF֮explode����
1.1 explode�����
����UDTF�����ɺ���,�ܶ�����������ʲô��������һ��,������С�
Ϊʲô����������?�ܹ���������?�������Ǿ���ѧϰHive�������õ�һ���dz�������UDTF����,���ֽ���explode����,����Ϸ��֮Ϊ����ը������,����ը�����ݡ�
explode��������map����array���͵�������Ϊ����,Ȼ��Ѳ����е�ÿ��Ԫ��ը�����һ�����ݡ�һ��Ԫ��һ�С�������Ч����������������һ��������С�
explode�����ڹ�ϵ�����ݿ��б����Dz��ó��ֵġ�
��Ϊ���ij��ֱ��������ڲ����������һ��ʽ������(ÿ�����Զ������ٷ�)�������Ѿ�Υ�������ݿ�����ԭ��,������������������ݿ�������ݲֿ���,��Щ�淶���Է����ı䡣
explode(a) - separates the elements of array a into multiple rows, or the elements of a map into multiple rows and columns 
explode(array)��array�б����ÿ��Ԫ������һ��;
explode(map)��map���ÿһ��Ԫ����Ϊһ��,����keyΪһ��,valueΪһ��;
һ�������,explode��������ֱ��ʹ�ü���,Ҳ���Ը�����Ҫ���lateral view����ͼʹ�á�
1.2 explode������ʹ��
select explode(array(11,22,33)) as item;
select explode(map(��id��,10086,��name��,��zhangsan��,��age��,18));

1.3 ����:NBA�ܹھ��������
1.3.1 ҵ������
��һ�����ݡ�The_NBA_Championship.txt��,���ڲ�����ݵ�NBA�ܹھ��������:

��һ���ֶα�ʾ�����������,�ڶ����ֶ��ǻ�ȡ�ܹھ������,�ֶ�֮����,�ָ�;
��ȡ�ܹھ����֮����|���зָ
����:ʹ��Hive����ӳ��ɹ�����,�����ݲ��,Ҫ����֮������������ʾ:

������ø�����ݵĵ����������
1.3.2 ����ʵ��
--step1:����
create table the_nba_championship(
team_name string,
champion_year array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';
--step2:���������ļ�������
load data local inpath '/root/hivedata/The_NBA_Championship.txt' into table the_nba_championship;
--step3:��֤
select *
from the_nba_championship;

����ʹ��explode����:
�Cstep4:ʹ��explode������champion_year���в�� �׳�ը��
select explode(champion_year) from the_nba_championship;
select team_name,explode(champion_year) from the_nba_championship;

1.3.3 explodeʹ������
��select������,���ֻ��explode��������ʽ,����ִ����û���κ������;
���������select������,����explode�������ֶ�,�ͻᱨ����������ϢΪ:
org.apache.hadoop.hive.ql.parse.SemanticException:UDTF��s are not supported outside the SELECT clause, nor nested in expressions
��ô����������������?Ϊʲô��select��ʱ��,explode���Ա߲�֧�������ֶε�ͬʱ����?
1.3.4 explode�����ԭ��
1�� explode��������UDTF����,�������ɺ���;
2�� explode����ִ�з��صĽ����������Ϊһ������ı�,��������Դ��Դ��;
3�� ��select��ֻ��ѯԴ������û������,ֻ��ѯexplode���ɵ����������Ҳû����
4�� ���Dz�����ֻ��ѯԴ����ʱ��,���뷵��Դ���ֶ����뷵��explode���ɵ�������ֶ�
5�� ͨ�㽲,�����ű�,����ֻ��ѯһ�ű����Ƿ��طֱ��������ű����ֶ�;
6�� ��SQL��������˵Ӧ�ö����ű����й�����ѯ
7�� Hiveר���ṩ���lateral View����ͼ,ר�����ڴ���explode������UDTF����,������������Ҫ��

2 Lateral View����ͼ
2.1 ����
Lateral View��һ��������,��Ҫ���ڴ���UDTF�����ܵĺ���һ��ʹ��,���ڽ��UDTF������һЩ��ѯ���Ƶ����⡣
����ͼ��ԭ���ǽ�UDTF�Ľ��������һ����������ͼ�ı�,Ȼ��ԭ���е�ÿһ�к�UDTF���������ÿһ�н�������,����һ���µ�������������ͱ�����UDTF��ʹ���������⡣ʹ��lateral viewʱҲ���Զ�UDTF�����ļ�¼�����ֶ�����,�������ֶο�������group by��order by ��limit�������,����Ҫ�ٵ���Ƕ��һ���Ӳ�ѯ��
һ��ֻҪʹ��UDTF,�ͻ�̶�����lateral viewʹ�á�
�ٷ�����:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
2.2 UDTF��ϲ���ͼʹ��
�������NBA�ھ���������������,ʹ��explode����+lateral view����ͼ,�����������:
�Clateral view����ͼ���������
select ���� from tabelA lateral view UDTF(xxx) ���� as col1,col2,col3����;
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
�C������ݵ�������
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;
3 Aggregation �ۺϺ���
3.1 �����ۺ�
HQL�ṩ�˼������õ�UDAF�ۺϺ���,����max(��),min(��)��avg(��)����Щ���ǰ�����֮Ϊ�����ľۺϺ�����
ͨ�������,�ۺϺ�������GROUP BY�Ӿ�һ��ʹ�á� ���δָ��GROUP BY�Ӿ�,Ĭ�������,����������������ݡ�
--------------�����ۺϺ���-------------------
--1������������
drop table if exists student;
create table student(
num int,
name string,
sex string,
age int,
dept string)
row format delimited
fields terminated by ',';
--��������
load data local inpath '/root/hivedata/students.txt' into table student;
--��֤
select * from student;
--����1:û��group by�Ӿ�ľۺϲ���
select count(*) as cnt1,count(1) as cnt2 from student; --����һ��
--����2:����group by�Ӿ�ľۺϲ��� ע��group by�����
select sex,count(*) as cnt from student group by sex;
--����3:selectʱ����ۺϺ���һ��ʹ��
select count(*) as cnt1,avg(age) as cnt2 from student;
--����4:�ۺϺ�����case when����ת��������coalesce������if����ʹ��
select
sum(CASE WHEN sex = '��'THEN 1 ELSE 0 END)
from student;
select
sum(if(sex = '��',1,0))
from student;
--����5:�ۺϲ�����֧��Ƕ�ۺϺ���
select avg(count(*)) from student;
--�ۺϲ������null�Ĵ�����ʽ
--null null 0
select max(null), min(null), count(null);
--������������֧��null
select sum(null), avg(null);
--����5:�ۺϲ���ʱ���null�Ĵ���
CREATE TABLE tmp_1 (val1 int, val2 int);
INSERT INTO TABLE tmp_1 VALUES (1, 2),(null,2),(2,3);
select * from tmp_1;
--�ڶ�������(NULL, 2) �ڽ���sum(val1 + val2)��ʱ��ᱻ����
select sum(val1), sum(val1 + val2) from tmp_1;
--����ʹ��coalesce�������
select
sum(coalesce(val1,0)),
sum(coalesce(val1,0) + val2)
from tmp_1;
--����6:���distinct�ؼ���ȥ�ؾۺ�
--�˳�����,������ڼ���Զ�����ֻ����һ��reduce task�������� ���ܿ��ܻ�� �������ӵ��
select count(distinct sex) as cnt1 from student;
--������ȥ�� �ھۺ� ͨ���Ӳ�ѯ���
--��Ϊ��ִ��distinct��ʱ�� ����ʹ�ö��reducetask��������
select count(*) as gender_uni_cnt
from (select distinct sex from student) a;
--��������:�ҳ�student����Ůѧ���������ļ�������
--����ʹ����struct���������� Ȼ�����structӦ��max�ҳ����Ԫ�� Ȼ��ȡֵ
select sex,
max(struct(age, name)).col1 as age,
max(struct(age, name)).col2 as name
from student
group by sex;
select struct(age, name) from student;
select struct(age, name).col1 from student;
select max(struct(age, name)) from student;
3.2 ��ǿ�ۺ�
3.2.1 ����������ݻ�����
��ǿ�ۺϵ�grouping_sets��cube��rollup�⼸��������Ҫ������OLAP��ά���ݷ���ģʽ��,��ά�����е�άָ�ķ�������ʱ���������ά�ȡ��Ƕȡ�
������������һ������,ͨ���������õ����⺯���Ĺ��ܺ���
�ֶ�:�·ݡ��졢�û�cookieid
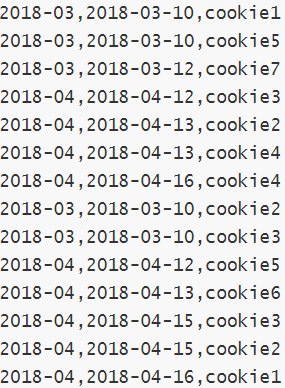
--���������Ҽ�������
CREATE TABLE cookie_info(
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
load data local inpath '/root/hivedata/cookie_info.txt' into table cookie_info;
select * from cookie_info;
3.2.2 Grouping sets
grouping sets��һ�ֽ����group by��д��һ��sql����еı���д����
�ȼ��ڽ���ͬά�ȵ�GROUP BY���������UNION ALL��
GROUPING__ID��ʾ���������һ�����鼯�ϡ�
---group sets---------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
--grouping_id��ʾ��һ���������ĸ����鼯��,
--����grouping sets�еķ�������month,day,1�Ǵ���month,2�Ǵ���day
--�ȼ���
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day;
--�ٱ���
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
--�ȼ���
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
3.2.3 Cube
cube�������ָ����:����GROUP BY��ά�ȵ�������Ͻ��оۺϡ�
����cube,�����n��ά��,��������ϵ��ܸ�����:2^n��
����Cube��a,b,c3����,��������������:
((a,b,c),(a,b),(b,c),(a,c),(a),(b),?,())��
------cube---------------
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
--�ȼ���
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS nums,0 AS GROUPING__ID FROM cookie_info
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
3.2.4 Rollup
cube�������ָ����:����GROUP BY��ά�ȵ�������Ͻ��оۺϡ�
rollup��Cube���Ӽ�,��������ά��Ϊ��,�Ӹ�ά�Ƚ��в㼶�ۺϡ�
����ROLLUP��a,b,c3����,��������������:
((a,b,c),(a,b),(a),())��
--rollup-------------
--����,��monthά�Ƚ��в㼶�ۺ�:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
--��month��day����˳��,����dayά�Ƚ��в㼶�ۺ�:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie_info
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
4 Window functions ���ں���
4.1 ���ں�������
���ں���(Window functions)��һ��SQL����,�dz��ʺ������ݷ���,���Ҳ����OLAP����,������ص���:����ֵ�Ǵ�SELECT���Ľ�����е�һ�л���еġ����ڡ��л�ȡ�ġ���Ҳ��������Ϊ�����д���С(���ж�����)��
ͨ��OVER�Ӿ�,���ں���������SQL�����������������������OVER�Ӿ�,�����Ǵ��ں����������ȱ��OVER�Ӿ�,������һ����ͨ�ľۺϺ�����
���ں������Լؽ���Ϊ�����ھۺϺ����ļ��㺯��,����ͨ��GROUP BY�Ӿ���ϵij���ۺϻ��������ھۺϵĸ�����,�������һ��,���ں����ۺϺ��Է��ʵ��еĸ�����,���ҿ��Խ���Щ���е�ijЩ�������ӵ�������С�

Ϊ�˸���ֱ�۸��ܴ��ں���,����ͨ��sum�ۺϺ���������ͨ����ۺϺʹ��ھۺ�,һ��Ч����
----sum+group by��ͨ����ۺϲ���------------
select sum(salary) as total from employee group by dept;
----sum+���ں����ۺϲ���------------
select id,name,deg,salary,dept,sum(salary) over(partition by dept) as total from employee;



4.2 ���ں����
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
--����Function(arg1,..., argn) ��������������е�����һ��
--�ۺϺ���:����sum max avg��
--������:����rank row_number��
--��������:����lead lag first_value��
--OVER [PARTITION BY <...>] ������group by ����ָ������ ÿ���������������������
--���û��PARTITION BY ��ô���ű��������о���һ��
--[ORDER BY <....>] ����ָ��ÿ�������ڵ������������ ֧��ASC��DESC
--[<window_expression>] ����ָ��ÿ�������� ���������ݷ�Χ Ĭ���Ǵ�����������
4.3 ����:��վ�û�ҳ�������������
����վ������,����ʹ��cookie����ʶ��ͬ���û�����,ͨ��cookie�����ٲ�ͬ�û���ҳ��������,��������������:
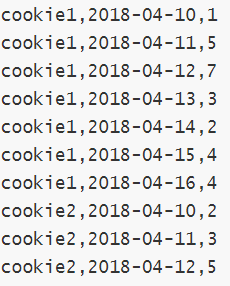
�ֶκ���:cookieid ������ʱ�䡢pv��(ҳ�������)
�ֶκ���:cookieid������ʱ�䡢����ҳ��url
��Hive�д������ű���,�����ݼ��ؽ�ȥ���ڴ��ڷ�����
---�������Ҽ�������
create table website_pv_info(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
create table website_url_info (
cookieid string,
createtime string, --����ʱ��
url string --����ҳ��
) row format delimited
fields terminated by ',';
load data local inpath '/root/hivedata/website_pv_info.txt' into table website_pv_info;
load data local inpath '/root/hivedata/website_url_info.txt' into table website_url_info;
select * from website_pv_info;
select * from website_url_info;
4.3.1 ���ھۺϺ���
��Hive v2.2.0��ʼ,֧��DISTINCT�봰�ں����еľۺϺ���һ��ʹ�á�
������sum()����Ϊ��,�����ۺϺ���ʹ�����ơ�
-----���ھۺϺ�����ʹ��-----------
--1�����ÿ���û���pv�� sum+group by��ͨ����ۺϲ���
select cookieid,sum(pv) as total_pv from website_pv_info group by cookieid;
--2��sum+���ں��� �ܹ��������÷� ע��������ۺ� �����ۻ��ۺ�
--sum(...) over( )�Ա����������
--sum(...) over( order by ... ) �����ۻ����
--sum(...) over( partition by... ) ͬ�������������
--sum(...) over( partition by... order by ... ) ��ÿ��������,�����ۻ����
--����:�����վ�ܵ�pv�� �����û����з��ʼ�����
--sum(...) over( )�Ա����������
select cookieid,createtime,pv,
sum(pv) over() as total_pv
from website_pv_info;
--����:���ÿ���û���pv��
--sum(...) over( partition by... ),ͬ�����������
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid) as total_pv
from website_pv_info;
--����:���ÿ���û���ֹ������,�ۻ�����pv��
--sum(...) over( partition by... order by ... ),��ÿ��������,�����ۻ����
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime) as current_total_pv
from website_pv_info;


4.3.2 ���ڱ���ʽ
����֪��,��sum(��) over( partition by�� order by �� )������������,���е��ۻ��ۺϲ���,Ĭ���ۻ��ۺ���Ϊ��:�ӵ�һ�оۺϵ���ǰ�С�
Window expression���ڱ���ʽ�������ṩ��һ�ֿ����з�Χ������,������ǰ2��,���3�С�
�����:
�ؼ�����rows between,���������⼸��ѡ��
- preceding:��ǰ
- following:����
- current row:��ǰ��
- unbounded:�߽�
- unbounded preceding ��ʾ��ǰ������
- unbounded following:��ʾ��������յ�
---���ڱ���ʽ
--��һ�е���ǰ��
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and current row) as pv2
from website_pv_info;
--��ǰ3������ǰ��
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and current row) as pv4
from website_pv_info;
--��ǰ3�� ���1��
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5
from website_pv_info;
--��ǰ�������һ��
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from website_pv_info;
--��һ�е����һ�� Ҳ���Ƿ����ڵ�������
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;
4.3.3 ����������
�������������ڸ�ÿ�������ڵ����ݴ�������ı�š�ע�ⴰ����������֧�ִ��ڱ���ʽ���ܹ���4��������Ҫ����:
row_number:��ÿ��������,Ϊÿ�з���һ����1��ʼ��Ψһ���к�,����,�������ظ�;
rank: ��ÿ��������,Ϊÿ�з���һ����1��ʼ�����к�,�����ظ�,��ռ����λ��;
dense_rank: ��ÿ��������,Ϊÿ�з���һ����1��ʼ�����к�,�����ظ�,����ռ����λ��;
-----����������
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = 'cookie1';

���������������ڷ���TopN�ij����dz��ʺϡ�
--����:�ҳ�ÿ���û�����pv����Top3 �ظ����еIJ�����
SELECT * from
(SELECT
cookieid,
createtime,
pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS seq
FROM website_pv_info) tmp where tmp.seq <4;

����һ������,����ntile����,�书��Ϊ:��ÿ�������ڵ����ݷ�Ϊָ�������ɸ�Ͱ��(��Ϊ���ɸ�����),����Ϊÿһ��Ͱ����һ��Ͱ��š�
�������ƽ������,�����ȷ����С��ŵ�Ͱ,���Ҹ���Ͱ���ܷŵ�����������1��
��ʱ��������������:�������������Ϊ������,ҵ����Աֻ�������е�һ����,��ν����м������֮һ�����ó�����?NTILE�������������㡣
--��ÿ�������ڵ����ݷ�Ϊ3Ͱ
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;

--����:ͳ��ÿ���û�pv������ǰ3��֮1�졣
--����:�����ݸ���cookieid�� ����pv�������� ����֮���Ϊ3������ ȡ��һ����
SELECT * from
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn
FROM website_pv_info) tmp where rn =1;

4.3.4 ���ڷ�������
LAG(col,n,DEFAULT) ����ͳ�ƴ��������ϵ�n��ֵ
��һ������Ϊ����,�ڶ�������Ϊ���ϵ�n��(��ѡ,Ĭ��Ϊ1),����������ΪĬ��ֵ(�����ϵ�n��ΪNULLʱ��,ȡĬ��ֵ,�粻ָ��,��ΪNULL);
LEAD(col,n,DEFAULT) ����ͳ�ƴ��������µ�n��ֵ
��һ������Ϊ����,�ڶ�������Ϊ���µ�n��(��ѡ,Ĭ��Ϊ1),����������ΪĬ��ֵ(�����µ�n��ΪNULLʱ��,ȡĬ��ֵ,�粻ָ��,��ΪNULL);
FIRST_VALUE ȡ�����������,��ֹ����ǰ��,��һ��ֵ;
LAST_VALUE ȡ�����������,��ֹ����ǰ��,���һ��ֵ;
-----------���ڷ�������----------
--LAG
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM website_url_info;
--LEAD
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM website_url_info;
--FIRST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM website_url_info;
--LAST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM website_url_info;

5 Sampling ��������
5.1 ��������
������������ʱ,���ǿ�����Ҫ���������Ӽ��Լӿ����ݴ����ٶȷ����� ����dz���������,һ������ʶ��ͷ��������е��Ӽ��ļ���,�Է����������ݼ��е�ģʽ�����ơ�

��HQL��,����ͨ�����ַ�ʽ��������:�������,�洢Ͱ�������Ϳ������
5.2 Random�������
�������ʹ��rand()������LIMIT�ؼ�������ȡ���ݡ� ʹ����DISTRIBUTE��SORT�ؼ���,����ȷ������Ҳ����ֲ���mapper��reducer֮��,ʹ�õײ�ִ����Ч�ʡ�
ORDER BY ��rand()���Ҳ���Դﵽ��ͬ��Ŀ��,���DZ��ֲ��á���ΪORDER BY��ȫ������,ֻ����������һ��Reducer��
--���ݱ�
select * from student;
--����:�����ȡ2��ѧ����������в鿴
SELECT * FROM student
DISTRIBUTE BY rand() SORT BY rand() LIMIT 2;
--ʹ��order by+randҲ����ʵ��ͬ����Ч�� ����Ч�ʲ���
SELECT * FROM student
ORDER BY rand() LIMIT 2;

5.3 Block�����
Block���������select�����ȡn������,�����ݴ�С��n���ֽڵ����ݡ�
����������HDFS�����
---block����
--������������
SELECT * FROM student TABLESAMPLE(1 ROWS);
--�������ݴ�С�ٷֱȳ���
SELECT * FROM student TABLESAMPLE(50 PERCENT);
--�������ݴ�С����
--֧�����ݵ�λ b/B, k/K, m/M, g/G
SELECT * FROM student TABLESAMPLE(1k);
5.4 Bucket table��Ͱ������
����һ������IJ�������,��Է�Ͱ���������Ż���
---bucket table����
--�����������ݽ��г���
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON rand());
--���ݷ�Ͱ�ֶν��г��� Ч�ʸ���
describe formatted t_usa_covid19_bucket;
SELECT * FROM t_usa_covid19_bucket TABLESAMPLE(BUCKET 1 OUT OF 2 ON state);
