??大家好,我是不温卜火,昵称来源于成语―
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!博客主页:https://buwenbuhuo.blog.csdn.net/
目录
前言
此系列主要为我的学弟学妹们所创作,在某些方面可能偏基础。如果读者感觉较为简单,还望见谅!如果文中出现错误,欢迎指正~

本文主要介绍了Hadoop简介及Apache Hadoop完全分布式集群搭建,包括大数据简介、Hadoop简介、Hadoop的重要组成和Apache Hadoop 完全分布式集群搭建。
一、Hadoop概述
1.1 Hadoop是什么
🔎Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
🔎Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
🔎Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
🔎Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力,主要解决海量数据的存储和海量数据的分析计算问题。
🔎几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
🔎狭义上说Hadoop就是一个框架平台,广义上讲Hadoop代表大数据的一个技术生态圈,包括很多其他软件框架,如下:
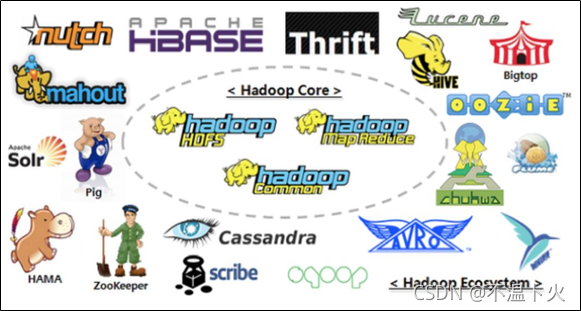
1.2 Hadoop的发展历程

🔍Hadoop最初是由Apache Lucene项目的创始人Doug Cutting开发的文本搜索库。Hadoop源自始于2002年的Apache Nutch项目――一个开源的网络搜索引擎并且也是Lucene项目的一部分。Nutch 是一个开源 Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫,但随着抓取网页数量的增加,遇到了严重的可扩展性问题――如何解决数十亿网页的存储和索引问题。
🔍 在2003年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身
🔍 2004年,谷歌公司又发表了另一篇具有深远影响的论文Google MapReduce,阐述了MapReduce分布式编程思想
💡你需要知道的三驾马车Google的三篇论文(三驾马车)分别是:
- GFS:Google的分布式文件系统(Google File System)
- MapReduce:Google的分布式计算框架
- BigTable:大型分布式数据库
💡发展演变关系::
- GFS ―> HDFS
- Google MapReduce ―> Hadoop MapReduce
- BigTable ―> HBase
🔍2005年,Nutch开源实现了谷歌的MapReduce
🔍到了2006年2月,Nutch中的NDFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时,Doug Cutting加盟雅虎
🔍 2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用
🔍2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒
🔍在2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准
📢Hadoop名字来源于Hadoop之父Doug Cutting儿子的毛绒玩具象:

1.3 Hadoop的特点
🔉Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:

🔍1.高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失

🔍2.高拓展性:在集群间分配任务数据,可方便的扩展数以千计的节点。

🔍3. 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
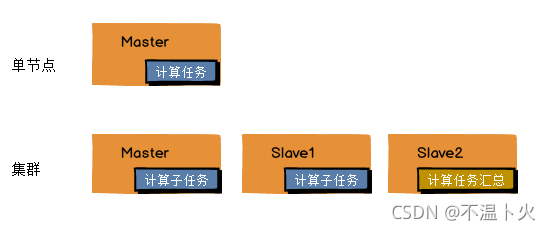
🔍4.高容错性:能够自动将失败的任务重新分配。

🔍5.低成本:Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据。以至于成本很低
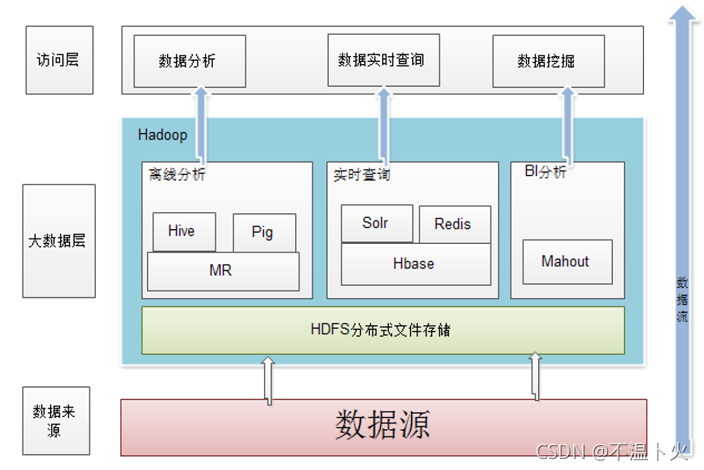
1.4 Hadoop的应用现状
🔉Hadoop在企业中的应用架构
1.5 Hadoop三大发行版本
目前Hadoop发行版非常多,有Cloudera发行版(CDH)、Hortonworks发行版、华为发行版、Intel发行版等,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,是由Apache Hadoop的开源协议决定的(任何人可以对其进行修改,并作为开源或商业产品发布/销售)。
企业中主要用到的三个版本分别是:Apache Hadoop版本(最原始的,所有发行版均基于这个版本进行改进)、Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)、Hortonworks版本(Hortonworks Data Platform,简称“HDP”)。
分别如下:
🔍Apache Hadoop
原始版本,学习环境使用。
????
????官网地址:http://hadoop.apache.org/
????
????优点:拥有全世界的开源贡献,代码更新版本比较快,学习非常方便
????
????缺点:版本的升级,版本的维护,以及版本之间的兼容性
????
????Apache所有软件的下载地址(包括各种历史版本):?http://archive.apache.org/dist/
🔍ClouderaManager(收费,部分开源)
CDH版本,生产环境使用。
????
????官网地址:https://www.cloudera.com/
????
????Cloudera主要是美国一家大数据公司,在Apache开源Hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境强烈推荐使用。
🔍HortonWorks(免费开源)
HDP版本,生产环境使用。
????
????官网地址:https://hortonworks.com/
????
????web管理界面软件HDF网址:http://ambari.apache.org/
????
????Hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态。因为HortonWorks已经被Cloudera收购,所以HDP的使用也可能会逐渐减少,商用以CDH为主。
1.6 ApacheHadoop版本变化及组成架构变化
Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0
第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则增加了NameNode HA等新的重大特性
第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性
Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,于是Hadoop社区基于JDK1.8重新发布一个新的Hadoop版本,也就是Hadoop3.0
🔍下图为Hadoop1.x与Hadoop2.x的组成:
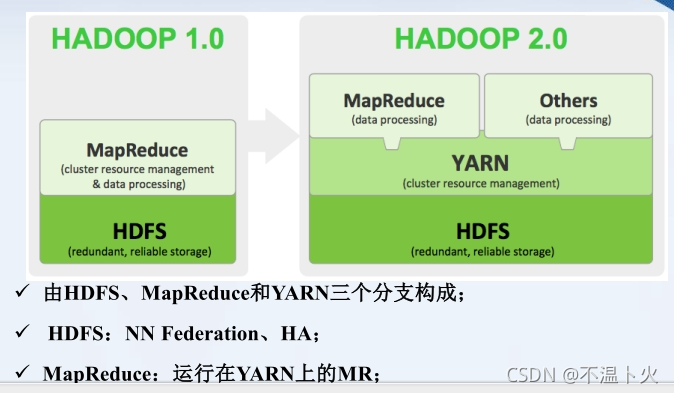
🔎在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
🔎在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算。
🔎Hadoop3.x在组成上没有变化。
1.6 Hadoop的重要组成
狭义的Hadoop由四部分组成:
- HDFS(分布式文件系统)
- MapReduce(分布式计算框架)
- Yarn(资源协调框架)
- Common模块
1.6.1 HDFS(Hadoop Distribute File System )――高可靠、高吞吐量的分布式文件系统
HDFS的思想是分而治之,主要功能如下:
-
数据切割
????将海量数据进行拆分,以保证可以在单台机器上进行保存。
????例如100T数据拆分为10G一个数据块由一个电脑节点存储这个数据块。 -
制作副本
????由于电脑可能出现宕机的情况,所以需要制作副本,让另外的电脑也保存相同的数据。 -
分散储存
????将数据切割后,分散存储在不同的机器上,同时在另外的机器上有相同数据的副本。
如下图所示:
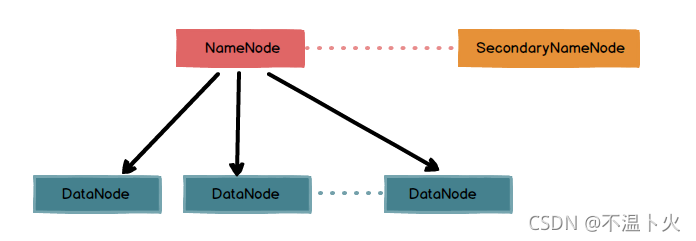
HDFS属于Master/Slave(主从架构):
NameNode(nn):
属于Master节点,主要负责管理和维护元数据:存储文件的元数据,元数据记录了文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode节点信息等。
????
SecondaryNameNode(2nn)
辅助NameNode管理和维护元数据,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据快照,对NameNode元数据备份。
DataNode(dn)
属于Slave节点,负责存储文件数据块:在本地文件系统存储文件块数据,以及块数据的校验
????
其中,NN、2NN、DN既是角色名称、进程名称,也代指电脑节点名称。
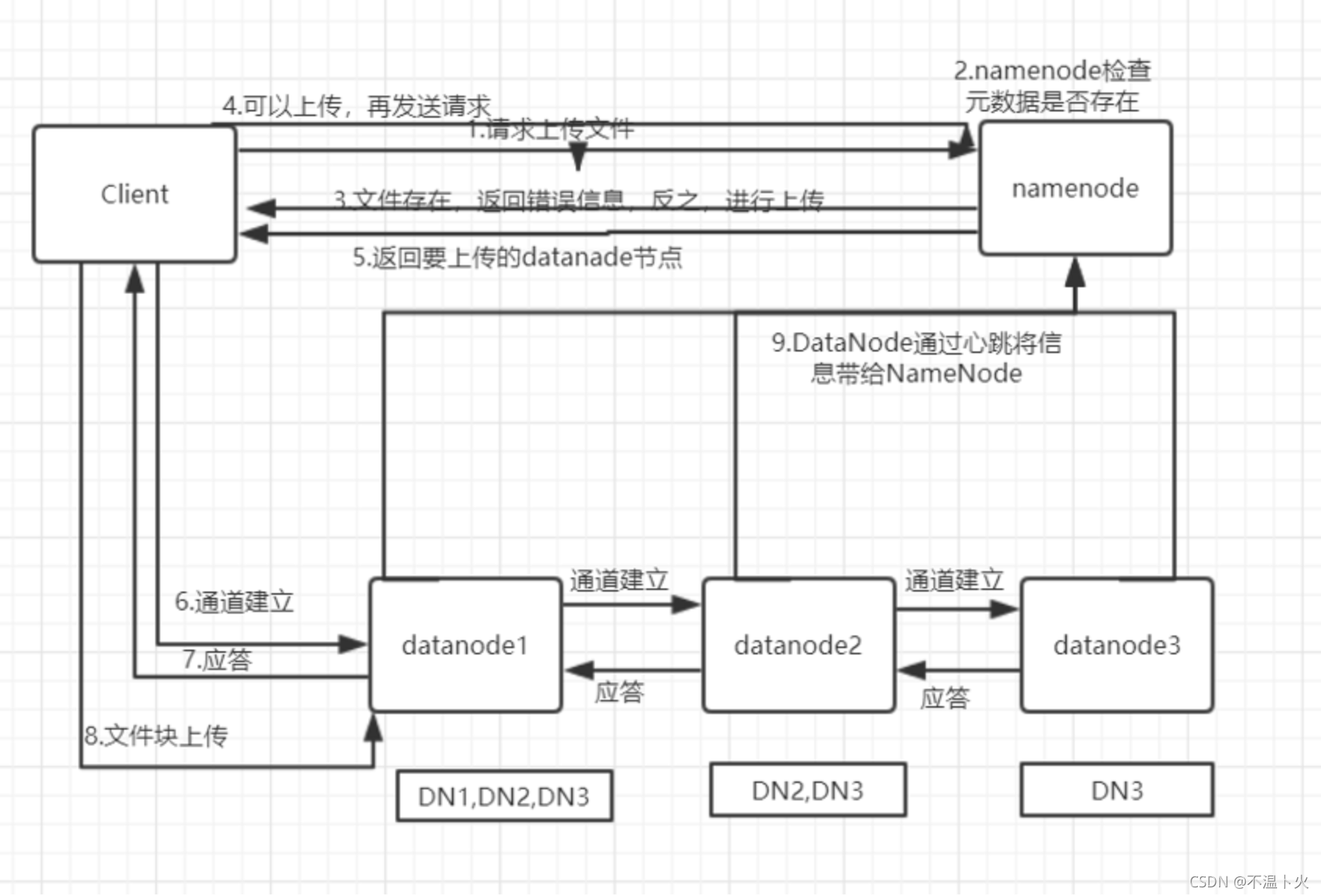
HDFS写入文件过程:
对于大数据进行拆分(切割)得到数据块,可能得到多个数据块,由多个DataNode进行存储。具体流程如下图所示:
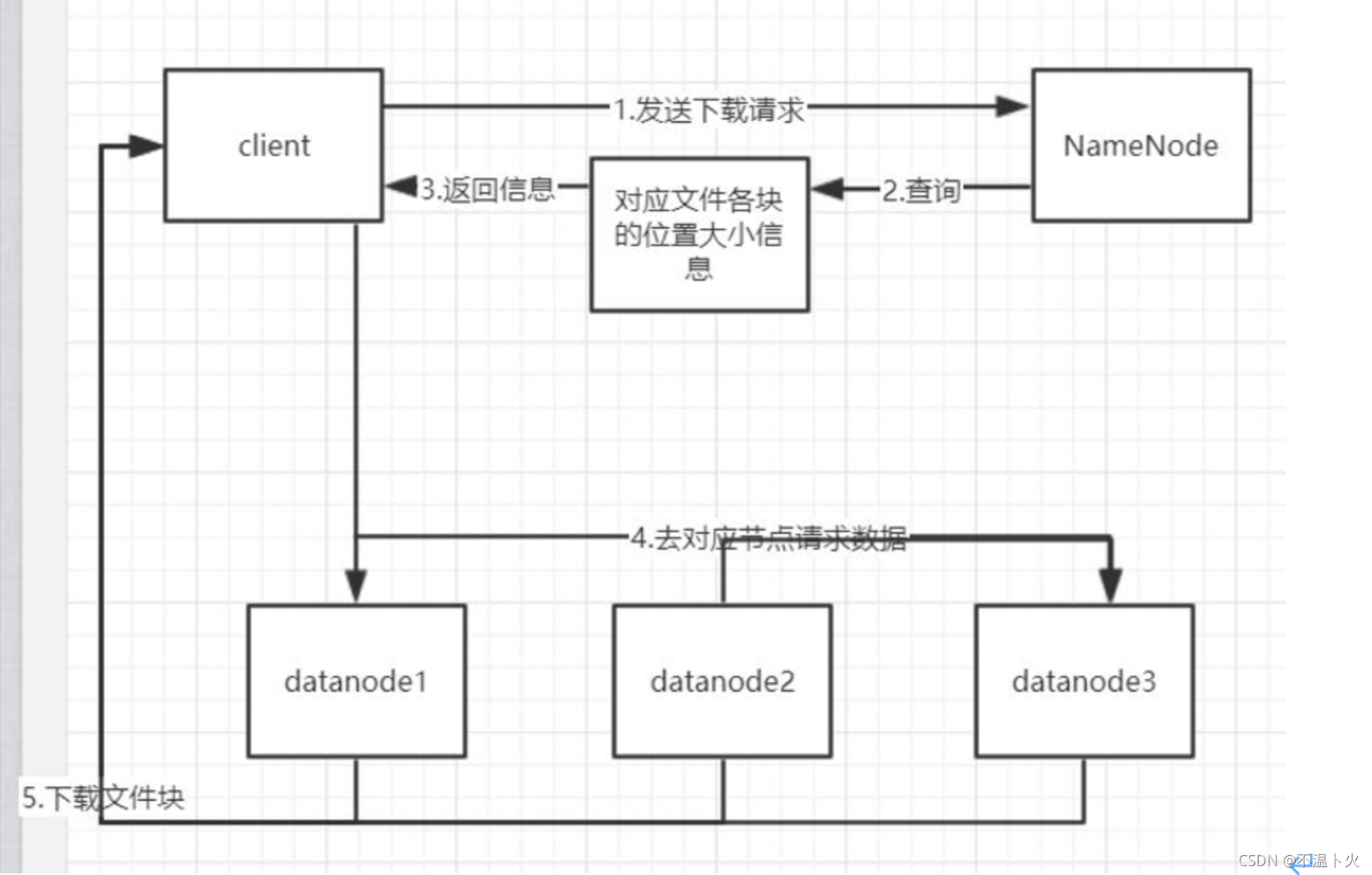
HDFS读取文件过程:
向NameNode请求获取到之前存入文件的块以及块所在的DataNode的信息,分别下载并最终合并,就得到之前的文件。具体流程如下图所示:
1.6.2 Hadoop MapReduce――一个分布式的离线并行计算框架
MapReduce的思想也是分而治之,主要功能如下:
- 拆解任务
将数据进行切分,得到切片。 - 分散处理
- 汇整结果
如下图所示:
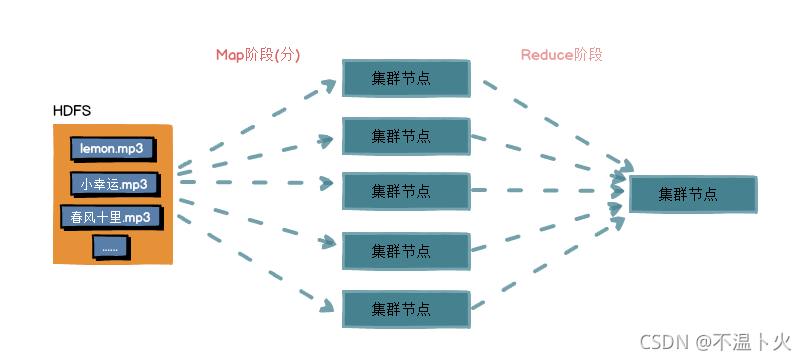
MapReduce将计算过程分为两个阶段:Map和Reduce
-
Map阶段就是“分”的阶段
将数据切分到多个节点后,多个节点并行处理 输入数据,即每个节点负责一份数据的计算,并得到部分结果。 -
Reduce阶段就是“合”的阶段
对Map阶段的输出结果进行汇总,得到全局的结果。
1.6.3 Hadoop Yarn――作业调度与集群资源管理的框架
Yarn负责集群中计算资源的分配和作业任务的调度:
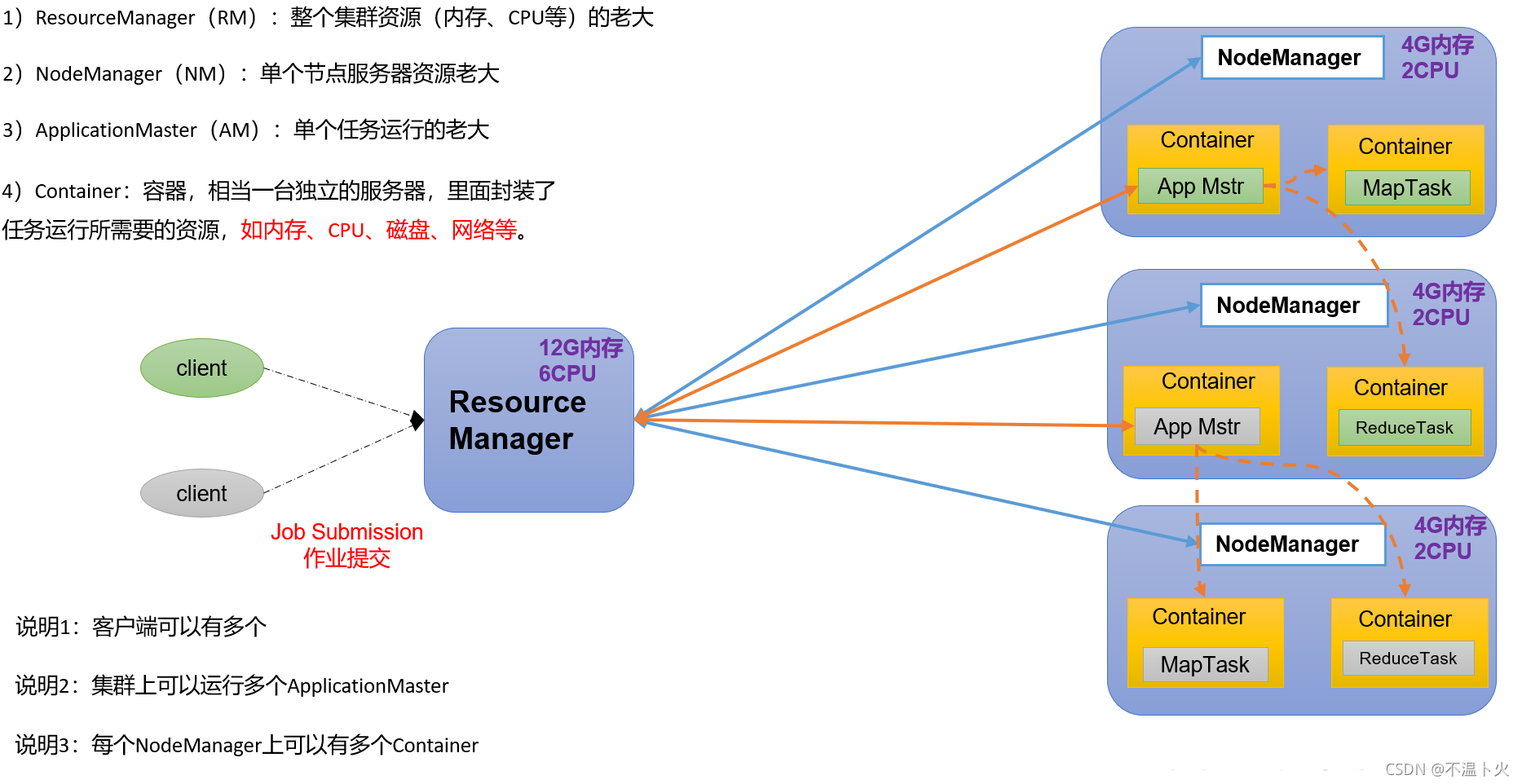
Yarn架构也是主从架构主要角色如下:
-
ResourceManager(rm)
是Master,处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度。 -
NodeManager(nm)
是Slave,单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令。 -
ApplicationMaster(am)
是计算任务专员,数据切分、为应用程序(任务)申请资源,并分配给内部任务、任务监控与容错。 -
Container
对任务运行环境的抽象,一个Container负责一个Task,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息,可以理解为虚拟资源集合或小型计算机。
1.6.4 HDFS、YARN、MapReduce三者之间的关系
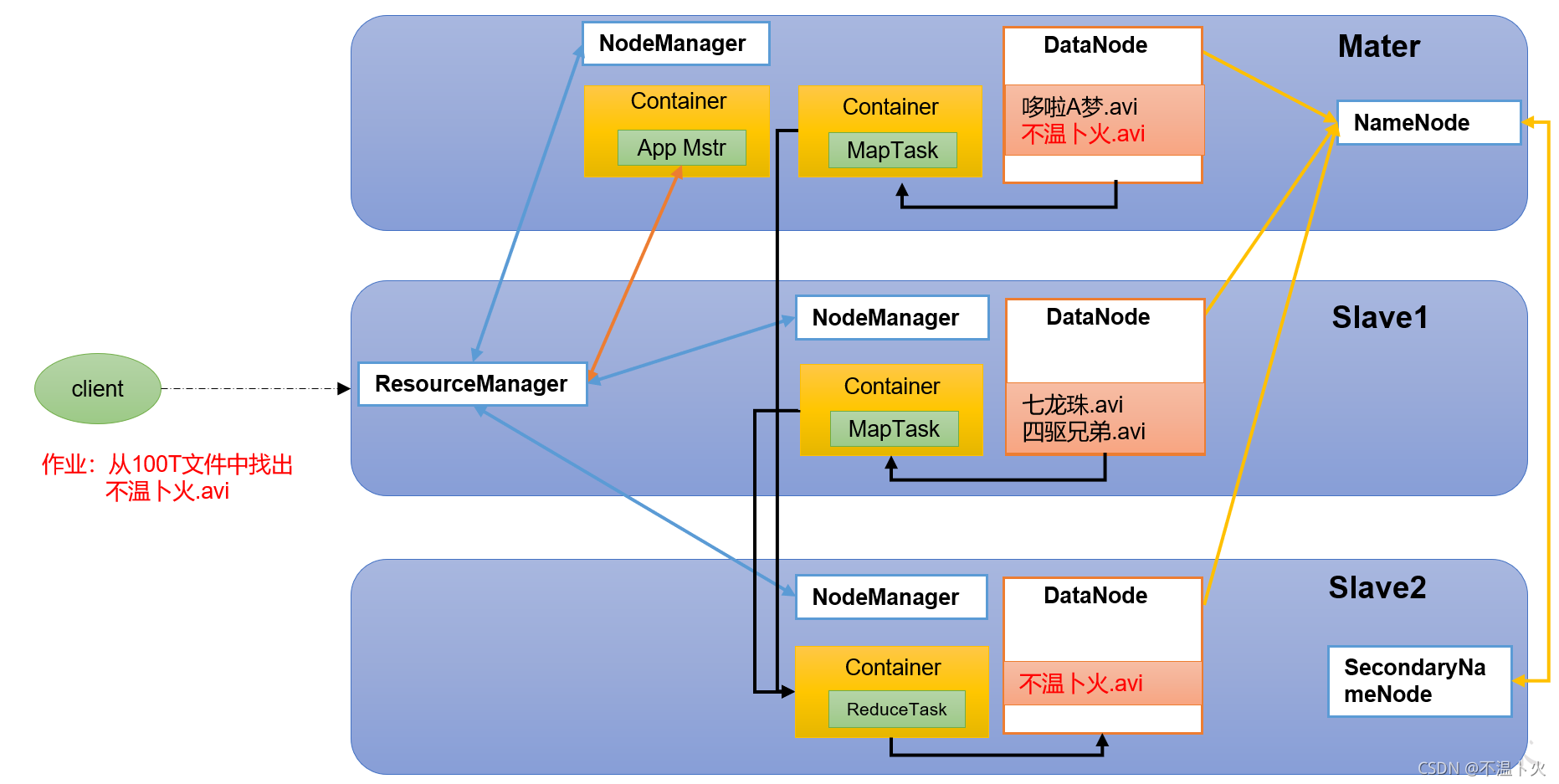
1.6.5 Hadoop Common――支持其他模块的工具模块
包括以下几部分:
- Configuration
公共的配置,包括集群节点、节点资源、IP、主机名、参数等配置项 - RPC
远程过程调用,是分布式框架中多个节点之间进行网络通讯的首选方式,高效、稳定、安全,Hadoop中实现了Hadoop RPC框架。 - 序列化机制
- 日志操作
1.7 大数据技术生态体系
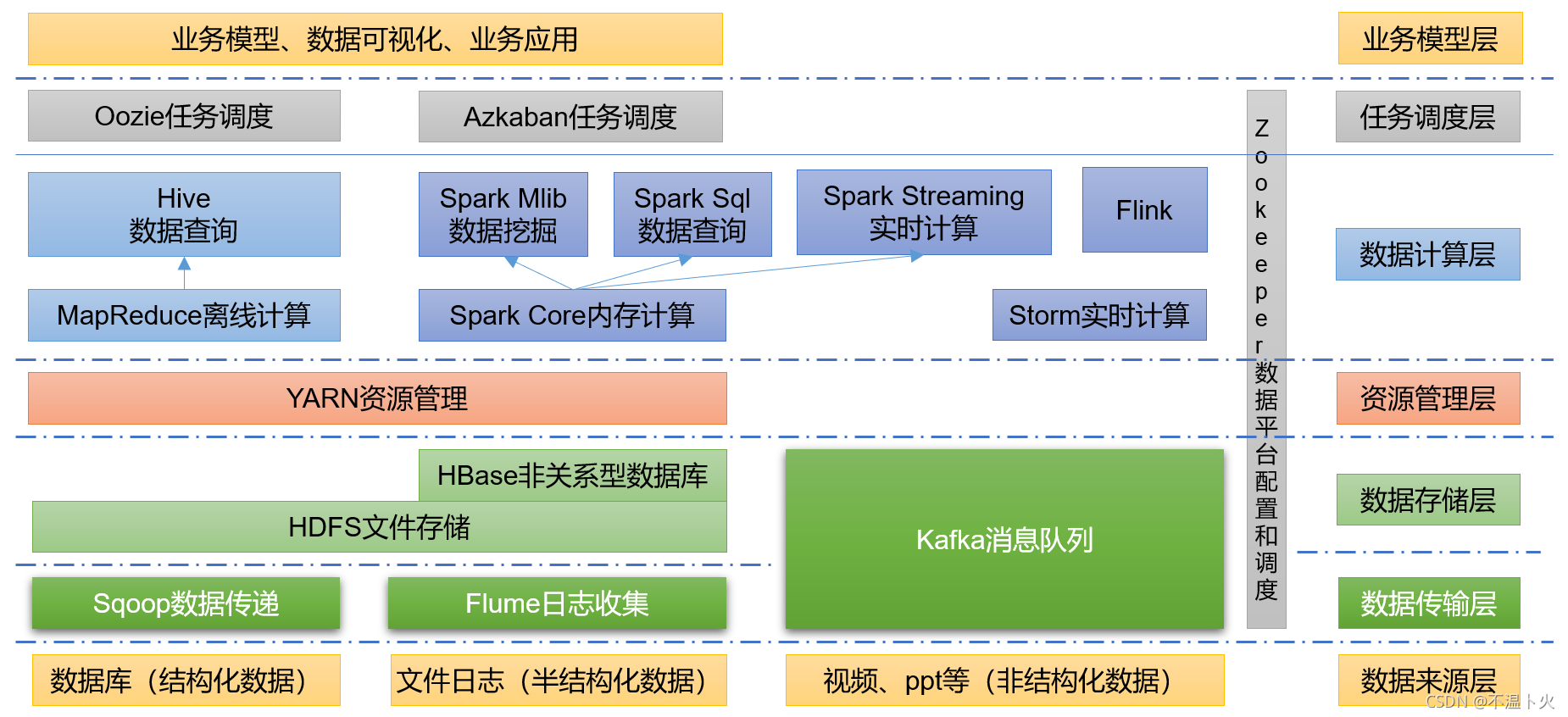
图中所设计的技术名词解释如下:
| 大数据技术生态体系 |
|---|
| Hadoop(HDFS + MapReduce + Yarn) |
| Hive 数据仓库 |
| HBase Hadoop上的非关系型的分布式数据库 |
| Sqoop 一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 |
| Sqoop 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie Hadoop上的工作流管理系统 |
| Zookeeper 提供分布式协调一致性服务 |
| Kafka 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Ambari Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Flink 当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。 |
| … … |
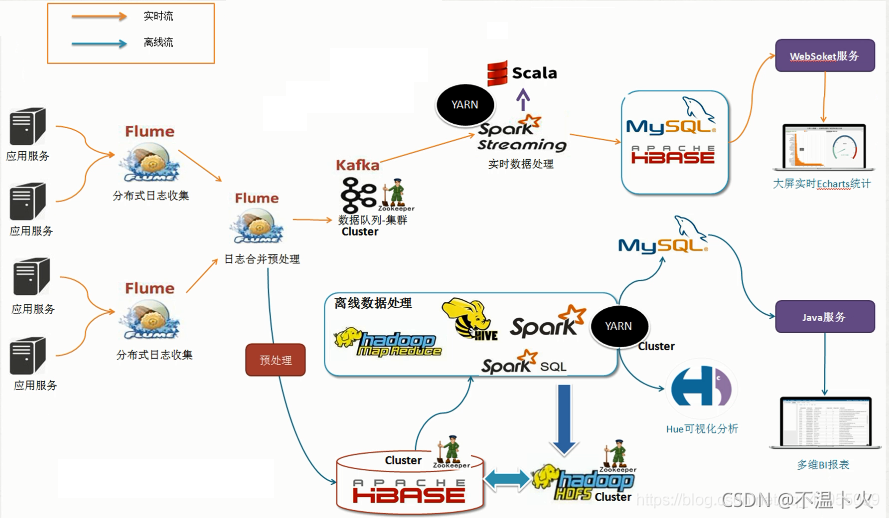
1.8 常见大数据项目所使用的技术分类
根据项目可以划分为实时流和离线流,如下图所示:
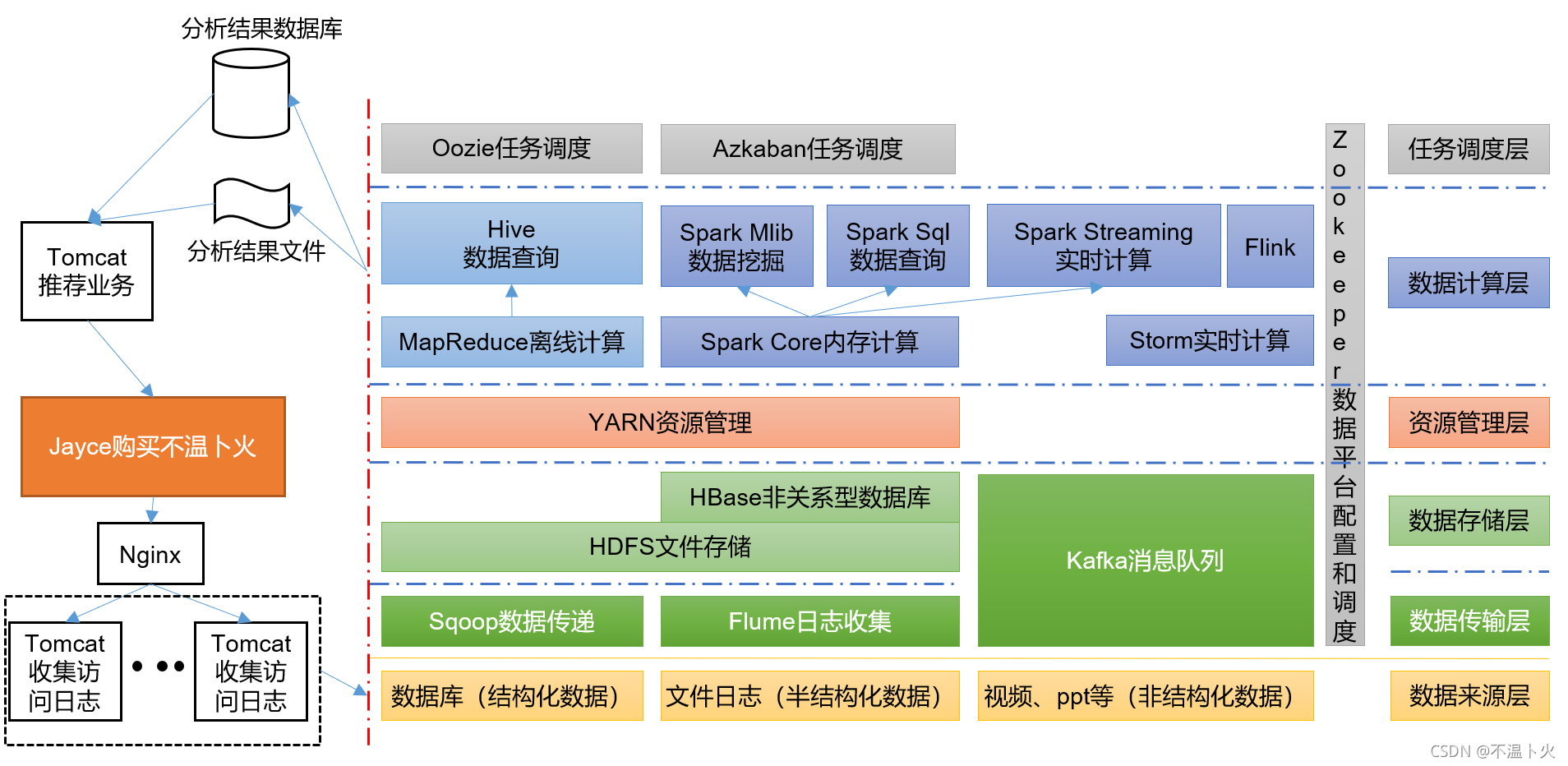
1.9 推荐系统结构图
下图为传统的推荐系统的架构:
二、前提准备
2.1 虚拟机环境准备
2.1.1 下载安装虚拟机
由于本校使用Ubuntu作为操作系统,因此本系列教程采用Ubuntu 16.04 64位作为系统环境(或者Ubuntu 14.04,Ubuntu18.04 也行,32位、64位均可)。
在此给出系统镜像下载地址(Kylin 此处不推荐):
Ubuntu 历史版本下载
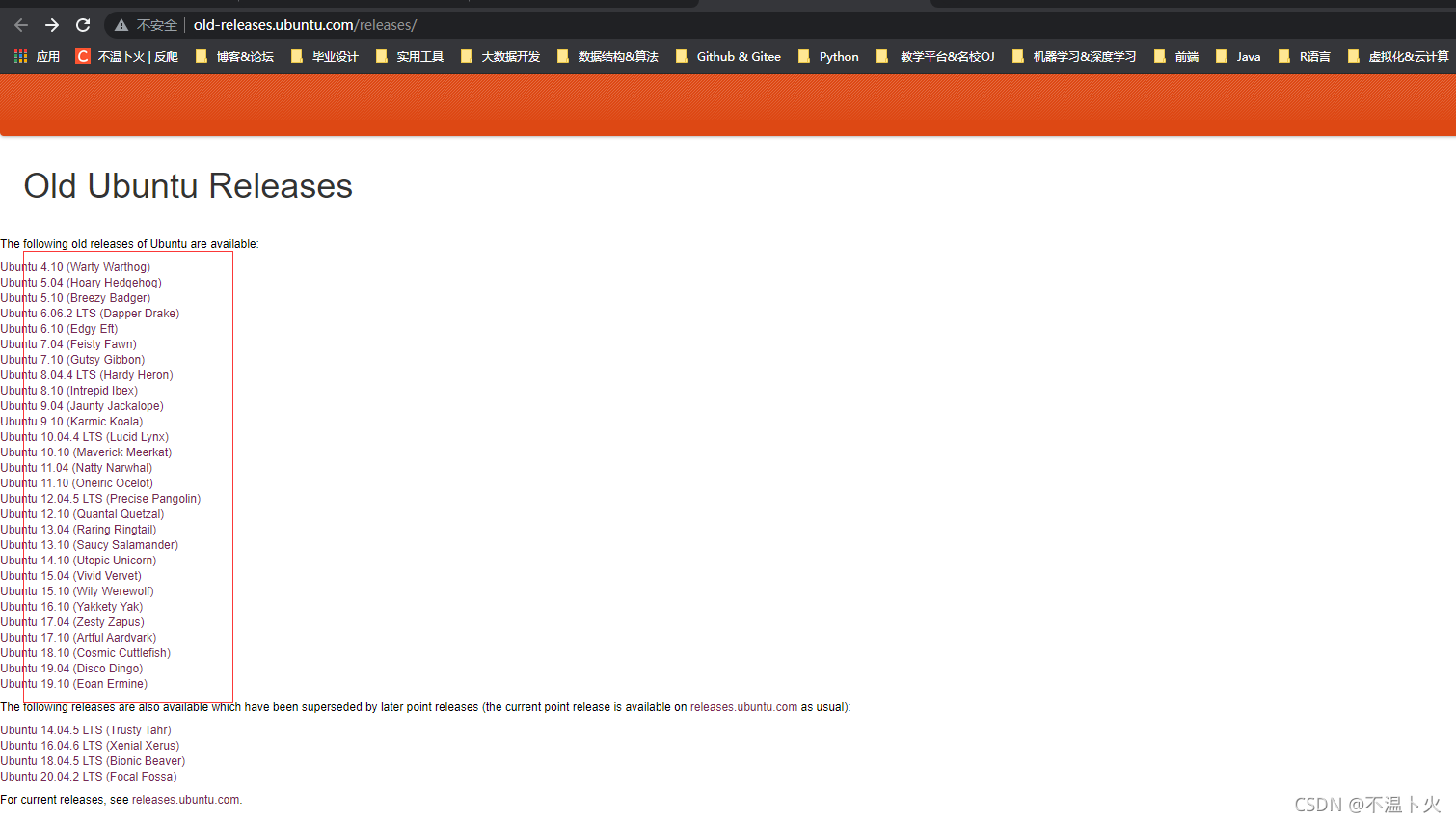
如何下载,以下载Ubuntu历史版本为例:
🔎1.打开网址
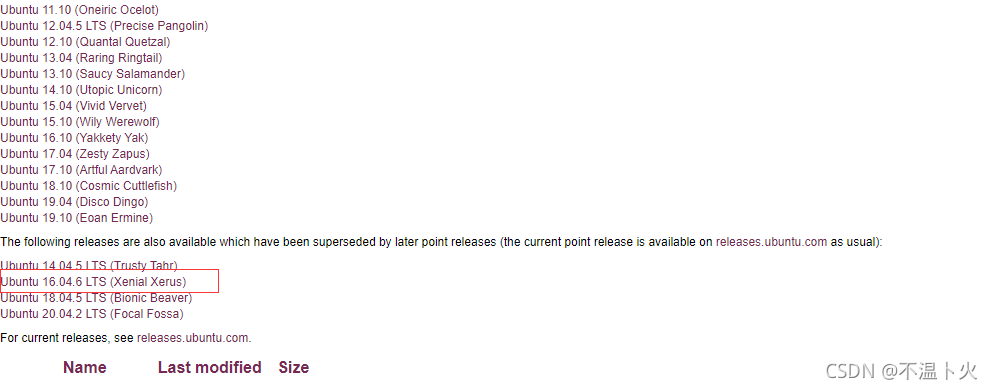
🔎2.选择想要下载的历史版本,在此以Ubuntu 16.04.1 LTS (Xenial Xerus)为例
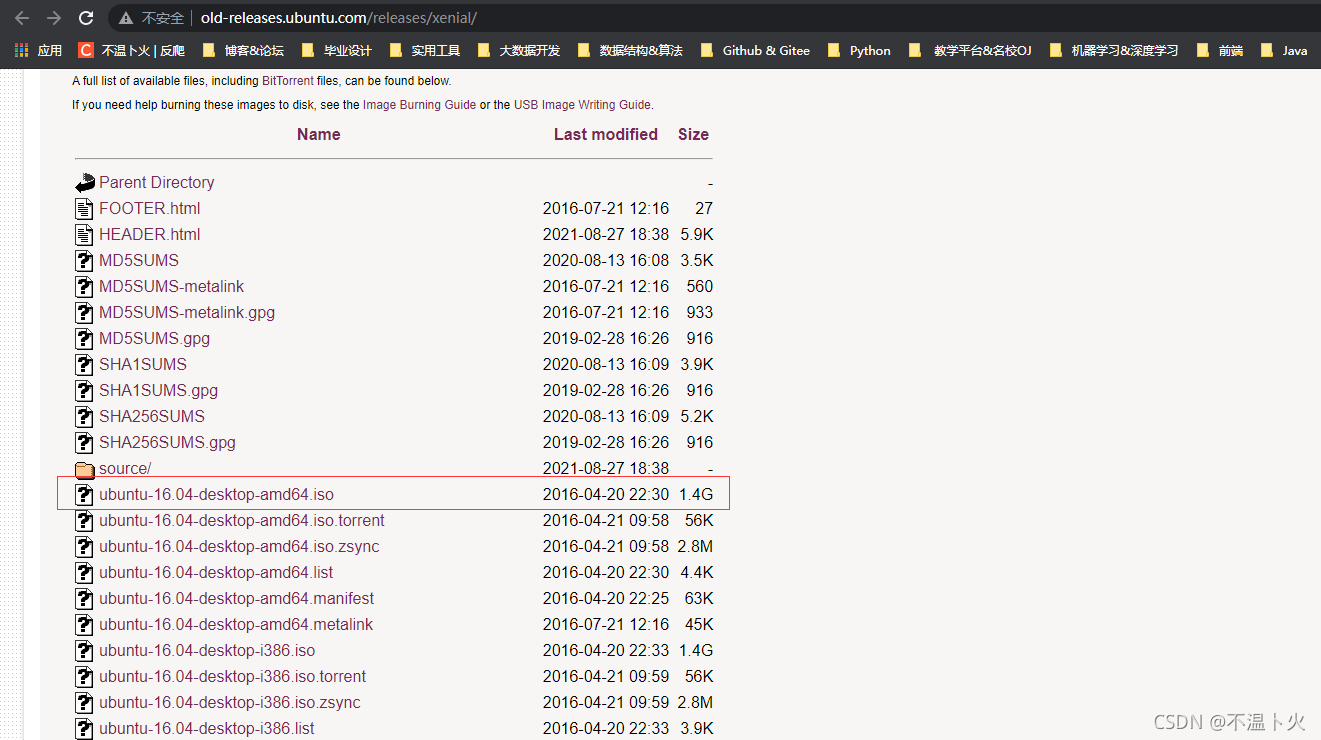
🔎3. 选择镜像进行下载
下载完成后,下面就是安装了。但是由于此部分主要讲解环境搭建,所以安装这一过程在此省略。下面直接从装好Ubuntu系统开始讲解。
2.1.2 创建Hadoop用户
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
# 创建可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell
buwenbuhuo@ubuntu:/opt/moudle$ sudo useradd -m hadoop -s /bin/bash
📣你需要知道的一些知识:
🔎sudo命令
本文中会大量使用到sudo命令。sudo是ubuntu中一种权限管理机制,管理员可以授权给一些普通用户去执行一些需要root权限执行的操作。当使用sudo命令时,就需要输入您当前用户的密码.
🔎密码
在Linux的终端中输入密码,终端是不会显示任何你当前输入的密码,也不会提示你已经输入了多少字符密码。而在windows系统中,输入密码一般都会以“*”表示你输入的密码字符
🔎Ubuntu终端复制粘贴快捷键
在Ubuntu终端窗口中,复制粘贴的快捷键需要加上 shift,即粘贴是 ctrl+shift+v。
# 使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码
buwenbuhuo@ubuntu:/opt/moudle$ sudo passwd hadoop
# 如下命令可为hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题
buwenbuhuo@ubuntu:/opt/moudle$ sudo adduser hadoop sudo
最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
2.1.3 重置root密码并配置免密登录
Ubuntu安装完成后,一般默认密码你是不知道的,这个时候我们可以通过重置root密码进行解决。
🔍1. 修改密码
hadoop@ubuntu:~$ sudo passwd root # 重置root密码
输入新的 UNIX 密码: # 一般密码都不显示,直接输入回车即可
重新输入新的 UNIX 密码:
passwd: password updated successfully # 提示你修改成功
🔍2. 切换成root账户
hadoop@ubuntu:~$ su root # 切换到root账户
密码: # 输入密码,一会进行配置免密登录就可不用再次输入
root@ubuntu:/home/hadoop# # 成功切换到root账户
🔍3. 修改/etc/sudoers配置文件
root@ubuntu:/home/hadoop# vim /etc/sudoers
...
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL # 此处为要修改部分,hadoop为你自己的账户名
...
🔍4. 测试免密

2.1.4 更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
hadoop@ubuntu:~$ sudo apt-get update

若出现如下 “Hash校验和不符” 的提示,可通过更改软件源来解决。若没有该问题,则不需要更改。从软件源下载某些软件的过程中,可能由于网络方面的原因出现没法下载的情况,那么建议更改软件源。在学习Hadoop过程中,即使出现“Hash校验和不符”的提示,也不会影响Hadoop的安装。
关于如何更改软件源,林子雨老师的博客已经给出答案。如有兴趣可自行查看。
后续需要更改一些配置文件,我比较喜欢用的是 vim(vi增强版,基本用法相同),建议安装一下(如果你实在还不会用 vi/vim 的,请将后面用到 vim 的地方改为 gedit,这样可以使用文本编辑器进行修改,并且每次文件更改完成后请关闭整个 gedit 程序,否则会占用终端):
hadoop@ubuntu:~$ sudo apt-get install vim
安装软件时若需要确认,在提示处输入 y 即可。

2.1.5 安装SSH、配置SSH无密码登陆
🌟在进行免密登录配置之前,我们需要先了解免密登录的原理,如下图所示:
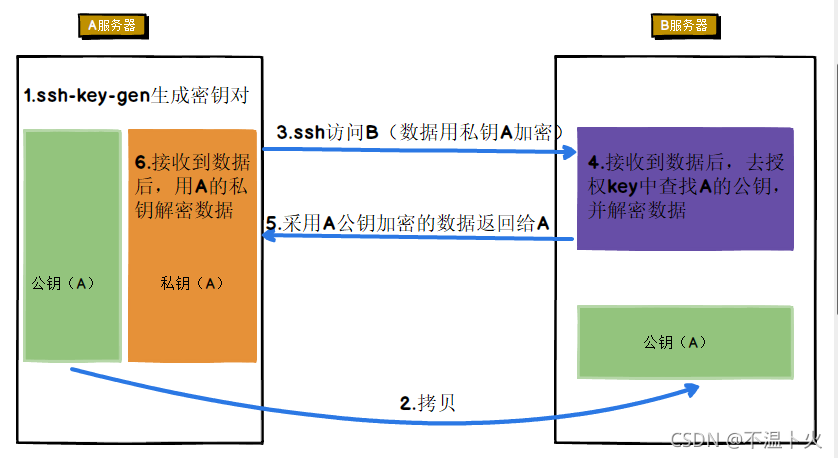
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
hadoop@ubuntu:~$ sudo apt-get install openssh-server

安装后,可以使用如下命令登陆本机:
hadoop@ubuntu:~$ ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
hadoop@ubuntu:~$ exit # 退出刚才的 ssh localhost
hadoop@ubuntu:~$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
hadoop@ubuntu:~$ ssh-keygen -t rsa # 会有提示,都按回车就可以,三个回车
hadoop@ubuntu:~$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
🌟.ssh文件夹下~/.ssh的文件功能解释
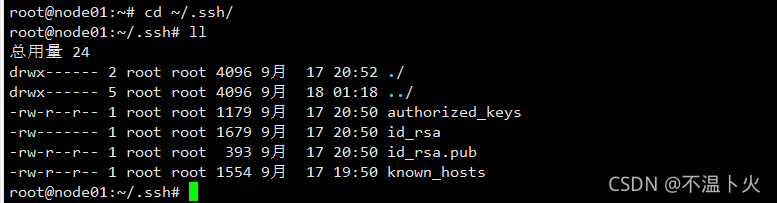
| 名称 | 含义 |
|---|---|
| authorized_keys | 存放授权过的无密登录服务器公钥 |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
📣~的含义
在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 后面的文字是注释,只需要输入前面命令即可。
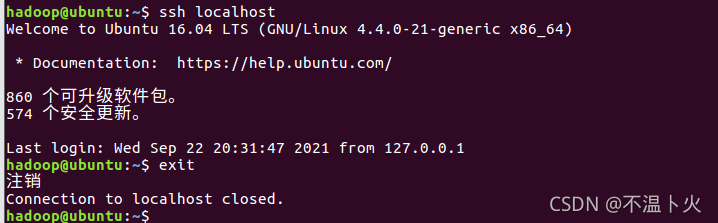
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
2.1.6 安装WMware Tools
VMware Tools是一套可以提高虚拟机客户机操作系统性能并改善虚拟机管理的实用工具。如果你还对安装WMware Tools有什么疑惑,我们不妨看下它的功能,其功能如下:
🔍1、支持Aero的操作系统上大大提升的图形性能和WindowsAero体验
🔍2、使虚拟机中的应用程序像其他任何应用程序窗口一样显示在主机桌面上的Unity功能
🔍3、主机与客户机文件系统之间的共享文件夹
🔍4、在虚拟机与主机或客户端桌面之间复制并粘贴文本、图形和文件。效果如下图所示:

🔍5、改进的鼠标性能
🔍6、虚拟机中的时钟与主机或客户端桌面上的时钟同步
🔍7、帮助自动执行客户机操作系统操作的脚本
🔍8、启用虚拟机的客户机自定义。
安装VMware Tools可以大大提升图形化性能,对于初学者而言很有必要。当然,此部分并非必要,因为还可以使用第三方连接工具如Xshell等进行连接。
下面讲解下如何安装
🔎1. 虚拟机―> 重新安装WMware Tools―>复制到自己想存放的位置

🔎1.解压缩WMware Tools
root@ubuntu:~# cd /opt/software/ # 进入到WMware Tools存放目录
root@ubuntu:/opt/software# ll # 查看当前文件夹内存在的内容
drwxrwxrwx 2 root root 4096 9月 22 19:11 ./
drwxr-xr-x 4 root root 4096 9月 15 19:51 ../
-rw-rw-r-- 1 hadoop hadoop 56435756 2月 20 2019 VMwareTools-10.3.10-12406962.tar.gz
root@ubuntu:/opt/software# tar -zxvf VMwareTools-10.3.10-12406962.tar.gz -C /opt/moudle/ # 解压缩文件
🔎2.安装WMware Tools
root@ubuntu:/opt/software# cd /opt/moudle/ # 进入到解压缩目录
root@ubuntu:/opt/moudle# ll
总用量 20
drwxr-xr-x 5 root root 4096 9月 22 19:34 ./
drwxr-xr-x 4 root root 4096 9月 15 19:51 ../
drwxr-xr-x 9 root root 4096 2月 20 2019 vmware-tools-distrib/
root@ubuntu:/opt/moudle# cd vmware-tools-distrib/
root@ubuntu:/opt/moudle/vmware-tools-distrib# ll
总用量 408
drwxr-xr-x 9 root root 4096 2月 20 2019 ./
drwxr-xr-x 5 root root 4096 9月 22 19:34 ../
drwxr-xr-x 2 root root 4096 2月 20 2019 bin/
drwxr-xr-x 5 root root 4096 2月 20 2019 caf/
drwxr-xr-x 2 root root 4096 2月 20 2019 doc/
drwxr-xr-x 5 root root 4096 2月 20 2019 etc/
-rw-r--r-- 1 root root 146996 2月 20 2019 FILES
-rw-r--r-- 1 root root 2538 2月 20 2019 INSTALL
drwxr-xr-x 2 root root 4096 2月 20 2019 installer/
drwxr-xr-x 14 root root 4096 2月 20 2019 lib/
drwxr-xr-x 3 root root 4096 2月 20 2019 vgauth/
-rwxr-xr-x 1 root root 227024 2月 20 2019 vmware-install.pl* # 此处为安装文件
oot@ubuntu:/opt/moudle/vmware-tools-distrib# ./vmware-install.pl # 进行安装 安装过程中出现yes/no 全部默认回车即可,安装完成后重启生效。
root@ubuntu:/opt/moudle/vmware-tools-distrib# reboot # 执行重启命令
2.1.7 安装Jdk
一般主流都不会选择最新版本,为求稳定大都会选择Jdk8。此处选择jdk-8u162-linux-x64作为Jdk。
官方链接(需注册oracle账户):Jdk 历史版本下载
学长在此给出自己使用的JDK:https://pan.baidu.com/s/1c1V66MGf5gwZ2ZhW6RP6vw 提取码:4e8f
🔎1. Jdk解压
hadoop@ubuntu:/opt/software$ ll
总用量 1849704
drwxrwxrwx 2 root root 4096 9月 22 19:11 ./
drwxr-xr-x 4 root root 4096 9月 15 19:51 ../
-rw-rw-r-- 1 hadoop hadoop 189815615 9月 15 19:49 jdk-8u162-linux-x64.tar.gz
-rw-rw-r-- 1 hadoop hadoop 56435756 2月 20 2019 VMwareTools-10.3.10-12406962.tar.gz
hadoop@ubuntu:/opt/software$ sudo tar -zxvf jdk-8u162-linux-x64.tar.gz -C /opt/moudle/ #把JDK文件解压到/opt/moudle目录下
hadoop@ubuntu:/opt/software$ cd /opt/moudle/
hadoop@ubuntu:/opt/moudle/$ ll
总用量 20
drwxr-xr-x 5 root root 4096 9月 22 20:05 ./
drwxr-xr-x 24 root root 4096 9月 15 18:18 ../
drwxr-xr-x 8 uucp 143 4096 12月 20 2017 jdk1.8.0_162/ # 我们可以看到已经解压成功
hadoop@ubuntu:/opt/moudle/ $ sudo mv jdk1.8.0_162/ jdk1.8 # 通常习惯吧版本号简化些,这样方便以后配置文件
hadoop@ubuntu:/opt/moudle/ $ ll
总用量 20
drwxr-xr-x 5 root root 4096 9月 22 20:07 ./
drwxr-xr-x 24 root root 4096 9月 15 18:18 ../
drwxr-xr-x 8 uucp 143 4096 12月 20 2017 jdk1.8/

🔎2. 设置环境变量
hadoop@ubuntu:/opt/moudle$ sudo vim ~/.bashrc
# 下面为要添加的部分
# Java_HOME
export JAVA_HOME=/opt/moudle/jdk1.8 # 自己解压目录位置
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 继续执行如下命令让.bashrc文件的配置立即生效
hadoop@ubuntu:/opt/moudle$ source ~/.bashrc
🔎3. 查看是否安装成功
hadoop@ubuntu:/opt/moudle$ java -version
如果能够在屏幕上返回如下信息,则说明安装成功:

至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
2.1.8 安装Hadoop
🔎 1.Hadoop下载
我们可以到Hadoop官网下载hadoop-3.1.3.tar.gz
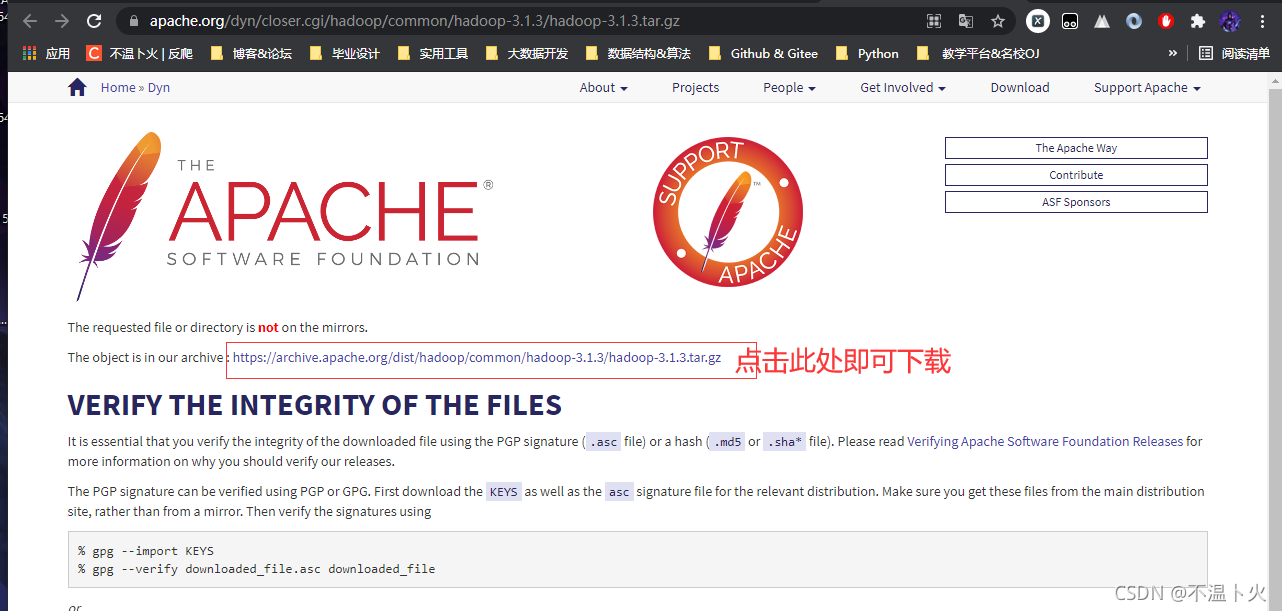
也可以在https://archive.apache.org/dist/hadoop/common/中选择合适的版本进行下载,这里选择3.1.3版本。
🔎 2.Hadoop上传
可以先点击https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz下载到本地,再使用上传到虚拟机的/opt/software目录下,也可以直接在虚拟机的/opt/software目录下执行wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz进行下载,可以根据需要选择。
🔎 3. 使用参考
在使用时,可以参考Hadoop官方文档:https://hadoop.apache.org/docs/r3.1.3/
🔎 4. 解压文件
我们选择将 Hadoop 安装至 /opt/moudle/ 中:
hadoop@ubuntu:/opt/software$ sudo tar -zxvf hadoop-3.1.3.tar.gz -C /opt/moudle/ # 解压到/opt/moudle中
hadoop@ubuntu:/opt/software$ cd /opt/moudle/
hadoop@ubuntu:/opt/moudle$ sudo mv hadoop-3.1.1 hadoop # 将文件夹名改为hadoop
hadoop@ubuntu:/opt/moudle$ sudo chown -R hadoop:hadoop hadoop # 修改文件权限

🔎 5. 查看版本信息
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
hadoop@ubuntu:/opt/moudle/hadoop$ ./bin/hadoop version
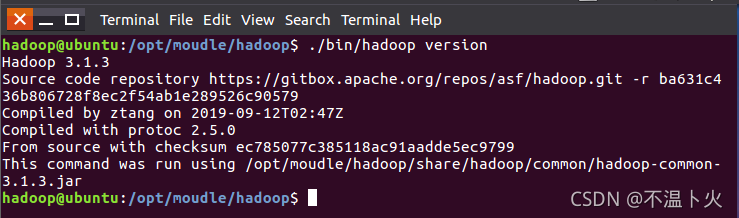
📢相对路径与绝对路径
请务必注意命令中的相对路径与绝对路径,后续出现的 ./bin/...,./etc/... 等包含 ./ 的路径,均为相对路径,以 /opt/moudle/hadoop 为当前目录。例如在/opt/moudle/hadoop 目录中执行 ./bin/hadoop version 等同于执行 /opt/moudle/hadoop/bin/hadoop version。可以将相对路径改成绝对路径来执行,但如果你是在主文件夹 ~ 中执行 ./bin/hadoop version,执行的会是 /home/hadoop/bin/hadoop version,就不是我们所想要的了。
🔎 6. 配置Hadoop的PATH变量
hadoop@ubuntu:/opt/moudle/hadoop$ vim ~/.bashrc
# 要添加的部分
export PATH=$PATH:/opt/moudle/hadoop/bin:/opt/moudle/hadoop/sbin
hadoop@ubuntu:/opt/moudle/hadoop$ source ~/.bashrc # 使立即生效
配置以后就可以在任意目录中直接使用hadoop、hdfs等命令了。
2.2 windows主机环境准备
2.2.1 修改windows的主机映射文件(hosts文件)
🔎1.进入C:\Windows\System32\drivers\etc路径
🔎2.打开hosts文件并添加如下内容,然后保存
192.168.2.5 hadoop
192.168.2.6 master
192.168.2.7 slave1
192.168.2.8 slave2
192.168.2.9 slave3
2.2.2 配置Java环境
一般主流都不会选择最新版本,为求稳定大都会选择Jdk8。
学长在此给出自己使用的JDK:https://pan.baidu.com/s/1c1V66MGf5gwZ2ZhW6RP6vw 提取码:4e8f
🔎1. Jdk解压(随意解压到任意目录)
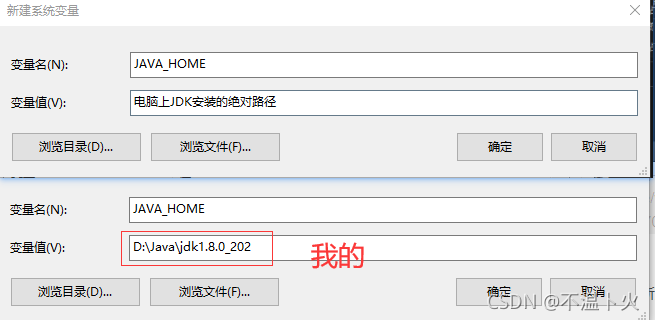
🔎2. 新建JAVA_HOME 变量
变量名:JAVA_HOME
变量值:电脑上JDK安装的绝对路径
JDK 路径下必须能够看到如下的文件。
🔎3.新建/修改 CLASSPATH 变量
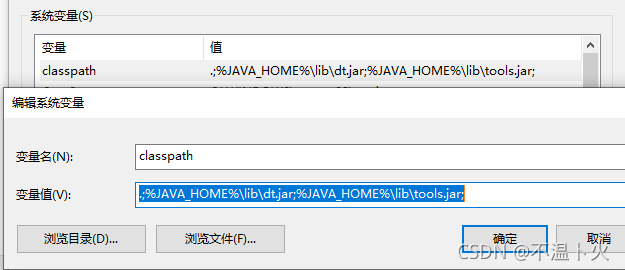
如果存在 CLASSPATH 变量,选中点击 Edit(编辑)。
如果没有,点击 New(新建)… 新建。
输入/在已有的变量值后面添加:
变量名:CLASSPATH
变量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
点击 OK 保存.
🔎4.修改Path 变量
由于 win10 的不同,当选中 Path 变量的时候,系统会很方便的把所有不同路径都分开了,不会像 win7 或者 win8 那样连在一起。
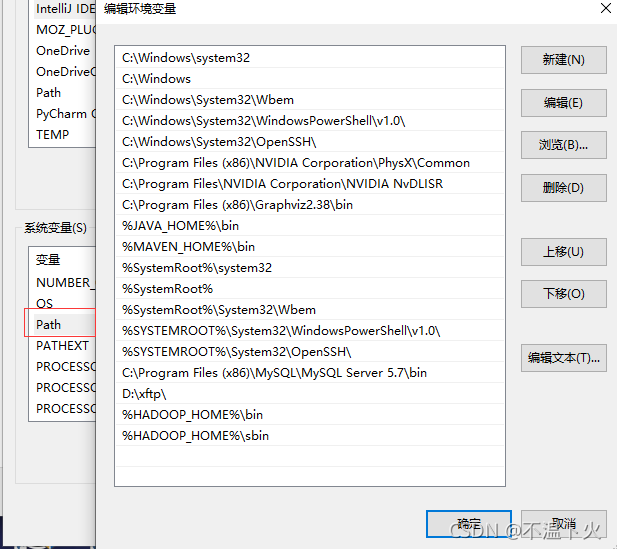
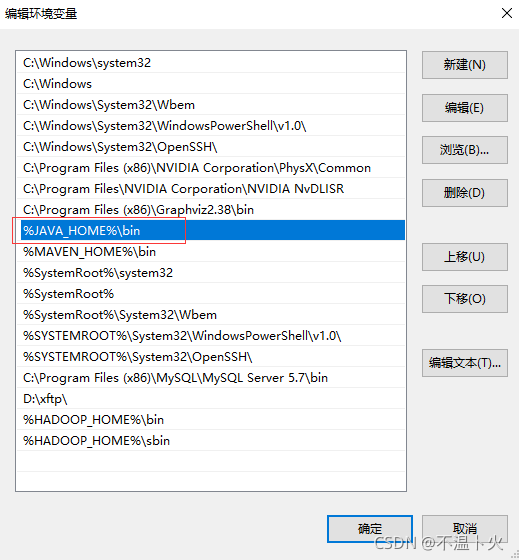
新建两条路径:
%JAVA_HOME%\bin
%JAVA_HOME%\jre\bin
🔎5.查看是否配置成功
打开 cmd,输入 java,出现一连串的指令提示,说明配置成功了:
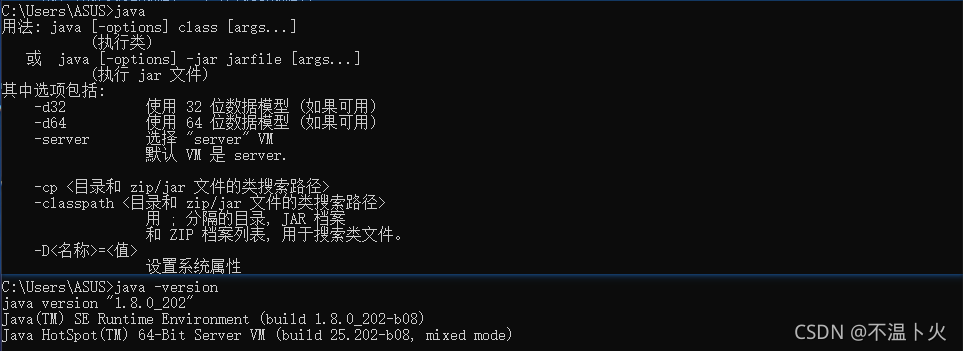
2.2.3 配置Hadoop环境(如果想在本机操作此过程是必须要做的)
Windows版本的Hadoop需要进行重新编译才可以使用,在此为了方便就直接给出编译完成的版本,链接:
链接:https://pan.baidu.com/s/1lLQCza1Hc4hK1Hqv9sAOgw 提取码:l76k
🔎1.Hadoop解压(随意解压到任意目录)
🔎2.配置HADOOP_HOME

🔎3.配置Path
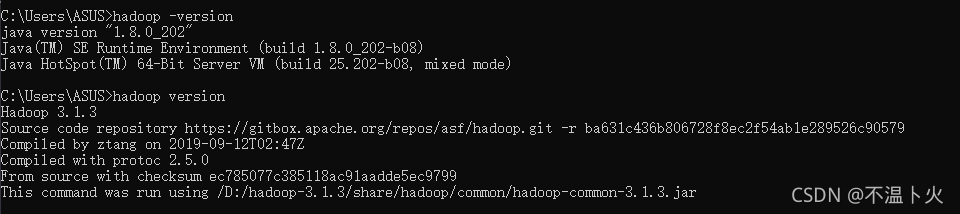
🔎4.检查版本号
🔎5.启动测试
D:\hadoop-3.1.3\sbin>start-dfs.cmd
D:\hadoop-3.1.3\sbin>start-yarn.cmd
如果出现以下四个界面说明成功:
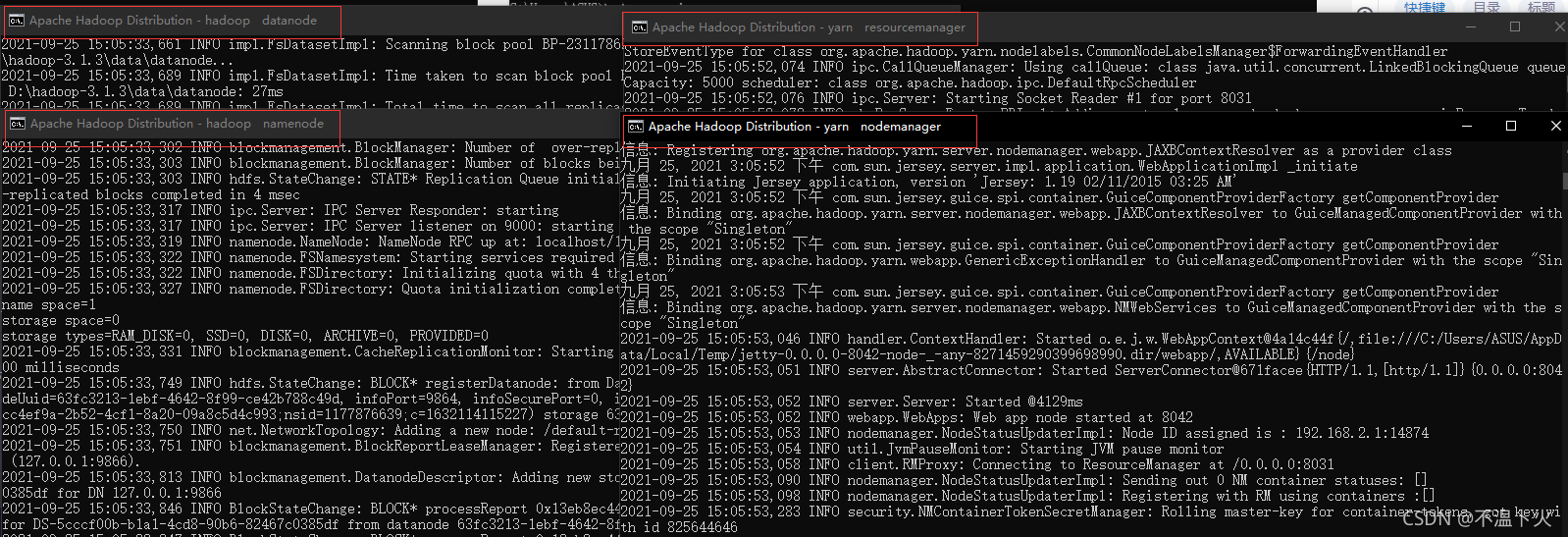
也可以查看UI界面。
http://localhost:9870
http://localhost:8088
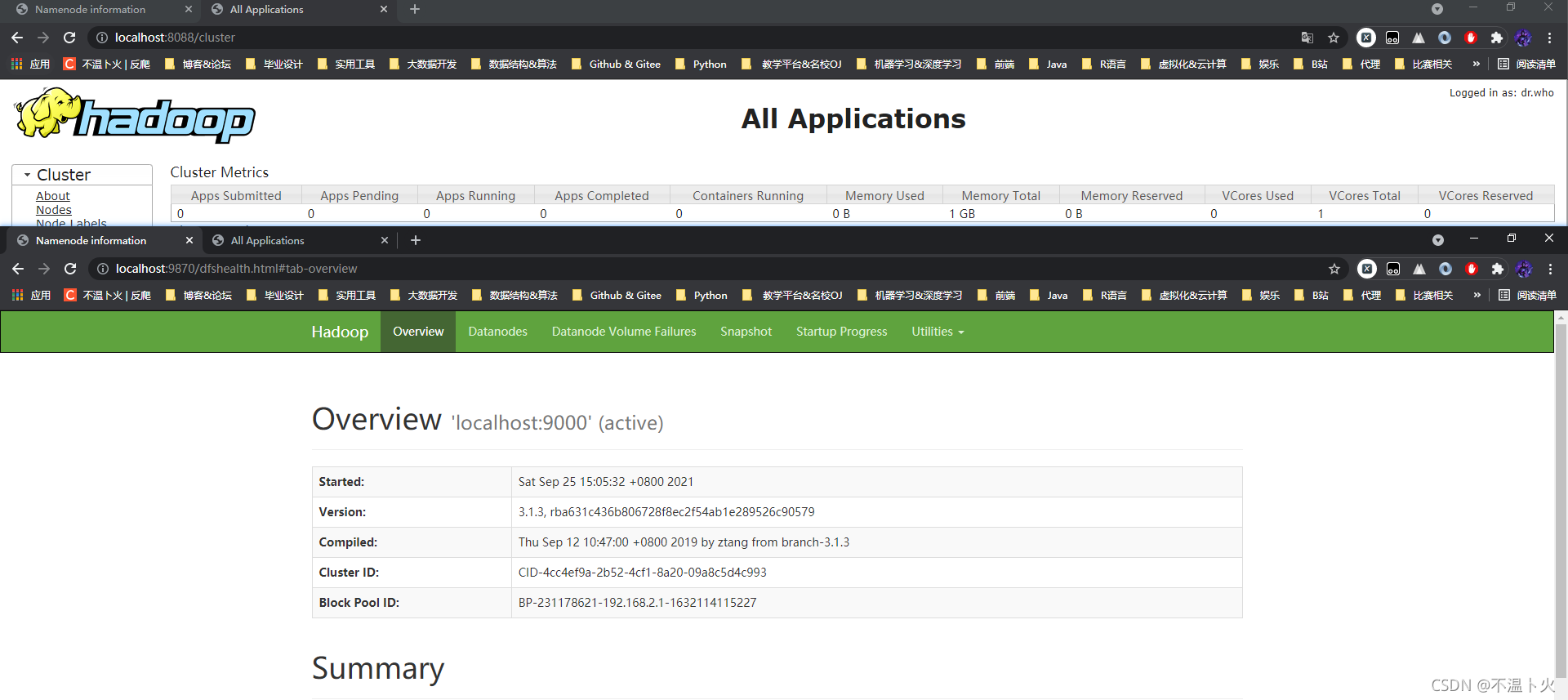
🔎6.关闭hadoop
D:\hadoop-3.1.3\sbin>stop-all.cmd
2.3 Hadoop结构详解
2.3.1 Hadoop的目录结构
🔎1.查看Hadoop目录结构
hadoop@Master:/opt/moudle/hadoop$ ll
drwxr-xr-x 2 hadoop hadoop 4096 9月 12 2019 bin/
drwxr-xr-x 3 hadoop hadoop 4096 9月 12 2019 etc/
drwxr-xr-x 2 hadoop hadoop 4096 9月 12 2019 include/
drwxr-xr-x 3 hadoop hadoop 4096 9月 12 2019 lib/
drwxr-xr-x 4 hadoop hadoop 4096 9月 12 2019 libexec/
-rw-rw-r-- 1 hadoop hadoop 147145 9月 4 2019 LICENSE.txt
-rw-rw-r-- 1 hadoop hadoop 21867 9月 4 2019 NOTICE.txt
-rw-rw-r-- 1 hadoop hadoop 1366 9月 4 2019 README.txt
drwxr-xr-x 3 hadoop hadoop 4096 9月 12 2019 sbin/
drwxr-xr-x 4 hadoop hadoop 4096 9月 12 2019 share/
如果查看目录出现属主和数组不一致的情况,在之后的操作中,可能会出现信息混乱,如下列情况:
hadoop@Master:/opt/moudle/hadoop$ ll
drwxr-xr-x 2 hadoop hadoop 4096 9月 12 2019 bin/
drwxr-xr-x 3 hadoop hadoop 4096 9月 12 2019 etc/
drwxr-xr-x 2 root root 4096 9月 12 2019 include/
drwxr-xr-x 3 hadoop hadoop 4096 9月 12 2019 lib/
drwxr-xr-x 4 hadoop hadoop 4096 9月 12 2019 libexec/
-rw-rw-r-- 1 root hadoop 147145 9月 4 2019 LICENSE.txt
-rw-rw-r-- 1 hadoop hadoop 21867 9月 4 2019 NOTICE.txt
-rw-rw-r-- 1 hadoop hadoop 1366 9月 4 2019 README.txt
drwxr-xr-x 3 hadoop root 4096 9月 12 2019 sbin/
drwxr-xr-x 4 hadoop hadoop 4096 9月 12 2019 share/
这个时候我们可以执行命令chown -R hadoop:hadoop /opt/moudle/hadoop,执行后再查看,如下图所示。
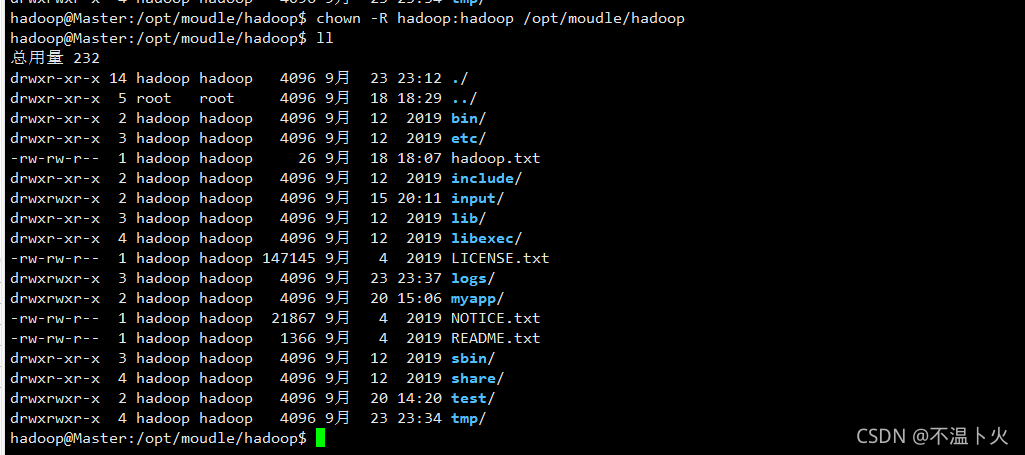
🔎2.重要目录
- 1.bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
- 2.etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- 3.lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- 4.sbin目录:存放启动或停止Hadoop相关服务的脚本
- 5.share目录:存放Hadoop的依赖jar包、文档、和官方案例
- …
2.3.2 各目录详细介绍
🔎1.bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本,如图所示:
hadoop@Master:/opt/moudle/hadoop/bin$ ll
├── container-executor
├── hadoop
├── hadoop.cmd
├── hdfs
├── hdfs.cmd
├── mapred
├── mapred.cmd
├── rcc
├── test-container-executor
├── yarn
└── yarn.cmd
其中,以.cmd结尾的是在Windows上使用的,其他是在Linux上使用的,包含了hadoop、hdfs和yarn,因为之前将该目录配置到了环境变量,所以可以执行hadoop version命令。
🔎2.etc目录:Hadoop的配置文件目录,如hdfs-site.xml、core-site.xml等文件的存放目录。
hadoop@Master:/opt/moudle/hadoop/etc/hadoop$ ll
├── capacity-scheduler.xml
├── core-site.xml
├── hdfs-site.xml
├── mapred-site.xml
├── yarn-site.xml
├── ......
🔎3.lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
hadoop@Master:/opt/moudle/hadoop/lib/native$ ll
├── libhadoop.so -> libhadoop.so.1.0.0*
├── libhdfs.so -> libhdfs.so.0.0.0*
├── libnativetask.so -> libnativetask.so.1.0.0*
├── libhdfs.a
├── libnativetask.so.1.0.0*
├── ......
🔎4.sbin目录:存放启动或停止Hadoop相关服务的脚本
hadoop@Master:/opt/moudle/hadoop/sbin$ ll
├── distribute-exclude.sh
├── FederationStateStore
│ ├── MySQL
│ │ ├── dropDatabase.sql
│ │ ├── dropStoreProcedures.sql
│ │ ├── dropTables.sql
│ │ ├── dropUser.sql
│ │ ├── FederationStateStoreDatabase.sql
│ │ ├── FederationStateStoreStoredProcs.sql
│ │ ├── FederationStateStoreTables.sql
│ │ └── FederationStateStoreUser.sql
│ └── SQLServer
│ ├── FederationStateStoreStoreProcs.sql
│ └── FederationStateStoreTables.sql
├── hadoop-daemon.sh
├── hadoop-daemons.sh
├── hdfs-config.cmd
├── hdfs-config.sh
├── httpfs.sh
├── kms.sh
├── mr-jobhistory-daemon.sh
├── refresh-namenodes.sh
├── slaves.sh
├── start-all.cmd
├── start-all.sh
├── start-balancer.sh
├── start-dfs.cmd
├── start-dfs.sh
├── start-secure-dns.sh
├── start-yarn.cmd
├── start-yarn.sh
├── ......
包含了sh和cmd文件。
🔎5.share目录:存放Hadoop的依赖jar包、文档、和官方案例,在此仅以mapreduce为展示对象
hadoop@Master:/opt/moudle/hadoop/share/hadoop/mapreduce$ ll
├── hadoop-mapreduce-client-app-3.1.3.jar
├── hadoop-mapreduce-client-common-3.1.3.jar
├── hadoop-mapreduce-client-core-3.1.3.jar
├── hadoop-mapreduce-client-hs-3.1.3.jar
├── hadoop-mapreduce-client-hs-plugins-3.1.3.jar
├── ......
如果想查看这些jar包的源码,需要对其进行反编译。
三、Apache Hadoop 三种搭建方式
Hadoop搭建的方式包括3种:
-
单机模式
单节点、不是集群,生产不会使用这种模式。 -
单机伪分布式模式
单节点、多线程模拟集群的效果,因为发挥的也只是一台电脑的性能,因此生产中不会使用。 -
完全分布式模式
多台节点,真正的分布式Hadoop集群的搭建,生产环境建议使用这种方式。
下面学长主要针对这三种搭建方式分别阐述具体安装过程。
3.1 Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
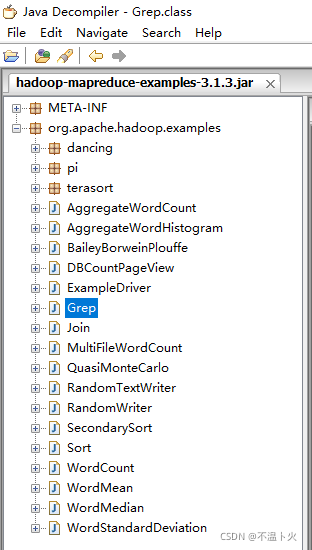
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我们选择运行 wordcount 例子,我们将 input 文件夹中的所有文件作为输入,最后输出结果到 output 文件夹中。
hadoop@ubuntu:~$ cd /opt/moudle/hadoop/
hadoop@ubuntu:/opt/moudle/hadoop$ mkdir input
hadoop@ubuntu:/opt/moudle/hadoop$ vim jayce.txt
# 自己随机输入的内容
jayce jayce
jayce yasuo
jayce hadoop
jayce
hadoop@ubuntu:/opt/moudle/hadoop$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount input output
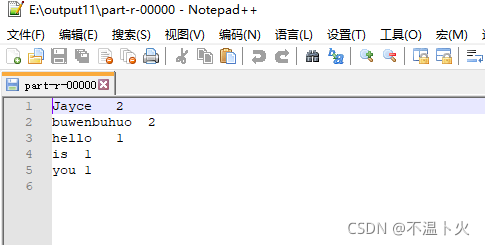
执行成功后如下所示,输出了作业的相关信息,如果输出的结果正确,则输出的结果hadoop出现1次,jayce出现5次,yasuo出现1次
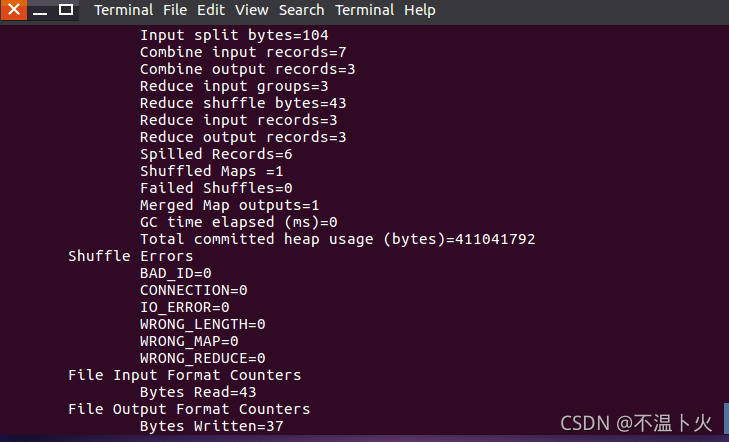
hadoop@ubuntu:/opt/moudle/hadoop$ cat output/*
hadoop 1
jayce 5
yasuo 1
📢注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 output 删除。
hadoop@ubuntu:/opt/moudle/hadoop$rm -rf output
3.2 Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于/opt/moudle/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
🔎1. 修改配置文件 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/moudle/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
🔎2. 修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/moudle/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/moudle/hadoop/tmp/dfs/data</value>
</property>
</configuration>
📢Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
🔎3. 执行 NameNode 的格式化
hadoop@ubuntu:~$ cd /opt/moudle/hadoop/
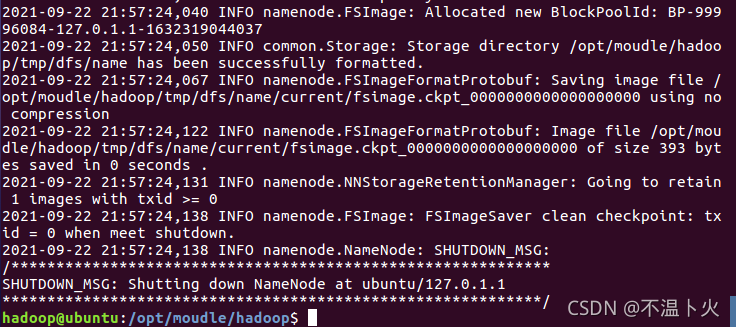
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs namenode -format # 格式化
成功的话,会看到 “successfully formatted” 的提示,具体返回信息类似如下:
🔎4. 启动HDFS
hadoop@ubuntu:/opt/moudle/hadoop$ start-dfs.sh
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。

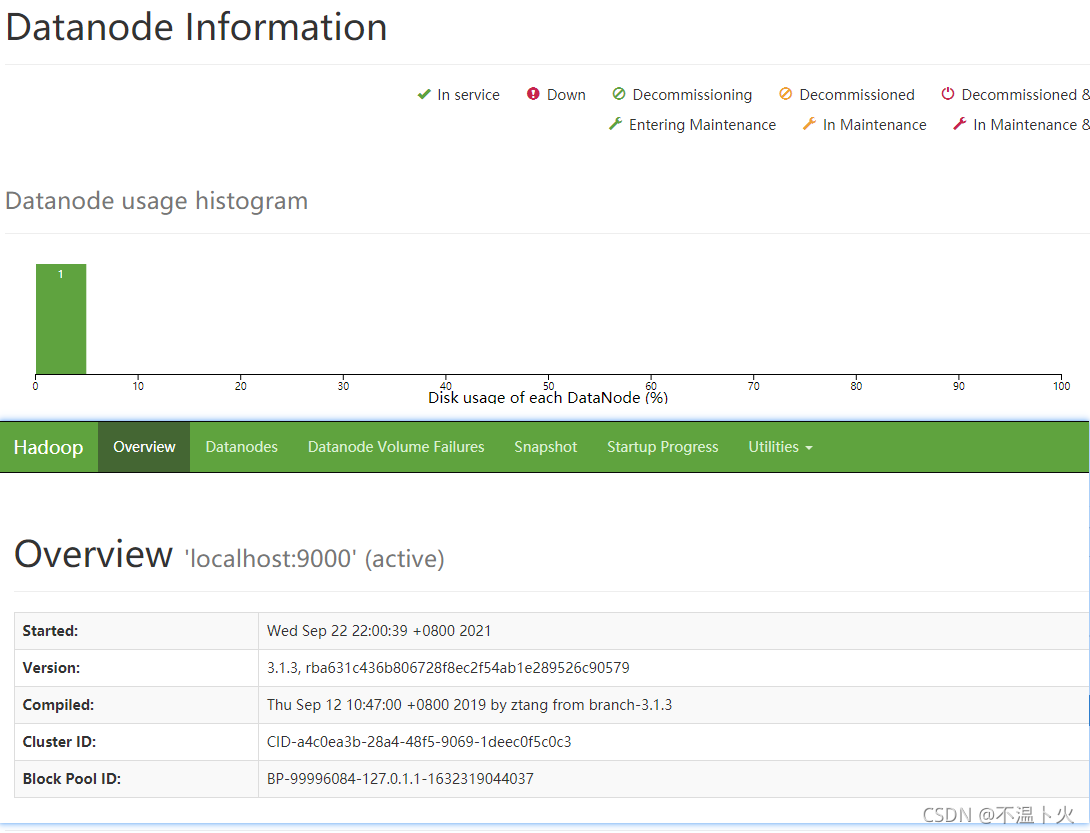
启动成功后可以打开UI界面进行查看
http://localhost:9870/如果出现以下画面,代表成功启动。
🔎5. 运行Hadoop伪分布式实例
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs dfs -mkdir -p /user/hadoop
📢注意有三种shell命令方式。
- hadoop fs
- hadoop dfs
- hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /opt/moudle/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs dfs -mkdir input
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs dfs -put input/jayce.txt input # 文件上传到user/hadoop/input
出现下图的结果,一般为成功。

上传完成后,我们可以通过以下两种方式方式进行查看:
1??在终端进行查看
# 在终端进行查看
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs dfs -ls input

2?? 在ui界面查看
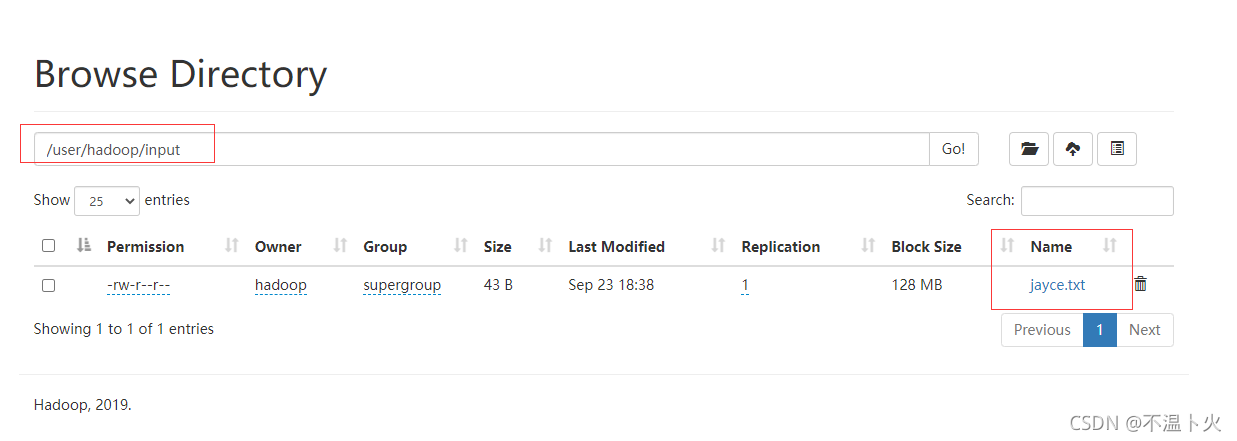
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
hadoop@ubuntu:/opt/moudle/hadoop$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount input output
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs dfs -cat output/*
结果如下,注意到刚才我们已经更改了配置文件,所以运行结果不同。

我们也可以将运行结果取回到本地:
hadoop@ubuntu:/opt/moudle/hadoop$ rm -rf output # 先删除本地的 output 文件夹(如果存在)
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs dfs -get output output # 将 HDFS 上的 output 文件夹拷贝到本机
2021-09-22 22:29:34,712 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
hadoop@ubuntu:/opt/moudle/hadoop$ cat output/*
hadoop 1
jayce 5
yasuo 1
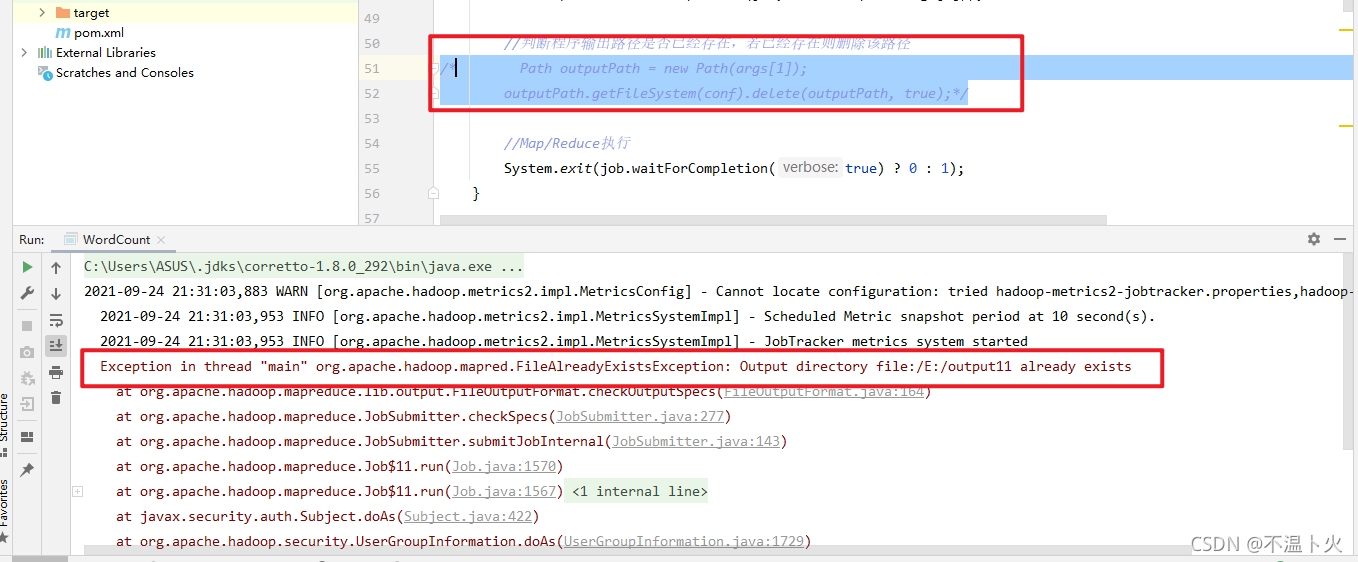
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
hadoop@ubuntu:/opt/moudle/hadoop$ hdfs dfs -rm -r output # 删除 output 文件夹
📢运行程序时,输出目录不能存在
运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作:
/* 判断程序输出路径是否已经存在,若已经存在则删除该路径 */
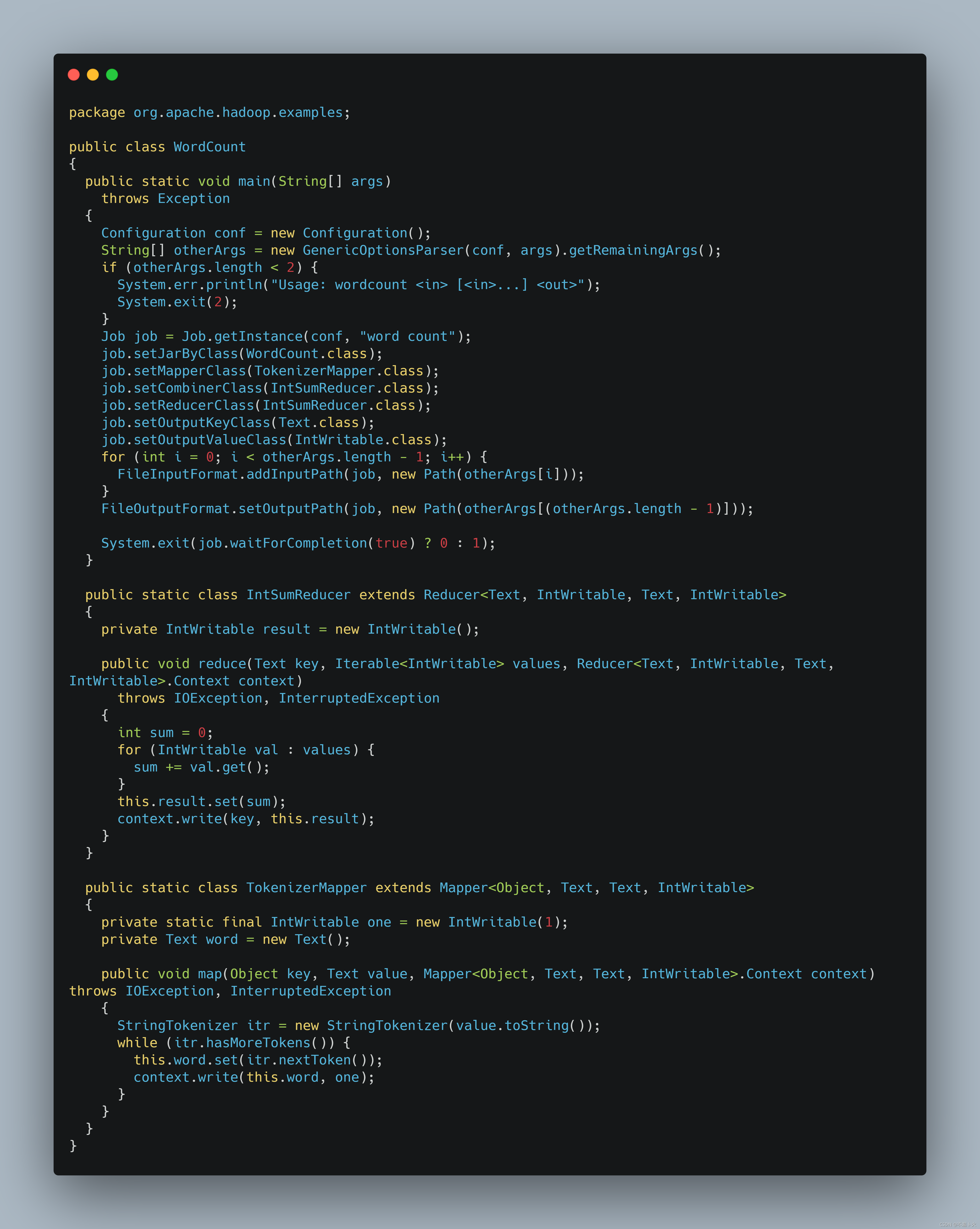
Path outPath = new Path(otherArgs[1]);
if (fs.exists(outPath)) fs.delete(outPath, true);
👉我们先看下反编译的hadoop-mapreduce-examplesjar包的整体结构,在下图中,我们可以看到给出的案例demo。
?我们选择wordcount作为研究对象,反编译后的源码如下:
👊运行案例如下:
?修改后的源码如下(部分加上注释):
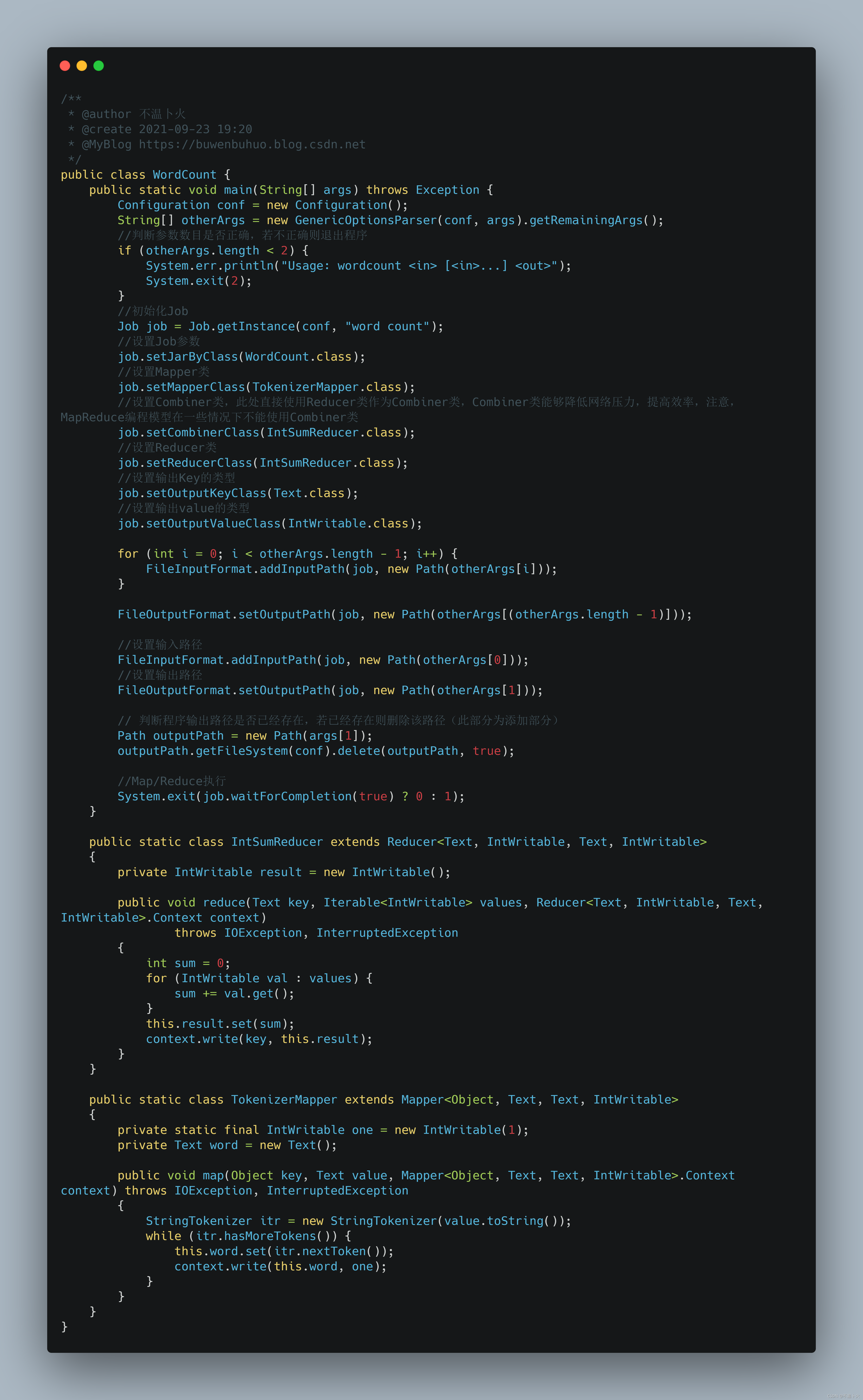
👊添加判断删除语句后,即使没有手动删除output目录,也不会报错,如下图:

👊如果注释上述添加部分,在此运行会报错,结果如下:
🔎关闭Hadoop
若要关闭 Hadoop,则运行
hadoop@ubuntu:/opt/moudle/hadoop$ stop-dfs.sh

📢下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以!
3.3 Hadoop完全分布式搭建
3.3.1 快照与克隆
👉在进行搭建之前,我们需要对已经配置好的伪分布式样板机打上快照。首先我们来看下虚拟机快照的作用。
快照的作用类似于一个系统还原点,一个虚拟系统里可以存在多个快照。利用快照可进行系统和数据还原。
当搭建好一个环境后,在没有添加任何数据时,或改变系统环境时,可以启用快照功能,虚拟机会保存虚拟系统里当前的环境,包括所安装的软件等设置;
当环境改变或需要重新搭建并系统初始化时,为免安装其他大型软件,可以启用快照的保存点进行恢复。作用就达到了快捷搭建环境的作用,也可以说是一种备份。
所以我们要先对其进行快照备份!
过程如下:

备份完成后,我们分别克隆三台虚拟机。分别命名为Master,Slave1,Slave2。克隆过程如下(注意克隆尽量选择完整克隆):

🔆等到完成后,完整克隆三个即可停止。
3.3.2 前期准备工作
当Hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。这时,数据就可以分布到多个节点上,不同数据节点上的数据计算可以并行执行,这时的MapReduce分布式计算能力才能真正发挥作用。
为了降低分布式模式部署难度,本教程简单使用三个节点(三台物理机器)来搭建集群环境,一台机器作为 Master节点,局域网IP地址为192.168.2.6,一台机器作为 Slave1 节点,局域网 IP 地址为192.168.2.7,另一台机器作为 Slave2 节点,局域网 IP 地址为192.168.2.8。
Hadoop 集群的安装配置大致包括以下步骤:
(1)步骤1:选定一台机器作为 Master;
(2)步骤2:在Master节点上创建hadoop用户、安装SSH服务端、安装Java环境;
(3)步骤3:在Master节点上安装Hadoop,并完成配置;
(4)步骤4:在其他Slave节点上创建hadoop用户、安装SSH服务端、安装Java环境;
(5)步骤5:将Master节点上的“/opt/moudle/hadoop”目录复制到其他Slave节点上;
(6)步骤6:在Master节点上开启Hadoop;
上述这些步骤中,关于如何创建hadoop用户、安装SSH服务端、安装Java环境、安装Hadoop等过程,已经在上文中详细解释,在此不再赘述,并且由于克隆虚拟机的缘故,其实这几步是可以直接省略的。我们在此所要完成的内容为配置主节点即Master节点的配置文件并分发到其他从(Slave)节点上。然后格式化,启动测试即可。
在此我们先把前期准备做好。
🔎 1. 网络配置
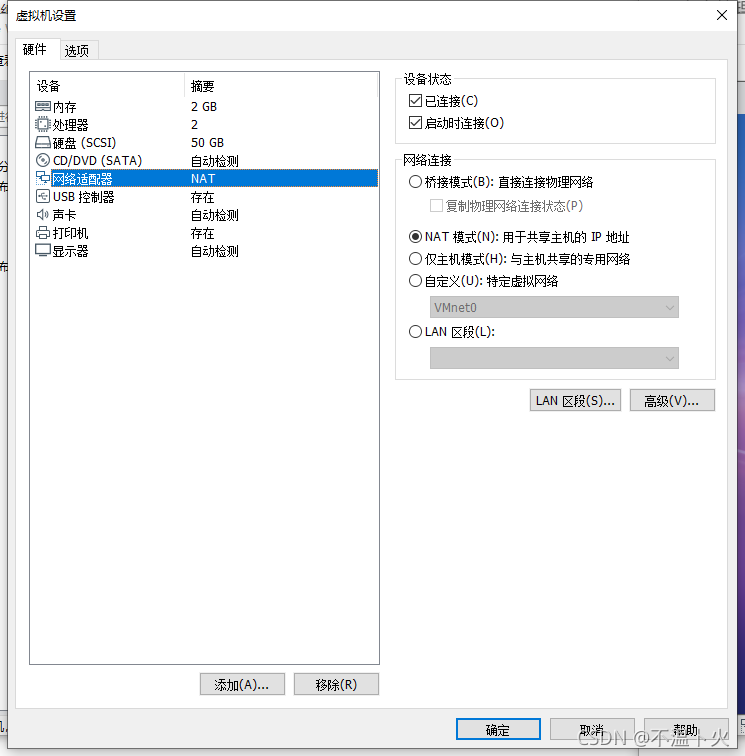
假设集群所用的三个节点(机器)都位于同一个局域网内。如果三个节点使用的是虚拟机安装的Linux系统,那么三者都需要更改网络连接方式为NAT模式,才能实现多个节点互连,如下图所示。
当然一般安装时,我们就推荐使用NAT模式进行安装。
网络配置完成以后,可以查看一下机器的IP地址,可以使用ifconfig命令查看。本教程在同一个局域网内部的三台机器的IP地址分别是192.168.2.6、192.168.1.7和192.168.1.8。如下图所示:
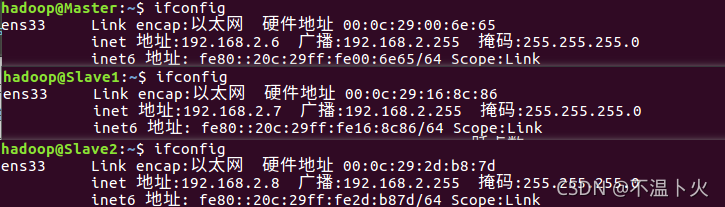
当然我们除了使用克隆机自己分配的ip外,也可以自定义修改成自己喜欢的ip地址,修改过程如下:
hadoop@Master:~$ sudo vim /etc/network/interfaces
# 下面为要修改部分
auto ens33
# static表示设置静态IP,动态IP用dhcp,一般默认就是dhcp状态
iface ens33 inet static
#IP地址
address 192.168.2.6
#子网掩码
netmask 255.255.255.0
#网关
gateway 192.168.2.2
#广播地址,可以不设
broadcast 192.168.2.255
修改完成后重启网络即可
hadoop@Master:~$ sudo /etc/init.d/networking restart

出现上述结果即为成功,这时候可以通过ifconfig查看是否修完成功。修改了Master节点,Slave节点也不要忘了呀~
🔎 2. 修改主机名与映射
由于集群中有三台机器需要设置,所以,在接下来的操作中,一定要注意区分Master节点和Slave节点。为了便于区分Master节点和Slave节点,可以修改各个节点的主机名,这样,在Linux系统中打开一个终端以后,在终端窗口的标题和命令行中都可以看到主机名,就比较容易区分当前是对哪台机器进行操作。在Ubuntu中,我们在 Master 节点上执行如下命令修改主机名:
hadoop@Master:~$ sudo vim /etc/hostname
执行上面命令后,就打开了“/etc/hostname”这个文件,这个文件里面记录了主机名,比如,假设安装Ubuntu系统时,设置的主机名是“ubuntu”,因此,打开这个文件以后,里面就只有“ubuntu”这一行内容,可以直接删除,并修改为“Master”(注意是区分大小写的),然后,保存退出vim编辑器,这样就完成了主机名的修改,需要重启Linux系统才能看到主机名的变化。
要注意观察主机名修改前后的变化。在修改主机名之前,如果用hadoop登录Linux系统,打开终端,进入Shell命令提示符状态,会显示如下内容:
hadoop@ ubuntu:~$
修改主机名并且重启系统之后,用hadoop登录Linux系统,打开终端,进入Shell命令提示符状态,会显示如下内容:
hadoop@ Master:~$
可以看出,这时就很容易辨认出当前是处于Master节点上进行操作,不会和Slave节点产生混淆。
然后,在Master节点中执行如下命令打开并修改Master节点中的“/etc/hosts”文件,可以在hosts文件中增加如下两条IP和主机名映射关系:
hadoop@Master:~$ sudo vim /etc/hosts
# 添加映射
192.168.2.6 Master
192.168.2.7 Slave1
192.168.2.8 Slave2
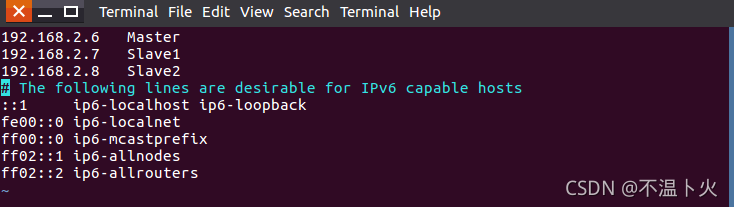
需要注意的是,一般hosts文件中只能有一个127.0.0.1,其对应主机名为localhost,如果有多余127.0.0.1映射,应删除,特别是不能存在“127.0.0.1 Master”这样的映射记录。修改后需要重启Linux系统。
上面完成了Master节点的配置,接下来要继续完成对其他Slave节点的配置修改。本教程有二个Slave节点,主机名为Slave1、Slave2。请参照上面的方法,把Slave节点上的“/etc/hostname”文件中的主机名修改为“Slave1”、“Slave1”,同时,修改“/etc/hosts”的内容,在hosts文件中增加如下三条IP和主机名映射关系:
hadoop@Slave1:~$ sudo vim /etc/hosts
# 添加映射
192.168.2.6 Master
192.168.2.7 Slave1
192.168.2.8 Slave2
修改完成以后,请重新启动Slave节点的Linux系统。
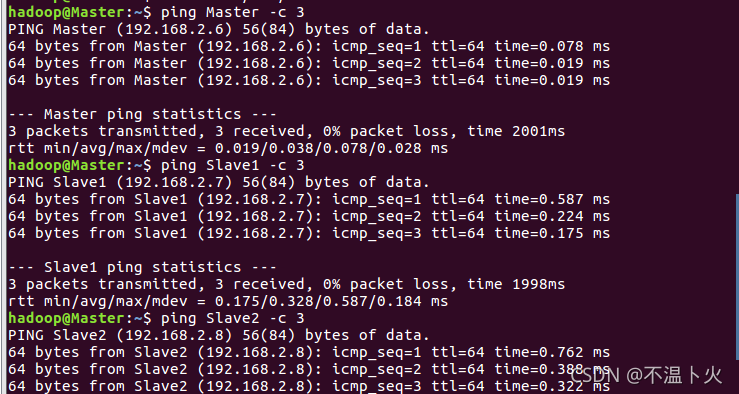
这样就完成了Master节点和Slave节点的配置,然后,需要在各个节点上都执行如下命令,测试是否相互ping得通,如果ping不通,后面就无法顺利配置成功:
hadoop@Master:~$ ping Master -c 3 # 只ping 3次就会停止,否则要按Ctrl+c中断ping命令
hadoop@Master:~$ ping Slave1 -c 3
hadoop@Master:~$ ping Slave2 -c 3
Ping通结果如下图所示:
🔎 3. SSH无密码登录节点
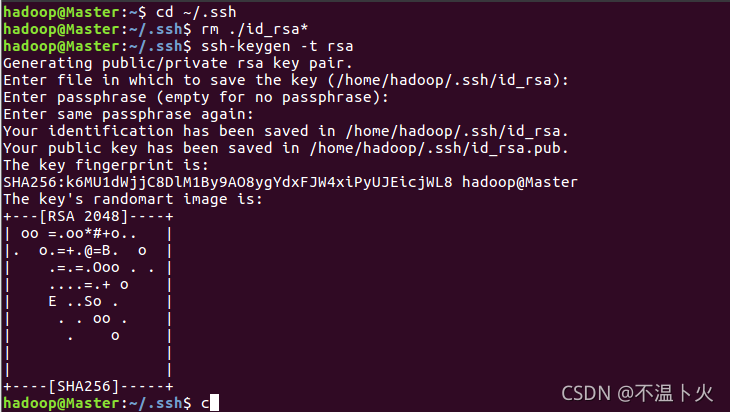
必须要让Master节点可以SSH无密码登录到各个Slave节点上。首先,生成Master节点的公匙,如果之前已经生成过公钥,必须要删除原来生成的公钥,重新生成一次,因为前面我们对主机名进行了修改。具体命令如下:
hadoop@Master:~$ cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
hadoop@Master:~/.ssh$ rm ./id_rsa* # 删除之前生成的公匙(如果已经存在)
hadoop@Master:~/.ssh$ ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按回车就可以
为了让Master节点能够无密码SSH登录本机,需要在Master节点上执行如下命令:
adoop@Master:~/.ssh$ cat ./id_rsa.pub >> ./authorized_keys
完成后可以执行命令“ssh Master”来验证一下,可能会遇到提示信息,只要输入yes即可,测试成功后,请执行“exit”命令返回原来的终端。
接下来,在Master节点将上公匙传输到Slave节点:
hadoop@Master:~$ scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
hadoop@Master:~$ scp ~/.ssh/id_rsa.pub hadoop@Slave2:/home/hadoop/
上面的命令中,scp是secure copy的简写,用于在 Linux下进行远程拷贝文件,类似于cp命令,不过,cp只能在本机中拷贝。执行scp时会要求输入Slave上hadoop用户的密码,输入完成后会提示传输完毕,如下图所示。

接着在Slave1节点上,将SSH公匙加入授权,Slave2同理:
hadoop@Slave1:~$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在,则忽略本命令
mkdir: 无法创建目录"/home/hadoop/.ssh": 文件已存在
hadoop@Slave1:~$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
hadoop@Slave1:~$ rm ~/id_rsa.pub # 用完以后就可以删掉

如果有其他Slave节点,也要执行将Master公匙传输到Slave节点以及在Slave节点上加入授权这两步操作。如下:
adoop@Slave2:~$ mkdir ~/.ssh
hadoop@Slave2:~$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
hadoop@Slave2:~$ rm ~/id_rsa.pub

这样,在Master节点上就可以无密码SSH登录到各个Slave节点了,可在Master节点上执行如下命令进行检验:
hadoop@Master:~$ ssh Slave1
hadoop@Master:~$ ssh Slave2
根据上图,我们可以看到免密登录已经完成。
3.3.3 配置集群/分布式环境
现在进行集群环境规划,对3台虚拟机的角色分布如下:
| 框架 | Master | Slave1 | Slave2 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| Yarn | NodeManager、ResourceManager | NodeManager | NodeManager |
最终启动的服务如下图所示(图中的jps-all脚本会在后面给出):

📡配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
🔎1.默认配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| core-default.xml | hadoop-common-3.1.3.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
🔎2.自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
📡在配置集群/分布式模式时,需要修改“/opt/moudle/etc/hadoop”目录下的配置文件,这里仅设置正常启动所必须的设置项,包括workers 、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml共5个文件,更多设置项可查看官方说明。
🔎(1)修改文件workers
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
本教程让Master节点也作为数据节点使用,因此将workers文件中原来的localhost删除,添加如下三行内容:
hadoop@Master:/opt/moudle/hadoop/etc/hadoop$ vim workers
Master
Slave1
Slave2
🔎(2)修改文件core-site.xml
请把core-site.xml文件修改为如下内容:
hadoop@Master:/opt/moudle/hadoop/etc/hadoop$ vim core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/moudle/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
🔎(3)修改文件hdfs-site.xml
对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。本教程数据节点也为3。所以 ,dfs.replication的值还是设置为3。hdfs-site.xml具体内容如下:
hadoop@Master:/opt/moudle/hadoop/etc/hadoop$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Slave2:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/moudle/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/moudle/hadoop/tmp/dfs/data</value>
</property>
</configuration>
🔎(4)修改文件mapred-site.xml
在有些版本中,“/opt/moudle/hadoop/etc/hadoop”目录下有一个mapred-site.xml.template,需要修改文件名称,把它重命名为mapred-site.xml。如果不需要修改可以忽略此部分说明。然后,把mapred-site.xml文件配置成如下内容:
hadoop@Master:/opt/moudle/hadoop/etc/hadoop$ vim mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/moudle/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/moudle/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/moudle/hadoop</value>
</property>
</configuration>
🔎(5)修改文件 yarn-site.xml
请把yarn-site.xml文件配置成如下内容:
hadoop@Master:/opt/moudle/hadoop/etc/hadoop$ vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
上述5个文件全部配置完成以后,需要把Master节点上的“/opt/moudle/hadoop”文件夹复制到各个节点上。如果之前已经运行过伪分布式模式,建议在切换到集群模式之前首先删除之前在伪分布式模式下生成的临时文件。具体来说,需要首先在Master节点上执行如下命令:
hadoop@Master:~$ cd /opt/moudle/hadoop/
hadoop@Master:/opt/moudle/hadoop$ rm -rf tmp/ # 删除 Hadoop 临时文件
hadoop@Master:/opt/moudle/hadoop$ rm -rf logs/* # 删除日志文件
hadoop@Master:/opt/moudle$ tar -zcf /opt/software/hadoop.tar.gz hadoop # 先压缩再复制
hadoop@Master:/opt/moudle$ cd /opt/software/
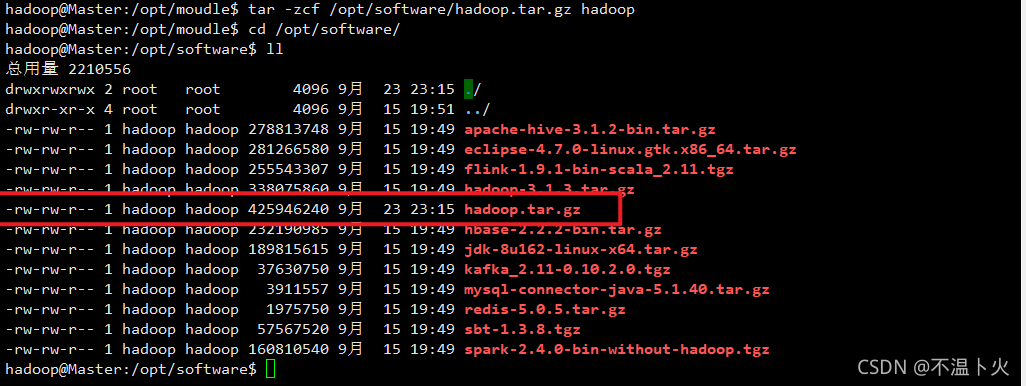
出现上图标红的tar包即为压缩成功,下面进行分发:
hadoop@Master:/opt/software$ scp hadoop.tar.gz Slave1:/home/hadoop
hadoop@Master:/opt/software$ scp hadoop.tar.gz Slave2:/home/hadoop
分发成功后,需要分别在Slave1和Slave2中查看是否分发成功,如下图所示。
接下来在Slave1和Slave2节点上分别执行如下命令:
hadoop@Slave1:~$ cd /opt/moudle/
hadoop@Slave1:/opt/moudle$ rm -rf hadoop # 删掉旧的(如果存在)
hadoop@Slave1:/opt/moudle$ sudo tar -zxf ~/hadoop.tar.gz -C /opt/moudle/
hadoop@Slave1:/opt/moudle$ sudo chown -R hadoop:hadoop hadoop
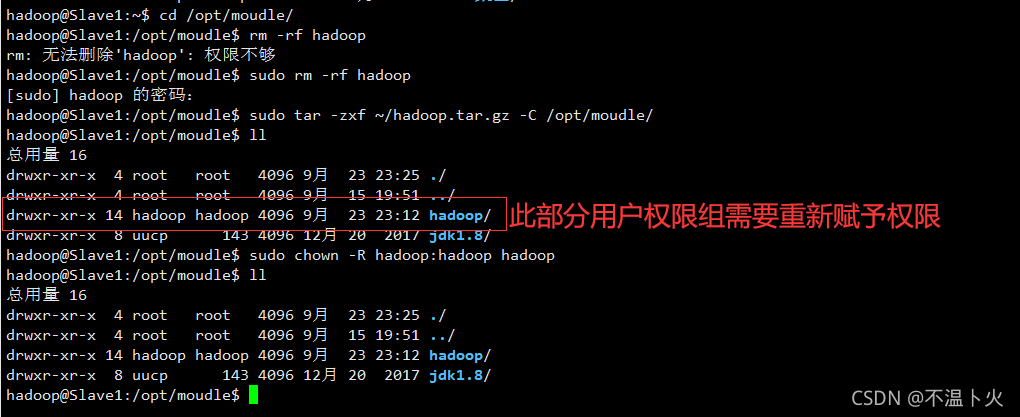
同样,如果有其他Slave节点,也要执行将hadoop.tar.gz传输到Slave节点以及在Slave节点解压文件的操作。
首次启动Hadoop集群时,需要先在Master节点执行名称节点的格式化(只需要执行这一次,后面再启动Hadoop时,不要再次格式化名称节点),命令如下:
hadoop@Master:/opt/software$ hdfs namenode -format
出现下图即为成功。
 现在就可以启动
现在就可以启动Hadoop了,启动需要在Master节点上进行,执行如下命令:
hadoop@Master:/opt/moudle/hadoop$ start-dfs.sh
hadoop@Master:/opt/moudle/hadoop$ start-yarn.sh
hadoop@Master:/opt/moudle/hadoop$ mr-jobhistory-daemon.sh start historyserver
启动成功后通过命令jps可以查看各个节点所启动的进程。如果已经正确启动,则在Master节点上可以看到NameNode、DataNode、ResourceManager、NodeManager和JobHistoryServer进程,如下图所示。

在Slave1节点可以看到DataNode和NodeManager进程,如下图所示。

在Slave2节点可以看到DataNode、SecondrryNameNode和NodeManager进程,如下图所示。

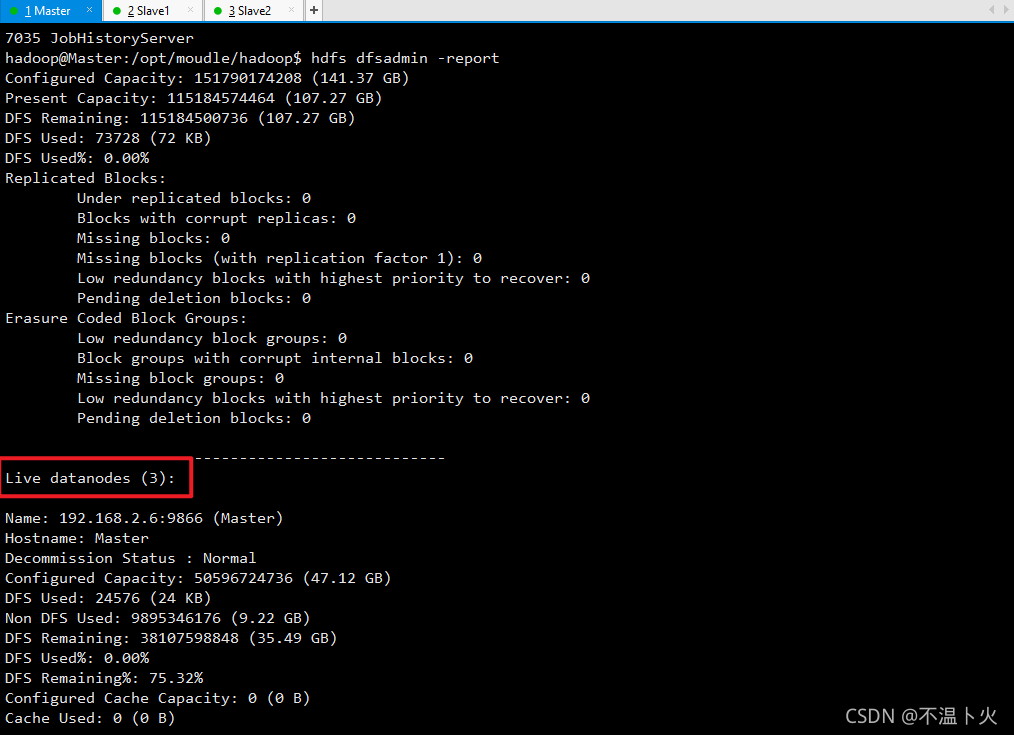
缺少任一进程都表示出错。另外还需要在Master节点上通过命令“hdfs dfsadmin -report”查看数据节点是否正常启动,如果屏幕信息中的“Live datanodes”不为 0 ,则说明集群启动成功。当数据节点启动成功以后,会显示如下图所示信息。
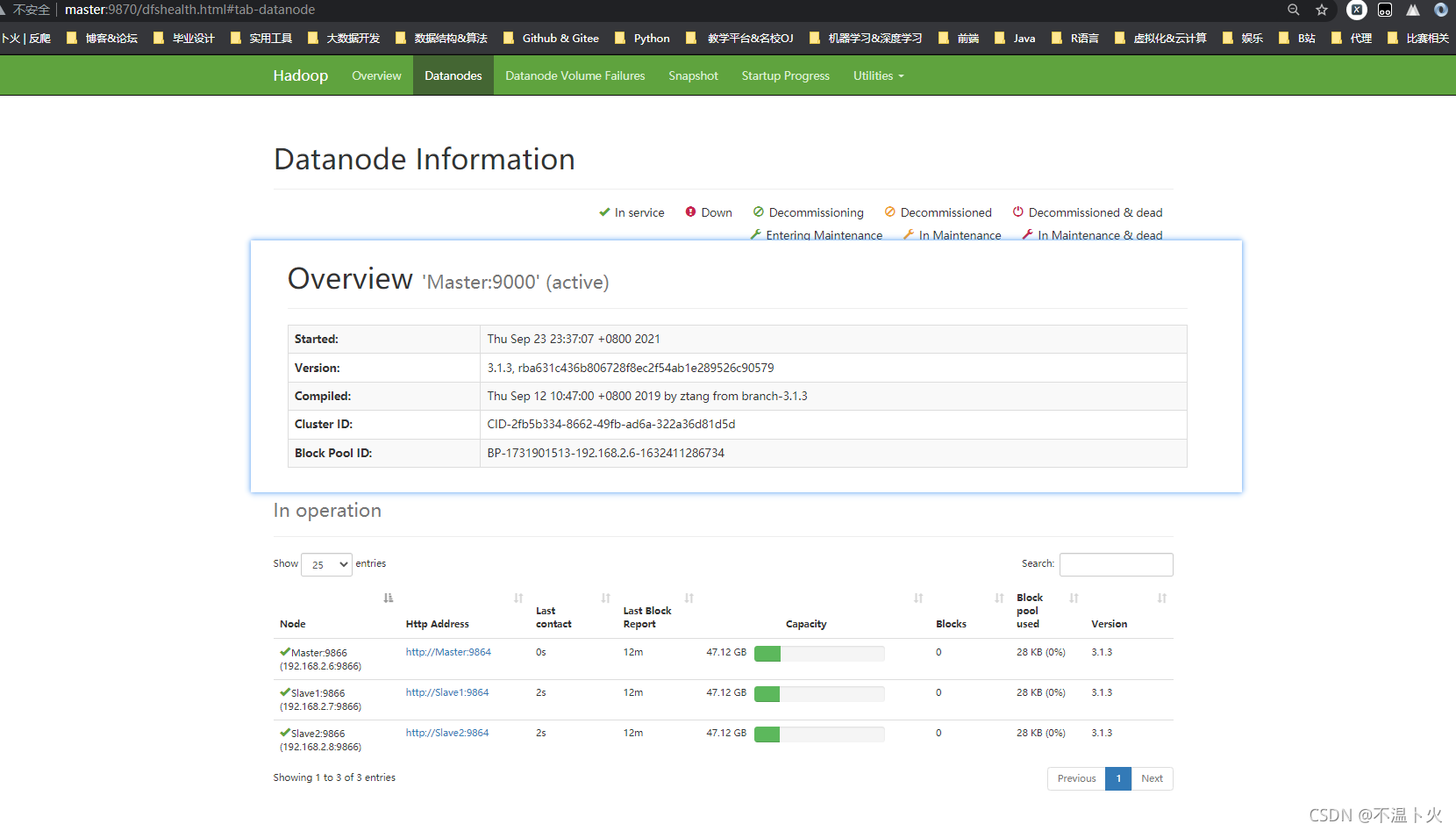
也可以在浏览器中输入地址“http://Master:9870/”,通过 Web 页面看到查看名称节点和数据节点的状态。如果不成功,可以通过启动日志排查原因,界面如下图。
📢这里再次强调,伪分布式模式和分布式模式切换时需要注意以下事项:
- 从分布式切换到伪分布式时,不要忘记修改
slaves配置文件; - 在两者之间切换时,若遇到无法正常启动的情况,可以删除所涉及节点的临时文件夹,这样虽然之前的数据会被删掉,但能保证集群正确启动。所以,如果集群以前能启动,但后来启动不了,特别是数据节点无法启动,不妨试着删除所有节点(包括
Slave节点)上的“/opt/moudle/hadoop/tmp”文件夹,再重新执行一次“hdfs namenode -format”,再次启动即可。
3.3.4 执行分布式实例
执行分布式实例过程与伪分布式模式一样,首先创建HDFS上的用户目录,命令如下:
hadoop@Master:/opt/moudle/hadoop$ hdfs dfs -mkdir -p /user/hadoop
然后,在HDFS中创建一个input目录,并把“/opt/moudle/hadoop/etc/hadoop”目录中的配置文件作为输入文件复制到input目录中,命令如下:
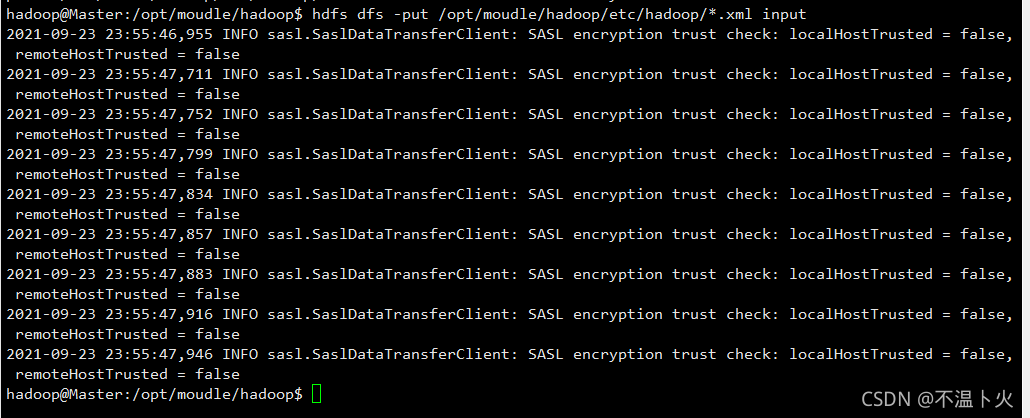
hadoop@Master:/opt/moudle/hadoop$ hdfs dfs -mkdir input
hadoop@Master:/opt/moudle/hadoop$ hdfs dfs -put /opt/moudle/hadoop/etc/hadoop/*.xml input
执行过程如下:
如果执行成功可以在UI查看或者通过命令行查看,在此仅从UI查看,如图:
 接着就可以运行
接着就可以运行 MapReduce 作业了,命令如下:
hadoop@Master:/opt/moudle/hadoop$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
运行时的输出信息与伪分布式类似,会显示MapReduce作业的进度,如下图所示。
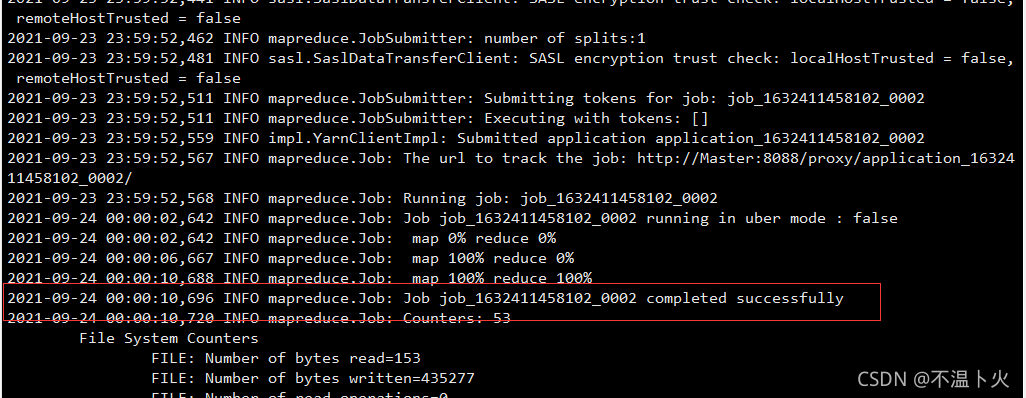
执行过程可能会有点慢,但是,如果迟迟没有进度,比如5分钟都没看到进度变化,那么不妨重启Hadoop再次测试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改YARN的内存配置来解决。
在执行过程中,可以打开浏览器,在地址栏输入“http://Master:8088/cluster”,通过Web界面查看任务进度,在Web界面点击 “Tracking UI” 这一列的History连接,可以看到任务的运行信息,如下图所示。

执行完毕后的输出结果如下图所示。
hadoop@Master:/opt/moudle/hadoop$ hdfs dfs -cat output/*

除此之外也可以通过UI界面查看,如图所示:

最后,关闭Hadoop集群,需要在Master节点执行如下命令:
hadoop@Master:/opt/moudle/hadoop$ stop-dfs.sh
hadoop@Master:/opt/moudle/hadoop$ stop-yarn.sh
hadoop@Master:/opt/moudle/hadoop$ mr-jobhistory-daemon.sh stop historyserver
至此,就顺利完成了Hadoop集群搭建。
四、拓展部分
4.1 启动进程
启动Hadoop的话,我们即可以分别启动,也可以群体启动,关闭亦是如此。
🔎1.启动
hadoop@Master:/opt/moudle/hadoop$ start-dfs.sh
hadoop@Master:/opt/moudle/hadoop$ start-yarn.sh
hadoop@Master:/opt/moudle/hadoop$ start-all.sh
🔎2.关闭
hadoop@Master:/opt/moudle/hadoop$ stop-dfs.sh
hadoop@Master:/opt/moudle/hadoop$ stop-yarn.sh
hadoop@Master:/opt/moudle/hadoop$ stop-all.sh
4.2 查看集群所有节点jps脚本
在3.3.3 配置集群/分布式环境此部分中,需要在每个虚拟机内分别输入jps查看进程,如下图所示:

我们有没有发现很是麻烦,那么能否通过编写简单的shell脚本进行群体查看呢?答案是可以的,具体过程如下:
🔎1.进入到/bin目录下
hadoop@Master:~$ cd /bin/
🔎2.在 /bin 下创建 jps-all,并编写脚本
hadoop@Master:/bin$ sudo vim jps-all
#! /bin/bash
# 批量查看进程脚本
for i in Master
do
echo --------- $i ----------
ssh $i "$*"
done
for i in Slave1 Slave2
do
echo --------- $i ----------
ssh $i "$*"
done
🔎3.给 jps-all赋权限
hadoop@Master:/bin$ sudo chmod 777 jps-all
🔎4.测试效果
在 master 上查看集群所有节点的 jps 进程
hadoop@Master:~$ jps-all jps

4.3 集群分发脚本(不要求掌握,了解即可。使用Ubuntu系统需要一些前提配置)
在上文中,分发文件我们使用的均为scp(secure copy)安全拷贝,我们接下来介绍的为rsync远程同步工具。
先来简单介绍下两者。
4.3.1 scp 安全拷贝
🔎1.定义
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
🔎2.基本语法
| scp | -r | p d i r / pdir/ pdir/fname | u s e r @ user@ user@host: p d i r / pdir/ pdir/fname |
|---|---|---|---|
| 命令 | 递归 | 要拷贝的文件路径/名称 | 目的地用户@主机:目的地路径/名称 |
🔎3.案例实操
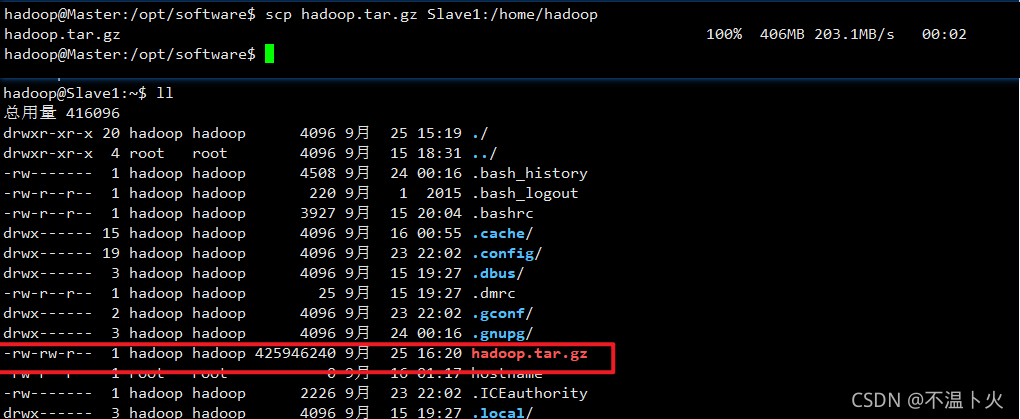
在Master上,将Master中/opt/software中的hadoop.tar.gz拷贝到Slave1的/home/hadoop上
hadoop@Master:/opt/software$ scp hadoop.tar.gz Slave1:/home/hadoop
4.3.2 rsync远程同步工具
🔎1.定义
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
🔎2.两者区别
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
🔎3.基本语法
| rsync | -av | p d i r / pdir/ pdir/fname | u s e r @ user@ user@host: p d i r / pdir/ pdir/fname |
|---|---|---|---|
| 命令 | 选项参数 | 要拷贝的文件路径/名称 | 目的地用户@主机:目的地路径/名称 |
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
🔎4.案例实操
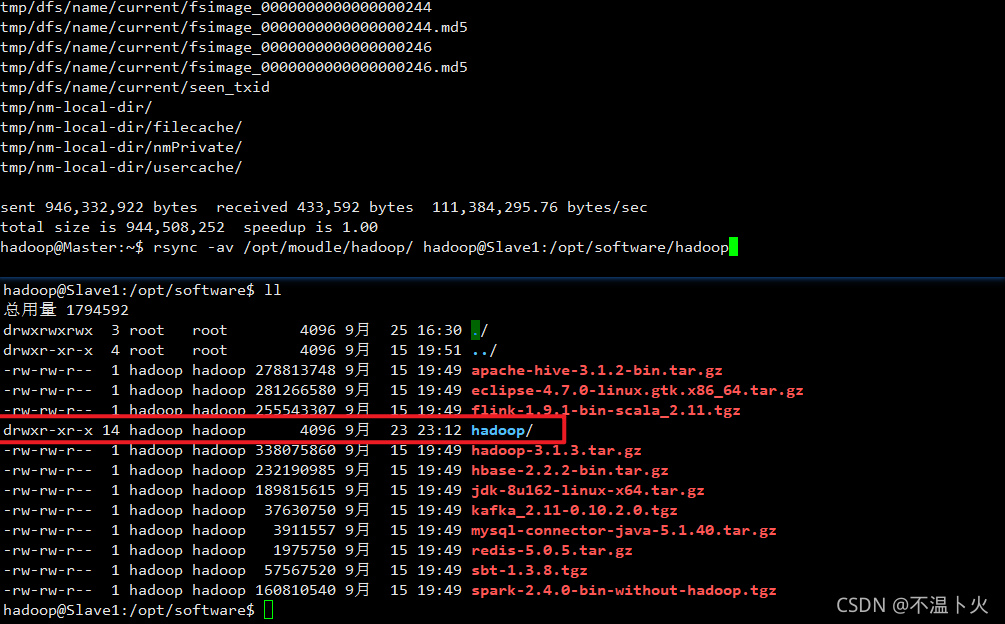
同步Master中的/opt/module/hadoop到Slave1中的/opt/software中
hadoop@Master:~$ rsync -av /opt/moudle/hadoop/ hadoop@Slave1:/opt/software/hadoop
4.3.3 xsync集群分发脚本
🔎1.需求
需求:循环复制文件到所有节点的相同目录下
🔎2.需求分析
?①rsync命令原始拷贝
hadoop@node01:~$ rsync -av /opt/moudle/ hadoop@Slave1:/opt
?②期望脚本
xsync要同步的文件名称
?③期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
hadoop@node01:~$ echo $PATH

如果还没有配置请按照下面进行操作
hadoop@node01:/bin$ vim ~/.bashrc
# 所要添加部分
export PATH=$PATH:/home/hadoop/bin
hadoop@node01:/bin$ source ~/.bashrc

🔎3.脚本实现
?①在/home/hadoop/bin目录下创建xsync文件
hadoop@node01:/bin$ cd /home/hadoop/
hadoop@node01:~$ mkdir bin
hadoop@node01:~$ cd bin/
hadoop@node01:~/bin$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in node01 node02 node03
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
?②修改脚本 xsync 具有执行权限
hadoop@node01:~/bin$ chmod +x xsync

?③测试脚本
hadoop@node01:~/bin$ xsync /home/hadoop/bin/ # /home/hadoop/bin 下的所有内容到 node02 node03
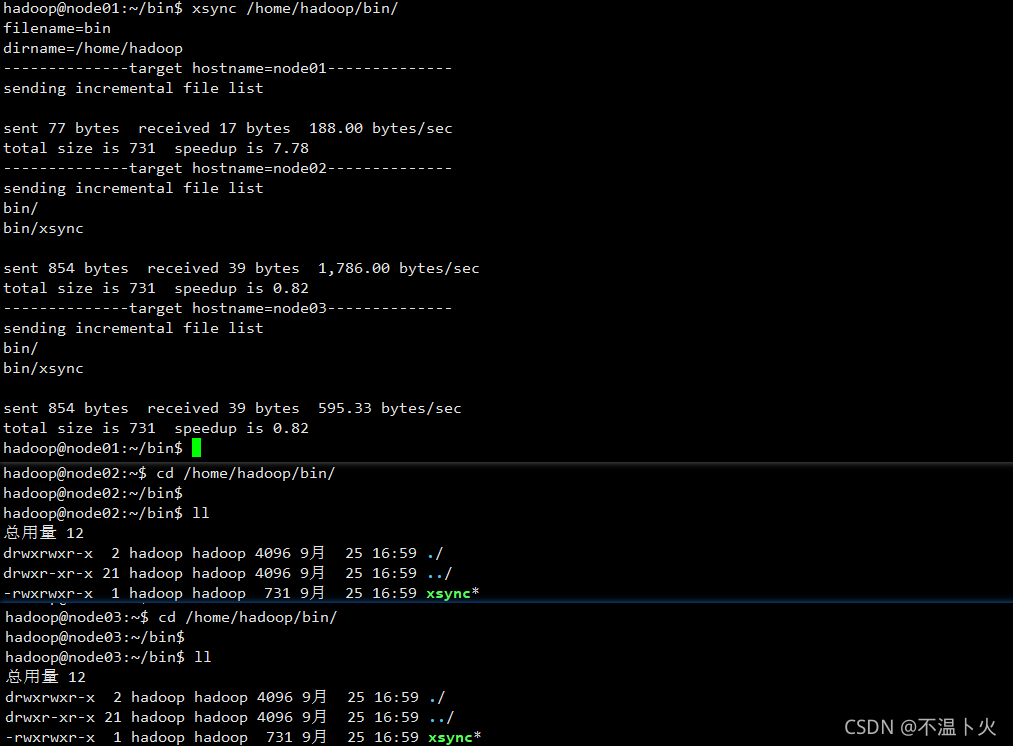
?④将脚本复制到/bin中,以便全局调用(从此步骤开始往下可以不用操作)
hadoop@node01:~/bin$ sudo cp xsync /bin/
hadoop@node01:~/bin$ sudo -i
root@node01:~# cd /bin/
root@node01:/bin# ll
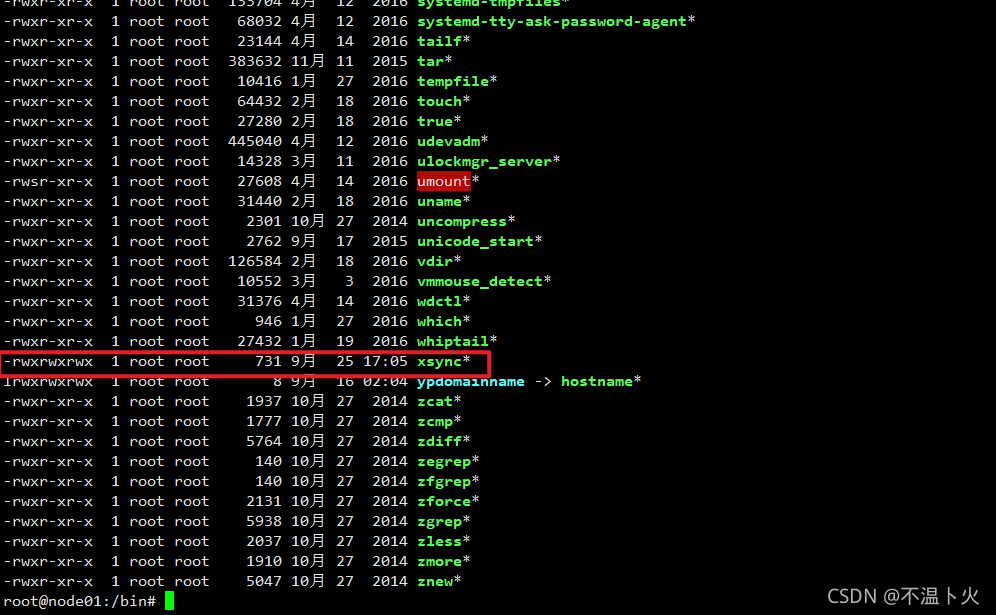
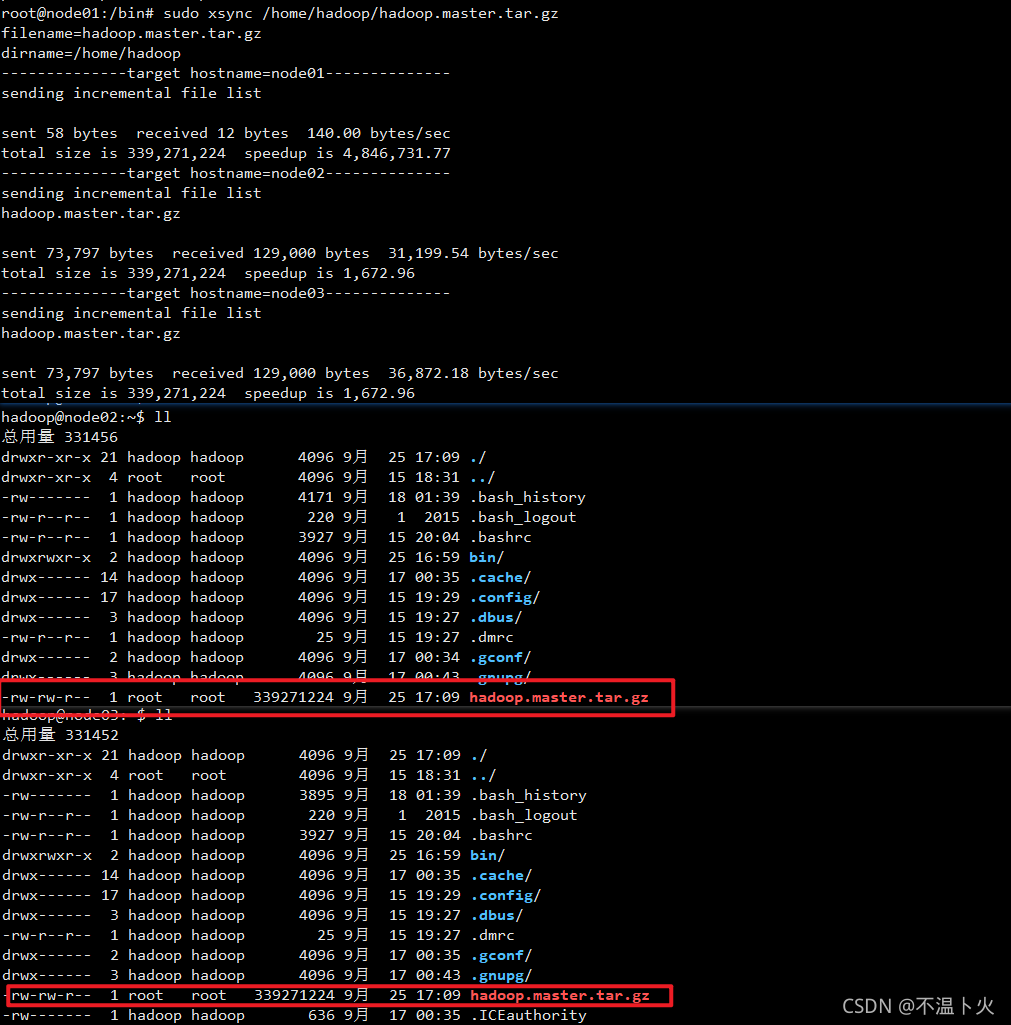
?⑤以root权限同步文件
root@node01:/bin# sudo xsync /home/hadoop/hadoop.master.tar.gz
本篇文章到这里就结束了,如有不足请指出~
