文章目录
- 1. 简述hadoop1与hadoop2 的架构异同
- 2. 请介绍一下hadoop的HDFS
- 3. Hadoop的运行模式有哪些
- 4. Hadoop生态圈的组件并做简要描述
- 5. 解释“hadoop”和“hadoop生态系统”两个概念
- 6. 请介绍HDFS的组成架构
- 7. HDFS的文件块大小有什么影响
- 8. HDFS的写(上传)数据流程
- 9. 机架感知(副本存储节点选择策略)
- 10. HDFS的读数据流程
- 11. NN 和 2NN 工作机制(元数据持久化机制)
- 12. Fsimage 和 Edits中的内容
- 13. NameNode与SecondaryNameNode 的区别与联系?
- 14. NameNode运行期间Editlog不断变大的问题
- 15. SecondaryNameNode的目的是什么?
- 16. 请简述DataNode工作机制
- 17. DataNode掉线时长是多少
- 18. HDFS可靠性机制(健壮性、容错性、数据完整性机制)
- 19. Hadoop集群安全模式
- 20. HDFS存储优化之纠删码原理
- 21. HDFS存储优化之异构存储(冷热数据分离)
- 22. 简要介绍一下MapReduce
- 23. MapReduce 进程有哪些
- 24. MapReduce之Hadoop的序列化
- 25. 切片与 MapTask 并行度决定机制
- 26. MapReduce的Job(或Task) 提交流程源码
- 27. FileInputFormat切片(InputSplit)流程源码
- 28. FileInputFormat的实现类有哪些
- 29. MapReduce 工作流程(重点)
- 30. Partitioner分区与ReduceTask 并行度决定机制
- 31. 如果没有定义 partitioner,那数据在被送达 reducer 前是如何被分区的?
- 32.如果MapTask的分区数不是1,但是ReduceTask为1,是否执行分区过程
- 33. 如何判定一个 job 的 map 和 reduce 的数量?
- 34. mapReduce 有几种排序及排序发生的阶段
- 35. MapReduce中setup、cleanup、run、context的作用
- 36. MapReduce 怎么实现 TopN?
- 37. OutputFormat 接口实现类
- 38. MapReduce 2.0 容错性、健壮性
- 39. MapReduce 推测执行算法及原理
- 40. 什么样的计算不能用 mr 来提速?
- 41. Hadoop所支持的几种压缩格式
- 42. Hadoop中的压缩位置
- 43. Hadoop 的缓存机制(Distributedcache)
- 44. 如何使用 mapReduce 实现两个表的 join?
- 45. MapReduce 跑的慢的原因
- 46. MapReduce 优化方法
- 47. MapReduce 数据倾斜问题
- 48. Hadoop 小文件优化方法
- 49. HDFS小文件归档
- 50. SequenceFile和MapFile的理解
- 51. 请简单介绍一下Yarn
- 52. Yarn的组成架构有哪些
- 53. YARN工作原理简述
- 54. YARN工作原理详述(源码角度)
- 55. Yarn 调度器和调度算法
- 56. 请列出正常工作的Hadoop集群中Hadoop都分别需要启动哪些进程,它们的作用分别是什么?
- 57. 请详细介绍一下Hadoop高可用的原理
1. 简述hadoop1与hadoop2 的架构异同
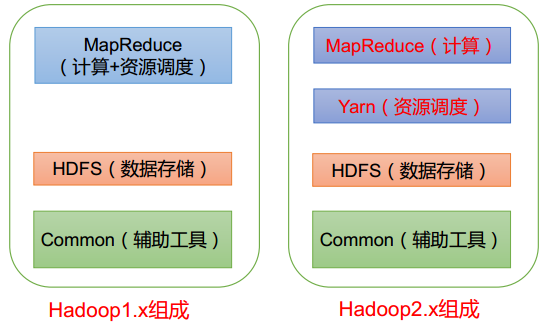
在hadoop1时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在hadoop2时代,增加了Yarn 。 Yarn 只负责资 源 的 调 度 ,MapReduce 只负责运算 。另外,hadoop HA加入了对zookeeper的支持实现比较可靠的高可用。
2. 请介绍一下hadoop的HDFS
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件; 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
HDFS优点
1)高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。

- 某一个副本丢失以后,它可以自动恢复。

2)适合处理大数据
- 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)可构建在廉价机器上,通过多副本机制,提高可靠性。
HDFS缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
- HDFS的block大小可以设置,默认为128M,一个文件块目录都是占用150字节,128M能存储9亿个小文件目录信息
3)不支持并发写入、文件随机修改。
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据append(追加),不支持文件的随机修改。
3. Hadoop的运行模式有哪些
本地模式、伪分布式模式、完全分布式模式
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用。
4. Hadoop生态圈的组件并做简要描述
1)Zookeeper: 是一个开源的分布式协调服务框架,为分布式系统提供一致性服务。基于zookeeper可以实现数据同步(数据发布/订阅),统计配置,命名服务。
2)Flume:是一个分布式的海量日志采集、聚合和传输的系统。
3)Hbase:是一个分布式的、面向列的开源数据库, 利用Hadoop HDFS作为其存储系统。
4)Hive:基于Hadoop的一个数据仓库工具,可以将结构化的数据档映射为一张数据库表,并提供简单的sql 查询功能,可以将sql语句转换为MapReduce任务进行运行。
5)Sqoop:将一个关系型数据库中的数据导进到Hadoop的 HDFS中,也可以将HDFS的数据导进到关系型数据库中。
5. 解释“hadoop”和“hadoop生态系统”两个概念
Hadoop是指Hadoop框架本身;hadoop生态系统,不仅包含hadoop,还包括保证hadoop框架正常高效运行其他框架,比如zookeeper、Flume、Hbase、Hive、Sqoop等辅助框架。
6. 请介绍HDFS的组成架构
(一)NameNode(nn):就是Master。NameNode负责管理整个文件系统的元数据,所有的文件路径和数据块的存储信息都保存在NameNode(其实就是文件系统中所有目录和文件inode的序列化形式)。除此之外,NameNode处理客户端读写请求,分发给DataNode去执行。
(二)DataNode:就是Slave。存储实际的数据块,执行真正的读写操作。
(三)Client:就是客户端。
- 文件切分。文件上传HDFS的时候,Client(根据NameNode数据块的大小)将文件切分成一个一个的Block,然后进行上传
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或者写入数据
- Client提供一些命令来管理HDFS,比如NameNode格式化
- Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
(四)SecondaryNameNode:并非NameNode的热备。SecondaryNameNode定期触发CheckPoint(服务),代替NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。同时在合并期间,NameNode也可以对外提供写操作。
7. HDFS的文件块大小有什么影响
HDFS 中的文件在物理上是分块存储 (Block ) , 块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
如果一个文件文件小于128M,该文件会占用128M的空间吗?不是的,它只占用文件本身大小的空间,其它空间别的文件也可以用,所以这128M的含义是HDFS数据块的大小,和每个文件的大小没有关系。
把下图的流程过一下:
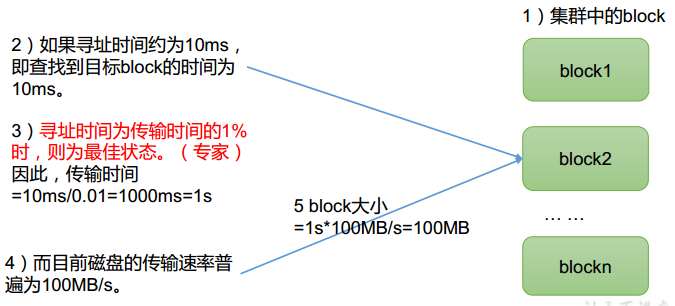
思考:为什么块的大小不能设置太小,也不能设置太大?
- HDFS的块设置太小,会增加寻址时间。例如,块的大小是1KB,文件大小是100KB,这时候要分100个块来存储文件,读取文件时要找到100个块的地址,会大大增加寻址时间。
- 如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。比如,块的大小是1TB,传输这个1TB的数据会非常慢,并且程序处理这个1TB的数据时,也非常的慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。对于一般硬盘来说,传输速率为100M/s,一般设置块的大小128M,因为128是2的7次方,最接近于100M。固态硬盘一般传输速率为200M/s~300M/s,可以设置块大小为256M。在企业,128M和256M是常用的块大小。
8. HDFS的写(上传)数据流程

(1)HDFS client创建DistributedFileSystem 对象,通过该对象向 NameNode 请求上传文件,NameNode 检查权限,并判断目标文件是否已存在。
(2)如果权限许可,目标文件也存在,NameNode进行响应,返回是否可以上传文件。
(3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4)NameNode 返回 3 个 DataNode 节点(默认副本数为3),分别为 dn1、dn2、dn3。(这一步要考虑服务器是否可用、副本存储节点选择策略、DataNode负载均衡)
(5) 客户端创建FSDataOutputStream数据流对象,通过该对象请求dn1(即DataNode1) 上传(或写)数据(即建立传输通道), dn1 收到请求会继续调用dn2建立通道,然后 dn2 调用 dn3,这样dn1~dn3的通信通道建立完成。
(6)传输通道建立完成后,dn1、dn2、dn3 逐级应答客户端。
(7)客户端开始往 dn1 上传第一个 Block (先从磁盘读取数据放到一个本地内存缓存),以Packet为单位(每次发送的是一个Packet对象),dn1 收到一个 Packet (直接从内存中)传给 dn2,dn2 传给 dn3。需要注意的是,这里传输的packet大小是64K,这个64K的packet其实就是一个缓冲队列,里面包含多个(chunk和chunksum),一个chunk是512byte,其校验码chunksum是4byte。dn1 每传一个 packet会放入一个应答队列(即ack队列,起备份作用)等待应答,当所有的DataNode应答成功后,会将该packet从应答队列中移除。
(8)当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 到服务器。(重复执行 3-7 步)。
(9)所有的Block传输完毕并确认完成后,HDFS CLient关闭FSDataOutputStream数据流对象。然后,HDFS Client联系NameNode,确认数据写完成,NameNode 在内存中对其元数据进行增删改(然后再通过SecondaryNameNode对元数据进行修改)。注意,此时只是把更新操作记录到编辑日志Editlog,并没有真正合并编辑日志和镜像文件,只有触发checkPoint才合并。
9. 机架感知(副本存储节点选择策略)
Hadoop3.1.3官方说明:http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
默认情况下,HDFS中的数据块有3个副本。副本存储策略如下(看源码):
- 第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
- 第二个副本在另一个机架的随机一个节点
- 第三个副本在第二个副本所在机架的随机节点
- 第四个及以上,随机选择副本存放位置。
这么选的好处:
- 第一个副本在本地,考虑到结点距离最近,上传速度最快
- 第二个副本在另一个机架的节点上,考虑到数据的可靠性
- 第三个副本在第二个副本所在机架的节点,又要兼顾对应的效率
副本距离计算公式:
两个节点到达最近的共同祖先的距离总和(其实就是数路径个数)。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为/d1/r1/n1。利用这种标记,下图给出四种距离描述。
- Distance(/d1/r1/n0,/d1/r1/n0)=0 :同一台服务器的距离为0
- Distance(/d1/r1/n1,/d1/r1/n2)=2 :同一机架不同的服务器距离为2
- Distance(/d1/r2/n0,/d1/r3/n2)=4 :不同机架的服务器距离为4

10. HDFS的读数据流程

(1)HDFS client创建DistributedFileSystem 对象,通过该对象向 NameNode 请求下载文件,NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
(2)挑选一台 DataNode(要考虑结点距离最近选择原则、DataNode负载均衡)服务器,请求读取数据。
(3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验),串行读取,即先读取第一个块,再读取第二个块拼接到上一个块后面。
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
11. NN 和 2NN 工作机制(元数据持久化机制)

(一)第一阶段:NameNode 启动
(1)第一次启动 NameNode 格式化后,创建 镜像文件fsimage 和 编辑日志edits_inprogress_001 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode 记录更新操作到edits_inprogress_001 中
(4)NameNode 在内存中对元数据进行增删改(然后再通过SecondaryNameNode对元数据进行修改)。
(二)第二阶段:Secondary NameNode 工作
(1)Secondary NameNode 询问 NameNode 是否需要 CheckPoint(即是否需要服务),带回 NameNode是否可服务的条件。CheckPoint触发条件:定时时间到;Edits中的数据满了。
(2)Secondary NameNode 请求执行 CheckPoint(即请求服务)。
(3)NameNode 滚动正在写的 edits_inprogress_001 日志,将其命名为edits_001,并生产新的日志文件edits_inprogress_002,以后再有客户端操作,日志将记录到edits_inprogress_002中。
(4)将编辑日志edits_001和镜像文件fsimage拷贝到 SecondaryNameNode。
(5)Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件 fsimage.chkpoint。
(7)拷贝 fsimage.chkpoint 到 NameNode。
(8)NameNode 将 fsimage.chkpoint 重新命名成 fsimage(此时的fsimage是最新的)。
NN存储的是edits_inprogress,2NN存储的是edits。
12. Fsimage 和 Edits中的内容
NameNode被格式化之后,将在/opt/module/hadoop-3.1.3/data/dfs/name/current目录中产生如下文件

(1)FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一个文件或目录的元数据的内部表示,包含的信息有:文件或目录的创建、修改和访问时间、访问权限、块大小以及组成文件的块。
FsImage文件没有记录块存储在哪个数据节点。而是由NameNode把这些映射保留在内存中,当DataNode加入HDFS集群时,DataNode会把自己所包含的块列表告知给NameNode,此后会定期执行这种告知操作,以确保NameNode的块映射是最新的。
(2)Edits文件:存放HDFS文件系统的所有更新的操作,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
(3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字
思考:NameNode 如何确定下次开机启动的时候合并哪些 Edits?
可以根据seen_txid文件保存的是一个数字,seen_txid保存的就是最后一个edits_的数字,是最新的edits。
13. NameNode与SecondaryNameNode 的区别与联系?
区别
(1)NameNode负责管理整个文件系统的元数据,所有的文件路径和数据块的存储信息都保存在NameNode(其实就是文件系统中所有目录和文件inode的序列化形式),除此之外,NameNode处理客户端读写请求,分发给DataNode去执行。
(2)SecondaryNameNode:并非NameNode的热备。SecondaryNameNode定期触发CheckPoint(服务),代替NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。同时在合并期间,NameNode也可以对外提供写操作。而SecondaryNameNode至始至终不能对外提供写操作。
联系
(1)SecondaryNameNode中保存了一份和namenode一致的历史镜像文件(fsimage)和历史编辑日志(edits)。但是, NameNode还有一份正在使用的编辑日志edit_inporgress,这是SecondaryNameNode没有的
(2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复历史的数据。
14. NameNode运行期间Editlog不断变大的问题
Hadoop1版本中,在NameNode运行期间,HDFS的所有更新操作都是直接写到EditLog中,久而久之, EditLog文件将会变得很大。
虽然这对NameNode运行时候是没有什么明显影响的,但是,当名称节点重启的时候,名称节点需要先将FsImage里面的所有内容映像到内存中,然后再一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,会导致名称节点启动操作非常慢,而在这段时间内HDFS系统处于安全模式(即合并编辑日志EditLog和镜像文件Fsimage期间不能对外提供服务),一直无法对外提供写操作,影响了用户的使用。
如何解决?答案是:SecondaryNameNode第二名称节点
SecondaryNameNode定期触发CheckPoint,代表NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。同时在合并期间,NameNode也可以对外提供写操作。
15. SecondaryNameNode的目的是什么?
SecondaryNameNode定期触发CheckPoint,代表NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。同时在合并期间,NameNode也可以对外提供写操作。
16. 请简述DataNode工作机制

(1)一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据的校验信息包括数据块的长度,块数据的校验和,以及时间戳。
(2) DataNode 启动后向 NameNode 注册,之后周期性(默认 6 小时)的向 NameNode 上报所有的块信息。同时,DN 扫描自己节点块信息列表的时间,检查DN中的块是否完好,如果某块磁盘损坏,就将该块磁盘上存储的所有 BlockID报告给NameNode。
(3)心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。 如果超过 10 分钟 + 30s 没有收到某个 DataNode 的心跳,则认为该节点不可用。
17. DataNode掉线时长是多少

18. HDFS可靠性机制(健壮性、容错性、数据完整性机制)
HDFS主要目的是保证存储数据完整性,对于各组件的失效,做了可靠性处理。
(1)数据存储故障容错
磁盘介质在存储过程中受环境或者老化影响,其存储的数据可能会出现错乱。HDFS的应对措施是,对于存储在DataNode上的数据块,计算并存储校验和(CheckSum)。在读取数据的时候,重新计算读取出来的数据的校验和,如果校验不正确就抛出异常,应用程序捕获异常后就到其他DataNode 上读取备份数据。
(2)磁盘故障容错
如果DataNode监测到本机的某块磁盘损坏,就将该块磁盘上存储的所有 BlockID报告给NameNode,NameNode检查这些数据块还在哪些DataNode上有备份,通知相应的DataNode服务器将对应的数据块复制到其他服务器上,以保证数据块的备份数满足要求。
(3)DataNode 故障容错
DataNode会通过心跳和NameNode保持通信,如果DataNode超时未发送心跳,并超过 10 分钟 + 30s 没有收到某个 DataNode 的心跳,则NameNode认为该节点不可用,立即查找这个 DataNode上存储的数据块有哪些,以及这些数据块还存储在哪些服务器上,随后通知这些服务器再复制一份数据块到其他服务器上,保证HDFS存储的数据块备份数符合用户设置的数目,即使再出现服务器宕机,也不会丢失数据。
‘(4)NameNode故障容错
NameNode负责管理整个文件系统的元数据,所有的文件路径和数据块的存储信息都保存在NameNode(其实就是文件系统中所有目录和文件inode的序列化形式),除此之外,NameNode处理客户端读写请求,分发给DataNode去执行。如果NameNode故障,整个 HDFS系统集群都无法使用;如果 NameNode上记录的数据丢失,整个集群所有DataNode存储的数据也就没用了。
所以,NameNode高可用容错能力非常重要。NameNode可以采用HDFS NameNode 的高可用机制,具体见Hadoop高可用那一题。
总结:正是因为HDFS的这些策略,才保证存储数据完整性,为运行于Hadoop之上的应用,提供稳固的支持。
19. Hadoop集群安全模式
安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求
进入安全模式场景
- NameNode 在启动时加载镜像文件和编辑日志期间处于安全模式
- NameNode 在接收 DataNode 注册时,处于安全模式【因为NN要知道DN都有哪些块才能对外提供服务】
退出安全模式有三个条件
条件一:集群上最小可用的datanode 数量大于0
dfs.namenode.safemode.min.datanodes:最小可用 datanode 数量,默认 0。
条件二:系统中99.99%的数据块都可用了,即系统中只允许丢一个块
dfs.namenode.safemode.threshold-pct:副本数达到最小要求的 block 占系统总 block 数的
百分比,默认 0.999f。(只允许丢一个块)
条件三:集群在启动过后得过了30s之后才能退出安全模式
dfs.namenode.safemode.extension:稳定时间,默认值 30000 毫秒,即 30 秒
20. HDFS存储优化之纠删码原理
HDFS 默认情况下,一个文件有 3 个副本,这样提高了数据的可靠性,但也多带来了 2 倍的冗余开销。 Hadoop3.x 引入了纠删码, 采用计算的方式, 可以节省约 50%左右的存储空间。
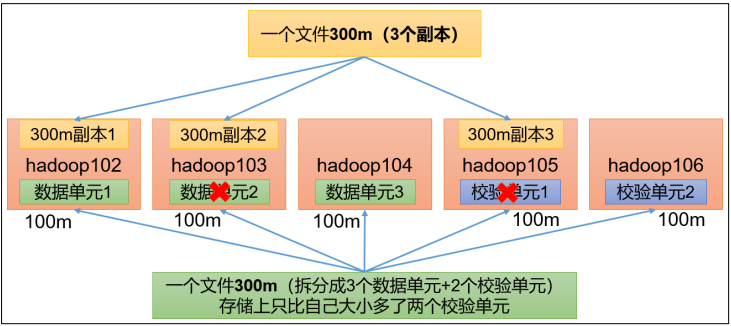
RS-3-2-1024k:使用 RS 编码,把一个文件拆成 3 个数据单元,生成 2 个校验单元,共 5 个单元,也就是说:这 5 个单元中,只要有任意的 3 个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是 1024k=1024*1024=1048576。
这个的每个单元的大小是 1024k是指最小单元为1M,如果一个文件大小为300M,则这个文件会分成300个数据单元,然后采用3-2策略,即每100个最小单元组成1个数据单元,这样就可以组成3个数据单元。这样总共900M的存储开销降到了500M。
RS-10-4-1024k:使用 RS 编码,每 10 个数据单元(cell),生成 4 个校验单元,共 14个单元,也就是说:这 14 个单元中,只要有任意的 10 个单元存在 (不管是数据单元还是校验单元,只要总数=10),就可以得到原始数据。每个单元的大小是 1024k=1024*1024=1048576。
RS-6-3-1024k:使用 RS 编码,每 6 个数据单元,生成 3 个校验单元,共 9 个单元,也就是说:这 9 个单元中,只要有任意的 6 个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。每个单元的大小是 1024k=1024*1024=1048576。
RS-LEGACY -6-3-1024k:策略和上面的 RS-6-3-1024k 一样,只是编码的算法用的是 rslegacy。 XOR-2-11024k:使用 XOR 编码(速度比 RS 编码快),每 2 个数据单元,生成 1 个校验单元,共 3 个单元,也就是说:这 3 个单元中,只要有任意的 2 个单元存在(不管是数据单元还是校验单元,只要总数 = 2 ),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
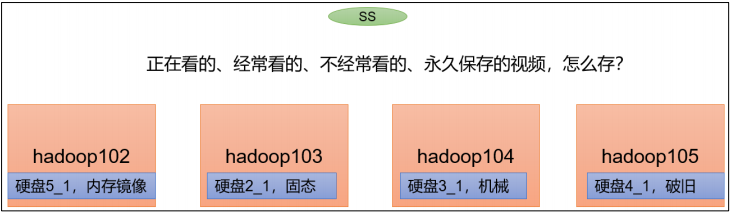
21. HDFS存储优化之异构存储(冷热数据分离)
异构存储主要解决,不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
存储类型
RAM_DISK:(内存镜像文件系统)
SSD:(SSD固态硬盘)
DISK:(普通磁盘,在HDFS中,如果没有主动声明数据目录存储类型默认都是DISK)
ARCHIVE:(没有特指哪种存储介质,主要的指的是计算能力比较弱而存储密度比较高的存储介质,用来解决数据量的容量扩增的问题,一般用于归档)
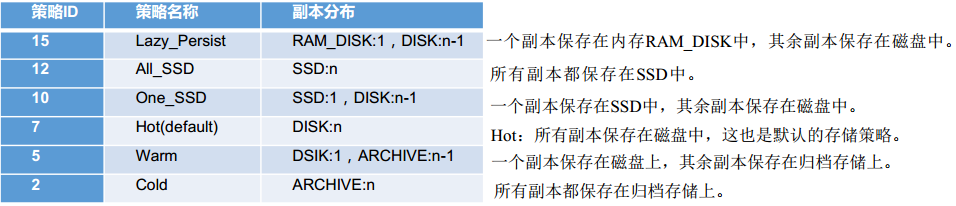
存储策略
说明:从Lazy_Persist到Cold,分别代表了设备的访问速度从快到慢
22. 简要介绍一下MapReduce
MapReduce 是一个分布式运算程序的编程框架,它的核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
优点
1)MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序, 这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
4)适合 TB/PB 级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点
1)不擅长实时计算
MapReduce 无法像 MySQL 一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而 MapReduce 的输入数据集是静态的,不能动态变化。这是因为 MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长 DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后, 每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
23. MapReduce 进程有哪些
整体框架:

一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序 (一个Job或Task或Mr)的过程调度及状态协调。【查到的进程就是它自己】
(2)MapTask:负责 Map 阶段的整个数据处理流程。【查到的进程是YarnChild】
(3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。 【查到的进程是YarnChild】
24. MapReduce之Hadoop的序列化
(1)什么是序列化
序列化就是把内存中的对象,转换成字节序列 (或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
(2)为什么不用 Java 的序列化
Java 的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息, Header,继承体系等),不便于在网络中高效传输。所以,Hadoop 自己开发了一套序列化机制(Writable)。
(3)Hadoop 序列化特点:
- 紧凑 :高效使用存储空间。
- 快速:读写数据的额外开销小。
- 互操作:支持多语言的交互
(4)如何实现hadoop的序列化
具体实现 bean 对象序列化步骤如下 7 步。
- 必须实现 Writable 接口
- 必须有空参构造。(反序列化时,需要反射调用空参构造函数,所以必须有空参构造。如果没有任何构造函数,可以不写,如果有了带参的构造函数,必须加上空参构造函数)。
- 重写序列化write方法
- 重写反序列化readFields方法
- 注意反序列化的顺序和序列化的顺序完全一致
- 要想把结果显示在文件中,需要重写 toString(),可用"\t"分开,方便后续用(注意默认传输过来的是地址值)。
- 如果需要将自定义的 bean 放在 key 中传输,则还需要实现 Comparable 接口,重写compareTo方法,因为MapReduce 框中的 Shuffle 过程要求对 key 必须能排序。【也可直接实现WritableComparable】
25. 切片与 MapTask 并行度决定机制
(1)问题引入
MapTask 的并行度决定 Map 阶段的任务处理并发度,进而影响到整个 Job 的处理速度。
MapTask并不是也多越好,也不是越好越好。太少,并行能力较弱,会导致task等待,延长处理时间;太多,可能会导致任务启动的时间大于任务本身处理的时间,会得不偿失,并且会造成很多资源的浪费,比如1M的文件开启10个MapTask就没必要,而1G文件开启10个MapTask就很有必要了。
(2)MapTask 并行度决定机制
- 数据块:Block 是 HDFS 物理上把数据分成一块一块(默认是128M)。数据块是 HDFS 存储数据单位。
- 数据切片: 数据切片只是在逻辑上对输入进行分片, 并不会在磁盘上将其切分成片进行存储。 数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个 MapTask。
数据切片与MapTask并行度决定机制

26. MapReduce的Job(或Task) 提交流程源码
Job提交流程源码详解
waitForCompletion();
submit();
// 一、建立连接
connect();
// 创建提交 Job 的代理
new Cluster(getConfiguration());
// 判断是本地运行环境还是 yarn 集群运行环境
initialize(jobTrackAddr, conf);
// 二、提交 job
submitter.submitJobInternal(Job.this, cluster)
// (1)创建给集群提交数据的 Stag 路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// (2)获取 jobid ,并创建 Job 路径
JobID jobId = submitClient.getNewJobID();
// (3)拷贝 jar 包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// (4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// (5)向 Stag 路径写 XML 配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// (6)提交 Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(),job.getCredentials());

总结:
- 建立连接,创建提交 Job 的集群代理
- 创建给集群提交数据的 Stag 路径,如果是本地运行环境使用file协议,如果是yarn集群运行环境,则使用HDFS协议
- 获取 jobid,将jobid和Stag路径拼接起来,用于该任务的提交路径
- 调用
FileInputFormat.getSplits()切片规划,并序列化成Job.split - 将Job相关参数写到文件Job.xml
- 如果是yarn集群运行环境,还需要拷贝拷贝 jar 包到集群
27. FileInputFormat切片(InputSplit)流程源码
FileInputFormat切片源码解析(input.getSplits(job)即InputSplit)【这是hadoop3.1.3的源码】
(1)程序先找到输入数据存储的目录。
(2)开始遍历处理目录下的每一个文件
(3)按照每一个文件单独切片,具体如下:
(a)获取文件大小fs.sizeOf(ss.txt)
(b)计算切片大小`computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M`
(c)默认情况下,切片大小=blocksize,如果增大切片大小,则将minSize设置大于128M,如果要减小切片大小,则将maxSize设置小于128M
(d)开始切,形成第1个切片:ss.txt―0:128M 第2个切片ss.txt―128:256M 第3个切片ss.txt―256M:300M(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,大于1.1倍就划分一块切片,小于1.1倍就不再切了)
(e)将切片信息写到一个切片规划Job.split文件中
(f)整个切片的核心过程在getSplit()方法中完成
(g)InputSplit只是在物理上记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
(4)提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。
注意:Math.max(minSize, Math.min(maxSize, blockSize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
28. FileInputFormat的实现类有哪些
思考:在运行 MapReduce 程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。 那么,针对不同的数据类型, MapReduce 是如何读取这些数据的呢?
FileInputFormat 常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、CombineTextInputFormat、NLineInputFormat和自定义 InputFormat 等。
(1)TextInputFormat
TextInputFormat 是默认的 FileInputFormat 实现类。按行读取每条记录。 键是存储该行在整个文件中的起始字节偏移量, LongWritable 类型。值是这行的内容,不包括任何行终止符(换行符和回车符),是Text 类型。
(2)KeyValueTextInputFormat
CombineTextInputFormat 用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片,以减少切片的数量。
每行均为一条记录,被分隔符分割为key,value。可以通过在驱动类中设置conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");来设定分隔符。默认分隔符是tab(\t)。分隔符前面的内容是key,分隔符后面的内容是value(Key和value的类型由用户定义)。
(3)NLineInputFormat
如果使用NLineInputFormat指定的行数N来划分切片。即输入文件的总行数 除以 N =切片数,如果不整除,切片数=商+1。
(4)CombineTextInputFormat
框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个 MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
(4.1)应用场景:
CombineTextInputFormat 用于小文件过多的场景, 它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个 MapTask 处理。
(4.2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
(4.3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。 举个例子来说明:
假如有四个文件,每个文件大小如下:
a.txt 1.7M
b.txt 5.1M
c.txt 3.4M
d.txt 6.8M
处理过程如下图所示

第一步:虚拟存储过程
将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个虚拟块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块; 当剩余数据大小超过设置的最大值且不大于最大值 2 倍,此时将文件均分成 2 个虚拟存储块(防止出现太小切片),最终形成多个虚拟存储的文件。
例如 setMaxInputSplitSize 值为 4M,输入文件大小为 8.02M,则先逻辑上分成一个4M。剩余的大小为 4.02M,如果按照 4M 逻辑划分,就会出现 0.02M 的小的虚拟存储文件,所以将剩余的 4.02M 文件切分成(2.01M 和 2.01M)两个文件。
第二步:切片过程
(a)判断虚拟存储的文件大小是否大于 setMaxInputSplitSize 值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片,依次类推,直到产生大于4M的切片为止。
(c) 测试举例:有 4 个小文件大小分别为 1.7M、 5.1M、 3.4M 以及 6.8M 这四个小文件,则虚拟存储之后形成 6 个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M 以及(3.4M、3.4M)
最终会形成 3 个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
29. MapReduce 工作流程(重点)
整体框架:
MapReduce详细工作流程


参考:https://mp.weixin.qq.com/s/uAySEG98urCgwD0uB6kimg
假如有一个200M的待处理文件,具体工作流程如下:
-
切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按128M每块进行切片。(InputSplit的切片流程,具体看27题)
-
提交:提交可以提交到本地工作环境或者Yarn工作环境,本地只需要提交切片规划Job.split和Job相关参数文件Job.xml,Yarn环境还需要提交jar包;本地环境一般只作为测试用。(Job提交流程,具体看26题)
-
将job提交到yarn上(或本地环境后),YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数(详细见后边的Yarn工作流程介绍)。
-
MapTask中执行Mapper的map方法,此方法需要k和v作为输入参数,所以会首先获取kv值;
-
- 首先调用InputFormat方法,默认为TextInputFormat方法,在此方法调用createRecoderReader方法,一行1一行读取数据封装为k,v键值对,传递给map方法
-
map方法进行一系列用户写的逻辑操作,到这里map阶段其实已经完成了,下面进入Shuffer阶段
-
map处理完成相关的逻辑操作之后,会产生一系列新的key/value,首先通过OutputCollector.collect()向环形缓冲区写入数据,环形缓冲区主要两部分,一部分写入数据的索引信息,另一部分写入数据的内容。环形缓冲区的默认大小是100M,当缓冲的容量达到默认大小的80%时,开启一个新的线程进行反向溢写,之所以反向溢写是因为这样就可以边接收数据边往磁盘溢写数据。
-
在环形缓冲区溢写到文件之前,会将缓冲区中的的数据(调用Partitioner)进行分区,并针对Key的索引按照字典顺序进行快速排序。
-
在分区和排序之后,溢写到磁盘,可能发生多次溢写,溢写到多个文件。
-
对所有溢写到磁盘的文件进行归并排序。
-
在9到10步之间还可以有一个Combine合并操作,意义是对每个MapTask的输出进行局部汇总,以减少网络传输量:
-
Map阶段的进程数一般比Reduce阶段要多,所以放在Map阶段处理效率更高
-
Map阶段合并之后,传递给Reduce的数据就会少很多
-
但是Combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出kv要和Reduce的输入kv类型对应起来。
例如,我们要求平均值,就不符合要求。但是,如果我们要求和,那么使用Combiner后,不影响最终结果。
-
-
另外,在第10步,还可以进行压缩(主要是用snappy和lzo,主要是快),以减少网络传输量。下面是Reduce阶段
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
- MapTask结束后,启动相应数量的ReduceTask(和分区数量相同)
- ReduceTask从每个MapTask上远程拷贝(拉取)相应的数据文件,如果文件大小超过一定阈值(即超过ReduceTask进程内存缓冲区的大小),则溢写磁盘上,否则存储在内存中。(如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上)。当所有数据拷贝完毕后,ReduceTask 统一对内存和磁盘上的所有数据进行一次归并排序。
- 最后将数据传给reduce进行处理,一次读取一组数据。
- 最后通过OutputFormat输出,默认为TextOutputFormat方法,在此方法调用createRecoderWrite将结果写到HDFS中。
30. Partitioner分区与ReduceTask 并行度决定机制
MapTask 并行度由切片个数决定,切片个数由输入文件和切片规则决定。ReduceTask 的并行度同样影响整个 Job 的执行并发度和执行效率,但与 MapTask 的并发数由切片数决定不同,ReduceTask 数量的决定是可以直接手动设置,一般与getPartition的结果数相同
(1)问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
(2)默认Partitioner分区
java
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
默认分区是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。
(3)自定义Partitioner步骤
① 自定义类继承Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制分区代码逻辑
… …
return partition;
}
}
② 在Job驱动中,设置自定义Partitioner
job.setPartitionerClass(CustomPartitioner.class);
③ 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
job.setNumReduceTasks(5);
(4)分区总结
- 如果ReduceTask的数量
>getPartition的结果数,则会多产生几个空的输出文件part-r-000xx - 如果1
<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会抛出Exception - 如果ReduceTask的数量=1,则不管getPartition的结果数为多少,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件 part-r-00000。
- ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
- ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
- 具体多少个ReduceTask,需要根据集群性能而定。
- 如果MapTask的分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
- 分区号必须从零开始,逐一累加。
(5)案例分析
例如:假设自定义分区数为5,则
job.setNumReduceTasks(1); //会正常运行,只不过会产生一个输出文件
job.setNumReduceTasks(2); //会报错
job.setNumReduceTasks(6); //大于5,程序会正常运行,会产生空文件
// 不写job.setNumReduceTasks,默认同job.setNumReduceTasks(1)
job.setNumReduceTasks(0); //相当于没有reduce阶段
31. 如果没有定义 partitioner,那数据在被送达 reducer 前是如何被分区的?
如果没有自定义的 partitioner,则默认的 partition 算法,即根据每一条数据的 key 的 hashcode 值摸运算(%)reduce 的数量,得到的数字就是“分区号“。 用户没法控制哪个key存储到哪个分区。
32.如果MapTask的分区数不是1,但是ReduceTask为1,是否执行分区过程
如果MapTask的分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
33. 如何判定一个 job 的 map 和 reduce 的数量?
1)map 数量
splitSize=computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
默认情况下,切片大小=blocksize,如果增大切片大小,则将minSize设置大于128M,如果要减小切片大小,则将maxSize设置小于128M。
map 数量由处理的数据分成的 block 数量决定 default_num = total_size / split_size;
注意,每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,大于1.1倍就划分一块切片,小于1.1倍就不再切了。
2)reduce 数量
reduce 的数量 job.setNumReduceTasks(x);x 为 reduce 的数量。不设置的话默认为 1。
但是要注意,ReduceTask的数量并不是随意设置的:
- 如果ReduceTask的数量
>getPartition的结果数,则会多产生几个空的输出文件part-r-000xx - 如果1
<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会抛出Exception - 如果ReduceTask的数量=1,则不管getPartition的结果数为多少,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件 part-r-00000。
- ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
- ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
- 具体多少个ReduceTask,需要根据集群性能而定。
- 如果MapTask的分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
- 分区号必须从零开始,逐一累加。
(3)MapTask和ReaduceTask数量的合理性
MapTask和ReaduceTask的数量并不是也多越好,也不是越好越好,要根据具体情况而定。太少,并行能力较弱,会导致task等待,延长处理时间;太多,可能会导致任务启动的时间大于任务本身处理的时间,会得不偿失,并且会造成很多资源的浪费,比如1M的文件开启10个MapTask就没必要,而1G文件开启10个MapTask就很有必要了。
34. mapReduce 有几种排序及排序发生的阶段
排序是MapReduce框架中最重要的操作之一。
MapTask 和 ReduceTask 均会对数据 按照 key 进行排序 。 该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值(80%)后,再对缓冲区中的数据进行一次快速排序(排序的过程是在内存中完成的),并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值(即超过ReduceTask进程内存缓冲区的大小),则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask 统一对内存和磁盘上的所有数据进行一次归并排序。
(一)排序分类
(1)部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
(2)全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
替代方案:首先创建一系列排好序的文件;其次,串联这些文件;最后,生成一个全局排序的文件。具体做法是使用自定义的分区来描述输出的全局排序。例如:可以为待分析文件创建 3 个分区,在第一分区中,记录的单词首字母 a-g,第二分区记录单词首字母 h-n, 第三分区记录单词首字母 o-z。
(3)辅助排序:(GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
(4)二次排序(或自定义排序)
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
(二)自定义排序WritableComparable原理分析
bean对象做为 key 传输,需要实现 WritableComparable 接口(如果只是序列化,则实现Writable 接口就行)重写 compareTo 方法, 就可以实现排序。
@Override
public int compareTo(FlowBean bean) {
int result;
// 按照总流量大小,倒序排列
if (this.sumFlow > bean.getSumFlow()) {
result = -1;
}else if (this.sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
35. MapReduce中setup、cleanup、run、context的作用
参考:https://mp.weixin.qq.com/s/_e2aJsgd7J41_SozRaYfpw
Mapper类中的方法:
- 抽象类Context
- 方法setup
- 方法cleanup
- 方法map
- 方法run
Mapper类中的方法:
- 抽象类Context
- 方法setup
- 方法cleanup
- 方法reduce
- 方法run
(1)setup(),此方法被MapReduce框架仅且执行一次,在执行Map任务前,进行相关变量或者资源的集中初始化工作。若是将资源初始化工作放在方法map()中,导致Mapper任务在解析每一行输入时都会进行资源初始化工作,导致重复,程序运行效率不高!
(2)cleanup(),此方法被MapReduce框架仅且执行一次,在执行完毕Map任务后,进行相关变量或资源的释放工作。若是将释放资源工作放入方法map()中,也会导致Mapper任务在解析、处理每一行文本后释放资源,而且在下一行文本解析前还要重复初始化,导致反复重复,程序运行效率不高!
(3)run 是程序启动运行,下面看一下run方法
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
(3)Context 是MapReduce任务运行的一个上下文,包含了整个任务的全部信息context作为了map和reduce执行中各个函数的一个桥梁,这个设计和java web中的session对象、application对象很相似。
(4)执行顺序
setup---->map或reduce----->cleanup
解:Setup一般是在执行map函数前做一些准备工作,map是主要的处理业务逻辑,cleanup则是在map执行完成后做一些清理工作和finally字句的作用很像,
36. MapReduce 怎么实现 TopN?
具体实验看:https://cloud.tencent.com/edu/learning/course-3084-55772
首先,定义符合业务逻辑的Bean类,并实现WritableComparable中的compareTo方法
然后,定义一个TopNMapper,添加一个全局的TreeMap对象(天然按key排序),其key的类型为Bean,value根据情况而定,然后在map里面将每一个行记录定义一个Bean对象,放在treeMap中,并判断treeMap.Size()是否大于N,如果大于N,则执行treeMap.remove(treeMap.firstKey())移除最小的key,这样就能一直保证treeMap中只有N个最大的数据。通过Mapper的cleanup方法通过context.write一次性将treeMap中的内容写出(写出的key是Bean,value视情况而定)。这样就完成了一个MapTask的TopN实现,但是根据实际文件个数和文件大小的不同,很可能有多个MapTask,所以要在Reduce阶段再次实现TopN。
定义一个TopNReducer,同样添加一个全局的TreeMap对象(天然按key排序),在reduce里面的业务逻辑和map里面相同,一直保证treeMap中只有N个最大的数据,最后通过Reducer的cleanup方法一次性将treeMap中的内容写出。
这样就实现了全局的TopN。
37. OutputFormat 接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了 OutputFormat接口。下面我们介绍几种常见的OutputFormat实现类。
- 默认输出格式为TextOutputFormat,功能逻辑是:将每一个 KV 对,向目标文本文件输出一行。
- 自定义OutputFormat
- 应用场景:输出数据到MySQL/HBase/Elasticsearch等存储框架中。
- 自定义OutputFormat步骤
? 自定义一个类继承FileOutputFormat。
? 重写getRecordWriter方法,具体是重写RecordWrite的write()方法。
38. MapReduce 2.0 容错性、健壮性
1)MRAppMaster容错性
一旦运行失败,由YARN的ResourceManager负责重新启动,最多重启次数可由用户设置,默认是2次。一旦超过最高重启次数,则作业运行失败。
2)MapTask/ReduceTask
Task周期性向MRAppMaster汇报心跳;一旦Task挂掉,则MRAppMaster将为之重新申请资源,并运行之。最多重新运行次数可由用户设置,默认4次。
39. MapReduce 推测执行算法及原理
1)作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map 任务和Reduce 任务构成。因硬件老化、软件Bug 等,某些任务可能运行非常慢。
典型案例:系统中有99%的Map任务都完成了,只有少数几个Map老是进度很慢,完不成,怎么办?
2)推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度。为拖后腿任务启动一个备份任务,同时运行。谁先运行完,则采用谁的结果。
3)不能启用推测执行机制情况
(1)任务间存在严重的数据负载倾斜;
(2)特殊任务,比如任务向数据库中写数据。
4)算法原理
假设某一时刻,任务T的执行进度为progress(是一个百分比),则可通过一定的算法推测出该任务的最终完成时刻estimateEndTime1。另一方面,如果此刻为该任务启动一个备份任务,则可推断出它可能的完成时刻estimateEndTime2,于是可得出以下几个公式:
estimatedRunTime=(currentTimestamp-taskStartTime)/progress
estimateEndTime1=estimatedRunTime+taskStartTime
estimateEndTime2= currentTimestamp+averageRunTime
其中,currentTimestamp为当前时刻;taskStartTime为该任务的启动时刻;averageRunTime为已经成功运行完成的任务的平均运行时间。这样,MRv2总是选择(estimateEndTime1- estimateEndTime2)差值最大的任务,并为之启动备份任务。为了防止大量任务同时启动备份任务造成的资源浪费,MRv2为每个作业设置了同时启动的备份任务数目上限。
推测执行机制实际上采用了经典的算法优化方法:以空间换时间,它同时启动多个相同任务处理相同的数据,并让这些任务竞争以缩短数据处理时间。显然,这种方法需要占用更多的计算资源。在集群资源紧缺的情况下,应合理使用该机制,争取在多用少量资源的情况下,减少作业的计算时间。
所以是否启用推测执行,如果能根据资源情况来决定,如果在资源本身就不够的情况下,还要跑推测执行的任务,这样会导致后续启动的任务无法获取到资源,以导致无法执行。mapreduce的MapTask和ReudceTask的推测执行机制时默认开启的。
https://blog.csdn.net/qianshangding0708/article/details/47615167
40. 什么样的计算不能用 mr 来提速?
1)数据量很小,计算量很大的程序。
2)繁杂的小文件。
3)索引是更好的存取机制的时候。
4)事务处理。
5)只有一台机器的时候。
6)不擅长 DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后, 每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
41. Hadoop所支持的几种压缩格式
(1)Gzip压缩
优点:压缩率比较高,而且压缩/解压速度也比较快;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样,使用压缩格式后,压缩之后原来的程序不需要做任何修改;使用hadoop本地库运行;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。
应用场景:当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑用gzip压缩格式。譬如说一天或者一个小时的日志压缩成一个gzip文件,运行mapreduce程序的时候通过多个gzip文件达到并发。hive程序,streaming程序,和java写的mapreduce程序完全和文本处理一样,压缩之后原来的程序不需要做任何修改。
(2)lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率,比gzip要低一些;支持split,是hadoop中最流行的压缩格式;使用hadoop本地库运行;可以在linux系统下安装lzop命令,使用方便。
缺点:压缩率比gzip要低一些;hadoop本身不支持,需要安装;在应用中对lzo格式的文件需要做一些特殊处理(为了支持split需要建索引,还需要指定inputformat为lzo格式)。
应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越越明显。
(3)Snappy压缩
优点:高速压缩速度和合理的压缩率,压缩率比gzip要低;使用hadoop本地库运行。压缩之后原来的程序不需要做任何修改
缺点:不支持split;压缩率比gzip要低;hadoop本身不支持,需要安装;linux系统下没有对应的命令。
应用场景:当mapreduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式;或者作为一个mapreduce作业的输出和另外一个mapreduce作业的输入。
(4)Bzip2压缩
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持使用hadoop本地库运行;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
应用场景:适合对速度要求不高,但需要较高的压缩率的时候,可以作为mapreduce作业的输出格式;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用程序(即应用程序不需要修改)的情况。
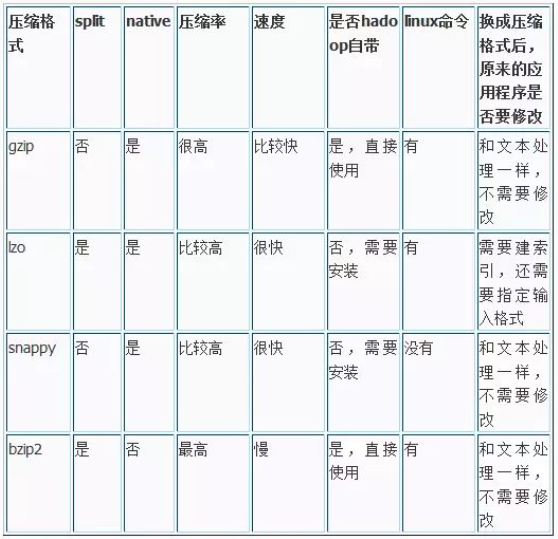
最后用一张图比较上述4种压缩格式的特征(优缺点):只看压缩格式、split、压缩率、速度、是否hadoop自带是否需要修改
42. Hadoop中的压缩位置
压缩可以在 MapReduce 作用的任意阶段启用。

输入端建:
- 数据量小于块大小用Gzip、Snappy
- 数量量非常大建议用LZO
Mapper输出:
- 建议用LZO、Snappy
Reduce输出:
- 一般归档用Bzip2
43. Hadoop 的缓存机制(Distributedcache)
分布式缓存一个最重要的应用就是在进行 join 操作的时候,如果一个表很大,另一个表很小,我们就可以将这个小表进行广播处理,即每个计算节点上都有一份,然后进行 map 端的连接操作,经过我的实验验证,这种情况下处理效率大大高于一般的 reduce 端 join,因为在 Reduce 端处理过多的表,非常容易产生数据倾斜。
首先,将缓存的文件(小表)上传到HDFS中(或者拷贝到本地),在Drive中通过job.addCacheFile方法告诉DistributedCache 在 HDFS (或本地)中的位置。在Map端通过setup方法中通过context.getCacheFiles()和context.getConfiguration()获取缓存文件,然后与大表中的每一条记录进行Join,具体是通过HashMap实现的。
具体实现请看:https://wxler.github.io/2021/03/31/214801/#63-map-join
44. 如何使用 mapReduce 实现两个表的 join?
1)reduce join : 在 map 阶段,map 函数同时读取两个文件 File1 和 File2,为了区分两种来源的 key/value 数据对,对每条数据打一个标签(tag),比如:tag=0 表示来自文件 File1,tag=2 表示来自文件 File2。 在 Reduce 端以连接字段作为 key 的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在 Map 阶段已经打标志)分开,最后进行合并就 ok 了。
2)map join : Map side join 是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们就可以采用 DistributedCache的方法,具体看上一题:Hadoop 的缓存机制(Distributedcache)
45. MapReduce 跑的慢的原因
MapReduce 程序效率的瓶颈在于两点:
1)计算机性能
CPU、内存、磁盘、网络,一般集群的最主要瓶颈是磁盘IO
2)I/O 操作优化
(1)数据倾斜。比如一个任务数据很多,而其它的任务数据很少(一般在Reducer端发生)例如 相同的key很多,空值很多
(2)Map 运行时间太长,导致 Reduce 等待过久
(3)map和reduce数设置不合理
(4)小文件过多
(5)spill(溢写)次数过多
(6)merge次数过多等
46. MapReduce 优化方法
主要看下面的
(1)Map和Shuffle
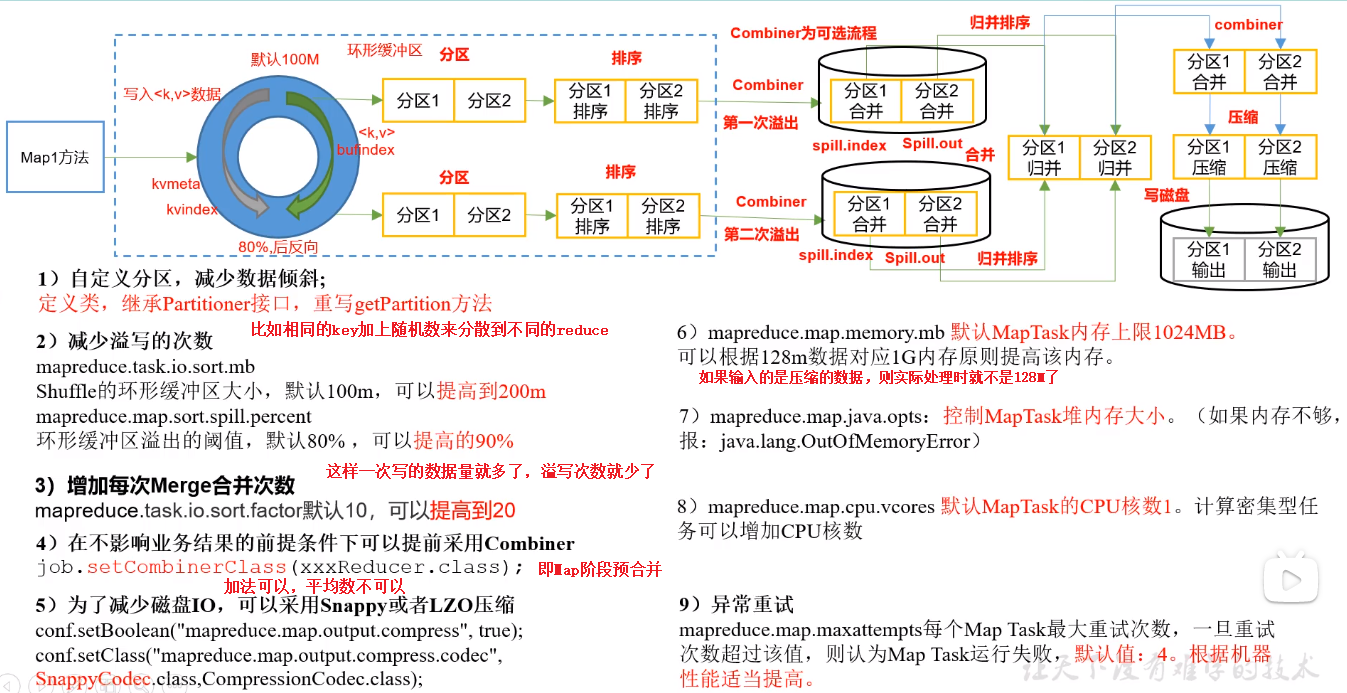
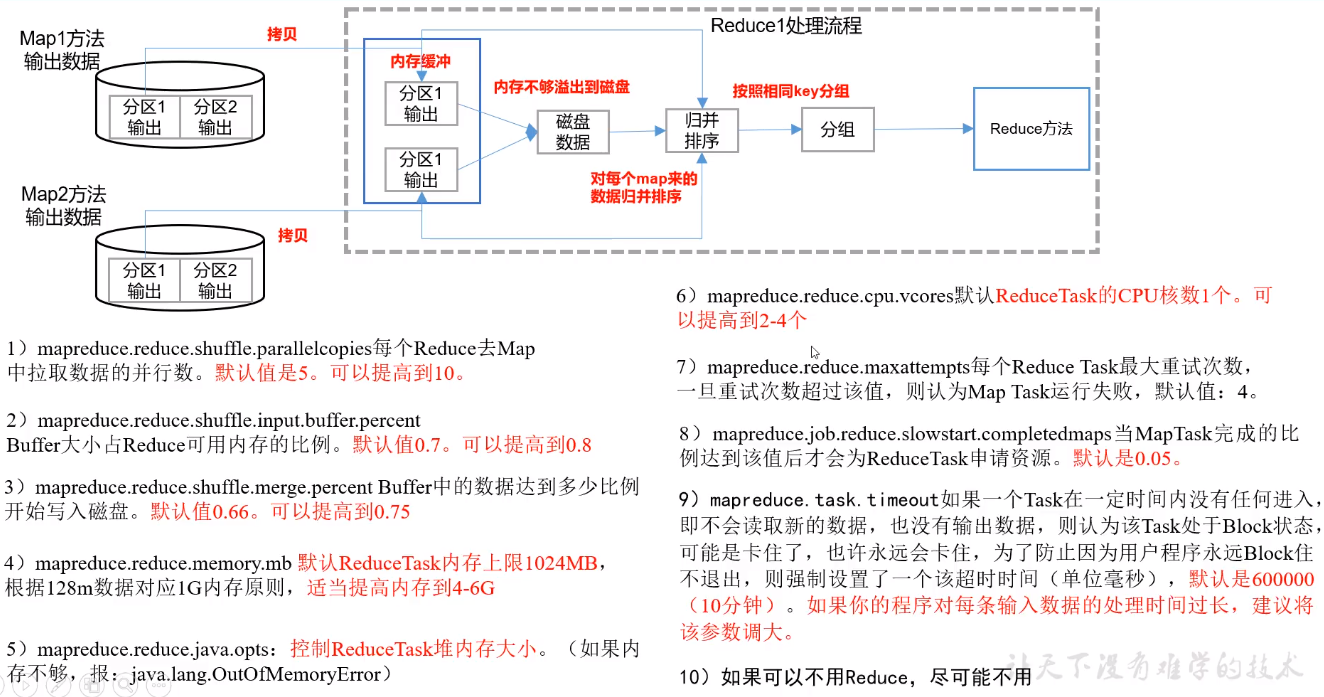
(2)Reduce
1)数据输入
(1)合并小文件:在执行mr任务前将小文件进行合并,大量的小文件会产生大量的map任务,增大map任务装载次数,而任务的装载比较耗时,从而导致mr运行较慢。
(2)采用ConbinFileInputFormat来作为输入,解决输入端大量小文件场景。
2)map阶段
(1)减少spill次数:通过调整io.sort.mb及sort.spill.percent参数值,增大触发spill的内存上限,减少spill次数,从而减少磁盘 IO。
(2)减少merge次数:通过调整io.sort.factor参数(默认是10),增大merge的文件数目,减少merge的次数,从而缩短mr处理时间。
(3)在 map 之后先进行combine处理,减少I/O。
(4) 在 map 之后先进行压缩处理,减小传输量。
3)reduce阶段
(1)合理设置map和reduce数:两个都不能设置太少,也不能设置太多。太少,并行能力较弱,会导致task等待,延长处理时间;太多,可能会导致任务启动的时间大于任务本身处理的时间,会得不偿失,并且会造成很多资源的浪费,比如1M的文件开启10个MapTask就没必要,而1G文件开启10个MapTask就很有必要了。
(2)设置map、reduce共存:调整slowstart.completedmaps参数(默认MapTask完成比例是0.05),使map运行到一定程度后,reduce也开始运行,减少reduce的等待时间。
(3)规避使用reduce join,因为在 Reduce 端处理过多的表,非常容易产生数据倾斜,最好使用map join
(4)合理设置reduce端的buffer,默认情况下,数据达到一个阈值的时候,buffer中的数据就会写入磁盘,然后reduce会从磁盘中获得所有的数据。也就是说,buffer和reduce是没有直接关联的,中间多个一个写磁盘->读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少IO开销:mapred.job.reduce.input.buffer.percent,默认为0.0。当值大于0的时候,会保留指定比例的内存读buffer中的数据直接拿给reduce使用。这样一来,设置buffer需要内存,读取数据需要内存,reduce计算也要内存,所以要根据作业的运行情况进行调整。
4)IO传输
(1)采用数据压缩的方式,减少网络IO的的时间。安装Snappy和LZOP压缩编码器。
(2)使用SequenceFile二进制文件,具体看48题
5)数据倾斜问题
(1)数据倾斜现象
数据频率倾斜――某一个区域的数据量要远远大于其他区域。
数据大小倾斜――部分记录的大小远远大于平均值。
(2)解决方法
看下一题:MapReduce 数据倾斜问题
47. MapReduce 数据倾斜问题
MapReduce 参考:https://mp.weixin.qq.com/s/VSHpTUMEvfPCa3E-fmaW7Q
Hive参考:https://mp.weixin.qq.com/s?__biz=Mzg2MzU2MDYzOA==&mid=2247485154&idx=1&sn=cd7129544497c1a621e49dbc1d7ed5c3&scene=21#wechat_redirect
MapReduce和Spark中的数据倾斜解决方案原理都是类似的,以下讨论Hive使用MapReduce引擎引发的数据倾斜,Spark数据倾斜也可以此为参照。
(1)空值引发的数据倾斜
实际业务中有些大量的null值或者一些无意义的数据参与到计算作业中,表中有大量的null值,如果表之间进行join操作,这样所有的null值都会被分配到一个reduce中,必然产生数据倾斜。
解决方案:
方法一:异常数据时,空KEY过滤
有时 join 超时是因为某些 key 对应的数据太多,而相同 key 对应的数据都会发送到相同的 reducer 上,从而导致内存不够。此时我们应该仔细分析这些异常的 key,很多情况下,这些 key 对应的数据是异常数据,我们需要在 SQL 语句中进行过滤。例如 key 对应的字段为空,
insert overwrite table jointable select n.* from (select
* from nullidtable where id is not null) n left join bigtable o on n.id =
o.id;
方法二:非异常数据时,空key转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上。由于null 值关联不上,处理后并不影响最终结果。
set mapreduce.job.reduces = 5;
insert overwrite table jointable
select n.* from nullidtable n full join bigtable o on
nvl(n.id,rand()) = o.id;
这里一定要注意,产生的随机数不要和原来的id有重复.
nvl(value,default_value):判断value是否为null,如果为null则放置default_value
(2)表连接时引发的数据倾斜
排除空值后,如果表连接的键存在倾斜,那么在 Reduce阶段必然会引起数据倾斜。
解决方案:
通常做法是将倾斜的数据存到分布式缓存中,分发到各个Map任务所在节点。在Map阶段完成join操作,即MapJoin,从而减少了Reduce数据倾斜。
在Hive 0.11版本之前,如果想在Map阶段完成join操作,必须使用MAPJOIN来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小。
如将a表放到Map端内存中执行,在Hive 0.11版本之前需要这样写:
select /* +mapjoin(a) */ a.id , a.name, b.age
from a join b
on a.id = b.id;
如果想将多个表放到Map端内存中,只需在mapjoin()中写多个表名称即可,用逗号分隔,如将a表和c表放到Map端内存中,则 /* +mapjoin(a,c) */ 。
在Hive 0.11版本及之后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin,可以通过以下两个属性来设置该优化的触发时机:
hive.auto.convert.join=true 默认值为true,自动开启MAPJOIN优化。
hive.mapjoin.smalltable.filesize=2500000 默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中。
注意:使用默认启动该优化的方式如果出现莫名其妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化:
hive.auto.convert.join=false(关闭自动MAPJOIN转换操作)hive.ignore.mapjoin.hint=false(不忽略MAPJOIN标记)
再提一句:将表放到Map端内存时,如果节点的内存很大,但还是出现内存溢出的情况,我们可以通过这个参数 mapreduce.map.memory.mb 调节Map端内存的大小。
(3)Group By
如果group by 维度过小, Map 阶段同一 Key 有大量的数据分发给一个 reduce,很容易发生倾斜了。
两个参数:
-
hive.map.aggr=true:在map中会做部分聚集操作,效率更高但需要更多的内存。 -
hive.groupby.skewindata=true:数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
由上面可以看出起到至关重要的作用的其实是第二个参数的设置,它使计算变成了两个mapreduce,先在第一个中在 shuffle 过程 partition 时随机给 key 打标记,使每个key 随机均匀分布到各个 reduce 上计算,但是这样只能完成部分计算,因为相同key没有分配到相同reduce上,所以需要第二次的mapreduce,这次就回归正常 shuffle,但是数据分布不均匀的问题在第一次mapreduce已经有了很大的改善,因此基本解决数据倾斜。
当然,也可以自己通过mapreduce程序来实现,即在 map 阶段将造成倾斜的key 先分成多组,例如 aaa 这个 key,map 时随机在 aaa 后面加上 1,2,3,4 这四个数字之一,把 key 先分成四组,先进行一次运算,之后再恢复 key 进行最终运算。
(4) Count(Distinct) 去重统计
数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成,一般 COUNT DISTINCT 使用先 GROUP BY 再 COUNT 的方式替换,但是需要注意 group by 造成的数据倾斜问题
(5)不可拆分大文件引发的数据倾斜
当集群的数据量增长到一定规模,有些数据需要归档或者转储,这时候往往会对数据进行压缩;当对文件使用GZIP压缩等不支持文件分割操作的压缩方式,在日后有作业涉及读取压缩后的文件时,该压缩文件只会被一个任务所读取。如果该压缩文件很大,则处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,该Map任务会成为作业运行的瓶颈。这种情况也就是Map读取文件的数据倾斜。
解决方案:
这种数据倾斜问题没有什么好的解决方案,只能将使用GZIP压缩等不支持文件分割的文件转为bzip和zip等支持文件分割的压缩方式。或者加大MapTask内存的大小(默认为1G)
所以,我们在对文件进行压缩时,为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时候可以采用bzip2和Zip等支持文件分割的压缩算法。
48. Hadoop 小文件优化方法
Hadoop 小文件弊端
HDFS 上每个文件都要在 NameNode 上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode 的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行 MR 计算时,会生成过多切片,需要启动过多的 MapTask。每个MapTask 处理的数据量小,导致 MapT ask 的处理时间比启动时间还小,白白消耗资源。
Hadoop 小文件解决方案
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传 HDFS(数据源头)
(2)Hadoop Archive(存储方向)
通过HDFS的har归档文件进行归档,它将HDFS中一个个小文件归档成一个文件,对 NameNode 是一个整体,但是其内部实际上还是许多个小文件,减少了 NameNode 的内存。 具体看49题
(3)CombineTextInputFormat(计算方向)
CombineTextInputFormat 用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片,以减少切片的数量。
(4)开启 uber 模式,实现 JVM 重用(计算方向)
默认情况下,每个 Task 任务都需要启动一个 JVM 来运行,如果 Task 任务计算的数据量很小,我们可以让同一个 Job 的多个 Task 运行在一个 JVM 中,不必为每个 Task 都开启一个 JVM。
(5)使用Sequence file
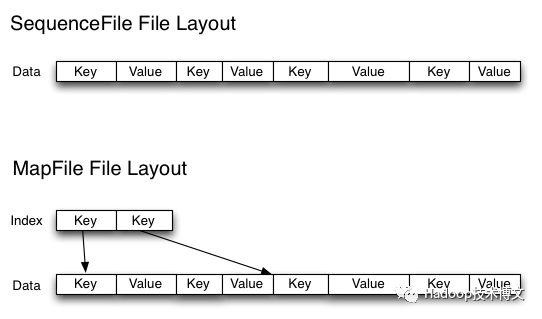
sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。 和 HAR 不同的是,这种方式还支持压缩。该方案对于小文件的存取都比较自由,不限制文件的多少,但是 SequenceFile 文件不能追加写入,适用于一次性写入大量小文件的操作。
49. HDFS小文件归档
(1) HDFS 存储小文件弊端
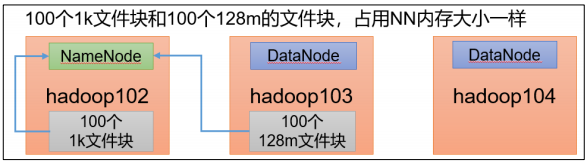
每个文件均按块存储,每个块的元数据存储在 NameNode 的内存中,因此 HDFS 存储小文件会非常低效。因为大量的小文件会耗尽 NameNode 中的大部分内存。这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode 的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行 MR 计算时,会生成过多切片,需要启动过多的 MapTask。每个MapTask 处理的数据量小,导致 MapTask 的处理时间比启动时间还小,白白消耗资源。
(2)解决存储小文件办法之一
通过HDFS的har归档文件进行归档,它将HDFS中一个个小文件归档成一个文件,对 NameNode 是一个整体,但是其内部实际上还是许多个小文件,减少了 NameNode 的内存。
例如,100个1K的文件归档成一个文件,在NameNode中只占150个字节,减少了150倍。
50. SequenceFile和MapFile的理解
参考:https://mp.weixin.qq.com/s/HjYPR0emkm319Psw7X9jnw
Hadoop 的 HDFS 和 MapReduce 子框架主要是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源(每一个小文件占用一个 Block,每一个 block 的元数据都存储在 namenode 的内存里)。解决办法通常是选择一个容器,将这些小文件组织起来统一存储。HDFS 提供了两种类型的容器,分别是 SequenceFile 和 MapFile。
关于SequenceFile
(1)介绍
SequenceFile 是 Hadoop 的一个重要数据文件类型,它提供key-value的存储,但与传统key-value存储(比如hash表)不同的是,它是appendonly的,于是你不能对已存在的key进行写操作。
(2)解决问题
该文件格式通常被用来解决hadoop中的小文件问题,相当于一个容器,把这些小文件组织起来统一存储。
(3)压缩格式
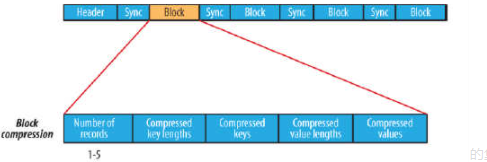
SeqeunceFile支持两种格式的数据压缩,分别是:record compression 和 block compression。
record compression是对每条记录的value进行压缩
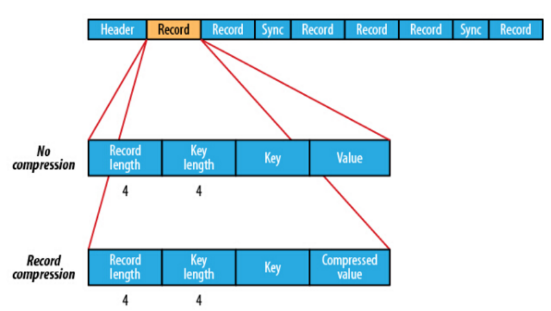
block compression是将一连串的record组织到一起,统一压缩成一个block
(4)存储结构
在存储结构上,SequenceFile 主要由一个 Header 后跟多条 Record 组成。
Header 主要包含了 Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条 Record 以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key 的长度、Key 值和 Value 值,并且 Value 值的结构取决于该记录是否被压缩
(5)操作方式
SequenceFile 可通过如下 API 来完成新记录的添加操作:
fileWriter.append(key,value)
可以看到,每条记录以键值对的方式进行组织,但前提是 Key 和 Value 需具备序列化和反序列化的功能
关于MapFile
(1)介绍及组成
MapFile 是排序后的 SequenceFile,通过观察其目录结构可以看到 MapFile 由两部分组成,分别是 data 和 index。
index 作为文件的数据索引,主要记录了每个 Record 的 key 值,以及该 Record 在文件中的偏移位置。在 MapFile 被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定 Record 所在文件位置,因此,相对SequenceFile 而言,MapFile 的检索效率是高效的,缺点是会消耗一部分内存来存储 index 数据。
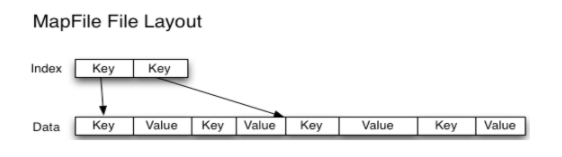
与SequenceFile不同的是
MapFile 的 KeyClass 一定要实现 WritableComparable 接口,即 Key 值是可比较的。
SequenceFile和MapFile的局限性
1.文件不支持复写操作,不能向已存在的 SequenceFile(MapFile)追加存储记录
2.当 write 流不关闭的时候,没有办法构造 read 流。也就是在执行文件写操作的时候,该文件是不可读取的
51. 请简单介绍一下Yarn
Yarn 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
52. Yarn的组成架构有哪些
参考:https://github.com/wangzhiwubigdata/God-Of-BigData/blob/master/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%A1%86%E6%9E%B6%E5%AD%A6%E4%B9%A0/Hadoop-YARN.md
YARN 主要由 ResourceManager、NodeManager、ApplicationMaster 和 Container 等组件构成。
ResourceManager(RM)是整个集群资源(内存、CPU等)的老大,它是整个集群资源的主要协调者和管理者,具体如下:
- 处理客户端请求
- 监控NodeManager运行情况,如果某一个节点资源紧张,可以把新的任务分配给别其它闲置的结点
- 启动或监控ApplicationMaster的任务运行情况,如果某个任务挂了,则可以把任务分配给别的结点执行。
- 管理整个集群资源的分配与调度
NodeManager(NM)是单个节点服务器资源老大,主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康,具体如下:
- 启动时向
ResourceManager注册并定时发送心跳消息,等待ResourceManager的指令 - 维护
Container的生命周期,监控Container的资源使用情况; - 管理任务运行时的相关依赖,根据
ApplicationMaster的需要,在启动Container之前将需要的程序及其依赖拷贝到本地。

ApplicationMaster(AM)是单个任务运行的老大。在用户提交一个应用程序时,YARN 会通过ResourceManager 启动一个轻量级的进程 ApplicationMaster,通过ApplicationMaster来管理整个任务的运行。ApplicationMaster 作业具体如下:
- 根据应用的运行状态来决定动态计算资源需求;
- 向
ResourceManager申请资源,监控申请的资源的使用情况; - 跟踪任务状态和进度,报告资源的使用情况和应用的进度信息;
- 负责任务的容错。
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当 ApplicationMaster(AM)向 ResourceManager 申请资源时,RM 为 AM 返回的资源是用 Container 表示的。YARN 会为每个任务分配一个 Container,该任务只能使用该 Container 中描述的资源。ApplicationMaster 可在 Container 内运行任何类型的任务。例如,MapReduce ApplicationMaster 请求一个容器来启动 map 或 reduce 任务,而 Giraph ApplicationMaster 请求一个容器来运行 Giraph 任务。
53. YARN工作原理简述
参考:https://github.com/wangzhiwubigdata/God-Of-BigData/blob/master/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%A1%86%E6%9E%B6%E5%AD%A6%E4%B9%A0/Hadoop-YARN.md
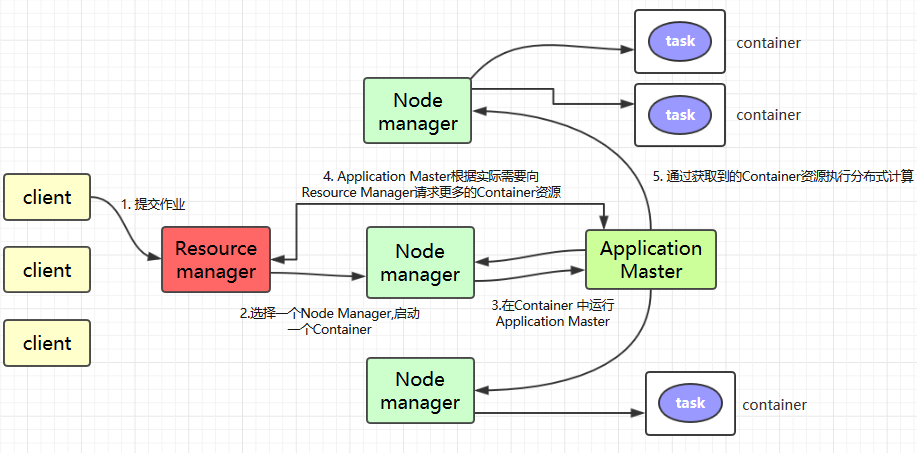
Client提交作业到 YARN 上;Resource Manager选择一个NodeManager,启动一个Container并运行Application Master实例;Application Master根据实际需要向Resource Manager请求更多的Container资源(如果作业很小, 应用管理器会选择在其自己的 JVM 中运行任务);Application Master通过获取到的Container资源执行分布式计算。
54. YARN工作原理详述(源码角度)
参考: https://github.com/wangzhiwubigdata/God-Of-BigData/blob/master/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%A1%86%E6%9E%B6%E5%AD%A6%E4%B9%A0/Hadoop-YARN.md
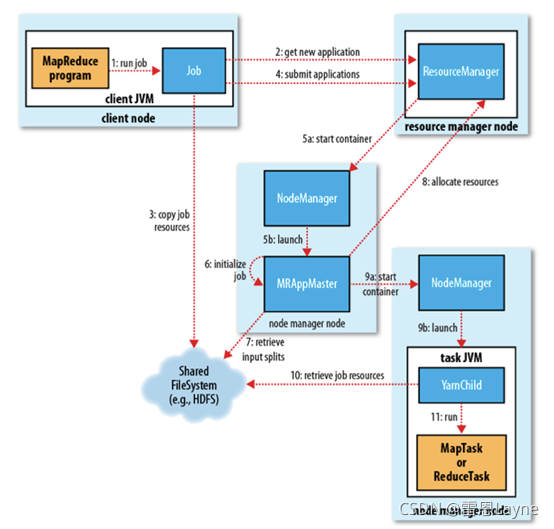
一、作业提交
client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业 (第 1 步) 。新的作业 ID(应用 ID) 由ResourceManager分配 (第 2 步)。作业的 client 核实作业的输出, 计算输入的 split, 将作业的资源 (包括 Jar 包,切片规划Job.split和Job相关参数文件Job.xml) 拷贝给 HDFS(第 3 步)。 最后, 通过调用ResourceManager的 submitApplication() 来提交作业 (第 4 步)。
二、作业初始化
当ResourceManager收到 client的submitApplciation() 的请求时, 就将该请求发给调度器 (scheduler), 调度器分配 container, 然后ResourceManager在该 container 内启动ApplicationMaster进程, 由NodeManager监控 (第 5 步)。
调度器:容量调度器和公平调度器
MapReduce 作业的ApplicationMaster是一个主类为 MRAppMaster 的 Java 应用,其通过创造一些 bookkeeping 对象来监控作业的进度, 得到任务的进度和完成报告 (第 6 步)。然后其通过HDFS得到由客户端计算好的Inputsplit(其实就是切片规划)(第 7 步),然后为每个Inputsplit创建一个 map 任务, 根据mapreduce.job.reduces 创建 reduce 任务对象。
三、任务分配
如果作业很小, ApplicationMaster会选择在其自己的 JVM (即在自己的Container)中运行任务。
如果不是小作业, 那么ApplicationMaster向ResourceManager请求 新的container 来运行所有的 map 和 reduce 任务 (第 8 步)。
这些请求是通过心跳来传输的, 包括每个 map 任务的数据位置,比如存放Inputsplit 的主机名和机架 (rack),调度器(scheduler)利用这些信息来调度任务,尽量将任务分配给存储数据的节点, 或者分配给和存放Inputsplit 的节点相同机架的节点。
四、任务运行
当一个任务由ResourceManager的调度器分配给一个 container 后,ApplicationMaster通过联系NodeManager来启动 container(第 9 步)。任务由一个主类为 YarnChild 的 Java 应用执行, 在运行任务之前首先本地化任务需要的资源,比如作业配置Job.xml,JAR 文件, 以及分布式缓存的所有文件 (第 10 步)。 最后, 运行 map 或 reduce 任务 (第 11 步)。
YarnChild 运行在一个专用的 JVM 中, 但是 YARN 不支持 JVM 重用。
五、进度和状态更新
YARN 中的任务将其进度和状态 (包括 counter) 返回给ApplicationMaster, 客户端每秒 (通 mapreduce.client.progressmonitor.pollinterval 设置) 向ApplicationMaster请求进度更新, 展示给用户。
六、作业完成
除了向ApplicationMaster请求作业进度外, 客户端每 5 分钟都会通过调用 waitForCompletion() 来检查作业是否完成,时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业完成之后, ApplicationMaster和 container 会清理工作状态, OutputCommiter 的作业清理方法也会被调用。作业的信息会被作业历史服务器存储以备之后用户核查。
55. Yarn 调度器和调度算法
当资源管理器收到 client的submitApplciation() 的请求时, 就将该请求发给调度器 (scheduler), 调度器分配 container, 然后资源管理器在该 container 内启动ApplicationMaster进程, 由NodeManager监控。
目前,Hadoop 作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。Apache Hadoop3.1.3 默认的资源调度器是 Capacity Scheduler。
Apache默认调度器:容量
CDH默认调度器:公平调度器
(1)FIFO 调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。

优点:简单易懂;
缺点:不支持多队列,生产环境很少使用;
(2)容量调度器(Capacity Scheduler)

1、支持多队列:每个队列可配置一定的资源量,每个队列采用FIFO调度策略。
2、容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
3、灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
4、多租户:
支持多用户共享集群和多应用程序同时运行。为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
容量调度器资源分配算法:优先选择资源占用率最低的队列进行分配,队列内部的作业按照FIFO方式来调度

(3)公平调度器Fair Scheduler
? 同计算能力调度器类似,支持多队列多用户,具有容量保证,每个队列中的资源量可以配置,默认情况下,同一队列中的作业公平共享队列中所有资源。
与容量调度器不同点
① 核心调度策略不同
- 容量调度器:优先选择资源利用率低的队列
- 公平调度器:优先选择对资源的缺额比例大的
② 每个队列可以单独设置资源分配方式
- 容量调度器:FIFO、 DRF
- 公平调度器:FIFO、FAIR、DRF
公平调度器――缺额

- 公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫“缺额”
- 为保证公平,调度器会优先为缺额大的作业分配资源
公平调度器队列资源分配方式
(1)FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
(2)Fair策略
Fair 策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
具体资源分配流程和容量调度器一致:
- 选择队列
- 选择作业
- 选择容器
以上三步,每一步都是按照公平策略分配资源
(3)DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:
假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU,100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
56. 请列出正常工作的Hadoop集群中Hadoop都分别需要启动哪些进程,它们的作用分别是什么?
1)NameNode:NameNode负责管理整个文件系统的元数据,所有的文件路径和数据块的存储信息都保存在NameNode(其实就是文件系统中所有目录和文件inode的序列化形式)。除此之外,NameNode处理客户端读写请求,分发给DataNode去执行。
2)SecondaryNameNode:SecondaryNameNode定期触发CheckPoint,代表NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。同时在合并期间,NameNode也可以对外提供写操作。
3)DataNode:存储实际的数据块,执行真正的读写操作。
4)ResourceManager(RM)是整个集群资源(内存、CPU等)的老大,它是整个集群资源的主要协调者和管理者,具体如下:
- 处理客户端请求
- 监控NodeManager运行情况,如果某一个节点资源紧张,可以把新的任务分配给别其它闲置的结点
- 启动或监控ApplicationMaster的任务运行情况,如果某个任务挂了,则可以把任务分配给别的结点执行。
- 管理整个集群资源的分配与调度
- NodeManager(NM)是单个节点服务器资源老大,主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康,具体如下:
- 启动时向
ResourceManager注册并定时发送心跳消息,等待ResourceManager的指令 - 维护
Container的生命周期,监控Container的资源使用情况; - 管理任务运行时的相关依赖,根据
ApplicationMaster的需要,在启动Container之前将需要的程序及其依赖拷贝到本地。
6)主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
7)JournalNode:高可用情况下存放namenode的editlog文件。
57. 请详细介绍一下Hadoop高可用的原理
原理(写的很好):https://mp.weixin.qq.com/s/DHHDCYycWIkBUqiol1Ntgg
部署参加:https://github.com/wangzhiwubigdata/God-Of-BigData/blob/master/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%A1%86%E6%9E%B6%E5%AD%A6%E4%B9%A0/installation/%E5%9F%BA%E4%BA%8EZookeeper%E6%90%AD%E5%BB%BAHadoop%E9%AB%98%E5%8F%AF%E7%94%A8%E9%9B%86%E7%BE%A4.md
Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解:
1. 高可用概述
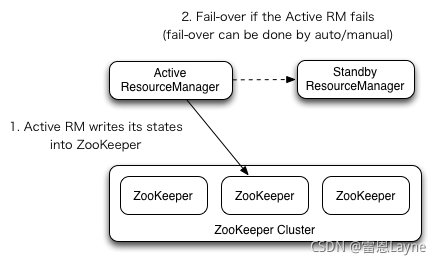
在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode 的单点问题尤为严重。因为 NameNode 保存了整个 HDFS 的元数据信息,一旦 NameNode 挂掉,整个 HDFS 就无法访问,同时 Hadoop 生态系统中依赖于 HDFS 的各个组件,包括 MapReduce、Hive、Pig 以及 HBase 等也都无法正常工作,并且重新启动 NameNode 和进行数据恢复的过程也会比较耗时。这些问题在给 Hadoop 的使用者带来困扰的同时,也极大地限制了 Hadoop 的使用场景。
所幸的是,在 Hadoop2.0 中,HDFS NameNode 和 YARN ResourceManger(JobTracker 在 2.0 中已经被整合到 YARN ResourceManger 之中) 的单点问题都得到了解决,经过多个版本的迭代和发展,目前已经能用于生产环境。HDFS NameNode 和 YARN ResourceManger 的高可用 (High Availability,HA) 方案基本类似,两者也复用了部分代码,但是由于 HDFS NameNode 对于数据存储和数据一致性的要求比 YARN ResourceManger 高得多,所以 HDFS NameNode 的高可用实现更为复杂一些,本文从内部实现的角度对 HDFS NameNode 的高可用机制进行详细的分析。
2. 高可用整体架构

HDFS 高可用架构主要由以下组件所构成:
- Active NameNode 和 Standby NameNode:两台 NameNode 形成互备,一台处于 Active 状态,为主 NameNode,另外一台处于 Standby 状态,为备 NameNode,只有主 NameNode 才能对外提供读写服务。
- 主备切换控制器 ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。
- Zookeeper 集群:为主备切换控制器提供主备选举支持。
- 共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。主 NameNode 和 NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
- DataNode 节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
3. NameNode主备切换
NameNode 主备切换主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 这 3 个组件来协同实现。
ZKFailoverController 作为 NameNode 机器上一个独立的进程启动 (在 hdfs 启动脚本之中的进程名为 zkfc),启动的时候会创建 HealthMonitor 和 ActiveStandbyElector 这两个主要的内部组件,并向它们注册相应的回调方法。
HealthMonitor 主要负责检测 NameNode 的健康状态,如果检测到 NameNode 的状态发生变化,会回调 ZKFailoverController 的相应方法进行自动的主备选举。
ActiveStandbyElector 主要负责完成自动的主备选举,内部封装了 Zookeeper 的处理逻辑,一旦 Zookeeper 主备选举完成,会回调 ZKFailoverController 的相应方法来进行 NameNode 的主备状态切换。
NameNode 实现主备切换的流程下图所示:
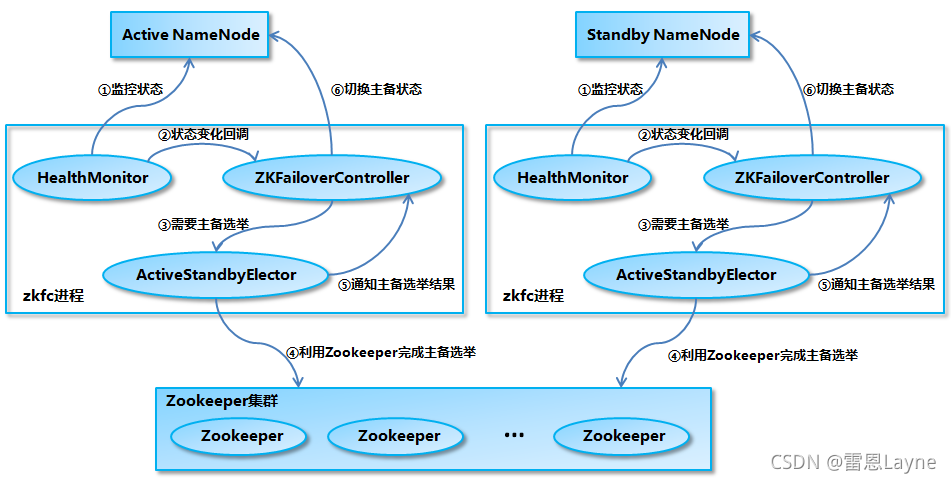
-
HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
RMI(Remote Method Invocation)远程方法调用 ,RPC(Remote Procedure Call Protocol)远程过程调用协议
-
HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
-
如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。
-
ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
-
ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 注册的相应方法来通知当前的NameNode 成为主 NameNode 或备 NameNode。
-
ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
4. Zookeeper主备选举机制
Namenode(包括 YARN ResourceManager) 的主备选举是通过 ActiveStandbyElector 来完成的,ActiveStandbyElector 主要是利用了 Zookeeper 的写一致性和临时节点机制,具体的主备选举实现如下:
(1)创建锁节点
如果 HealthMonitor 检测到对应的 NameNode 的状态正常,那么表示这个 NameNode 有资格参加 Zookeeper 的主备选举。如果目前还没有进行过主备选举的话,那么相应的 ActiveStandbyElector 就会发起一次主备选举,尝试在 Zookeeper 上创建一个路径为/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 的临时节点 。${dfs.nameservices} 为 Hadoop 的配置参数 dfs.nameservices 的值。
Zookeeper 的写一致性会保证最终只会有一个 ActiveStandbyElector 创建成功,那么创建成功的 ActiveStandbyElector 对应的 NameNode 就会成为主 NameNode,此时ActiveStandbyElector 会回调 ZKFailoverController 注册的方法进一步将对应的 NameNode 切换为 Active 状态。而创建失败的 ActiveStandbyElector 对应的 NameNode 成为备 NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Standby 状态。
(2)注册 Watcher 监听
不管创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点是否成功,ActiveStandbyElector 随后都会向 Zookeeper 注册一个 Watcher 来监听这个节点的状态变化事件,ActiveStandbyElector 主要关注这个节点的 NodeDeleted 事件。
(3)自动触发主备选举
如果 Active NameNode 对应的 HealthMonitor 检测到 NameNode 的状态异常时, ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock,这样处于 Standby 状态的 NameNode 的 ActiveStandbyElector 注册的监听器就会收到这个节点的 NodeDeleted 事件。收到这个事件之后,会马上再次进入到创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock节点的流程,如果创建成功,这个本来处于 Standby 状态的 NameNode 就选举为主 NameNode 并随后开始切换为 Active 状态。
当然,如果是 Active 状态的 NameNode 所在的机器整个宕掉的话,那么根据 Zookeeper 的临时节点特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点会自动被删除,从而也会自动进行一次主备切换。
(4)防止脑裂
Zookeeper 在工程实践的过程中经常会发生的一个现象就是 Zookeeper 客户端“假死”,所谓的“假死”是指如果 Zookeeper 客户端机器负载过高或者正在进行 JVM Full GC,那么可能会导致 Zookeeper 客户端到 Zookeeper 服务端的心跳不能正常发出,一旦这个时间持续较长,超过了配置的 Zookeeper Session Timeout 参数的话,Zookeeper 服务端就会认为客户端的 session 已经过期从而将客户端的 Session 关闭。
“假死”有可能引起分布式系统常说的双主或脑裂 (brain-split) 现象。具体到本文所述的 NameNode,假设 NameNode1 当前为 Active 状态,NameNode2 当前为 Standby 状态。如果某一时刻 NameNode1 对应的 ZKFailoverController 进程发生了“假死”现象,那么 Zookeeper 服务端会认为 NameNode1 挂掉了,根据前面的主备切换逻辑,NameNode2 会替代 NameNode1 进入 Active 状态。但是此时 NameNode1 可能仍然处于 Active 状态正常运行,即使随后 NameNode1 对应的 ZKFailoverController 因为负载下降或者 Full GC 结束而恢复了正常,感知到自己和 Zookeeper 的 Session 已经关闭,但是由于网络的延迟以及 CPU 线程调度的不确定性,仍然有可能会在接下来的一段时间窗口内 NameNode1 认为自己还是处于 Active 状态。这样 NameNode1 和 NameNode2 都处于 Active 状态,都可以对外提供服务。这种情况对于 NameNode 这类对数据一致性要求非常高的系统来说是灾难性的,数据会发生错乱且无法恢复。Zookeeper 社区对这种问题的解决方法叫做 fencing,中文翻译为隔离,也就是想办法把旧的 Active NameNode 隔离起来,使它不能正常对外提供服务。
ActiveStandbyElector 为了实现 fencing,会在成功创建 Zookeeper 节点 hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 从而成为 Active NameNode 之后,创建另外一个路径为/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 的持久节点,这个节点里面保存了这个 Active NameNode 的地址信息。Active NameNode 的 ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候 (注意由于/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 是临时节点,也会随之删除),会一起删除节点/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb。但是如果 ActiveStandbyElector 在异常的状态下 Zookeeper Session 关闭 (比如前述的 Zookeeper 假死),那么由于/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 是持久节点,会一直保留下来。后面当另一个 NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行 fencing,进行fencing的过程如下:
如果 ActiveStandbyElector 选主成功之后,先不立即把对应的NameNode变为Active 状态,而是先判断上一个 Active NameNode 遗留下来的/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 节点是否存在,如果存在,就意味着上一个Active NameNode因为某些原因(负载过高或者正在 JVM Full GC)而退出 ,那么 ActiveStandbyElector 会首先回调 ZKFailoverController 注册的 fenceOldActive 方法,尝试对旧的 Active NameNode 进行 fencing,在进行 fencing 的时候,会执行以下的操作:
- 首先尝试调用这个旧 Active NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,看能不能把它转换为 Standby 状态。
- 如果 transitionToStandby 方法调用失败,那么就执行 Hadoop 配置文件之中预定义的隔离措施,Hadoop 目前主要提供两种隔离措施,通常会选择 sshfence:
- sshfence:通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死;
- shellfence:执行一个用户自定义的 shell 脚本来将对应的进程隔离;
只有在成功地执行完成 fencing 之后,选主成功的 ActiveStandbyElector 才会回调 ZKFailoverController 的 becomeActive 方法将对应的 NameNode 转换为 Active 状态,开始对外提供服务。
5. NameNode共享存储实现
过去几年中 Hadoop 社区涌现过很多的 NameNode 共享存储方案,比如 shared NAS+NFS、BookKeeper、BackupNode 和 QJM(Quorum Journal Manager) 等等。目前社区已经把由 Clouderea 公司实现的基于 QJM 的方案合并到 HDFS 的 trunk(主干) 之中并且作为默认的共享存储实现,本部分只针对基于 QJM 的共享存储方案的内部实现原理进行分析。
基于 QJM 的共享存储系统主要用于保存 EditLog,并不保存 FSImage 文件。FSImage 文件还是在 NameNode 的本地磁盘上。
QJM 共享存储采用多个称为 JournalNode 的节点组成的 JournalNode 集群来存储 EditLog。每个 JournalNode 保存同样的 EditLog 副本。每次 NameNode 写 EditLog 的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向 JournalNode 集群之中的每一个 JournalNode 发送写请求,只要大多数 (majority) 的 JournalNode 节点返回成功就认为向 JournalNode 集群写入 EditLog 成功。如果有 2N+1 台 JournalNode,那么根据大多数的原则,最多可以容忍有 N 台 JournalNode 节点挂掉。当Active NameNode 把 EditLog 提交到 JournalNode 集群后,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog,当 Active NameNode 宕机后, Standby NameNode 在确认元数据完全同步之后就可以对外提供服务。

6. YARN高可用
YARN ResourceManager 的高可用与 HDFS NameNode 的高可用类似,但是 ResourceManager 不像 NameNode ,没有那么多的元数据信息需要维护,所以它的状态信息可以直接写到 Zookeeper 上,并依赖 Zookeeper 来进行主备选举。