- ����֮ǰ�Ѿ�����α�ֲ�ʽ����,������ȫ�ֲ�ʽ����֮ǰ,��Ҫ����ɾ��master����hadoop��װ·���µ�tmp��logs�ļ����е��ļ�:
 - ��������core-site.xml��hdfs-site.xml,�Լ�mapred-site.xml��yarn-site.xml��
(1)���ȱ༭core-site.xml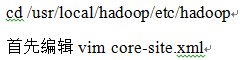 
(2)Ȼ��༭hdfs-site.xml

(3)�༭mapred-site.xml
 
(4)�༭yarn-site.xml
 - ��slaves�ļ�
�ļ�����(û��slave03�IJ�Ҫ���һ��):
slave01
slave02
slave03 - ѹ��hadoop��װ�ļ���,Ȼ��ַ���slave����:
 - ��slave�ڵ���root�˻���¼,�ڸ���slave�ڵ��ѹ:
 - ��master�ڵ��ʽ��namenode,ִֻ��һ��,�Ժ�����Hadoopʱ����Ҫ�ٴθ�ʽ����

ע��:�ظ���ʽ�������namenode��datanode��clusterID��һ��,���ִ������,��Ҫɾ�������ڵ�hadoop�µ�tmp�ļ��к�logs�ļ��е�����,Ȼ��,���¸�ʽ��namenode�� - ��ʽ����ɺ�,����Hadoop��Yarn��
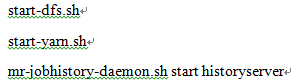 - ͨ��jps����鿴�����ڵ�Ľ���:
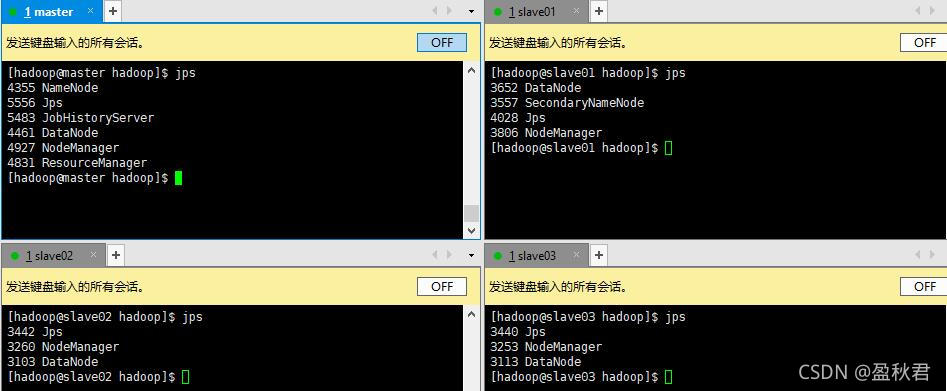
����и������û������,���Ե�������,����ͨ��hdfs --daemon start datanode�������ݽڵ㡣 - ��master�ڵ�ͨ��hdfs dfsadmin �Creport������Բ鿴��Ⱥ״̬,����,Live datanodes (4)������Ⱥ�����ɹ���
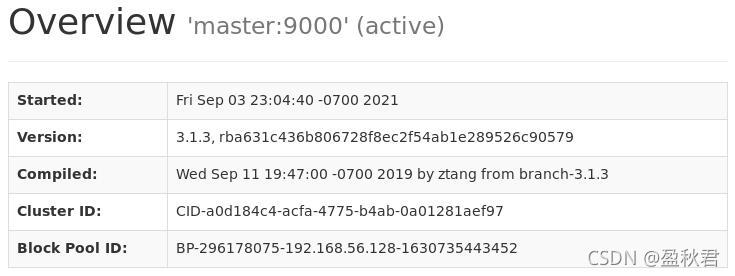
- ������ͨ��web����鿴��Ⱥ״̬,��linux���������http://master:9870/

 - ���,�ر�Hadoop��Ⱥ,��master�ڵ�ִ����������:
|