MapReduce
MapReduce是一种面向大规模数据处理的、分布式运算程序的编程框架。它通过将实际业务逻辑代码+自带默认组件的方式实现在Hadoop集群上的分布式计算。
MapReduce的优势
1. 易于编程
MapReduce框架将整个分布式的过程都进行了封装,用户只需要根据自己的实际业务,对简单的接口进行实现,就可以达到非常理想的目的。
2. 扩展性好
若计算资源不足时,可直接添加机器来提高计算力。
3. 容错率高
如果正在运行的节点发生了意外,可以把任务交给集群中另一个节点上运行,这个调度方法可直接由Hadoop内部完成,不需要人工干预。
MapReduce的劣势
1. 不擅长实时计算
MapReduce无法像 MySQL一样,在毫秒或者秒级内返回结果。
2. 不擅长流式计算
MapReduce无法处理在线产生的数据,只能处理离线数据。
3. 不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后,每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
资料来源:尚硅谷
MapReduce流程
MapReduce字如其名,其思想最主要的流程分为两大块,Map和Reduce。其中,map将数据分成几份并行计算,Reduce将map的结果统一。

但如果要将上述流程细分,则应该分成以下几步:
- InputFormat切片阶段:首先,客户端会将数据分成多个数据切片,并由ApplicationMaster分配给相同数量的MapTask,一个数据切片对应一个MapTask。
- Map阶段:每个MapTask通过InputFormat得到以<K, V>格式存在的数据切片数据,并将其作为输入运行用户根据具体的业务逻辑实现的map()接口方法。最后写入上下文context.write()交给Shuffle阶段。
在WordCount中,Mapper的输入<K, V>,K代表着该行文本数据的偏移量,V代表着该行数据;
Mapper的输出<K, V>由用户的具体业务逻辑决定,但是Mapper的输出<K, V>类型需要和Reducer的输入类型一致。
- Shuffle阶段:MapTask将Map阶段的输出逐步放到内存中的环形缓冲区,当环形缓冲区将满时(80%写入)通过分区、区内快速排序、写入磁盘的操作将缓冲区内的数据按照分区和key的顺序写入磁盘。再将多个落盘的文件根据分区进行合并,对相同的分区进行归并排序,生成不同的分区数据文件,由对应分区的Reducer请求拉取数据。每个Reducer只拉去对应自己分区的数据文件。
- Reducer阶段:ReduceTask从多个MapTask请求到对应的分区数据。一般来说,一个分区对应一个ReduceTask,也就意味着会得到与分区相同数量的输出结果,分区数量时常由用户具体业务决定,默认为1。Reducer将多个MapTask得到的分区数据再进行一次文件的合并,并使用归并排序,使得相同key的<K, V>数据能整合在一起。再将<K, V>数据输入到用户根据具体的业务逻辑实现的reducer()接口方法。最后写入上下文context.write()交给OutputFormat。
Reducer的输入<K, V>类型需要和Mapper的输出类型一致;
Reducer的输出<K, V>由用户的具体业务逻辑决定。
- OutputFormat输出阶段:Reducer输出的数据通过OutputFormat输出到指定输出路径。
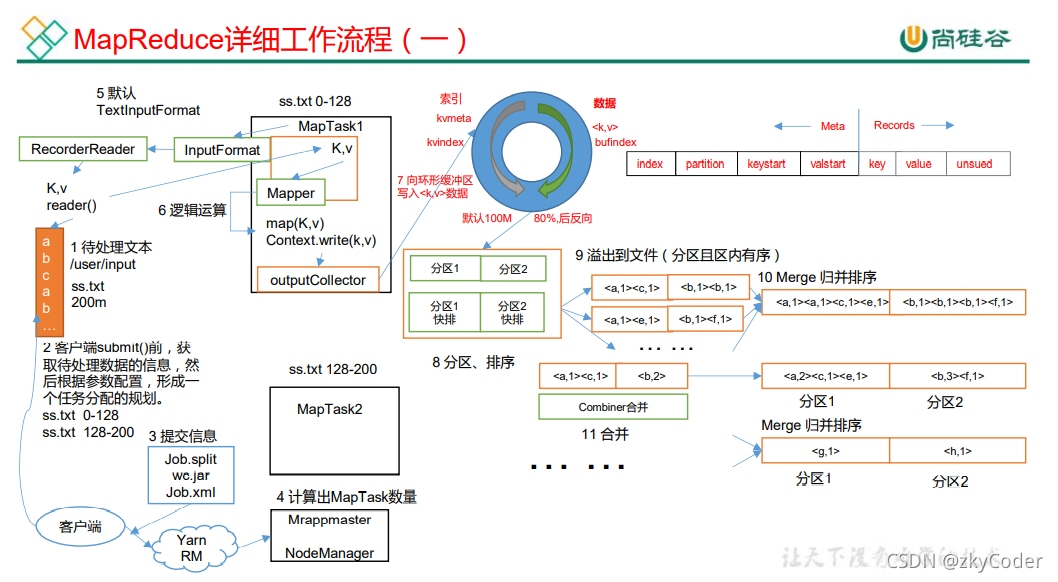
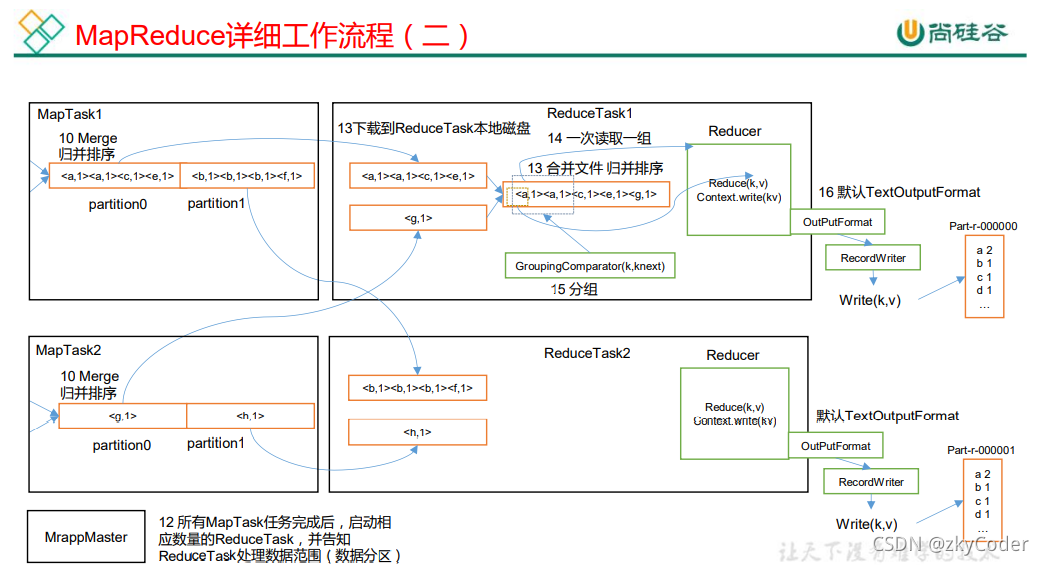
图片来源尚硅谷。