Redis 原理与实战
Java 从 0 到架构师目录:【Java从0到架构师】学习记录
关系型数据库:Oracel、MySQL、SqlServer,DB2
NoSql 数据库:NoSQL 数据库是为了解决大规模数据集合和多重数据种类带来的挑战
- key-value 存储数据库:Tokyo Cabinet / Tyrant、Redis、Voldemort、Oracle BDB
- 列存储数据库:Cassandra、HBase、Riak
500 万条数据就会对 MySQL 性能有影响,但对列式存储数据库几乎没有影响
- 文档性数据库::CouchDB、MongoDb、SequoiaDB(国内)
- 图形数据库:Neo4J
非关系型数据库的特点:
- 数据模型比较简单
- 需要灵活性更强的应用系统
- 对数据库性能要求较高
- 不需要高度的数据一致性
- 对于给定 key,比较容易映射复杂值的环境
Redis 基础
资料参考:
- Redis 在线入门:http://try.redis.io/
- Redis 中文资料站: http://www.redis.cn/
- Github:https://github.com/antirez/redis
- Redis 官网:https://redis.io/
- Redis 命令参考:http://redisdoc.com/
Redis 是一个简单的、高效的、分布式的,基于内存缓存工具,架设好服务器后,通过网络链接(类似数据库),提供 Key - Value 式缓存服务。
拓展类型:
- 水平拓展:在平行的基础上,增加主服务器或者从服务器
- 垂直拓展:直接在主服务器中增加内存或者加硬盘
高可用:
- 主从形式:只有一台机器是主节点,有多台机器是从节点
- 哨兵形式(Redis 2.x):主从模式下,有一台机器充当哨兵,监控其他机器的状态;当主节点挂了,哨兵会在从节点之间进行选举出性能较好的机器作为主节点;挂掉的主节点修复好后自动加进来变成从节点
- 集群模式(Redis 3.x):拥有多主多从,如果其中一台主节点挂了,选举下面的从节点为主节点(无需哨兵)
数据可靠性:在服务器断电之后重新启动,数据还能恢复(数据持久化)
- RDB:周期性的同步内存中的数据到所在的机器的硬盘上
- AOF:将 DML 操作写到一个日志中,实时记录,断电后可以通过日志知道之前的操作
Reids 的特点 :
- 速度快:读数据 11w/s、写数据 8w/s
- 丰富的数据类型:String、List、Set、Zset、Hash …
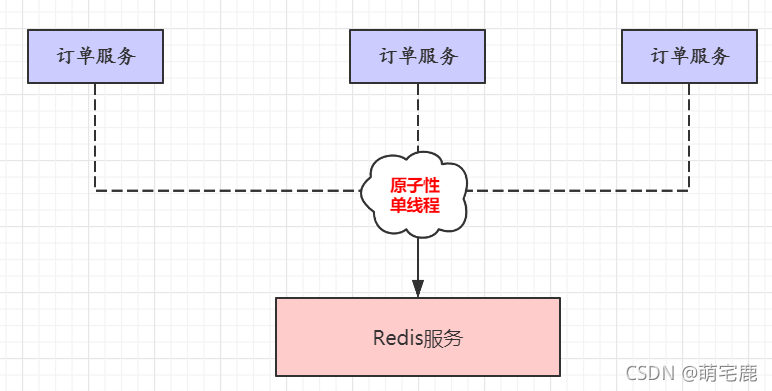
- 原子性操作:Redis 所有操作都是原子性,要么执行成功,要么执行失败完全不执行
多个操作也支持事务,通过 MULTI 和 EXEC 指令包起来 - 丰富的特征:Redis 支持 publish / subscribe、通知、key 过期 等特征
- 持久化机制
- 高可用分布式
为什么 Redis 这么快?
- 内存存储:所有的数据存放到内存当中(主要原因)
- 数据处理模型:工作线程是单线程处理
- 避免上下文切换和竞态消耗
- 使用 epoll 模型,非阻塞 IO
- 只有工作线程是单线程(指令执行),备份和同步都是多线程的
Redis 安装、启动
安装 gcc:Redis 是 C 语言编写的
yum -y install gcc automake autoconf libtool make
安装 Redis:
- 下载 wget:http://download.redis.io/releases/redis-5.0.8.tar.gz
- 解压:
tar -zxvf redis-5.0.8.tar.gz -C /usr/local - 编译:
make - 安装:将对应的执行脚本生成到指定目录的 bin 目录下
make PREFIX=/usr/local/redis-5.0.8 install
bin 目录下可执行文件说明:
redis-server # 启动redis服务命令
redis-cli # redis的客户端连接命令
redis-check-aof # 检查aof命令
redis-check-rdb # 检查rdb备份命令
redis-benchmark # redis性能测试命令
redis-sentinel # redis的哨兵机制启动命令
启动命令:进入目录 cd /usr/local/redis-5.0.8/bin,启动服务 ./redis-server
- 方式 1:直接使用
./redis-server - 方式 2:使用动态参数
./redis-server --port=6380 - 方式 3:使用配置文件启动(推荐)
# 启动时指定配置文件的路径 ./redis-server ../conf/redis_6300.conf
客户端访问:./redis-cli
redis-cli -h <IP地址> -p <端口>
退出客户端 Ctrl + C
Redis 常用配置
以下配置都是在 redis.conf 文件中修改:
- 配置后台启动:
daemonize yes - 配置远程登录:
bind 0.0.0.0
可以通过netstat -ntlp查看绑定的网卡信息 - 端口配置:
port: 6379 - 工作目录:
dir /usr/local/redis-5.0.8/data - 日志文件
logfile "6379.log" - 密码配置:
requirepass pwd1234,配置密码为 pwd1234
配置密码后关闭 Redis:./redis-cli -a pwd1234 shutdown
后台启动状态下关闭 Redis:
- 非正常关闭
# 查询PID ps -ef |grep redis-server # 通过PID强制关闭 kill -9 <PID> - 正常关闭
bin/redis-cli.sh shutdown # 不指定 -p, -h 默认情况连接的是本机的6379端口 bin/redis-cli.sh -p <port> -h <host>
Redis 数据类型
通用命令
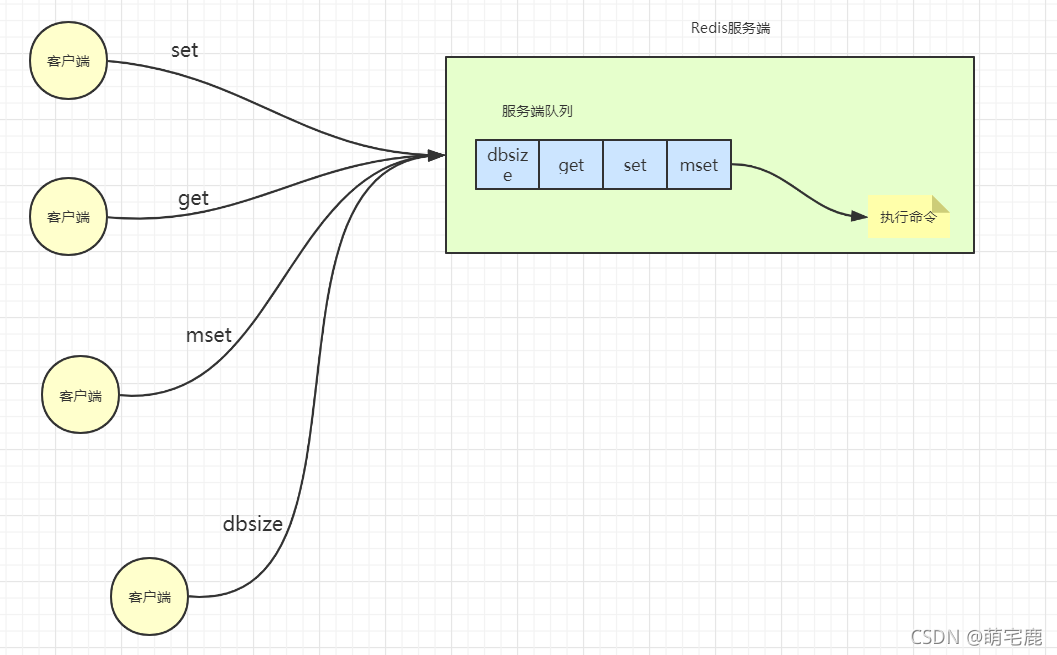
KEYS:查看所有的键;会扫描所有的数据,阻塞其他操作,不建议使用
DBSIZE:查看 key 的数量;性能很快,时间复杂度 O(1)
EXISTS [key]:判断是否存在对应的 key;存在返回 1, 不存在返回 0
EXPIRE [key] [seconds]:给对应的 key 设置过期时间,单位是秒
TTL [key]:获取 key 的有效时间;-1 代表永久有效,-2 代表无效的键
PERSIST [key]:把一个有过期时间的 key 设置为永久有效
DEL [key1] [key2] […]:根据指定 key 删除记录,可以一次删除多个
TYPE [key]:获取 key 对应的数据类型
FLUSHDB:清空数据库记录(不进行持久化操作,rdb 文件不变)
如果想恢复数据库,可以直接 kill 掉 redis-server 进程,然后重新启动服务,这样 Redis 重新读取 rdb 文件,数据恢复到 flushdb 操作之前的状态
注意:如果通过 shutdown 关闭服务会触发持久化操作,无法恢复数据,必须 kill 关闭服务
FLUSHALL:清空数据库记录(进行持久化操作,rdb 文件变化)
rdb 文件变成76个字节大小(初始状态下为76字节),数据库真正意义上清空
INFO:查看服务器信息
String - value 可以是字符串、数值、二进制、json数据
| 命令 | 说明 |
|---|---|
| set | 设置一个 key/value |
| get | 根据 key 获得对应的 value |
| del | 根据 key 删除数据 |
| mset | 一次设置多个 key value |
| mget | 一次获得多个 key 的 value |
| getset | 获得原始 key 的值,同时设置新值 |
| strlen | 获得对应 key 存储 value 的长度 |
| append | 为对应 key 的 value 追加内容 |
| getrange 索引0开始 | 截取 value 的内容 |
| setex | 设置一个 key 存活的有效期(秒) |
| psetex | 设置一个 key 存活的有效期(毫秒) |
| setnx | 存在不做任何操作,不存在添加 |
| msetnx 原子操作(只要有一个存在不做任何操作) | 可以同时设置多个 key,只要有一个存在都不保存 |
| decr | 进行数值类型的 -1 操作 |
| decrby | 根据提供的数据进行减法操作 |
| incr | 进行数值类型的 +1 操作 |
| incrby | 根据提供的数据进行加法操作 |
| incrbyfloat | 根据提供的数据加入浮点数 |
get、set、del:
127.0.0.1:6379> set name hesj
OK
127.0.0.1:6379> get name
"hesj"
127.0.0.1:6379> del name
(integer) 1
incr、decr、incrby、decrby:
127.0.0.1:6379> set count 100
OK
127.0.0.1:6379> incr count
(integer) 101
127.0.0.1:6379> decr count
(integer) 100
127.0.0.1:6379> INCRBY count 50
(integer) 150
127.0.0.1:6379> DECRBY count 50
(integer) 100
set、setnx、setxx、setex:
1 set : 新增或者修改,不存在则新增,存在则修改
2 setnx: 新增操作,存在则不处理
3 setxx: 修改操作,存在则修改,不存在则不处理
4 setex: 设置key的过期时间
127.0.0.1:6379> set user:1:age 21
OK
127.0.0.1:6379> set user:1:name lucy nx
OK
127.0.0.1:6379> set user:1:hobby football ex 20
OK
127.0.0.1:6379> set user:1:age 24 xx
OK
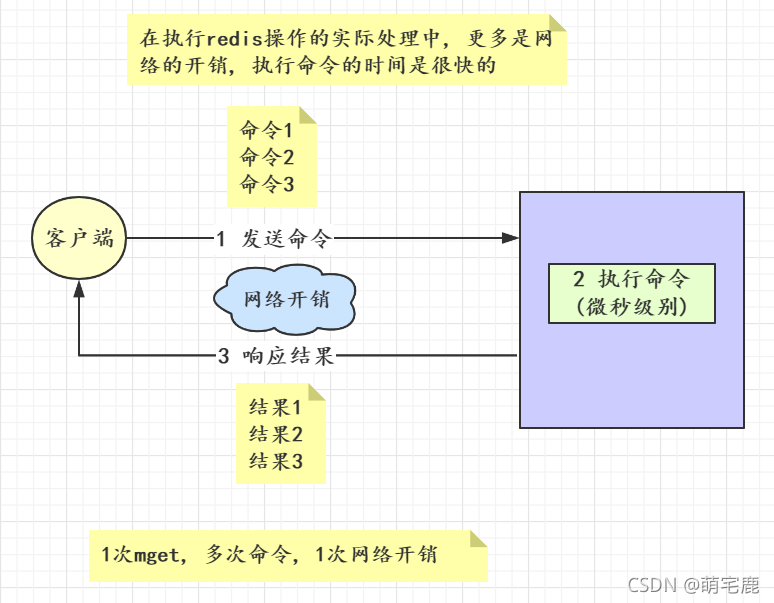
mget、mset:网络开销是影响性能的主要原因,使用批量操作减少网络开销
getset、append、strlen:
1 getset: 设置值并且返回原来的值
2 append: 字符串拼接
3 strlen: 字符串长度
127.0.0.1:6379> getset user:1:age 39
"24"
127.0.0.1:6379> APPEND user:1:name lili
(integer) 8
127.0.0.1:6379> get user:1:name
"lucylili"
127.0.0.1:6379> strlen user:1:name
(integer) 8
incrbyfloat、getrange、setrange:
incrbyfloat: 小数递增, 传入负数递减
getrange: 获取部分数据
settrange: 局部设置替换
127.0.0.1:6379> set count 200
OK
127.0.0.1:6379> INCRBYFLOAT count 26.5
"226.5"
127.0.0.1:6379> set name heshengjun
OK
127.0.0.1:6379> getrange name 0 4
"heshe"
127.0.0.1:6379> setrange name 0 li
(integer) 10
127.0.0.1:6379> get name
"lishengjun"
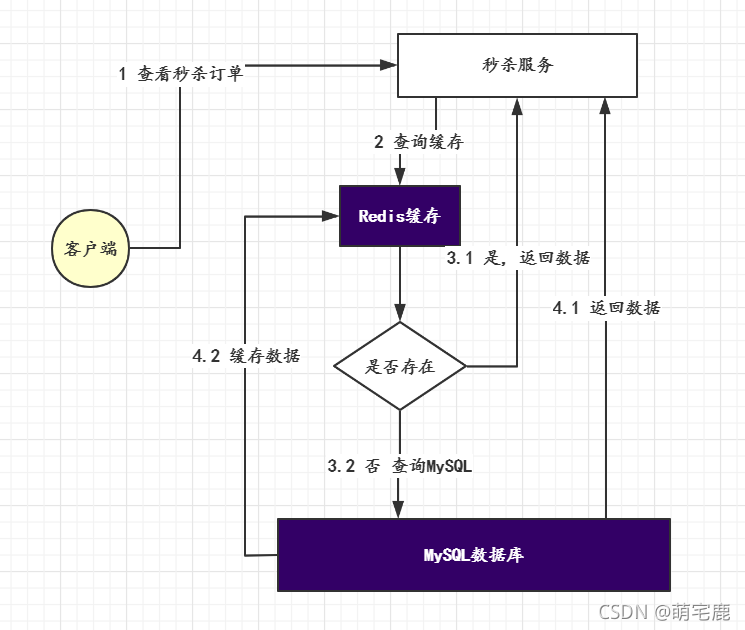
应用场景:
- 在线网站的访问量
- 缓存秒杀订单
- 分布式 ID 生成器
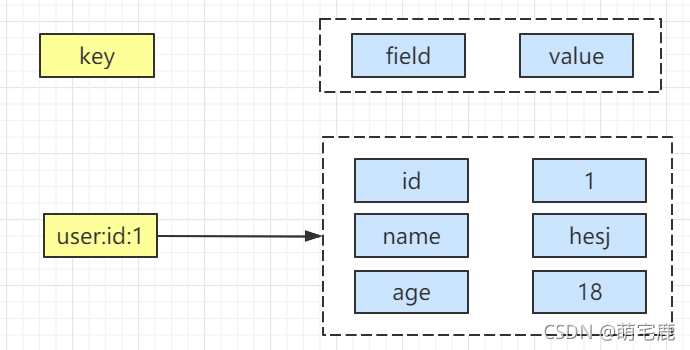
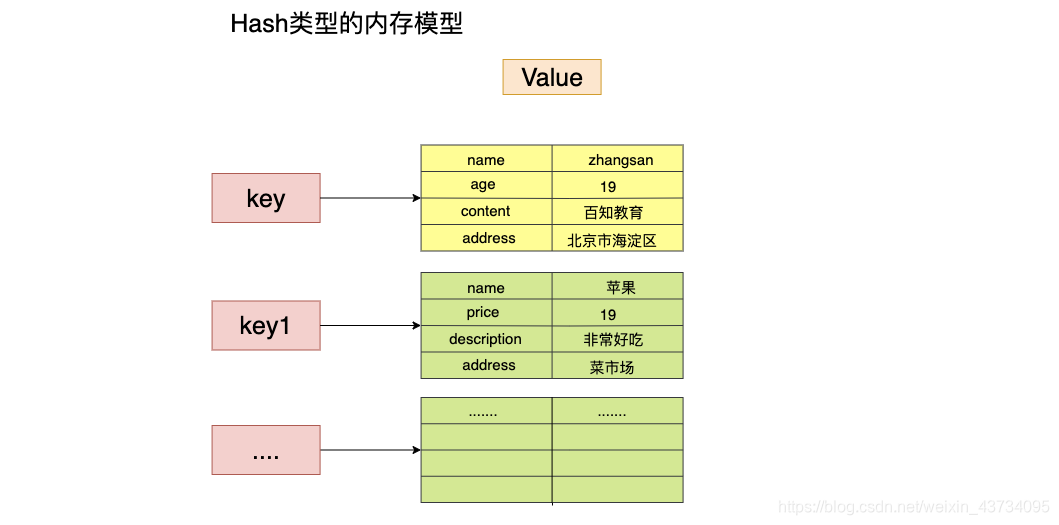
Hash - 存在 key-value,key 是无序的,value 是 map 结构
| 命令 | 说明 |
|---|---|
| hset | 设置一个 key/value 对 |
| hget | 获得一个 key 对应的 value |
| hgetall | 获得所有的 key/value 对 |
| hdel | 删除某一个 key/value 对 |
| hexists | 判断一个 key 是否存在 |
| hkeys | 获得所有的 key |
| hvals | 获得所有的 value |
| hmset | 设置多个 key/value |
| hmget | 获得多个 key 的 value |
| hsetnx | 设置一个不存在的 key 的值 |
| hincrby | 为 value 进行加法运算 |
| hincrbyfloat | 为 value 加入浮点值 |
hget、hset、hdel:
hget: 根据key和field获取对应的字段值
hset: 根据key和field设置对应的属性值
hdel: 根据key和field删除对应的值
127.0.0.1:6379> hset user:id:1 name hesj
(integer) 1
127.0.0.1:6379> hget user:id:1 name
"hesj"
127.0.0.1:6379> hset user:id:1 age 22
(integer) 1
127.0.0.1:6379> hget user:id:1 age
"22"
127.0.0.1:6379> hdel user:id:1 age
(integer) 1
hexists、hlen:
hexists: 判断字段是否存在
hlen: 判断有多少个field字段
127.0.0.1:6379> HEXISTS user:id:1 name
(integer) 1
127.0.0.1:6379> HEXISTS user:id:1 age
(integer) 0
127.0.0.1:6379> hlen user:id:1
(integer) 1
hmget、hmset:
hmget: 获取多个字段的值
hmset: 设置多个字段的值
127.0.0.1:6379> hmset user:id:2 name lucy age 21 hobby basketball
OK
127.0.0.1:6379> hmget user:id:2 name age hobby
1) "lucy"
2) "21"
3) "basketball"
hgetall、hvals、hkeys:
hgetall: 慎用
hgetall: 根据key返回hash的所有的字段和值
hvals: 根据key返回所有的值
hkeys: 根据key返回所有的字段
127.0.0.1:6379> hgetall user:id:2
1) "name"
2) "lucy"
3) "age"
4) "21"
5) "hobby"
6) "basketball"
127.0.0.1:6379> hkeys user:id:2
1) "name"
2) "age"
3) "hobby"
127.0.0.1:6379> hvals user:id:2
1) "lucy"
2) "21"
3) "basketball"
hsetnx、hincrby、hincrbyfloat:
hsetnx: 修改field字段的值,如果值存在,则不修改; 如果不存在,进行修改操作
hincrby: 对于字段field进行递增或者递减操作
hincrbyfloat: 对于字段field进行递增或者递减操作
127.0.0.1:6379> hsetnx user:id:2 height 170
(integer) 1
127.0.0.1:6379> HINCRBY user:id:2 height 2
(integer) 172
127.0.0.1:6379> HINCRBYFLOAT user:id:2 height -28.9
"143.10000000000000001"
应用场景:
- 用户主页的访问量
127.0.0.1:6379> hset user:1:homepage visit 100
(integer) 1
127.0.0.1:6379> hset user:1:homepage title 200
(integer) 1
127.0.0.1:6379> hset user:1:homepage friend 500
(integer) 1
List - 元素有序、可以重复

| 命令 | 说明 |
|---|---|
| lpush | 将某个值加入到一个 key 列表头部 |
| lpushx | 同 lpush,但是必须要保证这个 key 存在 |
| rpush | 将某个值加入到一个 key 列表末尾 |
| rpushx | 同 rpush,但是必须要保证这个 key 存在 |
| lpop | 返回和移除列表左边的第一个元素 |
| rpop | 返回和移除列表右边的第一个元素 |
| lrange | 获取某一个下标区间内的元素 |
| llen | 获取列表元素个数 |
| lset | 设置某一个指定索引的值(索引必须存在) |
| lindex | 获取某一个指定索引位置的元素 |
| lrem | 删除重复元素 |
| ltrim | 保留列表中特定区间内的元素 |
| linsert | 在某一个元素之前,之后插入新元素 |
应用场景:
- 消息队列:Redis 的 lpush + brpop 命令组合即可实现阻塞队列
生产者客户端是用 lupsh 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞时的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性
模拟消息队列, 阻塞状态
# 消息生产者
RPUSH user:1:friends e
# 消息消费者
blpop user:1:friends 50
- 朋友圈点赞
规定: 朋友圈内容的格式
内容: user:x:post:x content 来存储
点赞: post:x:good list 来存储
1. 创建一条朋友圈内容: set user:1:post:91 'hello redis'
2. 点赞:
lpush post:91:good '{id:1,name:lucy,img:xxx.jpg}'
lpush post:91:good '{id:2,name:tom,img:xxx.jpg}'
lpush post:91:good '{id:3,name:jack,img:xxx.jpg}'
3. 查看有多少人点赞: llen post:91:good
4. 查看哪些人点赞: lrange post:91:good 0 -1
- 回帖
1. 创建一个帖子: set user:1:post:90 'wohenshuai'
2. 创建一个回帖: set postreply:1 'nonono'
3. 把回帖和帖子关联: lpush post:90:replies 1
4. 再来一条回帖
set postreply:2 'hehe'
lpush post:90:replies 2
5. 查询帖子的回帖:
lrange post:90:replies 0 -1
get postreply:2
Set - 元素无序、不可重复

| 命令 | 说明 |
|---|---|
| sadd | 为集合添加元素 |
| smembers | 显示集合中所有元素(无序) |
| scard | 返回集合中元素的个数 |
| spop | 随机返回一个元素,并将元素在集合中删除 |
| smove | 从一个集合中向另一个集合移动元素(必须是同一种类型) |
| srem | 从集合中删除一个元素 |
| sismember | 判断一个集合中是否含有这个元素 |
| srandmember | 随机返回元素 |
| sdiff | 去掉第一个集合中其它集合含有的相同元素,求第一个集合与第二个集合的差集 |
| sinter | 求交集 |
| sunion | 求和集 |
sadd、srem:
127.0.0.1:6379> SADD user:1:friends 1 2 3 4
127.0.0.1:6379> SADD user:2:friends 4 5 6 7
127.0.0.1:6379> SMEMBERS user:1:friends
127.0.0.1:6379> SMEMBERS user:2:friends
127.0.0.1:6379> SREM user:2:friends 7
sinter、sdiff、sunion:
127.0.0.1:6379> SINTER user:1:friends user:2:friends
127.0.0.1:6379> SDIFF user:1:friends user:2:friends
127.0.0.1:6379> SUNION user:1:friends user:2:friends
scard、sismember、srandmember、smembers、sscan:
127.0.0.1:6379> scard user:1:friends
127.0.0.1:6379> SISMEMBER user:1:friends 2
127.0.0.1:6379> SRANDMEMBER user:1:friends
127.0.0.1:6379> sscan user:1:friends 0
spop、srandmember:
127.0.0.1:6379> spop user:1:friends 2
127.0.0.1:6379> SRANDMEMBER user:2:friends 1
应用场景:
- 抽奖系统
1, 准备一个抽奖池: sadd luckydraw 1 2 3 4 5 6 7 8 9 10 11 12 13
2, 抽3个三等奖: spop luckydraw 3
3, 抽2个二等奖: spop luckydraw 2
4, 抽1个二等奖: spop luckydraw 1
- 共同好友
好友推荐
1,初始化好友圈
sadd user:1:friends 'user:2' 'user:3' 'user:5'
sadd user:2:friends 'user:1' 'user:3' 'user:6'
sadd user:3:friends 'user:1' 'user:7' 'user:8'
2,把user:1的好友的好友集合做并集
user:1 user:3 user:6 user:7 user:8
Sunionstore user:1:union user:2:friends user:3:friends
3,让这个并集和user:1的好友集合做差集
user:1 user:6 user:7 user:8
Sdiffstore user:1:diff user:union user:1:friends
4,从差集中去掉自己
user:6 user:7 user:8
Srem user:diff user:1
5,随机选取推荐好友
SRANDMEMBER user:diff 2
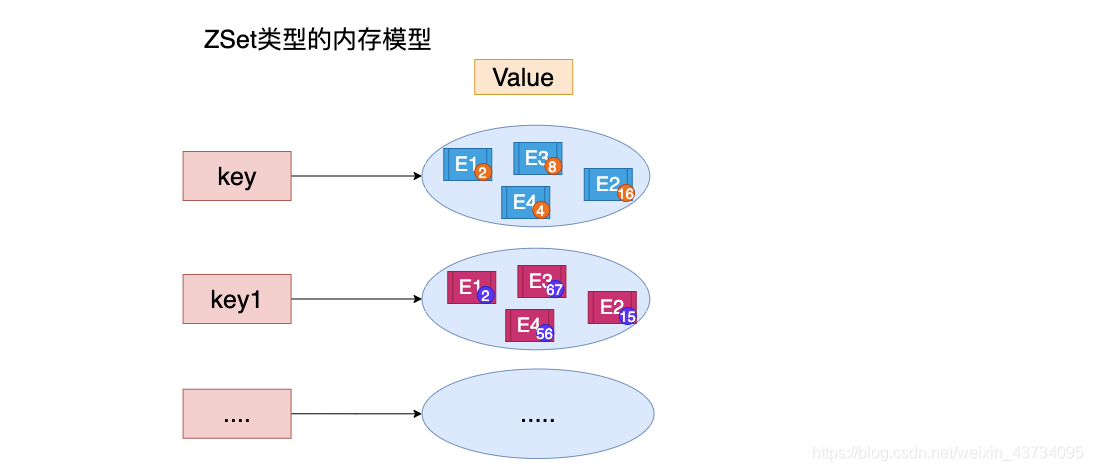
ZSet - 元素根据 score 排序、不可重复
| 命令 | 说明 |
|---|---|
| zadd | 添加一个有序集合元素 |
| zcard | 返回集合的元素个数 |
| zrange 升序 zrevrange 降序 | 返回一个范围内的元素 |
| zrangebyscore | 按照分数查找一个范围内的元素 |
| zrank | 返回排名 |
| zrevrank | 倒序排名 |
| zscore | 显示某一个元素的分数 |
| zrem | 移除某一个元素 |
| zincrby | 给某个特定元素加分 |
127.0.0.1:6379> zadd rank 80 001
(integer) 1
127.0.0.1:6379> zadd rank 75 002
127.0.0.1:6379> zadd rank 90 003
127.0.0.1:6379> zadd rank 60 004
127.0.0.1:6379> zadd rank 65 005
127.0.0.1:6379> zadd rank 100 006
127.0.0.1:6379> zrem rank 003
127.0.0.1:6379> zscore rank 002
"75"
127.0.0.1:6379> ZINCRBY rank 20 002
127.0.0.1:6379> zcard rank
127.0.0.1:6379> zrank rank 002
127.0.0.1:6379> zrevrank rank 001
127.0.0.1:6379> ZRANGE rank 0 -1
127.0.0.1:6379> ZRANGEBYSCORE rank 50 90
127.0.0.1:6379> zcount rank 50 90
应用场景:
- 排行榜(按照时间、按照播放量、按照获得的赞数等)