用户冷启动目前采用的召回策略主要有:
目录
一、短视频
1、对于完全没有观影历史的用户:
(1)基于用户的注册信息(性别、地域、学历、偏好、app list等)
找到用户所属人群,召回该人群中热度最高的头部视频,人群的分类策略是基于聚类算法;
找到用户最偏好的几个观影类别,召回每个类别下热度最高的视频,用户到类别的对应关系是通过对热用户的观影历史通过传统机器学习算法训练得到;(采用这种策略的原因在于,通过类别训练得到的人群,更有区分度,推荐的内容也不至于过于分散、杂乱)
(2)召回热门视频、默认列表;为使得默认列表能得到最好的收益,需要利用bandit算法,这里我们采用了LinUBC的策略进行热度和多样性上的权衡;原理详见【推荐系统】笔记 ― Bandit 算法 - 知乎
(3)利用社交信息:用户关注的其他用户,或学校相同、地域相同的用户,将新用户与老用户对应起来,把老用户喜好的视频推给新用户;
这里用到的模型是迁移学习中的知识蒸馏,具体原理见【总结】推荐系统中知识蒸馏应用 - 知乎
2、对于有观影历史,但近期观影历史或只有远期观影历史的用户(通常这部分用户也被叫做冷启动过渡用户):
(1)采用正常视频的召回策略:实时协同、embedding召回、离线实体词等;
(2)采用画像召回:基于kis、实时标签、类别的倒排策略;
(3)兴趣探索:基于标签、源站作者的探索;
3、对于无短视频观影历史,但有长视频观影历史或搜索记录的用户:
(1)用长视频kis、标签、类别推短视频的倒排策略;
(2)通过长视频推VRS片花;
(3)通过搜索关键词匹配短视频标题、类别、标签、kis;
(4)通过源站作者ctr;
(5)通过运营配置:如大V精选、优质作者pugc;
4、对长期画像分梯度召回
对于除2个月画像之外,6个月画像命中占比超过10%的用户,采用梯度召回的方式,这样可以保证对近期画像的利用率,保证画像的质量。
二、长视频
1、基于短视频kis、一级类或关键词搜索,映射到长视频;
2、基于用户固有特征,进行用户分群和一级类预测,进行类别倒排;
3、基于运营:长视频运营热点等;
4、打底策略:根据豆瓣得分、热度和时间等因素进行默认列表的计算;
三、用户冷启动所运用的算法模型及优化
1、用户分群
首先利用活跃用户的特征和观影历史,训练得到用户特征到视频类别的映射,这样在面对新用户时,就可以得到他的一级类预测,然后在该类别下进行倒排召回;
2、迁移学习――知识蒸馏
(1)原理:一般softmax层的输出,只取概率最大的正例,而遗失了负标签的概率值。而蒸馏的方法也同样提取了负标签的概率信息(soft target)。但softmax输出的概率分布熵相对较小,负标签的值都很接近0,对损失函数的贡献非常小,所以给softmax加上了温度T这个变量:
![]()
?T越高,softmax的output probability distribution越趋于平滑,其分布的熵也就越大,负标签所携带的信息会被相对地放大,模型训练将更加关注负标签。
(2)具体方法:先训练Net-T,然后在高温T下,蒸馏Net-T的知识到Net-S:

?高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。
![]()
?
![]()
?其中,α和β都是超参;Teacher model只在离线训练的时候用到,线上部署时只用Student model,一个Teacher model可以蒸馏得到多个student model,都达到了压缩模型的效果。
(3)温度的高低改变的是Net-S中对负标签的关注程度,温度较高时,会更多地关注到负标签;若要从有部分信息量地负标签中学习,温度要高一些;若要防止受负标签中噪声影响,温度要低一些。
知识蒸馏是迁移学习的一种。
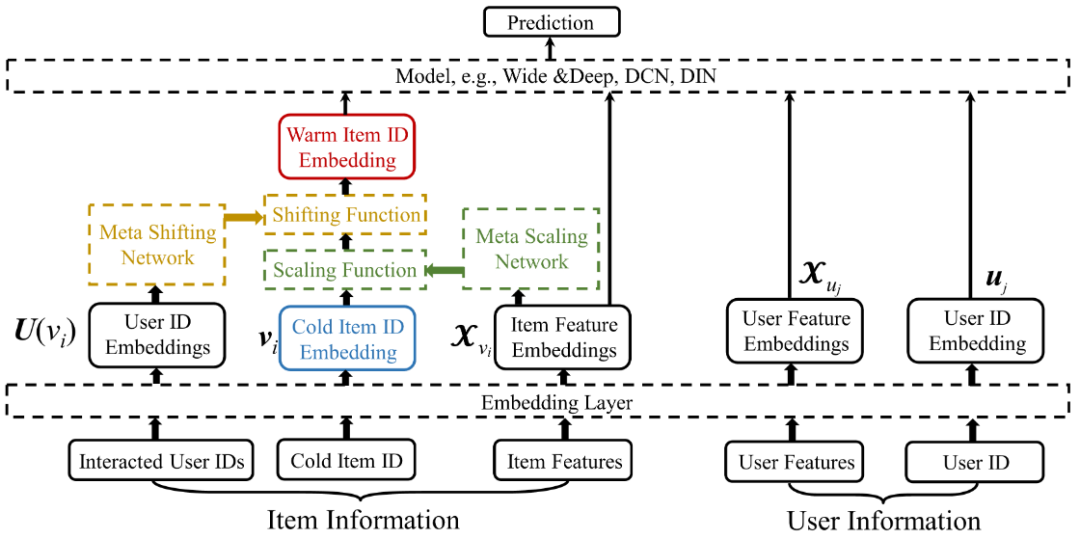
3、mwuf模型 (meta warm up framework)
(1)原理:
使用一个元偏移网络利用所有的交互过的用户的表示,来输出一个偏移向量,巩固ID embedding的表示(高效利用有限的交互数据)。其实本质就是,把现有所有物品学到的ID embedding做个算数平均值作为新物品的初始化ID?embedding。有点类似于airbnb embedding的思想。
提出通过一个元拉伸网络从物品特征中预测一个拉伸函数,对冷启动ID embedding进行一个特征变换,将其变换到一个更好的特征空间中。本质上就是训练了一个映射函数,然后把Cold ID embedding 映射成一个新的 ID embedding,把这个叫做warmer embedding,相当于加了一层预处理或者说是数学变换。
(2)模型结构:
4、bandit算法
(1)原理:
用分类或者Topic来表示每个用户兴趣,也就是MAB问题中的臂(Arm),我们可以通过几次试验,最小化累积遗憾,来刻画出新用户心目中对每个Topic的感兴趣概率,从而逼近用户真正感兴趣的topic。
(2)模型:
UCB(Upper Confidence Bound)算法:先对每个臂都摇一下,然后按照公式计算每个臂的分数,选择分数最大的臂;然后根据选择结果,更新 t 和 Tjt 。x(t) 是这个臂到目前的收益均值,为bonus,而后面一项则本质是均值的标准差, t是实验次数,Tjt是这个臂被试次数。
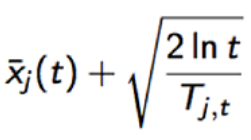
?LinUCB算法:假设一个Item被选择后推送给一个User,其回报和相关Feature成线性关系。用User和Item的特征预估回报及其置信区间,选择置信区间上界最大的Item推荐,观察回报后更新线性关系的参数.
(3)实现方案:

- 通过Storm程序来实时更新LinUCB参数
- 需要维护一个视频冷启动池和新用户标识,只记录新用户对冷启动池的行为操作作为参数迭代数据
- 这里的行为数据包含了展示点击和展示未点击
- 用户和视频特征需要先做一个基础特征,和CTR所用的丰富特征不同,LinUCB的特征一开始应谨慎选取,不宜太过丰富。
5、随机性和多样性的引入
在过引擎时,多路召回融合,做多样性控制,随机取画像以增加随机性;
6、针对流失用户的数据分析
对于冷启动流失用户,将其推荐历史作为负样本,更新默认列表或embedding等模型;
7、Explore & Exploit
通过兴趣探索和利用策略,来挖掘冷启动用户的兴趣;目前主要是标签维度和源站作者维度的探索,通过协同和word2vec模型;
8、知识图谱
参考:
【1】【经典简读】知识蒸馏(Knowledge Distillation) 经典之作 - 知乎
【2】一文梳理冷启动推荐算法模型进展_张小磊的博客-CSDN博客