redis简介
redis是一个基于内存的NoSQL数据库,因为数据是存在内存中
,主要用于缓存。
redis的存储方式是Key-Value的。
redis线程模型
redis采用的是单线程模型,为什么会采用单线程呢?
因为redis是基于内存的数据库,只会操作内存,不牵扯到IO,属于CPU计算密集型任务,如果贸然引入多线程的话,线程之间的切换只会白白浪费资源,不如单线程的执行效率。
除此之外,单线程不会造成并发问题,保证了线程安全问题。
单线程怎么同时处理多个连接呢?
redis采用的epoll,也就是多路IO复用。epoll详解可以看我之前写的文章linux中TCP连接详解
我在这里简单的说一下:
1、 epoll的做法是创建一个event_poll对象。
event_poll对象中维护了一个epitem就绪列表,epitem中记录了对应的socket对象指针和event_poll对象指针。
然后就可以新建一个线程调用epoll_wait()方法来获取对应的数据,如果event_poll中的就绪列表不为空,就取出数据,拿出对应的socket对象,就可以读取数据了。
2、 Linux中每个连接都会对应一个socket对象,socket中维护了一个接收队列,用来存放数据包;socket中同时维护了一个等待队列,在epoll模式下,等待队列中存放的是event_poll_callback()和epitem信息。当内核将数据包挂到socket的接收队列中的时候,会唤醒对应的event_poll_callback(),并将epitem作为参数传入。
3、 event_poll_callback()首先会将epitem放到对应的event_poll对象的就绪队列中,然后唤醒线程来读取数据了。
就是通过一个就绪列表就可以只利用一个线程来读取多个socket信息了。

redis五种数据类型
redis中能够存储五种数据类型
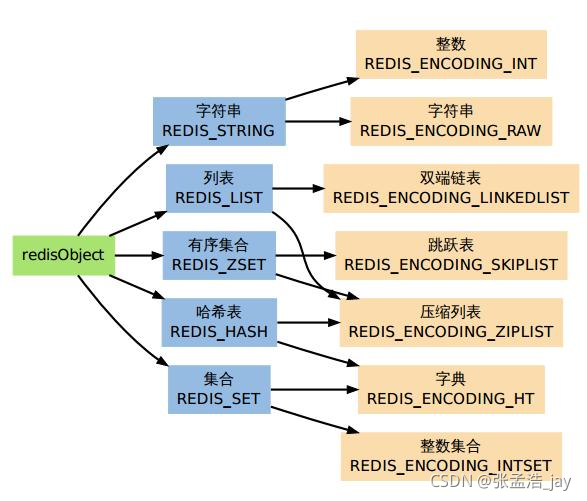
1、string
string有两种存储方式:
第一种是 如果string对应的是一个数字,就会按照int方式来存储
第二种是 按照字符数组存储的
struct sdshdr{
int len;/*字符串长度*/
int free;/*未使用的字节长度*/
char buf[];/*保存字符串的字节数组*/
}
sds有以下优点:
1、 O(1)时间获取长度
2、 预分配空间。如果string大小小于1M,预分配一倍的空闲空间,如果大小大于1M,就预分配1M的空间
3、 懒删除。当缩小字符串的时候,对应的空间不会回收,只会增加对应的free。而是等到后续append后继续使用
Redis中规定 string的大小不能超过512MB
2、list
list就是列表,对应两种实现方式:
1、ziplist
当list的长度小于512,并且list中元素的大小都小于64字节的时候,会使用ziplist存储。
从名字就可以看出,ziplist的目的是为了减少内存使用。
ziplist使用的是数组,而不是链表。
我们都知道链表的好处是不要求存储空间连续,但是坏处就是需要指针来保存对应的后续节点信息,64位操作系统,就需要8个字节来存储一个指针了。。。
如果list中元素小于8字节的话,指针都比数据占用空间高了,属实有点大头儿子了。。
所以ziplist利用的数组,数组因为地址是连续的,直接加上对应的偏移就可以得到对应的地址了。

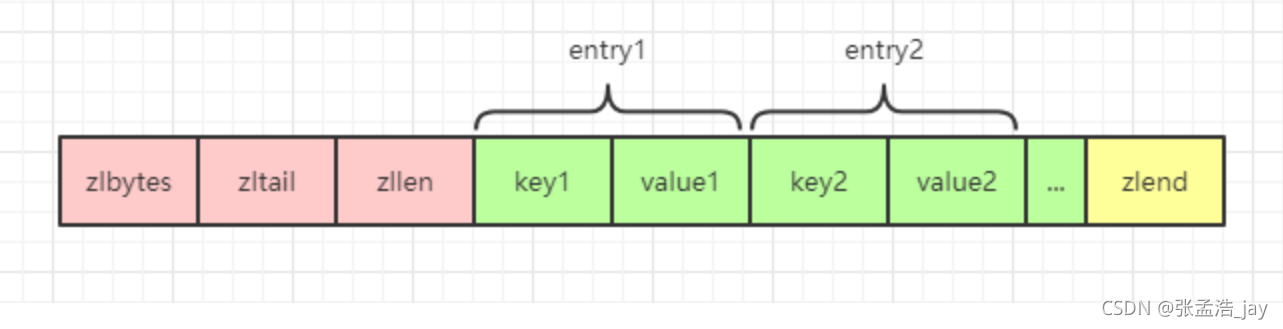
ziplist的组成结构如上图所示,ziplist使用了严格的编码结构,主要分为以下几个部分:
1、头部
zlbytes
ziplist的字节个数,占用4个字节
zltail
ziplist的尾部的偏移量 offset,占用4个字节
zllen
ziplist中的元素个数,占用两个字节
2、entry
真正存储的元素,组织结构如下

previous_entry_length
前一个entry的长度,用于从后往前遍历list。
采用动态长度编码,当前一个entry的长度小于254字节的时候,就用1个字节记录大小,当前一个entry的长度大于254的字节的时候,用5个字节表示大小。
怎么实现的动态编码呢?
首先观察第一个字节,如果第一个字节是0xFE的话,就说明是5个字节编码,后面的4个字节存储的是长度。否则就是按照1个字节编码,存储的就是对应的长度。
encoding
encoding用来表示content的存储数据类型和content的长度信息,同样采取动态编码
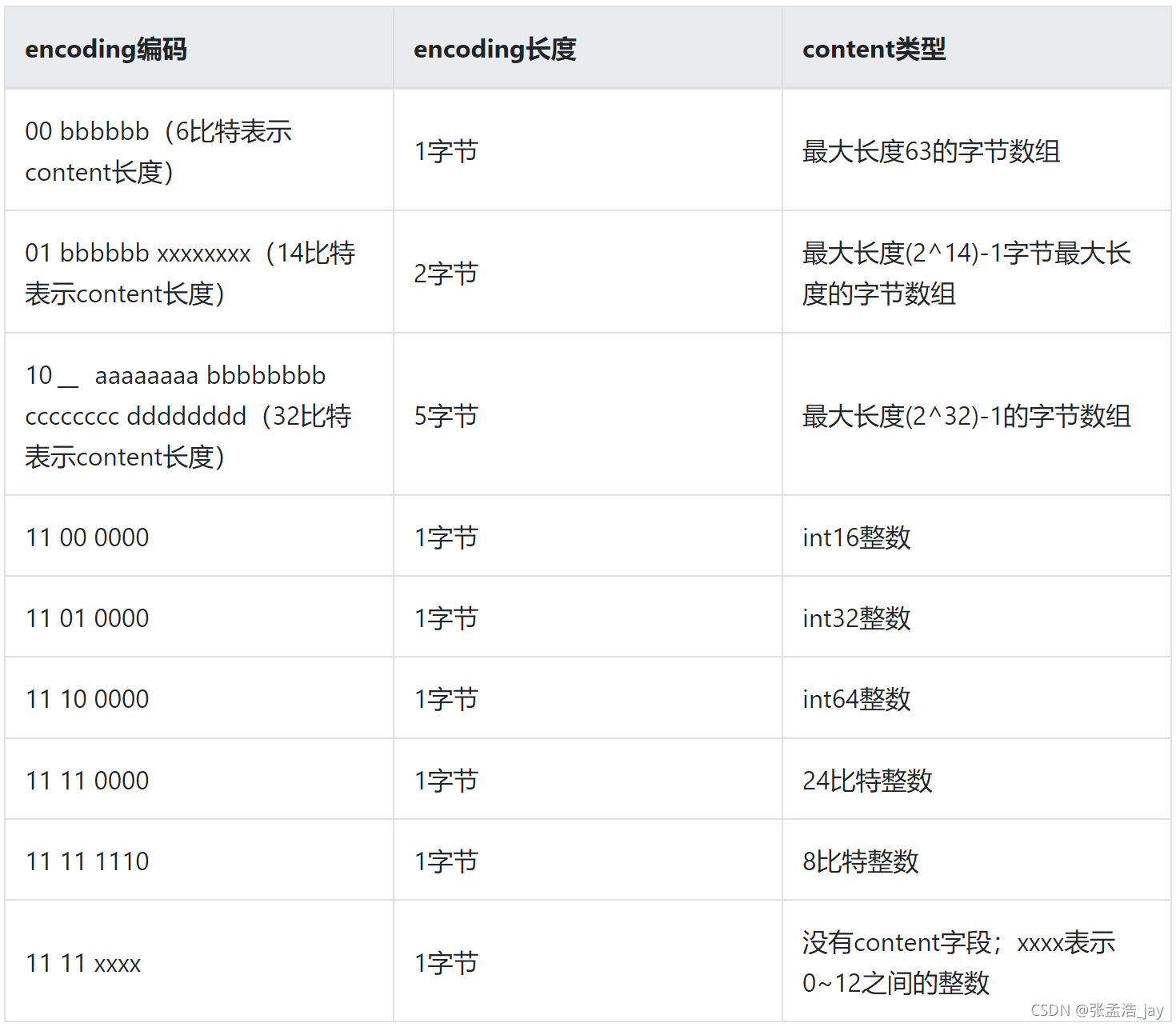
从上表可以看出,将前几位比特分类,对应着不同的存储类型和content长度编码。
content
content就是存储的实际数据
3、zlend
代表列表的末尾,占用一个字节,恒为0xFF
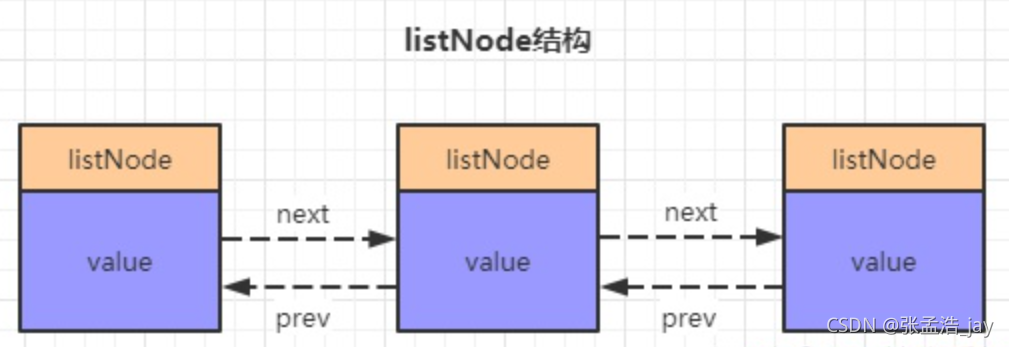
2、linkedlist
当list的长度大于512或者list中元素大于64字节的时候,就采用linkedlist来存放,因为数据太大了,不太好提供这么大的连续内存来存放数据了。
linkedlist就是一个双向链表
3、set
set对应的是元素不重复的集合,也有两种存储方式
1、intset
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素个数
uint32_t length;
// 保存元素的数组
int8_t contents[];
intset适用于元素为整数,并且set中元素个数小于512的情况,还是采用数组的方式来存储,使用连续内存,减少内存使用。
intset中是按照元素的大小顺序来排列。
encoding
intset采用变长编码的方式来存储,encoding分为int_16,int_32,int_64三种,分别对应16位、32位、64位 能够表示的整数范围。
当整数的范围在int_16的时候,就将整数按照16位来存储,减少内存的使用。
length
length为set中存储的元素个数。
contents
contents存储的是真正的数据,按数组方式存在。
插入元素
如果插入的元素大于encoding表示范围,就会引发升级。首先会通过元素个数和encoding的存储大小计算出新元素的对应位置,这个位置一定是在尾部,因为intset中是按照元素大小排列的。然后从后往前的将前面的数据一个一个的升级。
如果插入的元素在encoding的表示范围,就按照二分法找到对应的插入位置,将在插入位置之后的元素往后移动,最后把新元素插入到对应的位置。
dictht
typedf struct dict{
dictType *type;//类型特定函数,包括一些自定义函数,这些函数使得key和value能够存储
void *private;//私有数据
dictht ht[2];//两张hash表
int rehashidx;//rehash索引,字典没有进行rehash时,此值为-1
unsigned long iterators; //正在迭代的迭代器数量
}dict;
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht;
typedf struct dictEntry{
void *key;//键
union{
void val;
unit64_t u64;
int64_t s64;
double d;
}v;//值
struct dictEntry *next;//指向下一个节点的指针
}dictEntry;
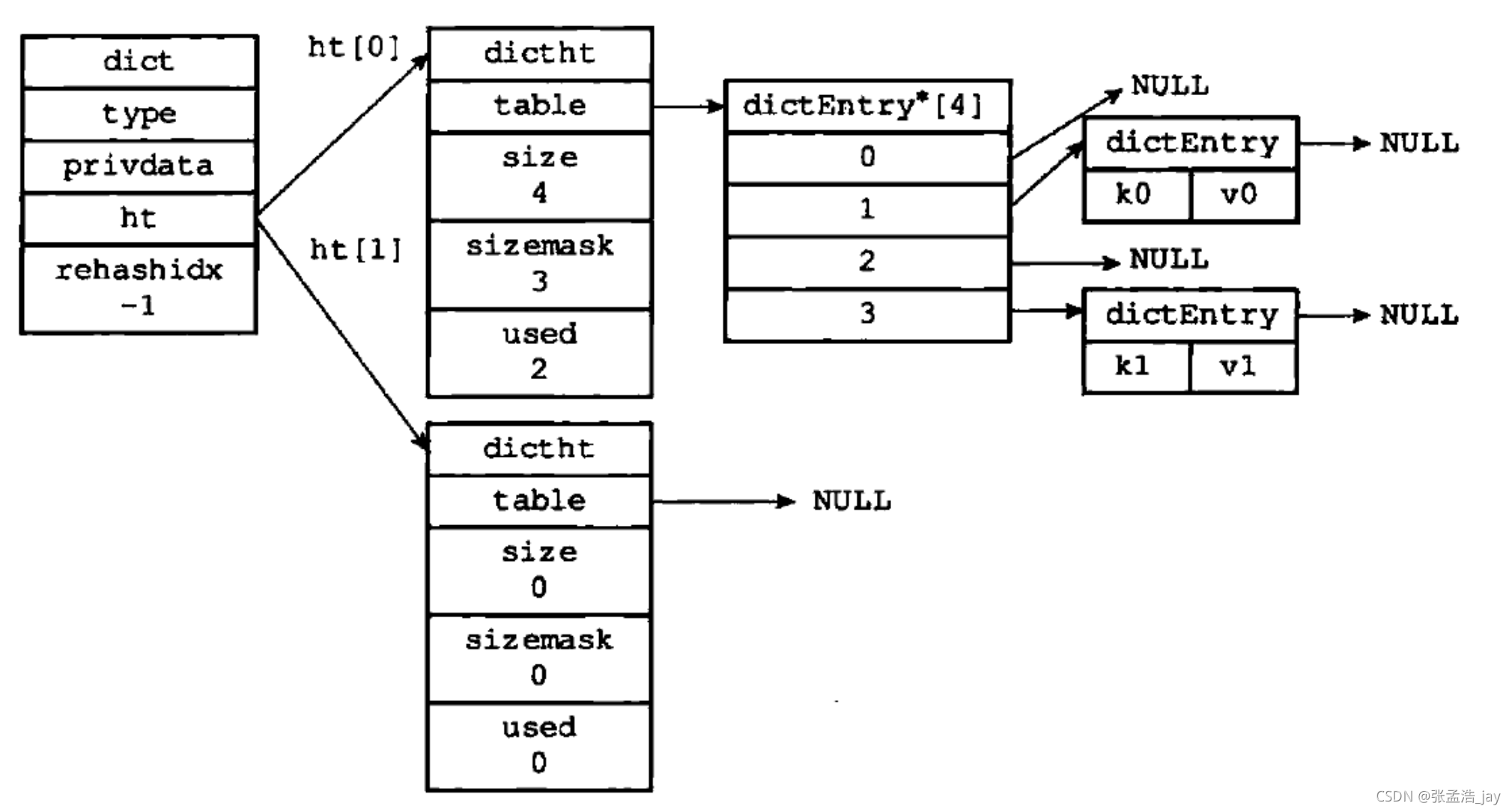
通过代码和图就可以看出,dictht是一个简化的hashmap,通过拉链来解决哈希冲突。
dict中含有两个dictht,ht[0]用于存放数据,ht[1]用于扩容和收缩。
扩容详情
以下两种情况会进行扩容。
首先说下 负载因子 = 元素个数(ht.used) / 哈希表数组大小
1、 如果没有进行持久化,负载因子 > 1
2、 如果正在持久化,负载因子 > 5
因为当持久化的时候,会往磁盘中写入对应的数据,尽量要避免扩容,所以负载因子会变成5。
1、 首先将哈希表的数组大小增加到 第一个 大于等于 ht.used * 2的 2n。比如当前ht.used = 100,那么新的哈希表大小就为 128。
2、 对ht[1]分配对应的哈希表空间,不会直接将ht[0]的数据重新hash然后搬运到ht[1]上,而是采用渐近扩容
渐近扩容
如果哈希表中存在很多数量的键值对,一次性的将键值对搬运到ht[1]的话,会占用redis的大量时间,造成用户服务变慢。所以采用渐近扩容。
ht中维护了一个rehash变量,在渐近扩容的时候,会将rehashindex = 0,当操作了一次ht[0]中的元素的时候,会将rehashindex ++,当rehashindex = ht[0].used的时候,就说明渐近扩容结束了,将rehash = -1,代表扩容结束。
增加:
首先查看ht[0]是否存在对应的元素,如果存在,就将其重新hash加入到ht[1]中,并将ht[0]中的元素删除。rehashindex+1
如果不存在,就将其加入到ht[1]中。
查询:
首先查询ht[1],如果ht[1]中存在,就直接返回,如果不存在就查询ht[0],将其重新hash加入到ht[1]中,并将其从ht[1]中删除。rehashindex+1
删除:
查询ht[0],如果ht[0]中存在,就将其删除,rehashindex+1.
更新:
查询ht[1],如果存在,直接更新。
如果不存在,就查询ht[0],如果存在,就将新值插入到ht[1]中,并且将旧值从ht[0]中删除,rehashindex+1.
收缩详情
当负载因子小于 0.1的时候,会触发收缩
ht[1]的大小变为第一个大于等于 ht[0].used 的 2n
然后继续开始渐近收缩,和渐近扩容一样。
当redis线程空闲的时候,也会帮助扩容或者收缩。
4、hash
hash是用来存储字典的,也有两种方式存储
1、ziplist
当key-value的大小小于64字节并且hash中元素个数小于512的时候,会使用ziplist来存储
ziplist的话,就需要遍历列表来查找对应的key和value了,所以ziplist适用于那种小规模数据。
2、dictht
当hash中的元素比较多的时候,申请比较大的连续内存也比较困难,就开始通过哈希表存储,具体原理和set中对应的hash一致。
5、zset
zset存储的是有序的set,也有两种存储格式:
1、ziplist
利用数组有序的排列元素,当元素个数小于128,并且元素小于64字节的时候采用ziplist
2、skiplist
skiplist叫做跳表,通过对一个底层链表建立多个上层抽象链表建立对应的目录来加快查找速度。
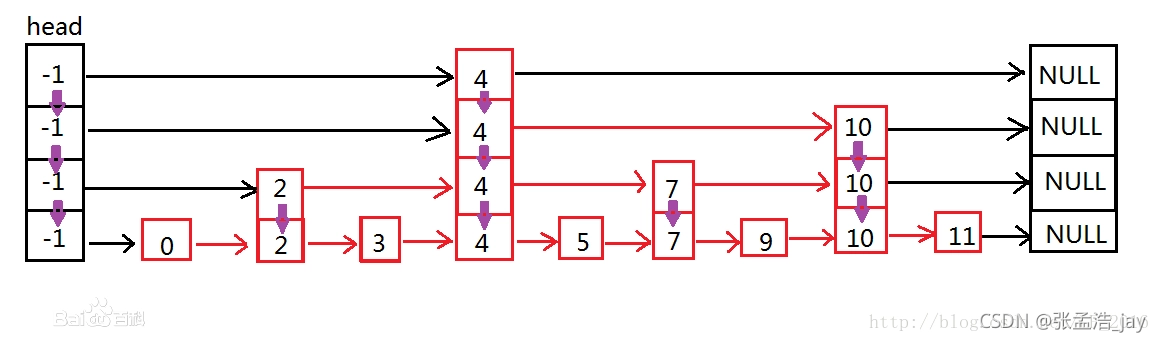
skiplist的具体实现原理我们单独开一篇文章说明。
skiplist是一个概率型结构,通过概率来决定新插入的节点插入到哪一层。
为什么不用红黑树或者B+树?
1、 红黑树只支持固定key的查询,不支持区间查询。
2、 相较于B+树,跳表的实现更加简单,并且跳表可以通过降低概率来减少索引项,减少内存的占用。
skiplist作者的原话在这里:
1)、 They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
2、 A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
3、 They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
使用场景
| 类型 | 使用场景 |
|---|---|
| string | 计数器 |
| hash | 存储对象,key-value代表着对象属性和对应的值 |
| list | 列表:消息列表、粉丝列表等 |
| set | set是去重的,可以用来求交集、并集、差集。可以用来快速统计共同关注、可能认识的人、朋友圈设计等 |
| zset | 有序的set。用来处理排行榜问题 |