文章目录
一、MVCC的由来
我们知道:标准的数据库事务是要具备ACID特性的。但是对于【I】隔离性而言,可以根据不同的场景,权衡使用不同的隔离级别。在MySQL中实现了SQL标准中的四大隔离级别,同时对应了可能会出现的不同问题:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED(读未提交) | 可能 | 可能 | 可能 |
| READ COMMITTED(读已提交) | 不可能 | 可能 | 可能 |
| REPEATABLE READ(可重复读) | 不可能 | 不可能 | *可能 |
| SERIALIZABLE(可串行化) | 不可能 | 不可能 | 不可能 |
其中,需要特别注意的一点是:也是与SQL标准规定不一样的一个地方,MySQL中RR可重复读的隔离级别下,是基本上不会出现幻读问题(这个地方会出现一些特殊的场景,后面会介绍)。
访问MySQL数据一般就是增删改查操作,对应的是insert、delete、update和select语句。
对于insert、delete、update这三种类型的语句而言,需要先定位到最新的数据;对于select语句,也有select … lock in share mode(MySQL8.0中增加了SELECT … FOR SHARE)/select… for update的操作,同样需要读取最新的数据,同时必须堵塞其他并发事务修改当前记录,所以需要进行加锁。 这些操作在MySQL中统一被称为――锁定读(Locking Reads),又称为当前读。
而对于普通的select语句,MySQL则根据不同的隔离级别,进行不同的处理:
- READ UNCOMMITTED(读未提交):读取最新的记录
- READ COMMITTED(读已提交):读取最新提交事务的记录
- REPEATABLE READ(可重复读):读取当前事务在开始前已提交的记录或者被自己事务修改的记录
- SERIALIZABLE(可串行化):读取最新的记录,同时也加上读锁,事务提交前不允许被其他事务修改,也就是select … lock in share mode
可以看到,对于READ COMMITTED(读已提交)和 REPEATABLE READ(可重复读)这两种隔离级别来说,普通的select是不需要加锁的,并且受到事务发生时机的影响。可以利用事务保存的历史版本数据,控制版本访问权限,这种方案就称之为――MVCC(Multi-Version Concurrency Control),而MVCC下的select查询,被称为――非锁定读(Consistent Nonlocking Reads),又称为快照读。
生成的快照就被称之为ReadView(一致性视图)
利用MVCC提供的快照读能力,可以实现在不加锁的情况下,避免读写冲突时的堵塞问题,极大提升并发查询性能,同时也保证了事务的隔离性。这是在并发性能和数据一致性之间做的一次trade-off。
二、MVCC的实际应用
前面提到,MVCC是在RC和RR隔离级别下使用历史版本数据实现事务隔离性的,下面我们来看个具体的案例分析。
首先先创建表 t1:
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
#插入一条数据
INSERT INTO `t1` (`id`, `c`, `d`) VALUES ('5', '5', '5');
RR级别场景
事务隔离级别为RR:
SELECT @@tx_isolation
REPEATABLE-READ
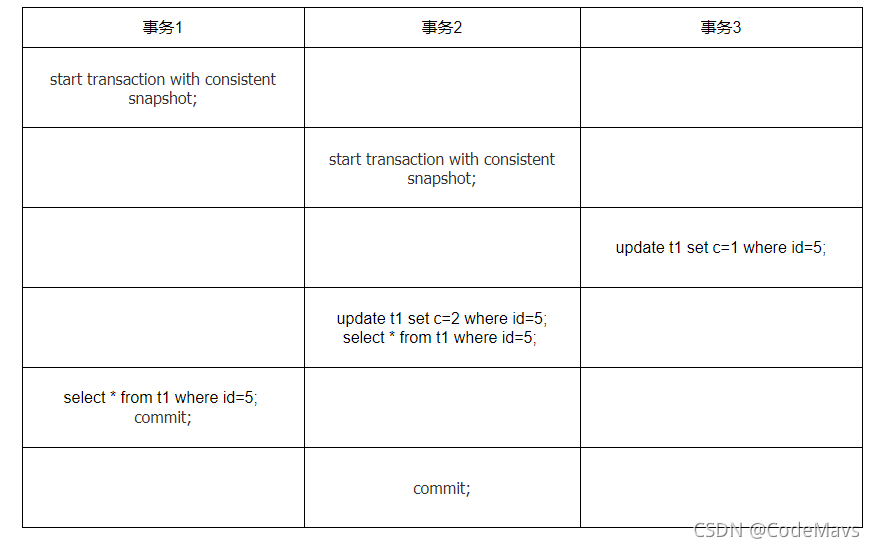
1.当事务1执行语句:start transaction with consistent snapshot;会创建一个ReadView,最后进行查询id=5的时候,仍然会读取到快照时的数据,也就是(5,5,5)这条数据
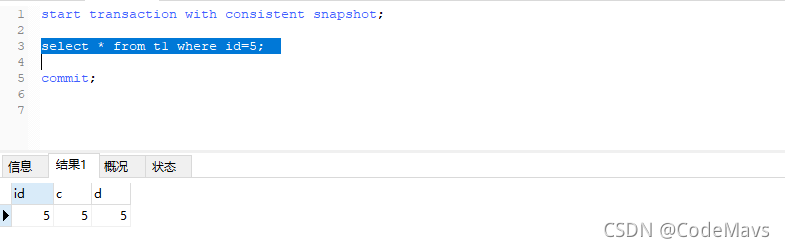
2.事务2同样使用start transaction with consistent snapshot开启了一个ReadView,但是由于事务中使用了update语句更新了这条数据,所以最后事务2查询id=5的数据时,结果是(5,2,5)
RC级别场景
事务隔离级别为RC:
set session transaction isolation level read committed;
SELECT @@tx_isolation
READ-COMMITTED
同样是对于这个案例:
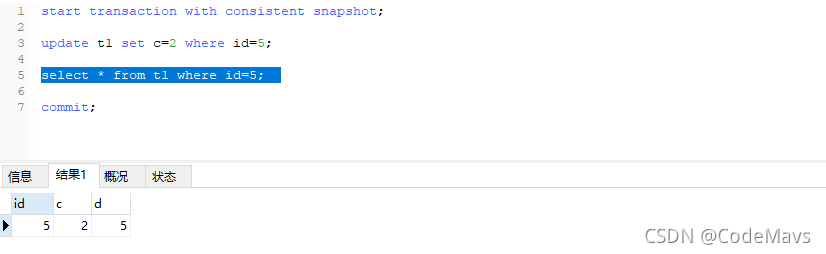
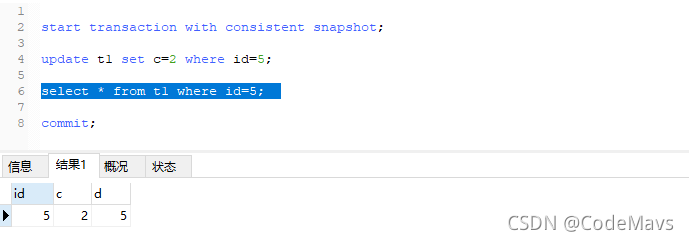
- 对于事务2,查询id=5的结果不变,还是(5,2,5)
- 对于事务1,由于隔离级别是 READ COMMITTED,可以查询到其他事务已提交的记录,也就是说ReadView是在查询语句开始时才生成的,不是事务开始前,所以查询id=5的结果也是(5,2,5)
小结一下:
- RR级别下,MVCC的一致性视图(快照)是只在事务开始(第一次查询语句)时生成;
- RC级别下,MVCC的一致性视图(快照)是在每次查询语句前时生成;
三、MVCC的实现
3.1 旧版本数据从哪里来――Undo Log
An undo log is a collection of undo log records associated with a single read-write transaction. An undo log record contains information about how to undo the latest change by a transaction to a clustered index record. If another transaction needs to see the original data as part of a consistent read operation, the unmodified data is retrieved from undo log records.
undo log是与单个读写事务相关联的撤消日志记录的集合。undo log记录可以明确如何撤消事务对聚集索引记录的最新更改。如果另一个事务需要通过一致性读取操作查看原始数据,可以从undo log记录中查询未修改前的数据。
也就是说,undo log是为了记录如何回滚事务而生成的。数据每进行一次增删改,就会对应一条或多条undo log。 InnoDB中使用不同的undo log类型对insert、delete和update进行区分。
3.1.1 插入操作对应的undo log
TRX_UNDO_INSERT_REC:是插入操作对应的undo log类型,因为插入操作对应的撤销逻辑是删除,所以只需要把这条记录的主键id记录下来。
3.1.2 删除操作对应的undo log
由于MVCC的存在,被删除的记录并不会被真正的删除, 而是进行delete mark操作――只是将行记录上的删除标记位delete_flag改为1,后面在再通过purge操作把记录加入垃圾链表中,待后续进行空间复用。生成删除语句对应的undo log类型为TRX_UNDO_DELETE_MARK_REC,相比于TRX_UNDO_INSERT_REC,TRX_UNDO_DELETE_MARK_REC不仅保存了主键id,也保存了相关的索引列信息,用来对删除过程中一些中间状态的清理。
3.1.3 更新操作对应的undo log
更新操作对应的undo log除了会记录主键和索引列信息之外,还会把被更新前各个字段的信息记录下来,还有指向旧记录的DB_ROLL_PTR和DB_TRX_ID。
- 不更新主键,且被更新的列存储空间不发生变化:直接在原有行记录上面更新。
- 不更新主键,且被更新的列存储空间发生了变化:先删除旧记录(不是delete mark,而是直接删除),再插入新记录。
- 更新主键:旧记录进行delete mark,再插入新记录。
- 过程中更新了二级索引:对旧的二级索引进行delete mark,插入新的二级索引记录。
通过以上3种不同操作对应的undo log,可以得到事务开始前的的历史记录。那么这些记录是如何关联起来的呢?
3.2 多版本数据如何关联――行记录隐藏字段和版本链
对于InnoDB引擎的表,聚簇索引记录中包含了两个必要的隐藏字段:
- DB_TRX_ID:一个事务每次对某条聚簇索引记录进行改动(插入、更新或删除)时,会把该事务id赋值给该字段
- DB_ROLL_PTR:每次对某条聚簇索引记录进行改动时,会把旧版本写入undo日志中,DB_ROLL_PTR就是指向这条记录上一个版本的指针。
还是对于表 t1:
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
1.插入一条数据
INSERT INTO `t1` (`id`, `c`, `d`) VALUES ('5', '5', '5');
此时版本只有一个:

2.执行了3次变更sql后:
update t1 set c=4 where id=5;
update t1 set c=3 where id=5;
update t1 set c=3 where id=5;
对应的undo版本链就变成:
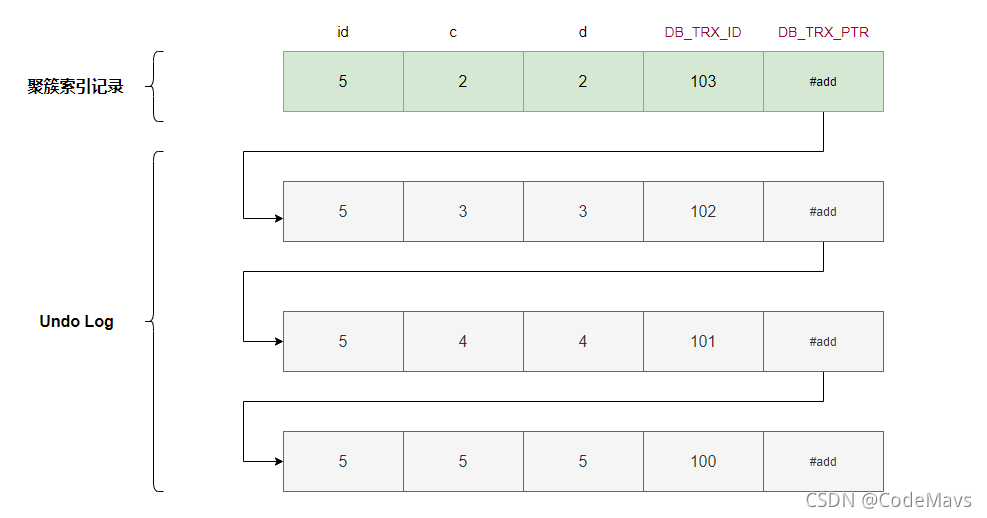
结合前面的undo log来看,每次进行记录变更的时候,都会把旧值放到一条undo log里面,同时利用DB_ROLL_PTR把多个版本的undo log组成一个版本链,并保持每个版本对应的事务id。
那么如何判断版本链中哪个才是当前事务可见的正确版本呢?
3.3 不同版本数据如何正确访问――Read View访问规则
3.3.1 Read View
Read View就是事务进行快照读操作的时候生成的,是一个逻辑层面的概念。
Read View主要包含以下几部分内容:
- m_ids: 表示生成Read View时,系统中正在活跃的事务id列表。
- up_limit_id:表示生成Read View时,系统中正在活跃的最小事务id,也就是m_ids中的最小值。
- low_limit_id:表示生成Read View时,系统还未分配的下一个事务 ID ,也就是目前已出现过的事务 ID 的最大值 + 1。
- creator_trx_id:生成Read View的事务id
判断逻辑如下:
- 若版本数据的DB_TRX_ID属性值和creator_trx_id相同,代表是本事务修改的记录,可以访问。
- 若版本数据的DB_TRX_ID属性值小于up_limit_id,代表是在生成Read View前就已经提交的事务,可以访问。
- 若版本数据的DB_TRX_ID属性值大于low_limit_id,代表是在生成Read View之后才开启的事务,不可以访问。
- 若版本数据的DB_TRX_ID属性值在up_limit_id和low_limit_id之间,需要再判断DB_TRX_ID是否在m_ids里面,如果在,则代表是在生成Read View时,该版本数据所在的事务还未提交,不可以访问;如果不在,则代表是在生成Read View时,该版本数据所在的事务已经提交,可以访问。
3.3.2 覆盖索引下的MVCC
由于DB_TRX_ID和DB_ROLL_PTR都是在聚簇索引记录中的,当事务中使用覆盖索引进行查询时,如何能确认正确的数据版本呢?
二级索引页上有一个PAGE_MAX_TRX_ID的属性,记录该页面变更时的最大事务id,如果PAGE_MAX_TRX_ID的值是在Read View创建前提交的,那么该页的全部索引都可见;如果不是,则需要根据二级索引的主键进行回表,进行再次判断。
小结一下:
对于一个 Read View 来说,除了自己的更新总是可见以外,有三种情况:
- 事务未提交的记录版本,不可见;
- 事务已提交的记录版本,但是是在Read View创建后提交的,不可见;
- 版本已提交,而且是在Read View创建前提交的,可见。
再结合前文提到的:
- RR级别下,MVCC的一致性视图(快照)是只在事务开始(第一次查询语句)时生成;
- RC级别下,MVCC的一致性视图(快照)是在每次查询语句前时生成;
就能找到正确的版本数据,实现RR和RC事务隔离级别的快照读机制。
四、扩展一――MVCC的多版本是否影响性能
因为MVCC是通过回溯undo log的方式,将符合访问条件的历史版本查询出来,而undo log文件是保存在磁盘中,是否会影响查询性能?
由于undo log是为了回滚未成功提交的事务和MVCC存在的,如果事务成功提交,以及当系统里最早的Read View不再访问它们的时候,就会使用purge操作进行清除,所以undo log的生存周期一般来说不会太长,但是使用时,我们仍需要避免使用长事务。
五、扩展二――RR级别能否完全避免幻读问题
回到最开始提到的:MySQL中RR可重复读的隔离级别下,是基本上不会出现幻读问题。但是是否可以完全解决幻读问题呢?
在RR可重复读级别下, InnoDB使用了MVCC避免【快照读】场景下的幻读问题,而在【当前读】场景下, 是使用gap lock间隙锁的方式避免幻读问题。但是如果同时使用了快照读和当前读会发生什么情况呢?
下面还是使用表 t1 模拟一个案例,在RR级别下开启两个事务会话:
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `codemavs`.`t1` (`id`, `c`, `d`) VALUES ('0', '0', '0');
INSERT INTO `codemavs`.`t1` (`id`, `c`, `d`) VALUES ('1', '1', '1');
INSERT INTO `codemavs`.`t1` (`id`, `c`, `d`) VALUES ('5', '5', '5');

1、事务1【1.1】开启了快照读后,查询结果是(1,1,1)和(5,5,5);
2、事务2把了id=0的记录中c的字段更新为5;
3、事务1【1.2】中使用了select…for update的当前读,此时返回的结果不再是(1,1,1)和(5,5,5),而是 (0,5,0),(1,1,1)和(5,5,5),中间多出了(0,5,0)这条记录。
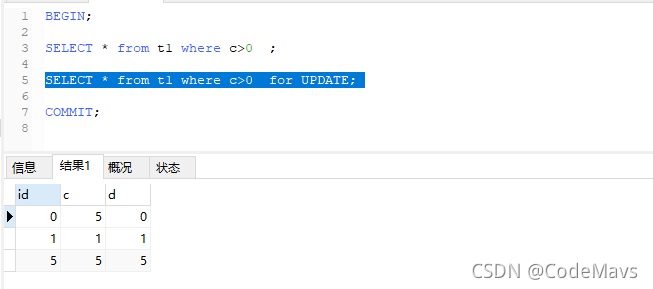
这是一种特殊的场景:在同一个事务中,先使用了快照读, 再使用当前读,两次的结果可能出现不一致。
可知RR级别下先使用非锁定读,再使用锁定读时,可能会出现幻读问题,但这在MySQL中是允许出现的。
总结
MVCC是RC和RR隔离级别下利用【快照读】提升了读写并发的整体性能,主要通过Undo Log、版本链和Read View访问规则来实现。