З°СФ
ұКХЯФЪҙУMongoDB 2өД°жұҫЙэј¶өҪMongoDB4өДКұәт,·ўПЦЗэ¶ҜAPIРЮёДәЬҙу,ЛдИ»ИФИ»ұЈБфБЛҫЙөДAPIҝЙТФК№УГ,ө«КЗЗэ¶ҜІ»ЦӘөАКІГҙКұәтҫН»бЙҫіэХвР©ҫЙөДAPI,ЛщТФК№УГБЛРВөДAPI,ЖдЦРТ»ёцЦШТӘөДҝУКЗјЖЛгdocumentөДcount,ФӯАҙКЗDBCollectionөДcount()·Ҫ·Ё,ПЦФЪAPIұдёьОӘMongoCollectionТСҫӯ·ПЖъБЛ,ұКХЯПлөұИ»өДК№УГБЛMongoCollectionөДcountDocuments,ХвАпҫНБфПВБЛРФДЬТю»јЎЈКВКөТІКЗ:MongoDBЗэ¶ҜҙУ3.xЙэј¶өҪ4.x,әЬ¶а·ПЖъөДAPIТСҫӯЙҫіэБЛЎЈ
1. MongoDB Жф¶Ҝ
ұКХЯұҫөШ»·ҫіКЗmac»·ҫі,ЖдЛы»·ҫіLinuxН¬Ан,ХвАпҙоҪЁТ»ёцөҘ»ъMongoDB,І»ҙоҪЁёұұҫјҜ»тХЯ·ЦЖ¬јҜИә,MongoDB№ЩНшПВФШЙзЗш°ж
И»әуК№УГГ»УРИЁПЮөД·ҪКҪЖф¶Ҝ,ЦұҪУФЛРРmongod,win»·ҫіК№УГbat»тХЯcmdҪЕұҫЖф¶Ҝ
./mongod --dbpath=../data --logpath=../logs/mongod.log
ЦұҪУФЪұҫ»ъөЗВј

К№УГuse admin,ЗР»»adminөДОДөөјҜ
db.createUser({user:"ХЛәЕ",pwd:"ГЬВл",roles:[{"role":"userAdmin","db":"admin"},{"role":"root","db":"admin"},{"role":"userAdminAnyDatabase","db":"admin"}]})
И»әуК№УГ--authЖф¶Ҝ
./mongod --dbpath=../data --logpath=../logs/mongod.log --auth?&
ЦБҙЛMongoDBөҘҪЪөгЖф¶ҜOK,ҝЙТФК№УГБЛЎЈ
2. demo№№ҪЁ
№№ҪЁspring bootУҰУГ,ТААөmongodbөДstarter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.5.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
<version>2.5.5</version>
</dependency>№№ҪЁДЈДвКэҫЭУлcount APIөДК№УГdemo,ХвАпЧўТвMongoDBөДЧФФціӨ_idЦ»ДЬК¶ұрObjectId,ObjectIdКЗТ»ёц12ЧЦҪЪөДBSONАаРНЧЦ·ыҙ®,°ьә¬БЛUNIXКұјдҙБ,»ъЖчК¶ұрВл,ҪшіМәЕ,јЖКэЦөРЕПўЎЈІ»ДЬК¶ұрLong IntegerАаРНөДАаРНКэҫЭЎЈ
@Repository
public class MongoDBRepository {
@Autowired
private MongoOperations mongoOperations;
public long insertDemos(){
List<CountDemoEntity> list = new LinkedList<>();
for (int i = 0; i < 100000; i++) {
CountDemoEntity countDemoEntity = new CountDemoEntity();
countDemoEntity.setDemo("demo"+i);
countDemoEntity.setDemoName("demo-name"+i);
list.add(countDemoEntity);
if (i % 1000 == 0) {
mongoOperations.insert(list, "countDemo");
list.clear();
}
}
return 100000;
}
public long countDocuments(){
return mongoOperations.getCollection("countDemo").countDocuments();
}
public long estimatedDocumentCount(){
return mongoOperations.getCollection("countDemo").estimatedDocumentCount();
}
}
@Document(collation = "countDemo")
public class CountDemoEntity {
@Id
private ObjectId id;
private String demoName;
private String demo;
public ObjectId getId() {
return id;
}
public void setId(ObjectId id) {
this.id = id;
}
public String getDemoName() {
return demoName;
}
public void setDemoName(String demoName) {
this.demoName = demoName;
}
public String getDemo() {
return demo;
}
public void setDemo(String demo) {
this.demo = demo;
}
}
@RestController
public class MongoDBController {
@Autowired
private MongoDBRepository repository;
@RequestMapping("/insertDemos")
public String insertDemos() {
repository.insertDemos();
return "ok";
}
@RequestMapping("/countDocuments")
public long countDocuments() {
long start = System.currentTimeMillis();
long count = repository.countDocuments();
System.out.println("countDocuments = " + (System.currentTimeMillis()-start));
return count;
}
@RequestMapping("/estimatedDocumentCount")
public long estimatedDocumentCount() {
long start = System.currentTimeMillis();
long count = repository.estimatedDocumentCount();
System.out.println("estimatedDocumentCount = " + (System.currentTimeMillis()-start));
return count;
}
}К№УГinsert·Ҫ·ЁДЈДвКэҫЭ
??????http://localhost:8080/insertDemos
ұКХЯФмБЛ6138062МхКэҫЭ
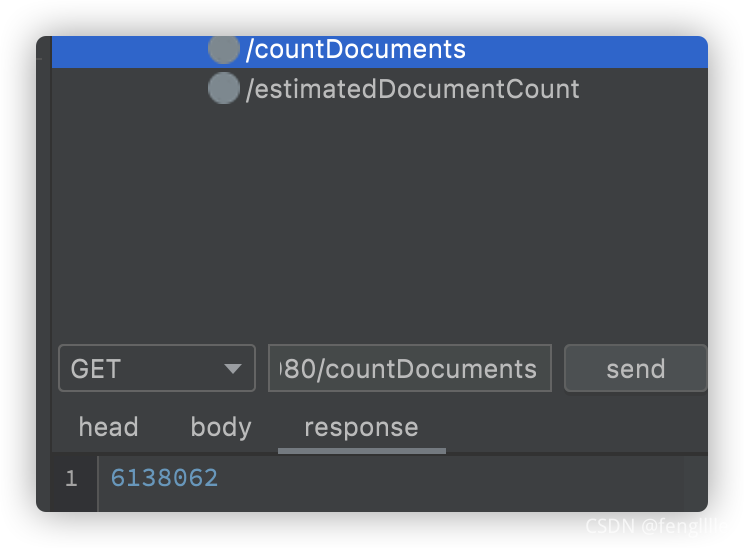
?ЦҙРРcountөДКұјд·ЦұрОӘ
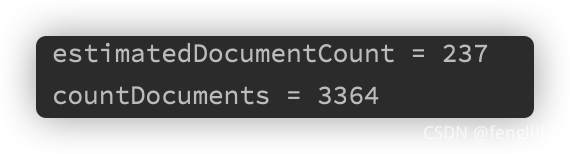
237әБГлУл3364әБГл,ІоҫаКөФЪМ«ҙуБЛ,¶шЗТЛжЧЕMongoDBөДҙжҙўОДөөөДФцјУ¶шөЭФцЎЈЛщТФҙУРФДЬөДҪЗ¶И,НЖјцК№УГ
estimatedDocumentCount
3. ОӘКІГҙІ»НЖјцК№УГcountDocuments
ХвЖдЦРөДФӯТтКЗОӘЙ¶ДШ,РиТӘІйҝҙФҙВл·ЦОц
3.1 estimatedDocumentCountәҜКэ
public long estimatedDocumentCount(final EstimatedDocumentCountOptions options) {
return executeCount(null, new BsonDocument(), fromEstimatedDocumentCountOptions(options), CountStrategy.COMMAND);
}Йжј°ІЯВФ,estimatedDocumentCountК№УГcount command·ҪКҪ,јҙ·ҙУҰФЪnosqlУпҫдөДcountәҜКэ
public enum CountStrategy {
/**
* Use the count command
*/
COMMAND,
/**
* Use the Aggregate command
*/
AGGREGATE
}ҪшТ»ІҪёъЧЩ,commandҝЙТФҝҙөҪК№УГcountЦёБо
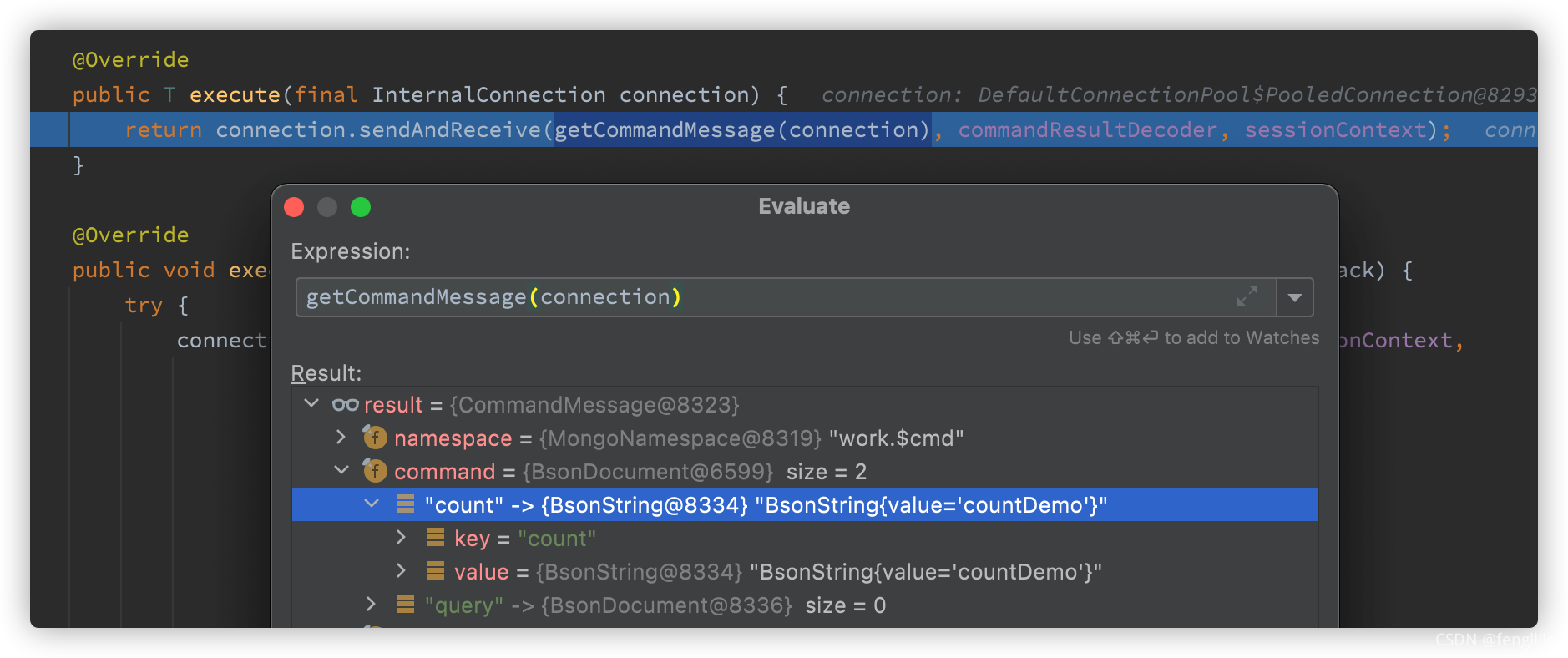
·ўЛНҪУКХПыПў,УРөгrxjavaөДО¶өА,№ЫІмХЯДЈКҪ,АаЛЖspringөДКВјю»ъЦЖ
public <T> T sendAndReceive(final CommandMessage message, final Decoder<T> decoder, final SessionContext sessionContext) {
ByteBufferBsonOutput bsonOutput = new ByteBufferBsonOutput(this);
CommandEventSender commandEventSender;
try {
//ЧйЧ°message
message.encode(bsonOutput, sessionContext);
commandEventSender = createCommandEventSender(message, bsonOutput);
//ХвАпИз№ыІ»ҝӘЖфИХЦҫ,ҫНКІГҙТІІ»»бЧц
commandEventSender.sendStartedEvent();
} catch (RuntimeException e) {
bsonOutput.close();
throw e;
}
try {
//·ўЛНГьБоПыПў
sendCommandMessage(message, bsonOutput, sessionContext);
if (message.isResponseExpected()) {
//ИЎПыПў,ДГҪб№ы
return receiveCommandMessageResponse(decoder, commandEventSender, sessionContext, 0);
} else {
commandEventSender.sendSucceededEventForOneWayCommand();
return null;
}
} catch (RuntimeException e) {
commandEventSender.sendFailedEvent(e);
throw e;
}
}?ХвАпҫНҝЙТФҙтУЎИХЦҫ,НшЙПЛөЕдЦГҙтУЎИХЦҫКЗІ»РРөД
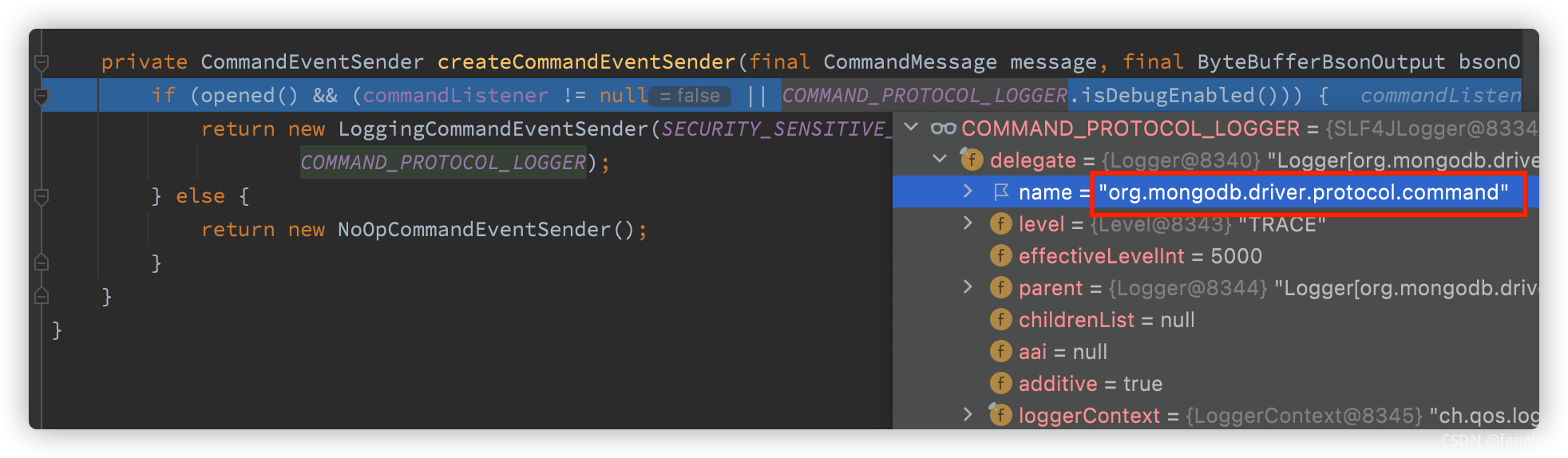
?spring-bootРиТӘЕдЦГ
logging:
level:
org.mongodb.driver.protocol.command: DEBUG
ІЕДЬҙтУЎnosqlРЕПў,КөјщЦӨГчИ·КөИзҙЛ
2021-10-07 21:22:55.728 DEBUG 5615 --- [nio-8080-exec-1] org.mongodb.driver.protocol.command ? ? ?: Sending command '{"count": "countDemo", "query": {}, "$db": "work", "lsid": {"id": {"$binary": {"base64": "mUhZ0SIkSYWkCSQNo6GdrA==", "subType": "04"}}}}' with request id 6 to database work on connection [connectionId{localValue:3, serverValue:81}] to server localhost:27017
?·ўЛНЦёБо
public void sendMessage(final List<ByteBuf> byteBuffers, final int lastRequestId) {
notNull("stream is open", stream);
if (isClosed()) {
throw new MongoSocketClosedException("Cannot write to a closed stream", getServerAddress());
}
try {
stream.write(byteBuffers);
} catch (Exception e) {
close();
throw translateWriteException(e);
}
}ҪУКХҪб№ы,УРheaderУлbuffer,»№ҝЙТФС№Лх·ҪКҪҪУКХҪб№ы,ҪөөННшВзIO
private ResponseBuffers receiveResponseBuffers(final int additionalTimeout) throws IOException {
ByteBuf messageHeaderBuffer = stream.read(MESSAGE_HEADER_LENGTH, additionalTimeout);
MessageHeader messageHeader;
try {
messageHeader = new MessageHeader(messageHeaderBuffer, description.getMaxMessageSize());
} finally {
messageHeaderBuffer.release();
}
ByteBuf messageBuffer = stream.read(messageHeader.getMessageLength() - MESSAGE_HEADER_LENGTH, additionalTimeout);
if (messageHeader.getOpCode() == OP_COMPRESSED.getValue()) {
CompressedHeader compressedHeader = new CompressedHeader(messageBuffer, messageHeader);
Compressor compressor = getCompressor(compressedHeader);
ByteBuf buffer = getBuffer(compressedHeader.getUncompressedSize());
compressor.uncompress(messageBuffer, buffer);
buffer.flip();
return new ResponseBuffers(new ReplyHeader(buffer, compressedHeader), buffer);
} else {
return new ResponseBuffers(new ReplyHeader(messageBuffer, messageHeader), messageBuffer);
}
}3.2?countDocuments·Ҫ·Ё
public long countDocuments(final Bson filter, final CountOptions options) {
return executeCount(null, filter, options, CountStrategy.AGGREGATE);
}К№УГaggregateөД·ҪКҪ,НЁ№эУОұкөД·ҪКҪ
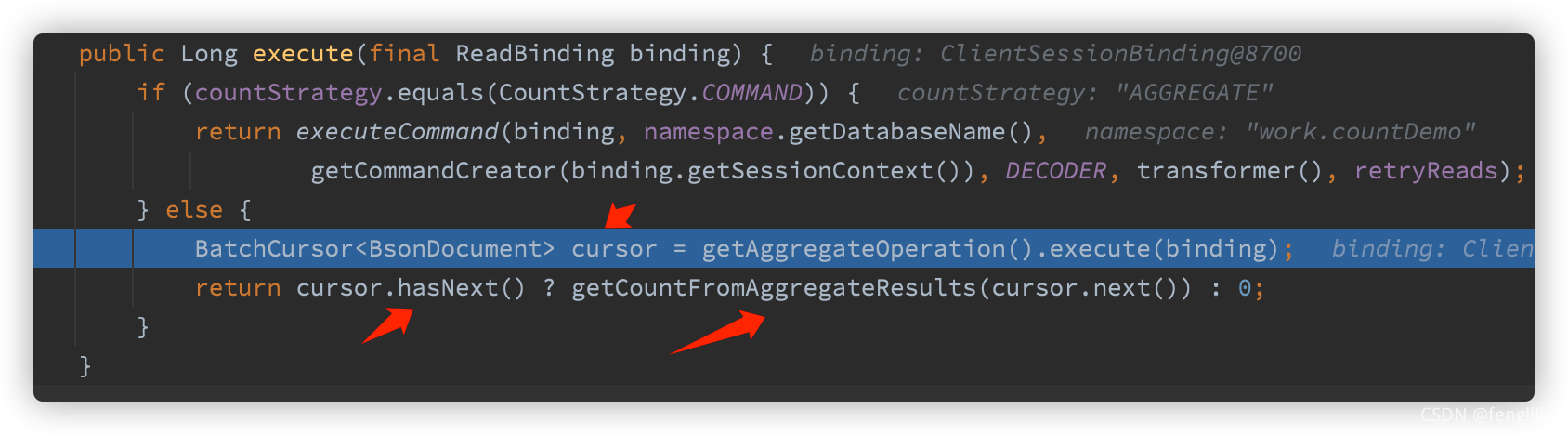
?ДЗГҙОТГЗҝҙҝҙnosqlөДГьБоКЗҙҙҪЁөДЙ¶
BsonDocument getCommand(final SessionContext sessionContext) {
BsonDocument commandDocument = new BsonDocument("aggregate", aggregateTarget.create());
appendReadConcernToCommand(sessionContext, commandDocument);
commandDocument.put("pipeline", pipelineCreator.create());
if (maxTimeMS > 0) {
commandDocument.put("maxTimeMS", maxTimeMS > Integer.MAX_VALUE
? new BsonInt64(maxTimeMS) : new BsonInt32((int) maxTimeMS));
}
BsonDocument cursor = new BsonDocument();
if (batchSize != null) {
cursor.put("batchSize", new BsonInt32(batchSize));
}
commandDocument.put(CURSOR, cursor);
if (allowDiskUse != null) {
commandDocument.put("allowDiskUse", BsonBoolean.valueOf(allowDiskUse));
}
if (collation != null) {
commandDocument.put("collation", collation.asDocument());
}
if (comment != null) {
commandDocument.put("comment", new BsonString(comment));
}
if (hint != null) {
commandDocument.put("hint", hint);
}
return commandDocument;
}ЦұҪУІйҝҙ,😖,НЁ№э$sumөД·ҪКҪ,И«ұнЙЁГиАЫјУ,ДС№ЦР§ВКөНПВ,ХвЦЦ·ҪКҪИз№ыКЗУРҫ«И·Мхјю»№әГ,ө«КЗИ«ІҝјҜәПЦҙРРКЗІ»РРөДЎЈ
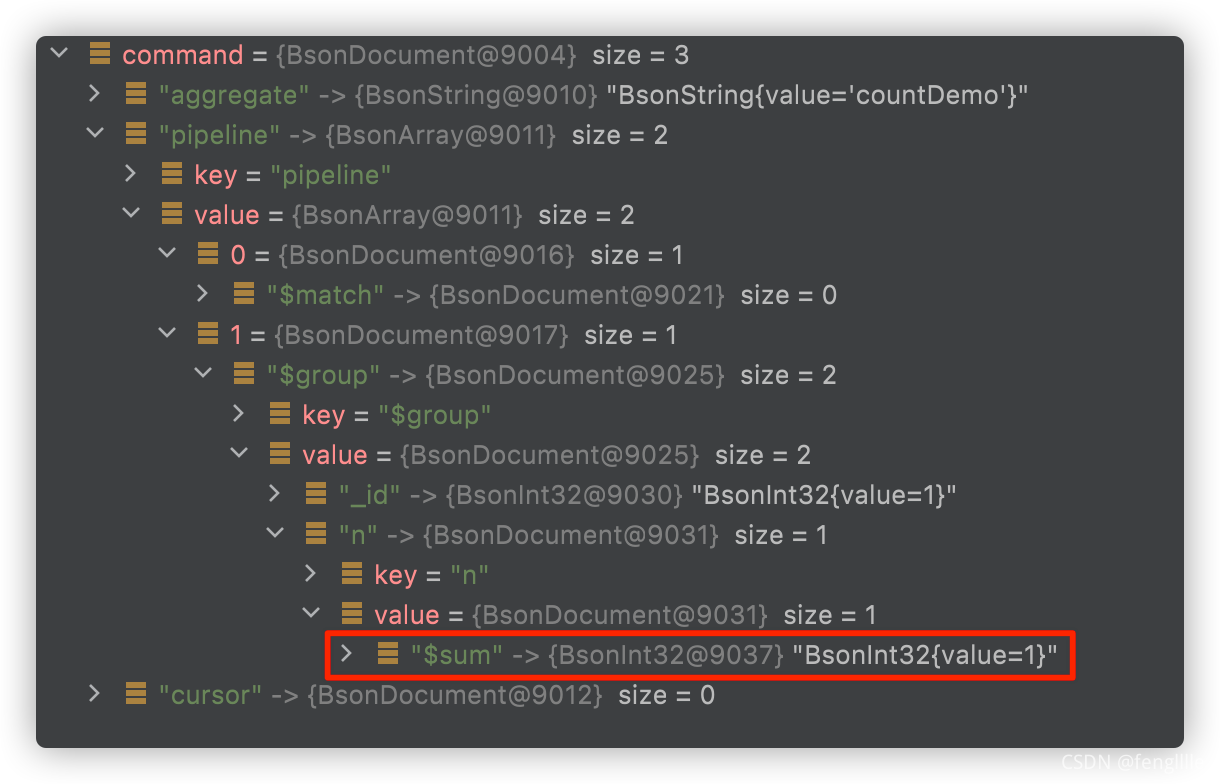
әуГжөДВЯјӯІОҝј3.1ЙПГжөД·ҪКҪ,Ц»І»№эКЗҪУКХУОұк,¶шЗТҪУКХҪб№ыКЗЧиИыөД,ЦұөҪДГөҪҪб№ы
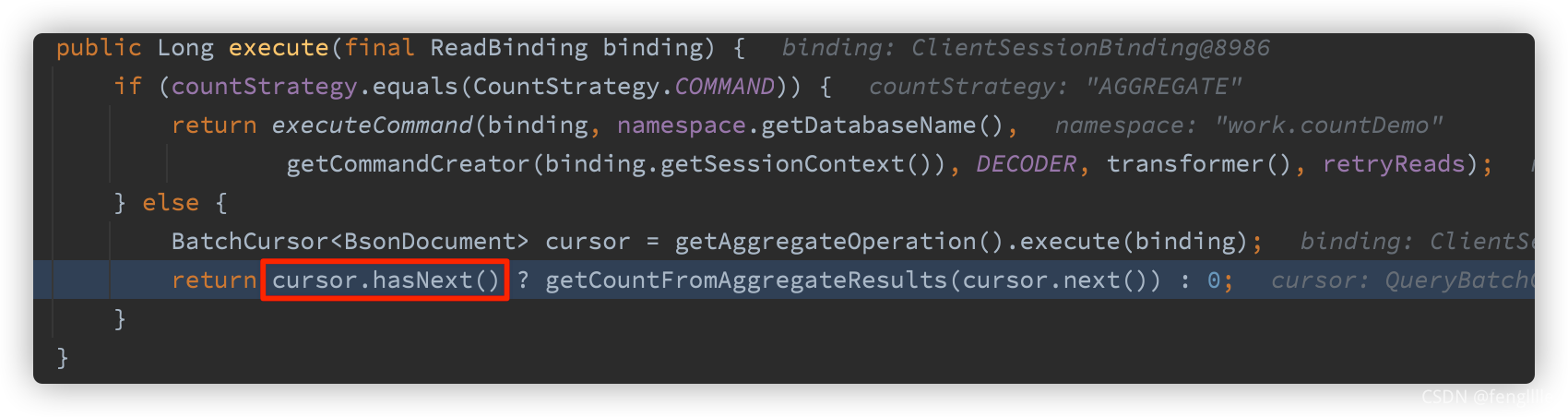
ёъЧЩҝҙҝҙ
public boolean hasNext() {
if (closed) {
throw new IllegalStateException("Cursor has been closed");
}
if (nextBatch != null) {
return true;
}
if (limitReached()) {
return false;
}
while (serverCursor != null) {
getMore();
if (closed) {
throw new IllegalStateException("Cursor has been closed");
}
if (nextBatch != null) {
return true;
}
}
return false;
}№ШјьФЪgetMore
private void getMore() {
Connection connection = connectionSource.getConnection();
try {
//3.2ј°ТФЙП°жұҫ,ҝҙАҙ3.2°жұҫёД¶ҜәЬҙу
if (serverIsAtLeastVersionThreeDotTwo(connection.getDescription())) {
try {
initFromCommandResult(connection.command(namespace.getDatabaseName(),
asGetMoreCommandDocument(),
NO_OP_FIELD_NAME_VALIDATOR,
ReadPreference.primary(),
CommandResultDocumentCodec.create(decoder, "nextBatch"),
connectionSource.getSessionContext()));
} catch (MongoCommandException e) {
throw translateCommandException(e, serverCursor);
}
} else {
QueryResult<T> getMore = connection.getMore(namespace, serverCursor.getId(),
getNumberToReturn(limit, batchSize, count), decoder);
initFromQueryResult(getMore);
}
if (limitReached()) {
killCursor(connection);
}
} finally {
connection.release();
releaseConnectionSourceIfNoServerCursor();
}
}?ЦҙРРҪб№ы

Н¬АнИХЦҫТІЛөГчОКМв
2021-10-07 21:47:20.363 DEBUG 5615 --- [nio-8080-exec-8] org.mongodb.driver.protocol.command ? ? ?: Sending command '{"aggregate": "countDemo", "pipeline": [{"$match": {}}, {"$group": {"_id": 1, "n": {"$sum": 1}}}], "cursor": {}, "$db": "work", "lsid": {"id": {"$binary": {"base64": "mUhZ0SIkSYWkCSQNo6GdrA==", "subType": "04"}}}}' with request id 29 to database work on connection [connectionId{localValue:3, serverValue:81}] to server localhost:27017
ЧЬҪб
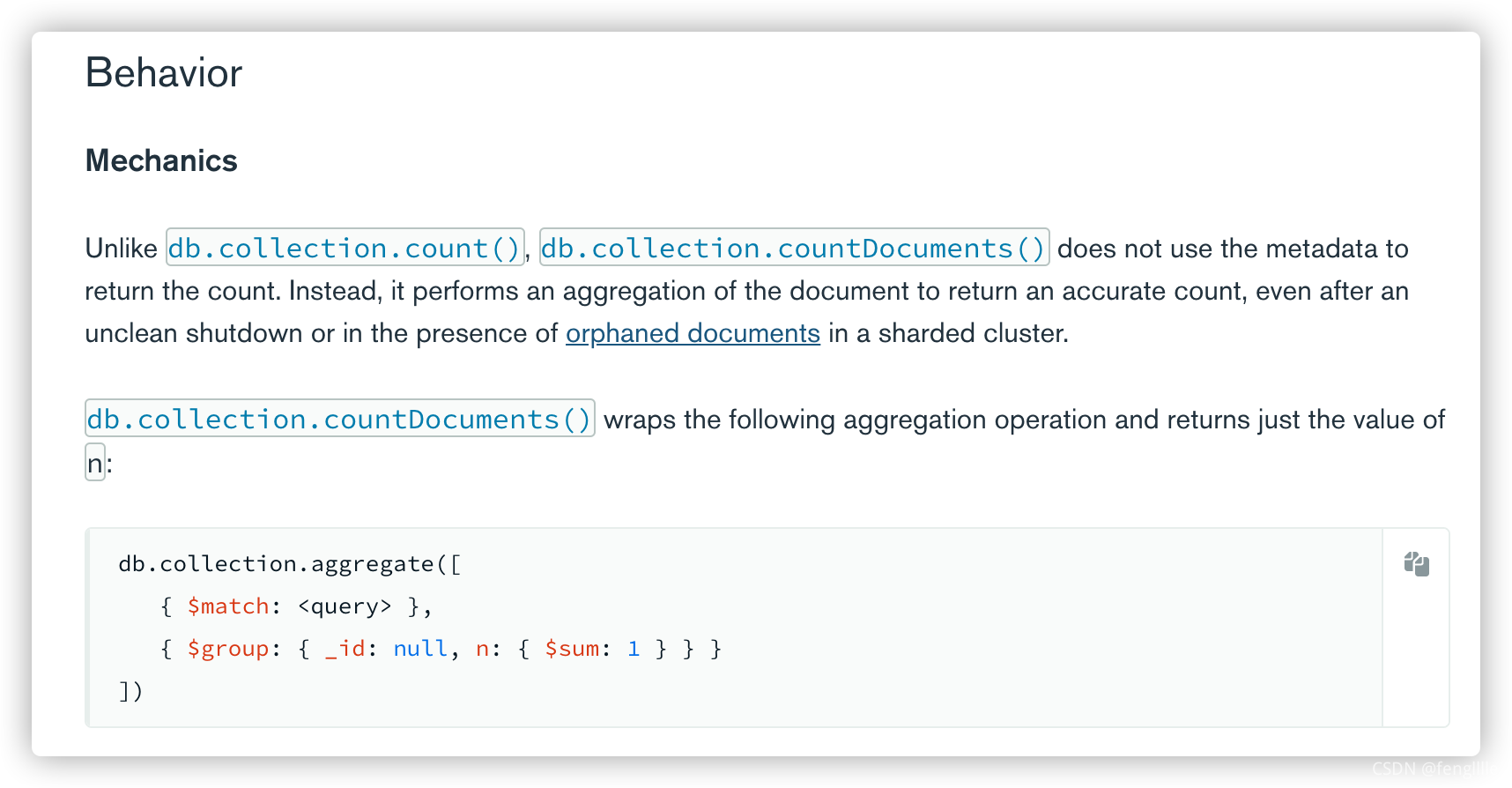
ФҙВл·ЦОцәу,·ўПЦcountDocumentsК№УГsumЗуәНөД·ҪКҪјЖКэөД,ККәПФЪУРҫ«И·МхјюөДЗйҝцПВК№УГ,countЦёБоІЕәПККјҜәПХыМејЖКэЎЈ№Щ·ҪОДөөТІУРҪйЙЬ:db.collection.countDocuments() ЎӘ MongoDB Manual
?
?