ES学习笔记―ES简介
1.ES简介
- Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储、检索数据。
- 本身扩展性很好,可扩展到上百台服务器,处理PB级别的数据。
- ES使用Java开发并使用Lucene作为其核心来实现索引和搜索的功能,但是它通过简单的RestfulAPI和javaAPI来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2. Elasticsearch的功能
- 分布式的搜索引擎
- 全文检索
- 数据分析引擎(分组聚合)
- 对海量数据进行近实时的处理
3. Elasticsearch的特点
- Elasticsearch的特点是它提供了一个极速的搜索体验。
- 这源于它的高速(speed)。相比较其它的一些大数据引擎,Elasticsearch可以实现秒级的搜索,速度非常有优势
- Elasticsearch的cluster是一种分布式的部署,极易扩展(scale )这样很容易使它处理PB级的数据库容量。
- 最重要的是Elasticsearch是它搜索的结果可以按照分数进行排序,它能提供我们最相关的搜索结果(relevance) 。
- 安装方便:没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群
- JSON:输入/输出格式为 JSON,意味着不需要定义 Schema,快捷方便
- RESTful:基本所有操作 ( 索引、查询、甚至是配置 ) 都可以通过 HTTP 接口进行
- 分布式:节点对外表现对等(每个节点都可以用来做入口) 加入节点自动负载均衡
- 多租户:可根据不同的用途分索引,可以同时操作多个索引
- 支持超大数据: 可以扩展到 PB 级的结构化和非结构化数据 海量数据的近实时处理
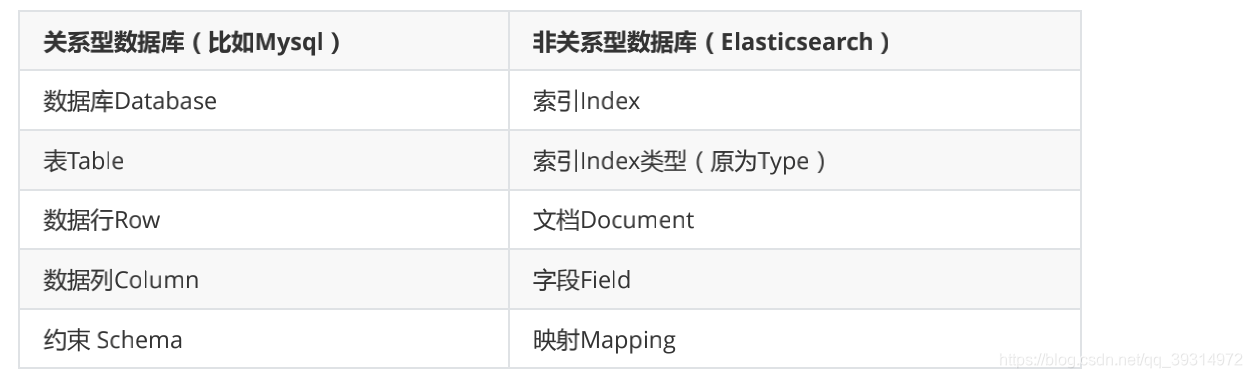
3. Elasticsearch的核心概念
- 索引:类似的数据放在一个索引,非类似的数据放不同索引, 一个索引也可以理解成一个关系型数据库。
- 类型:代表document属于index中的哪个类别(type)也有一种说法一种type就像是数据库的表。
- 映射(mapping):mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构。
- 常用数据类型:text、keyword、number、array、range、boolean、date、geo_point、ip、nested、object
4. Elasticsearch集成IK分词器
- 安装方式有以下几种:
- 使用命令:
/usr/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.3.0/elasticsearch-analysis-ik-7.3.0.zip - 在es的plugins的目录下将下载好的插件进行解压,之后将解压的内容放入到plugins创建的文件夹中就好了
- 注意: ik分词器和es的版本一定要一致,否则es无法启动
- IK分词器有两种分词模式:ik_max_word和ik_smart模式。
ik_max_word (常用):会将文本做最细粒度的拆分
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}
ik_smart:会做最粗粒度的拆分
POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}
5. Elasticsearch集成IK分词器―扩展词典使用
扩展词:就是不想让哪些词被分开,让他们分成一个词。- 由于我是在
plugins下安装的压缩包,所以我在plugins/analysis-ik/config(安装包安装方式)目录下, 新增自定义词典:vim myself_ext_dict.dic,将内容编辑进去 - 编辑
IKAnalyzer.cfg.xml文件,将我们自定义的扩展词典文件添加到IKAnalyzer.cfg.xml配置中 - 配置完之后需要重启es
6. Elasticsearch集成IK分词器―同义词典使用
- 创建
/config/analysis-ik/synonym.txt文件,输入一些同义词并存为utf-8格式。例如:如下所示china,中国
self,自己
|