Hive调优-数据倾斜优化
问题抛出:
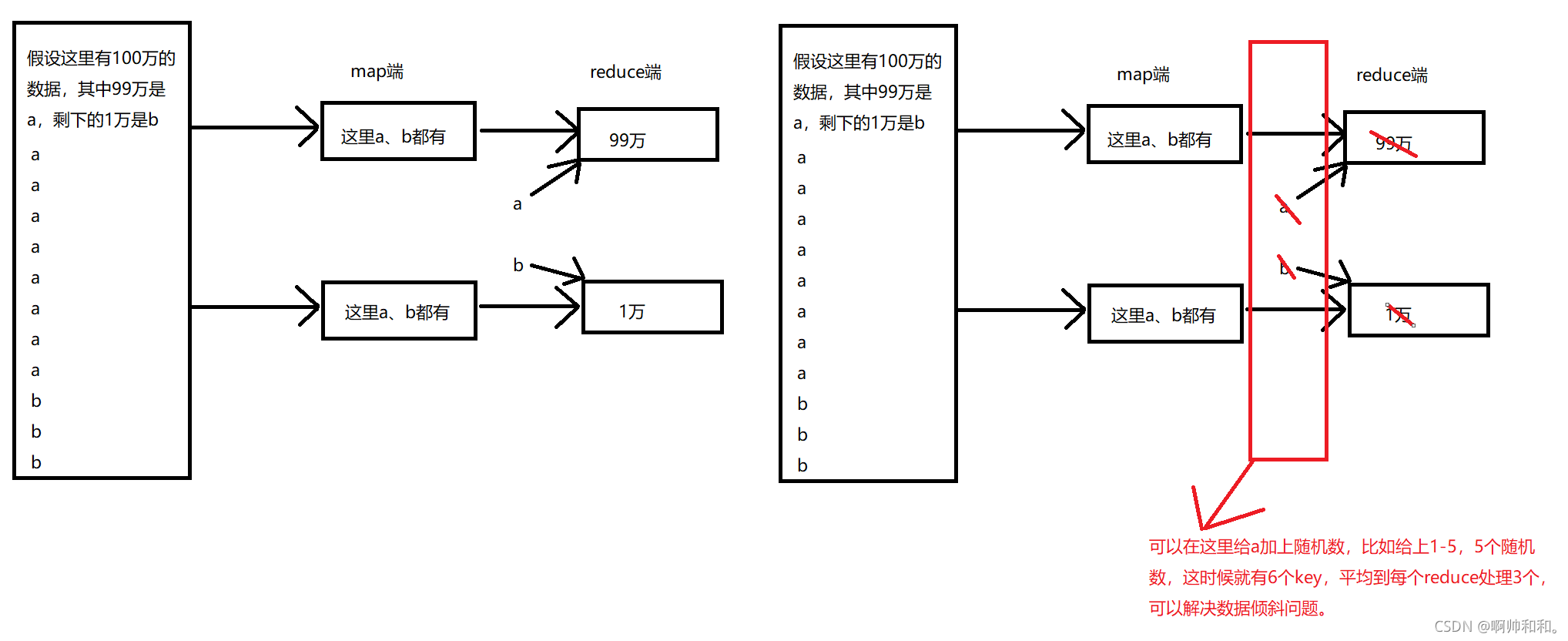
比如这里有100万的数据,99万的a,1万的b,最终到reduce阶段,相同的处理能力,一个处理99万,一个处理1万,最后处理的效率肯定是不相同的,会产生数据倾斜。
随机数怎么打:(也可以直接打在后面做字符串的拼接,然后再去掉)
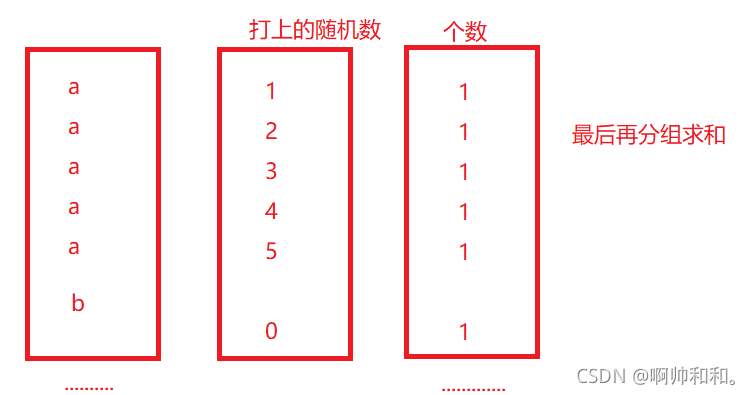
思路
1,数据倾斜解决
看下key的分布
处理集中的key
原因
1)、key分布不均匀(实际上还是重复) 比如 group by 或者 distinct的时候
2)、数据重复,join 笛卡尔积 数据膨胀
表现
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
解决方案:
1,看下业务上,数据源头能否对数据进行过滤,比如 key为 null的,业务层面进行优化。
2,找到key重复的具体值,进行拆分,hash。异步求和。
解决
数据样式:
(99万的(84401,a),和其他数据)
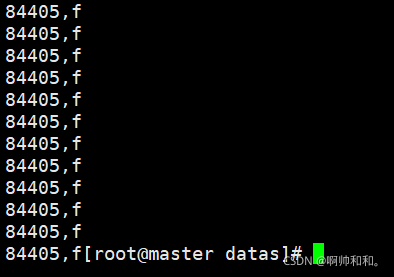
直接求结果
select key,count(*) from skew group by key;
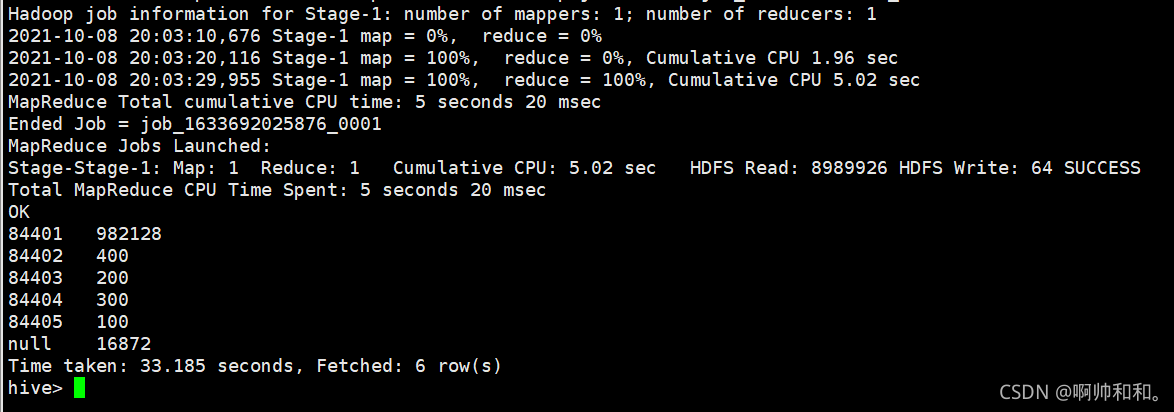
异步求和求结果
1、加随机数(只给数据比较大的加随机数,这里只给84401和null加随机数)分组聚合
2、在第一步的基础上进行分组
select key,count(*) as num,if(key=='84401' or key=='null',floor(rand()*6),0) as hashkey from skew
group by key,if(key=='84401' or key=='null',floor(rand()*6),0)
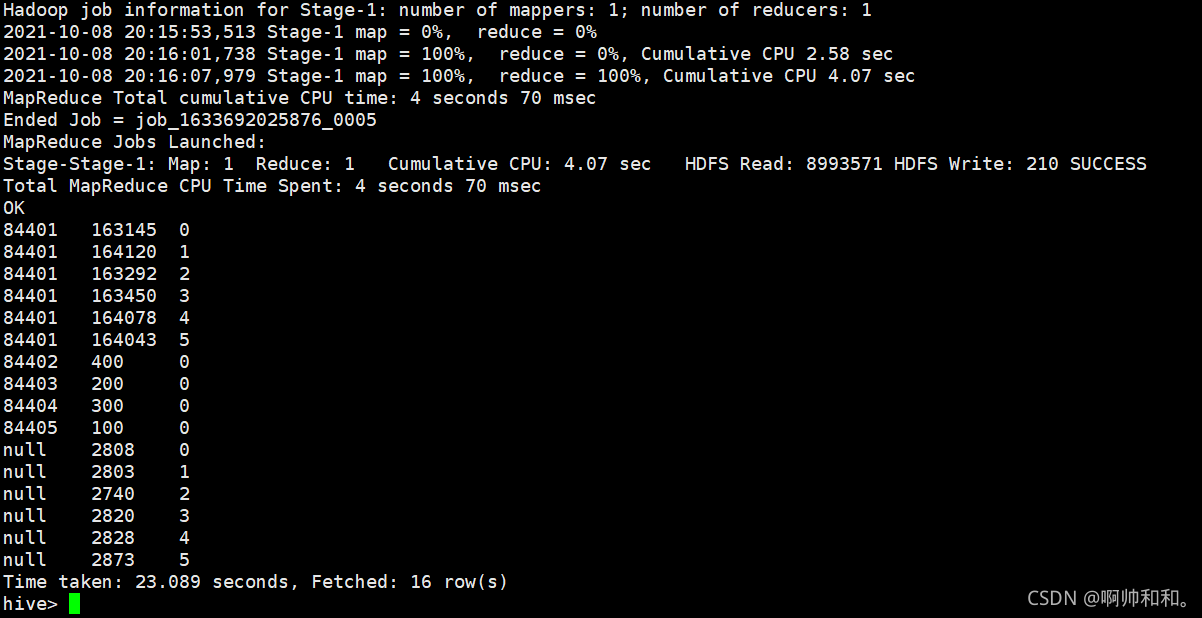
3、在上一步的基础上进行聚合
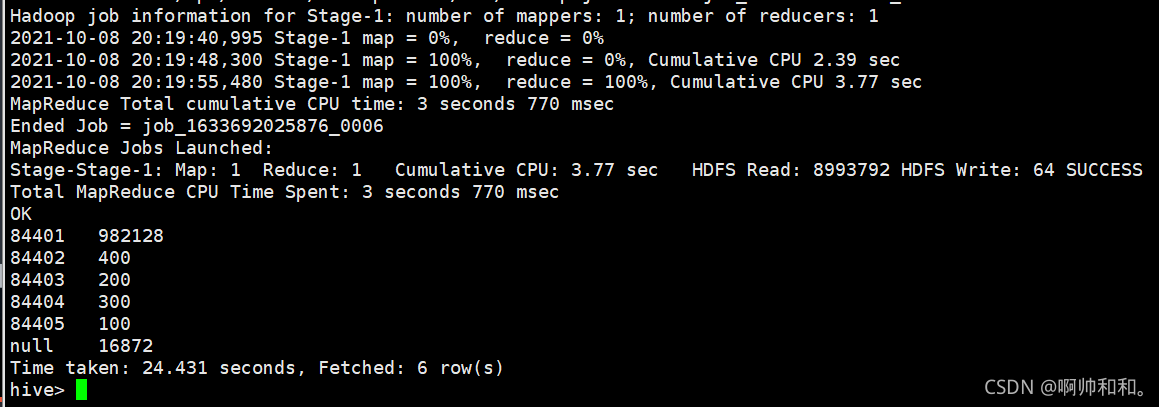
select key,sum(num) from
(
select key,count(*) as num,if(key=='84401' or key=='null',floor(rand()*6),0) as hashkey from skew
group by key,if(key=='84401' or key=='null',floor(rand()*6),0)
) as t group by key
可以看到,相比较原来,效率进行了提升
感谢阅读,我是啊帅和和,一位大数据专业大四学生,祝你快乐。