Spark2.4.8 ЙВЯэБфСПжЎРлМгЦї
вЛЁЂЙВЯэБфСП
ЭЈГЃ,ЕБДЋЕнИјSparkВйзї(Р§ШчmapЛђreduce)ЕФКЏЪ§дкдЖГЬМЏШКНкЕуЩЯжДааЪБ,ЫќЛсдкКЏЪ§жаЪЙгУЕФЫљгаБфСПЕФЕЅЖРИББОЩЯЙЄзїЁЃетаЉБфСПБЛИДжЦЕНУПЬЈЛњЦїЩЯ,дЖГЬЛњЦїЩЯБфСПЕФИќаТВЛЛсДЋВЅЛиЧ§ЖЏГЬађЁЃжЇГжПчШЮЮёЕФЭЈгУЁЂЖСаДЙВЯэБфСПНЋЪЧЕЭаЇЕФЁЃЕЋЪЧ,SparkЮЊСНжжГЃМћЕФЪЙгУФЃЪНЬсЙЉСЫСНжжгаЯоЕФЙВЯэБфСПРраЭ:ЙуВЅБфСПКЭРлМгЦїЁЃ
sparkЭЈЙ§ЙуВЅБфСПКЭРлМгЦїЪЕЯжЙВЯэБфСПЁЃ
ЖўЁЂРлМгЦї
РлМгЦїЪЧжЛФмЭЈЙ§ЙиСЊКЭНЛЛЛВйзїЬэМгЕФБфСП,вђДЫПЩвдгааЇЕиВЂаажЇГжЁЃЫќУЧПЩвдгУгкЪЕЯжМЦЪ§Цї(ШчMapReduce)ЛђЧѓКЭЁЃSparkБОЕижЇГжЪ§зжРраЭЕФРлМгЦї,ГЬађдБПЩвдЬэМгЖдаТРраЭЕФжЇГжЁЃзїЮЊгУЛЇ,ФњПЩвдДДНЈУќУћЛђЮДУќУћЕФРлМгЦїЁЃШчЯТЭМЫљЪО,вЛИіУќУћЕФРлМгЦї(дкетИіЪЕР§МЦЪ§Цїжа)НЋЯдЪОдкаоИФРлМгЦїЕФstageЕФweb UIжаЁЃSparkдкTasksБэжаЯдЪОШЮЮёаоИФЕФУПИіРлМгЦїЕФжЕЁЃ
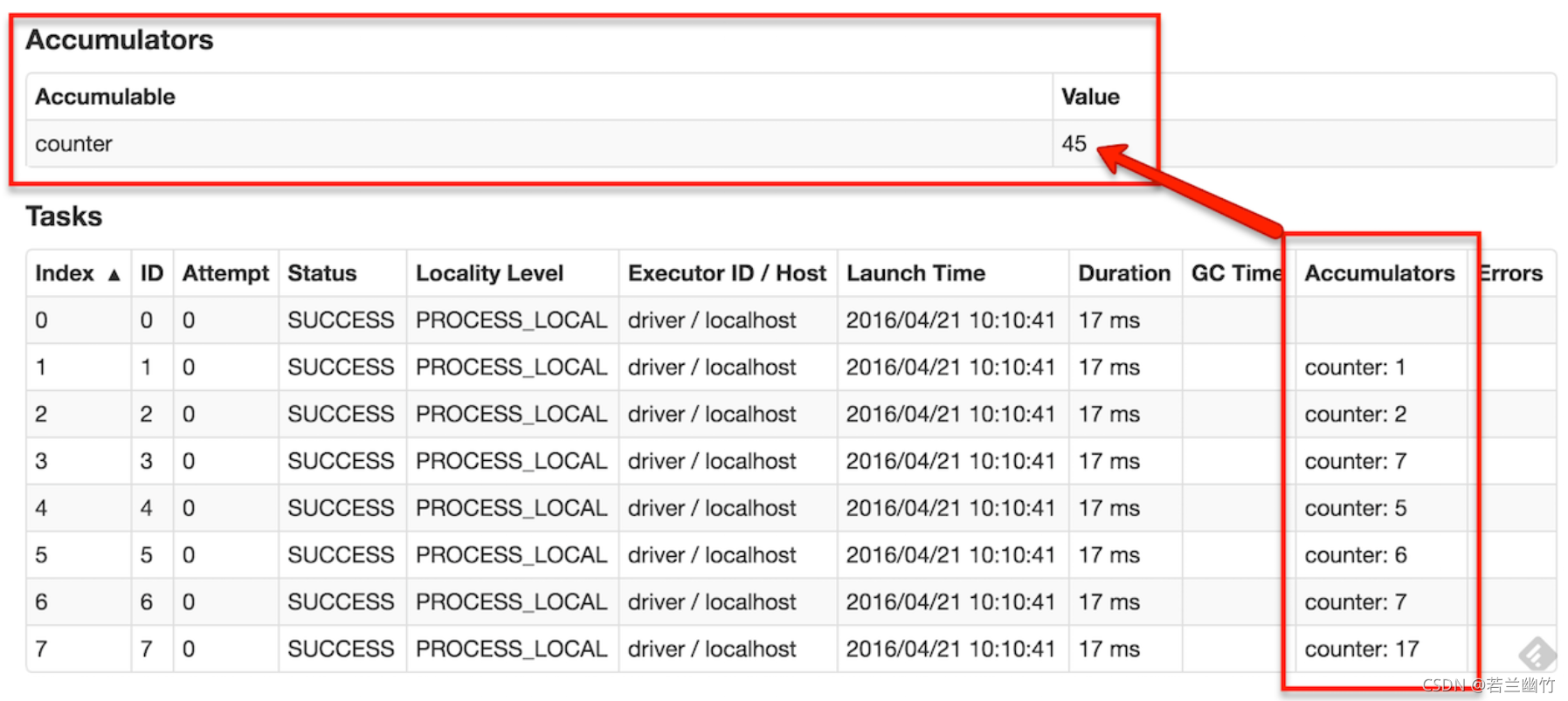
Ш§ЁЂЛљДЁбнЪО
- ашЧѓУшЪі:РћгУРлМгЦїЭГМЦГіworkerЩЯЫљгаtaskдЫааДЮЪ§
- бнЪОЛЗОГ:
Ш§ЬЈащФтЛњзщГЩЕФМЏШК - дЫааЛЗОГ:
spark-shell - ВНжш:
- ЦєЖЏspark-shell:
bin/spark-shell --master spark://niit01:7077 - БраДШчЯТДњТы:
scala> val ac1 = sc.longAccumulator("ac1") ac1: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(ac1), value: 0) scala> sc.parallelize(1 to 20).map(x => {ac1.add(1);x+1}).reduce(_+_) // дкmapжаЭГМЦГіЕБЧАЕФmap task дЫааЕФДЮЪ§ res0: Int = 230 // reduceЕФНсЙћ scala> ac1.value // ЛёШЁРлМгЦїЕФжЕ res1: Long = 20 // РлМгЦїНјааСЫ20ДЮ
- ЦєЖЏspark-shell:
ЫФЁЂЪЕбщАИР§
- ЪЕбщвЊЧѓ:РћгУРлМгЦїЭъГЩЖдЬиЖЈЬѕМўЯТЕФtaskШЮЮёдЫааДЮЪ§ЭГМЦ,ШчЭГМЦГіФГЪ§СажаЕФЦцЪ§ЯюБЛМЦЫуЕФДЮЪ§
- ДњТыШчЯТ:
scala> val ac1 = sc.longAccumulator("ac1") // ДДНЈРлМгЦї scala> ac1.value // ЛёШЁРлМгЦїГѕЪМжЕ res0: Long = 0 scala> sc.parallelize(1 to 20).map(x => { // ЭГМЦЦцЪ§БЛжДааЕФДЮЪ§ | if (x % 2 != 0) | {ac1.add(1) } | x}).reduce(_+_) scala> ac1.value // ЛёШЁРлМгЦїЕФЪ§жЕ,жЛБЛРлМгСЫ10ДЮ res2: Long = 10 - дкwebuiЩЯВщПД,ШчЯТ:
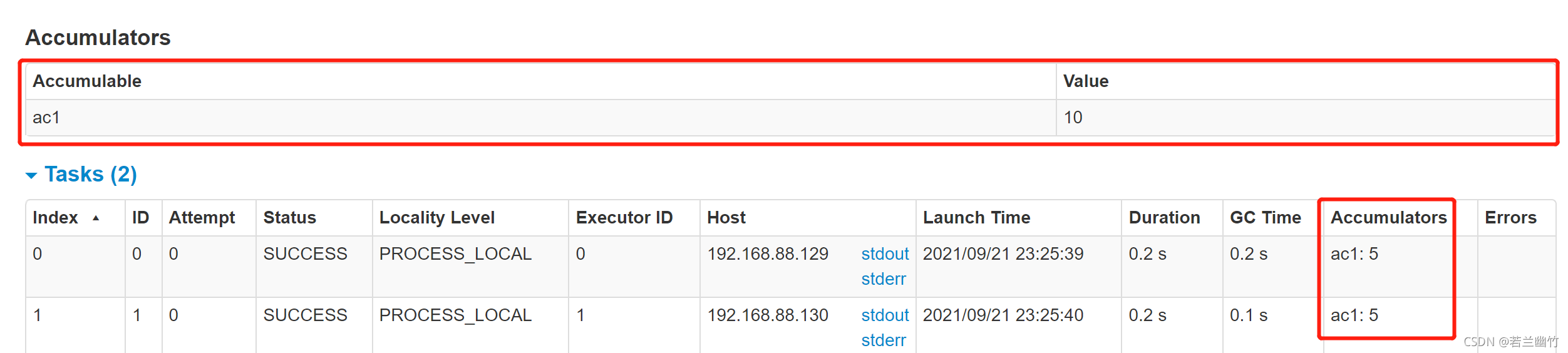
ЮхЁЂМђвЊЗжЮі
- ЩЯЪіЕФЪЕбщАИР§дкwebuiЩЯВщПДЗЂЯжСНЬЈworkerНкЕуЩЯУПЬЈНкЕуЩЯИїзджДааСЫ5ДЮЁЃЙЪ,ЖдгкШЮвтвЛИіjobЖјбд,ЦфЫљгаЕФtaskЕФзмЪ§ЪЧМЏШКжаЫљгаtaskжЎКЭЁЃСэЭт,ЖдгкРлМгЦїЖјбд,УПИіtaskЖМПЩвдЙВЯэРлМгЦї,ЕзВуРћгУЗжВМЪНЫјРДШЗБЃУПИіtaskдкЪЙгУРлМгЦїЧАЦфжЕЖМЪЧзюаТЕФ,УПИіtaskдкдРДЕФЪ§жЕЩЯНјааРлМЦЁЃЯТУцЮвУЧРДВщПДЯТУПИіtaskдЫааЪБРлМгЦїЕФЪ§жЕБфЛЏ:
АбЩЯУцЕФДњТыИФаДГЩШчЯТ:scala> val ac2 = sc.longAccumulator("ac2") // ДДНЈРлМгЦї scala> sc.parallelize(1 to 20).map(x => { | if( x % 2 != 0) | { | | | var hostname = java.net.InetAddress.getLocalHost.getHostName; | val ac2Val = ac2.value | var str = hostname + " : " + Thread.currentThread().getName + " => ac2 before add: " + ac2Val; | ac2.add(1) | val ac2Val2 = ac2.value | str = str + " => ac2 after add: " + ac2Val2 + "\r\n" | val socket = new java.net.Socket(hostname,9999); | val out = socket.getOutputStream; | out.write(str.getBytes()) | out.flush() | out.close() | socket.close() | } | x }).reduce(_+_)зЂвт:ЩЯЪіМгШыСЫSocket,ЙЪашвЊдкworkerНкЕуЩЯАДееncНјааВщПДаЇЙћ,ЙигкncЕФАДеегаСНжж,ЭЦМіЪЙгУдкЯпАВзА,жДаа: yum install -y nc - дЫааЩЯЪіДњТыКѓВщПДЦфЫћСНЬЈНкЕуПижЦЬЈЪфГі,ВщПДЧАашвЊЗжБ№дкСНЬЈДгНкЕуЩЯЦєЖЏnc,жДаа:
nc -lk 9999ЛиГЕ,аЇЙћШчЯТ:- niit02ДгНкЕу

- niit03ДгНкЕу

дкweb uiЩЯВщПД,ШчЯТЫљЪО:
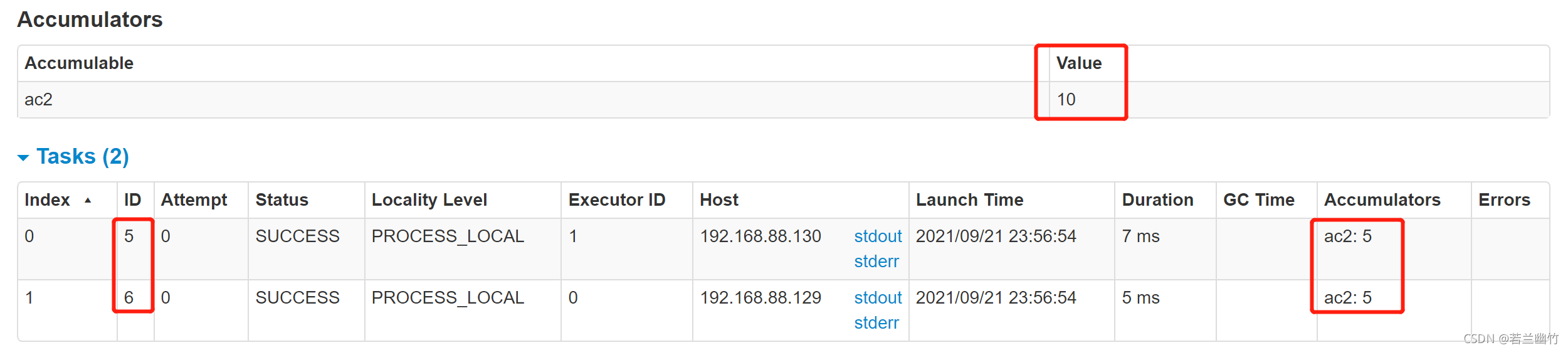
УПИіTaskЖдРлМгЦїИќаТСЫ5ДЮЁЃ
жСДЫ,ЖдРлМгЦїЕФНщЩмОЭЕНетРя,ШчЖдФугаЫљАяжњ,ФуЕФдоНЋЪЧЖдЮвзюДѓЕФЙФРј,аЛаЛ~!!
- niit02ДгНкЕу