本文目录如下:
使用 IDEA 创建一个新的 Spark ML 预测项目
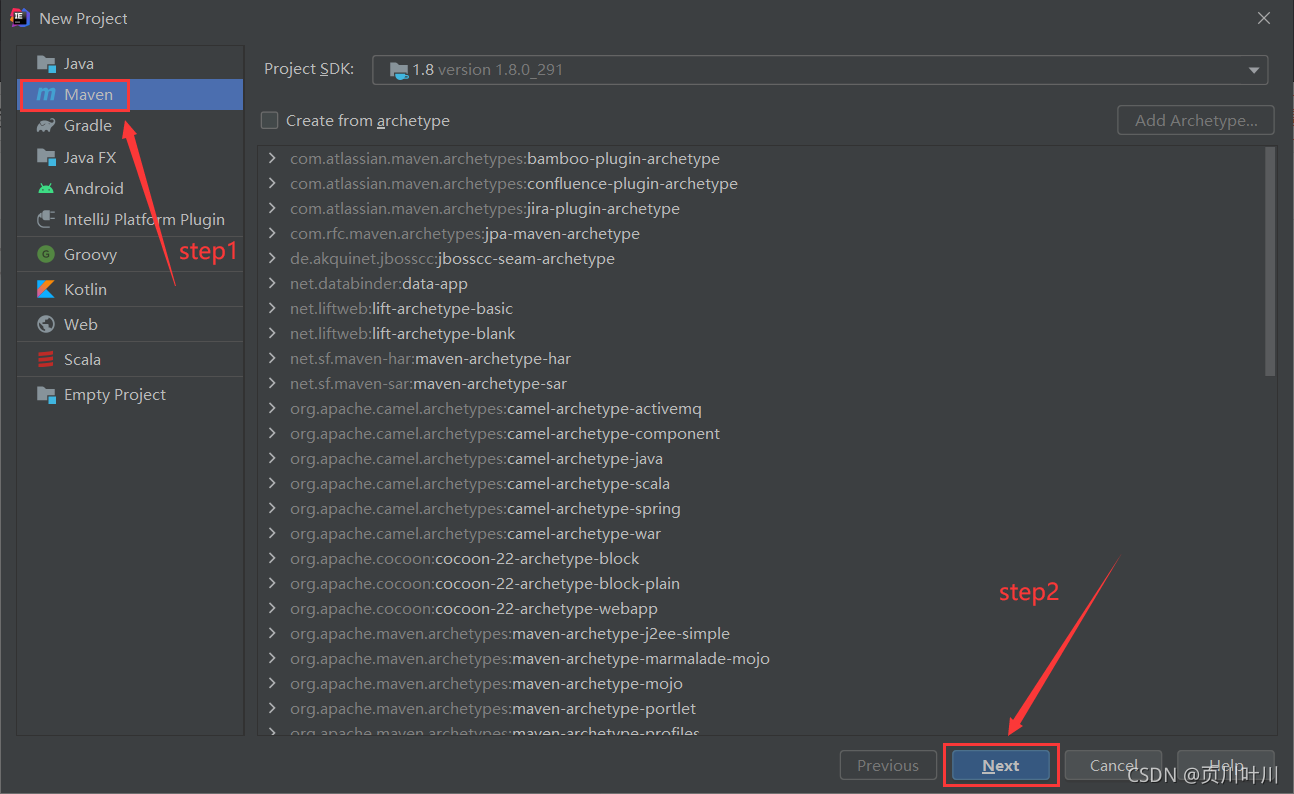
1.新建 Maven 项目
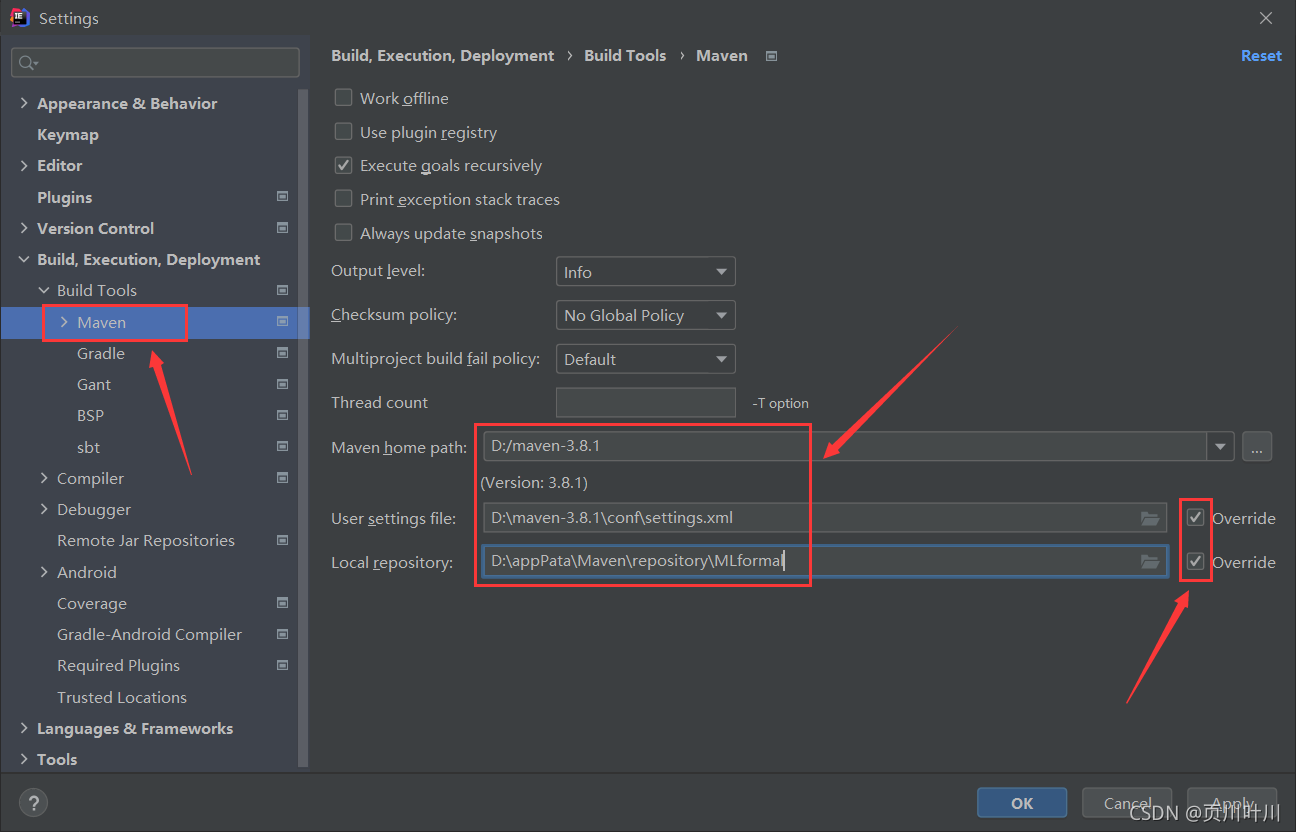
2.更具需求设置 Maven 仓库信息
3.设置 pom.xml 文件, 引入项目依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<!-- Hive 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>2.4.8</version>
<!-- <scope>compile</scope>-->
</dependency>
</dependencies>
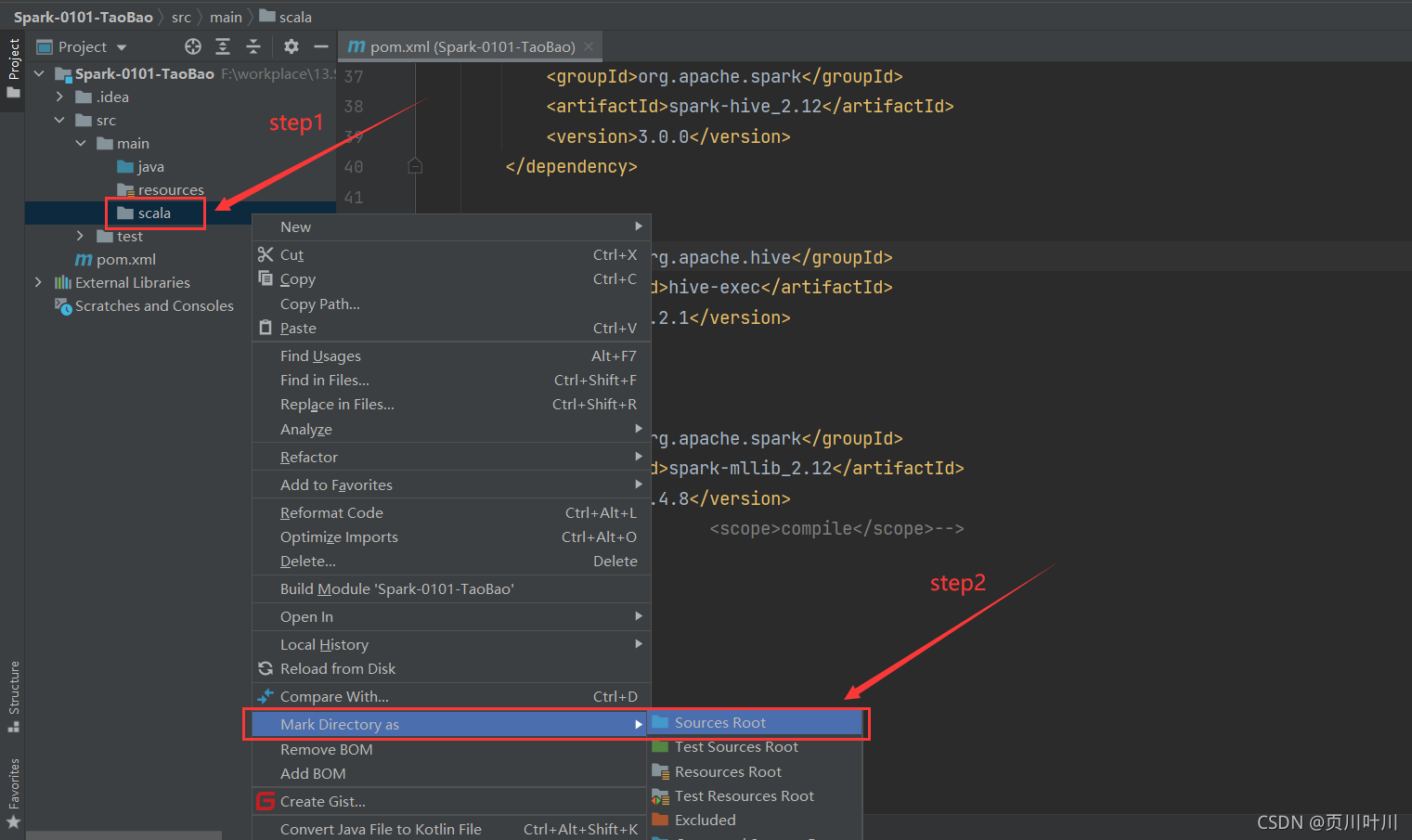
4.新建 scala 文件夹, 并将其设置为源代码文件夹
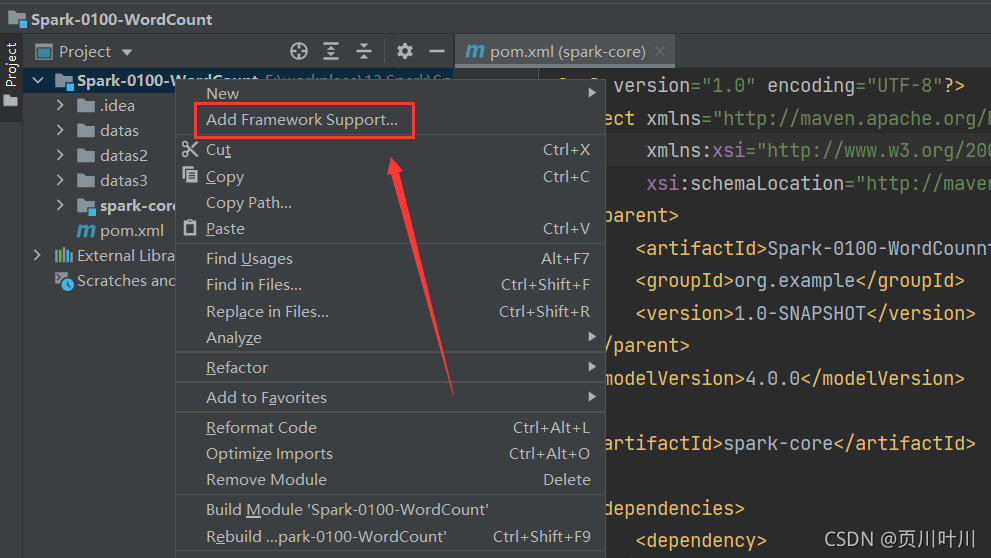
5.设置右键创建 Scala 类
只需要右键项目,选择 Add Framework Support,然后在弹出的窗口中选择 Scala 并点击 确定 即可。
6.新建 com.xqzhao.scala.spark 文件夹
7.在 resource 目录下创建 log4j.properties 文件
文件内容如下:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
8.创建 HelloSpark对象, 并执行 WordCount 案例
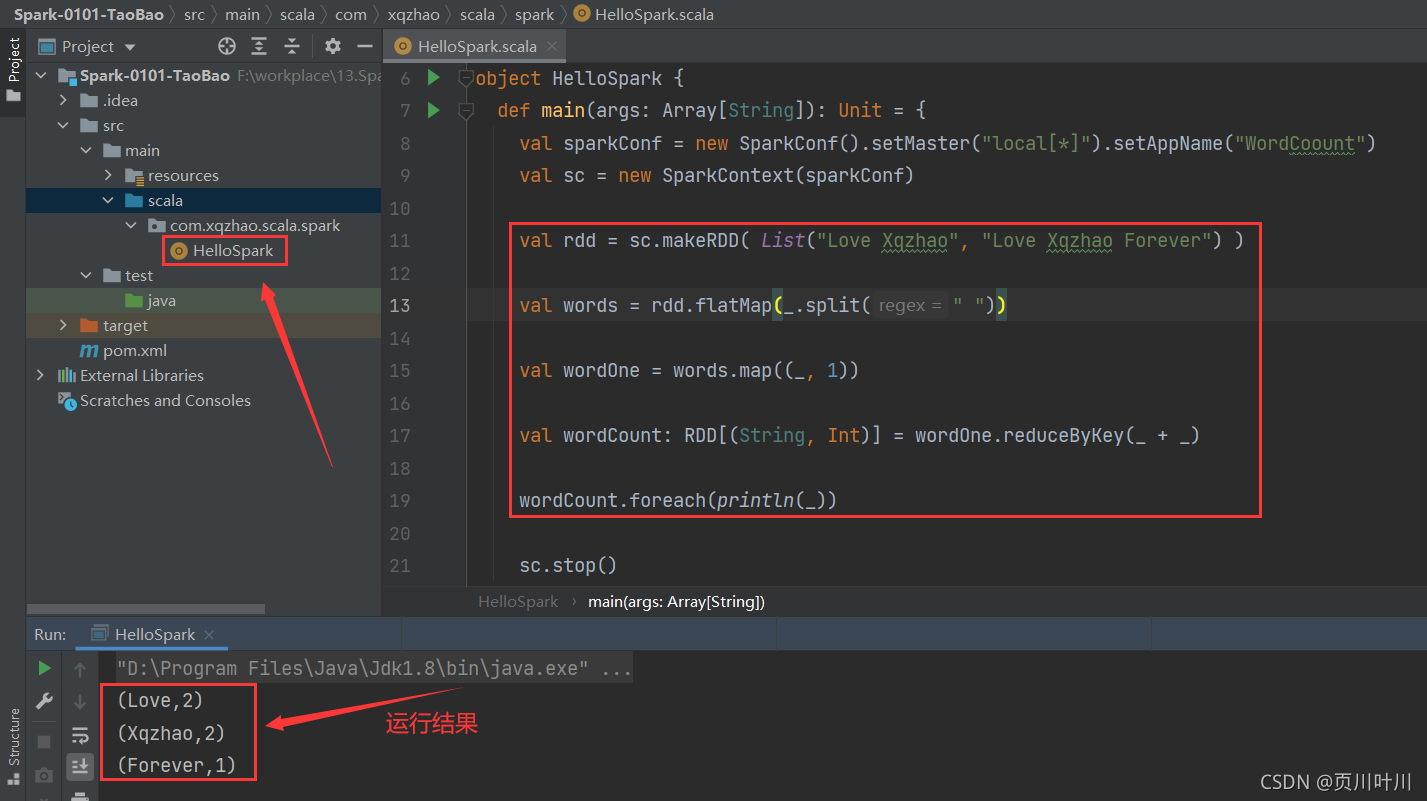
HelloSpark.scala 文件内容如下:
package com.xqzhao.scala.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object HelloSpark {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCoount")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD( List("Love Xqzhao", "Love Xqzhao Forever") )
val words = rdd.flatMap(_.split(" "))
val wordOne = words.map((_, 1))
val wordCount: RDD[(String, Int)] = wordOne.reduceByKey(_ + _)
wordCount.foreach(println(_))
sc.stop()
}
}
9.将 hive-site.xml 文件放入 resource 目录下

关于 hive-site.xml 文件的具体信息可以参考: Hive 学习笔记 。