2021SC@SDUSC
概述
索引是指按表中某些关键属性或表达式建立元组的逻辑顺序。使用索引可快速访问表中的特定元组。
例如在下面SQL语句中:
// 查询
SELECT name form student where id=120000;
如果不加索引,数据库会一行一行地进行扫描,查询的效率会大大降低,因此索引的重要性由此可知,它可以大大提高数据库查询性能。
PostgreSQL中有四种重要的索引类型:B_Tree ,Hash,GIN, GiST。本篇博客主要讲解postgreSQL是如何对不同的索引类型进行管理和操作实现其功能的。初步使用gdb调试方法设置相关函数断点,逐行运行,观察函数执行顺序来找到索引的相关管理和操作方法。
分析到的文件主要有以下几个pg_am.h,pg_am.dat,pg_index.h,genam.h,index.c,amapi.c,index.c,indexam.c,pg_index.h,ampi.h(自己对于代码的理解已经加在代码注释中)
管理索引的系统表
记录索引相关的系统表
为了管理不同的索引类型,postgreSQL定义了管理索引的系统表,首先每种索引都在pg_am系统表中用一个元组进行记录
下面为pg_am系统表。
// pg_am.dat
[
{ oid => '2', oid_symbol => 'HEAP_TABLE_AM_OID',
descr => 'heap table access method',
amname => 'heap', amhandler => 'heap_tableam_handler', amtype => 't' },
{ oid => '403', oid_symbol => 'BTREE_AM_OID',
descr => 'b-tree index access method',
amname => 'btree', amhandler => 'bthandler', amtype => 'i' },//btree相关元组,包括oid,amname等属性,以下元组均以此类推
{ oid => '405', oid_symbol => 'HASH_AM_OID',
descr => 'hash index access method',
amname => 'hash', amhandler => 'hashhandler', amtype => 'i' },
{ oid => '783', oid_symbol => 'GIST_AM_OID',
descr => 'GiST index access method',
amname => 'gist', amhandler => 'gisthandler', amtype => 'i' },
{ oid => '2742', oid_symbol => 'GIN_AM_OID',
descr => 'GIN index access method',
amname => 'gin', amhandler => 'ginhandler', amtype => 'i' },
{ oid => '4000', oid_symbol => 'SPGIST_AM_OID',
descr => 'SP-GiST index access method',
amname => 'spgist', amhandler => 'spghandler', amtype => 'i' },
{ oid => '3580', oid_symbol => 'BRIN_AM_OID',
descr => 'block range index (BRIN) access method',
amname => 'brin', amhandler => 'brinhandler', amtype => 'i' },
]
而与该元组相关的数据结构则在pg_am.h中进行定义
// pg_am.h
CATALOG(pg_am,2601,AccessMethodRelationId)
{
Oid oid; /* oid */
/* access method name *///即为索引名称
NameData amname;
/* handler function */
regproc amhandler BKI_LOOKUP(pg_proc);
/* see AMTYPE_xxx constants below */
char amtype;
} FormData_pg_am;
而在pg_am_d.h也有关于pg_am.h相关的宏定义
// pg_am_d.h
#ifndef PG_AM_D_H
#define PG_AM_D_H
#define AccessMethodRelationId 2601
#define Anum_pg_am_oid 1
#define Anum_pg_am_amname 2
#define Anum_pg_am_amhandler 3
#define Anum_pg_am_amtype 4
#define Natts_pg_am 4
/*
* Allowed values for amtype
*/
#define AMTYPE_INDEX 'i' /* index access method */
#define AMTYPE_TABLE 't' /* table access method */
//各种索引类型的OID
#define HEAP_TABLE_AM_OID 2
#define BTREE_AM_OID 403
#define HASH_AM_OID 405
#define GIST_AM_OID 783
#define GIN_AM_OID 2742
#define SPGIST_AM_OID 4000
#define BRIN_AM_OID 3580
#endif
而进一步发现pg_amop.dat的系统表中也保存着记录不同索引的其他属性如amopfamily,amoplefttype等属性,其含义PostgreSQL上都有注释,在这里不再赘述。与pg_am相关的一系列系统表宏观的记录了不同索引类型的相关属性以及不同索引的操作函数。
而更进一步在系统表pg_index.dat上则记录了当我们创建使用索引时的相关属性和信息。
分析pg_index.h可得知其相关的数据结构
// pg_index.h
CATALOG(pg_index,2610,IndexRelationId) BKI_SCHEMA_MACRO
{
Oid indexrelid; /* OID of the index */
Oid indrelid; /* OID of the relation it indexes */
int16 indnatts; /* total number of columns in index */
int16 indnkeyatts; /* number of key columns in index */
bool indisunique; /* is this a unique index? */
bool indisprimary; /* is this index for primary key? */
bool indisexclusion; /* is this index for exclusion constraint? */
bool indimmediate; /* is uniqueness enforced immediately? */
bool indisclustered; /* is this the index last clustered by? */
bool indisvalid; /* is this index valid for use by queries? */
bool indcheckxmin; /* must we wait for xmin to be old? */
bool indisready; /* is this index ready for inserts? */
bool indislive; /* is this index alive at all? */
bool indisreplident; /* is this index the identity for replication? */
/* variable-length fields start here, but we allow direct access to indkey */
int2vector indkey; /* column numbers of indexed cols, or 0 */
#ifdef CATALOG_VARLEN
oidvector indcollation; /* collation identifiers */
oidvector indclass; /* opclass identifiers */
int2vector indoption; /* per-column flags (AM-specific meanings) */
pg_node_tree indexprs; /* expression trees for index attributes that
* are not simple column references; one for
* each zero entry in indkey[] */
pg_node_tree indpred; /* expression tree for predicate, if a partial
* index; else NULL */
#endif
} FormData_pg_index;
而具体的属性表示含义也可由下图汇总得出
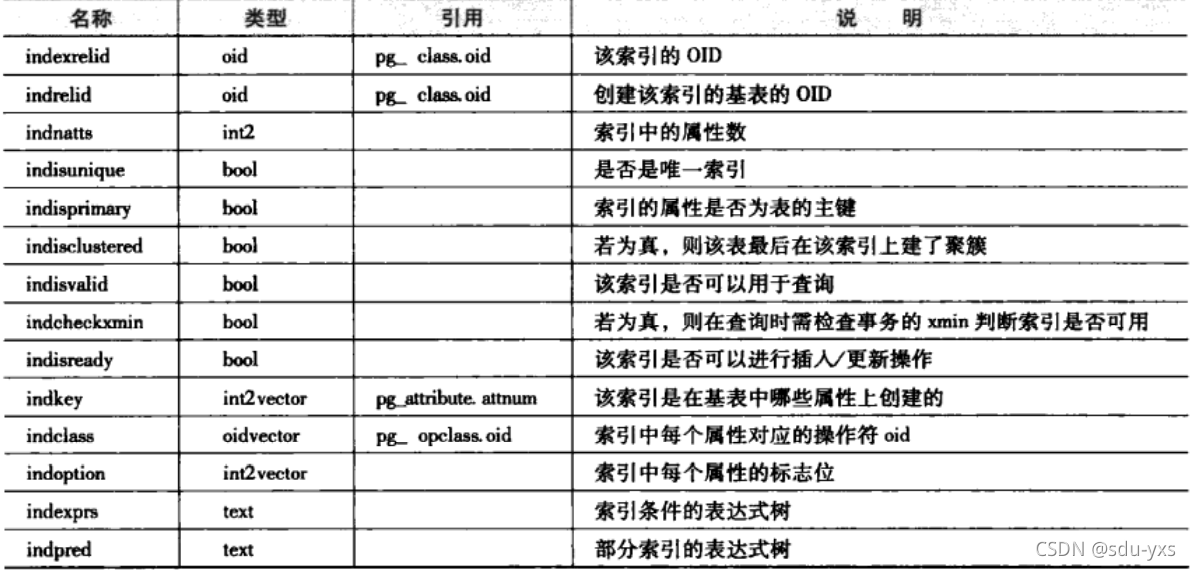
而pg_index.dat并不直接设定各种索引所要操作的数据类型,这一部分则由pg_opclass进行管理。在这里不再展开讲述。
总而言之,系统表定义了关于索引的具体属性,可以更好的统一管理索引,可见postgreSQL的逻辑性,结构性都很强。
与索引系统表相关的后端源码
而对于如何对系统表进行相关的操作的相关源码则应该在backend/catalog中,由文件名可大致判断存在于index.c,indexing.c等文件中。因此我进行gdb调试将断点设置在了index.c的index_build的函数上
同时启动数据库,进行创建索引操作
另一边gdb调试查看堆栈可知index.c文件与索引相关的系统表的操作相关。同样方法调试indexing.c,可知相关。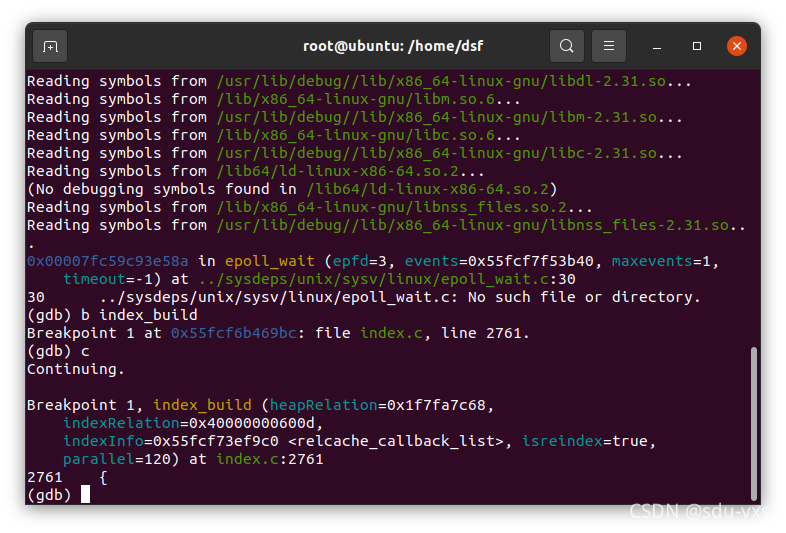
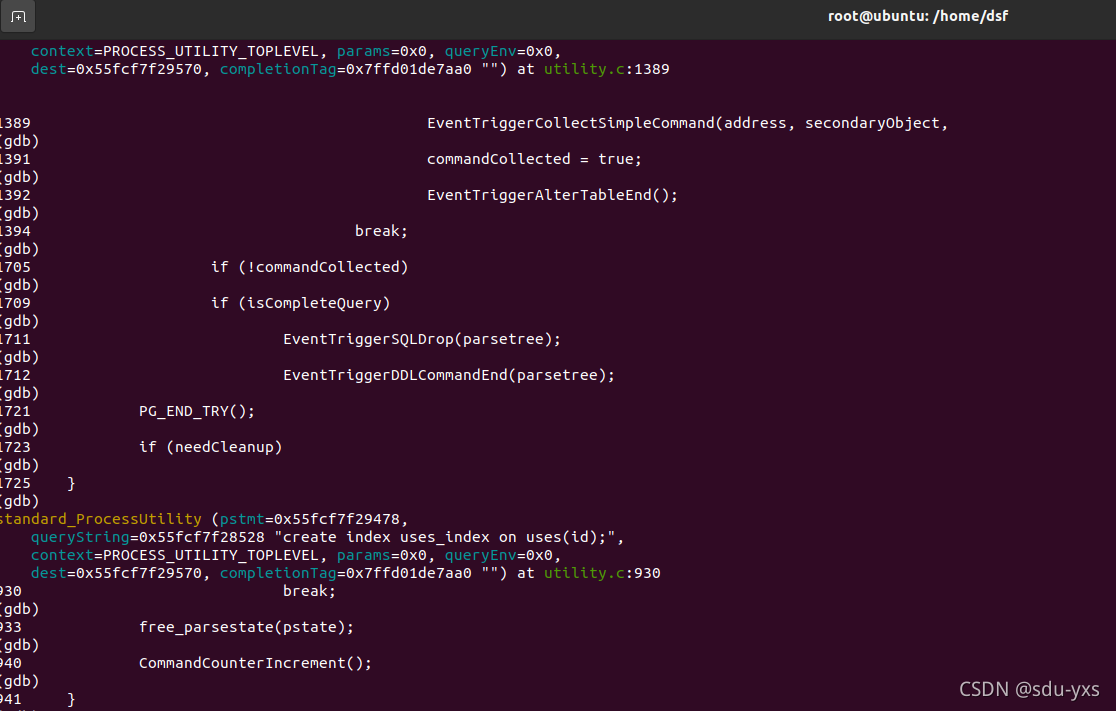
通过阅读index.c的相关代码,可知是有关于对创建和删除索引时进行一系列操作的代码,因为index.c的代码有近四千行,在这里不一样分析,只粘贴部分函数代码进行分析。
// index_build
void
index_build(Relation heapRelation,
Relation indexRelation,
IndexInfo *indexInfo,
bool isreindex,
bool parallel)
{
IndexBuildResult *stats;
Oid save_userid;
int save_sec_context;
int save_nestlevel;
//进行一个安全性检查
Assert(RelationIsValid(indexRelation));
Assert(PointerIsValid(indexRelation->rd_indam));
Assert(PointerIsValid(indexRelation->rd_indam->ambuild));
Assert(PointerIsValid(indexRelation->rd_indam->ambuildempty));
/*
* Determine worker process details for parallel CREATE INDEX. Currently,
* only btree has support for parallel builds.
*
* Note that planner considers parallel safety for us.
*/
if (parallel && IsNormalProcessingMode() &&
indexRelation->rd_rel->relam == BTREE_AM_OID)
indexInfo->ii_ParallelWorkers =
plan_create_index_workers(RelationGetRelid(heapRelation),
RelationGetRelid(indexRelation));
if (indexInfo->ii_ParallelWorkers == 0)
ereport(DEBUG1,
(errmsg("building index \"%s\" on table \"%s\" serially",
RelationGetRelationName(indexRelation),
RelationGetRelationName(heapRelation))));
else
ereport(DEBUG1,
(errmsg_plural("building index \"%s\" on table \"%s\" with request for %d parallel worker",
"building index \"%s\" on table \"%s\" with request for %d parallel workers",
indexInfo->ii_ParallelWorkers,
RelationGetRelationName(indexRelation),
RelationGetRelationName(heapRelation),
indexInfo->ii_ParallelWorkers)));
//切换该索引所属的拥有者id
//与锁相关的操作函数
GetUserIdAndSecContext(&save_userid, &save_sec_context);
SetUserIdAndSecContext(heapRelation->rd_rel->relowner,
save_sec_context | SECURITY_RESTRICTED_OPERATION);
save_nestlevel = NewGUCNestLevel();
/* Set up initial progress report status */
{
const int index[] = {
PROGRESS_CREATEIDX_PHASE,
PROGRESS_CREATEIDX_SUBPHASE,
PROGRESS_CREATEIDX_TUPLES_DONE,
PROGRESS_CREATEIDX_TUPLES_TOTAL,
PROGRESS_SCAN_BLOCKS_DONE,
PROGRESS_SCAN_BLOCKS_TOTAL
};
const int64 val[] = {
PROGRESS_CREATEIDX_PHASE_BUILD,
PROGRESS_CREATEIDX_SUBPHASE_INITIALIZE,
0, 0, 0, 0
};
pgstat_progress_update_multi_param(6, index, val);
}
/*
* Call the access method's build procedure
*/
stats = indexRelation->rd_indam->ambuild(heapRelation, indexRelation,
indexInfo);
Assert(PointerIsValid(stats));
//对于未记录的索引如何操作
if (indexRelation->rd_rel->relpersistence == RELPERSISTENCE_UNLOGGED &&
!smgrexists(indexRelation->rd_smgr, INIT_FORKNUM))
{
RelationOpenSmgr(indexRelation);
smgrcreate(indexRelation->rd_smgr, INIT_FORKNUM, false);
indexRelation->rd_indam->ambuildempty(indexRelation);
}
if ((indexInfo->ii_BrokenHotChain || EarlyPruningEnabled(heapRelation)) &&
!isreindex &&
!indexInfo->ii_Concurrent)
{
Oid indexId = RelationGetRelid(indexRelation);
Relation pg_index;
HeapTuple indexTuple;
Form_pg_index indexForm;
pg_index = table_open(IndexRelationId, RowExclusiveLock);
indexTuple = SearchSysCacheCopy1(INDEXRELID,
ObjectIdGetDatum(indexId));
if (!HeapTupleIsValid(indexTuple))
elog(ERROR, "cache lookup failed for index %u", indexId);
indexForm = (Form_pg_index) GETSTRUCT(indexTuple);
/* If it's a new index, indcheckxmin shouldn't be set ... */
Assert(!indexForm->indcheckxmin);
indexForm->indcheckxmin = true;
CatalogTupleUpdate(pg_index, &indexTuple->t_self, indexTuple);
heap_freetuple(indexTuple);
table_close(pg_index, RowExclusiveLock);
}
/*
* Update heap and index pg_class rows
*/
index_update_stats(heapRelation,
true,
stats->heap_tuples);
index_update_stats(indexRelation,
false,
stats->index_tuples);
/* Make the updated catalog row versions visible */
CommandCounterIncrement();
if (indexInfo->ii_ExclusionOps != NULL)
IndexCheckExclusion(heapRelation, indexRelation, indexInfo);
/* Roll back any GUC changes executed by index functions */
AtEOXact_GUC(false, save_nestlevel);
/* Restore userid and security context */
SetUserIdAndSecContext(save_userid, save_sec_context);
}
观察这些代码,引用了大量的函数进行检查,创建等操作,另外index_build函数也是对于关于索引系统表状态的更新,而其中ambuildempty,ambuild等am函数开头的函数很常见,其实就是下文我们要介绍的与索引相关的操作函数,而通过分析index.c也定义了对于索引的操作函数。
索引的操作函数
关于索引的操作函数分为上层操作函数和下层接口函数,上层操作函数是统一对不同索引类型的操作,而下层接口函数则是不同索引类型对此的操作。
上层操作函数
不难找出在/backend/access/index文件夹中indexam.c是上层操作函数函数
// indexam.c
* INTERFACE ROUTINES
* index_open - open an index relation by relation OID
* index_close - close an index relation
* index_beginscan - start a scan of an index with amgettuple
* index_beginscan_bitmap - start a scan of an index with amgetbitmap
* index_rescan - restart a scan of an index
* index_endscan - end a scan
* index_insert - insert an index tuple into a relation
* index_markpos - mark a scan position
* index_restrpos - restore a scan position
* index_parallelscan_estimate - estimate shared memory for parallel scan
* index_parallelscan_initialize - initialize parallel scan
* index_parallelrescan - (re)start a parallel scan of an index
* index_beginscan_parallel - join parallel index scan
* index_getnext_tid - get the next TID from a scan
* index_fetch_heap - get the scan's next heap tuple
* index_getnext_slot - get the next tuple from a scan
* index_getbitmap - get all tuples from a scan
* index_bulk_delete - bulk deletion of index tuples
* index_vacuum_cleanup - post-deletion cleanup of an index
* index_can_return - does index support index-only scans?
* index_getprocid - get a support procedure OID
* index_getprocinfo - get a support procedure's lookup info
*
在其中定义了这些函数,包括index.c等一系列的文件中的函数是在我们进行数据库相关操作时可以操纵索引的函数,便于统一的使用,也是postgreSQL的聪明之处。
下层接口函数
在index文件夹中可以很快的找到下层接口函数在amapi.c,amapi.h,genam.c,genam.h有定义,通过分析结构和gdb调试,可以找到对于ambuild,aminsert等实现的基层函数在于genam.c实现.可见索引的下层接口函数层层嵌套,指针的多次使用更加展现了源码的健壮性,更让我认识到postgreSQL结构层次复杂但却具有严密的逻辑性和可读性。
接下来我会对于不同索引类型的实现进行展开分析。