二、Spark DataFrame基础操作
2.1、DataFrame
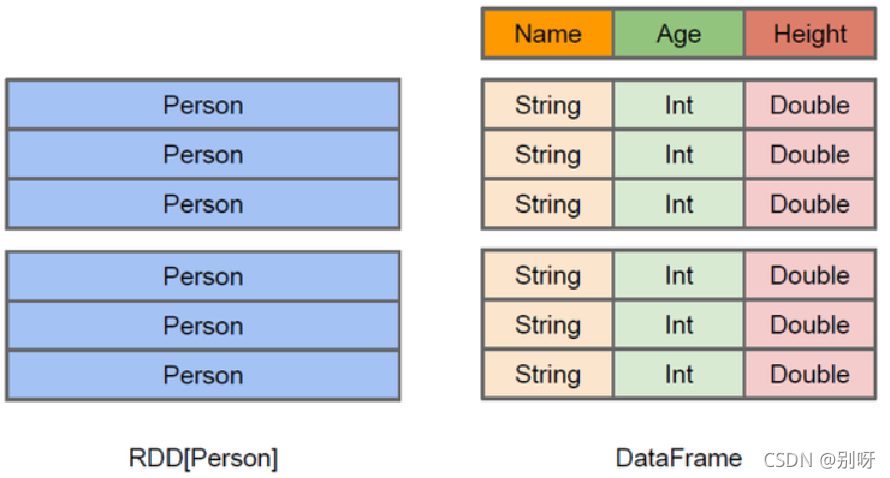
- DataFrame是一种不可变的分布式数据集,这种数据集被组织成指定的列,类似于关系数据库中的表。
- 数据集的每一列都带有名称和类型,对于数据的内部结构又很强的描述性。
- RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。
2.1.1、DataFrame特点
- 支持KB级到PB级得到数据处理
- 支持多种数据格式和存储系统
- 通过Spark SQL Catalyst优化器可以进行高效的代码生成与优化
- 能够无缝集成Spark上的大数据处理工具
- 提供了Python、Java、Scala、R等多种语言API
2.2、创建DataFrame
- 从结构化数据文件创建DataFrame
- 从外部数据库创建DataFrame
- 从RDD创建DataFrame
- 从Hive中的表创建DataFrame
2.2.1、从结构化数据文件创建DataFrame
- 初始化一个SparkSession,名称为spark
spark.read.parquet(path: String):读取一个Parquet文件,返回一个DataFramespark.read.json(path: String):读取一个JSON文件,返回一个DataFramespark.read.csv(path: String):读取CSV文件,返回一个DataFramespark.read.text(path: String):读取文本文件的数据,返回一个DataFrame,只有一个value字段
查看DataFrame
printSchema:查看数据模式,打印出列的名称和类型show:查看数据
show():显示前20条记录
show(numRows:Int):显示numRows条
show(truncate:Boolean):是否最多只显示20个字符,默认为true
show(numRows:Int,truncate:Boolean):显示numRows条记录并设置过长字符串的显示格式first/head/take/takeAsList:获取若干行数据collect/collectAsList:获取所有数据
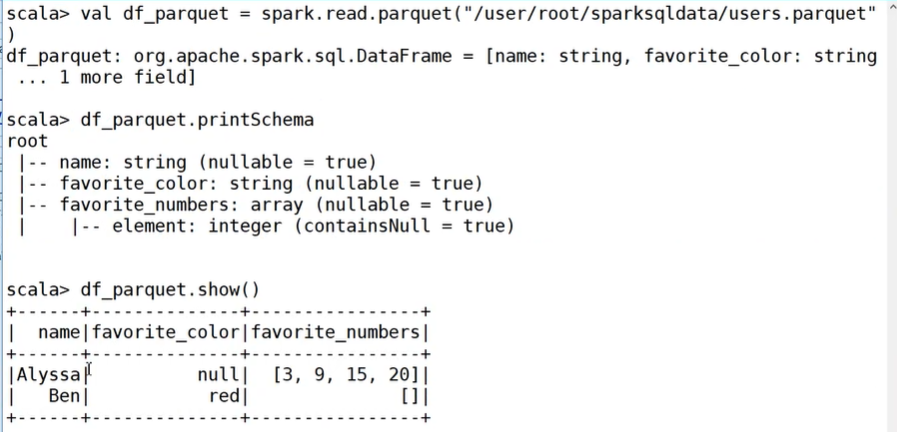
示例:读取parquet文件创建DataFrame
1、从parquet读取数据:
val df_parquet = spark.read.parquet("/user/root/sparksql_data/users.parquet")
2、从json读取数据:
val df_json = spark.read.json("/user/root/sparksql_data/people.json")
3、从csv读取数据:
val df_csv = spark.read.option("header", "true").option("sep", ";").csv("/user/root/sparksql_data/people.csv")
2.2.2、从外部数据库创建DataFrame
- Spark SQL可以从外部数据库(比如MySQL、Oracle等数据库)中创建DataFrame
- 使用这种方式创建DataFrame需要通过JDBC连接或ODBC连接的方式访问数据库
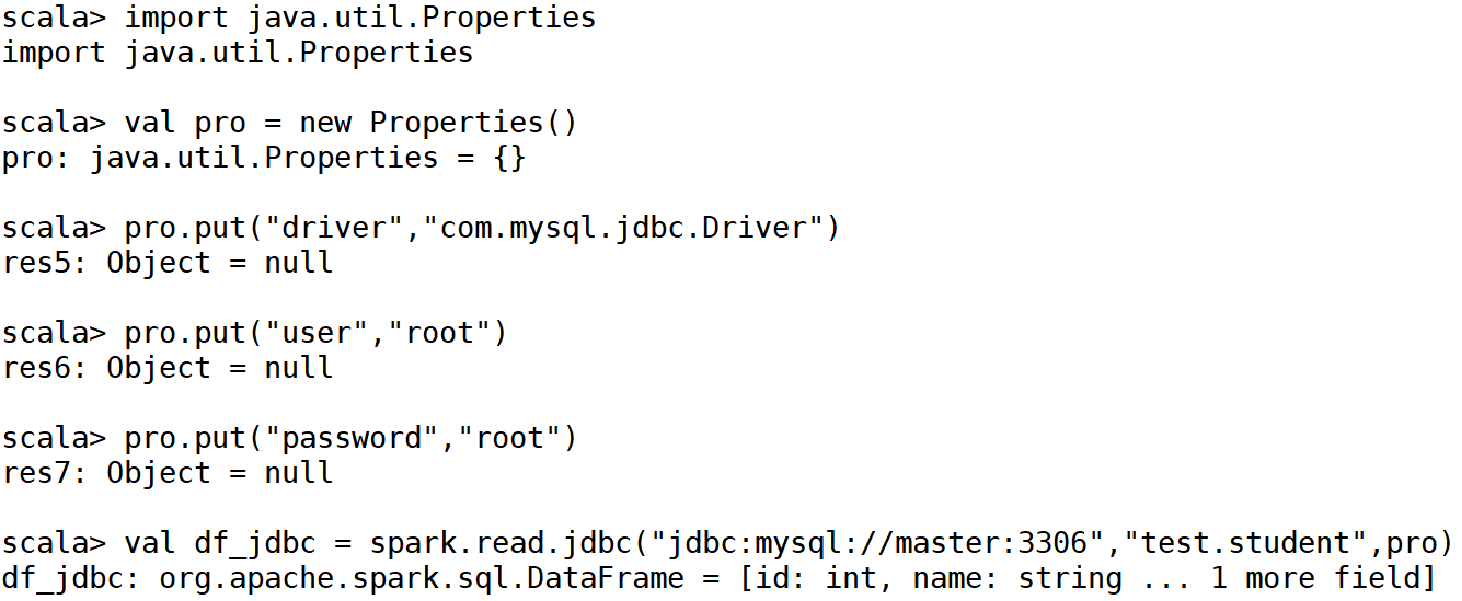
spark.read.jdbc(url: String, table: String, properties: Properties)
示例:读取mysql数据库test的student表

2.2.3、从RDD创建DataFrame-方法1
- 利用反射机制推断RDD模式,使用这种方式首先需要定义一个case class,因为只有case class才能被Spark隐式地转换为DataFrame。
示例:
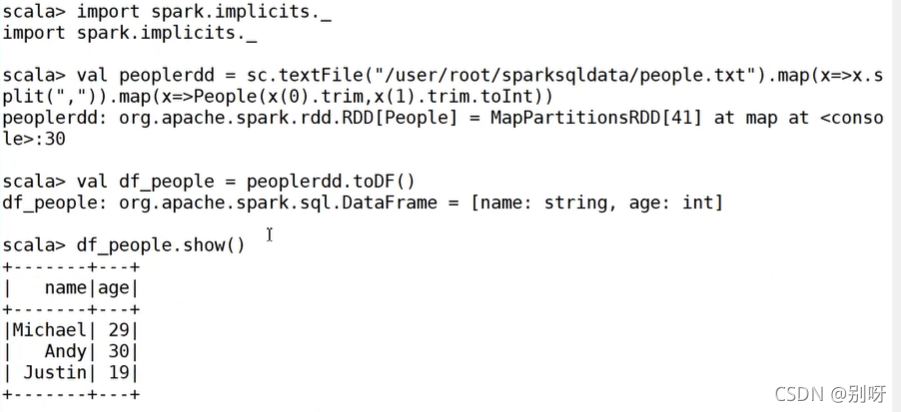
2.2.4、从RDD创建DataFrame-方法2
- 从原始RDD创建一个元素为Row类型的RDD
- 用StructType创建一个和RDD中Row的结构相匹配的Schema
- 通过SparkSession提供的createDataFrame方法将Schema应用到RDD上
示例:读取people.txt创建DataFrame

2.2.5、从Hive中的表创建DataFrame
- 通过SQL查询语句
spark.read.table(tablename)
示例:


任务1:
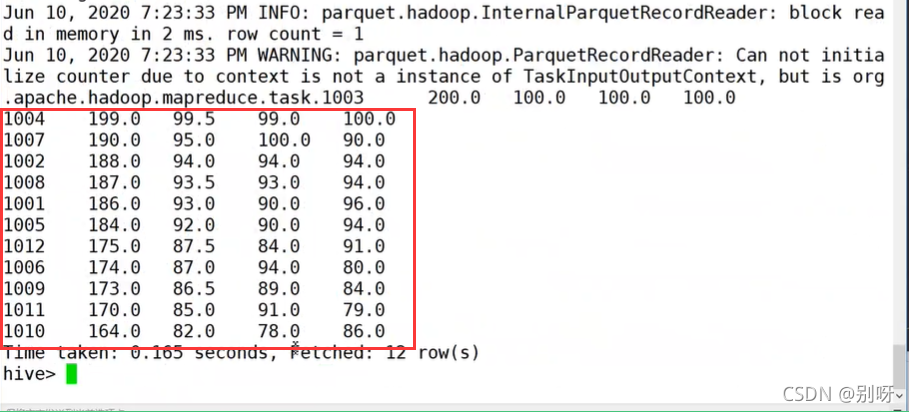
任务实现:读取Hive中的学生成绩表bigdata和math,查看学生信息
-
创建Hive表bigdata和math

-
导入数据到表中
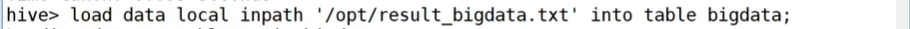
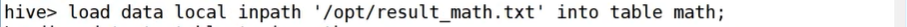
-
读取Hive表bigdata和math创建DataFrame

-
查看DataFrame


2.3、DataFrame常用API

示例:

2.3.1、自定义udf-用于SQL查询
import org.apache.spark.sql.functions._import org.apache.spark.sql.types._udf(f: AnyRef, dataType: DataType)
示例:

2.3.2、自定义udf-用于DataFrame API
org.apache.spark.sql.functions._import org.apache.spark.sql.types._udf(f: AnyRef, dataType: DataType)
示例:

任务2:
任务实现:统计每个学生的平均成绩和总分
- 关联bigdata和math
- 根据学生ID分组统计成绩平均分和总分
- 并根据总分进行降序排序

2.4、保存DataFrame
-
1、保存成文本文件
-
2、保存到外部数据库
-
3、保存为Hive表
-
write方法可以将DataFrame保存成文件,write操作有一个可选参数SaveMode,用这个参数可以指定如何处理数据已经存在的情况。
参数SaveMode:
Overwrite代表覆盖目录下之前存在的数据
Append代表给指导目录下追加数据
Ignore代表如果目录下已经有文件,那就什么都不执行
ErrorIfExists代表如果保存目录下存在文件就报错
2.4.1、保存为文本文件
-
df.write.mode("overwrite").parquet(path: String)

-
df.write.mode("overwrite"). json(path: String)

-
df.write.mode("overwrite").option("header", "true").option("sep", ";"). csv(path: String)

-
df.write.mode("overwrite").text(path: String) //只能有一个字段
2.4.2、保存到外部数据库
jdbc(url: String, table: String, connectionProperties: Properties)
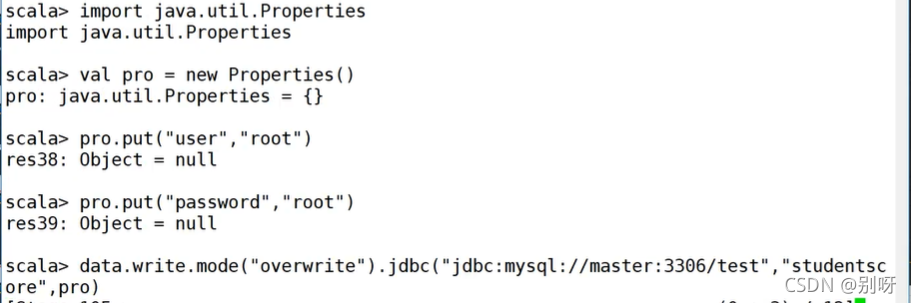
mysql查看:

2.4.3、保存到Hive
df.write.mode("overwrite"). saveAsTable(tableName: String)

hive查看(先进入train数据库,然后再查看):
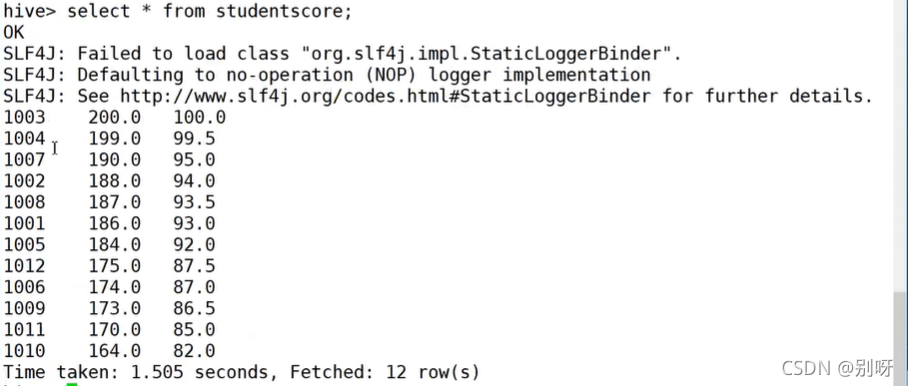
任务3:
任务实现:将每个学生各科成绩、总分、平均分都保存到Hive中。
- 合并学生的各科成绩、总分、平均分
- 保存DataFrame到Hive

hive查看(先进入train数据库,然后再查看):

结果: