���������� ,���ں�:��ʦ��A
����:����
�ű�����:
�Ҹտ�ʼд�ĵ�һ�������� ����Ϊ������,ֻ�߱�������ȡ�����Ĺ��ܡ�
�����ҿ�ʼд�ڶ���,������ȡ�Ӽ����������,�����ô������,�����ô���pass��
���Ǹ�������������д��,�̶̼�ʮ�д��������ɱ档
������,���кܶ�㡣
�������Ĵ���ԭ����һ�����ô���,����Ϊ�״������������,��������ʧ��,��ôһ����������Ϊ�������õĴ���,�����������Ǵ����ˡ�
���߱���ѯ�䶯�Ĺ���,���߱���Ϲ�����������ip�Ĺ��ܡ���
Ϊ�������ҵ�����,�ҿ�ʼ�ο����ϴ����ǵ�˼·,DZ���о�,ͨ���ﵩ,������ʳ,ҹ�Լ��ա�������
��=��=��=( ̄�� ̄)������ʮ�ε��� ����д���˵������������桿�����ء�

���������������ŵ㡿:
1.��ѯ�䶯IP
2.��������,��������̭
3.�첽����,����ȴ�
4.sqlmap�����,IP������ȥ
5.�����������ݿ�,WEB AIP���ɽ��
����,�Ҳ���BB,ֱ�Ӳ�������
ʵ�ִ�������ѯ�䶯-�ӵ�һ����ĸ��ʼ����
һ.�����ص�ʵ������:
(1).������Ҫ��װ����python�еĿ�,��װ�����ܼ�,pip3 install ����������
��������Ҫ�õ��Ŀ�,���а���ϵͳ�Դ���,��ҿɸ����������ѡ��װ��(��ȱ����Ӧ��ģ��,�ڽű�ִ��ʱ���б�����ʾ��,�ɸ�����ʾ���䰲װ)
��Ȼ,������������Ի�˽����
Redis,redis-dump
Pyquery
urllib
random
asyncio
aiohttp
botocore
multiprocessing
(2).��װRedis-x64-3.0.504.msi,������װ��ű�����ʱ�ᱨ��:Error 10061 connecting to 127.0.0.1:6379. ����Ŀ�����������ܾ�,������
����ԭ��:Redis����û������
��װ�̳�:github����,�����ٶȼ���,��Ҫ�����ӡ����ǵ���ƪ���²����漰��ǽ,�����ҽ��Ҵ��������غõ�Redis-x64-3.0.504.msi�ŵ��·��ĸ�����,����Ұ�װ��

��.����˼·
(1).ģ�鴴��
���δ�����ȫ������,Ϊ��ʵ�ֹ��ܵĶ�����,�Լ���֤�ű����ȶ���,�ɶ��ԡ�
�ҽ�����6��ģ��ű�,ʵ�ִӴ��������С�������ȡ�����������洢��������⡪�����ӿڡ��������õȹ��ܡ�
(2).ʵ�ִ���ά��
ʹ�ô�����ֵ��,��������ȡ����Ѵ���ͳһ����ʼֵΪ10,���������ݿ���,ͨ�����ģ���������������������,���״�����ɹ�,�ô�����ʼֵ������100,���״�����ʧ����ʼֵ��1,������ֵ��Ϊ0,�����Ӵ��������Ƴ���
(3.)��������
ͨ��WEB API�ӿ�,�õ�������ô���,��������Ϊ�������ӵ�ֵ,���Ȼ�ȡ���ֵ����(ֵԽ��Խ�ȶ�),�������ֵ����,�����ֵ�Ĵ�С��������,������������ǰ�Ĵ���,������ʹ�á�
��.������д
˵ʵ���������治��һ��һ���������ÿ��������˼,��Ϊ����̫����,���Ա�ķʽ�̳��ڱ�ƪ�����оͲ������ˡ������������,����һ���ܱ�֤��ҿ��ö���ƪ����,�����ڿ��걾ƪ���º�,�ܹ������α�д�Լ������ص�˼·��
С��ͬѧ��Ҫ�ܵ�ί����~���������ű�ƪ���¶�С������һ���Ǿ��!!!
�洢ģ���д:
(1).����ȡ�Ĵ����洢��Redis���ݿ���,ͨ������һ����������Redis�����ϡ�
(2).����ǰ��˵��ҪΪ��������ʼֵ,���Ҹ��ݸ�ֵ��С��������,�������Dz��ò�����Redis�������������ǵ�Ҫ��
ʲô��Redis����:
Redis ���Ϻͼ���һ��Ҳ��string����Ԫ�صļ���,�Ҳ������ظ��ij�Ա����ͬ����ÿ��Ԫ�ض������һ��double���͵ķ�����
redis����ͨ��������Ϊ�����еij�Ա���д�С���������
�����double���ͷ�����������Ϊ��������ֵ��
��������Ҫ����һ����,һЩ���� ��һЩ������ʵ�ִ����Ĵ洢��
����db.pyΪ�洢ģ��: ����������Ҫ���Ƕ�Redis��ĺ��������˽�,Ҫ��Ȼ�ǿ������ġ�
python
coding=gbk
�洢ģ��
����������һЩ����:
python
MAX_SCORE = 100 #���ֵ
MIN_SCORE = 0 #��Сֵ
INITIAL_SCORE = 10 #��ʼֵ
REDIS_HOST = 'localhost' #Redis����IP
REDIS_PORT = 6379 #Redis���Ӷ˿�
REDIS_PASSWORD = None #��������,��Ҹ����Լ�����ѡ��
REDIS_KEY = 'proxies' #���ϼ���,��ȡ�����洢ʹ�õ�����
���ÿⲢ������ͷ���:
python
import redis #ʵ��Redis�����Ӽ�ʹ��
from random import choice #����һ���б�,Ԫ����ַ����������
class RedisClient(object):
def __init__(self, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD):
"""
��ʼ��
:param host: Redis ��ַ
:param port: Redis �˿�
:param password: Redis����
"""
self.db = redis.StrictRedis(host=host, port=port, password=password, decode_responses=True)
�����и�Сϸ��:self.db�Ƕ���һ��ʵ��,�����������ݿ��,������һ��decode_responses����ֵΪTrue ������Ϊ������Ҫ�ؼ�ֵʱ,�����Ӵ�������᷵�ء���b��Value�� ,���ؽ������һ����ƨ��b,b����Ϊbyte��������,���Ե�����decode_responses=Trueʱ,���ؽ���Ͳ����и�ƨ���ˡ�����Valie��
python
def add(self, proxy, score=INITIAL_SCORE):
"""
���Ӵ���,���÷���Ϊ���
:param proxy: ����
:param score: ����
:return: ���ӽ��
"""
if not self.db.zscore(REDIS_KEY, proxy):
return self.db.zadd(REDIS_KEY, score, proxy)
add()ʵ��Ϊ������ȡ�Ĵ������ӳ�ʼֵ10��
def random(self):
"""
�����ȡ��Ч����,���ȳ��Ի�ȡ��߷�������,���������,����������ȡ,�����쳣
:return: �������
"""
result = self.db.zrangebyscore(REDIS_KEY, MAX_SCORE, MAX_SCORE)
if len(result):
return choice(result)
else:
result = self.db.zrevrange(REDIS_KEY, 0, 100)
if len(result):
return choice(result)
else:
raise PoolEmptyError
��һ��result��������ֵΪ100�Ĵ���(���Ч����),�ڶ���result����������ν���,��Ҳ�ܲ����ġ�
def decrease(self, proxy):
"""
����ֵ��һ��,С����Сֵ��ɾ��
:param proxy: ����
:return: �ĺ�Ĵ�������
"""
score = self.db.zscore(REDIS_KEY, proxy)
if score and score > MIN_SCORE:
print('����', proxy, '��ǰ����', score, '��1')
return self.db.zincrby(REDIS_KEY, proxy, -1)
else:
print('����', proxy, '��ǰ����', score, '�Ƴ�')
return self.db.zrem(REDIS_KEY, proxy)
Redis�����������,ʵ�����ô����Ƴ�����
def exists(self, proxy):
"""
�ж��Ƿ����
:param proxy: ����
:return: �Ƿ����
"""
return not self.db.zscore(REDIS_KEY, proxy) == None
#����д��,������������ʱ ����not
def max(self, proxy):
"""
����������ΪMAX_SCORE
:param proxy: ����
:return: ���ý��
"""
print('����', proxy, '����,����Ϊ', MAX_SCORE)
return self.db.zadd(REDIS_KEY, MAX_SCORE, proxy)
def count(self):
"""
��ȡ����
:return: ����
"""
return self.db.zcard(REDIS_KEY)
def all(self):
"""
��ȡȫ������
:return: ȫ�������б�
"""
return self.db.zrangebyscore(REDIS_KEY, MIN_SCORE, MAX_SCORE)
����crawler.pyΪ��ȡģ��:
�Ӹ�����վ������ȥ����,�Ƚϼ� ��������˵�� ��ǰ�������漰�������ԭ����
���ÿ⼰����
from pyquery import PyQuery as pq #����
import urllib.request #����
����һ����,
class ProxyMetaclass(type):
def __new__(cls, name, bases, attrs):
count = 0
attrs['__CrawlFunc__'] = []
for k, v in attrs.items():
if 'crawl_' in k:
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs)
class Crawler(object, metaclass=ProxyMetaclass):
def get_proxies(self, callback): #callback = crawl_daili66 �������涨��Ļ�ȡ�����ķ�������
proxies = []
for proxy in eval("self.{}()".format(callback)):
print('�ɹ���ȡ������', proxy)
proxies.append(proxy)
return proxies
��ʵ���������Ԫ����ʵ�֡�kk��������Ԫ�����˽��Ҳ�����
����attrs�ֵ���ʽ KΪ�� VΪֵ�����а������Ƕ���ķ������� ��ͼ:

���ʹ���:
������һ�� ProxyMetaclass,Crawl �ཫ������ΪԪ��,Ԫ����ʵ���� new() ����,��������й̶��ļ�������,���е��ĸ����� attrs �а��������һЩ����,�����оͰ��������з�����һЩ��Ϣ,���ǿ��Ա��� attrs ����������ɻ�ȡ������з�����Ϣ��
���������������� new() �����б����� attrs ���������,�������һ���ֵ�һ��,������Ӧ�ľ��Ƿ���������,�������ж��俪ͷ�Ƿ��� crawl_,
�����,������뵽 CrawlFunc ������,�������Ǿͳɹ��������� crawl ��ͷ�ķ����������һ������,�ͳɹ���̬�ػ�ȡ�������� crawl ��ͷ�ķ����б��ˡ�
��һ�����巽��:��Ҫ������������ȡ����:
��������Ҫ��ס,Ϊ��ʵ�ֶ����ȡ��ͬ������վ���뷨,���DZ���ͳһ�涨������ķ����ԡ�crawl_����ͷ
def crawl_daili66(self,page_count=4):
start_url = 'http://www.66ip.cn/{}.html'
urls = [start_url.format (page) for page in range(1, page_count + 1)]
for url in urls:
print('Crawling', url)
req = urllib.request.Request(url=url)
res = urllib.request.urlopen(req)
html = res.read()
if html:
doc = pq(html)
trs = doc('.containerbox table tr:gt(0)').items()
for tr in trs:
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
yield ':' .join([ip,port])
def crawl_proxyXH(self):
start_url = "http://www.89ip.cn/index_{}.html"
urls = [start_url.format(page) for page in range(1,10)]
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
for url in urls:
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read()
if html:
doc = pq(html)
trs = doc('.layui-row table tr:gt(0)').items()
for tr in trs:
ip = tr.find('td:nth-child(1)').text() #tr�ڵ��µ�һ��td�ӽڵ���ı�����
port = tr.find('td:nth-child(2)').text()
yield ':' .join([ip,port])
�����������ô��,���Ŀ�һ�۾��ܿ�����
ΨһҪ��һ�µ�һ����,�����tr:gt(0)���������,����ʹ��gt(0),������˵�����˴ӵ�һ��tr�ڵ㵽���һ��tr�ڵ�����нڵ�,���ǰ�����tr�ڵ����һ���ֵܽڵ㼰��������tr�ڵ㡣
���仰˵,���dz��˵�һ��tr�ڵ��� ������tr�ڵ㶼��������
�����������ȽϺ����ҷ����ٶȱȽϿ����վ,֮����������С�ô���������Ϊ���׳��ַ����ӳٵ�����,Ӱ��ű����ȶ��ԡ�
�ڶ���������վ��Ҫ��������ͷ��,Ҫ��Ȼ���ֹ���ʡ�
���淽����������еļ���ͼ,��66ipΪ��:
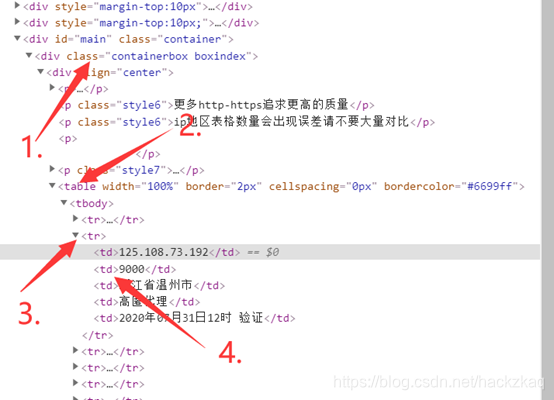
�������,����tr�ڵ� ɸѡ�ӽڵ� �����������,���������,��������˽�����ҡ�
���ǻ���Ҫ����һ��getter.py��ģ��,������̬����������crawl_��ͷ�ķ���,Ȼ��ץȡ����,�洢�����ݿ��С�
getter.pyģ��:
��Ϊ�漰����ȡ�ʹ洢 ����ֱ�Ӵ���ǰ����ģ���е����Ѿ������õ�������
from db import RedisClient
from crawler import Crawler
���ƴ����ص�����ݴ���Ϊ10000
POOL_UPPER_THRESHOLD = 10000
����Getter��,����ʵ��,Ϊ�˵���������ĺ���
class Getter():
def __init__(self):
self.redis = RedisClient()
self.crawler = Crawler()
def is_over_threshold(self):
"""
����RedisClient��count()����
�ж��Ƿ�ﵽ�˴���������
"""
if self.redis.count() >= POOL_UPPER_THRESHOLD:
return True
else:
return False
def run(self):
print('��ȡ����ʼִ��')
if not self.is_over_threshold():
for callback_label in range(self.crawler.__CrawlFuncCount__): #���б���ȡ���а���crawl_�ķ���
callback = self.crawler.__CrawlFunc__[callback_label]
proxies = self.crawler.get_proxies(callback) #�нӻ�ȡģ���еĺ���,��ȡ����
for proxy in proxies:
self.redis.add(proxy) #�洢��redis���ݿ���
������ is_over_threshold() �����жϴ������Ƿ��Ѿ��ﵽ��������ֵ,�����ǵ����� RedisClient �� count() ������ȡ����������,Ȼ������ж�,��������ﵽ��ֵ�� True,���� False��
��������������ƿ��Խ��˷������÷��� True��
������������ run() ����,�����ж��˴������Ƿ�ﵽ��ֵ,Ȼ��������͵����� Crawler ��� CrawlFunc ����,��ȡ�������� crawl ��ͷ�ķ����б�,����ͨ�� get_proxies() ��������,�õ���������ץȡ���Ĵ���,Ȼ�������� RedisClient �� add() �����������ݿ�
����tester.pyΪ���ģ��:
������db.py crawler.py getter.py����ģ����,�����Ѿ��ܹ��ɹ���ȡ�������ҽ���������ݿ��С�
Ȼ�����Ҫһ�����ģ���������еĴ�������һ���ֵļ��,�����þ�����Ϊ 100,�����þͷ����� 1,�����Ϳ���ʵʱ�ı�ÿ�������Ŀ������,�ڻ�ȡ��Ч������ʱ��ֻ��Ҫ��ȡ�����ߵĴ������ɡ�
���ڴ����������dz���,Ϊ����ߴ����ļ��Ч��,����������ʹ���첽����� Aiohttp �����м�⡣
ΪʲôҪ��Aiohttp��,������һ��,������������ַ��ʱ��ͨ��ϰ��ʹ��requests������,��Requests ��Ϊһ��ͬ�������,�����ڷ���һ������֮����Ҫ�ȴ���ҳ�������֮����ܼ���ִ�г���
Ҳ����������̻������ڵȴ���Ӧ�������,�����������Ӧ�dz���,����һ������ȴ�ʮ����,��ô����ʹ�� Requests ���һ������ͻ���Ҫʮ�����ʱ��,�м���ʵ����һ���ȴ���Ӧ�Ĺ���,����Ҳ�����������ִ�С�
��Aiohttp�첽�����������Ľ����������⡣������֮��,������Լ�������ȥִ��ȥ������������,����Ӧ����ʱ,��֪ͨ������ȥ���������Ӧ,���������û�б�����,��ְ�ʱ�����Դ��������,������Ч�ʡ�
�������������ǵĴ������ʹ���첽����� Aiohttp,ʵ��ʾ������:
VALID_STATUS_CODES = [200]
TEST_URL = 'http://www.baidu.com'
BATCH_TEST_SIZE = 100
���ú�״̬��200ΪĿ��������Ѿ�����������
BATCH_TEST_SIZE���ú�һ�μ�����������,����һ�������100������
TEST_URL:ʹ�ø���վ���м��,��������Ϊһ������� IP ����վ���ٶȾͺܲ���Ŷ~
from db import RedisClient
import asyncio #������д ���� ����Ŀ�
import aiohttp
import time
init() �����н�����һ�� RedisClient ����,��������������ʹ��
class Tester(object):
def __init__(self):
self.redis = RedisClient()
������������һ�� test_single_proxy() ����,������ⵥ�������Ŀ������,��������DZ����Ĵ�����
async def test_single_proxy(self, proxy):
conn = aiohttp.TCPConnector(verify_ssl=False) #����ʹ��TCP����HTTP��HTTPS��������
async with aiohttp.ClientSession(connector=conn) as session:
try:
if isinstance(proxy, bytes):
proxy = proxy.decode('utf-8')
real_proxy = 'http://' + proxy
print('���ڲ���', proxy)
async with session.get(TEST_URL, proxy=real_proxy, timeout=15) as response: #����get()�������
if response.status in VALID_STATUS_CODES:
self.redis.max(proxy)
print('��������', proxy)
else:
self.redis.decrease(proxy)
print('������Ӧ�벻�Ϸ�', proxy)
except :
self.redis.decrease(proxy)
print('��������ʧ��', proxy)
ע���������ǰ����� async �ؼ���,��������������첽��,�����ڲ����ȴ����� Aiohttp �� ClientSession ����,�˶��������� Requests �� Session ����,����ֱ�ӵ��øö���� get() ����������ҳ�档
��������������÷�ʽ��ͨ�� proxy �������ݸ� get() ����,����ǰ��Ҳ��Ҫ���� async �ؼ��ʱ������첽����,��Ҳ�� Aiohttp ʹ��ʱ�ij���д����
def run(self):
print('��������ʼ����')
try:
proxies = self.redis.all() # ���еĴ���
loop = asyncio.get_event_loop() #�¼�ѭ���Ļ�ȡ
# ��������
for i in range(0, len(proxies), BATCH_TEST_SIZE):
test_proxies = proxies[i:i + BATCH_TEST_SIZE]
tasks = [self.test_single_proxy(proxy) for proxy in test_proxies]
loop.run_until_complete(asyncio.wait(tasks))
time.sleep(5)
except Exception as e:
print('��������������', e.args)
Aiohttp��Ҳ��˽�,�ⲿ��ֱ�Ӱ����ϵĴ����á�
����api.py�ӿ�ģ��:
�ᵽ�ӿڴ���뵽�Ŀ϶�����API,��ô����Ϊʲô��ʹ���������ݿ�,���������Redis���ݿ�,���ǵ���WEB API��ʵ�ֽӿ�ģ���������?
(1).���ݿ�����й¶����
(2).Ϊ��Զ�����Ӵ�����
(3).����ͬ������
������ȡ����ֻ��Ҫ����һ�½ӿڼ���,���ϵļ���ȱ��˿��Խ����
����������ʹ��һ���Ƚ��������Ŀ� Flask ��ʵ������ӿ�ģ��,ʵ��ʾ������:
from flask import Flask, g #����flask��
from db import RedisClient #������
���Ǹ�С֪ʶ��all�Ǹ������б�,���ǿ���all����[��app��]��˼����˵ ,�ڱ�ģ����,�������ø�ģ��,��ֻ����ִ��app����-> Flask(name)
__all__ = ['app']
app = Flask(__name__)
��ʼ��:���е�Flask�����봴������ʵ��,
web������ʹ��wsgiЭ��,�ѿͻ������е�����ת�����������ʵ��
����ʵ����Flask�Ķ���,һ������������·���ʵ����
Flask��ֻ��һ������ָ���IJ���,��������ģ����߰�������,name��ϵͳ����,�ñ���ָ���DZ�py�ļ����ļ���
def get_conn():
if not hasattr(g, 'redis'):
g.redis = RedisClient()
return g.redis
@app.route('/')
def index():
return '<h2>Welcome to Proxy Pool System</h2>'
@app.route('/random')
def get_proxy():
conn = get_conn()
return conn.random()
@app.route('/count')
def get_counts():
conn = get_conn()
return str(conn.count())
�ͻ��˷���url��web������,web��������urlת����flask����ʵ��,����ʵ��
��Ҫ֪������ÿһ��url����������һ���ִ���,���Ա�����һ��url��python������ӳ���ϵ��
����url�ͺ���֮���ϵ�ij���,��Ϊ·��
��flask��,����·������ķ�ʽ,��ʹ�ó���ʵ����app.routeװ����,��װ�εĺ���ע��Ϊ·��
if __name__ == '__main__':
app.run()
���һ��ģ�� ���dz�֮Ϊ����ģ�顣
����run.py����ģ��:
���ģ����ʵ���ǵ������������������ģ��,����������ģ��ͨ������̵���ʽ��������,ʾ������:
TESTER_CYCLE = 20
GETTER_CYCLE = 20
TESTER_ENABLED = True
GETTER_ENABLED = True
API_ENABLED = True
�����ﻹ����������,TESTER_ENABLED��GETTER_ENABLED��API_ENABLED ���Dz�������,True ���� False�������˲���ģ�顢��ȡģ�顢�ӿ�ģ��Ŀ���,���Ϊ True,�����ģ�鿪����
import time
from multiprocessing import Process
from api import app #���ýӿ�ģ��
from getter import Getter #���û�ȡģ��(2) crawler.py��getter��Ϊ��ȡģ��
from tester import Tester #���ü��ģ��
�������ȷ����ṹҲ�dz�����,���� schedule_tester() ����,�����������Ȳ���ģ��ķ���,��������һ�� Tester ����,Ȼ�������ѭ������ѭ�������� run() ����,ִ����һ��֮�������һ��ʱ��,���߽���֮��������ִ�С�����������ʱ��Ҳ����Ϊһ������,�� 20 ��,�����ͻ�ÿ�� 20 �����һ�δ�����⡣
class Scheduler():
def schedule_tester(self, cycle=TESTER_CYCLE):
tester = Tester()
while True:
print('��������ʼ����')
tester.run()
time.sleep(cycle)
#ÿ��20������ݿ��ȡһ�δ���
def schedule_getter(self, cycle=GETTER_CYCLE):
getter = Getter()
while True:
print('��ʼץȡ����')
getter.run()
time.sleep(cycle)
def schedule_api(self):
app.run('127.0.0.1','5000') #����Ҫ������,������������5000�˿�Ҳ����AIP_PORT,����˿���ô��,��ҿ���ֱ��ִ��aip.pyģ��
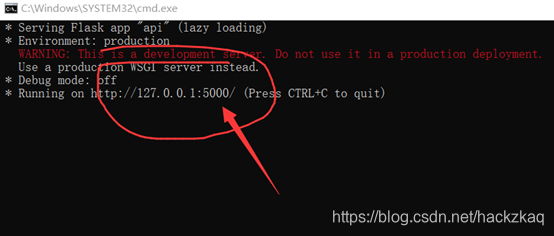
��������� run() ����,��ֱ��ж�������ģ��Ŀ���,��������Ļ�,���½�һ�� Process ����,���ú�����Ŀ��,Ȼ����� start() ��������,�����������̾Ϳ��Բ���ִ��,�������š�
def run(self):
print('�����ؿ�ʼ����')
if TESTER_ENABLED:
tester_process = Process(target=self.schedule_tester)
tester_process.start()
if GETTER_ENABLED:
getter_process = Process(target=self.schedule_getter)
getter_process.start()
if API_ENABLED:
api_process = Process(target=self.schedule_api)
api_process.start()
���е�ʱ��Ҫ����д:
if __name__=='__main__':
Scheduler().run()
����ͻ����һ��������ʾ
��.�����ص�����
(1).����Ҫ��֤Redis������,��û�����Ļ������ز���װRedis-x64-3.0.504.msi
��װ�������ӵ�������,�㿪ֱ�����ԡ���һ����,��װ�ɹ���,�ҵ�.exe�ļ�����Ŀ¼,˫��ִ�м��ɡ�
Port:6379����,�ű������Ѿ���ǰд���ˡ�
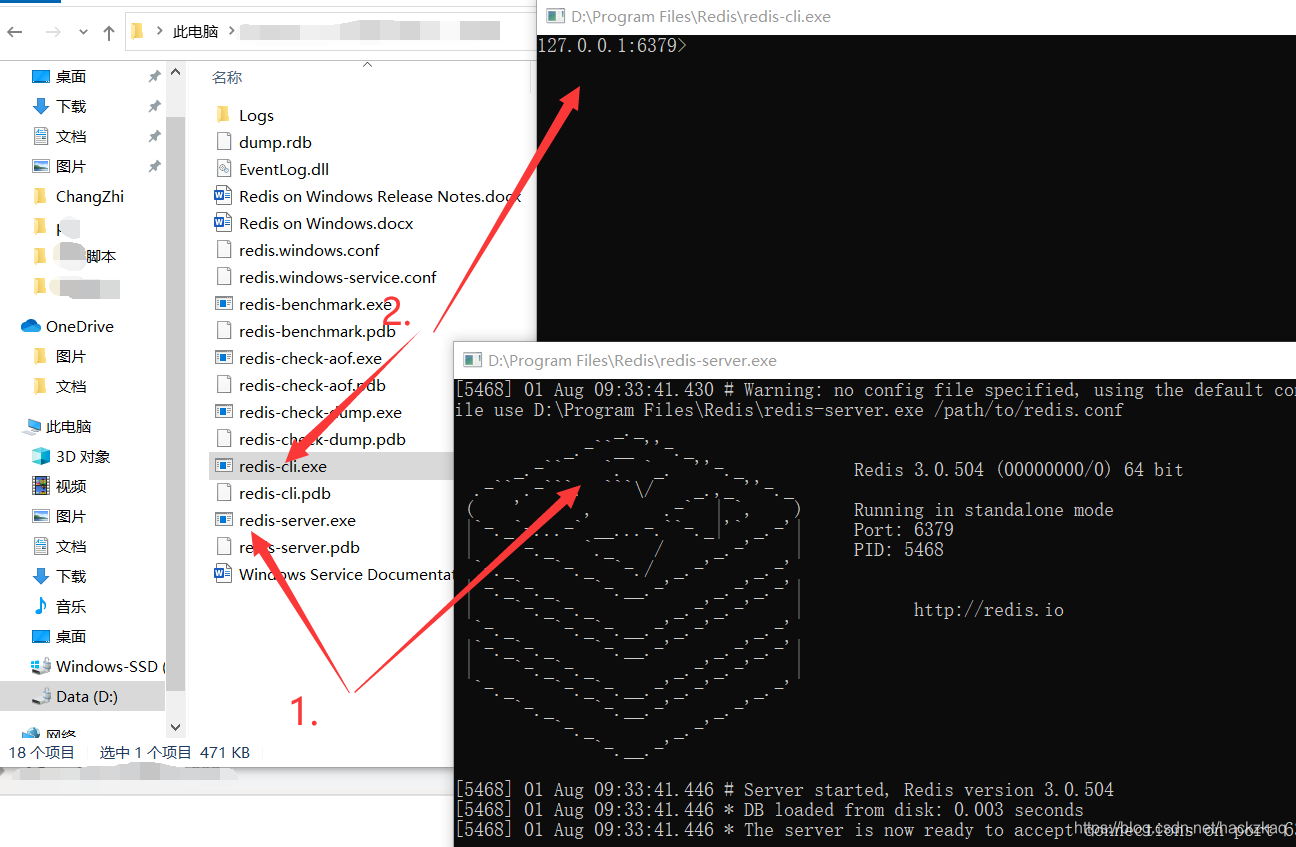
(2).�ص�run.py�ű� ֱ��ִ��(��֤����ģ�����ͬһĿ¼��)
(3).ִ��Ч��:��ͼ

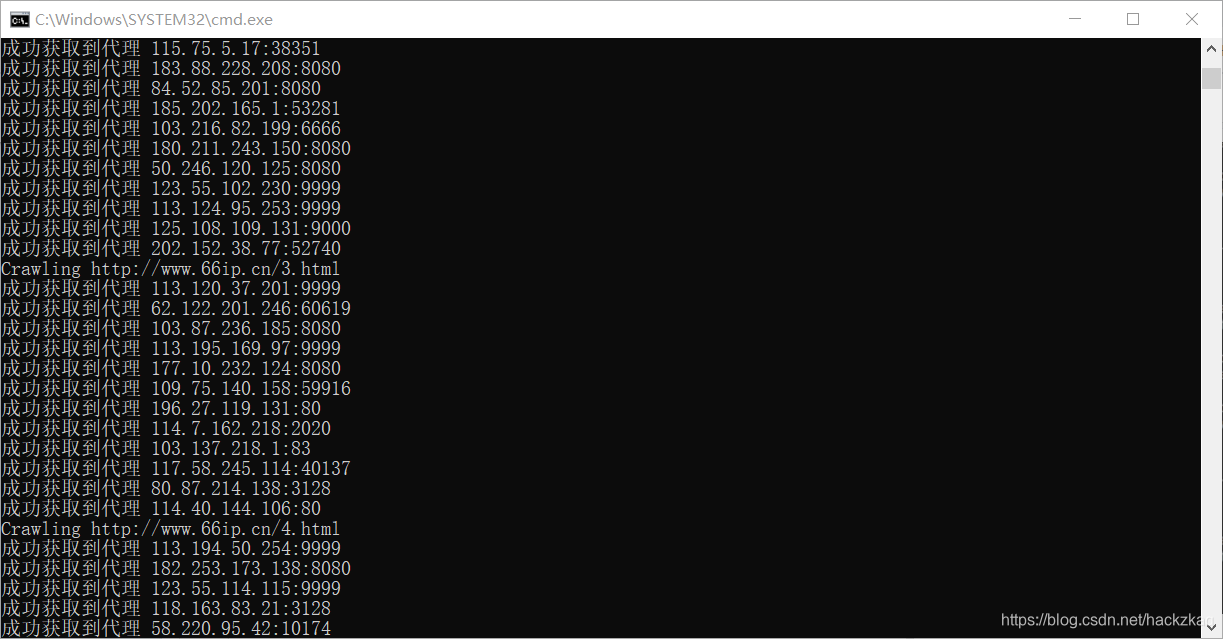
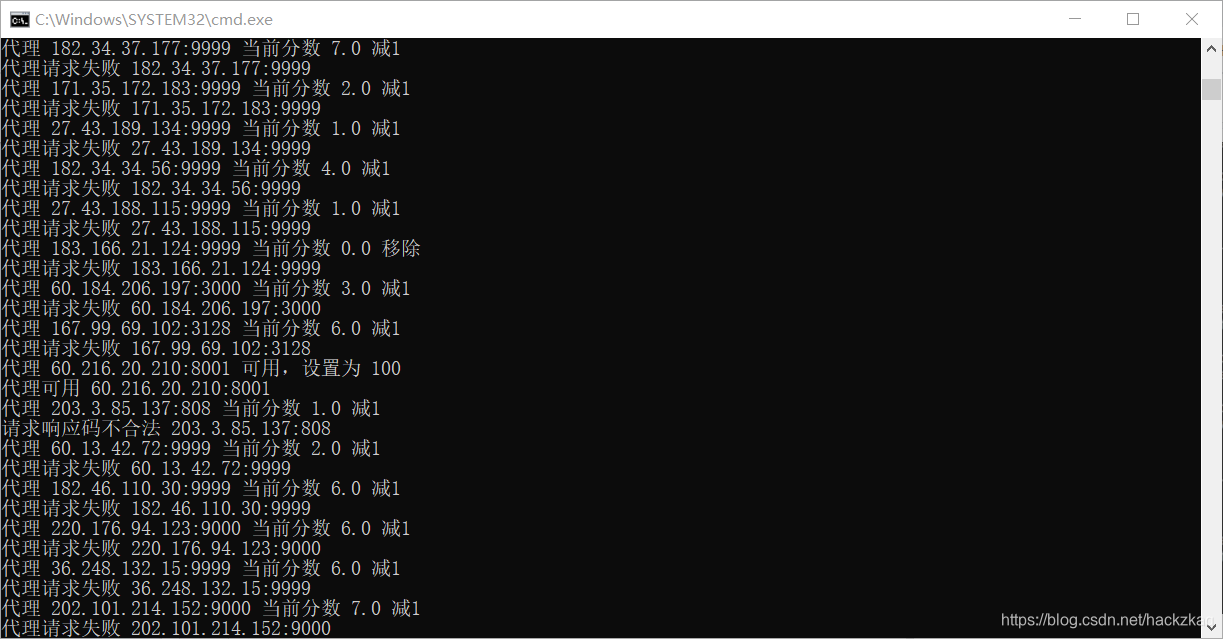
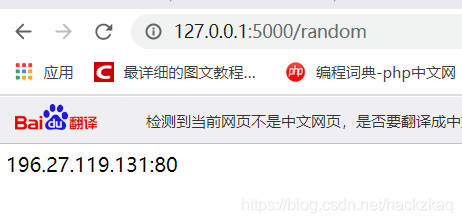
�ɼ���Ѵ������õĻ��Ǻ��ٵġ������Ի��ǽ�����������ͬѧȡ���Ѵ���ʹ��

���Ͼ��Ǵ����ش�����ʵ�ֵ�ȫ�������ˡ�
��ͬѧ����,�Ҹ�����������ѯ�䶯�������С�
����,����sqlmapɨ��Ŀ����ַ���DZ���,����ô���ýű���?
����:sqlmap -u Ŀ����ַ �Cporxy = http://127.0.0.1:5000/random
����ʵ��ÿɨ��һ�ξ�,�䶯һ������ɨ������IP��ַ���Dz��Ǻ�ţ�������ӡ�
*Դ�뼰Redis��װ��ͳһ���ϴ����͵ġ�������Դ����,����������