Spark Doris Connector ��Doris��0.12�汾���Ƴ����¹��ܡ��û�����ʹ�øù���,ֱ��ͨ��Spark��Doris�д洢�����ݽ��ж�д,֧��SQL��Dataframe��RDD�ȷ�ʽ��
��Doris�Ƕȿ�,������������Spark,����ʹ��Sparkһϵ�зḻ����̬��Ʒ,�ؿ��˲�Ʒ��������,Ҳʹ��Doris����������Դ�����ϲ�ѯ��Ϊ����
1.����ѡ��
�����ڵķ�����,����ֱ�ӽ�Doris��JDBC�ӿ��ṩ��Spark������JDBC���Datasource,Spark��Ĺ���ԭ��Ϊ,Spark��Driverͨ��JDBCЭ��,����Doris��FE,�Ի�ȡ��ӦDoris����Schema��Ȼ��,����ijһ�ֶ�,����ѯ��Ϊ���Partition�Ӳ�ѯ����,�·������Spark��Executors��Executors���������Partitionת���ɶ�Ӧ��JDBC��ѯ,ֱ�ӷ���Doris��FE�ӿ�,��ȡ��Ӧ���ݡ����ַ�����������Ķ�����,������ΪSpark����֪Doris�����ݷֲ�,�ᵼ�´�Doris�IJ�ѯѹ���dz���
�����������������Doris���µ�Datasource,Spark-Doris-Connector�����ַ�����,Doris���Ա�¶Doris���ݷֲ���Spark��Spark��Driver����Doris��FE��ȡDoris����Schema�͵ײ����ݷֲ���֮��,���ݴ����ݷֲ�,�����������ݲ�ѯ�����Executors�����,Spark��Executors�ֱ���ʲ�ͬ��BE���в�ѯ����������˲�ѯ��Ч�ʡ�
2.ʹ�÷���
��Doris�Ĵ����� extension/spark-doris-connector/ Ŀ¼�±�������doris-spark-1.0.0-SNAPSHOT.jar,�����jar������Spark��ClassPath��,����ʹ��Spark-on-Doris������
2.1 ��ȡ
2.1.1 SQL
CREATE TEMPORARY VIEW spark_doris
USING doris
OPTIONS(
"table.identifier"="$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME",
"fenodes"="$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"user"="$YOUR_DORIS_USERNAME",
"password"="$YOUR_DORIS_PASSWORD"
);
SELECT * FROM spark_doris;
2.1.2 DataFrame
val dorisSparkDF = spark.read.format("doris")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.load()
dorisSparkDF.show(5)
2.1.3 RDD
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME"),
cfg = Some(Map(
"doris.fenodes" -> "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"doris.request.auth.user" -> "$YOUR_DORIS_USERNAME",
"doris.request.auth.password" -> "$YOUR_DORIS_PASSWORD"
))
)
dorisSparkRDD.collect()
2.2 �
2.2.1 SQL��ʽ
CREATE TEMPORARY VIEW spark_doris
USING doris
OPTIONS(
"table.identifier"="$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME",
"fenodes"="$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"user"="$YOUR_DORIS_USERNAME",
"password"="$YOUR_DORIS_PASSWORD"
);
INSERT INTO spark_doris VALUES ("VALUE1","VALUE2",...);
# or
INSERT INTO spark_doris SELECT * FROM YOUR_TABLE
2.2.2 DataFrame(batch/stream)��ʽ
## batch sink
val mockDataDF = List(
(3, "440403001005", "21.cn"),
(1, "4404030013005", "22.cn"),
(33, null, "23.cn")
).toDF("id", "mi_code", "mi_name")
mockDataDF.show(5)
mockDataDF.write.format("doris")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.save()
## stream sink(StructuredStreaming)
val kafkaSource = spark.readStream
.option("kafka.bootstrap.servers", "$YOUR_KAFKA_SERVERS")
.option("startingOffsets", "latest")
.option("subscribe", "$YOUR_KAFKA_TOPICS")
.format("kafka")
.load()
kafkaSource.selectExpr("CAST(key AS STRING)", "CAST(value as STRING)")
.writeStream
.format("doris")
.option("checkpointLocation", "$YOUR_CHECKPOINT_LOCATION")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.start()
.awaitTermination()
2.3 ����
2.3.1 ������ʷ���ݱ��
��û��Spark Doris Connectorǰ,Doris�����ݵijɱ��ܸ�,�����ݵ��ĺ�ɾ����������ʵҵ����ʱ�����֡�
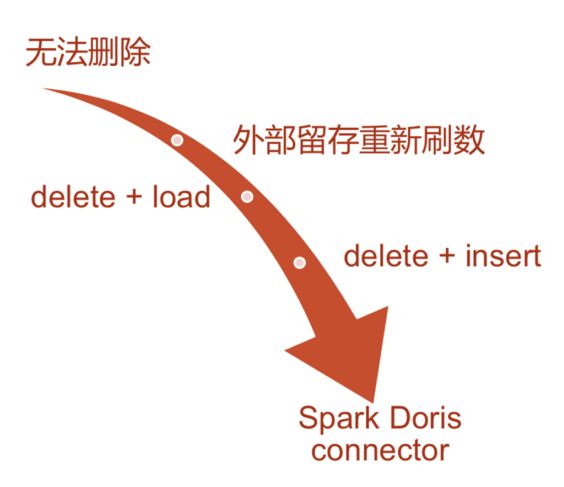
Spark Doris Connector֮ǰ
����һ:֮ǰ����Ĵ������ݲ�Ҫɾ��,����replace�ķ�ʽ,�����������ȫ������һ�ݸ�ֵ��,�Ӷ���valueˢ��0,�ٽ���ȷ�����ݵ����ȥ��
������:�Ѵ�������ɾ��,Ȼ���ٽ���ȷ����insert������
��������������һ������,������һ��ʱ�䴰��������valueΪ0��������ⲿϵͳ��˵�Dz������̵ġ�����������Ҫ�鿴�Լ����˻���Ϣ,��������ݱ������������˻���ʾΪ0,�������Խ��ܵ�,�ܲ��Ѻá�
Spark Doris Connector����
����Spark Doris Connector,������ʷ���ݱ��������ӱ��

����ͼ��ʾ,��һ���Ǵ�������,�ڶ�������ȷ���ݡ�Spark��������������,һ����ʹ��Spark Doris Connector����Doris,һ���������ⲿ����ȷ����(����ҵ�������ɵ�Parquet�ļ�)����Spark����diff����,������value���diffֵ,��ͼ�����һ�еĽ�������䵼���Doris���ɡ������ĺô��ǿ��������м��ʱ�䴰��,ͬʱҲ����ƽʱ����ʹ��Spark��ҵ�������в���,�dz��Ѻá�
ʹ��Spark��Doris�е����ݺ���������Դ�������Ϸ���
�ܶ�ҵ���ŻὫ�Լ������ݷ��ڲ�ͬ�Ĵ洢ϵͳ��,����һЩ���߷��������������ݷ���Doris��,һЩ�ṹ���������ݷ���Elasticsearch�С�һЩ��Ҫ��������ݷ���MySQL��,�ȵȡ�ҵ��������Ҫ�����洢Դ���з���,ͨ��Spark Doris Connector��ͨSpark��Doris��,ҵ�����ֱ��ʹ��Spark,��Doris�е����������ⲿ����Դ�����ϲ�ѯ���㡣
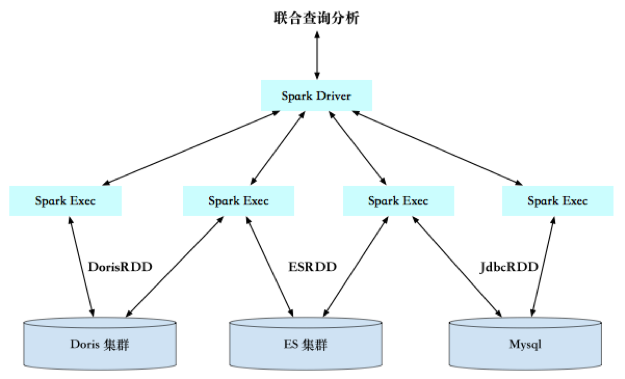
2.3.2 ����ʵʱ����д��
ĿǰSpark doris connector ֧��ͨ��SQL,DataFrame��ʽ�Դ�����Դ�ж�ȡ����,ͨ��SQL��DataFrame������д�뵽doris�С�ͬʱ����������Spark�ļ������������ݽ���һЩʵʱ���㡣
3.�������
3.1 ͨ������
| Key | Default Value | Comment |
|---|---|---|
| doris.fenodes | �C | Doris FE http ��ַ,֧�ֶ����ַ,ʹ�ö��ŷָ� |
| doris.table.identifier | �C | Doris ����,��:db1.tbl1 |
| doris.request.retries | 3 | ��Doris������������Դ��� |
| doris.request.connect.timeout.ms | 30000 | ��Doris������������ӳ�ʱʱ�� |
| doris.request.read.timeout.ms | 30000 | ��Doris��������Ķ�ȡ��ʱʱ�� |
| doris.request.query.timeout.s | 3600 | ��ѯdoris�ij�ʱʱ��,Ĭ��ֵΪ1Сʱ,-1��ʾ��ʱ���� |
| doris.request.tablet.size | Integer.MAX_VALUE | һ��RDD Partition��Ӧ��Doris Tablet������ ����ֵ����ԽС,�������Խ���Partition���Ӷ�����Spark��IJ��ж�,��ͬʱ���Doris��ɸ����ѹ���� |
| doris.batch.size | 1024 | һ�δ�BE��ȡ���ݵ�����������������ֵ�ɼ���Spark��Doris֮�佨�����ӵĴ����� �Ӷ����������ӳ��������ĵĶ���ʱ�俪���� |
| doris.exec.mem.limit | 2147483648 | ������ѯ���ڴ����ơ�Ĭ��Ϊ 2GB,��λΪ�ֽ� |
| doris.deserialize.arrow.async | false | �Ƿ�֧���첽ת��Arrow��ʽ��spark-doris-connector���������RowBatch |
| doris.deserialize.queue.size | 64 | �첽ת��Arrow��ʽ���ڲ���������,��doris.deserialize.arrow.asyncΪtrueʱ��Ч |
3.2 SQL �� Dataframe ר������
| Key | Default Value | Comment |
|---|---|---|
| user | �C | ����Doris���û��� |
| password | �C | ����Doris������ |
| doris.filter.query.in.max.count | 100 | ν��������,in����ʽvalue�б�Ԫ���������������������,��in����ʽ����������Spark�ദ���� |
3.3 RDD ר������
| Key | Default Value | Comment |
|---|---|---|
| doris.request.auth.user | �C | ����Doris���û��� |
| doris.request.auth.password | �C | ����Doris������ |
| doris.read.field | �C | ��ȡDoris���������б�,����֮��ʹ�ö��ŷָ� |
| doris.filter.query | �C | ���˶�ȡ���ݵı���ʽ,�˱���ʽ����Doris��Dorisʹ�ô˱���ʽ���Դ�����ݹ��ˡ� |
3.4 Doris �� Spark ������ӳ���ϵ
| Doris Type | Spark Type |
|---|---|
| NULL_TYPE | DataTypes.NullType |
| BOOLEAN | DataTypes.BooleanType |
| TINYINT | DataTypes.ByteType |
| SMALLINT | DataTypes.ShortType |
| INT | DataTypes.IntegerType |
| BIGINT | DataTypes.LongType |
| FLOAT | DataTypes.FloatType |
| DOUBLE | DataTypes.DoubleType |
| DATE | DataTypes.StringType1 |
| DATETIME | DataTypes.StringType1 |
| BINARY | DataTypes.BinaryType |
| DECIMAL | DecimalType |
| CHAR | DataTypes.StringType |
| LARGEINT | DataTypes.StringType |
| VARCHAR | DataTypes.StringType |
| DECIMALV2 | DecimalType |
| TIME | DataTypes.DoubleType |
| HLL | Unsupported datatype |
- ע:Connector��,��
DATE��DATETIMEӳ��ΪString������Doris�ײ�洢���洦����,ֱ��ʹ��ʱ������ʱ,���ǵ�ʱ�䷶Χ��������������ʹ��?String?����ֱ�ӷ��ض�Ӧ��ʱ��ɶ��ı�