1、分享概要
本次分享会先从Redis可重入锁最简单的Demo入手,一步一图分析Redis可重入锁底层的源码,在边看源码的过程中、边画出Redis可重入锁的核心流程图。
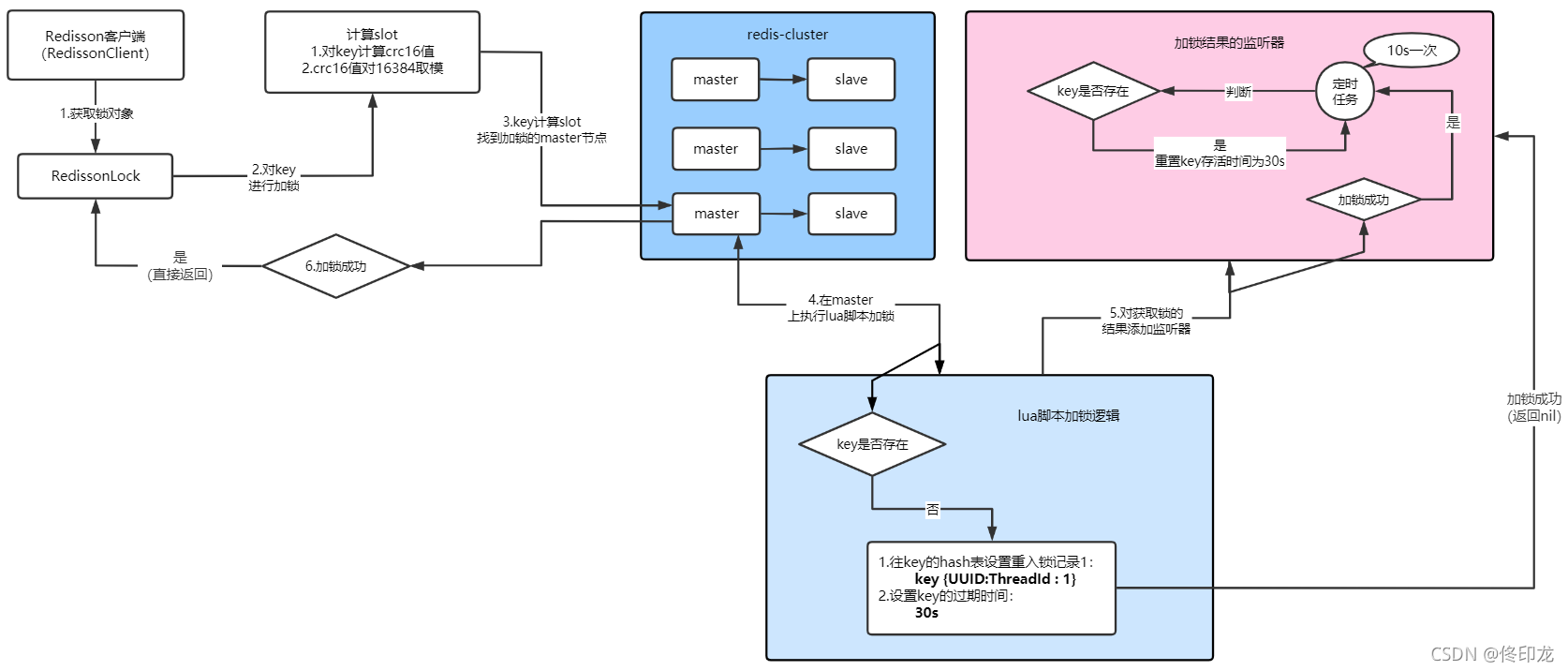
通过这张核心的流程图,我们可以看到一个企业级的、基于Redis分布式锁的方案是怎样的形成的,在开始分享前,大家先思考下如下常见的面试题:
1、客户端线程在底层是如何实现加锁的?
2、客户端线程是如何维持加锁的?
Redis可重入锁源码的分享,上半部分将重点围绕以上2个核心问题一步步展开分析,大家可以心中带着这几个问题一步步看下去,最后形成的完整的流程图如下所示:
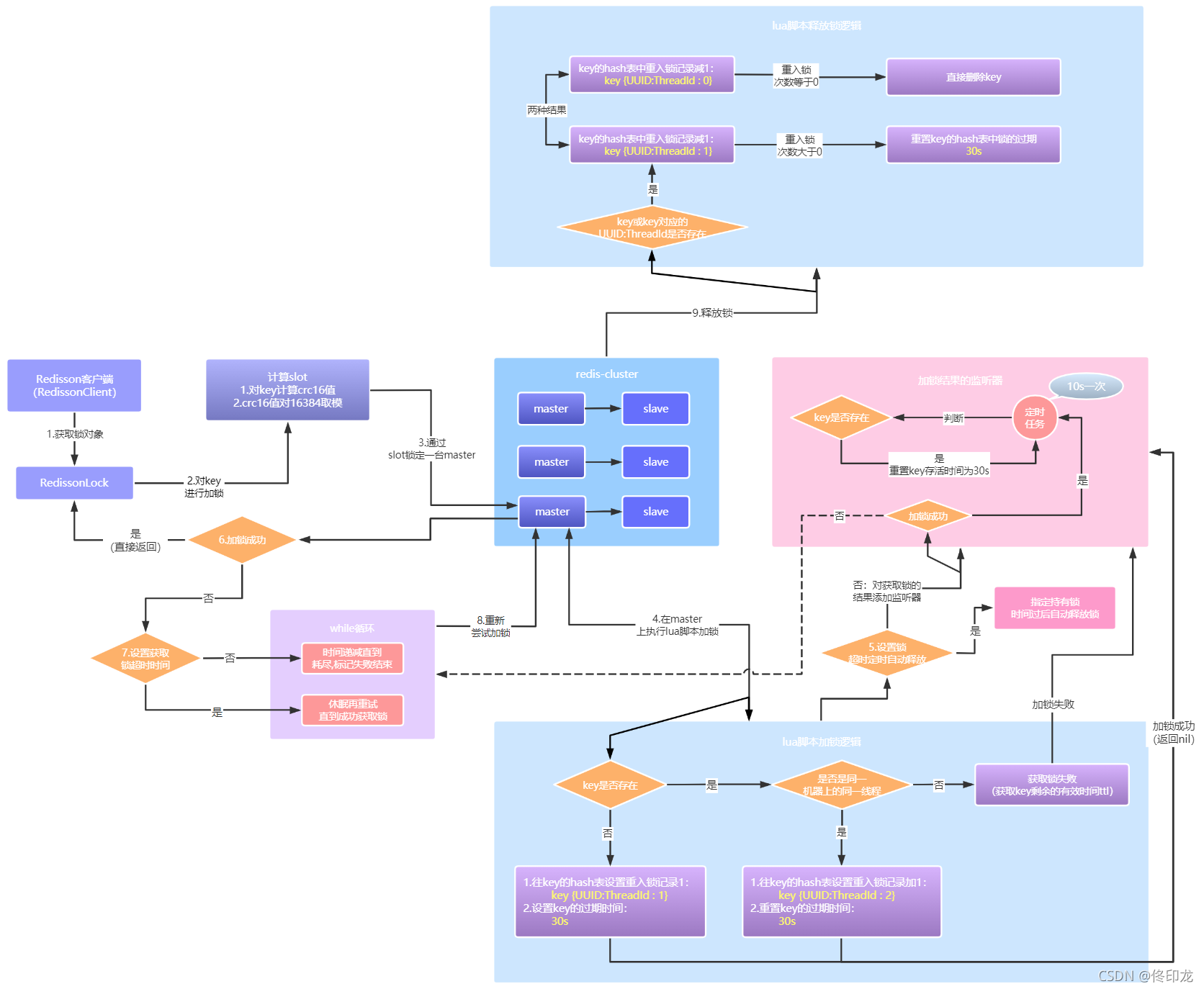
2、Redis可重入锁的核心流程
本次主要分享Redis最知名的客户端框架Redisson可重入锁的源码,我们先创建一个Maven工程,然后从一个简单Demo案例来入手。
2.1 Redis可重入锁Demo
创建一个maven工程,在pom中引入依赖,本次我们就采用Redisson 3.8.1版本:

如下Demo中Redis的环境采用三主三从的方式搭建一套Redis-Cluster集群环境(搭建Redis-Cluster集群的步骤这里省略,我们重点关注源码层面),Demo代码示例如下:

public class Application {
public static void main(String[] args) throws Exception {
//1.配置Redis-Cluster集群节点的ip和port
Config config = new Config();
//redis-cluster集群的ip和port
config.useClusterServers()
.addNodeAddress("redis://192.168.43.159:7001")
.addNodeAddress("redis://192.168.43.159:7002")
.addNodeAddress("redis://192.168.43.159:7003")
.addNodeAddress("redis://192.168.43.114:7001")
.addNodeAddress("redis://192.168.43.114:7002")
.addNodeAddress("redis://192.168.43.114:7003");
//2.通过以上配置创建Redisson的客户端
RedissonClient redisson = Redisson.create(config);
//3.测试Redisson可重入锁的加锁、释放锁等功能
testRedissonSimpleLock(redisson);
}
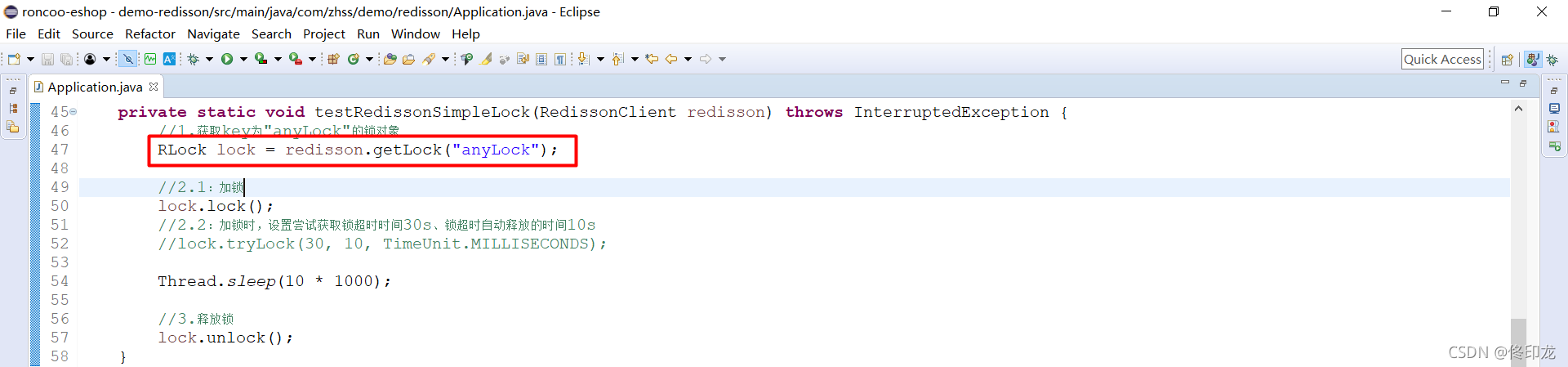
private static void testRedissonSimpleLock(RedissonClient redisson) throws InterruptedException {
//1.获取key为"anyLock"的锁对象
RLock lock = redisson.getLock("anyLock");
//2.1:加锁
lock.lock();
//2.2:加锁时,设置尝试获取锁超时时间30s、锁超时自动释放的时间10s
//lock.tryLock(30, 10, TimeUnit.MILLISECONDS);
Thread.sleep(10 * 1000);
//3.释放锁
lock.unlock();
}
}
Demo比较简单,就是我们平常开发高频用到的一些Api,包括加锁和释放锁,但是底层是如何实现加锁这一语义的呢?
1:如何维持加锁呢?
2:如何实现尝试获取锁超时的控制?
3:锁超时又是如何自动释放锁的呢?
4:释放锁的语义又是如何实现的?
带着这些迷雾般的困惑,接下来的源码环节、我们好好的看一下。
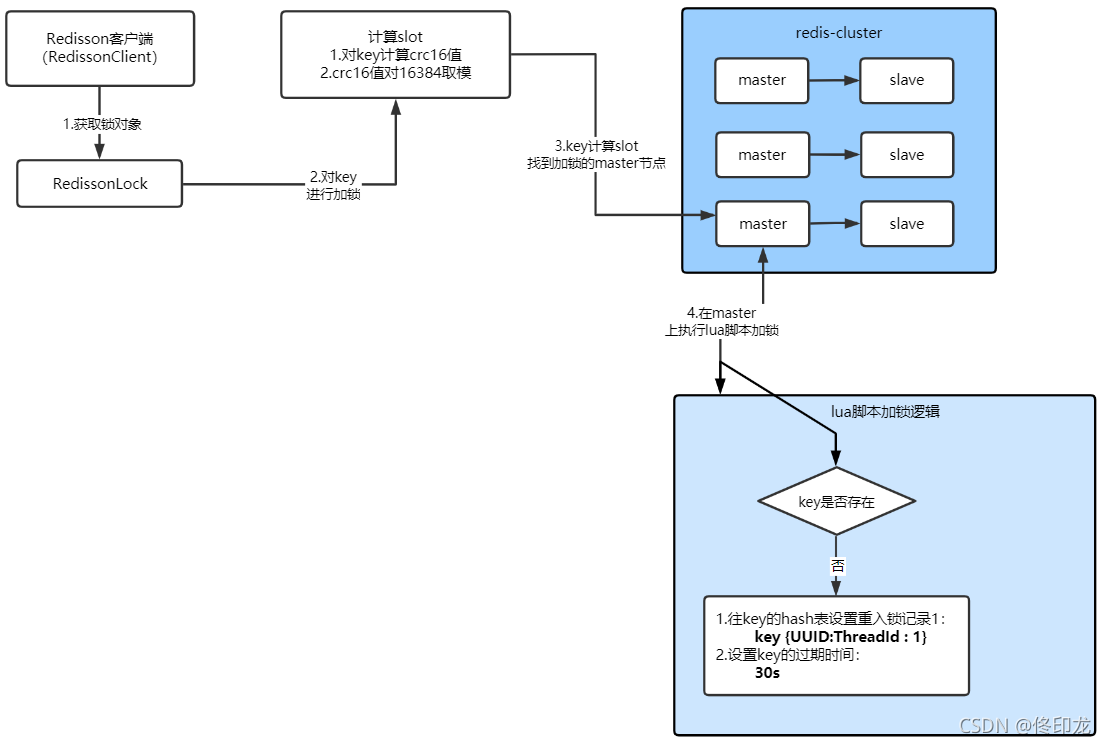
1、找哪台机器加锁呢?
首先我们先看下它是怎么获取一个锁对象的,如下图:
RLock对象表示一个锁对象,这里表示我们要对key为anyLock加锁,先获取一个锁对象。
首先我们可以先猜下,既然是要加锁,具体体现到Redis底层命令上肯定就是最朴素的set key value的方式啊,我们先不管它里面的其他各种复杂机制,
第一个问题肯定就是要在Redis-Cluster集群中、那么多的master节点中选择一个master节点来加锁即执行命令
此时肯定会是在redisson.getLock方法中、针对"anyLock"这个key就选择好了要对哪个master节点上加锁,然后下一步的lock.lock直接就往那台master节点上执行redis命令加锁就行了。
带着这个想法,那下一步肯定要到redisson.getLock(“anyLock”)中的getLock方法中看下,如下图所示:
有点小小的遗憾,暂时我们并没有发现有锁定master节点相关的逻辑,但是通过上图我们却发现了这里redisson.getLock方法最终获取到的锁对象竟然是RedissonLock,而对Redisson的构造中只不过是各种变量的设置而已。
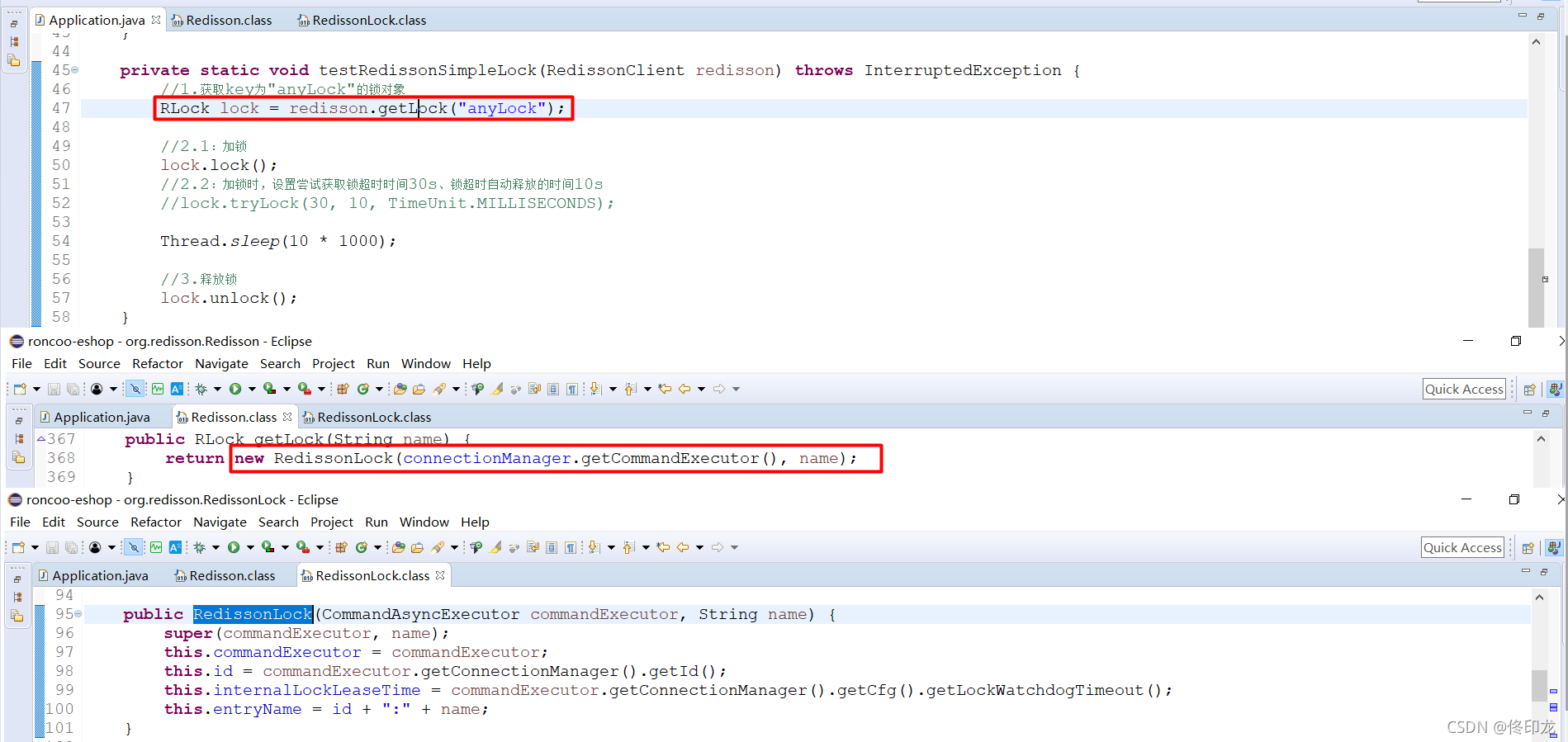
我们慢慢通过图片、把我们好不容易找到的东西收集起来,如下图所示:
那既然不在第一步中锁定master节点,那么我们就继续看下lock.lock()方法,如下图所示:
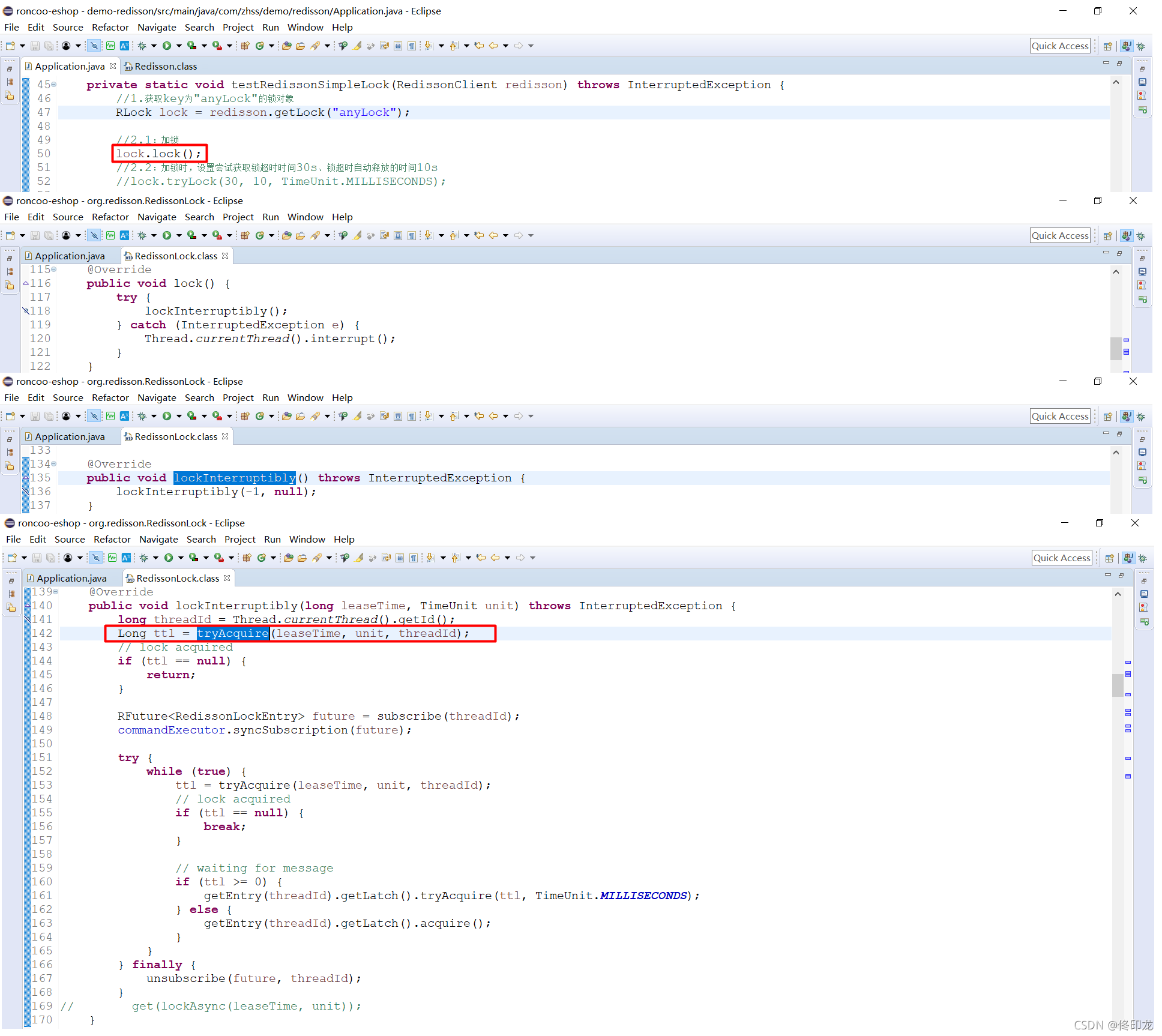
通过对lock.lock()方法的层层追踪,终于我们来到lockInterruptibly方法中,发现这里面还算有点东西,其中发现tryAcquire方法,顾名思义、有点像要获取什么东西的意思,进去看看:
好像发现了点不可思议的东西,藏得真深、开源框架还真蛮喜欢深度嵌套调用,层层追踪后终于发现,原来加锁的底层逻辑是通过lua脚本的方式来实现的。
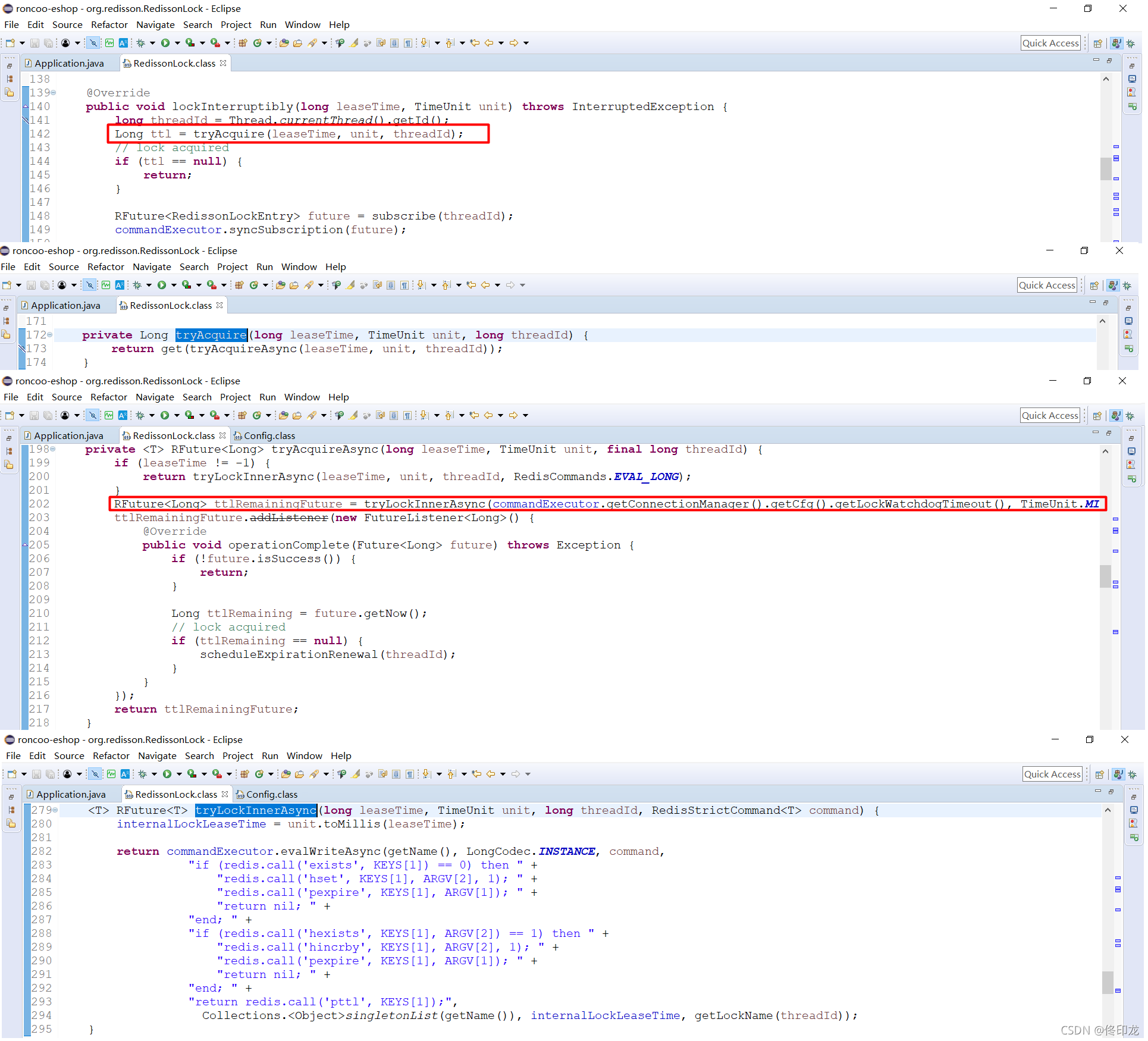
当然我们看到的lua脚本只是一大串长字符串,它只不过是作为方法evalWriteAsync方法的一个参数而已,所以下一步肯定要到evalWriteAsync方法中看下了方法内部的逻辑是怎样的:
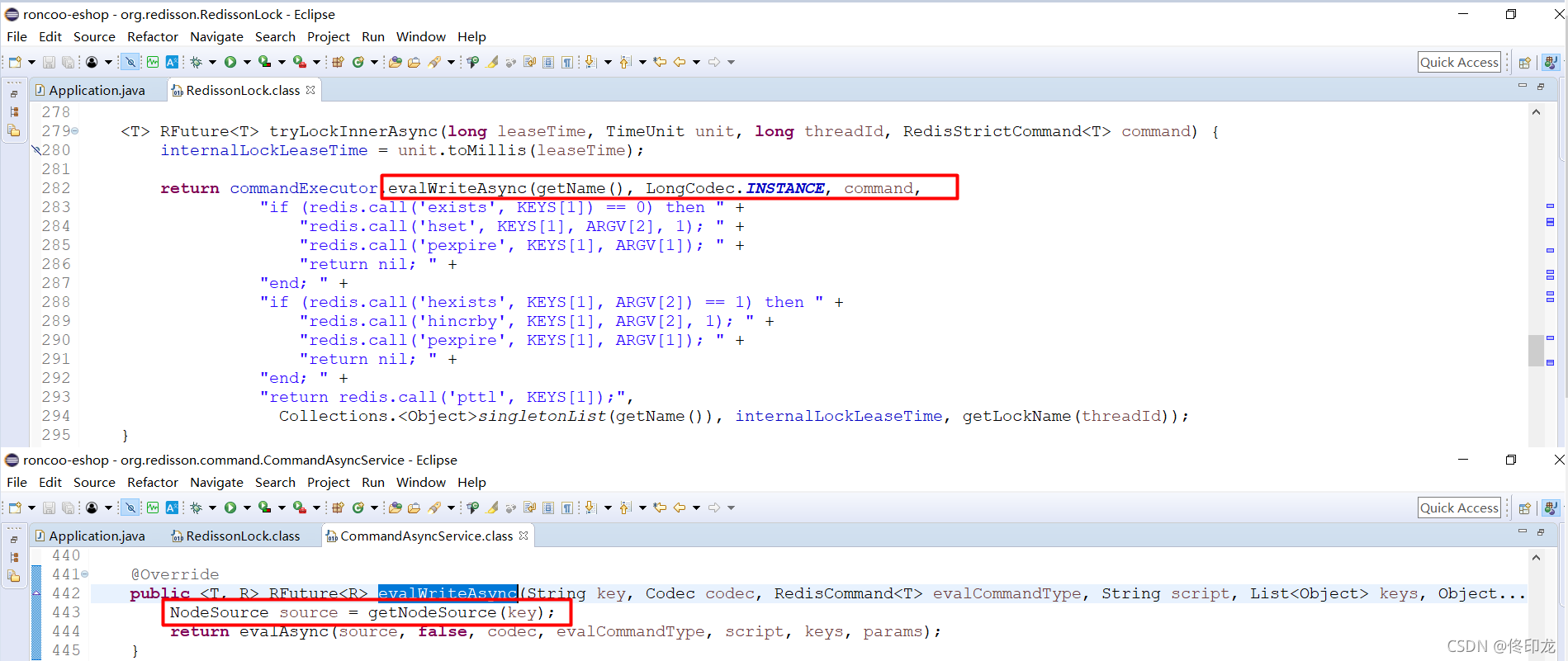
看到这里,我们就发现有点意思了,这里的getNodeSource,好像就是获取源节点、目标master的意思了,越来越靠近我们之前的猜想了,没关系,我们再进去瞧瞧:
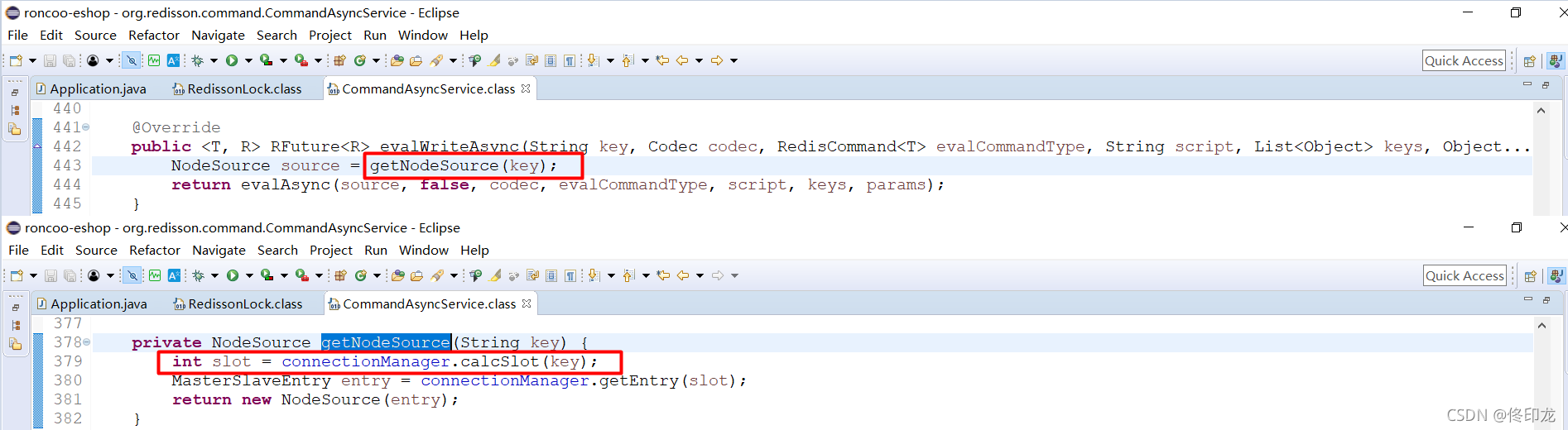
看到这里,关于如何通过key锁定Redis-Cluster集群中、某一个master节点的事几乎真相大白了。
了解过一点Redis-Cluster集群基础知识应该都知道,Redis-Cluster集群中的数据分布式是通过一个一个hash slot方式来实现的,Redis-Cluster集群总共16384个hash slot,它们都会被均匀分布到所有master节点上,这里计算出key的hash slot之后,就可以通过hash slot去看一看哪个master上有这个hash slot,如果哪个master上有个这个hash slot,那么这个key当然就会落到该master节点上,执行加锁指令当然就在该master上执行喽。
但是这里依然还是有层迷雾 ,那就是具体是怎么通过key来计算出对应的hash slot的呢,我们继续往下看:
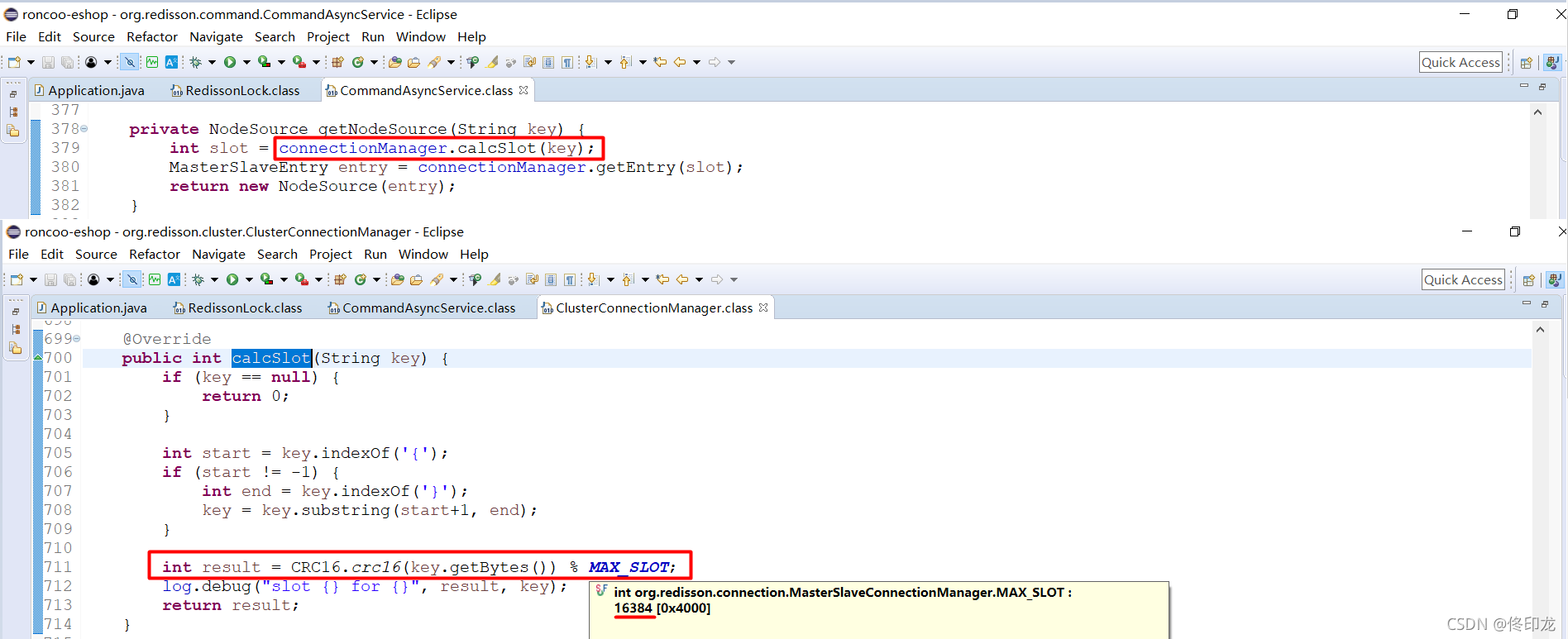
千辛万苦、忐忐忑忑,看到这里算是彻底明白了,首先会通过key计算出CRC16值,然后CRC16值对16384进行取模,进而得到hash slot,如下图所示:
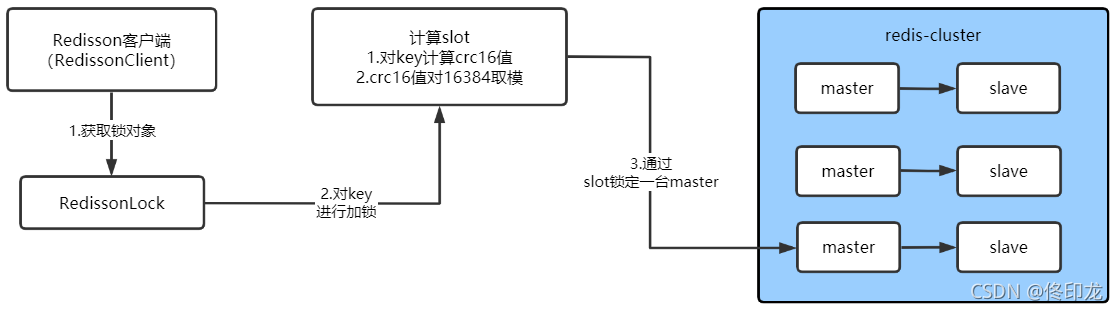
现在我们已经知道了、Redisson客户端是如何通过key锁定Redis-Cluster集群中具体的哪个master节点,那么下一步我们就要进入正式的主题了,即可重入锁的各种加锁、释放锁等等逻辑,这些才是重头戏。
2、客户端线程首次加锁
加锁的逻辑,刚才我们已经瞥到一眼了,就是那堆lua脚本,如下图:
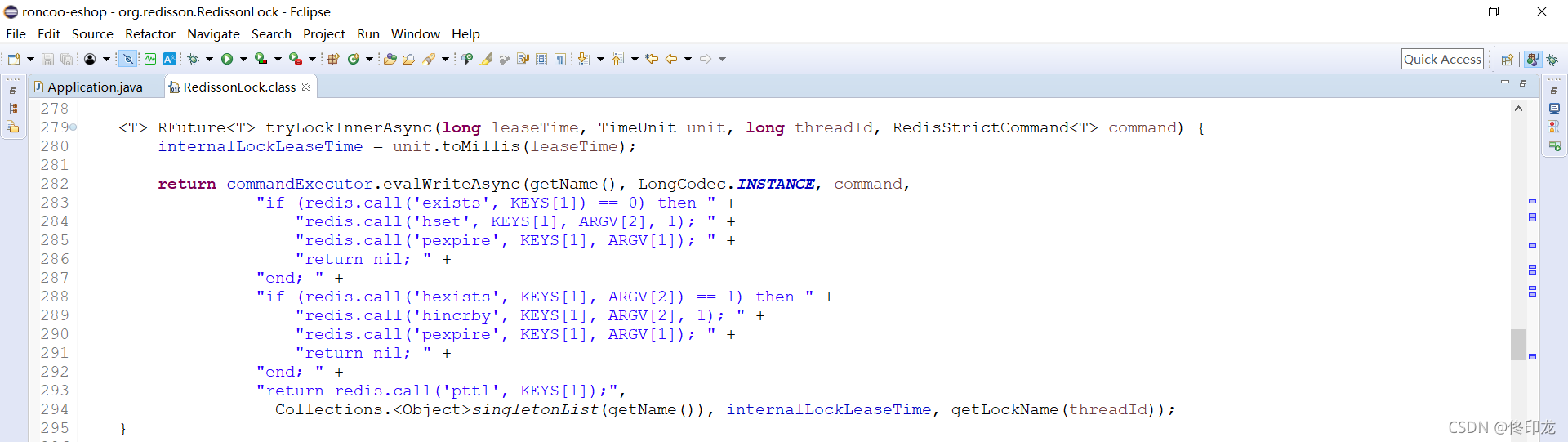
我们一起来看下吧,首先我们看到里面有很多参数比如KEYS[1]和ARGV[1]、ARGV[2],这些参数没搞清楚,这段lua脚本根本看不进去,我们先梳理下这些参数,方便我们阅读这段lua脚本,如下图所示:
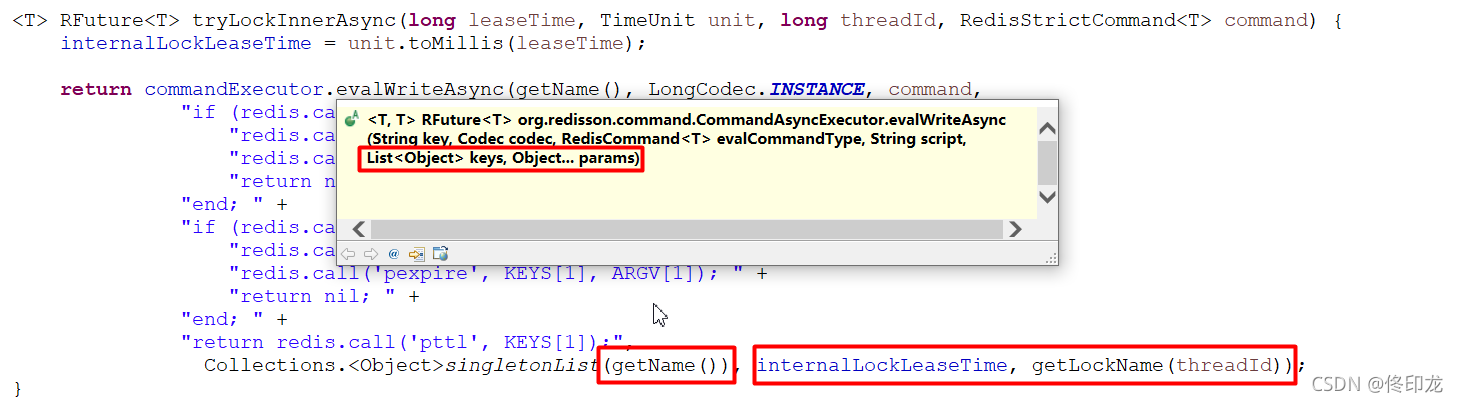
通过方法提示我们可以看到keys和params就是最后的两个参数啊,getName()返回的List对象就是KEYS数组、而ARGV变长数组有两个元素,就是最后这两个参数啊,进去看看吧:
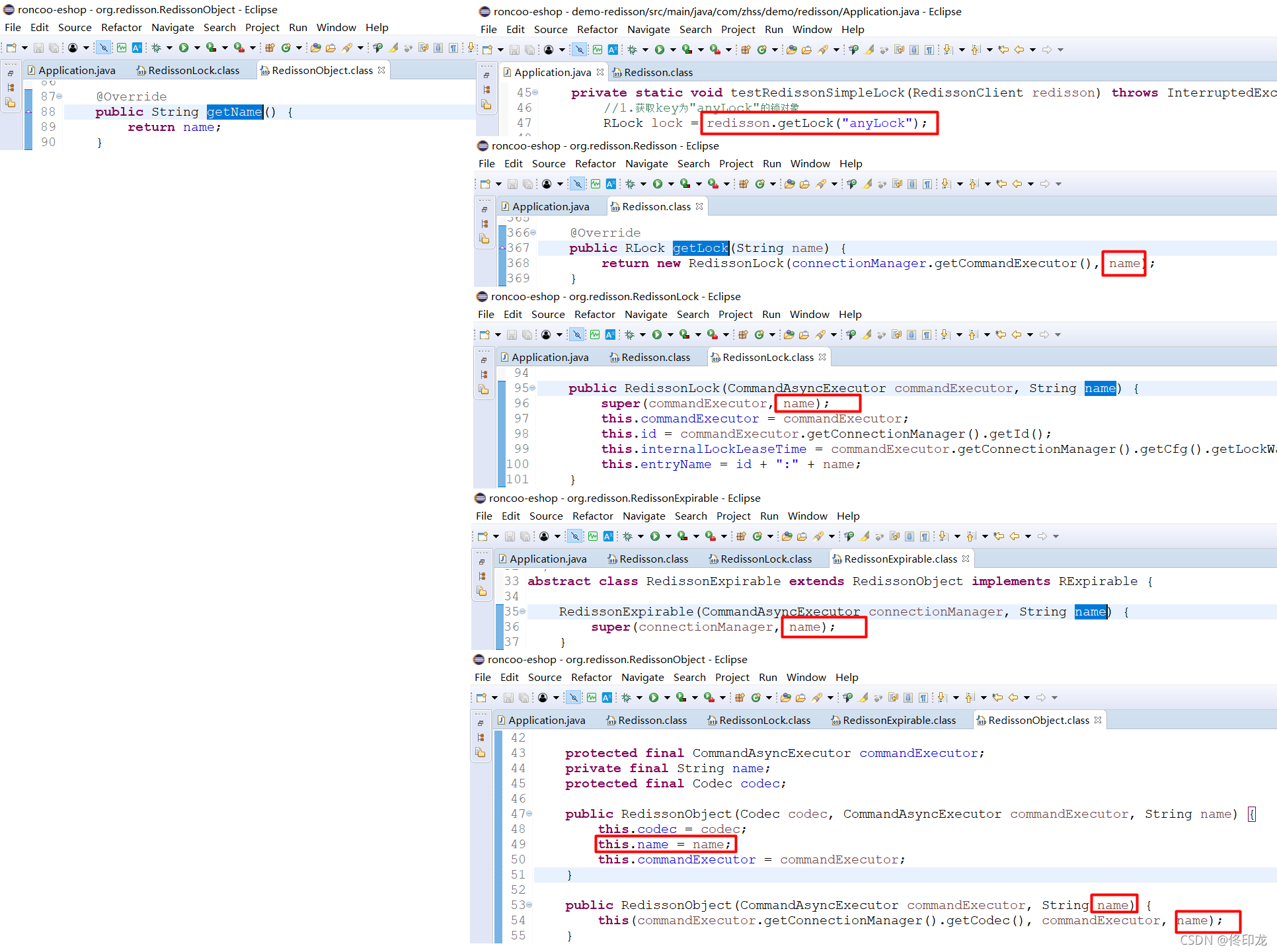
很显然KEYS[1]就是key的名称,Demo里指定的就是"anyLock",ARGV继续看下:
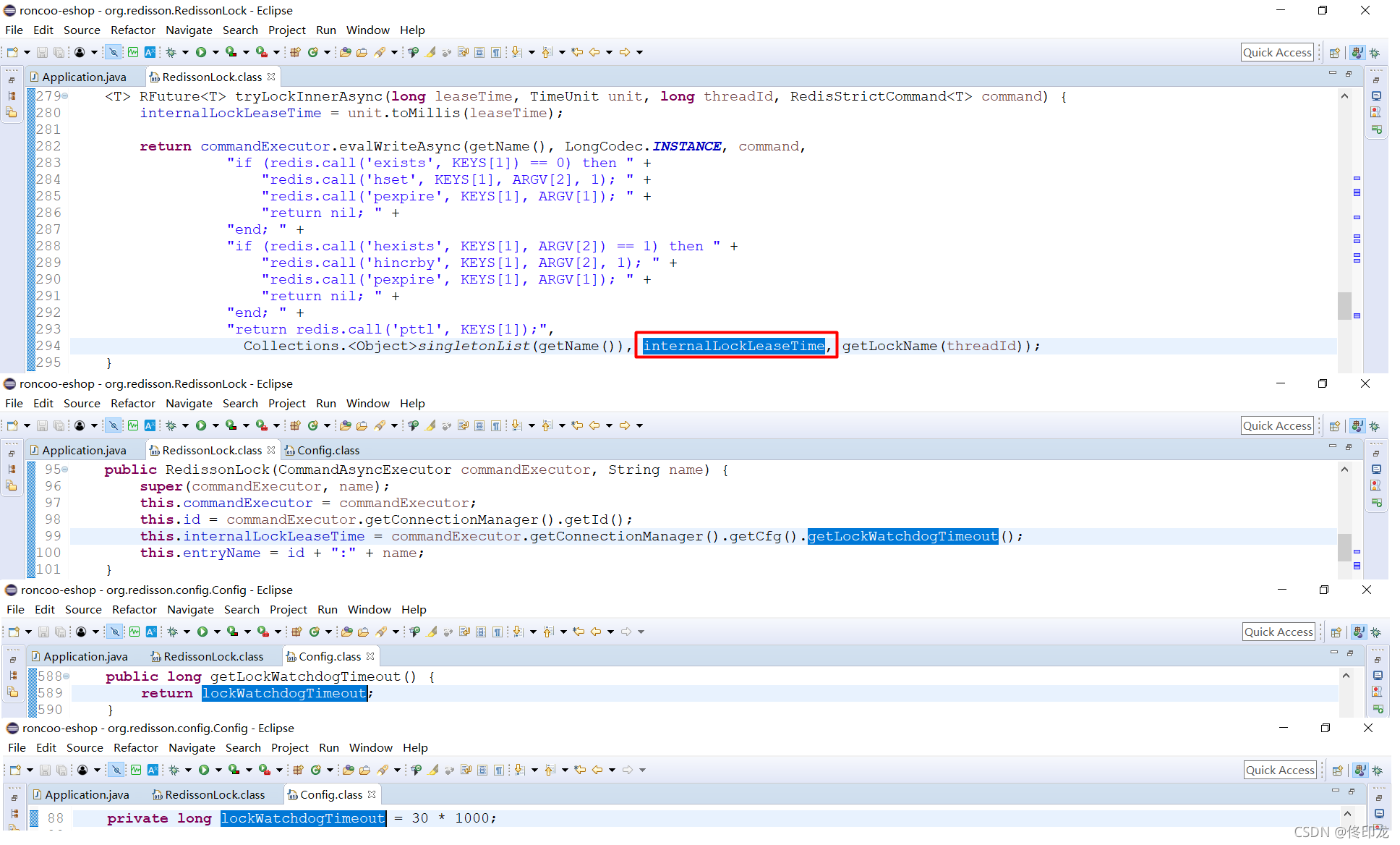
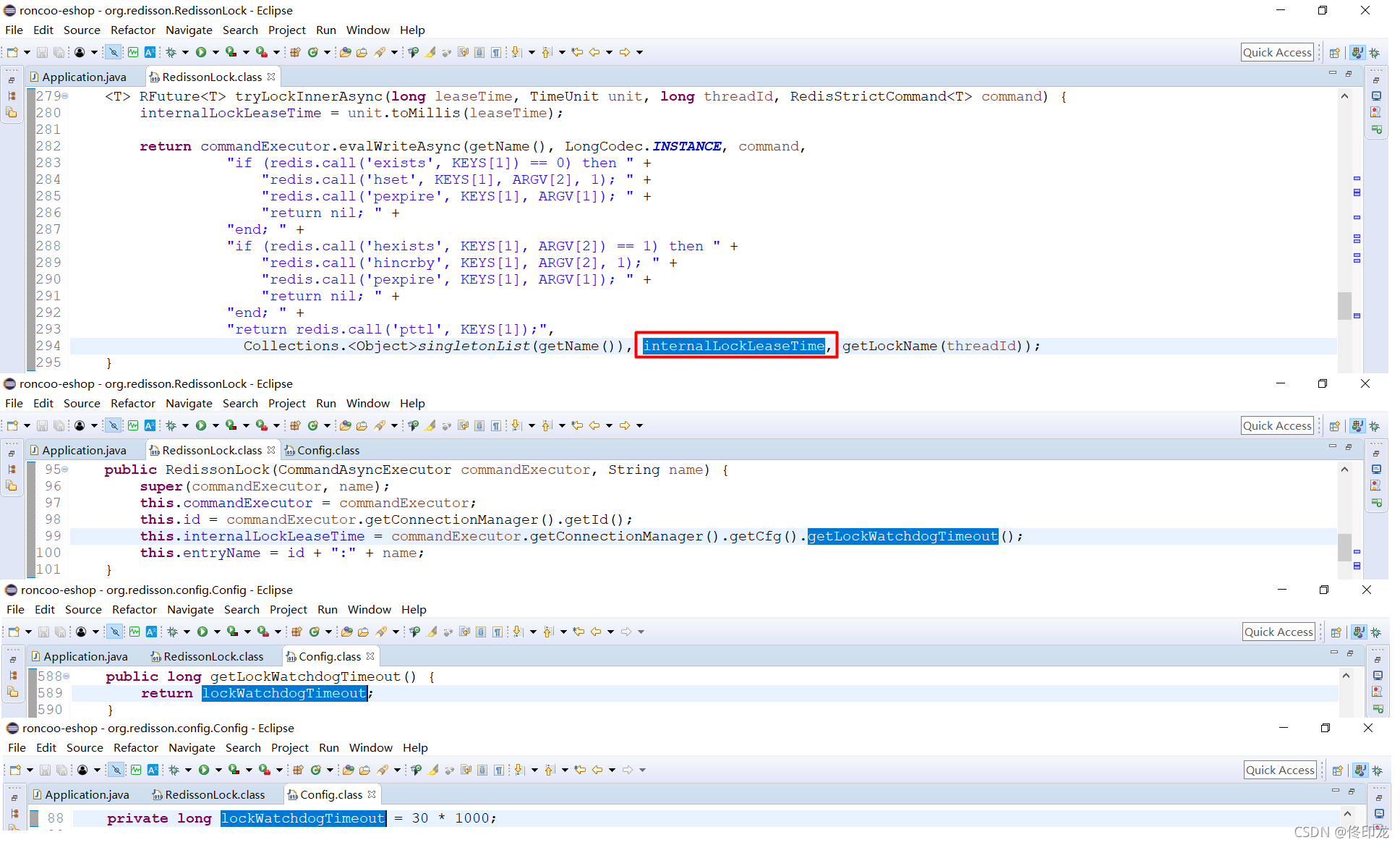
通过这里我们就知道了ARGV[1]的internalLockLeaseTime就是30 * 1000ms,也就是30s了,而ARGV[2]的getLockName(threadId)是什么呢:
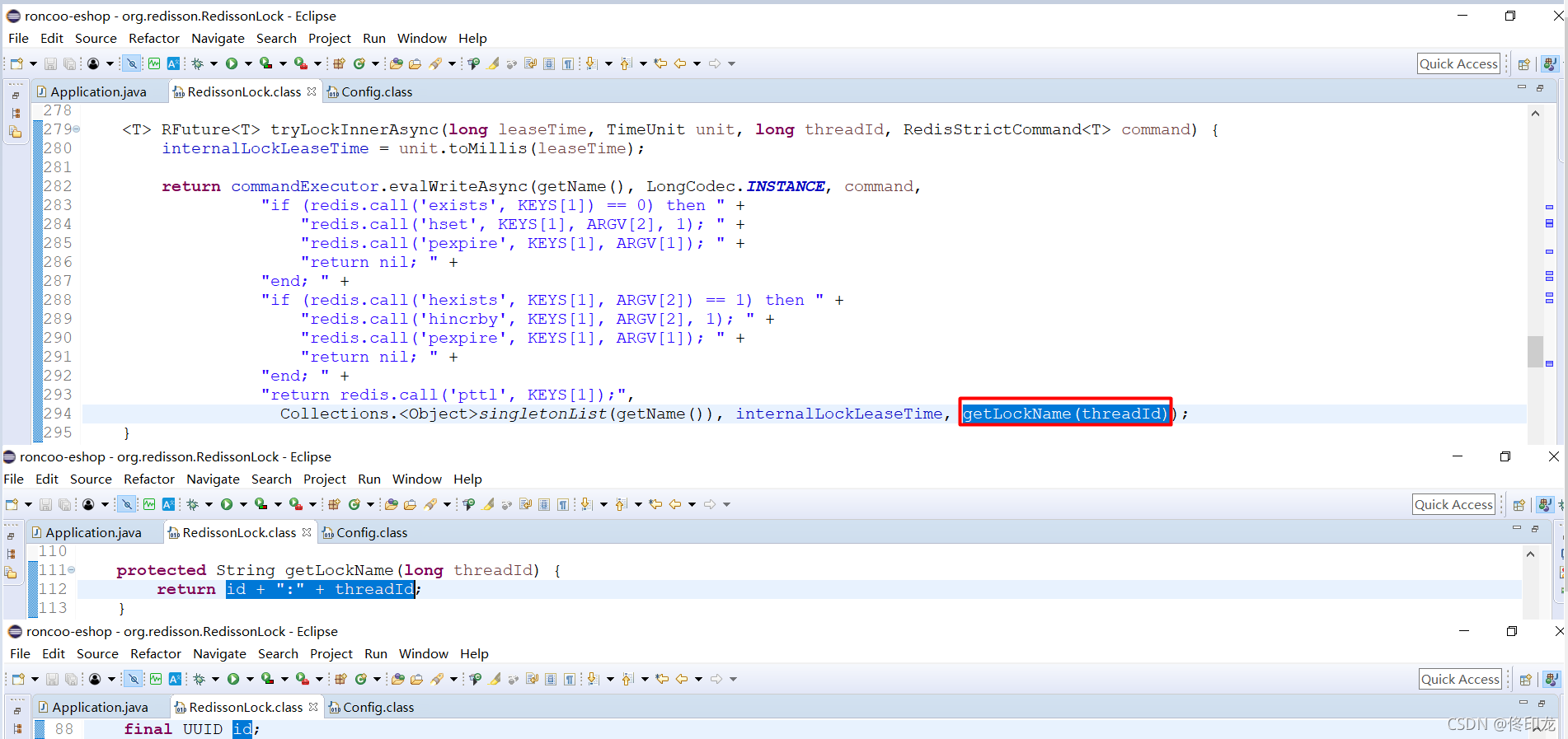
我们发现getLockName(threadId)得到的就是一个UUID:ThreadId。
这里我们可以理解为用UUID来唯一标识一个客户端,毕竟肯定会有多个客户端的多个线程过来加锁,结合起来UUID:ThreadId当然就是表示、具体哪个客户端上的哪个线程过来加锁,通过这样的组合方式能唯一标识一个线程,思路还是挺不错的。
当我们这些准备工作弄好之后,我们就可以正式来看下具体的加锁逻辑了,首先我们看到lua脚本第一段就是:
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
很简单,就是先判断下KEYS[1]这个key在master节点上是否存在,第一次当然肯定不存在啊,所以逻辑成立。
因为我们现在已经知道参数了,接下来执行的lua脚本逻辑、转换成redis指令就是:
hset anyLock UUID:ThreadId 1
pexpire anyLock 30000
hset表示给anyLock这个key的hash数据结构添加数据,类似java中的Map,此时的数据结构大概就是:
anyLock :
{
UUID:ThreadId:1
}
这样的话,就相当于每个key都有一个Map这样的一个hash数据结构,那么为什么每个key都要有这样一个hash数据结构呢?
这个问题很好,我们可以想象下假如你是Redisson的设计者,你会怎么表示一个key当前已经被某个客户端线程持有呢?其实往这个角度想一下,我们大概会想到、那得用一个数据结构记录一下key相关的信息,比如key被线程1持有锁了,那就记录一下key相关的这份信息啊,回想一下好像hash数据结构是最容易想到的了、比较容易也简单明了,而且如果说关于这个key我还要放其他的信息呢,直接在这个key的hash数据结构中添加key-value对就行了;最后至于key为UUID:ThreadId对应的value为1是什么意思呢?我们暂时先埋个伏笔,后文继续揭晓。
紧接着,pexpire这个就是为anyLock这个key设置下key的过期时间为30s,意思就是30s过后、这个key就会自动过期被删除了,当然key对应的锁在那时也就被释放了。
所以我们可以看到,加锁的逻辑也挺简单的,无非就是在key对应的hash数据结构中记录了一下当前是哪个线程过来加锁了,然后设置了一下key的过期时间为30s,可能就是第一次不太好接受它竟然是通过redis中、key的hash数据结构的方式表示加锁的语义,这个我们可以好好体会下。
此时整体流程进度如下图所示:
3、加锁成功后如何维持加锁
当我们成功加锁后,我们看到脚本这里返回的是nil,如下图所示:
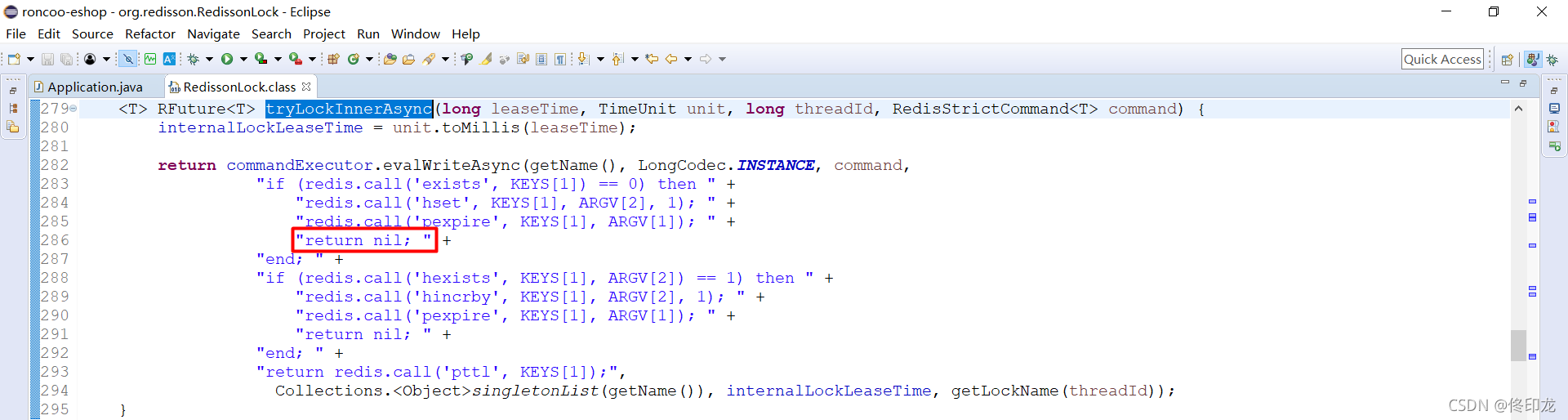
此时加锁成功之后,tryLockInnerAsync方法就返回了,所以下一步当然就要再看下调用tryLockInnerAsync方法的位置在干些什么,如下图所示:
因为我们已经加锁成功了,所以第一个if (!future.isSucess())肯定不成立。
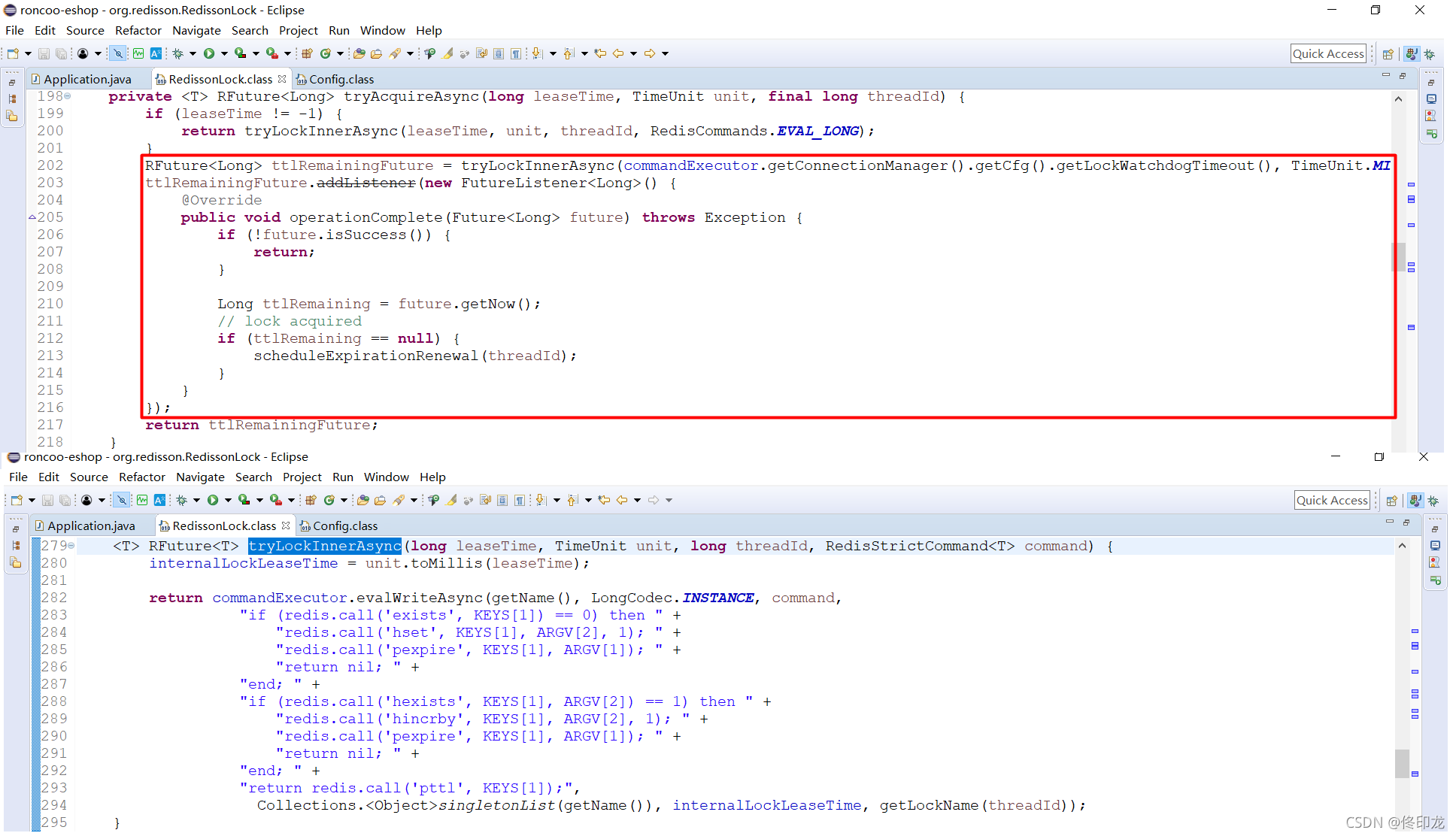
根据上文我们已经知道,加锁成功后返回的是nil,这是lua脚本的返回形式,体现到java代码中当然就是得到null,所以if (ttlRemaining == null)毫无疑问成立了,那就再进入scheduleExpirationRenewal方法看下:
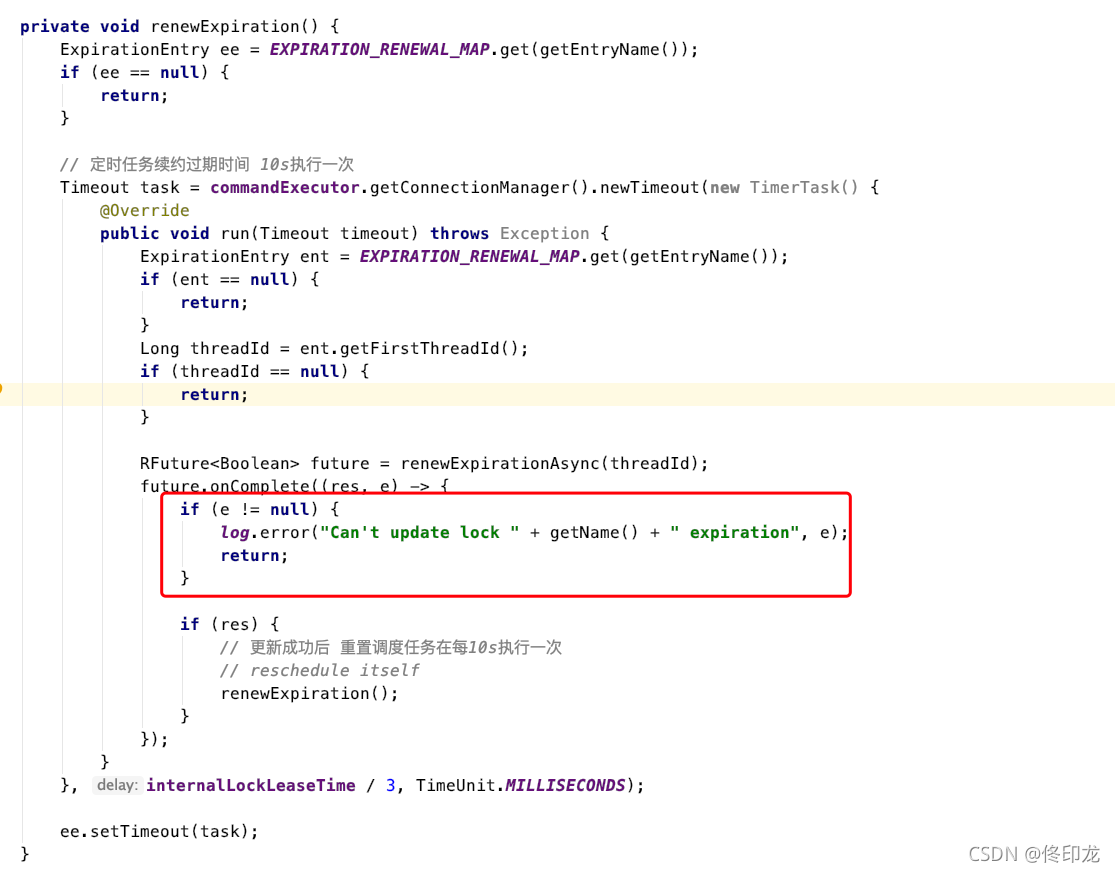
我们会发现当加锁成功之后,这里就会对返回结果ttlRemainingFuture添加一个监听器FutureListener,而监听的核心逻辑当然就在operationComplete方法中,我们可以仔细看下operationComplete方法中在干些什么。
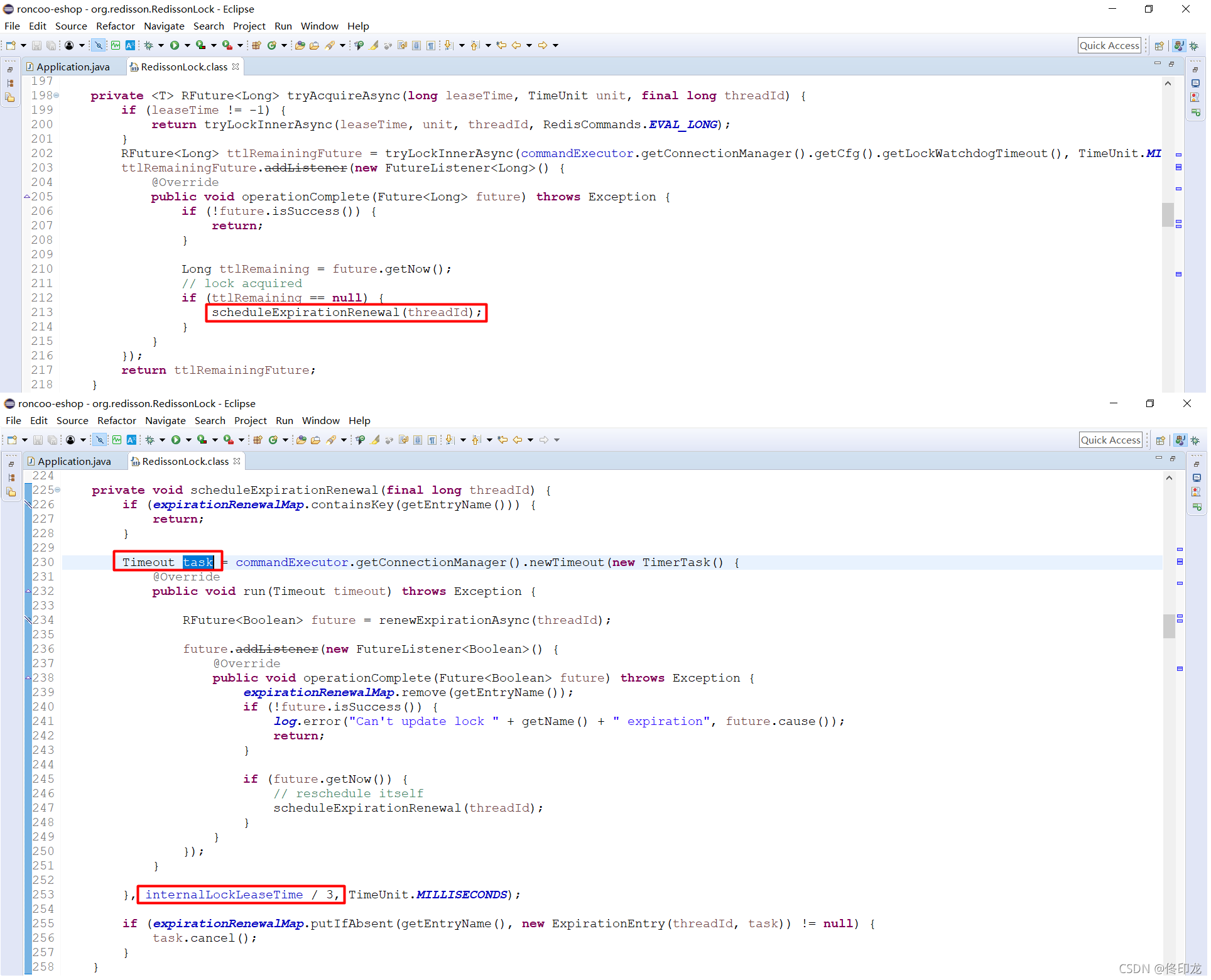
一看瞄过去,我们看到在方法scheduleExpirationRenewal中创建了一个定时任务task,还记得参数internalLockLeaseTime吗,上文中我们为了看lua脚本代码找到发现是301000ms,此时就可以判定这个定时任务的执行周期是每隔301000/3=10*1000ms,也就是每隔10s执行一次。
那这个定时任务到底在干什么呢?为什么获取锁成功要开启一个定时任务呢?我们继续看:
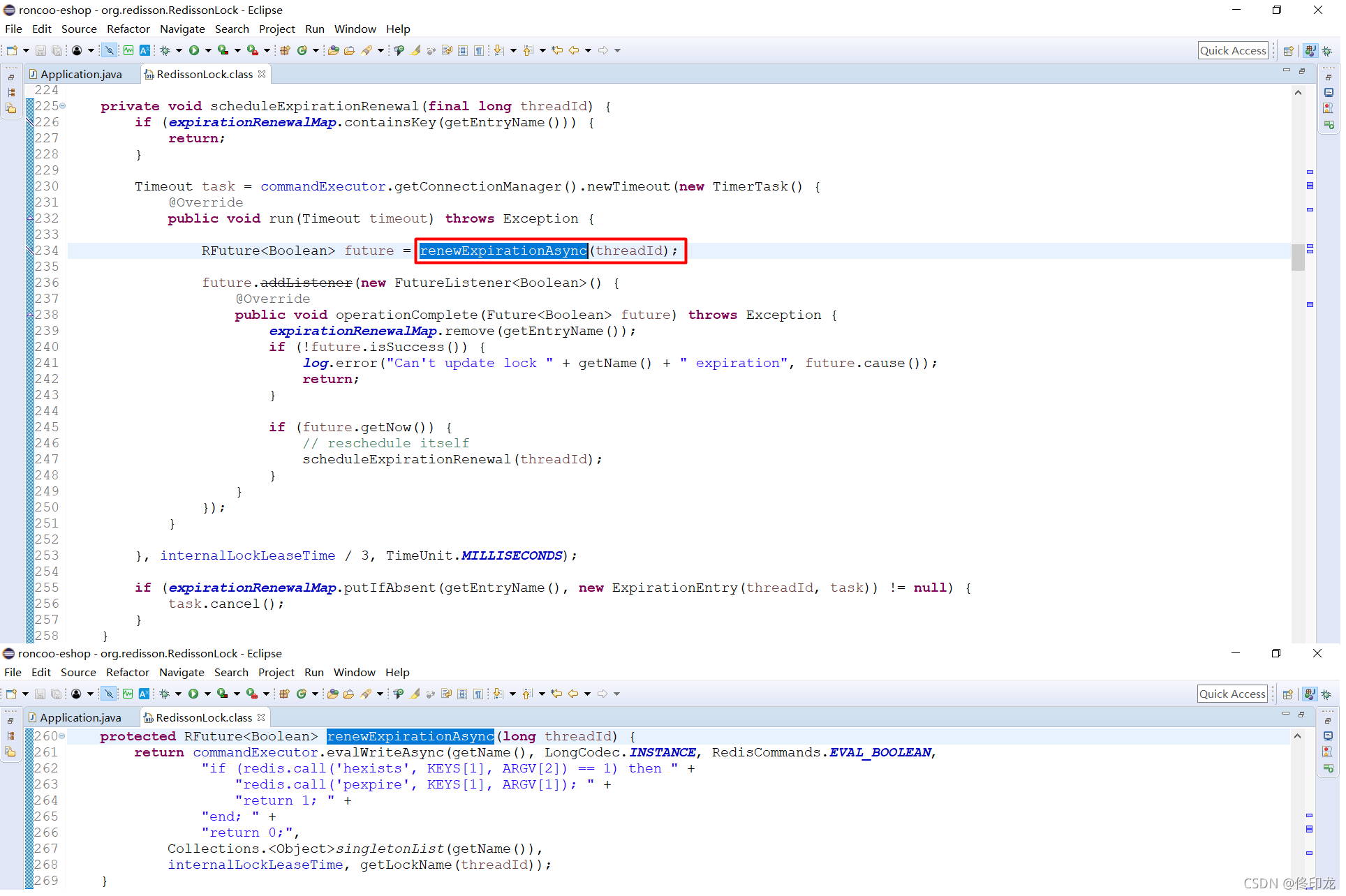
定时任务中的这个方法里面,也是一段lua脚本,幸运的是这段脚本比较小段。
首先第一个if中:
redis.call(‘hexists’, KEYS[1], ARGV[2]) == 1,即:hexists anyLock UUID:ThreadId
表示判断当前key中,是否还被线程UUID:ThreadId持有锁,因为是刚刚加锁完毕当然是持有啊,此时就会对这个key进行续期30s。
原来如此,我们好像又解开一个谜团了:
如何维持加锁,原来每次来加锁成功后,监听加锁结果的监听器就会马上开启一个后台线程,每隔10s检查一下key是否存在,如果存在就为key续期30s。
所以一个key往往当过期时间慢慢消逝到20s左右时就又会被定时任务重置为了30s,这样就能保证、只要这个定时任务还在、只要这个key还在,就能让这个key一直存活下去,也就是一直维持加锁。
这个定时任务的机制在Redisson中也被称为watchdog看门狗机制,毕竟还记得超时时间获取吗,参数命名为lockWatchdogTimeout 为30s,如下图所示。
watchdog看门狗这个机制的命名还挺形象的,好吧,现在我们算是已经知道了客户端是如何维持加锁的了,就是通过一个后台定时任务、每隔10s定时检查key如果存在,就为它自动续期30s。
此时整体流程进度如下图所示:
q:
watchdog怎么感知持有锁线程挂掉,不在续期
a:线程挂的时候,你释放锁
q:问下watchdog本身异常的话是怎么处理的?
a:异常后就不续约了
q:老师,watchdog在哪块代码处判断线程挂掉,从而不在执行续约逻辑
a:他会判断你是否还持有锁,需要主线程去释放锁