大数据伪分布式,从开始一步一步详细配置,配不好打死我
安装好虚拟机VMware
直接从网上下载,比较简单基础,这里就不赘述了
安装Ubuntu系统
安装Java
下载JDK安装包::
第一种方法:官网下载
https://www.oracle.com/java/technologies/javase/javase8-archive-downloads.html
下载的话,可能需要注册账号
第二种:
懒得注册的话可以百度云:
链接:[https://pan.baidu.com/s/1Sx4dAmOCB2VAuhYpllWDew]
提取码:0mgb
java配置
$ mkdir ~/soft
$ cd ~/soft
$ tar -zxvf jdk-8u171-linux-x64.tar.gz
$ ln -s jdk1.8.0_171 jdk
nano ~/.bashrc
在文件末尾添加
export JAVA_HOME=~/soft/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存退出
让环境变量立即生效
$ source ~/.bashrc
验证是否安装成功
$ java -version

安装配置Hadoop
1.下载hadoop2.7.3的安装包

解压安装包
$ cd ~/soft
$ tar -zxvf hadoop-2.7.3.tar.gz
$ ln -s hadoop-2.7.3 hadoop
$ nano ~/.bashrc
在文件末尾添加
export HADOOP_HOME=~/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让环境变量立即生效
$ source ~/.bashrc
设置免密码登录
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
验证ssh node1

配置成Hadoop伪分布式
cd ${HADOOP_HOME}/etc/hadoop
$ nano hadoop-env.sh
更改java环境:
export JAVA_HOME=/home/hadoop/soft/jdk
这里面的java环境一定要和你的对应上
$ echo $JAVA_HOME #查看JAVA_HOME的绝对路径
链接: link.
$ nano core-site.xml
在与之间添加配置内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
<!-- 以上主机名node1要按实际情况修改 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/你的用户名/soft/hadoop/tmp</value>
</property>
$ nano hdfs-site.xml
同样在与之间添加配置内容,配置内容如下:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
$ cp mapred-site.xml.template mapred-site.xml
$ nano mapred-site.xml
同样在与之间添加配置内容,配置内容如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
$ nano yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
nano slaves
$ hdfs namenode -format
启动Hadoop
$ start-dfs.sh
将localhost修改为主机名,例如: node1
图片: 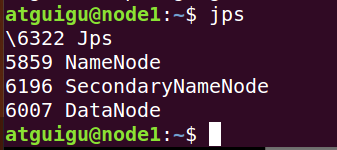
$ start-yarn.sh
对了配置ssh
配置ssh
$ sudo apt-get install openssh-server
$ sudo /etc/init.d/ssh restart
修改映射
$ sudo nano /etc/hostname
将原有内容删除,添加如下内容,修改成新的主机名,例如:node1
$ sudo reboot
$ sudo nano /etc/hosts
把第二行127.0.1.1换成Ubuntu的IP地址
你的ip node1
参考原文链接
https://blog.csdn.net/qq_42881421/article/details/88781764