ЮЂаХ дЮФСДНг,дФЖСИќЪцЪЪ!!
ГдЭИЁКMySQLЁЛЯЕСа
?ЮЂаХЙЋжкКХ:ЁИаЁСњcodingЁЙ
ЙизЂбЁдёЁИаЧБъЁЙ,жиАѕИЩЛѕ,ЕквЛЪБМфЫЭДя!
ШчЙћФуОѕЕУЮФеТЖдФугаАяжњ,ЛЖгЁИЙизЂ,дкПД,Еудо,зЊЗЂЁЙ!
ЙизЂЯТЗНЙЋжкКХЁОаЁСњcodingЁП ЛиИДЁОЛљгкШЫЙЄжЧФмЕФаЃдАжњЪжЁПСьШЁДѓГЇУцЪдОЋЦЗЯюФП,ЁОжњСІРёАќЁПСьШЁЖьГЇДѓРаЧяеаУцЪджњСІРёАќЁЃ
?
ДѓМвКУ,ЮвЪЧаЁСњЁЃ
зюНќЪеЕНКмЖраЁЛяАщЫНаХ,НаЮвЯЕЭГНВНтвЛЯТMySQLЁЃЫЕЦ№MySQL,етПЩЪЧЮвЧПЯюжЎвЛАЁ,ЧяеаЦОНшMySQLЕФЖРЕНРэНтШУУцЪдЙйЖдЮветИіЖўБОЩњвВЙЮФПЯрПДЁЃ
вђДЫ,ЮвДђЫуПЊвЛИіЁИГдЭИMySQLЯЕСаЁЙЕФзЈРИЁЃ
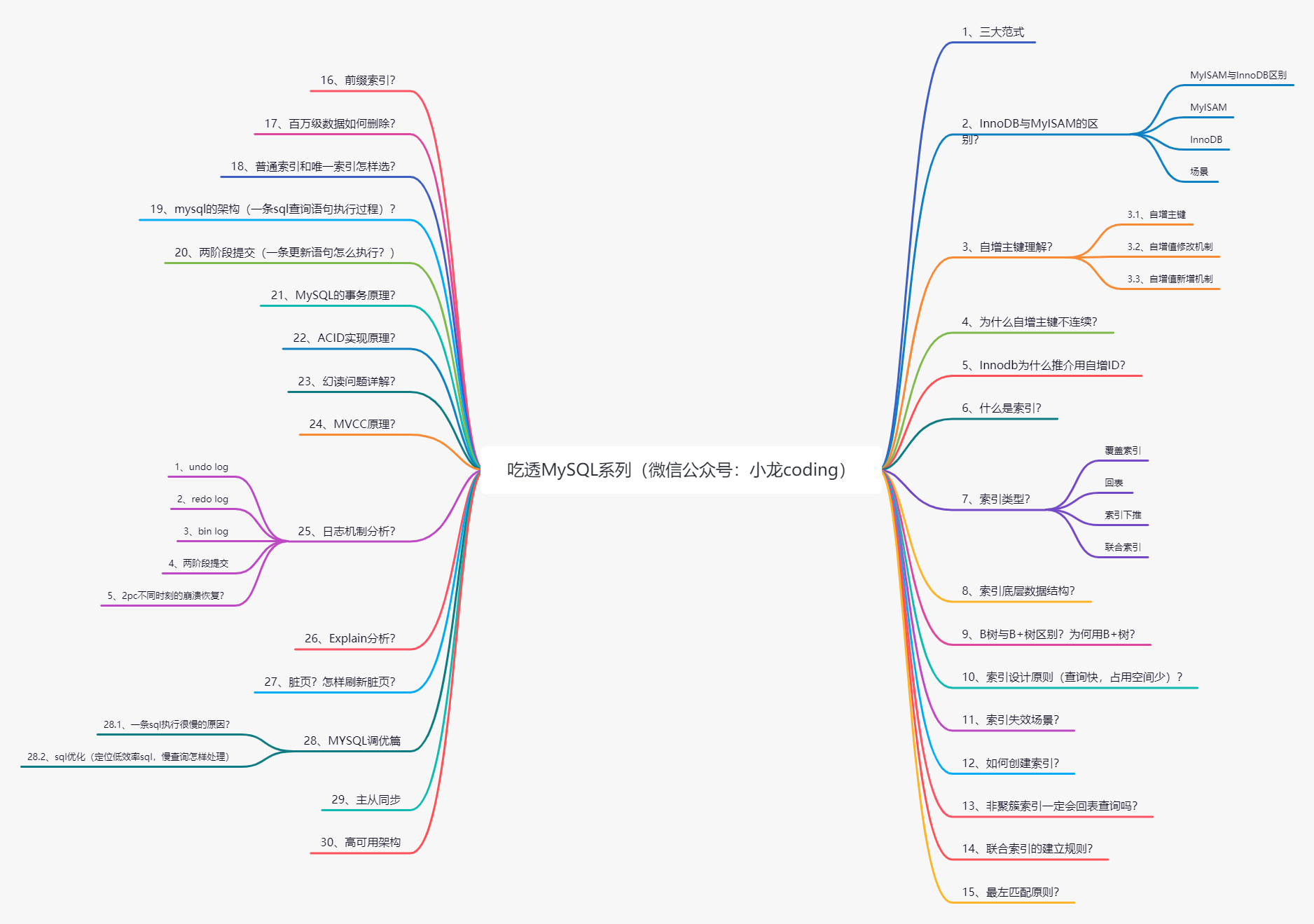
БОЮФНЋзїЮЊБОзЈРИЁИГдЭИMySQLЯЕСаЁЙФПТМ,вВЪЧДѓГЇУцЪдБъзМЛиД№,ОпЬхУПИіЕуЕФЯъЯИНтЮіЛсЪеТМгкБОзЈРИ,ЙизЂЁОаЁСњcodingЁП,ГжајдФЖСКѓајОЋЦЗЮФеТ!!
?БОЮФЪеТМгкЁОУцЪдБЪМЧЁП,ИќЖрИЖЗбЮФеТ,ПЩвдКѓЬЈЛиИДЁОУцЪдБЪМЧЁПЛёШЁ,ЁОЕуЛїЪдЖСЁПЁЃЁЃ
?
1ЁЂ Ш§ДѓЗЖЪН?
ЕквЛЗЖЪН:зжЖЮОпгадзгад,ВЛПЩдйЗж(зжЖЮЕЅвЛжАд№)
ЕкЖўЗЖЪН:ТњзуЕквЛЗЖЪН,УПаагІИУБЛЮЈвЛЧјЗж,МгвЛСаДцЗХУПааЕФЮЈвЛБъЪЖЗћ,ГЦЮЊжїМќ(ЖМвЊвРРЕжїМќ)
ЕкШ§ЗЖЪН:ТњзувЛЖўЗЖЪН,ЧввЛИіБэВЛФмАќКЌЦфЫћБэвбДцдкЕФЗЧжїМќаХЯЂ(ВЛМфНгвРРЕ-ВЛДцдкЦфЫћБэЕФЗЧжїМќаХЯЂ)
ЁИЗЖЪНгХЕугыШБЕуЁЙ:
ЁИгХЕуЁЙ:ЗЖЪНЛЏ,жиИДШпгрЪ§ОнЩй,ИќаТПь,аоИФЩй,ВщбЏЪБИќЩйЕФdistinctЁЃ
ЁИШБЕуЁЙ:вђЮЊвЛИіБэВЛДцдкШпгржиИДЪ§Он,ЁИВщбЏПЩФмдьГЩКмЖрЙиСЊЁЙ,аЇТЪБфЕЭ,ПЩФмЪЙвЛаЉЁИЫїв§ВпТдЮоаЇЁЙ,ЗЖЪНЛЏНЋСаДцдкВЛЭЌБэжа,етаЉСаШєдкЭЌвЛИіБэжаПЩвдЪЧвЛИіЫїв§ЁЃ
2ЁЂInnoDBгыMyISAMЕФЧјБ№?
2.1ЁЂMyISAMгыInnoDBЧјБ№
-
InnoDBОлДиЫїв§,MyISAMЗЧОлДиЫїв§ -
InnoDBЪ§ОнгыЫїв§вЛЦ№БЃДц.ibd,MyISAMБэНсЙЙ.frm Ыїв§.myi Ъ§Он.myd -
InnoDBжЇГжЪТЮёЁЂЭтМќЁЂааЫјБэЫј,MyISAMВЛжЇГжЪТЮёЁЂЭтМќЁЂжЛжЇГжБэЫј -
select count(*) -
MyISAMВщбЏИќгХ,InnoDBИќаТИќгХ -
ЖМЪЧB+treeЫїв§ -
MyISAMжЇГжШЋЮФЫїв§,InnoDB5.6КѓжЇГж
2.2ЁЂMyISAM
-
ВЛжЇГжЪТЮё,ЕЋЪЧУПДЮВщбЏЖМЪЧдзгЕФ -
жЇГжБэМЖЫј,УПДЮВйзїЖдећИіБэМгЫј -
ДцДЂБэЕФзмааЪ§ -
вЛИіMyISAMБэгаШ§ИіЮФМў:БэНсЙЙ.frm Ыїв§.myi Ъ§Он .myd -
ВЩгУЗЧОлМЏЫїв§,Ыїв§ЮФМўЕФЪ§ОнгђДцДЂжИЯђЪ§ОнЮФМўЕФжИеыЁЃИЈЫїв§гыжїЫїв§ЛљБОвЛжТ,ЕЋЪЧИЈЫїв§ВЛгУБЃжЄЮЈвЛадЁЃ
2.3ЁЂInnoDB
-
жЇГжACIDЪТЮё,жЇГжЫФжжИєРыМЖБ№ -
жЇГжааМЖЫјМАЭтМќдМЪј,вђДЫжЇГжаДВЂЗЂ -
ВЛДцДЂзмааЪ§ -
жїМќЫїв§ВЩгУОлМЏЫїв§(Ыїв§ЕФЪ§ОнгђДцДЂЪ§ОнЮФМўБОЩэ),ИЈЫїв§ЕФЪ§ОнгђДцДЂжїМќЕФжЕ;вђДЫДгИЈЫїв§ВщевЪ§Он,ашвЊЯШЭЈЙ§ИЈЫїв§евЕНжїМќжЕ,дйЗУЮЪИЈЫїв§;зюКУЪЙгУзддіжїМќ,ЗРжЙВхШыЪ§ОнЪБ,ЮЊЮЌГжB+ЪїНсЙЙ,ЮФМўЕФДѓЕїећЁЃ
2.4ЁЂЪЙгУГЁОА
ДѓЖрЪ§ЪБКђЮвУЧЪЙгУЕФЖМЪЧ InnoDB ДцДЂв§Чц,дкФГаЉЖСУмМЏЕФЧщПіЯТ,ЪЙгУ MyISAM вВЪЧКЯЪЪЕФЁЃВЛЙ§,ЧАЬсЪЧФуЕФЯюФПВЛНщвт
MyISAM ВЛжЇГжЪТЮёЁЂБРРЃЛжИДЕШШБЕу(ПЩЪЧ~ЮвУЧвЛАуЖМЛсНщвтАЁ!)ЁЃ
-
MyISAMЪЪКЯЖСЖрИќаТЩйЕФ:MyISAMЫїв§ИњЪ§ОнЗжПЊЗХ,вђДЫгаЖСШЁИќПьЕФЫЕЗЈЁЃ -
InnoDBЪЪКЯВхШыИќаТЦЕЗБЕФ:Ыїв§гыЪ§ОнвЛЦ№ЗХ,НЈСЂЫїв§ИќИДдг,ЪЙгУааЫј,ИќаТЦЕЗБаЇТЪИќИп -
ашвЊЪТЮё,ИпВЂЗЂГЁОАгУInnoDB:InnoDBжЇГжЪТЮё,ВЩгУааЫј -
MyISAMВщбЏБШInnoDBПь,ИќаТInnoDBПь
ЁИГЁОАЁЙ:MyISAMВщбЏИќгХ,InnoDBИќаТИќгХЁЃ
MyISAMЪЪКЯЖСЖр,ИќаТЩйЕФГЁОАЁЃMyISAMЪЙгУЗЧОлДиЫїв§,Ъ§ОнКЭЫїв§ЗжПЊДцЕФ,ЖјInnoDBЪ§ОнКЭЫїв§ДцвЛЦ№ЕФ,
Ъ§ОнСПДѓЪБ,вЛИіФкДцвГДѓаЁЙЬЖЈ,ЖСНјФкДцЕФЪ§ОнMyISAMОЭЖрвЛЕу(Ъ§ОнСПаЁПДВЛГіВюОр,Ъ§ОнСПДѓЪБВюОрОЭУїЯд)ЁЃ
вђЮЊMyISAMжЛАбЫїв§жИеыЖСНјФкДц,ПЩвдДцИќЖр,ВщбЏЫйЖШвВОЭИќПь,ЖјЧвInnoDBЛЙашвЊЮЌЛЄЦфЫћЪ§Он,БШШчЦфЫћвўВизжЖЮ row_id tx_idЕШЁЃ
3ЁЂзддіжїМќРэНт?
зддіжїМќ
InnoDBв§ЧцЕФзддіжЕ,ЦфЪЕЪЧЁИБЃДцдкСЫФкДцЁЙРя,ВЂЧвЕНСЫMySQL 8.0АцБОКѓ,ВХгаСЫЁАзддіжЕГжОУЛЏЁБЕФФмСІ,вВОЭЪЧВХЪЕЯжСЫЁАШчЙћЗЂЩњжиЦє,БэЕФзддіжЕПЩвдЛжИДЮЊMySQLжиЦєЧАЕФжЕЁБ,ОпЬхЧщПіЪЧ:(ВщПДБэНсЙЙ,ЛсПДЕНзддіжїМќ=ЖрЩй)ЁЃ
-
дкMySQL 5.7МАжЎЧАЕФАцБО,ЁИзддіжЕБЃДцдкФкДцРяЁЙ,ВЂУЛгаГжОУЛЏЁЃУПДЮжиЦєКѓ,ЕквЛДЮДђПЊБэЕФЪБКђ,ЖМЛсШЅевЁИзддіжЕЕФзюДѓжЕЁЙ
max(id),ШЛКѓНЋmax(id)+1зїЮЊетИіБэЕБЧАЕФзддіжЕЁЃ
?ОйР§РДЫЕ,ШчЙћвЛИіБэЕБЧАЪ§ОнааРязюДѓЕФidЪЧ10,AUTO_INCREMENT=11ЁЃетЪБКђ,ЮвУЧЩОГ§id=10ЕФаа,AUTO_INCREMENTЛЙЪЧ11ЁЃЕЋШчЙћТэЩЯжиЦєЪЕР§,жиЦєКѓетИіБэЕФAUTO_INCREMENTОЭЛсБфГЩ10ЁЃ вВОЭЪЧЫЕ,MySQLжиЦєПЩФмЛсаоИФвЛИіБэЕФAUTO_INCREMENTЕФжЕЁЃ
?
-
дкMySQL 8.0АцБО,НЋзддіжЕЕФБфИќМЧТМдкСЫredo logжа,жиЦєЕФЪБКђвРППredo logЛжИДжиЦєжЎЧАЕФжЕЁЃ
зддіжЕаоИФЛњжЦ
-
ШчЙћВхШыЪ§ОнЪБidзжЖЮжИЖЈЮЊ0ЁЂnull ЛђЮДжИЖЈжЕ,ФЧУДОЭАбетИіБэЕБЧАЕФ AUTO_INCREMENTжЕЬюЕНзддізжЖЮЁЃ -
ШчЙћВхШыЪ§ОнЪБidзжЖЮжИЖЈСЫОпЬхЕФжЕ,ОЭжБНгЪЙгУгяОфРяжИЖЈЕФжЕЁЃ
зддіжЕаТдіЛњжЦ
-
ШчЙћзМБИВхШыЕФжЕ>=ЕБЧАзддіжЕ,аТЕФзддіжЕОЭЪЧЁАзМБИВхШыЕФжЕ+1ЁБ; -
Зёдђ,зддіжЕВЛБфЁЃ
4ЁЂЮЊЪВУДзддіжїМќВЛСЌај
-
дкMySQL 5.7МАжЎЧАЕФАцБО,зддіжЕБЃДцдкФкДцРя,ВЂУЛгаГжОУЛЏ -
ЪТЮё ЁИЛиЙіЁЙ(зддіжЕВЛФмЛиЭЫ,вђЮЊВЂЗЂВхШыЪ§ОнЪБ,ЛиЭЫзддіIDПЩФмдьГЩжїМќГхЭЛ) -
ЮЈвЛМќГхЭЛ(гЩгкБэЕФзддіжЕвбБф,ЕЋЪЧжїМќЗЂЩњГхЭЛУЛВхНјШЅ,ЯТвЛДЮВхШыжїМќ=ЯждкБфСЫЕФзгдіжЕ+1,ЫљвдВЛСЌај)
ЁИeg:ЁЙ
МйЩш,БэtРяУцвбОгаСЫ(1,1,1)етЬѕМЧТМ,етЪБЮвдйжДаавЛЬѕВхШыЪ§ОнУќСю:
insert?into?t?values(null,?1,?1);?(зддіid,ЮЈвЛМќc,ЦеЭЈзжЖЮd)
етИігяОфЕФжДааСїГЬОЭЪЧ:
-
жДааЦїЕїгУInnoDBв§ЧцНгПкаДШывЛаа,ДЋШыЕФетвЛааЕФжЕЪЧ(0,1,1); -
InnoDBЗЂЯжгУЛЇУЛгажИЖЈзддіidЕФжЕ,ЛёШЁБэtЕБЧАЕФзддіжЕ2; -
НЋДЋШыЕФааЕФжЕИФГЩ(2,1,1); -
НЋБэЕФзддіжЕИФГЩ3; -
МЬајжДааВхШыЪ§ОнВйзї,гЩгквбОДцдкc=1ЕФМЧТМ,ЫљвдБЈDuplicate key error,гяОфЗЕЛиЁЃ
етИіБэЕФзддіжЕИФГЩ3,ЪЧдкеце§жДааВхШыЪ§ОнЕФВйзїжЎЧАЁЃетИігяОфеце§жДааЕФЪБКђ,вђЮЊХіЕНЮЈвЛМќcГхЭЛ,Ыљвдid=2етвЛааВЂУЛгаВхШыГЩЙІ,ЕЋвВУЛгаНЋзддіжЕдйИФЛиШЅЁЃ
Ыљвд,дкетжЎКѓ,дйВхШыаТЕФЪ§ОнааЪБ,ФУЕНЕФзддіidОЭЪЧ3ЁЃЁИвВОЭЪЧЫЕ,ГіЯжСЫзддіжїМќВЛСЌајЕФЧщПіЁЙЁЃ
5ЁЂInnodbЮЊЪВУДЭЦНщгУзддіID
ЂйжїМќвГОЭЛсНќКѕгкЫГађЕФМЧТМЬюТњ,ЬсЩ§СЫвГУцЕФзюДѓЬюГфТЪ,ВЛЛсгавГЕФРЫЗб
ЂкаТВхШыЕФаавЛЖЈЛсдкдгаЕФзюДѓЪ§ОнааЯТвЛаа,mysqlЖЈЮЛКЭбАжЗКмПь,ВЛЛсЮЊМЦЫуаТааЕФЮЛжУЖјзіГіЖюЭтЕФЯћКФ
ЂлМѕЩйСЫвГЗжСбКЭЫщЦЌЕФВњЩњ
ЁИUUIDЁЙ:ЁИДѓСПЕФЫцЛњIOЁЙ+ЁИвГЗжСбЕМжТвЦЖЏДѓСПЕФЪ§ОнЁЙ+Ъ§ОнЛсгаЫщЦЌ
ЁИзмНсЁЙ:зддіIDгаађ,ЛсАДЫГађЭљзюКѓВхШы,ЖјUUIDЮоађ,ЫцЛњЩњГЩ,ЫцЛњВхШы,ЛсдьГЩЦЕЗБвГЗжСб,ФкДцЫщЦЌЛЏ,ДѓСПЫцЛњIO
Ыїв§
6ЁЂЪВУДЪЧЫїв§
-
ХХКУађЕФЪ§ОнНсЙЙ,ПЩвдАяжњПьЫйВщевЪ§Он -
гХШБЕу:Ыїв§ПЩвдЬсИпВщбЏЫйЖШ,ВщбЏЪЙгУгХЛЏвўВиЦїЬсИпадФм,ЕЋЪЧвВЛсеМОнЮяРэПеМф,НЕЕЭдіЩОИФЕФЫйЖШ,вђЮЊЛЙвЊВйзїЫїв§ЮФМў
7ЁЂЫїв§РраЭ(ИВИЧЫїв§+ЛиБэ+Ыїв§ЯТЭЦ+СЊКЯЫїв§)
ЁИЦеЭЈЫїв§ЁЙ:ПЩвджиИД
ЁИЮЈвЛЫїв§ЁЙ:ЮЈвЛ,ПЩЮЊПе,БэжажЛгавЛИіжїМќЫїв§,ПЩЖрИіЮЈвЛЫїв§
ЁИжїМќЫїв§ЁЙ
-
ЮЈвЛ,ВЛЮЊПе,вЖзгНсЕуДцГіСЫааМЧТМЪ§Он,жїМќЫїв§вВГЦОлДиЫїв§,ЖдгІЗЧжїМќЫїв§ЕФвЖзгНсЕуДцЕФжїМќЕФжЕ(ЖўМЖЫїв§),гУЖўМЖЫїв§ВщашвЊЛиБэВйзї(ИљОнЖўМЖЫїв§ВщЕНжїМќ,дйИљОнжїМќШЅжїМќЫїв§Вщ) -
вЛАуЭЦМігУзддіжїМќ, ЁИБЃжЄПеМфРћгУТЪ,МѕЩйвГЗжСбЁЙ
ЁИШЋЮФЫїв§ЁЙ
ЁИИВИЧЫїв§ЁЙ:Ыїв§зжЖЮИВИЧСЫВщбЏгяОфЩцМАЕФзжЖЮ,жБНгЭЈЙ§Ыїв§ЮФМўОЭПЩвдЗЕЛиВщбЏЫљашЕФЪ§Он,ВЛБиЭЈЙ§ЛиБэВйзїЁЃ
ЁИЛиБэЁЙ:ЭЈЙ§Ыїв§евЕНжїМќ,дйИљОнжїМќidШЅжїМќЫїв§Вщ
ЁИЫїв§ЯТЭЦЁЙ
-
дкИљОнЫїв§ВщбЏЙ§ГЬжаОЭИљОнВщбЏЬѕМўЙ§ТЫЕєвЛаЉМЧТМ,МѕЩйзюКѓЕФЛиБэВйзї
?МйШчжДаа select * from stu where name=? and age=? ,УЛгаЫїв§ЯТЭЦЯШдйДцДЂв§ЧцИљОнnameЩИбЁЪ§ОнЗЕЛиИјserverВу,ШЛКѓserverВудйИљОнageЙ§ТЫгаЫїв§ЯТЭЦжБНгИљОнnameКЭageдкДцДЂв§ЧцВуОЭЩИбЁЕУЕННсЙћЁЃ
?
ЁИСЊКЯЫїв§ЁЙ:зщКЯЫїв§(зюзѓЧАзКддђ)
8ЁЂЫїв§ЕзВуЪ§ОнНсЙЙ?
B+ЪїЁЂhash
hashЕзВуЪЧЙўЯЃБэЪЕЯж,ЕШжЕВщбЏ,ПЩвдПьЫйЖЈЮЛ,вЛАуЧщПіаЇТЪКмИп,ВЛЮШЖЈ,ЕБГіЯжДѓСПМќжиИДЙўЯЃГхЭЛ,аЇТЪЯТНЕ,ВЛжЇГжЗЖЮЇ
ВщбЏ,ЮоЗЈгУгкХХађЗжзщ,ЮоЗЈФЃК§ВщбЏ,ЖрСаЫїв§ЕФзюзѓЧАзКЦЅХфддђ,змвЊЛиБэВйзїЕШЁЃ
9ЁЂBЪїгыB+ЪїЧјБ№?ЮЊКЮгУB+Ъї?
ЁИB+ЪїЁЙ:ЗЧвЖзгНсЕуВЛДцdata,жЛДцkey,ВщбЏИќЮШЖЈ,діДѓСЫЙуЖШ(B+ЪїГіЖШИќДѓ,ЪїИпАЋ,НкЕуаЁ,ДХХЬIOДЮЪ§Щй);вЖзгНсЕуЯТвЛМЖжИеы(ЗЖЮЇВщбЏ);Ыїв§ШпгрЁЃ
гыКьКкЪїЯрБШ
ЁИИќЩйВщбЏДЮЪ§ЁЙ:B+ЪїГіЖШИќДѓ,ЪїИпИќЕЭ,ВщбЏДЮЪ§ИќЩй
ЁИДХХЬдЄЖСдРэЁЙ:ЮЊСЫМѕЩйIOВйзї,ЭљЭљВЛбЯИёАДашЖСШЁ,ЖјЪЧдЄЖСЁЃB+ЪївЖзгЁИНсЕуДцДЂЯрСйЁЙ,ЁИЖСШЁЛсПьвЛаЉЁЙЁЃ
ЁИДцДЂИќЖрЫїв§НсЕуЁЙ:B+ЪїжЛдквЖзгНсЕуДЂДцЪ§Он,ЗЧвЖзгНсЕуДцЫїв§,ЖјвЛИіНсЕуОЭЪЧДХХЬвЛИіФкДцвГ,ФкДцвГДѓаЁЙЬЖЈ;
ФЧУДЯрБШBЪїетаЉПЩвдДцЁИИќЖрЁЙЕФЫїв§НсЕу,ЁИГіЖШИќДѓЁЙ,ЪїИпАЋ,ВщбЏДЮЪ§Щй,ЁИДХХЬIOЩйЁЙЁЃ
10ЁЂЫїв§ЩшМЦддђ(ВщбЏПь,еМгУПеМфЩй)
-
ГіЯждкwhereзгОфЛђдђСЌНгзгОфжаЕФСа -
ЛљЪ§аЁЕФБэУЛБивЊ -
ЪЙгУЖЬЫїв§,ШчЙћЫїв§ГЄзжЗћДЎСа,гІИУжИЖЈЧАзКГЄЖШ -
ЖЈвхгаЭтМќЕФЪ§ОнСавЛЖЈЫїв§ -
ВЛвЊЙ§ЖШЫїв§ -
ИќаТЦЕЗБЕФВЛЪЪКЯ -
ЧјЗжЖШВЛИпЕФВЛЪЪКЯ,ШчадБ№ -
ОЁСПРЉеЙЫїв§,Б№аТНЈЫїв§,Шч(a)->(a,b) -
зжЗћДЎзжЖЮНЈСЂЫїв§ЗНЗЈ -
1ЁЂжБНгДДНЈЭъећЫїв§,етбљПЩФмБШНЯеМгУПеМф; -
2ЁЂДДНЈЧАзКЫїв§,НкЪЁПеМф,ЕЋЛсдіМгВщбЏЩЈУшДЮЪ§,ВЂЧвВЛФмЪЙгУИВИЧЫїв§; -
3ЁЂЕЙађДцДЂ,дйДДНЈЧАзКЫїв§,гУгкШЦЙ§зжЗћДЎБОЩэЧАзКЕФЧјЗжЖШВЛЙЛЕФЮЪЬт; -
4ЁЂЖюЭтгУвЛИізжЖЮНјааЫїв§,ЖюЭтМЦЫуПЊЯњ
-
ЁИзмНсЁЙ:
ЂйЫїв§ЩшМЦддђвЊЧѓВщбЏПь,еМгУПеМфЩй;
ЂквЛАуНЈдкwhereЬѕМў,ЦЅХфЖШИпЕФ;
ЂлвЊЧѓЛљЪ§Дѓ,ЧјЗжЖШИп,ВЛвЊЙ§ДѓЫїв§,ОЁСПРЉеЙ,гУСЊКЯЫїв§,ИќаТЦЕЗБВЛЪЪКЯЁЂЪЙгУЖЬЫїв§ЁЃ
11ЁЂЫїв§ЪЇаЇГЁОА?
-
вдЁА%ЁБПЊЭЗЕФlikeгяОф,Ыїв§ЮоаЇ,КѓзКЁА%ЁБВЛгАЯь -
orгяОфЧАКѓУЛгаЭЌЪБЪЙгУЫїв§ -
СаРраЭЪЧзжЗћДЎ,вЛЖЈвЊдкЬѕМўжаНЋЪ§ОнгУ ЁИв§КХв§гУЁЙ,ЗёдђЪЇаЇ(вўЪНзЊЛЛ) -
ШчЙћMySQLЙРМЦЪЙгУШЋБэЩЈУшБШЫїв§Пь,дђВЛгУЫїв§(МќжЕЩй,жиИДЪ§ОнЖр) -
зщКЯЫїв§вЊзёЪи ЁИзюзѓЧАзКддђЁЙЁЊЁЊВЛЪЙгУЕквЛСаЫїв§ ЪЇаЇ -
дкЫїв§зжЖЮЩЯЪЙгУnot,<>,!= (ЖдЫќДІРэЪЧШЋБэЩЈУш) -
ЖдЫїв§зжЖЮНјааМЦЫуВйзї,зжЖЮЪЙгУ ЁИКЏЪ§ЁЙвВЛсЪЇаЇ -
is null
12ЁЂШчКЮДДНЈЫїв§
-
ALTER TABLE table_name ADD INDEX index_name (column_list); -
CREATE INDEX index_name ON table_name (column_list); -
дкcreate tableЪБДДНЈ
13ЁЂЗЧОлДиЫїв§вЛЖЈЛсЛиБэВщбЏТ№
ВщбЏзжЖЮШЋВПУќжаЫїв§,ЁИИВИЧЫїв§ЁЙ,ВЛзпЛиБэ,жБНгДгЫїв§ЕУЕННсЙћ,ВЛвЊВщЪ§ОнЮФМўЁЃ
ЁИзмНсЁЙ:ИВИЧЫїв§ОЭВЛзпЛиБэ
14ЁЂСЊКЯЫїв§ЕФНЈСЂЙцдђ
-
НЋ ЁИВщбЏашЧѓЦЕЗБЁЙЛђеп ЁИзжЖЮбЁдёадИпЁЙЕФСаЗХдкЧАУц -
Ыїв§ЕФ ЁИИДгУЁЙ,ПЩвдЩйЮЌЛЄвЛаЉЫїв§(a)->(a,b) -
ШчЙћМШгаСЊКЯВщбЏ,гжгаЛљгкaЁЂbИїздЕФВщбЏФи? ЁИПМТЧЕФддђОЭЪЧПеМф,НЋаЁЕФЕЅЖРНЈЫїв§ЁЙ
-
-
ЦеЭЈЫїв§КЭЮЈвЛЫїв§дѕбљбЁ?
15ЁЂзюзѓЦЅХфддђ
ДгзѓЭљгвЦЅХф,жБЕНгіЕНЗЖЮЇВщбЏ
НЈСЂСЊКЯЫїв§(a,b,c)
Ыїв§ЪЧЯШИљОнaХХађ,aЯрЭЌЪБbгаађ,aВЛЭЌЮоађ,вдДЫРрЭЦЁЃзмжЎгіЕНЗЖЮЇВщбЏОЭЭЃЁЃ
(a,b)СЊКЯЫїв§?????[(2,4),(),()]
????????????????????\|/????\|/
???[(1,1),(1,2),(2,1)]?????[(2,4),(3,1),(3,2)]
ЙцТЩ:aгаЫГађ(1,1,2,2,2,3,3)bЮоЫГађ,aЯрЭЌЪБbгжгаЫГађ,ВЛЭЌaжЎМфbУЛгаЫГађ,Ыљвдa=1,b>2зпСЊКЯЫїв§;a>1,b>2ВЛзпЫїв§ЁЃ
select?*?from?table_name?where?a?=?'1'?and?b?=?'2'?and?c?=?'3'
//ШЋжЕЦЅХфВщбЏ,гУЕНЫїв§,гыЫГађЮоЙи,ВщбЏгХЛЏЦї,ЛсздЖЏгХЛЏВщбЏЫГађ?
select?*?from?table_name?where?a?=?'1'?
select?*?from?table_name?where?a?=?'1'?and?b?=?'2'??
select?*?from?table_name?where?a?=?'1'?and?b?=?'2'?and?c?=?'3'
//ЦЅХфзѓБпЕФСаЪБ,гУЕНСЫЫїв§
select?*?from?table_name?where??b?=?'2'?
select?*?from?table_name?where??c?=?'3'
select?*?from?table_name?where??b?=?'1'?and?c?=?'3'
//УЛгагУЕНЫїв§
select?*?from?table_name?where?a?=?'1'?and?c?=?'3'?
//aгУЕНСЫЫїв§,bЁЂcУЛгаЕН
select?*?from?table_name?where??a?>?1?and?a?<?3?and?b?>?1;
//жЛгаaгУЕНЫїв§,дк1<a<3ЕФЗЖЮЇФкbЪЧЮоађЕФ,ВЛФмгУЫїв§,евЕН1<a<3ЕФМЧТМКѓ,жЛФмИљОнЬѕМў?b?>?1МЬајж№ЬѕЙ§ТЫ
select?*?from?table_name?where??a?=?1?and?b?>?3;
//?a=1ЕФЧщПіЯТbЪЧгаађЕФ,НјааЗЖЮЇВщевзпЕФЪЧСЊКЯЫїв§?зп?a?bЫїв§(aЯрЭЌЪБbгаађ)
16ЁЂЧАзКЫїв§
ОЁСПДДНЈЖЬЫїв§,ЖдГЄзгзжЗћДЎДДЫїв§ПЩЪЙгУЧАзКЫїв§,ЪЙгУзжЖЮжЕЧАМИИізжЗћзїЮЊЫїв§ index(filed(10))
17ЁЂАйЭђМЖЪ§ОнШчКЮЩОГ§
ЩОГ§Ъ§ОнЕФЫйЖШКЭДДНЈЕФЫїв§Ъ§СПЪЧГЩе§БШЕФЁЃЯШЩОЫїв§,дйЩОЮогУЪ§Он,дйДДНЈЫїв§
18ЁЂЦеЭЈЫїв§КЭЮЈвЛЫїв§дѕбљбЁ
ЁИВщбЏБШНЯЁЙ:
ВщбЏЛсвдвГЮЊЕЅЮЛНЋЪ§ОнвГМгдиНјФкДц,ВЛашвЊвЛЬѕМЧТМвЛЬѕМЧТМЖСШЁДХХЬЁЃШЛКѓЮЈвЛЫїв§ИљОнЬѕМўВщбЏЕНМЧТМЪБОЭЗЕЛиНсЙћ;
ЦеЭЈЫїв§ВщЕНЕквЛЬѕМЧТМЭљКѓБщРњжБЕНВЛТњзуЬѕМў,гЩгкЖМдкФкДцжа,ВЛашвЊДХХЬЖСШЁФЧУДДѓПЊЯњ,ДјРДЕФЁИЖюЭтВщбЏПЊЯњКіТдВЛМЦЁЙЁЃ
ЁИЫљвдВщбЏадФмМИКѕвЛжТЁЙ
ЁИИќаТБШНЯЁЙ:
ЮЈвЛЫїв§гЩгкИќаТЪБвЊМьВщЮЈвЛад,ЫљвдашвЊНЋЪ§ОнвГЯШМгдиНјФкДцВХФмХаЖЯ,ДЫЪБжБНгВйзїФкДц,ВЛашвЊВйзїЁОchange bufferЁПЁЃ
ЁИВЙГфЁЙ:ЦеЭЈЫїв§ШєЪ§ОндйФкДцжажБНгФкДцжаИќаТ,ЗёдђЛсНЋИќаТВйзїЯШМЧТМЕНchannge bufferжа,ЕШЯТвЛДЮВщбЏНЋЪ§ОнЖСЕНФкДцжадйНјааchange bufferРяЯрЙиИќаТВйзїКѓНЋЪ§ОнЗЕЛи;
етбљвЛРД,дйаДЖрЖСЩйЕФЧщПіЯТОЭМѕЩйСЫДХХЬIO,ШєаДЭъОЭТэЩЯВщбЏ,ОЭДѓПЩВЛБигУchange buffer,ВЛЕЋУЛЬсИпЖрЩйаЇТЪЛЙдьГЩЮЌЛЄchange bufferЖюЭтЯћКФ
НЋchange bufferЕФВйзїЖдгІЕНдЪМЪ§ОнвГЕФВйзїГЦЮЊЁИmergeЁЙ(ПЩвдВщбЏРДЪБЖСЕНФкДцдйаоИФЪ§Он,КѓЬЈЯпГЬвВЛсmerge,Ъ§ОнПте§ГЃЙиБевВЛсmerge)
ЁИЪЪКЯГЁОАЁЙ:
аДЖрЖСЩй,бЁгУЦеЭЈЫїв§ИќКУ,ПЩвдРћгУЁИchange bufferЁЙНјааадФмгХЛЏМѕЩйДХХЬIO,НЋИќаТВйзїМЧТМЕНchange bufer,ЕШВщбЏРДСЫНЋЪ§ОнЖСЕНФкДцдйНјаааоИФЁЃ
ЪТЮё&ИєРыЛњжЦ&ШежО&MVCC&ЫјЦЊ
19ЁЂmysqlЕФМмЙЙ(вЛЬѕsqlВщбЏгяОфжДааЙ§ГЬ)
ЁИmysqlЗжЮЊserverВугыДцДЂв§ЧцВу,serverВуАќКЌСЌНгЦїЁЂЗжЮіЦїЁЂгХЛЏЦїЁЂжДааЦїЁЃЁЙ
НгЯТРДвдвЛЬѕsqlВщбЏгяОфжДааЙ§ГЬНщЩмИїИіВПЗжЙІФмЁЃПЭЛЇЖЫжДаавЛЬѕsql:
1ЁЂЪзЯШгЩСЌНгЦїНјааЁИЩэЗнбщжЄ,ШЈЯоЙмРэЁЙ
2ЁЂШєПЊЦєСЫЛКДц,ЛсЁИМьВщЛКДцЁЙЪЧЗёгаИУsqlЖдгІНсЙћ(ЛКДцДцДЂаЮЪНkey-vlaue,keyЪЧжДааЕФsql,valueЪЧЖдгІЕФжЕ)ШєПЊЦєЛКДцгжгаИУsqlЕФгГЩф,НЋНсЙћжБНгЗЕЛи
3ЁЂЗжЮіЦїНјааЁИДЪЗЈгяЗЈЗжЮіЁЙ
4ЁЂгХЛЏЦїЛсЁИЩњГЩжДааМЦЛЎЁЙЁЂбЁдёЫїв§ЕШВйзї,бЁШЁзюгХжДааЗНАИ
5ЁЂШЛКѓРДЕНжДааЦї,ДђПЊБэЕїгУДцДЂв§ЧцНгПк,ж№ааХаЖЯЪЧЗёТњзуВщбЏЬѕМў,ТњзуЗХЕННсЙћМЏ,зюжеЗЕЛиИјПЭЛЇЖЫ;ШєгУЕНЫїв§,ЩИбЁаавВЛсИљОнЫїв§ЩИбЁЁЃ
20ЁЂСННзЖЮЬсНЛ(вЛЬѕИќаТгяОфдѕУДжДаа?)
1ЁЂЁИв§ЧцЁЙЯШИљОнЩИбЁЬѕМўЁИЩИбЁЁЙЖдгІЕФааЗЕЛиЁИИјжДааЦїЁЙ(ШєЖдгІЕФаадкФкДцжБНгЗЕЛи,ЗёдђЯШШЅДХХЬЖСШЁдйЗЕЛи)
2ЁЂЁИжДааЦїжДааЯрЙиИќаТВйзїЁЙШЛКѓЕїгУЁИв§ЧцНгПкаДЛиЁЙИќаТКѓЪ§Он
3ЁЂв§ЧцНЋаТЪ§ОнИќаТЕНФкДц,НЋИќаТВйзїМЧТМЕНredo log,ЁИredo logДІгкprepareЁЙ,ИцжЊжДааЦїжДааЭъ,ПЩЬсНЛЪТЮё
4ЁЂжДааЦїЩњГЩИУВйзїЕФbin log ВЂЁИНЋbin logаДШыДХХЬЁЙ
5ЁЂжДааЦїЕїгУв§ЧцЪТЮёЬсНЛНгПк,в§ЧцАбИеаДШыЕФЁИredo logИФЮЊcommitзДЬЌЁЙ,ИќаТЭъГЩЁЃ
21ЁЂMySQLЕФЪТЮёдРэ
ЁИЪТЮёЁЙ:вЛЯЕСаВйзїзщГЩ,вЊУДШЋВПГЩЙІ,вЊУДШЋВПЪЇАм
ЪТЮёACIDЬиад
-
ЁИдзгадЁЙ:вЛаЉСаВйзївЊУДШЋВПГЩЙІ,вЊУДШЋВПЪЇАм -
ЁИИєРыадЁЙ:ЪТЮёЕФНсЙћжЛгаЬсНЛСЫЦфЫћЪТЮёВХПЩМћ -
ЁИвЛжТадЁЙ:Ъ§ОнПтзмЪБДгвЛИівЛжТзДЬЌБфЕНСэвЛИівЛжТзДЬЌ(ЪТЮёаоИФЧАКѓЕФ ЁИЪ§ОнзмЬхБЃжЄвЛжТ зЊеЫЁЙ) -
ЁИГжОУадЁЙ:ЪТЮёЬсНЛКѓ,ЖдЪ§ОнаоИФгРОУЕФ
ЪТЮёЕФВЂЗЂЮЪЬт
-
ЁИдрЖСЁЙ:ЖСЕНЮДЬсНЛЕФЪ§Он -
ЁИВЛПЩжиИДЖСЁЙ:вЛИіЪТЮёЯТ,СНДЮЖСШЁЪ§ОнВЛвЛжТ(ВржиФкШнЪ§ОнЕФаоИФ) -
ЁИЛУЖСЁЙ:ЪТЮёA АДеевЛЖЈЬѕМўНјааЪ§ОнЖСШЁ, ЦкМфЪТЮёB ВхШыСЫЯрЭЌЫбЫїЬѕМўЕФаТЪ§Он,ЪТЮёAдйДЮАДеедЯШЬѕМўНјааЖСШЁЪБ,ЗЂЯжСЫЪТЮёB аТВхШыЕФЪ§Он ГЦЮЊ ЁИЛУЖСЁЙ( ЁИВржиаТдіЛђЩОГ§,ВхШыЪ§ОнЖСЕНЖрСЫвЛааЁЙ)
ИєРыМЖБ№дРэМАНтОіЮЪЬтЗжЮі
-
ЁИЖСЮДЬсНЛЁЙ: дРэ:жБНгЖСШЁЪ§Он,ВЛФмНтОіШЮКЮВЂЗЂЮЪЬт -
ЁИЖСвбЬсНЛЁЙ:ЖСВйзїВЛМгЫј,аДВйзїМгХХЫћЫј,НтОіСЫдрЖСЁЃ дРэ: ЁИРћгУMVCCЪЕЯжЁЙ,УПвЛОфгяОфжДааЧАЖМЛсЩњГЩRead View(вЛжТадЪгЭМ) -
ЁИПЩжиИДЖСЁЙ:MVCCЪЕЯж,жЛгаЪТЮёПЊЪМЪБЛсДДНЈRead View,жЎКѓЪТЮёРяЕФЦфЫћВщбЏЖМгУетИіRead ViewЁЃНтОіСЫдрЖСЁЂВЛПЩжиИДЖС, ЁИIЁЙ:ПьееЖС(ЦеЭЈВщбЏ,ЖСШЁРњЪЗЪ§Он)ЪЙгУMVCCНтОіСЫЛУЖС, ЁИIIЁЙ:ЕБЧАЖС(ЖСШЁзюаТЬсНЛЪ§Он)ЭЈЙ§МфЯЖЫјНтОіЛУЖС(lock in share modeЁЂfor updateЁЂupdateЁЂdeteteЁЂinsert),МфЯЖЫјдкПЩжиИДЖСЯТВХЩњаЇЁЃ( ЁИФЌШЯИєРыМЖБ№ЁЙ) -
ЁИПЩДЎааЛЏЁЙ: дРэ:ЪЙгУЫј,ЖСМгЙВЯэЫј,аДМгХХЫћЫј,ДЎаажДаа
ЁИзмНсЁЙ:ЖСвбЬсНЛКЭПЩжиИДЖСЪЕЯждРэОЭЪЧMVCC Read ViewВЛЭЌЕФЩњГЩЪБЛњЁЃПЩжиИДЖСжЛдкЪТЮёПЊЪМЪБЩњГЩвЛИіRead View,жЎКѓЖМгУЕФетИі;ЖСвбЬсНЛУПДЮжДааЧАЖМЛсЩњГЩRead ViewЁЃ
22ЁЂACIDЪЕЯждРэ
ЁИдзгадЁЙ:undolog(МЧТМЪТЮёПЊЪМЧАЕФРЯАцБОЪ§Он,ПЩвдБЃжЄдзгВйзї,ЛиЙі,ЪЕЯжMVCCАцБОСД)
ЁИИєРыадЁЙ:MVCC
ЁИГжОУадЁЙ:redo log(МЧТМЪТЮёПЊЦєКѓЖдЪ§ОнЕФаоИФ,ПЩгУгкcrash-safe)
23ЁЂЛУЖСЮЪЬтЯъНт
ЁИЛУЖСЮЪЬтЯъНтЁЙ:
1ЁЂДДНЈtxЪЕбщБэ
DROP?TABLE?IF?EXISTS?`tx`;
CREATE?TABLE?`tx`?(
??`age`?int(5)?DEFAULT?NULL,
??`name`?varchar(5)?DEFAULT?NULL,
??`id`?int(5)?NOT?NULL,
??PRIMARY?KEY?(`id`)
)?ENGINE=InnoDB?DEFAULT?CHARSET=utf8;
--?----------------------------
--?Records?of?tx
--?----------------------------
INSERT?INTO?`tx`?VALUES?('20',?'еХШ§',?'1');
INSERT?INTO?`tx`?VALUES?('20',?'РюЫФ',?'2');
2ЁЂЪЕбщ
ЁИНсТл(заЯИРэНт,НВЪеЛёТњТњ,БОШЫШЯецзмНсЕФ)ЁЙ:
1ЁЂЗЂЯжRRИєРыНчБ№ЁИШєжЛПьееЖСгыЕБЧАЖСУЛгаЛУЖСЮЪЬтЁЙ,ПьееЖС(ЦеЭЈВщбЏ,Шчselect * from table)ЖСШЁОЩЕФРњЪЗАцБО,гУMVCCЪЕЯж(MVCCдРэЯТЮФЗжЮі),ЛсдкЪТЮёПЊЪМЪБЩњГЩвЛИіRead View,жЎКѓЖМгУетИіRead ViewЪЕЯжRRИєРыМЖБ№ЁЃ
#ЕБЧАЖС
select?...?for?update?,select?...?lock?in?share?mode?,update/insert/deleteгяОф
ЖСШЁзюаТЪ§ОнАцБО,вРППМфЯЖЫјЛђдђСйМќЫјНтОіЛУЖС,ЕБФуЪТЮёT1жДааЕБЧАЖС,ШЛКѓЪТЮёT2ВхШыгяОф,ЪТЮёT2ЛсБЛзшШћзЁ,ВхВЛНјШЅЁЃ
2ЁЂЕБФуЪТЮёT1жаЁИЯШжДааПьееЖС,ЪТЮёT2ВхШыЪ§ОнВЂЬсНЛ,ЪТЮёT1дйжДааЕБЧАЖС(БШШчвдЯрЭЌЬѕМўИќаТЪ§Он),ЛсЗЂЯжГіЯжЛУЖСЁЙ,ИќаТЕНСЫаТВхШыааЕФЪ§Он(АзЛАЮФНтЪЭ:ЪТЮё1ЯШвдФГИіЬѕМўБШШчage=20ЕФВщбЏЕУЕН2ЬѕЪ§Он;
ШЛКѓЪТЮё2ВхШыаТЕФЪ§ОнageвВЮЊ20ШЛКѓЬсНЛЪТЮё,ДЫЪБЪТЮё1ИќаТage=20ЕФЪ§Он,ЗЂЯжИќаТЕНСЫ3аа,АбЪТЮёT2аТВхШыЕФФЧаавВИќаТСЫ,ЫљвдЁИЛУЖСзЂжиФуВхШыаТЪ§ОнЖМаоИФИФЕНСЫаТВхШыЕФЪ§Он,ЖјВЛПЩжиИДЖСЪЧФуаоИФСЫФГИіЪ§Он,СНДЮВщбЏЕУЕНВЛвЛжТНсЙћЁЃЁЙ)
ЁИзмНсЁЙ:(ЁИRRИєРыНчБ№ВЂУЛгаЭъШЋНтОіЛУЖСЁЙ)жЛЪЙгУПьееЖМЛђдђЕБЧАЖСВЛЛсЛУЖСЁЃШєЯШПьееЖС,ШЛКѓЕБЧАЖС,ЦкМфАДПьееЖСЯрЭЌЬѕМўВхШыЪ§Он,ЕБЧАЖСОЭЛсЗЂЩњЛУЖСЁЃ
24ЁЂMVCCдРэ
ЖрАцБОВЂЗЂПижЦЁЃ
ЁИдРэЬсСЖзмНсЁЙ:ЪЙгУАцБОСД+Read View
ЁИЯъНтЁЙ:
ЁИАцБОСДЁЙ ЭЌвЛааЪ§ОнПЩФмгаЖрИіАцБО
InnoDBЪ§ОнБэУПааЪ§ОнМЧТМЛсгаМИИівўВизжЖЮ,row_id,ЪТЮёID,ЛиЙіжИеыЁЃ
1ЁЂInnoDBВЩгУжїМќЫїв§(ОлДиЫїв§),ЛсРћгУжїМќЮЌЛЄЫїв§,ШєБэУЛгажїМќ,ОЭгУЕквЛИіЗЧПеЮЈвЛЫїв§,ШєУЛгаЮЈвЛЫїв§,дђгУrow_idетИівўВизжЖЮзїЮЊжїМќЫїв§ЁЃ
2ЁЂЪТЮёПЊЦєЛсЯђЯЕЭГЩъЧывЛИіЪТЮёID,бЯИёЕнді,ЛсЯђааМЧТМВхШызюНќВйзїЫќЕФФЧИіЪТЮёЕФID
3ЁЂundo logЛсМЧТМЪТЮёЧАРЯАцБОЪ§Он,ШЛКѓааМЧТМжаЛиЙіжИеыЛсжИЯђРЯАцБОЮЛжУ,ШчДЫаЮГЩвЛЬѕАцБОСДЁЃвђДЫПЩвдРћгУundo logЪЕЯжЛиЙі,БЃжЄдзгад,ЭЌЪБгУгкЪЕЯжMVCCАцБОСДЁЃ
ЁИRead ViewЁЙЖСвбЬсНЛИєРыМЖБ№ЯТ,ЛсдкУПДЮВщбЏЖМЩњГЩвЛИіRead View,ПЩжиЖСЖСжЛдкЪТЮёПЊЪМЪБЩњГЩвЛИіRead View,вдКѓУПДЮВщбЏЖМгУетИіRead View,вдДЫЪЕЯжВЛЭЌИєРыНчБ№ЁЃ
Read ViewРяУцАќКЌаЉЪВУД?(вЛжТадЪгЭМ)
ЁИвЛИіЪ§зщ+up_limit_id(ЕЭЫЎЮЛ)+low_limit_id(ИпЫЎЮЛ)ЁЙ(етРяЕФup,lowУЛаДДэ,ОЭЪЧетУДЖЈвхЕФ) 1ЁЂЪ§зщРяАќКЌЁИЪТЮёЦєЖЏЪБЁЙЕБЧАЛюдОЪТЮёID(ЮДЬсНЛЪТЮё),ЕЭЫЎЮЛОЭЪЧЛюдОЪТЮёзюаЁID,ИпЫЎЮЛОЭЪЧЯТвЛДЮНЋЗжХфЕФЪТЮёID,вВОЭЪЧФПЧАзюДѓЪТЮёID+1ЁЃ
Ъ§ОнПЩМћадЙцдђЪЧдѕбљЪЕЯжЕФ?
Ъ§ОнАцБОЕФПЩМћадЙцдђ,ОЭЪЧЁИЛљгкЪ§ОнЕФrow trx_idЁЙКЭетИіЁИвЛжТадЪгЭМЁЙ(Read View)ЕФЖдБШНсЙћЕУЕНЕФЁЃ
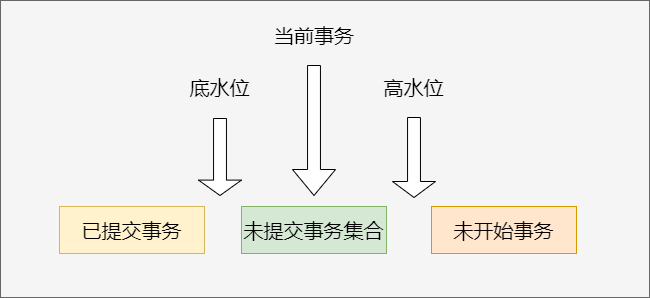
ЁИЖСШЁдРэ:ЁЙ
ФГЪТЮёTвЊЗУЮЪЪ§ОнA,ЯШЛёШЁИУЪ§ОнAжаЕФЪТЮёid(ЛёШЁзюНќВйзїЫќЕФЪТЮёЕФЪТЮёID),ЖдБШИУЪТЮёTЦєЖЏЪБПЬЩњГЩЕФreadview:
1ЁЂ**ШчЙћдкreadviewЕФзѓБп(**БШreadviewЖМаЁ),БэЪОетИіЪТЮёПЩвдЗУЮЪетЪ§Он(дкзѓБпвтЮЖзХИУЪТЮёвбОЬсНЛ)
2ЁЂЁИШчЙћдкreadviewЕФгвБпЁЙ(БШreadviewЖМДѓ),БэЪОетИіАцБОЪЧгЩНЋРДЦєЖЏЕФЪТЮёЩњГЩЕФ,ЪЧПЯЖЈВЛПЩМћЕФ;
3ЁЂЁИШчЙћЕБЧАЪТЮёдкЮДЬсНЛЪТЮёМЏКЯжаЁЙ:
ЁИaЁЙЁЂШє row trx_idдкЪ§зщжа,БэЪОетИіАцБОЪЧгЩЛЙУЛЬсНЛЕФЪТЮёЩњГЩЕФ,ВЛПЩМћ;
ЁИbЁЙЁЂШє row trx_idВЛдкЪ§зщжа,БэЪОетИіАцБОЪЧвбОЬсНЛСЫЕФЪТЮёЩњГЩЕФ,ПЩМћЁЃ
ВЛПЩвдЗУЮЪ,ЛёШЁroll_pointer,ЭЈЙ§АцБОСДШЁЩЯвЛАцБО,ИљОнЪ§ОнРњЪЗАцБОЪТЮёIDдйжиаТгыЪгЭМЪ§зщЖдБШЁЃ
етбљжДааЯТРД,ЫфШЛЦкМфетвЛааЪ§ОнБЛаоИФЙ§,ЕЋЪЧЪТЮёAВЛТлдкЪВУДЪБКђВщбЏ,ПДЕНетааЪ§ОнЕФНсЙћЖМЪЧвЛжТЕФ,ЫљвдЮвУЧГЦжЎЮЊЁИвЛжТадЖСЁЙЁЃ
25ЁЂШежОЛњжЦЗжЮі
ЧАжУжЊЪЖ,ЮЊСЫБЃжЄЪТЮёACIDжаЕФвЛжТадгыдзгад,MySQLВЩгУWAL,дЄаДШежО,ЯШаДШежО,КЯЪЪЪБдйаДДХХЬЁЃ
InnoDBв§ЧцМЖБ№гаundo logгыredo log,MySQL serverМЖБ№гаbin log
ЁИ1ЁЂundo logЁЙ
ЛиЙіШежО
ЁИзїгУЁЙ:undologМЧТМЪТЮёПЊЪМЧАРЯАцБОЪ§Он,гУгкЪЕЯжЛиЙі,БЃжЄдзгад,ЪЕЯжMVCC,ЛсНЋЪ§ОнаоИФЧАЕФОЩАцБОБЃДцдкundolog,ШЛКѓааМЧТМгаИівўВизжЖЮЛиЙіжИеыжИЯђРЯАцБОЁЃ
ЁИ2ЁЂredo logЁЙ
ЮяРэШежО
ЁИзїгУЁЙ:ЛсМЧТМЪТЮёПЊЦєКѓЖдЪ§ОнзіЕФаоИФ,crash-safe
ЁИЬиадЁЙ:ЁИПеМфвЛЖЈ,аДЭъКѓЛсбЛЗаДЁЙЁЃ
гаСНИіжИеыwrite posжИЯђЕБЧАМЧТМЮЛжУ,checkpointжИЯђНЋВСГ§ЕФЮЛжУ,redologЯрЕБгкЪЧИіШЁЛѕаЁГЕ,ЛѕЮяЬЋЖрЪБРДВЛМАвЛМўвЛМўШыПтЬЋТ§СЫетбљ,ОЭЯШНЋЛѕЮяЗХШыаЁГЕ,ЕШЕНЛѕЮяВЛЖрЛђдђаЁГЕТњСЫЛђдђЕъРяПеЯаЪБдйНЋаЁГЕЛѕЮяЫЭЕНПтЗПЁЃ
ДЫЭт,ЛЙгаИіЬиБ№живЊЕФзїгУ,ЁИгУгкcrash-safeЁЙ,Ъ§ОнПтвьГЃЖЯЕчЕШЧщПіПЩгУredo logЛжИДЁЃ
ЁИаДШыСїГЬЁЙ:ЯШаДredo log buffer,ШЛКѓwiteЕНЮФМўЯЕЭГЕФpage cache,ДЫЪБВЂУЛгаГжОУЛЏ,ШЛКѓfsyncГжОУЛЏЕНДХХЬ
ЁИаДШыВпТдЁЙ:ИљОнinnodb_flush_log_at_trx_commitВЮЪ§ПижЦ(ЮвЕФМЧвф:innodbвдЪТЮёЕФЪВУДЬсНЛЗНЪНЫЂаТШежО)
0ЁЊЁЊ>ЪТЮёЬсНЛЪБжЛАбredo logСєдкredo log buffer
1ЁЊЁЊ>НЋredo logжБНгГжОУЛЏЕНДХХЬ(ЫљвдгаИіЫЋЁА1ЁБХфжУ,КѓУцЛсНВ)
2ЁЊЁЊ>жЛЪЧАбredo logаДЕНpage cache
ЁИ3ЁЂbin logЁЙ
гУгкжїБИЭЌВН
га3жжИёЪН:
ЁИrowЁЙ:МЧТМећааЪ§Он,ИќаТМЧТМИќаТЧАКѓЕФЪ§Он ШБЕу:МЧТМУПааЪ§Он,еМПеМф
ЁИstatementЁЙ:МЧТМећЬѕsqlгяОф ШБЕу:ПЩФмдьГЩжїДгВЛвЛжТ
?mysql> delete from t where a>=4 and b<=5 limit 1; жїПтЪЧЫїв§a,ФЧУДЩОГ§a=4 БИПтЪЧЫїв§b,ФЧУДЩОГ§b=5
?
ЁИmixedЁЙ:ЛсХаЖЯstatementИёЪНЯТsqlгяОфЪЧЗёЛсдьГЩжїБИВЛвЛжТ,ВЛдьГЩОЭstatementИёЪН,ЗёдђОЭrowИёЪН
ЁИаДШыЛњжЦЁЙ:
1ЁЂЪТЮёжДааЙ§ГЬжаНЋШежОМЧТМЕНbinlog cache(ЯЕЭГЮЊbinlogЗжХфСЫвЛПщФкДц,УПИіЯпГЬвЛЗн)
2ЁЂЪТЮёЬсНЛЪБ,жДааЦїАбbinlog cacheРяЕФЭъећЪТЮёаДШыЕНbinlogжа,ВЂЧхПеbinlog cache
-
write:АбШежОаДЕНЮФМўЯЕЭГЕФpage cache,УЛгааДДХХЬ,ЫйЖШПь -
fsync:НЋЪ§ОнГжОУЛЏЕНДХХЬЕФВйзї,етЪБВХеМДХХЬIOPS
ИљОнsync_binlogВЮЪ§ПижЦ:
0ЁЊЁЊ>жЛwrite,ВЛfsync
1ЁЊЁЊ>УПДЮfsyncN
Дѓгк1ЁЊЁЊ>УПДЮЪТЮёЖМwrite,ЕШРлЛ§ЕНNКѓВХfsync,ПЩвдНЋsync_binlogЩшжУДѓвЛЕуЬсИпадФм(ПЩвдЬсИпIOадФм,ЕЋЪЧШєЗЂЩњвьГЃ,ШежОЛсЖЊЪЇ)
етРяsync_binlogКЭinnodb_flush_log_at_trx_commitХфКЯЩшжУЫЋ1ФЃЪН
ЁИСННзЖЮЬсНЛ:ЁЙ
ЯывЊШЋУцСЫНтСННзЖЮЬсНЛ,ЮвНгЯТДгет3ИіЗНУцЗжЮі:
1ЁЂКЮЮЊСННзЖЮЬсНЛ?
2ЁЂЮЊЪВУДвЊСННзЖЮЬсНЛ?
3ЁЂСННзЖЮЬсНЛЕФЙ§ГЬЪЧдѕбљЕФ?
ЁИКЮЮЊСННзЖЮЬсНЛ?(2PC)ЁЙ
MySQLжадкserverВуМЖБ№гаИіbinlogШежО,ЙщЕЕШежО,гУгкБИЗн,жїДгЭЌВНИДжЦ,ШчЙћВЩгУвЛжїЖрДгМмЙЙ,жїБИЧаЛЛ,ФЧОЭБиаыгУЕНbinlogНјаажїДгЭЌВН,ДЫЪБЪТЮёЬсНЛОЭБиаыБЃжЄredologгыbinlogЕФвЛжТад;
СэЭт,вЛАуЧщПіУЛгаПЊЦєbinlogШежО,ЪТЮёЬсНЛВЛЛсСННзЖЮЬсНЛ,ШєашвЊжїДгЭЌВНОЭБиаыПЊЦєbinlogЪЙгУСННзЖЮЬсНЛБЃжЄЪ§ОнвЛжТадЁЃ
ЁИЮЊЪВУДвЊСННзЖЮЬсНЛЁЙ?БЃжЄredologгыbinlogвЛжТад,БЃжЄЪТЮёдкЖрИів§ЧцЕФдзгадЁЃ
ЁИСННзЖЮЬсНЛЙ§ГЬ?ЁЙ
ЁИPrepare НзЖЮЁЙ:InnoDB НЋЛиЙіЖЮundologЩшжУЮЊ prepare зДЬЌ;НЋ redolog аДЮФМўВЂЫЂХЬ;(ЁИ1ЁЙЁЂЯШаДredolog,ЪТЮёНјШыprepareзДЬЌ)
ЁИCommit НзЖЮЁЙ:Binlog аДШыЮФМў;binlog ЫЂХЬ;InnoDB commit;(ЁИ2ЁЙЁЂprepareГЩЙІ,binlogаДХЬ,ШЛКѓЪТЮёНјШыcommitзДЬЌ,ЭЌЪБЛсдкredologМЧТМcommiteБъЪЖ,ДњБэЪТЮёЬсНЛГЩЙІ)
ЁИredologгыbinlogдѕбљСЊЯЕЦ№РДЕФ?ЁЙ(XID)
-
БРРЃЛжИДЕФЪБКђ,ЛсАДЫГађЩЈУшredo log,ШєredologМШгаprepareгжгаcommit,жБНгЬсНЛ -
ШчЙћХіЕНжЛгаprepareЁЂЖјУЛгаcommitЕФredo log,ОЭФУзХXIDШЅbinlogевЖдгІЕФЪТЮёЁЃ
ЁИдѕбљХаЖЯbinlogЪЧЗёЭъећ?ЁЙ
-
statementИёЪНЕФbinlog,зюКѓЛсгаCOMMIT -
rowИёЪН ФЉЮВгаXID event
ЁИ2pcВЛЭЌЪБПЬЕФБРРЃЛжИД?ЁЙ
-
1ЁЂredologгаcommiteБъЪЖ,ЪТЮёЭъећ,жБНгЬсНЛЪТЮё -
2ЁЂШєredologРяУцЕФЪТЮёжЛгаЭъећЕФprepare,дђХаЖЯЖдгІЪТЮёЕФbinlogЪЧЗёДцдкВЂЭъећ (ЪЧ-ЬсНЛЪТЮё | Зё-ЛиЙіЪТЮё)
ЁИзщЬсНЛЛњжЦЁЙ:Тд
26ЁЂExplainЗжЮі
type:БэЪОMySQLдкБэжаевЕНЫљашааЕФЗНЪН,ЛђепНаЗУЮЪРраЭ
-
ЁИtype=ALL,ШЋБэЩЈУш,MySQLБщРњШЋБэРДевЕНЦЅХфааЁЙ -
ЁИtype=index,Ыїв§ШЋЩЈУшЁЙ -
ЁИtype=range,Ыїв§ЗЖЮЇЩЈУшЁЙ -
ЁИtype=eq_ref,ЮЈвЛЫїв§ЁЙ -
ЁИtype=NULL,MySQLВЛгУЗУЮЪБэЛђепЫїв§,жБНгОЭФмЙЛЕУЕННсЙћ(адФмзюКУ)ЁЙ
ЁИpossible_keysЁЙ: БэЪОВщбЏПЩФмЪЙгУЕФЫїв§ ЁИkeyЁЙ: ЪЕМЪЪЙгУЕФЫїв§ ЁИkey_lenЁЙ: ЪЙгУЫїв§зжЖЮЕФГЄЖШ ЁИrowsЁЙ: ЩЈУшааЕФЪ§СП ЁИExtraЁЙ:
-
using index:ИВИЧЫїв§,ВЛЛиБэ -
using where:ЛиБэВщбЏ -
using filesort:ашвЊЖюЭтЕФХХађ,ВЛФмЭЈЙ§Ыїв§ЕУЕНХХађНсЙћ
27ЁЂдрвГ?дѕбљЫЂаТдрвГ?
ФкДцЪ§ОнвГКЭДХХЬЪ§ОнвГВЛвЛжТЁЃ
ЁИЫЂдрвГЧщОА:ЁЙ
-
ЁИredo logаДТњСЫЁЙ,ЭЃжЙЫљгаИќаТВйзї,НЋcheckpointЯђЧАЭЦНј,ЭЦНјФЧВПЗжШежОЕФдрвГИќаТЕНДХХЬ -
ЁИЯЕЭГФкДцВЛЙЛЁЙ,ашвЊНЋвЛВПЗжЪ§ОнвГЬдЬ,ШчЙћЪЧИЩОЛвГ,жБНгЬдЬОЭааСЫ,дрвГЕФЛА,ашвЊШЋВПЭЌВНЕНДХХЬЁЃ -
mysqlздШЯЮЊ ЁИПеЯаЁЙЪБ -
mysql ЁИе§ГЃЙиБеЁЙжЎЧА
28ЁЂMYSQLЕїгХЦЊ
28.1ЁЂвЛЬѕsqlжДааКмТ§ЕФдвђ?
вЛИі SQL жДааЕФКмТ§,ЮвУЧвЊЗжСНжжЧщПіЬжТл:
1ЁЂДѓЖрЪ§ЧщПіЯТКме§ГЃ,ХМЖћКмТ§,дђгаШчЯТдвђ
(1)ЁЂЪ§ОнПтдкЁИЫЂаТдрвГЁЙ,Р§Шч redo log аДТњСЫашвЊЭЌВНЕНДХХЬЁЃ
(2)ЁЂжДааЕФЪБКђ,ЁИгіЕНЫјЁЙ,ШчБэЫјЁЂааЫјЁЃ
(3)ЁЂЁИsqlаДЕФРУЁЙСЫ
2ЁЂетЬѕ SQL гяОфвЛжБжДааЕФКмТ§,дђгаШчЯТдвђЁЃ
(1)ЁЂУЛгагУЩЯЫїв§ЛђдђЫїв§ЪЇаЇ:Р§ШчИУзжЖЮУЛгаЫїв§;гЩгкЖдзжЖЮНјаадЫЫуЁЂКЏЪ§ВйзїЕМжТЮоЗЈгУЫїв§ЁЃ
(2)ЁЂгаЫїв§ПЩФмЛсзпШЋБэЩЈУш
ЁИдѕбљХаЖЯЪЧЗёзпШЋБэЩЈУшЁЙ:
Ыїв§ЧјЗжЖШ(Ыїв§ЕФжЕВЛЭЌдНЖр,ЧјЗжЖШдНИп),ГЦЮЊЛљЪ§,ЖјЪ§ОнСПДѓЪБВЛПЩФмШЋВПЩЈУшвЛБщЕУЕНЛљЪ§,ЖјЪЧВЩбљВПЗжЪ§ОнНјаадЄВт,ФЧгаПЩФмдЄВтДэСЫ,ЕМжТзпШЋБэЩЈУшЁЃ
28.2ЁЂsqlгХЛЏ(ЖЈЮЛЕЭаЇТЪsql,Т§ВщбЏдѕбљДІРэ)
(1)Ъ§ОнПтжаЩшжУSQLТ§ВщбЏ
ЗНЪНвЛ:аоИФХфжУЮФМў дк my.ini діМгМИаа: жївЊЪЧТ§ВщбЏЕФЖЈвхЪБМф(ГЌЙ§2УыОЭЪЧТ§ВщбЏ),вдМАТ§ВщбЏlogШежОМЧТМ( slow_query_log)
[mysqlld]
//ЖЈвхВщЙ§ЖрЩйУыЕФВщбЏЫуЪЧТ§ВщбЏ,ЮветРяЖЈвхЕФЪЧ2Уы
long_query_time=2
#5.8ЁЂ5.1ЕШАцБОХфжУШчЯТбЁЯю
log-slow-queries="mysql_slow_query.log"
#5.5МАвдЩЯАцБОХфжУШчЯТбЁЯю
slow-query-log=On
slow_query_log_file="mysql_slow_query.?log"
1/МЧТМЯТУЛгаЪЙгУЫїв§ЕФquery
log-query-not-using-indexestpspb16glos?dndnorte/t
ЗНЪНЖў:ЭЈЙ§MySQLЪ§ОнПтПЊЦєТ§ВщбЏ:
mysql>set?global?slow_query_log=ON
mysql>set?global?long_query_time?=?3600;
mysql>set?global?log_querise_not_using_indexes=ON;
(2)ЗжЮіТ§ВщбЏШежО
-
ПЩвдЭЈЙ§ЖЈЮЛЕЭаЇТЪжДааsql -
ЁИshow processlistЁЙ; -
ПЩвдгУ ЁИexplainЁЙЗжЮіжДааМЦЛЎ
(3)гХЛЏ
ЁИЫїв§ЁЙ
1ЁЂОЁСПИВИЧЫїв§,5.6жЇГжЫїв§ЯТЭЦ
2ЁЂзщКЯЫїв§ЗћКЯзюзѓЦЅХфддђ
3ЁЂБмУтЫїв§ЪЇаЇ
4ЁЂдйаДЖрЖСЩйЕФГЁОАЯТ,ПЩвдбЁдёЦеЭЈЫїв§ЖјВЛвЊЮЈвЛЫїв§
?ИќаТЪБ,ЦеЭЈЫїв§ПЩвдЪЙгУchange bufferНјаагХЛЏ,МѕЩйДХХЬIO,НЋИќаТВйзїМЧТМЕНchange bufer,ЕШВщбЏРДСЫНЋЪ§ОнЖСЕНФкДцдйНјаааоИФ.
?
5ЁЂЫїв§НЈСЂддђ(вЛАуНЈдкwhereКЭorder by,ЛљЪ§вЊДѓ,ЧјЗжЖШвЊИп,ВЛвЊЙ§ЖШЫїв§,ЭтМќНЈЫїв§)
ЁИsqlгяОфЁЙ
1ЁЂЗжвГВщбЏгХЛЏ
ИУЗНАИЪЪгУгкжїМќзддіЕФБэ,ПЩвдАбLimitВщбЏзЊЛЛГЩФГИіЮЛжУЕФВщбЏЁЃ
select?*?from?tb_sku?where?id>20000?limit?10;
2ЁЂгХЛЏinsertгяОф
-
ЖрЬѕВхШыгяОфаДГЩвЛЬѕ -
дкЪТЮёжаВхЪ§Он -
Ъ§ОнгаађВхШы(жїМќЫїв§)
ЁИЪ§ОнПтНсЙЙгХЛЏЁЙ
1ЁЂНЋзжЖЮЖрЕФБэЗжНтГЩЖрИіБэ
гааЉзжЖЮЪЙгУЦЕТЪИп,гааЉЕЭ,Ъ§ОнСПДѓЪБ,ЛсгЩгкЪЙгУЦЕТЪЕЭЕФДцдкЖјБфТ§,ПЩвдПМТЧЗжПЊЁЃ
2ЁЂЖдгкОГЃСЊКЯВщбЏЕФБэ,ПЩвдПМТЧНЈСЂжаМфБэ
ЁИгХЛЏЦїгХЛЏЁЙ
1ЁЂгХЛЏЦїЪЙгУMRR
ЁИдРэЁЙ:MRR ЁОMulti-Range ReadЁПНЋIDЛђМќжЕЖСЕНbufferХХађ,ЭЈЙ§АбЁИЫцЛњДХХЬЖСЁЙ,зЊЛЏЮЊЁИЫГађДХХЬЖСЁЙ,МѕЩйДХХЬIO,ДгЖјЬсИпСЫЫїв§ВщбЏЕФадФмЁЃ
mysql?>set?optimizer_switch='mrr=on';
explain?ВщПД?ExtraЖрСЫвЛИіMRR
explain?select?from?stu?where?age?between?10??and??20;
Ждгк Myisam,дкШЅДХХЬЛёШЁЭъећЪ§ОнжЎЧА,ЛсЯШАДее rowID ХХКУађ,дйШЅЫГађЕФЖСШЁДХХЬЁЃ
Ждгк Innodb,дђЛсАДееОлДиЫїв§МќжЕХХКУађ,дйЫГађЕФЖСШЁОлДиЫїв§ЁЃ
ЁИЫГађЖСгХЕу:ЁЙ
ЁИДХХЬдЄЖСЁЙ:ЧыЧѓвЛвГЕФЪ§ОнЪБ,ПЩвдАбКѓУцМИвГЕФЪ§ОнвВвЛЦ№ЗЕЛи,ЗХЕНЪ§ОнЛКГхГижа,етбљШчЙћЯТДЮИеКУашвЊЯТвЛвГЕФЪ§Он,ОЭВЛдйашвЊЕНДХХЬЖСШЁ(ОжВПаддРэ)
ЁИЫїв§БОЩэОЭЪЧЮЊСЫМѕЩйДХХЬ IO,МгПьВщбЏ,Жј MRR,дђЪЧАбЫїв§МѕЩйДХХЬ IO ЕФзїгУ,НјвЛВНЗХДѓЁЙ
https://zhuanlan.zhihu.com/p/148680235
ЁИМмЙЙгХЛЏЁЙ
ЖС/аДЗжРы(жїПтаД,ДгПтЖС)
ЁИгХЛЏзмНс:ЁЙ
1ЁЂЯШЩшжУТ§ВщбЏ(my.iniЛђЪ§ОнПтУќСю)
2ЁЂЗжЮіТ§ВщбЏШежО
3ЁЂЖЈЮЛЕЭаЇТЪsql(show processlist)
4ЁЂexplainЗжЮіжДааМЦЛЎ(ЪЧЗёЫїв§ЪЇаЇ,гУЕНЫїв§УЛ,гУСЫФФаЉ)
5ЁЂгХЛЏ(Ыїв§+sqlгяОф+Ъ§ОнПтНсЙЙгХЛЏ+гХЛЏЦїгХЛЏ+МмЙЙгХЛЏ)
29ЁЂжїДгЭЌВН
жїДгШ§ЬѕЯпГЬ+bin log+relay log(жаМЬШежО)
ЁИдРэ:ЁЙ
1ЁЂbinlogЛсдкЗўЮёЦїЦєЖЏЩњГЩ,гУгкМЧТМжїПтЪ§ОнПтБфИќМЧТМ,ЕБbinlogЗЂЩњБфИќЪБ,жїНсЕуЕФЁИlog dumpЁЙЯпГЬЛсНЋЦфФкШнЗЂИјИїИіДгНсЕу;
2ЁЂШЛКѓДгНсЕуЕФ IOЯпГЬНгЪеbinlogФкШн,ВЂаДШыrelay log(ДгНкЕуЩЯ),ДгНсЕуЕФSQLЯпГЬЖСШЁrelay logФкШнЖдЪ§ОнПтЪ§ОнНјааИќаТжиЗХ,БЃжЄжїДгвЛжТад
ЁИЭЌВНЮЪЬт:ЁЙ
ЁИШЋЭЌВНИДжЦЁЙ:жїПтЧПжЦЭЌВНШежОЕНДгПт,ЕШЁИШЋВПДгПтжДааЭъЁЙВХЗЕЛиПЭЛЇЖЫ,адФмВюЁЃ
ЁИАыЭЌВНИДжЦЁЙ:жїПтЪеЕНжСЩйвЛИіДгПтШЗШЯОЭШЯЮЊВйзїГЩЙІ,ДгПтаДШыШежОГЩЙІЗЕЛиackШЗШЯЁЃ
30ЁЂИпПЩгУМмЙЙ
вЛжївЛБИ
ЁИM-SНсЙЙЁЙ
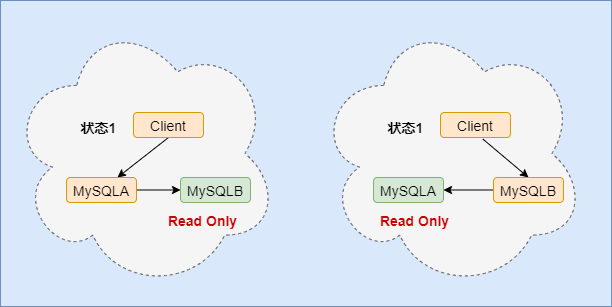
жїПтAгыБИПтB,ПЭЛЇЖЫВйзїA,BАбИќаТAЕФгяОфЭЌВНЙ§РДБОЕижДаа,Ъ§ОнОЭвЛжТСЫ;
НЈвщНЋБИПтЩшжУЮЊжЛЖСФЃЪН,вђЮЊЭЌВНИќаТЯпГЬЪЧГЌМЖШЈЯоВЛгАЯь,ЖјЧвЩшжУЮЊжЛЖСПЩвдШчЯТЁИКУДІЁЙ:
ЁИФПЕФЁЙ:
1ЁЂПЩвдБъЪЖФФИіЮЊБИПт
2ЁЂЕБашвЊДгБИПтВщбЏЪББмУтЮѓВйзї
ЁИжїБИбгГйЁЙ
1ЁЂЁИНтЪЭЁЙ:ЭЌвЛИіЪТЮё,БИПтжДааЭъЪБМфгыжїПтжДааЭъЪБМфжЎВю
2ЁЂЁИдвђЁЙ:
вЛАуЧщПі,ШежОДгжїПтЗЂЕНБИПтдьГЩЕФЪБМфКмЖЬЕФ,жївЊдвђЪЧБИПтНгЪеЭъетИіbinlogжДааетИіЪТЮёдьГЩЕФЪБМф,Ыљвд,жїБИбгГйзюжБНгЕФБэЯжЪЧ,ЁИБИПтЯћЗбжазЊШежО(relay log)ЕФЫйЖШ,БШжїПтЩњВњbinlogЕФЫйЖШвЊТ§ЁЙЁЃ
3ЁЂЁИжїБИбгГйЕФРДдДЁЙ:
IЁЂжїБИПтВПЪ№ЛњЦїадФмВювь
IIЁЂжЛПМТЧжїПтбЙСІ,КіТдБИПтбЙСІ,БИПтаДбЙСІДѓ,еМгУСЫcpuзЪдД,ЕМжТЭЌВНбгГй
-
ЁИНтОіЗНАИ:ЁЙ -
1ЁЂвЛжїЖрДг,ЗжЬЏЖСбЙСІ -
2ЁЂЭЈЙ§binlogЪфГіЕНЭтВПЯЕЭГ,БШШчHadoopетРрЯЕЭГ,ШУЭтВПЯЕЭГЬсЙЉЭГМЦРрВщбЏЕФФмСІЁЃ
-
IIIЁЂДѓЪТЮё,ДѓЪТЮёШУжїПтжДааКмОУ,ФЧУДЕНБИПтвВвЊжДааКмОУ,ЕМжТбгГйКмОУ,БШШчвЛДЮЪЧЩОКмЖрЪ§Он
ЁИжїБИЧаЛЛВпТд(ЁИгЩгкгажїБИбгГй,ЕМжТгаЖржжЧаЛЛВпТдЁЙ)ЁЙ
ПЩППадгХЯШВпТд(ЪЕМЪБЃжЄетИі)?
-
ЁИЧаЛЛСїГЬЁЙ:ЕШЕНжїБИЪ§ОнЭЌВНдйНЋБИПтЩшжУЮЊЖСаД,вЕЮёзЊЕНБИПтB -
ХаЖЯБИПтBЕФЭЌВНбгГйЪБМф( ЁИseconds_behind_masterЁЙ)аЁгкФГИіжЕЪБ,НЋжїПтAЩшжУЮЊжЛЖС( ЁИreadonly=tureЁЙ),ДЫЪБЯЕЭГЛсВЛПЩгУжїДгЖМжЛЖС,ШЛКѓМЬајЕШБИПтЕФЭЌВНбгГйЪБМфЮЊ0СЫ,НЋBБИПтЩшжУЮЊЖСаД( ЁИreadonly=falseЁЙ),ШЛКѓвЕЮёЧыЧѓзЊЕНB -
ЁИЮЪЬтЁЙ:ЕБжїПтЩшжУЮЊжЛЖСЪБ,ДЫЪБОЩЕФжїБИЖМжЛЖС,ЯЕЭГВЛПЩгУ,ЫљвдвЊЧѓБИПтЭЌВНбгГйОЁСПЖЬЪБВХПЊЪМЧаЛЛ
БИПтВЂааИДжЦ
ЁИЧАаажЊЪЖЁЙ:ШєБИПтжДааШежОЕФЫйЖШвЛжБТ§гкжїПтЩњГЩШежОЫйЖШ,бгГйПЩФмЛсДяЕНаЁЪБМЖБ№,ШєжїПтГжајИпбЙСІ,БИПтПЩФмЪМжезЗзЗВЛЩЯжїПтНкзрЁЃВЩгУБИПтВЂааИДжЦНтОі
ЁИФЃаЭ:ЁЙ
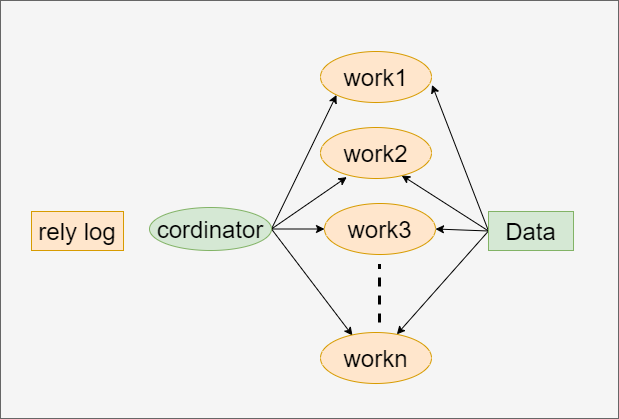
-
1ЁЂcoordinatorИКд№ЖСШЁжазЊШежОКЭЗжЗЂЪТЮё -
2ЁЂИїИіworkersИКд№еце§жДаа -
3ЁЂworkersИіЪ§гЩslave_paralles_wokersОіЖЈ,вЛАуЩшжУ8-16(32КЫ),БИПтЛЙашвЊЦфЫћВщбЏ
ЁИcoordinatorЗжЗЂЙцдђ(УПИіАцБОаызёЪиЁЙ)
-
1ЁЂИќаТЭЌвЛааЕФСНИіЪТЮёаыЗжХфЕНЭЌвЛИіworker -
2ЁЂЭЌвЛИіЪТЮёВЛФмВ№Зж,ашЗжХфЕНЭЌвЛИіworker


ФуКУ,ЮвЪЧаЁСњ,вЛЮЛФЉСїЖўБОГЩЙІФцЯЎBATЕФУШаТГЬађдБЁЃ
ЙЋжкКХ:жМдкАяДѓМвЭъУРФцЯЎBATЕФдДДММЪѕКХЁЃзЈзЂгкЗжЯэJAVAММЪѕЁЂMySQLЁЂRedisЁЂЗжВМЪНЁЂМЦЭјЁЂOSЕШ;етРяВЛНігаДѓГЇУцЪдЬтЯъНтЁЂДѓГЇФкЭЦ,ЛЙгаЁИЖўБОФцЯЎBATОбщЁЙгыКХжїЧяеаРњОМИЪЎГЁДѓжаГЇУцЪдзмНсЬсСЖЕФЁИУцЪдБЪМЧЁЙЗжЯэЁЃвдМАКХжїЕФвЛаЉЁИЭЖзЪжЎЕРЁЙгыЁИИБвЕжЎЗЈЁЙ!
ЙизЂЙЋжкКХ,КЭаЁСњвЛЦ№ЬНЫїИќЖрОЋВЪЁЃЯждкЙизЂ,КѓЬЈЛиИДЁИДѓГЇУцЪдЁЙСьШЁЁООЋЦЗУцЪдБЪМЧЁПжњФуГхЛїДѓГЇ!!,ЛиИДЁИЛљгкШЫЙЄжЧФмЕФжЧЛлаЃдАжњЪжЁЙСьШЁКХжїЧяеаУцЪдОЋЦЗЯюФПЁЃЁИУцЪдБЪМЧЁЙжњФуеЖЛёДѓГЇoffer!!
зюКѓОѕЕУетЦЊЮФеТВЛДэЕФЭЌбЇ,вЛЖЈвЊМЧЕУИјаЁСњЁИзЊЗЂЁЙЁЂЁИдйПДЁЙЁЂЁИЗжЯэЁЙИјИќЖрЭЌбЇгД!